BigQuery 特集: データ操作(DML)
Google Cloud Japan Team
※この投稿は米国時間 2020 年 11 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery 特集の以前の投稿で、BigQuery にデータを取り込み、データセットに対してクエリを実行する方法について説明しました。このブログ投稿では、BigQuery でデータ操作ステートメントを実行して、BigQuery に保存されているデータを追加、変更、削除する方法について解説します。さっそく始めましょう。
BigQuery でのデータ操作
BigQuery では 2016 年以降、標準 SQL のデータ操作言語(DML)機能がサポートされています。DML を使うと、BigQuery データセットの行と列の挿入、更新、削除が可能になります。BigQuery の DML では、単一ジョブでテーブル内の多数の行のデータを操作したり、テーブルに対して無制限の数の DML ステートメントを実行したりすることができます。つまり、より頻繁にテーブル内のデータに変更を適用し、データソースの変更をデータ ウェアハウスに反映して最新の状態に保つことが可能です。
このブログ投稿では、以下の点について説明します。
一般的な DML ステートメントのユースケースと構文
割り当てや料金などのトピックを含む、DML を使用する場合の考慮事項
BigQuery で DML を使用するためのベスト プラクティス
この投稿の例では、次のテーブルを使用します。
Transactions
- Customer
- Product
まず、BigQuery でサポートされている DML ステートメント(INSERT、UPDATE、DELETE、MERGE)とその使用方法について説明します。
INSERT ステートメント
INSERT ステートメントを使うと、テーブルに新しい行を追加することができます。新しい行は明示的な値を使用することで挿入可能ですが、テーブルやビューへのクエリの実行、またはサブクエリの使用によっても挿入できます。追加される値は、ターゲット列のデータ型との互換性が必要です。以下に、BigQuery テーブルに行を追加するパターンをいくつか示します。
INSERT(明示的な値を使用): 明示的な値を一括挿入する場合に使用できます。
- INSERT(SELECT ステートメントを使用): 通常はテーブルのコンテンツを別のテーブルまたはパーティションにコピーする場合に使用します。空のテーブルを作成し、そこに既存のテーブル(例: 一般公開データセット)からデータを追加するとしましょう。その場合は INSERT INTO … SELECT ステートメントを使用すると、ターゲット テーブルに新しいデータを追加できます。
- INSERT(サブクエリまたは共通テーブル式(CTE)を使用): 以前の投稿で説明したとおり、WITHステートメントを使うと、サブクエリに名前を付けて、それを SELECT や INSERT ステートメントなどの後続のクエリで使用できます(共通テーブル式とも呼ばれます)。次の例で挿入される値は、複数のテーブルで JOIN オペレーションを実行するサブクエリを使用して計算されます。
DELETE ステートメント
DELETE ステートメントを使うと、テーブルから行を削除できます。DELETE ステートメントを使用する場合は、WHERE 句と条件文を指定する必要があります。
