Guida alla soluzione: backup e RE di Google Cloud per Oracle su Bare Metal Solution
Panoramica
Per garantire la resilienza dei database Oracle all'interno di un ambiente Bare Metal Solution, devi avere una strategia chiara per i backup dei database e il ripristino di emergenza. Per aiutarti a soddisfare questo requisito, il team di Solution Architect di Google Cloud ha eseguito test approfonditi del Google Cloud servizio di backup e DR e ha compilato i risultati in questa guida. Di conseguenza, ti mostreremo i modi migliori per eseguire il deployment, configurare e ottimizzare le opzioni di backup e ripristino per i database Oracle all'interno di un ambiente Bare Metal Solution utilizzando il servizio di Backup e DR. Condivideremo anche alcuni dati sul rendimento dei risultati dei nostri test, in modo che tu possa avere un benchmark da confrontare con il tuo ambiente. Questa guida è utile se sei un amministratore dei backup, un amministratore diGoogle Cloud o un DBA Oracle.
Sfondo
A giugno 2022, il team di Solution Architect ha iniziato una dimostrazione di proof-of-concept (PoC) di Google Cloud Backup e DR per un cliente aziendale. Per soddisfare i loro criteri di successo, dovevamo supportare il recupero del loro database Oracle da 50 TB e ripristinarlo entro 24 ore.
Questo obiettivo ha posto una serie di sfide, ma la maggior parte delle persone coinvolte nel progetto PoC riteneva che avremmo potuto raggiungere questo risultato e che avremmo dovuto procedere con il progetto PoC. Abbiamo ritenuto che il rischio fosse relativamente basso perché avevamo dati di test precedenti del team di ingegneria di backup e RE che dimostravano che era possibile ottenere questi risultati. Abbiamo anche condiviso i risultati del test con il cliente per rassicurarlo in merito alla prosecuzione della PoC.
Durante la PoC, abbiamo imparato a configurare correttamente più elementi insieme (Oracle, Google Cloud Backup e RE, spazio di archiviazione e link di estensione regionali) in un ambiente Bare Metal Solution. Seguendo le best practice che abbiamo appreso, puoi ottenere risultati positivi.
"I risultati possono variare" è un ottimo modo per pensare ai risultati complessivi di questo documento. Il nostro obiettivo è condividere alcune conoscenze su ciò che abbiamo appreso, su cosa dovresti concentrarti, sulle cose da evitare e sulle aree da esaminare se non ottieni il rendimento o i risultati che desideri. Ci auguriamo che questa guida ti aiuti a prendere confidenza con le soluzioni proposte e che i tuoi requisiti possano essere soddisfatti.
Architettura
La Figura 1 mostra una visualizzazione semplificata dell'infrastruttura che devi creare quando esegui il deployment di Backup andRER per proteggere i database Oracle in esecuzione in un ambiente Bare Metal Solution.
Figura 1: componenti per l'utilizzo di Backup and RE con i database Oracle in un ambiente Bare Metal Solution

Come puoi vedere nel diagramma, questa soluzione richiede i seguenti componenti:
- Estensione regionale di Bare Metal Solution: ti consente di eseguire database Oracle in un data center di terze parti adiacente a un data center Google Cloud e di utilizzare le licenze software on-premise esistenti.
- Progetto di servizio RE e DR: consente di ospitare l'appliance di backup/ripristino e di eseguire il backup di Bare Metal Solution e dei workload nei bucket Cloud Storage. Google Cloud
- Progetto di servizio Compute: ti offre una posizione in cui eseguire le VM di Compute Engine.
- Servizio di backup e DR: fornisce la console di gestione di backup e RE che ti consente di gestire i backup e il ripristino di emergenza.
- Progetto host: consente di creare subnet regionali in un VPC condiviso che può connettere l'estensione regionale Bare Metal Solution al servizio Backup and DR, all'appliance di backup/recupero, ai bucket Cloud Storage e alle VM Compute Engine.
Installa Google Cloud Backup e RE
La soluzione Backup e RE richiede almeno i seguenti due componenti principali per funzionare:
- Console di gestione di RE e DR: un endpoint API e UI HTML 5 che ti consente di creare e gestire i backup dall'interno della consoleGoogle Cloud .
- Appliance di backup/ripristino: questo dispositivo funge da worker delle attività per l'esecuzione dei backup e il montaggio e il ripristino delle attività di tipo.
Google Cloud gestisce la console di gestione di Backup e RE. Devi eseguire il deployment della console di gestione in un progetto service producer (lato gestione) ed eseguire il deployment dell'appliance di backup/ripristino in un progetto service consumer (lato cliente).Google Cloud Per ulteriori informazioni su Backup e RE, consulta Configurare e pianificare un deployment di Backup e DR. Per visualizzare la definizione di un producer di servizi e di un consumatore di servizi, consulta il glossario di Google Cloud.
Prima di iniziare
Per installare il servizio di backup e DR Google Cloud , devi completare i seguenti passaggi di configurazione prima di iniziare il deployment:
- Abilita una connessione di accesso privato ai servizi. Devi stabilire questa connessione prima di poter iniziare l'installazione. Anche se hai già configurato una subnet di accesso privato ai servizi, deve avere almeno una subnet
/23. Ad esempio, se hai già configurato una subnet/24per la connessione di accesso privato ai servizi, ti consigliamo di aggiungere una subnet/23. Ancora meglio, puoi aggiungere una subnet/20per assicurarti di poter aggiungere altri servizi in un secondo momento. - Configura Cloud DNS in modo che sia accessibile nella rete VPC in cui implementi l'appliance di backup/recupero. In questo modo, googleapis.com viene risolto correttamente (tramite ricerca privata o pubblica).
- Configura le route predefinite di rete e le regole firewall per consentire il traffico in uscita a
*.googleapis.com(tramite IP pubblici) oprivate.googleapis.com(199.36.153.8/30) sulla porta TCP 443 o un'uscita esplicita per0.0.0.0/0. Anche in questo caso, devi configurare le route e il firewall nella rete VPC in cui installi l'appliance di backup/recupero. Ti consigliamo inoltre di utilizzare l'accesso privato Google come opzione preferita. Per ulteriori informazioni, vedi Configurare l'accesso privato Google. - Abilita le seguenti API nel progetto consumer:
- API Compute Engine
- API Cloud Key Management Service (KMS)
- API Cloud Resource Manager (per il progetto host e il progetto di servizio, se in uso)
- API Identity and Access Management
- API Workflows
- API Cloud Logging
- Se hai attivato dei criteri dell'organizzazione, assicurati di configurare quanto segue:
constraints/cloudkms.allowedProtectionLevelsincludonoSOFTWAREoALL.
- Configura le seguenti regole firewall:
- Traffico in entrata dall'appliance di backup/ripristino nel VPC di Compute Engine all'host Linux (agente) sulla porta TCP-5106.
- Se utilizzi un disco di backup basato su blocchi con iSCSI, l'uscita dall'host Linux (agente) in Bare Metal Solution all'appliance di backup/recupero nella VPC Compute Engine sulla porta TCP-3260.
- Se utilizzi un disco di backup basato su NFS o dNFS, l'uscita dall'host Linux (agente) in Bare Metal Solution all'appliance di backup/recupero nel VPC Compute Engine sulle seguenti porte:
- TCP/UDP-111 (rpcbind)
- TCP/UDP-756 (stato)
- TCP/UDP-2049 (nfs)
- TCP/UDP-4001 (mountd)
- TCP/UDP-4045 (nlockmgr)
- Configura Google Cloud DNS per risolvere i nomi host e i domini di Bare Metal Solution, in modo che la risoluzione dei nomi sia coerente tra i server, le VM e le risorse basate su Compute Engine, come il servizio di backup e DR.
Installa la console di gestione di Backup e RE
- Abilita l'API del servizio di Backup e DR, se non è già abilitata.
Nella console Google Cloud , utilizza il menu di navigazione per andare alla sezione Operazioni e seleziona Backup e DR:
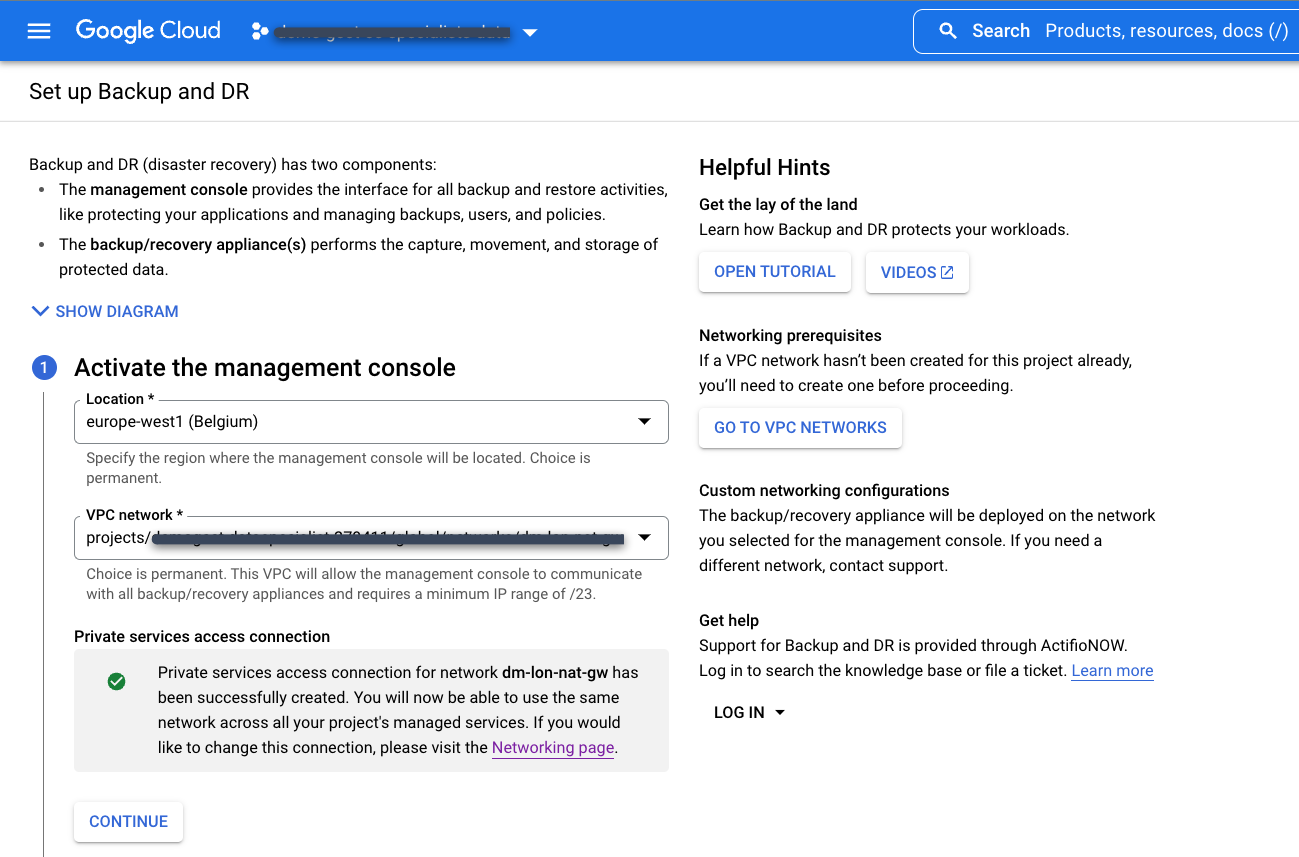
Seleziona la connessione di accesso privato ai servizi esistente che hai creato in precedenza.
Scegli la posizione per la console di gestione di Backup e RE. Questa è la regione in cui esegui il deployment dell'interfaccia utente della console di gestione Backup e RE in un progetto produttore di servizi. Google Cloud possiede e gestisce le risorse della console di gestione.
Scegli la rete VPC nel progetto consumer di servizi a cui vuoi connetterti al servizio Backup e DR. In genere si tratta di un progetto host o VPC condiviso.
