Sie können in der Dataflow-Monitoring-Oberfläche Diagramme zum Autoscaling-Monitoring für Streamingjobs aufrufen. Diese Diagramme zeigen Messwerte für die Dauer eines Pipelinejobs und enthalten folgende Informationen:
- Die Anzahl der Worker-Instanzen, die von Ihrem Job zu einem beliebigen Zeitpunkt verwendet werden
- Die Autoscaling-Logdateien
- Der geschätzte Rückstand im Zeitverlauf
- Die durchschnittliche CPU-Auslastung im Zeitverlauf
Die Diagramme sind vertikal ausgerichtet, sodass Sie die Messwerte für Backlog und CPU-Auslastung mit Worker-Skalierungsereignissen in Beziehung setzen können.
Weitere Informationen dazu, wie Dataflow Autoscaling-Entscheidungen trifft, finden Sie in der Dokumentation zu Autotuning-Features. Weitere Informationen zu Dataflow-Monitoring und -Messwerten finden Sie unter Dataflow-Monitoring-Oberfläche verwenden.
Auf Autoscaling-Monitoring-Diagramme zugreifen
Sie können mit derGoogle Cloud consoleauf die Monitoring-Oberfläche von Dataflow zugreifen. So greifen Sie auf den Tab Autoscaling mit Messwerten zu:
- Melden Sie sich in der Google Cloud Console an.
- Wählen Sie Ihr Google Cloud Projekt aus.
- Öffnen Sie das Navigationsmenü.
- Klicken Sie in Analytics auf Dataflow. Eine Liste der Dataflow-Jobs mit ihrem Status wird angezeigt.
- Klicken Sie auf den Job, den Sie überwachen möchten, und dann auf den Tab Autoscaling.
Autoscaling-Messwerte überwachen
Der Dataflow-Dienst wählt automatisch die zum Ausführen des Autoscaling-Jobs erforderliche Anzahl von Worker-Instanzen aus. Die Anzahl der Worker-Instanzen kann sich im Laufe der Zeit entsprechend den Jobanforderungen ändern.
Sie können Autoscaling-Messwerte auf dem Tab Autoscaling der Dataflow-Oberfläche ansehen. Die Messwerte sind in folgenden Diagrammen organisiert:
In der Autoscaling-Aktionsleiste werden der aktuelle Autoscaling-Status und die Anzahl der Worker angezeigt.
Autoscaling
Das Diagramm Autoscaling zeigt ein Zeitreihendiagramm mit der aktuellen Anzahl von Workern, der Zielanzahl der Worker sowie der Mindest- und Höchstzahl von Workern. “

Klicken Sie auf Autoscaling-Logs anzeigen, um die Autoscaling-Logs aufzurufen.
Klicken Sie auf Weiteren Verlauf, um den Verlauf der Autoscaling-Änderungen aufzurufen. Eine Tabelle mit Informationen zum Worker-Verlauf Ihrer Pipeline wird angezeigt. Der Verlauf umfasst Autoscaling-Ereignisse, einschließlich der Anzahl der Worker, die die minimale oder maximale Worker-Anzahl erreicht haben.
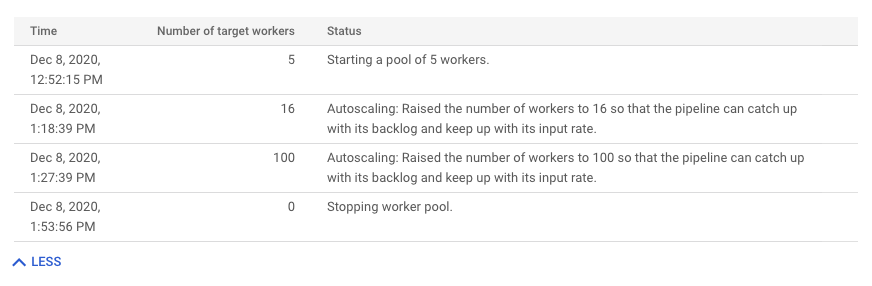
Gründe für das Autoscaling (nur Streaming Engine)
Das Diagramm Gründe für das Autoscaling zeigt, warum das Autoscaling in einem bestimmten Zeitraum entweder hoch- oder herunterskaliert wurde oder keine Aktionen ausgeführt hat.