DELETE(テーブルからすべての行を削除)
- DELETE(WHERE 句を使用):WHERE 句を使用して削除する特定の行を指定します。
- DELETE(サブクエリを使用): サブクエリを使用して削除する行を指定します。サブクエリでは他のテーブルをクエリするか、JOIN を実行して他のテーブルと結合できます。
UPDATE ステートメント
UPDATE ステートメントを使うと、テーブル内の既存の行を更新できます。DELETE ステートメントと同じように、各 UPDATE ステートメントには WHERE 句と条件文を含める必要があります。テーブル内のすべての行を更新する場合は WHERE true とします。
以下に、BigQuery テーブルで行を更新するパターンをいくつか示します。
UPDATE(WHERE 句を使用):WHERE 句を UPDATE ステートメントで使用して、変更する必要のある行を指定します。また、SET 句を使用して、特定の列を更新します。
- UPDATE(JOIN を使用): データ ウェアハウスで、別のテーブルの条件に基づいてテーブルを更新する場合に一般的なパターンです。前の例では、product テーブルの quantity 列と price 列を更新しました。次に、product テーブルの最新の値に基づいて transactions テーブルを更新します(注: FROM 句でソーステーブルと結合する際、更新するターゲット テーブルの行は、最大で 1 つの行と対応させる必要があります。複数の行が対応している場合、ランタイム エラーが発生します)。
- UPDATE(ネストされたフィールドと繰り返しフィールドの更新): 以前の投稿で説明したとおり、BigQuery は、STRUCT と ARRAY を使用するネストされたフィールドと繰り返しフィールドをサポートしているため、自然な方法で非正規化データを表現できます。BigQuery の DML を使うと、ネスト構造も UPDATE 可能です。product テーブルでは、specs は color 属性と dimension 属性を含むネスト構造で、dimension 属性はネスト構造です。次の例では、ネストされたフィールドの特定の行を WHERE 句で指定し、UPDATE しています。
MERGE ステートメント
MERGE ステートメントは、別のテーブルと一致する値に基づいて INSERT、UPDATE、DELETE の各オペレーションをテーブルで 1 つの「upsert」オペレーションに結合できる、強力なコンストラクトであり、最適化パターンです。スタースキーマやスノーフレーク スキーマを使用するエンタープライズ データ ウェアハウスでは、一般的にはソースデータに関するデータの履歴を保持する、変化が緩やかなディメンション(SCD)のテーブルの維持に使用されます(追加されたディメンションに対する新しいレコードの挿入、ソースに存在しないディメンションの削除やフラグ付け、ソース内で変更された値の更新など)。MERGE ステートメントは、ディメンション テーブルでこれらのオペレーションを 1 つの DML ステートメントで管理するために使用できます。
以下に、MERGE ステートメントの汎用の構造を示します。