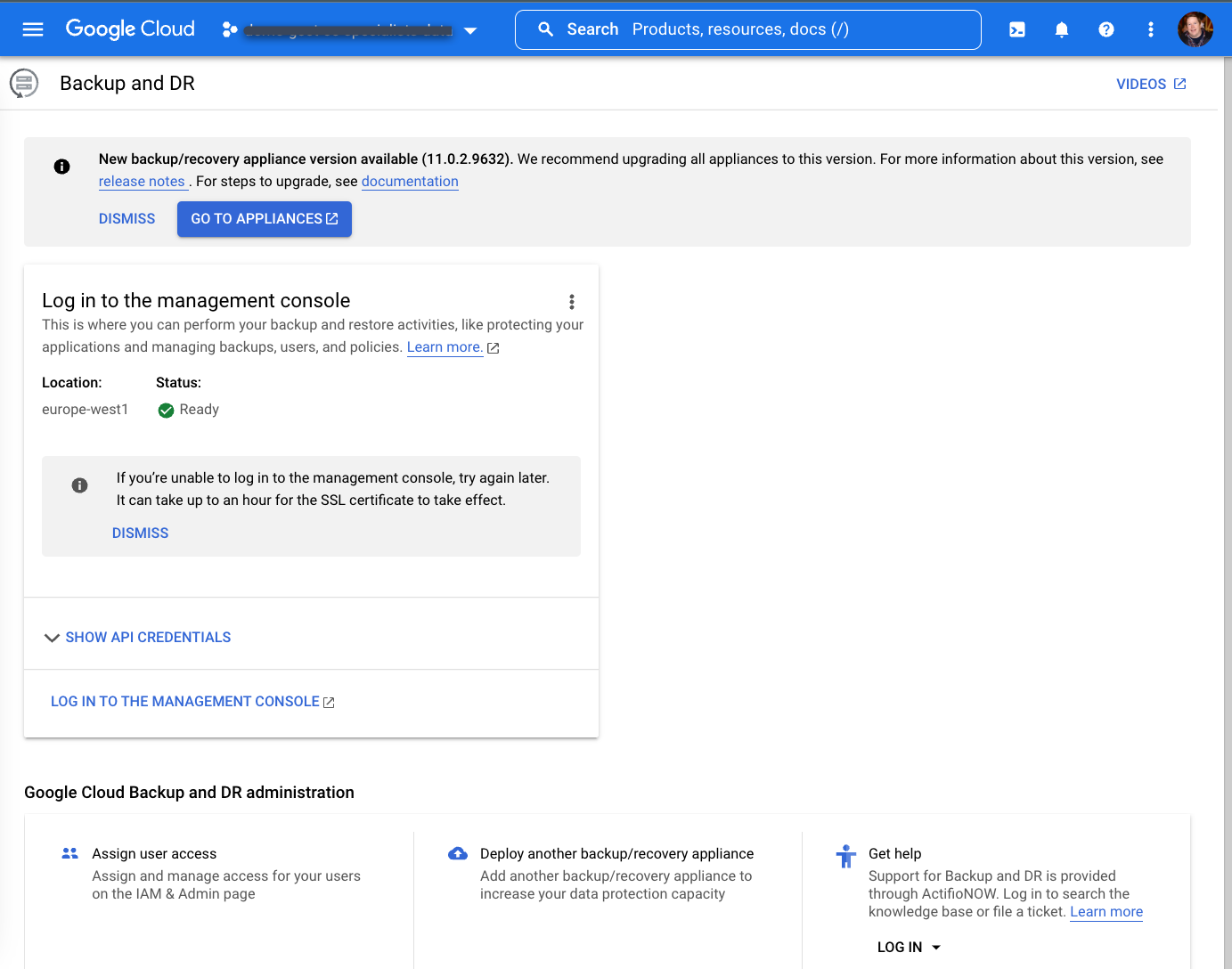
Dopo aver atteso fino a un'ora, dovresti visualizzare la seguente schermata al termine del deployment.
Installa l'appliance di backup/ripristino
Nella pagina RE e DR, fai clic su Accedi alla console di gestione:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Nella pagina principale della console di gestione di Backup and RE, vai alla pagina Appliance:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Inserisci il nome dell'appliance di backup/ripristino. Tieni presente che Google Cloud aggiunge automaticamente numeri casuali aggiuntivi alla fine del nome una volta iniziato il deployment.
Scegli il progetto consumer in cui vuoi installare l'appliance di backup/recupero.
Scegli la regione, la zona e la subnet che preferisci.
Seleziona un tipo di spazio di archiviazione. Consigliamo di scegliere Disco permanente standard per i PoC e Disco permanente SSD per un ambiente di produzione.
Fai clic sul pulsante Inizia installazione. Prevedi che la procedura richieda un'ora per eseguire il deployment sia della console di gestione di Backup eRER sia della prima appliance di backup/ripristino.
Puoi aggiungere altri dispositivi di backup/recupero in altre regioni o zone dopo il completamento della procedura di installazione iniziale.
Configura Google Cloud Backup e RE
In questa sezione imparerai i passaggi necessari per configurare il servizio di backup e DR e proteggere i tuoi workload.
Configura un service account
A partire dalla versione 11.0.2 (rilascio di dicembre 2022 di Backup and RE), puoi utilizzare un singolo account di servizio per eseguire l'appliance di backup/recupero per accedere ai bucket Cloud Storage e proteggere le macchine virtuali (VM) Compute Engine (non trattate in questo documento).
Ruoli del service account
Google Cloud Backup e RE utilizza Google Cloud Identity and Access Management (IAM) per l'autorizzazione e l'autenticazione di utenti e account di servizio. Puoi utilizzare i ruoli predefiniti per attivare una serie di funzionalità di backup. Le due più importanti sono le seguenti:
- Backup and DR Cloud Storage Operator: assegna questo ruolo al account di servizio o ai service account utilizzati da un dispositivo di backup/recupero che si connette ai bucket Cloud Storage. Il ruolo consente la creazione di bucket Cloud Storage per i backup degli snapshot di Compute Engine e l'accesso ai bucket con dati di backup esistenti basati su agenti per il ripristino dei carichi di lavoro.
- Operatore Compute Engine di Backup e DR: assegna questo ruolo al account di servizio o ai service account utilizzati da un'appliance di backup/recupero per creare snapshot di Persistent Disk per le macchine virtuali Compute Engine. Oltre a creare snapshot, questo ruolo consente al account di servizio di ripristinare le VM nello stesso progetto di origine o in progetti alternativi.
Puoi trovare il tuo account di servizio visualizzando la VM Compute Engine che esegue l'appliance di backup/recupero nel tuo progetto di consumo/servizio e esaminando il valore account di servizio elencato nella sezione Gestione di API e identità.
Per fornire le autorizzazioni appropriate alle appliance di backup/recupero, vai alla pagina Identity and Access Management e concedi i seguenti ruoli Identity and Access Management all'account di servizio dell'appliance di backup/recupero.
- Backup and DR Cloud Storage Operator
- Backup and DR Compute Engine Operator (facoltativo)
Configura i pool di archiviazione
I pool di archiviazione memorizzano i dati in posizioni di archiviazione fisica. Devi utilizzare Persistent Disk per i dati più recenti (1-14 giorni) e Cloud Storage per la conservazione a lungo termine (giorni, settimane, mesi e anni).
Cloud Storage
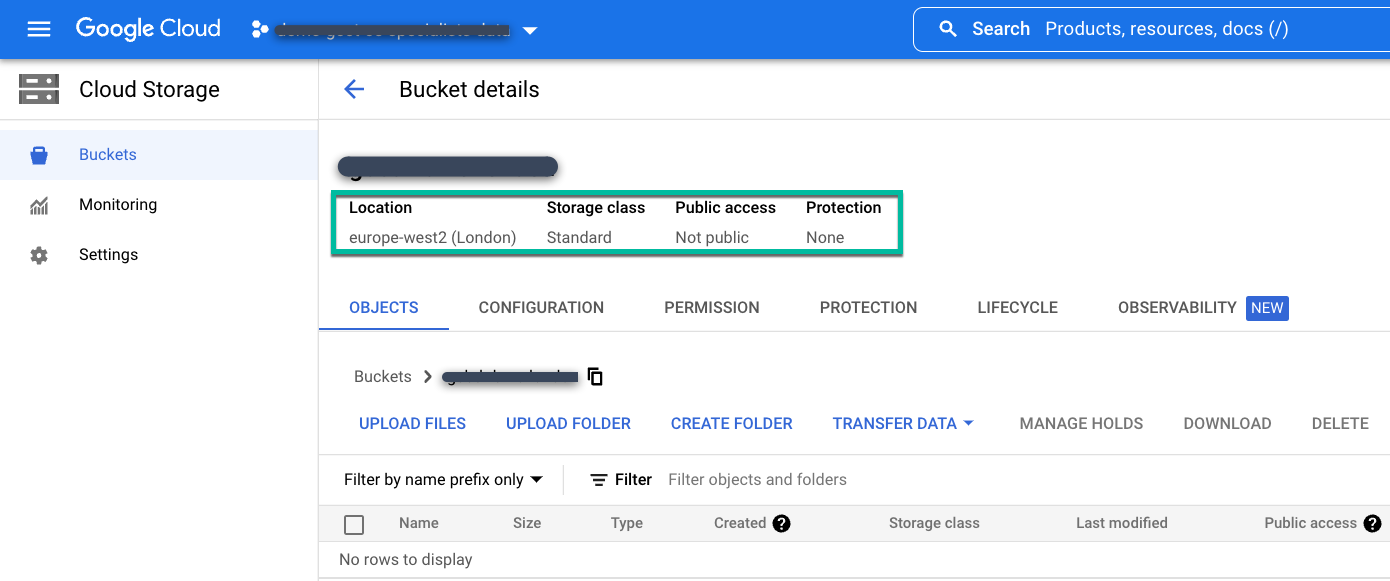
Crea un bucket standard regionale o multiregionale nella località in cui devi archiviare i dati di backup.
Segui queste istruzioni per creare un bucket Cloud Storage:
- Nella pagina Bucket Cloud Storage, assegna un nome al bucket.
- Seleziona la posizione di archiviazione.
- Scegli una classe di archiviazione: standard, nearline o coldline.
- Se scegli l'archiviazione nearline o coldline, imposta la modalità Controllo dell'accesso su Granulare. Per l'archiviazione standard, accetta la modalità di controllo dell'accesso predefinita Uniforme.
Infine, non configurare altre opzioni di protezione dei dati e fai clic su Crea.