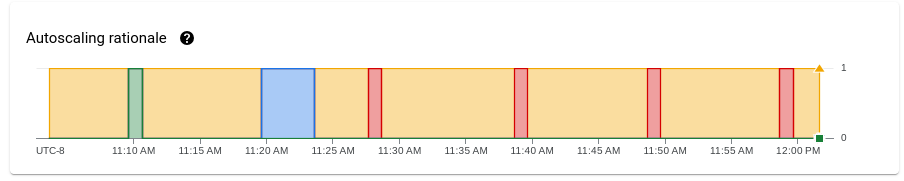
Wenn Sie eine Beschreibung der Begründung an einem bestimmten Punkt sehen möchten, bewegen Sie den Mauszeiger auf das Diagramm.
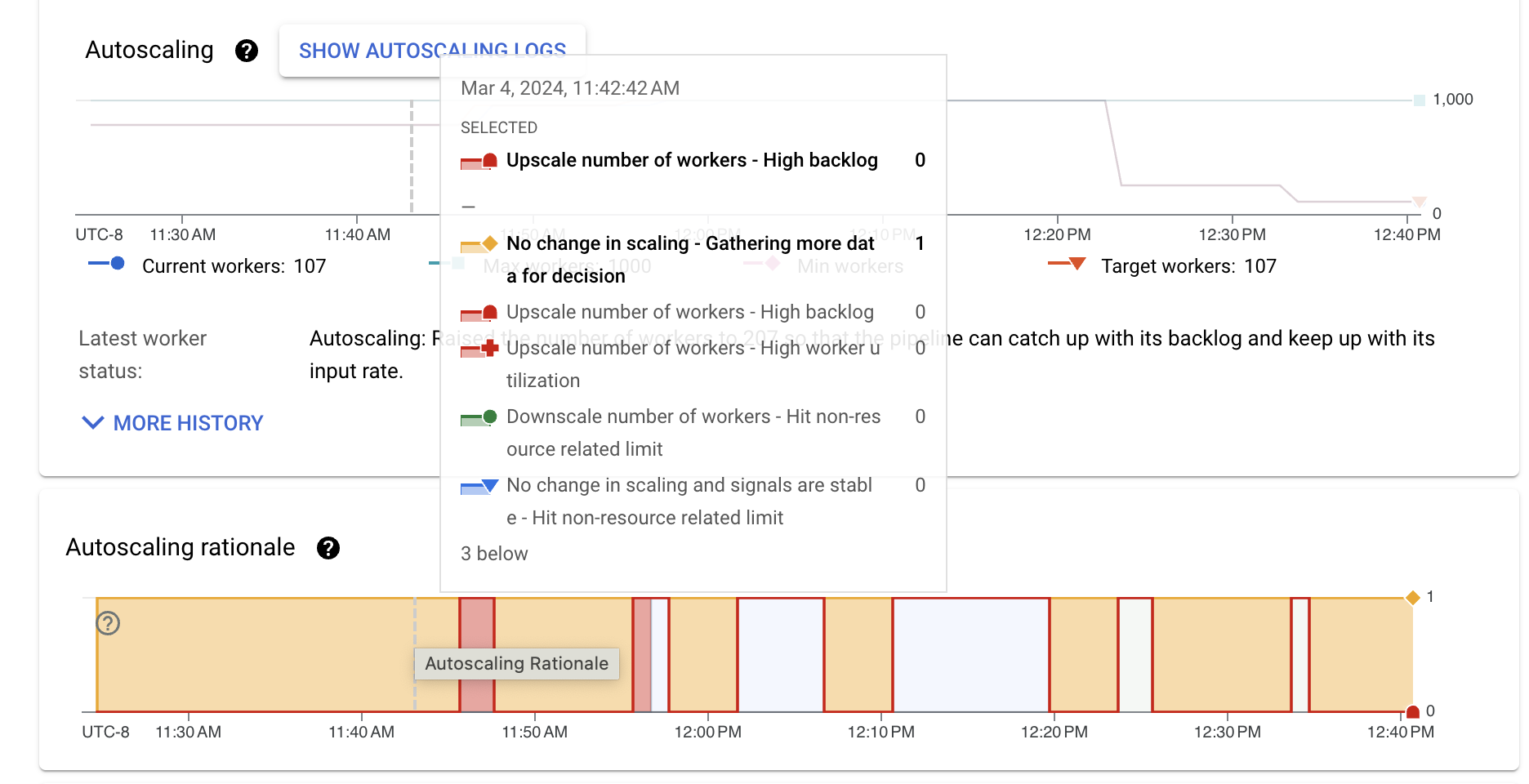
In der folgenden Tabelle sind Skalierungsaktionen und mögliche Skalierungsgründe aufgeführt.