MERGE オペレーションは、merge_condition に基づいてターゲットとソースの間で JOIN を実行します。次に、一致ステータス(MATCHED、NOT MATCHED BY TARGET、NOT MATCHED BY SOURCE)に応じて、対応するアクションが実行されます。MERGE オペレーションでは、ターゲット行ごとに最大で 1 つのソース行を対応させる必要があります。複数の行が対応している場合、オペレーションでエラーが発生します。次の図は、ソーステーブルとターゲット テーブルでの MERGE オペレーションを、対応するアクション(INSERT、UPDATE、DELETE)とともに示しています。
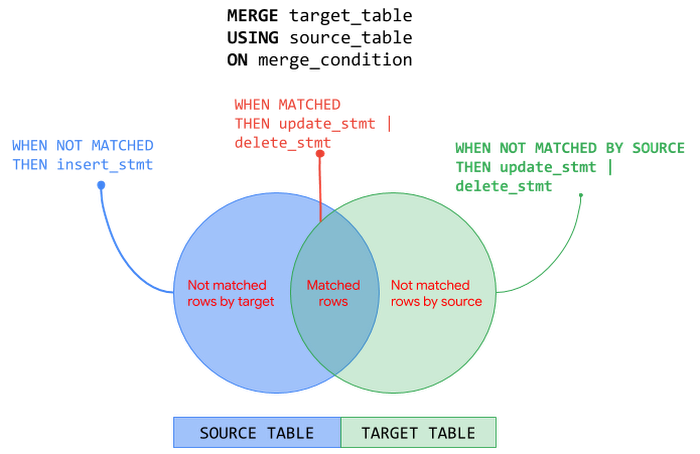
MERGE オペレーションは、サブクエリ、結合、ネスト構造、繰り返し構造として、ソースで使用できます。MERGE オペレーションでサブクエリを使用して、条件に応じて INSERT または UPDATE を実行するパターンを見てみましょう。次の例では、MERGE オペレーションは、ターゲット テーブルに存在しない新しい行がソーステーブルに存在する場合、その行を INSERT します。ソーステーブルとターゲット テーブルの両方で一致する行がある場合、その行を UPDATE します。
WHEN 句でオプションの検索条件を使用して、異なる方法でオペレーションを実行することもできます。次の例では、他の商品とは異なる方法で ‘Furniture’ 商品の価格を導き出しています。修飾された WHEN 句が複数ある場合には、行に対して最初の WHEN 句のみが実行されます。
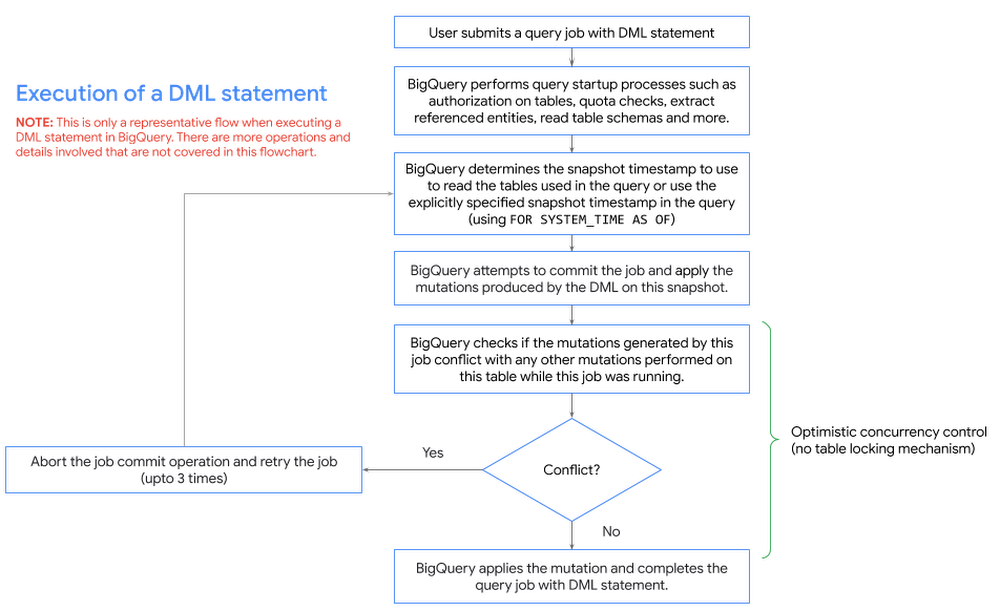
BigQuery で DML ステートメントを実行すると、成功時に自動的にトランザクションを commit する暗黙のトランザクションが起動されます。BigQuery での DML ステートメント実行の仕組みについては、こちらの記事をご覧ください。
割り当てと上限
BigQuery では、さまざまな理由で割り当てが適用されます。その理由の一つとして、予期しない使用量の急増を防ぎ、Google Cloud ユーザーのコミュニティを保護することが挙げられます。BigQuery の DML ステートメントに上限はありません。つまり、BigQuery ではテーブルに対して無制限の数の DML ステートメントを実行できます。ただし、データ ミューテーション オペレーションを設計する際に、BigQuery により次の割り当てが適用されます。
DML ステートメントは割り当て上限の対象にはなりませんが、割り当て数(1 日あたりのテーブル オペレーション数と 1 日あたりのパーティション変更数)にカウントされます。DML ステートメントはこの上限により失敗することはありませんが、他のジョブは失敗する場合があります。
DML ジョブの同時実行
BigQuery は、テーブル内の行を変更する DML ステートメントの同時実行を管理します。BigQuery はマルチバージョンかつ ACID 対応のデータベースです。スナップショット分離を使用して、テーブルで複数の同時オペレーションを処理できます。同じテーブルで変更 DML ステートメントを同時に実行すると、変更が競合して失敗することがあります。その場合、BigQuery は失敗したジョブを再試行します。そのため、最初に commit されたジョブが優先されます。つまり、短い DML オペレーションを多数実行した場合、実行時間が長いオペレーションほど優先度が低くなることが考えられます。BigQuery が DML ジョブの同時実行を管理する方法については、こちらの記事をご覧ください。