Poi aggiungi questo bucket all'appliance di backup/ripristino. Vai alla console di gestione di Backup e RE.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Seleziona la voce di menu Gestisci > Pool di archiviazione.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
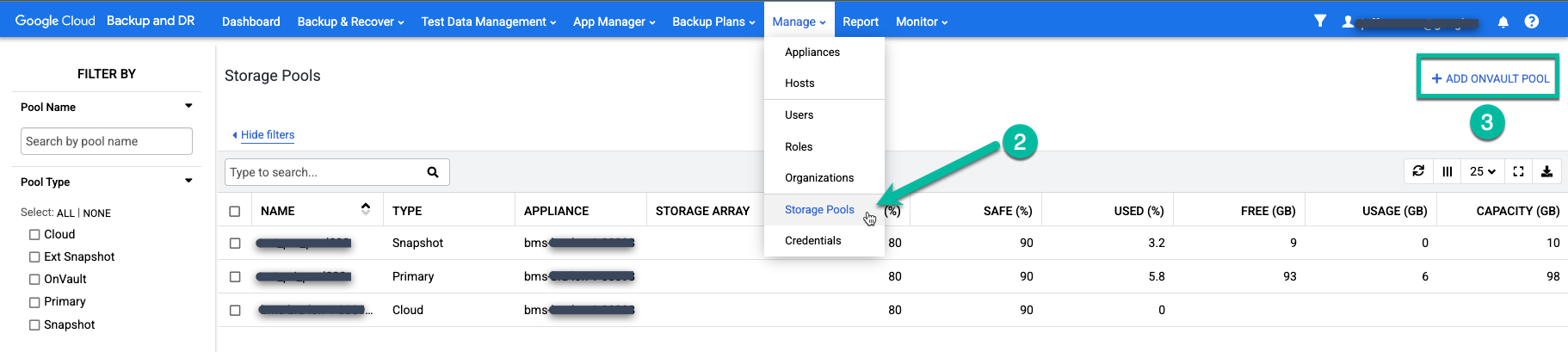
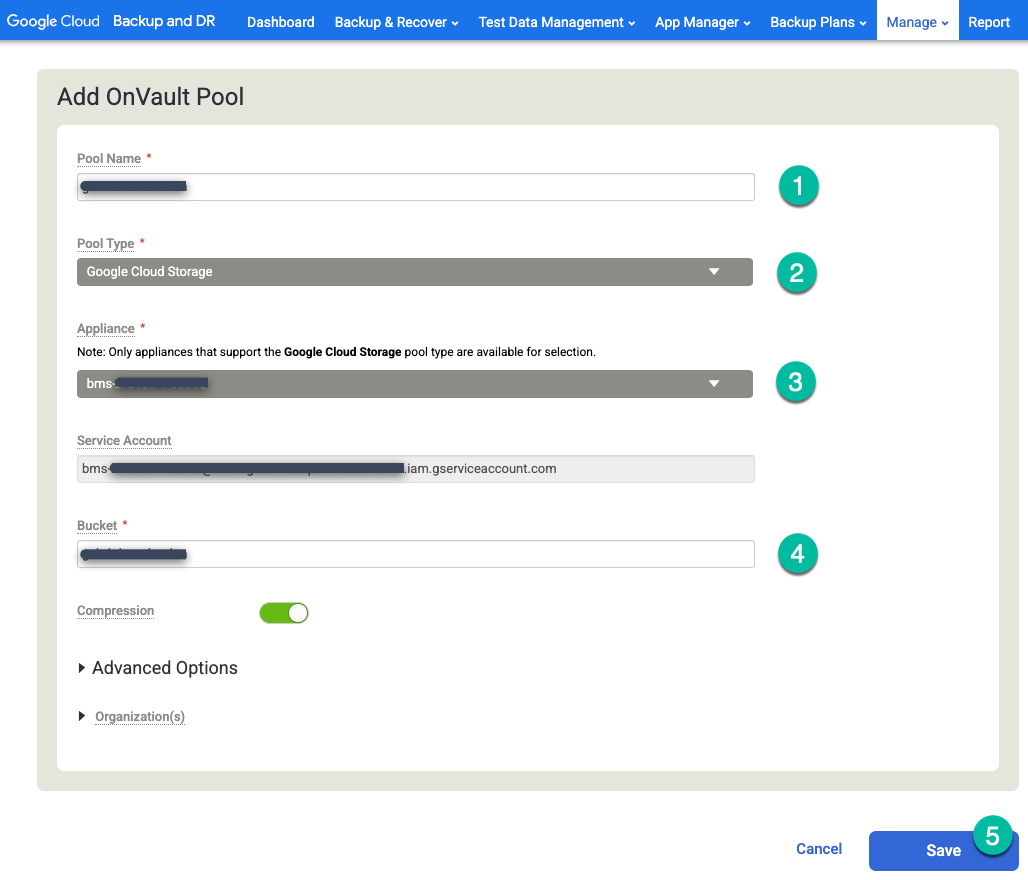
Fai clic sull'opzione all'estrema destra +Aggiungi pool OnVault.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- Digita un nome per il Pool name (Nome pool).
- Scegli Cloud Storage per il Tipo di pool.
- Seleziona l'appliance da collegare al bucket Cloud Storage.
- Inserisci il nome del bucket Cloud Storage.
Fai clic su Salva.
Pool di snapshot di Persistent Disk
Se hai eseguito il deployment dell'appliance di backup/recupero con le opzioni standard o SSD, il pool di snapshot di Persistent Disk sarà di 4 TB per impostazione predefinita. Se i database o i file system di origine richiedono un pool di dimensioni maggiori, puoi modificare le impostazioni dell'appliance di backup/recupero di cui è stato eseguito il deployment, aggiungere un nuovo Persistent Disk e creare un nuovo pool personalizzato o configurare un altro pool predefinito.
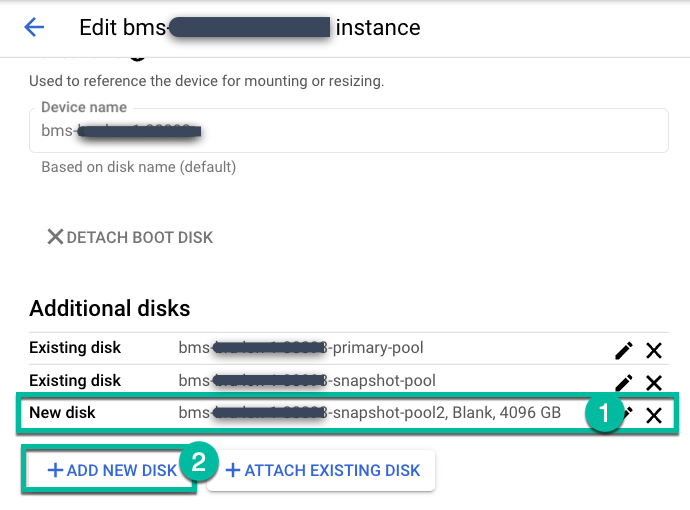
Vai alla pagina Gestisci > Appliance.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Modifica l'istanza backup-server e fai clic su +Aggiungi nuovo disco.
- Assegna un nome al disco.
- Seleziona un tipo di disco Vuoto.
- Scegli Standard, Bilanciato o SSD in base alle tue esigenze.
- Inserisci le dimensioni del disco che ti servono.
Fai clic su Salva.
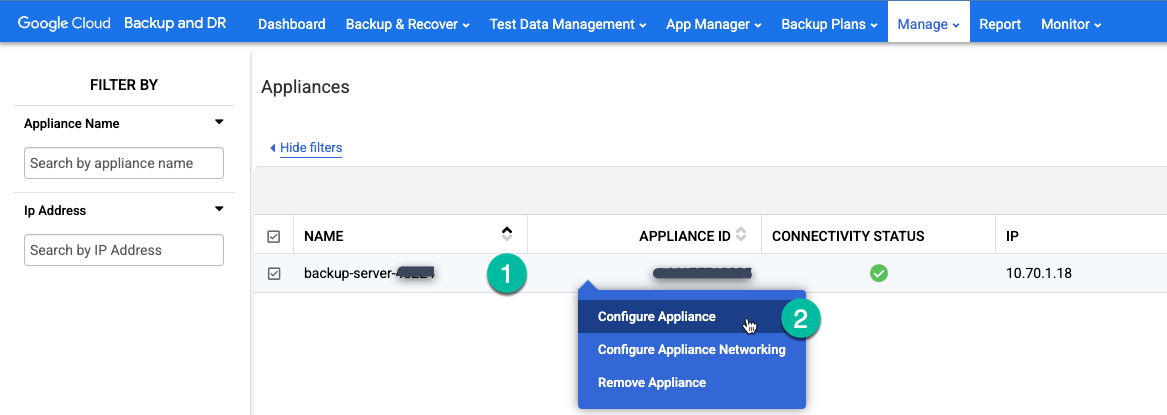
Vai alla pagina Gestisci > Appliance nella console di gestione di backup e RE.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Fai clic con il tasto destro del mouse sul nome dell'appliance e seleziona Configura appliance dal menu.
Puoi aggiungere il disco al pool di snapshot esistente (espansione) oppure creare un nuovo pool (tuttavia, non combinare tipi di Persistent Disk nello stesso pool). Se lo espandi, fai clic sull'icona in alto a destra del pool che vuoi espandere.
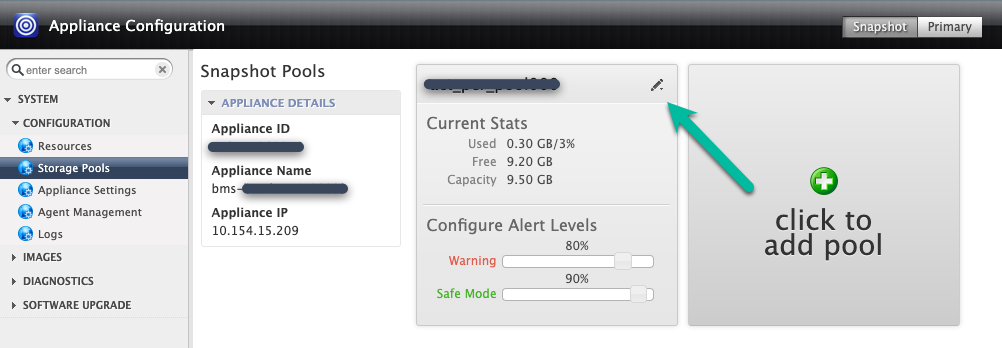
In questo esempio, crei un nuovo pool con l'opzione Fai clic per aggiungere il pool. Dopo aver fatto clic su questo pulsante, attendi 20 secondi prima che si apra la pagina successiva.
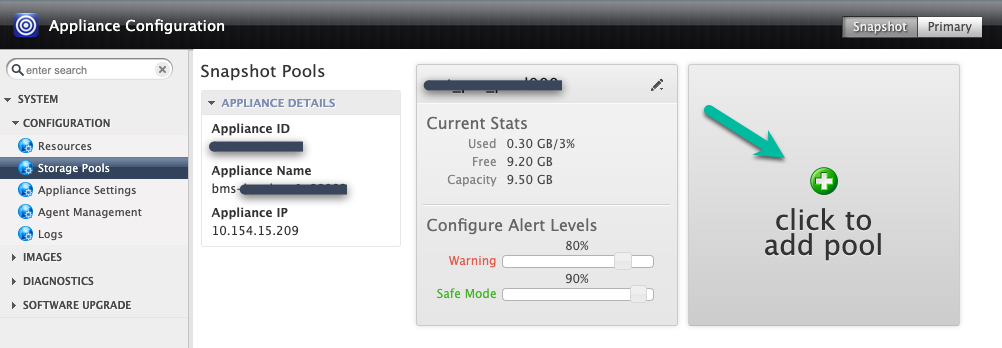
In questo passaggio, configura il nuovo pool.
- Assegna un nome al pool e fai clic sull'icona verde + per aggiungere il disco al pool.
- Fai clic su Invia.
- Conferma di voler continuare digitando PROCEDI in maiuscolo quando richiesto.
Fai clic su Conferma.
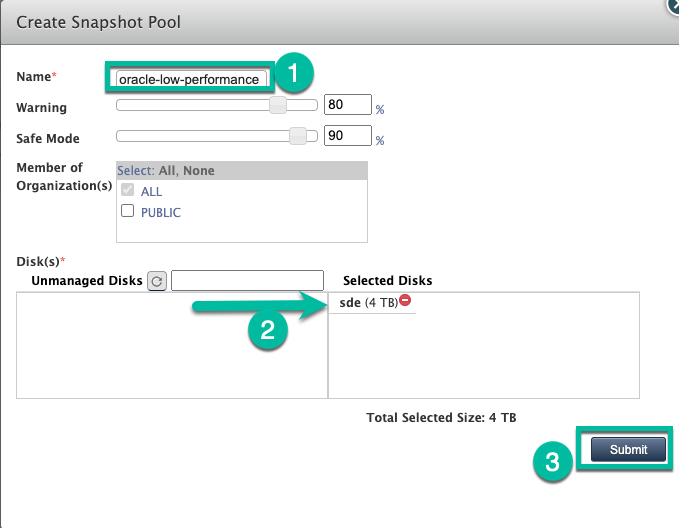
Il pool verrà ora espanso o creato con il Persistent Disk.
Configura i piani di backup
I piani di backup consentono di configurare due elementi chiave per il backup di qualsiasi database, VM o file system. I piani di backup incorporano profili e modelli.
- I profili ti consentono di definire quando eseguire il backup di un elemento e per quanto tempo conservare i dati di backup.
- I modelli forniscono un elemento di configurazione che ti consente di decidere quale appliance di backup/recupero e quale pool di archiviazione (Persistent Disk, Cloud Storage e così via) deve essere utilizzato per l'attività di backup.