| Skalierungsaktion | Begründung | Beschreibung |
|---|---|---|
| Keine Änderung der Skalierung | Mehr Daten für Entscheidung sammeln | Das Autoscaling hat nicht genügend Signale zum Hoch- oder Herunterskalieren. Ein Beispiel: Der Status des Worker-Pools wurde kürzlich geändert oder Rückstands- oder Auslastungsmesswerte schwanken. |
| Keine Änderung der Skalierung, stabile Signale | Nicht ressourcenbezogenes Limit erreicht | Die Skalierung wird durch ein Limit wie die Schlüsselparallelität oder die konfigurierten Mindest- und Höchstzahl der Worker eingeschränkt. |
| Geringer Rückstand und hohe Worker-Auslastung | Das Autoscaling der Pipeline hat sich angesichts des aktuellen Traffics und der aktuellen Konfiguration auf einen stabilen Wert eingestellt. Es ist keine Änderung der Skalierung erforderlich. | |
| Hochskalieren | Hoher Rückstand | Hochskalieren, um Rückstände zu reduzieren. |
| Hohe Worker-Auslastung | Hochskalierung, um die CPU-Zielauslastung zu erreichen. | |
| Nicht ressourcenbezogenes Limit erreicht | Die Mindestanzahl der Worker wurde aktualisiert und die aktuelle Anzahl der Worker liegt unter dem konfigurierten Mindestwert. | |
| Herunterskalieren | Geringe Worker-Auslastung | Herunterskalieren, um die CPU-Zielauslastung zu erreichen. |
| Nicht ressourcenbezogenes Limit erreicht | Die maximale Anzahl von Workern wurde aktualisiert und die aktuelle Anzahl von Workern liegt über dem konfigurierten Maximum. |
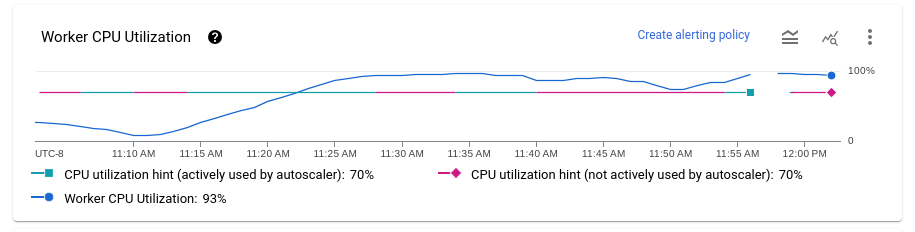
Worker-CPU-Auslastung
Die CPU-Auslastung ist die genutzte CPU-Kapazität, geteilt durch die CPU-Kapazität, die für die Verarbeitung verfügbar ist. Das Diagramm Mittlere CPU-Auslastung zeigt die durchschnittliche CPU-Auslastung für alle Worker im Zeitverlauf, den Hinweis zur Worker-Auslastung und ob Dataflow den Hinweis aktiv als Ziel verwendet hat.