同時実行可能な DML ジョブ数
INSERT DML ジョブの同時実行: 24 時間の中で、テーブルに挿入する最初の 1,000 件の INSERT ステートメントを同時に実行できます。この上限に達すると、テーブルに書き込む INSERT ステートメントの同時実行数は 10 件に制限されます。10 件を超えた INSERT DML ジョブは、PENDING 状態でキューに入れられます。実行中のジョブが終了すると、次の PENDING ジョブがキューから出され、実行されます。現在、1 つのテーブルに対して最大 100 件の INSERT DML ステートメントを、いつでもキューに入れることができます。

- UPDATE、DELETE、MERGE の各 DML ジョブの同時実行: BigQuery は、1 つのテーブルで一定数の変更 DML ステートメント(UPDATE、DELETE、MERGE)を同時実行します。同時実行の上限に達すると、BigQuery は追加の変更 DML ジョブを PENDING 状態で自動的にキューに入れます。実行中のジョブが終了すると、次の PENDING ジョブがキューから出され、実行されます。BigQuery では現在、各テーブルで最大 20 件まで変更 DML ジョブを PENDING 状態でキューに登録できます。この上限を超えた同時変更 DML は失敗します。この上限は、テーブルに対する読み込みジョブまたは INSERT DML ステートメントの同時実行による影響を受けません。これらのジョブやステートメントは、ミューテーション オペレーションの実行には影響しないためです。
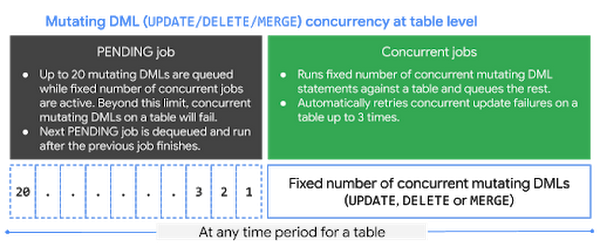
同時実行 DML ジョブが競合した場合の影響
DML の競合は、同時に実行された変更 DML ステートメント(UPDATE、DELETE、MERGE)が、テーブル内の同じパーティションを変更しようとした場合に発生します。この場合、同時更新が失敗することがあります。同じパーティションのデータを変更しない限り、変更 DML ステートメントの同時実行は成功します。同時更新が失敗した場合、BigQuery はクエリで使用するテーブルの読み取りに使用する新しいスナップショット タイムスタンプを決定し、その後ミューテーションを新しいスナップショットに適用します。このようにしてジョブを再試行することで、BigQuery は失敗した同時更新を自動的に処理します。BigQuery は同時更新に失敗しても、テーブルに対して最大 3 回まで再試行します。テーブルにデータを挿入しても、同時実行されている他の DML ステートメントと競合しません。DML オペレーションをグループ化し、UPDATE や DELETE を一括で実行することで、競合を緩和できます。
DML ステートメントの料金
システム内で DML オペレーションを設計する場合、BigQuery での DML ステートメントの料金設定を理解し、費用とパフォーマンスを最適化することが重要です。BigQuery での DML クエリの料金は、DML ステートメントを使用するクエリジョブで処理したバイト数に基づいて計算されます。次の表に、パーティション分割テーブルまたはパーティション分割なしのテーブルに基づいて処理されるバイト数の計算の概要を示します。
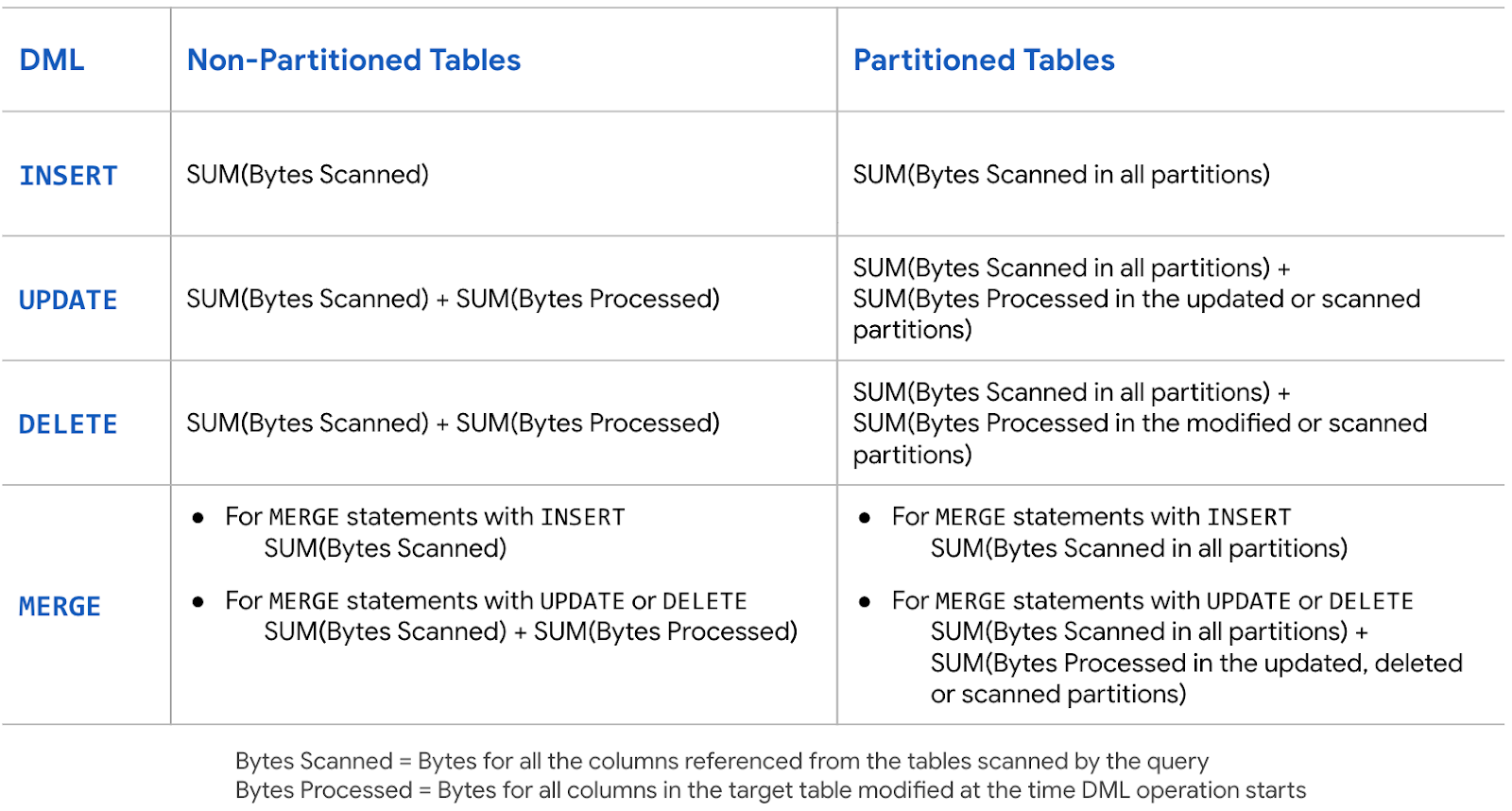