Crea un profilo
Nella console di gestione di Backup e RE, vai alla pagina Piani di backup > Profili.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
Verranno già creati due profili. Puoi utilizzare un profilo per gli snapshot delle VM di Compute Engine e modificare l'altro profilo per utilizzarlo per i backup di Bare Metal Solution. Puoi avere più profili, il che è utile se esegui il backup di molti database che richiedono diversi livelli di disco per il backup. Ad esempio, puoi creare un pool per SSD (prestazioni più elevate) e un pool per dischi permanenti standard (prestazioni standard). Per ogni profilo puoi scegliere un pool di snapshot diverso.
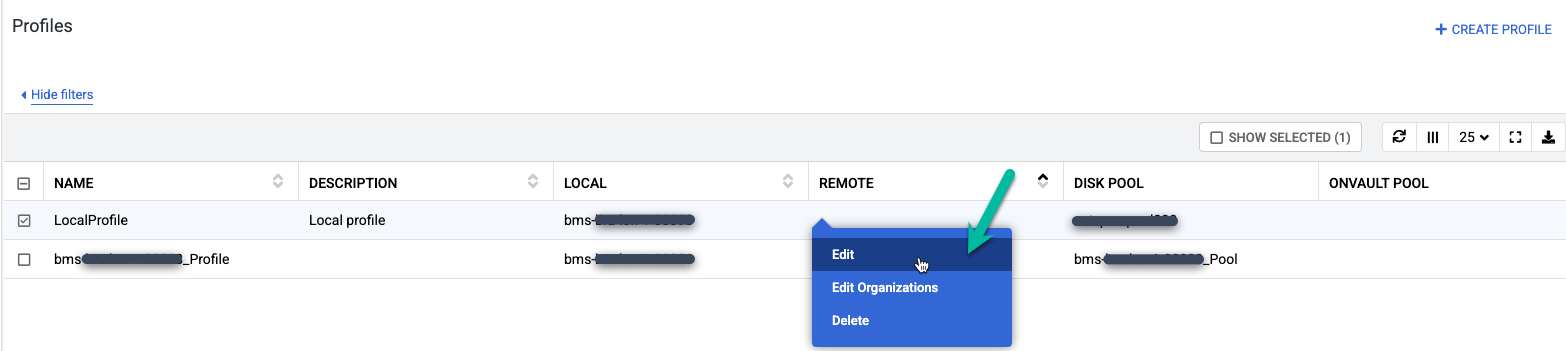
Fai clic con il tasto destro del mouse sul profilo predefinito denominato LocalProfile e seleziona Modifica.
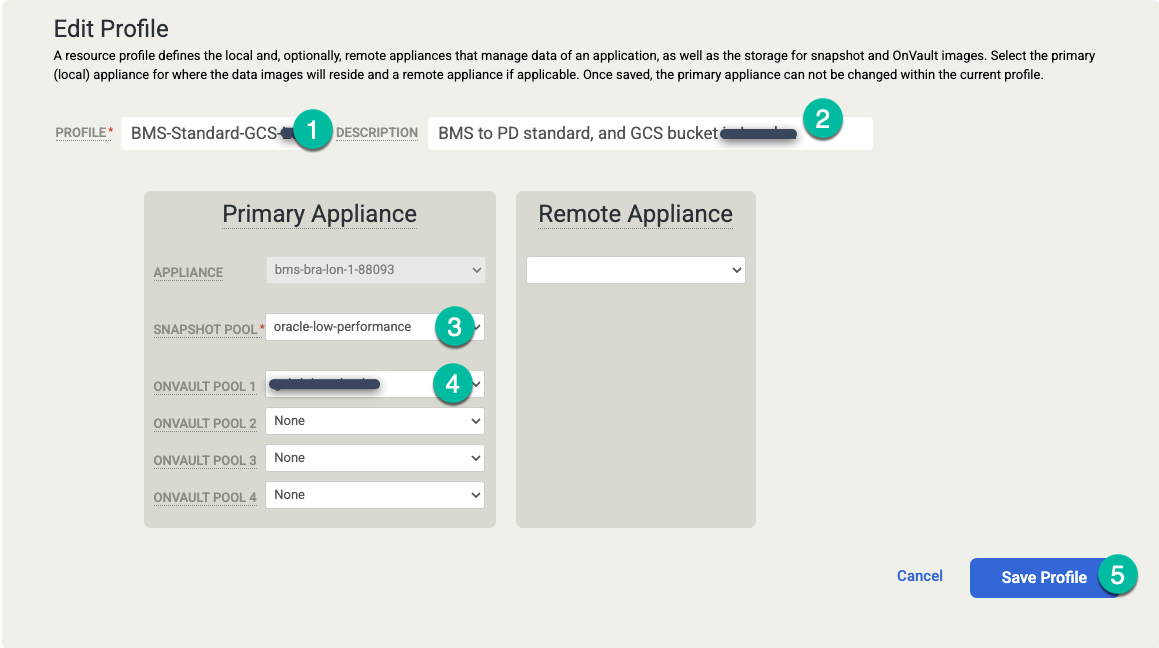
Apporta le seguenti modifiche:
- Aggiorna le impostazioni dei Profili con un nome e una descrizione più significativi. Puoi specificare il livello del disco da utilizzare, la posizione dei bucket Cloud Storage o altre informazioni che spiegano lo scopo di questo profilo.
- Modifica il pool di snapshot con il pool espanso o nuovo che hai creato in precedenza.
- Seleziona un pool OnVault (bucket Cloud Storage) per questo profilo.
Fai clic su Salva profilo.
Crea un modello
Nella console di gestione di Backup e RE, vai al menu Piani di backup > Modelli.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
Fai clic su +Crea modello.
- Assegna un nome al modello.
- Seleziona Sì per Consenti sostituzioni nelle impostazioni dei criteri.
- Aggiungi una descrizione di questo modello.
Fai clic su Salva modello.
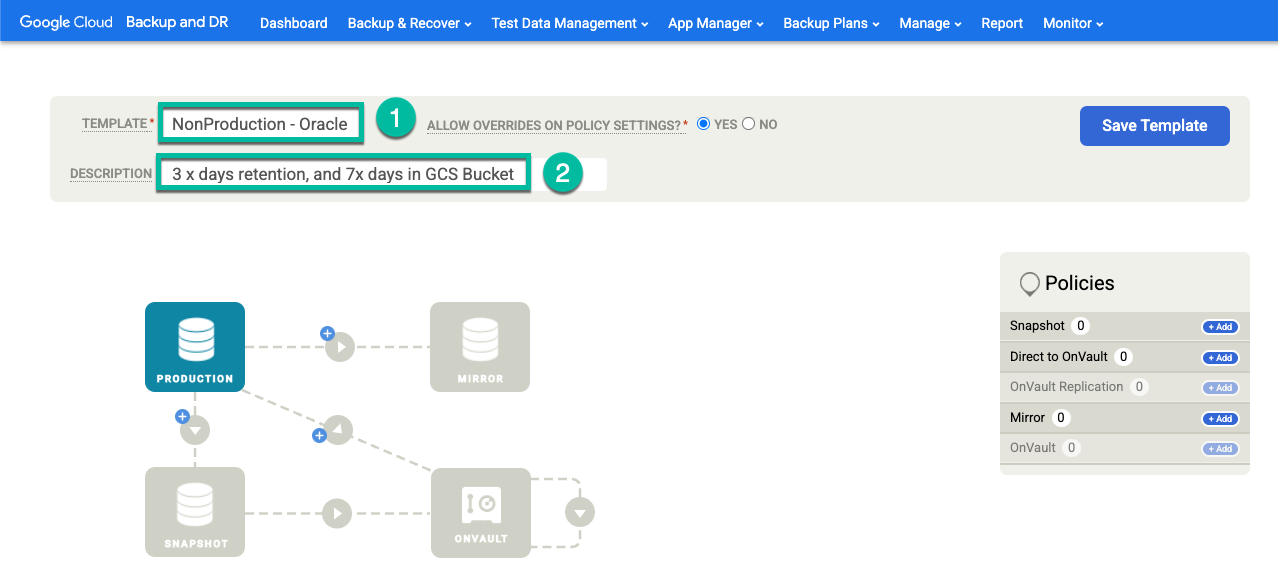
Nel modello, configura quanto segue:
- Nella sezione Norme a destra, fai clic su +Aggiungi.
- Fornisci un nome per la norma.
- Seleziona la casella di controllo per i giorni in cui vuoi che venga applicata la norma oppure lascia il valore predefinito Tutti i giorni.
- Modifica la finestra per i job che vuoi eseguire in quel periodo di tempo.
- Seleziona un periodo di conservazione.
Fai clic su Impostazioni avanzate dei criteri.
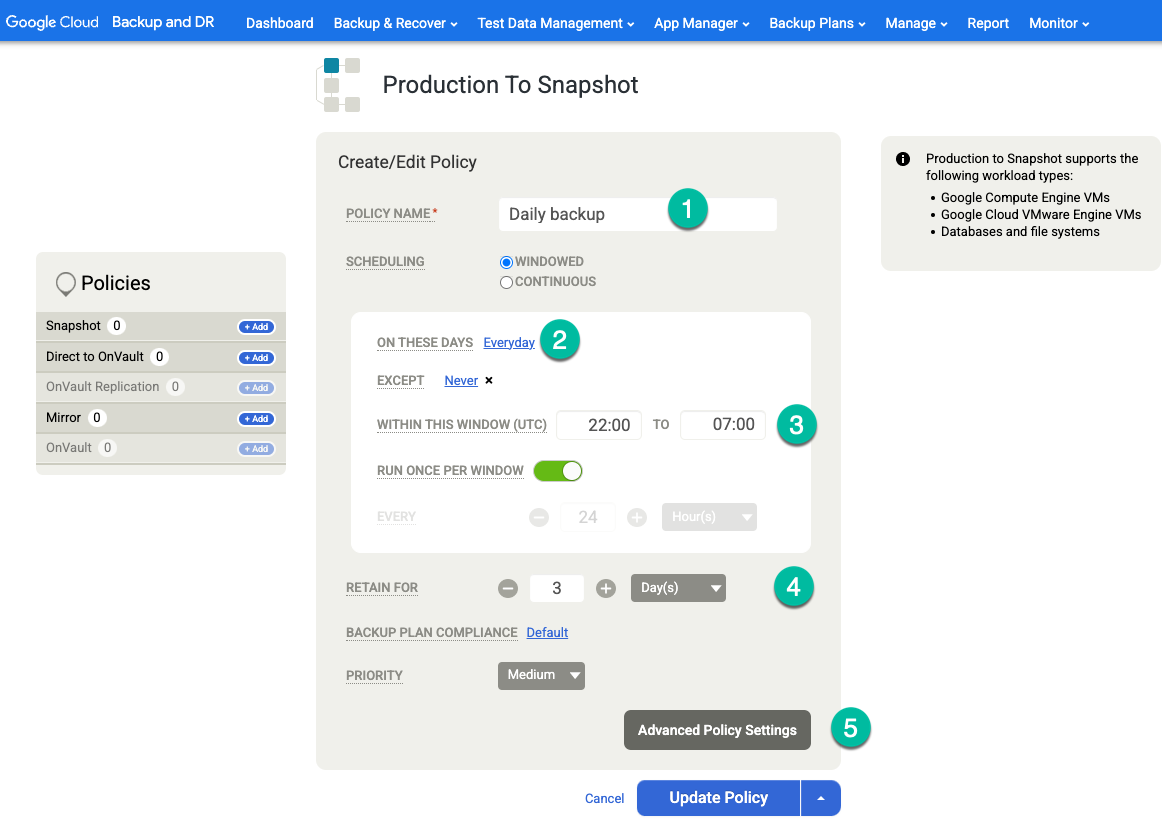
Se vuoi eseguire backup dei log di archivio con una frequenza regolare (ad esempio ogni 15 minuti) e replicare i log di archivio in Cloud Storage, devi attivare le seguenti impostazioni dei criteri:
- Imposta Tronca/Elimina log dopo il backup su Tronca se è quello che vuoi.
- Se vuoi, imposta Enable Database Log Backup (Attiva backup log database) su Yes (Sì).
- Imposta RPO (Minutes) sull'intervallo di backup dei log di archivio che preferisci.
- Imposta Periodo di conservazione del backup dei log (in giorni) sul periodo di conservazione che preferisci.