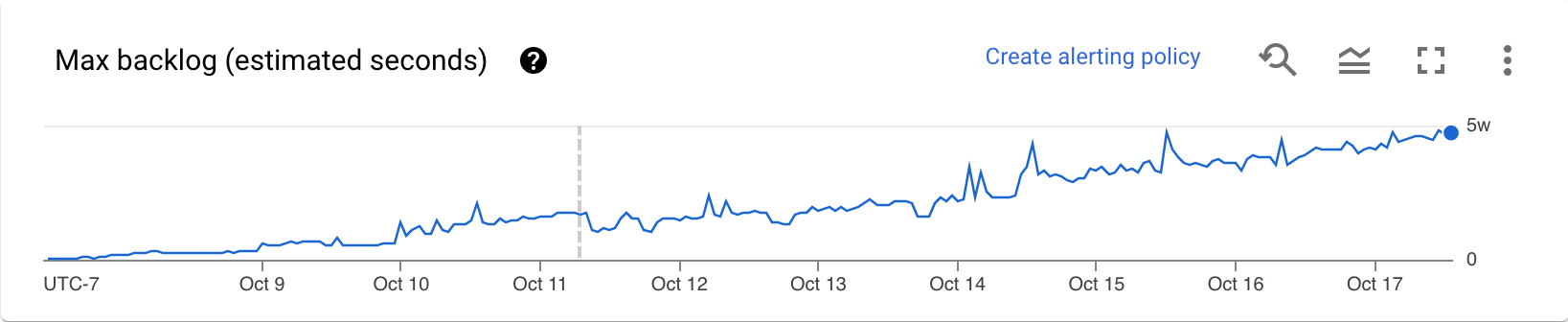
Rückstand (nur Streaming Engine)
Das Diagramm Maximaler Rückstand enthält Informationen zu Elementen, die noch verarbeitet werden müssen. Das Diagramm zeigt eine Schätzung der Zeit in Sekunden, die benötigt wird, um den aktuellen Rückstand zu verarbeiten, wenn keine neuen Daten eintreffen und sich der Durchsatz nicht ändert. Die geschätzte Rückstandszeit wird sowohl aus dem Durchsatz als auch aus den Rückstandbyte aus der Eingabequelle berechnet, die noch verarbeitet werden müssen. Dieser Messwert wird vom Feature Streaming-Autoscaling verwendet, um zu bestimmen, wann hoch- oder herunterskaliert werden soll.
Daten für dieses Diagramm sind nur für Jobs verfügbar, die Streaming Engine verwenden. Wenn Ihr Streamingjob Streaming Engine nicht verwendet, ist das Diagramm leer.
Empfehlungen
Im Folgenden finden Sie einige Verhaltensweisen, die Sie in Ihrer Pipeline evtl. beobachten können, sowie Empfehlungen zum Anpassen des Autoscalings:
Übermäßiges Herunterskalieren: Wenn die Ziel-CPU-Auslastung zu hoch eingestellt ist, sehen Sie möglicherweise ein Muster, bei dem Dataflow herunterskaliert, der Rückstand wächst und Dataflow wieder hochskaliert wird, um es auszugleichen, anstatt zu einer stabilen Zahl von Workern zu konvergieren. Um dieses Problem zu beheben, können Sie versuchen, einen niedrigeren Hinweis zur Worker-Auslastung festzulegen. Beobachten Sie die CPU-Auslastung an dem Punkt, an dem der Backlog zu wachsen beginnt, und legen Sie den Hinweis zur Auslastung auf diesen Wert fest.
Zu langsames Upscaling: Wenn das Hochskalieren zu langsam ist, kann es bei Traffic-Spitzen zu Verzögerungen kommen, was zu Phasen mit erhöhter Latenz führt. Versuchen Sie, den Hinweis zur Worker-Auslastung zu verringern, damit Dataflow schneller skaliert wird. Beobachten Sie die CPU-Auslastung an dem Punkt, an dem der Backlog zu wachsen beginnt, und legen Sie den Auslastungshinweis auf diesen Wert fest. Behalten Sie sowohl die Latenz als auch die Kosten im Blick, da ein niedrigerer Hinweiswert die Gesamtkosten für die Pipeline erhöhen kann, wenn mehr Worker bereitgestellt werden.
Übermäßiges Hochskalieren. Wenn Sie feststellen, dass das Upscaling zu stark ist und dadurch die Kosten steigen, sollten Sie den Hinweis zur Worker-Auslastung erhöhen. Behalten Sie die Latenz im Blick, damit sie für Ihr Szenario im akzeptablen Bereich bleibt.
Weitere Informationen finden Sie unter Hinweis zur Worker-Auslastung festlegen. Wenn Sie mit einem neuen Wert für den Hinweis zur Worker-Auslastung experimentieren, warten Sie nach jeder Anpassung einige Minuten, bis sich die Pipeline stabilisiert hat.