DML の料金はクエリジョブで処理したバイト数に基づいて計算されるため、SELECT クエリを使用してデータのクエリを実行する際のベスト プラクティスは、DML クエリジョブにも適用されます。たとえば、必要なデータに対してのみクエリを実行することで読み取るバイト数を制限する方法のほか、パーティション分割テーブルを使用したパーティションのプルーニング、クラスタ化テーブルを使用したブロック プルーニングなどがあります。
以下に、クエリジョブが読み取るバイト数の管理と、費用の最適化に関するベスト プラクティスを紹介します。
パーティション分割テーブルとパーティション分割なしのテーブルでの DML
以前の BigQuery 特集の投稿で、BigQuery のパーティション分割テーブルを使用して、簡単にデータの管理とクエリを行い、クエリのパフォーマンスを向上させ、クエリが読み取るバイト数を減らして費用を管理する方法について説明しました。DML ステートメントについても、変更が特定のパーティションに限定されている場合、パーティション分割テーブルを使用することで更新プロセスを高速化することができます。たとえば、DML ステートメントは(取り込み時間パーティション分割テーブルとパーティション分割テーブル両方の)複数のパーティション(日付、タイムスタンプ、日時、整数範囲の各パーティション分割)でデータを更新できます。
BigQuery 特集: ストレージの概要の投稿で示したパーティショニング セクションの例を参照しましょう。この例では、Stack Overflow の投稿に基づいて、一般公開データセットからパーティション分割なしのテーブルとパーティション分割テーブルを作成しました。
パーティション分割なしのテーブル
- パーティション分割テーブル
パーティション分割なしのテーブルとパーティション分割テーブルで UPDATE ステートメントを実行して、特定の日に作成されたすべての Stack Overflow の投稿の列を変更してみましょう。
パーティション分割なしのテーブル
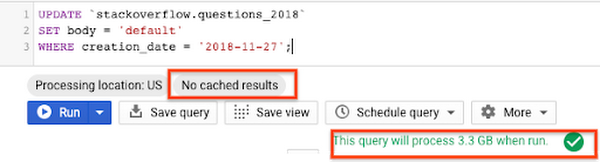
- パーティション分割テーブル
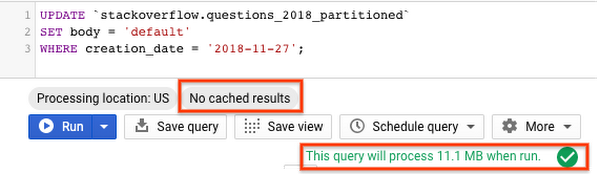
この例では、パーティション分割テーブルの場合、DML ジョブを使用したクエリは必要なパーティションのみをスキャンして更新し、約 11 MB のデータを処理しています。一方、パーティション分割なしのテーブルの DML ジョブでは、テーブル全体をスキャンし、約 3.3 GB のデータを処理しています。このように、パーティション分割テーブルで DML オペレーションを行うと、パーティション分割なしのテーブルより高速かつ低コストで処理できます。
DML ステートメント(INSERT、UPDATE、DELETE、MERGE)をパーティション分割テーブルとパーティション分割なしのテーブルで使用する場合、以前の投稿で説明したものと同じ DML 構文に従います。取り込み時間パーティション分割テーブルを使用する場合以外は、_PARTITIONTIME疑似列を参照するパーティションを指定します。以下に、取り込み時間パーティション分割テーブル用とパーティション分割テーブル用の INSERT ステートメントの例を示します。
INSERT(取り込み時間パーティション分割テーブル用)
- INSERT(パーティション分割テーブル用)
パーティション分割テーブルに対して MERGE ステートメントを使用する場合、search_condition フィルタまたは merge_condition フィルタを使用して、DML ステートメントの対象とするパーティションを限定できます。