- Imposta Replicate Logs (Uses Streamsnap Technology) su No.
- Imposta Invia log al pool OnVault su Sì se vuoi inviare i log al tuo bucket Cloud Storage. In caso contrario, seleziona No.
Fai clic su Salva modifiche.
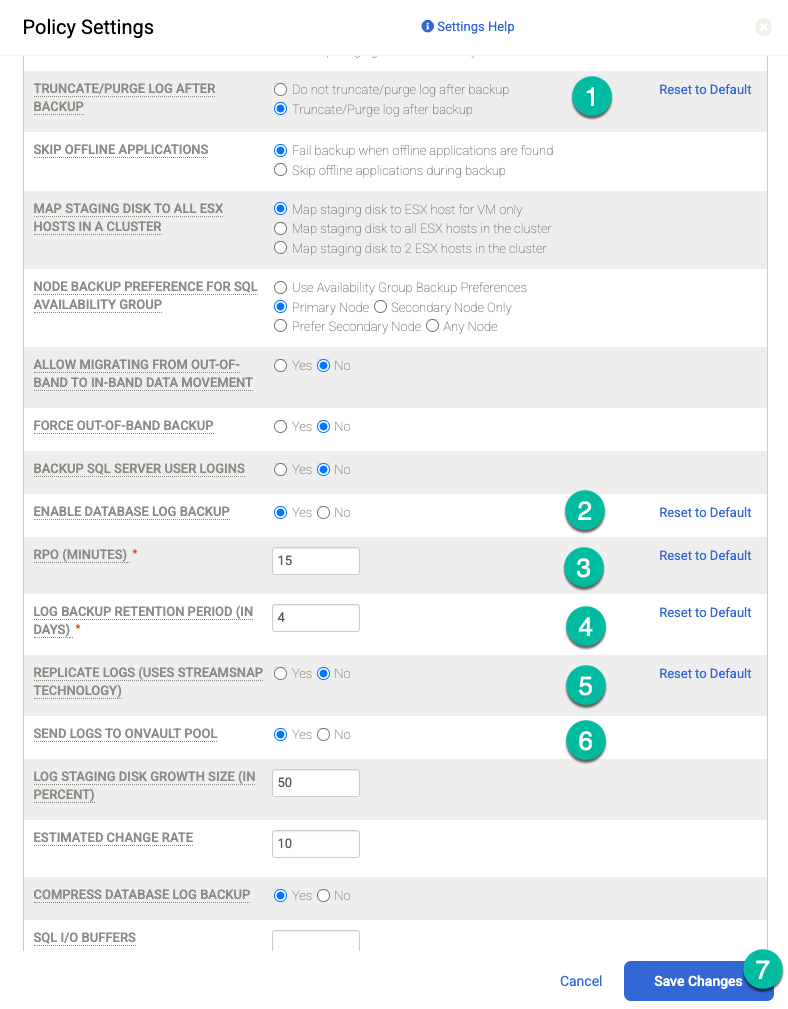
Fai clic su Aggiorna norma per salvare le modifiche.
Per OnVault a destra, esegui le seguenti azioni:
- Fai clic su +Aggiungi.
- Aggiungi il nome del criterio.
- Imposta il Periodo di conservazione in giorni, settimane, mesi o anni.
Fai clic su Aggiorna norma.
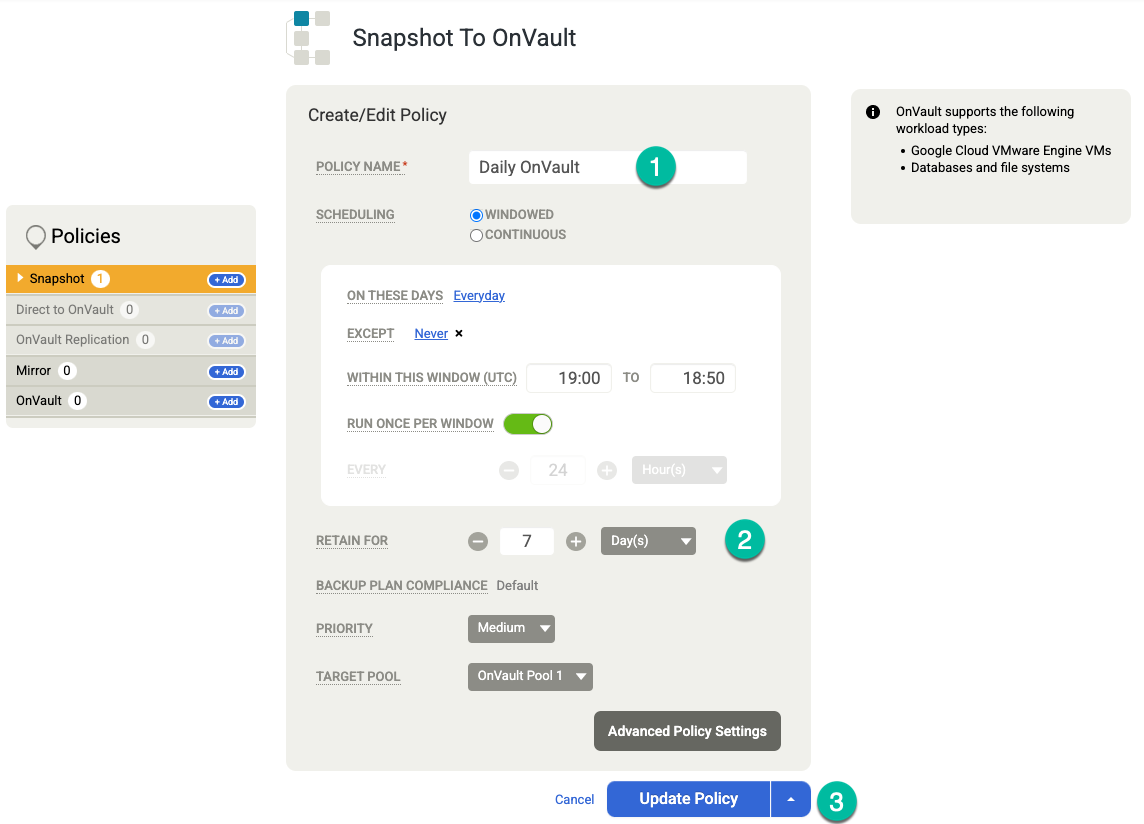
(Facoltativo) Se devi aggiungere altre opzioni di conservazione, crea criteri aggiuntivi per la conservazione settimanale, mensile e annuale. Per aggiungere un'altra norma di conservazione, segui questi passaggi:
- Per OnVault a destra, fai clic su +Aggiungi.
- Aggiungi un nome per la policy.
- Modifica il valore di In questi giorni con il giorno in cui vuoi attivare questo job.
- Imposta la Conservazione in Giorni, Settimane, Mesi o Anni.
Fai clic su Aggiorna norma.
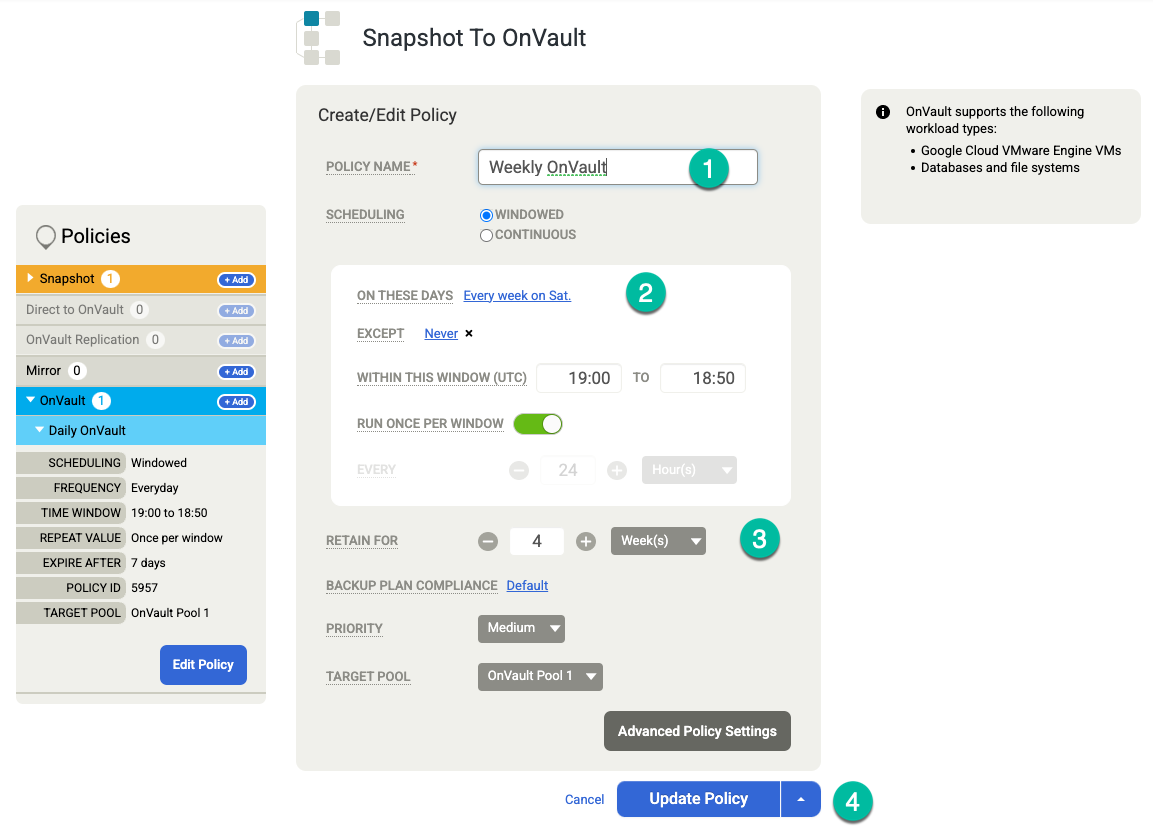
Fai clic su Salva modello. Nell'esempio seguente, vedrai una policy di snapshot che conserva i backup per 3 giorni nel livello Persistent Disk, 7 giorni per i job OnVault e 4 settimane in totale. Il backup settimanale viene eseguito il sabato sera.
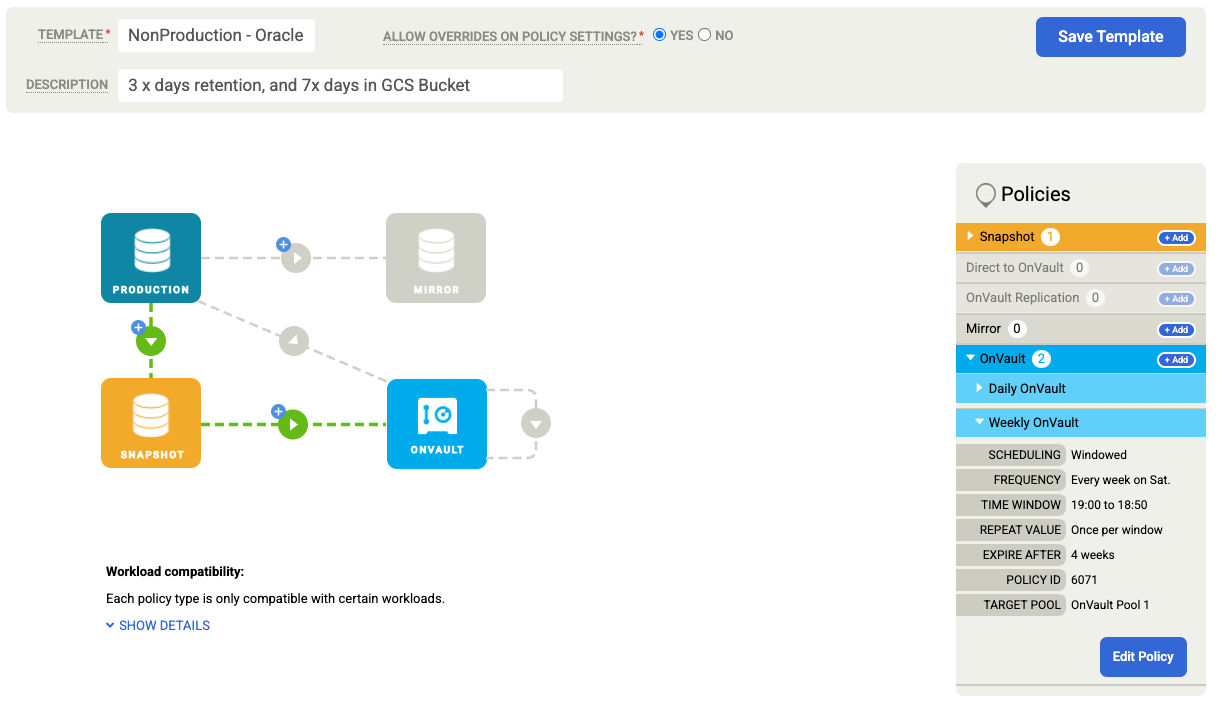
Esegui il backup di un database Oracle
L'architettura di Google Cloud Backup e RE fornisce backup Oracle incrementale permanente coerente con l'applicazione Google Cloude clonazione e ripristino istantanei per database Oracle di più terabyte.
Google Cloud Backup e RE utilizza le seguenti API Oracle:
- API RMAN image copy: il ripristino di una copia immagine di un file di dati è molto più rapido perché la struttura fisica del file di dati esiste già. La direttiva Recovery Manager (RMAN) BACKUP AS COPY crea copie immagine per tutti i file di dati dell'intero database e conserva il formato dei file di dati.
- API ASM e CRS: utilizza l'API Automatic Storage Management (ASM) e Cluster Ready Services (CRS) per gestire il gruppo di dischi di backup ASM.
- API di backup dei log di archivio RMAN: questa API genera i log di archivio, li esegue il backup su un disco di staging e li elimina dalla posizione di archivio di produzione.
Configura gli host Oracle
I passaggi per configurare gli host Oracle includono l'installazione dell'agente, l'aggiunta degli host a Backup and RE, la configurazione degli host e l'individuazione dei database Oracle. Una volta che tutto è a posto, puoi eseguire i backup del database Oracle in Backup e RE.
Installa l'agente di backup
L'installazione dell'agente Backup e RE è relativamente semplice. Devi installare l'agente solo la prima volta che utilizzi l'host, mentre gli upgrade successivi possono essere eseguiti dall'interfaccia utente di Backup e RE nella console Google Cloud . Per eseguire l'installazione di un agente, devi aver eseguito l'accesso come utente root o in una sessione autenticata sudo. Non è necessario riavviare l'host per completare l'installazione.
Scarica l'agente di backup dall'interfaccia utente o dalla pagina Gestisci > Appliance.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Fai clic con il tasto destro del mouse sul nome dell'appliance di backup/ripristino e seleziona Configura appliance. Si apre una nuova finestra del browser.
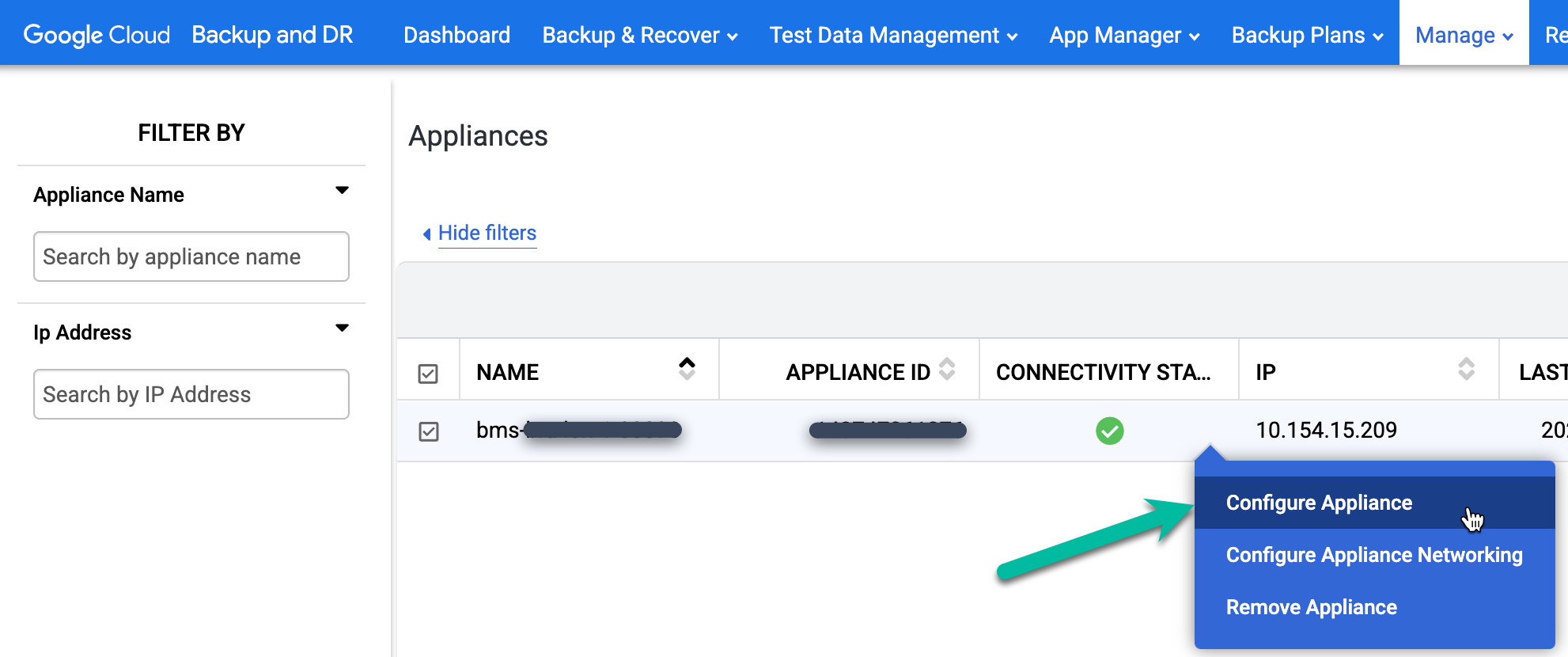
Fai clic sull'icona Linux 64 bit per scaricare l'agente di backup sul computer che ospita la sessione del browser. Utilizza scp (secure copy) per spostare il file dell'agente scaricato sugli host Oracle per l'installazione.
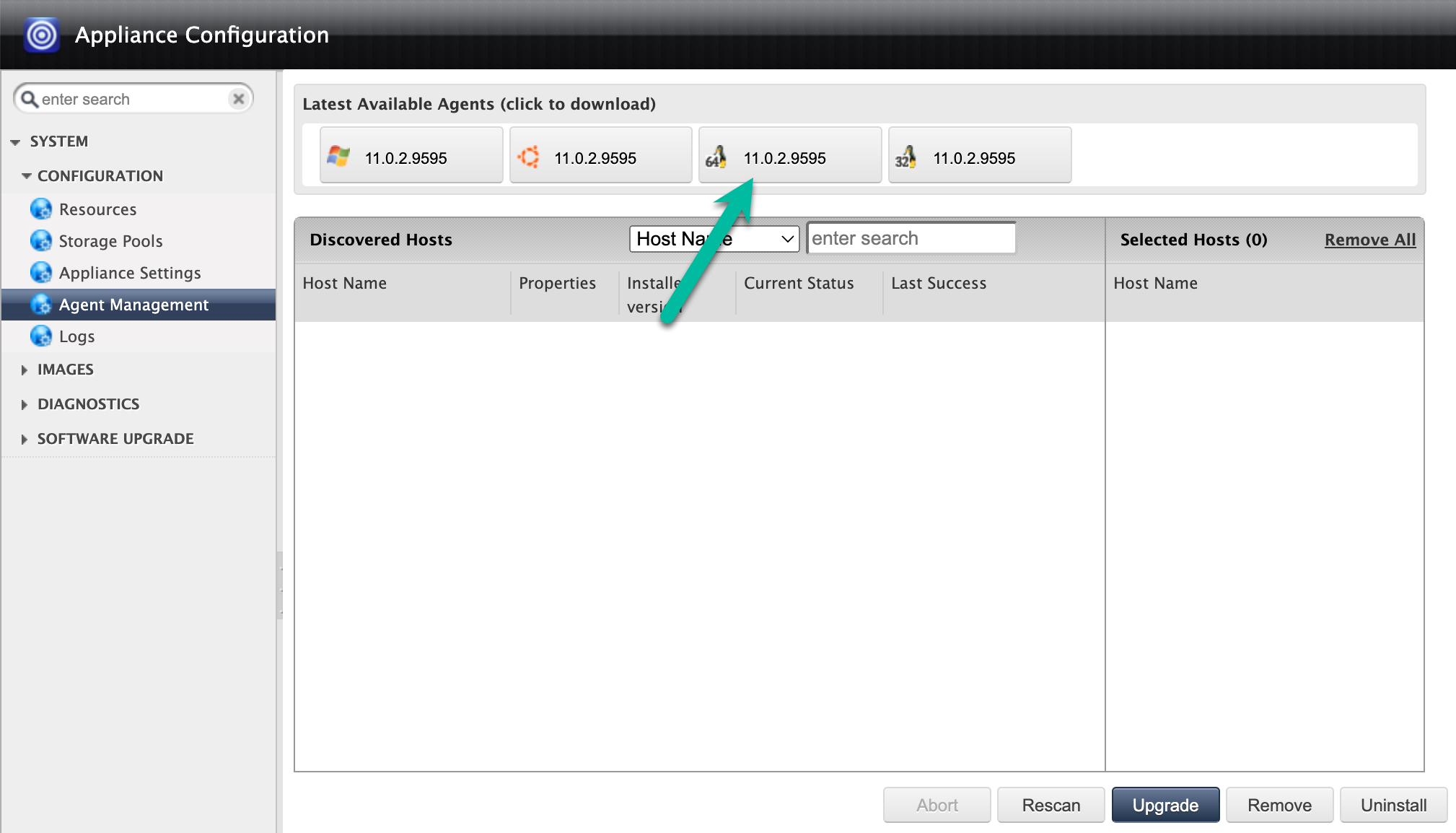
In alternativa, puoi archiviare l'agente di backup in un bucket Cloud Storage, attivare i download e utilizzare i comandi
wgetocurlper scaricare l'agente direttamente sugli host Linux.curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
Utilizza il comando
rpm -ivhper installare l'agente di backup.È molto importante copiare la chiave segreta generata automaticamente. Utilizzando la console di gestione di Backup e RE, devi aggiungere la chiave segreta ai metadati dell'host.