パーティション分割テーブルとパーティション分割なしのテーブルでの DML の使用については、BigQuery ドキュメントをご覧ください。
DML と BigQuery ストリーミング挿入
BigQuery 特集: データの取り込みの投稿で、tabledata.insertAll メソッドを使用してリアルタイムで BigQuery にデータをストリーミングすることにより、継続的な取り込みスタイルを可能にするストリーミング取り込みパターンについて説明しました。BigQuery では、テーブル内の書き込みのリピート間隔に基づいて、アクティブなストリーミング バッファによりテーブルに対する DML 変更を実行できます。
ストリーミングを使用して最近テーブルに書き込まれた行は変更できません。最近の書き込みとは通常、30 分以内に行われたものを指します。
テーブル内の他のすべての行は、変更 DML ステートメント(UPDATE、DELETE、MERGE)を使用して変更できます。
BigQuery で DML を使用するためのベスト プラクティス
ポイント固有の DML ステートメントは使用せず、代わりに DML オペレーションをグループ化します。
現在 BigQuery では DML ステートメントを無制限に実行できますが、以下の理由により、一括または大規模なミューテーションを実行することを検討してください。
BigQuery DML ステートメントの目的は一括更新です。ポイント固有の DML ステートメントを使用すると、BigQuery をオンライン トランザクション処理(OLTP)システムのように扱おうとしていることになります。BigQuery は、ポイント検索ではなく、テーブル スキャンを使用したオンライン分析処理(OLAP)に重点が置かれています。
データを変更する各 DML ステートメントは暗黙的にトランザクションを起動します。DML ステートメントをグループ化することで、不要なトランザクションのオーバーヘッドの発生を回避できます。
DML オペレーションは、全テーブル スキャン、パーティション スキャン、クラスタ スキャンのクエリで処理したバイト数に基づいて課金されます。DML ステートメントをグループ化することで、処理するバイト数を制限できます。
テーブルでの DML オペレーションは、短時間に複数の DML ステートメントを送信した場合はレート制限の対象となります。オペレーションをグループ化することで、レート制限による失敗のリスクを軽減できます。
以下に、一括ミューテーションを実行する方法をいくつか示します。
別のテーブルのコンテンツに基づいて、MERGE ステートメントを使用してミューテーションをバッチ処理します。MERGE ステートメントは、INSERT、UPDATE、DELETE の各オペレーションを 1 つのステートメントに結合してアトミックに実行できる最適化コンストラクトです。
サブクエリが変更する行を特定し、DML オペレーションが一括でデータを変更する DML ステートメントが含まれるサブクエリまたは相関サブクエリを使用します。
この投稿ですでに説明したとおり、明示的な値、サブクエリ、共通テーブル式(CTE)を使用して、単一行の INSERT を一括挿入に置き換えます。たとえば、次のようなポイント固有の INSERT ステートメントを BigQuery でそのまま実行することはアンチパターンとなるため推奨されません。
上記のステートメントは、一括オペレーションを実行する 1 つの INSERT ステートメントに置き換えることができます。
ユースケースで単一行の挿入が頻繁に行われる場合は、代わりにデータのストリーミングを検討してください。無料の読み込みジョブとは異なり、ストリーム データには料金がかかります。
ミューテーションのバッチ処理の例については、BigQuery ドキュメントをご覧ください。
大規模なミューテーションに CREATE TABLE AS SELECT(CTAS)を使用する
大規模な変更を行うと、DML ステートメントの料金が高額になることがあります。そのような場合には、代わりに CTAS(CREATE TABLE AS SELECT)を使用します。UPDATE や DELETE ステートメントを大量に実行する代わりに、SELECT ステートメントを実行し、CREATE TABLE AS SELECT オペレーションを使用して、新しいターゲット テーブルにクエリ結果を変更後のデータとともに保存します。変更後のデータを使用して新しいターゲット テーブルを作成したら、元のターゲット テーブルを破棄します。この場合、DML ステートメントを処理するよりも SELECT ステートメントを使用するほうが低コストになる可能性があります。
大量の INSERT ステートメントを使用するもう一つの典型的なシナリオは、既存のテーブルから新しいテーブルを作成する場合です。複数の INSERT ステートメントを使用する代わりに、CREATE TABLE AS SELECT ステートメントを使用し、1 回のオペレーションで新しいテーブルを作成してすべての行を挿入します。
すべての行を削除する際に TRUNCATE を使用する
テーブルからすべての行を削除する場合、DELETE オペレーションを実行する代わりに TRUNCATE TABLE ステートメントを使用します。TRUNCATE TABLE ステートメントは、DDL(データ定義言語)オペレーションです。テーブルからすべての行を削除しますが、テーブル スキーマ、説明、ラベルなどのテーブルのメタデータはそのまま残ります。TRUNCATE はメタデータ オペレーションのため、料金は発生しません。
データを分割する
この投稿ですでに説明したとおり、パーティション分割テーブルを使用することで、テーブルでの DML オペレーションのパフォーマンスを大幅に向上させるとともに、費用を最適化することができます。パーティショニングにより、変更をテーブル内の特定のパーティションのみに限定できます。たとえば、MERGE ステートメントを使用する場合、MERGE の実行前に影響を受けるパーティションを事前計算することで費用を削減可能です。また、MERGE ステートメントのサブクエリ フィルタ、search_condition フィルタ、merge_condition フィルタに、パーティションをプルーニングするターゲット テーブル用のフィルタを含めることができます。ターゲット テーブルをフィルタしない場合、変更 DML ステートメントは全テーブル スキャンを実行します。
次の例では、MERGE 条件でフィルタを指定して、MERGE ステートメントのスキャン対象を、ターゲット テーブルとソーステーブルの両方で '2018-01-01' パーティションの行のみに限定しています。