L'output del comando è simile al seguente:
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
Se utilizzi il comando
iptables, apri le porte per il firewall dell'agente di backup (TCP 5106) e i servizi Oracle (TCP 1521):sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
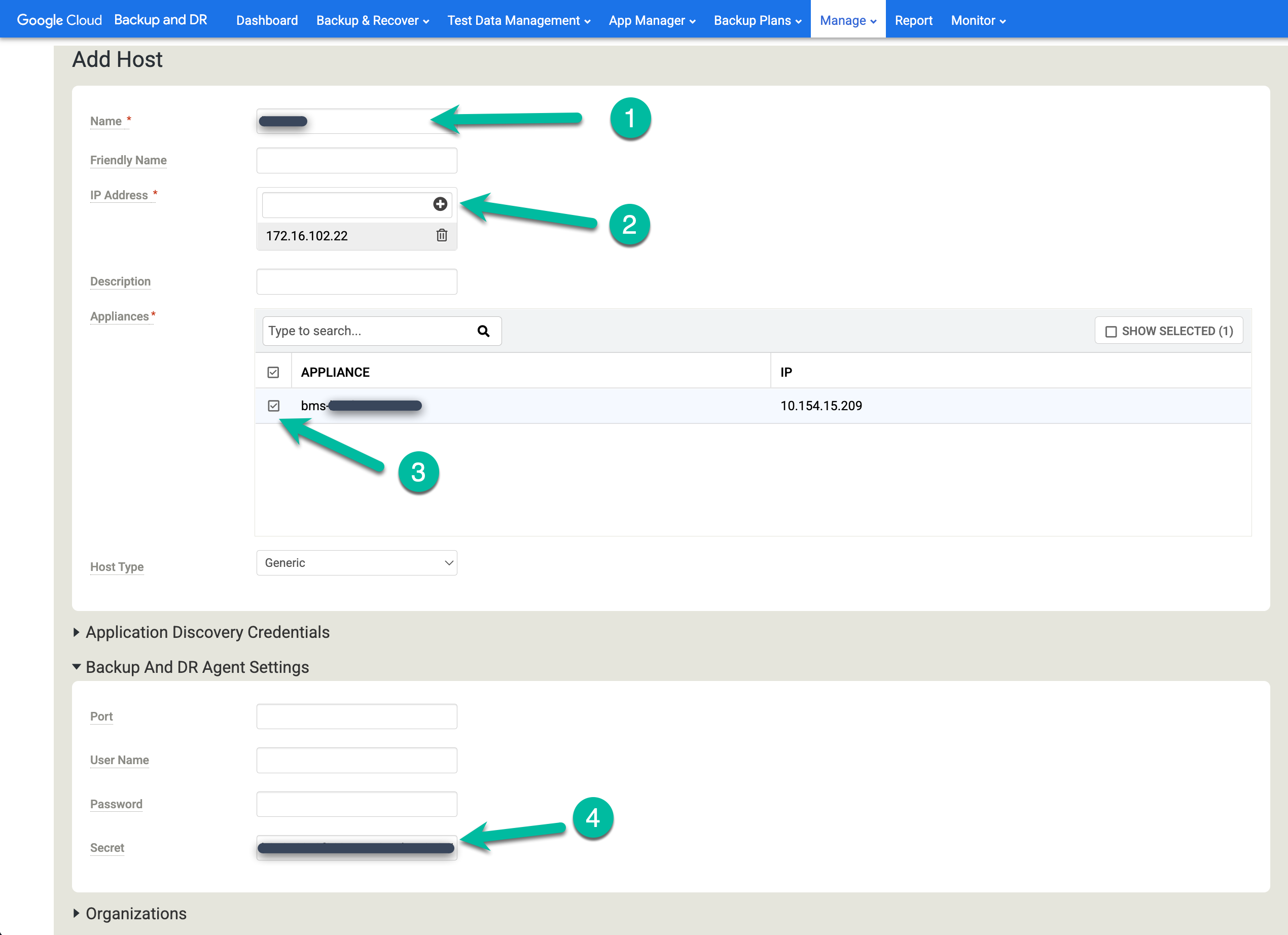
Aggiungere host a Backup e RE
Nella console di gestione di Backup e RE, vai a Gestisci > Host.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
- Fai clic su + Aggiungi host.
- Aggiungi il nome host.
- Aggiungi un indirizzo IP per l'host e fai clic sul pulsante + per confermare la configurazione.
- Fai clic sull'apparecchio o sugli apparecchi a cui vuoi aggiungere l'host.
- Incolla la chiave segreta. Devi eseguire questa attività meno di due ore dopo l'installazione dell'agente di backup e la generazione della chiave segreta.
Fai clic su Aggiungi per salvare l'host.
Se ricevi un messaggio di errore o Riuscito parzialmente, prova le seguenti soluzioni alternative:
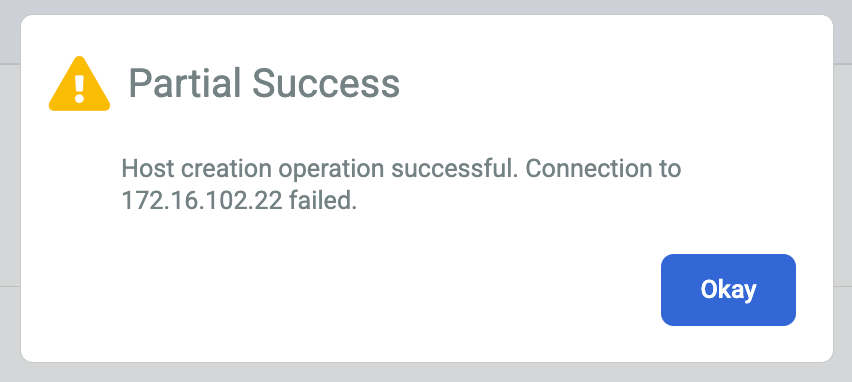
La chiave segreta di crittografia dell'agente di backup potrebbe essere scaduta. Se non hai aggiunto la chiave segreta all'host entro due ore dalla sua creazione. Puoi generare una nuova chiave segreta sull'host Linux utilizzando la seguente sintassi della riga di comando:
/opt/act/bin/udsagent secret --reset --restart
Il firewall che consente la comunicazione tra l'appliance di backup/ripristino e l'agente installato sull'host potrebbe non essere configurato correttamente. Segui i passaggi per aprire le porte del firewall dell'agente di backup e dei servizi Oracle.
La configurazione del Network Time Protocol (ntp) per gli host Linux potrebbe essere configurata in modo errato. Controlla e verifica che le impostazioni NTP siano corrette.
Quando risolvi il problema sottostante, lo Stato del certificato cambia da N/A a Valido.

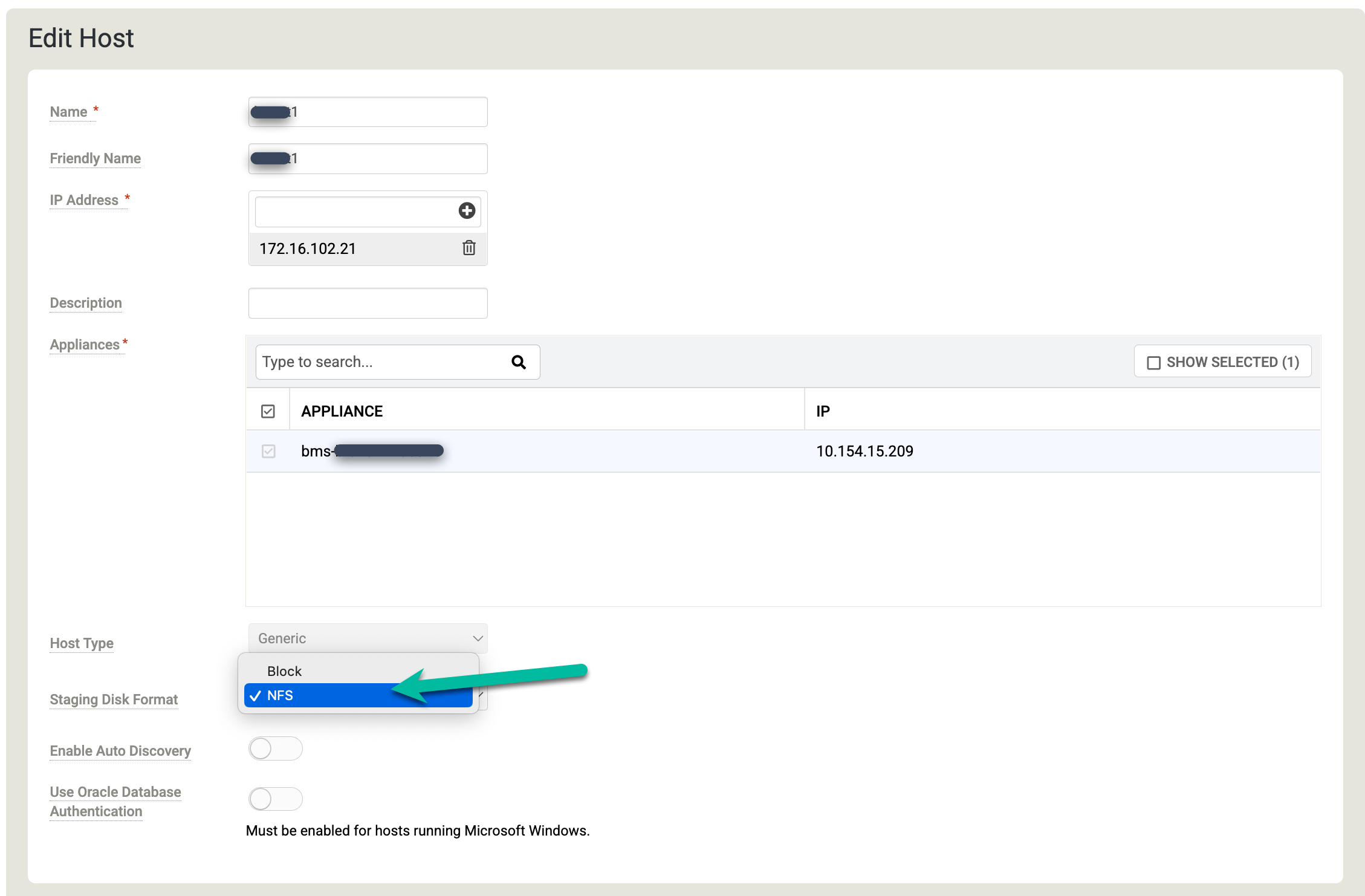
Configura gli host
Nella console di gestione di Backup e RE, vai a Gestisci > Host.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
Fai clic con il tasto destro del mouse sull'host Linux in cui vuoi eseguire il backup dei database Oracle e seleziona Modifica.
Fai clic su Formato disco di staging e scegli NFS.
Scorri verso il basso fino alla sezione Applicazioni rilevate e fai clic su Rileva applicazioni per avviare la procedura di rilevamento da appliance ad agente.
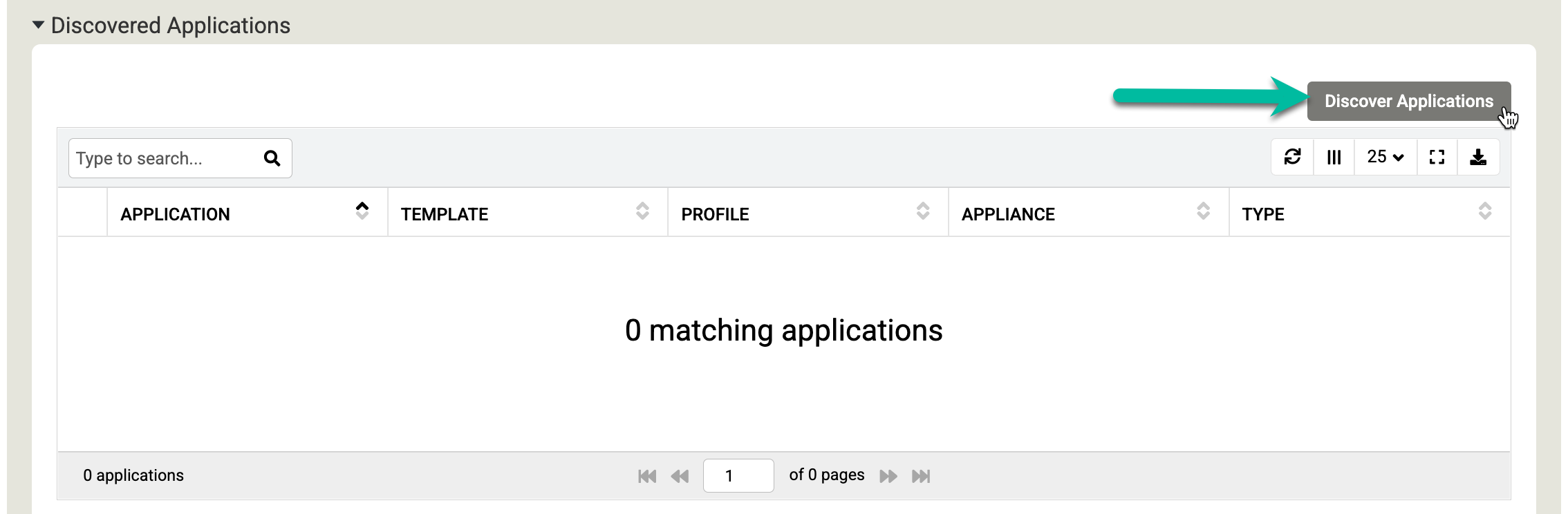
Fai clic su Scopri per iniziare la procedura. La procedura di rilevamento richiede fino a 5 minuti. Al termine, i file system e i database Oracle rilevati vengono visualizzati nella finestra delle applicazioni.