古いデータや特定の日付の範囲内のデータを UPDATE や DELETE で頻繁に変更する場合は、テーブルのパーティショニングを検討してください。各パーティションのデータ量が小さく、各更新の際にテーブル内の大部分のパーティションを変更している場合は、テーブルのパーティショニングを行わないようにします。
テーブルをクラスタリングする
BigQuery 特集の以前の投稿で、データのクラスタリングにより、関連するデータをブロック内で並べ替えて配置することで、特定のクエリのパフォーマンスを高められることを説明しました。1 つ以上の列が、値の狭い範囲内に収まる行を更新する頻度が高い場合は、クラスタ化テーブルの使用を検討してください。クラスタリングでは、ブロックレベルのプルーニングを行い、クエリに関連するデータのみをスキャンするため、クエリで処理するバイト数を削減できます。これにより、DML クエリのパフォーマンスを高め、費用を最適化することができます。クラスタリングは単独で使用することも、テーブルのパーティショニングと併用することも可能です。クラスタリングに料金はかかりません。クラスタ化テーブルでの DML クエリの例については、こちらをご覧ください。
データを編集する際は注意する
BigQuery 特集の以前の投稿で、テーブルまたはテーブルのパーティションが 90 日間変更されていない場合、長期保存により費用を大幅に抑えられることを説明しました。テーブルまたはパーティションを長期にわたって保存していても、パフォーマンス、耐久性、可用性などの各種機能性が損なわれることはありません。
長期保存を最大限に活用するために、データのストリーミング、コピー、読み込み(DML や DDL のアクションを含む)など、テーブルのデータを編集するアクションを実行する場合は注意してください。変更を行うと、データはアクティブ ストレージに戻り、90 日間のタイマーがリセットされます。これを回避する方法として、新しいデータのバッチを新しいテーブルまたはテーブルのパーティションに読み込むこともできます。
OLTP ユースケースでの Cloud SQL の使用を検討する
ユースケースが OLTP 機能に対応している場合は、Cloud SQL 連携クエリの使用を検討してください。これにより、BigQuery は Cloud SQL に存在するデータをクエリできるようになります。BigQuery からの Cloud SQL のクエリについては、こちらの動画をご覧ください。
次のステップ
この記事では、DML ステートメントを使用して BigQuery に保存されているデータを追加、変更、削除する方法、BigQuery が DML ステートメントを実行する仕組み、BigQuery で DML ステートメントを使用する際のベスト プラクティスと注意事項について説明しました。
DML ステートメントに関する BigQuery ドキュメントをご覧ください。
BigQuery の DML が無制限で利用可能という情報については、こちらのブログ投稿をご覧ください。
次回の投稿では、BigQuery におけるスクリプティング、ストアド プロシージャ、ユーザー定義関数の使い方について説明します。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、Twitter または LinkedIn でアクセスしてください。
この投稿に協力してくれた Pavan Edara と Alicia Williams に感謝します。
-Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam