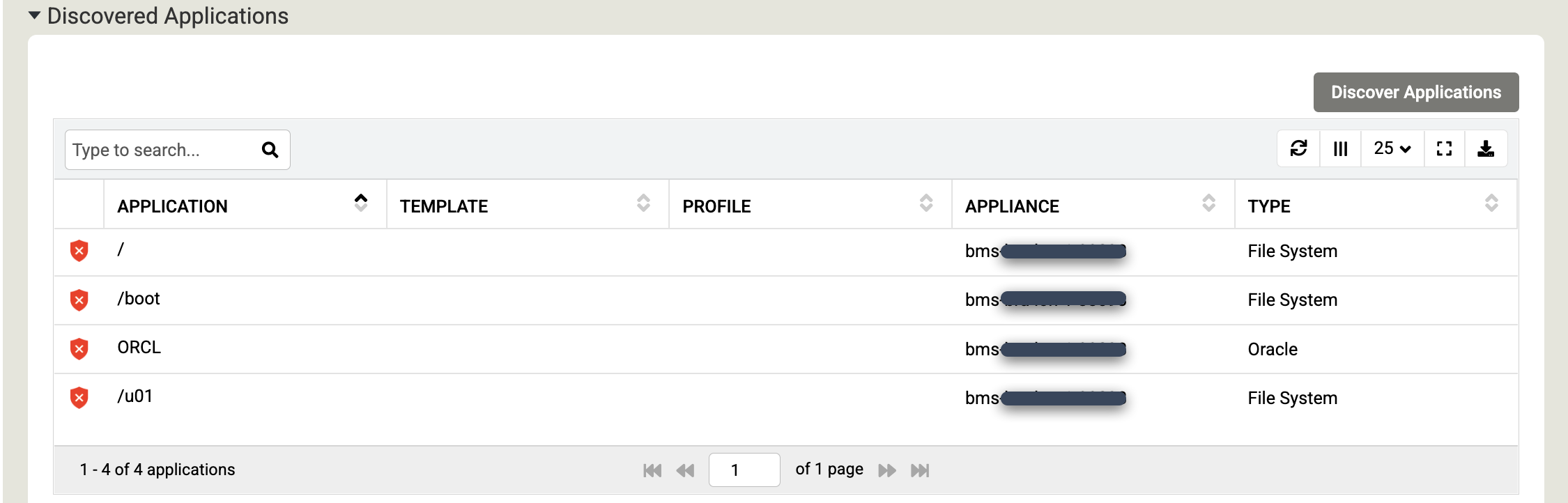
Fai clic su Salva per aggiornare le modifiche agli host.
Prepara l'host Linux
Installando i pacchetti di utilità iSCSI o NFS nell'host basato su Linux OS, puoi mappare un disco di staging a un dispositivo che scrive i dati di backup. Utilizza i seguenti comandi per installare le utilità iSCSI e NFS. Sebbene tu possa utilizzare uno o entrambi i set di utilità, questo passaggio ti assicura di avere ciò che ti serve quando ti serve.
Per installare le utilità iSCSI, esegui questo comando:
sudo yum install -y iscsi-initiator-utils
Per installare le utilità NFS, esegui questo comando:
sudo yum install -y nfs-utils
Prepara il database Oracle
Questa guida presuppone che tu abbia già configurato un'istanza e un database Oracle. Google Cloud Backup e RE supporta la protezione di database in esecuzione su file system, ASM, Real Application Clusters (RAC) e molte altre configurazioni. Per maggiori informazioni, consulta la pagina Backup e RE per i database Oracle.
Prima di avviare il job di backup, devi configurare alcuni elementi. Alcune di queste attività sono facoltative, tuttavia consigliamo le seguenti impostazioni per un rendimento ottimale:
- Utilizza SSH per connetterti all'host Linux e accedi come utente Oracle con privilegi su.
Imposta l'ambiente Oracle sull'istanza specifica:
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
Connettiti a SQL*Plus con l'account
sysdba:sqlplus / as sysdba
Utilizza i seguenti comandi per abilitare la modalità ARCHIVELOG. L'output dei comandi è simile al seguente:
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Configura Direct NFS per l'host Linux:
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
Configura il monitoraggio delle modifiche ai blocchi. Per prima cosa, controlla se è attivato o disattivato. L'esempio seguente mostra il monitoraggio delle modifiche ai blocchi disattivato:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
Esegui il seguente comando quando utilizzi un file system:
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
Verifica che il monitoraggio delle modifiche dei blocchi sia ora attivato:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Proteggere un database Oracle
Nella console di gestione di Backup e RE, vai alla pagina App Manager > Applicazioni.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Fai clic con il tasto destro del mouse sul nome del database Oracle che vuoi proteggere e seleziona Gestisci piano di backup dal menu.
Seleziona il modello e il profilo che vuoi utilizzare, poi fai clic su Applica piano di backup.
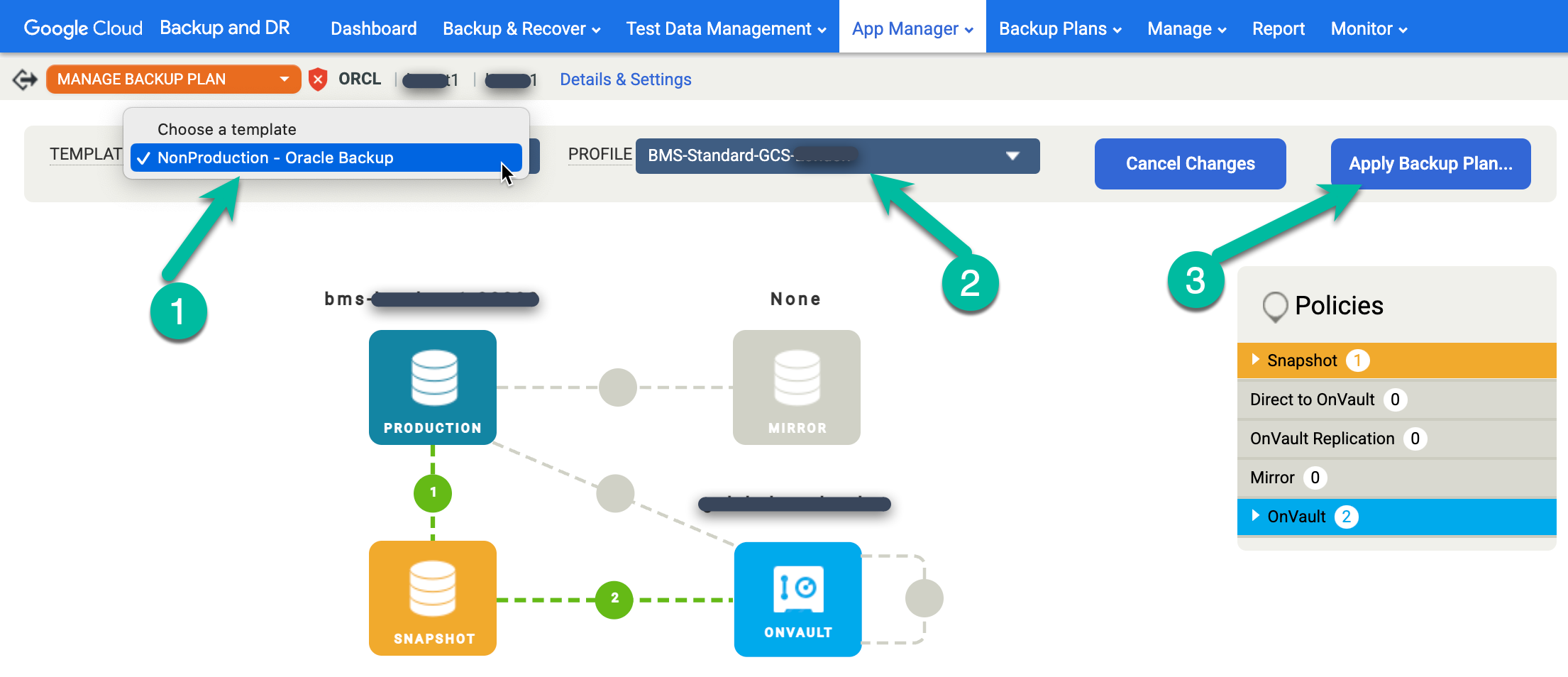
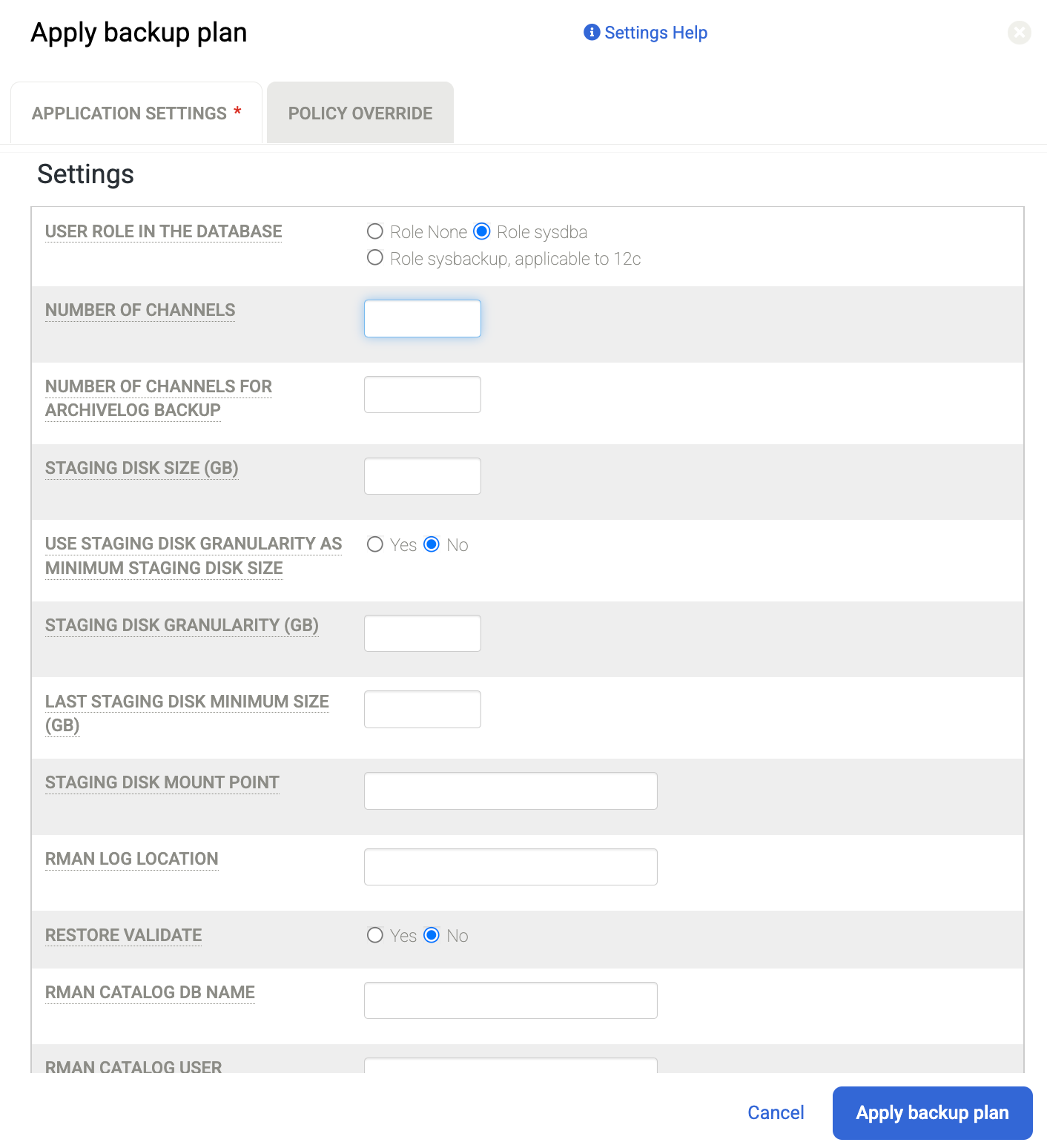
Quando richiesto, imposta le impostazioni avanzate specifiche per Oracle e RMAN richieste per la tua configurazione. Al termine, fai clic su Applica piano di backup.
Numero di canali, ad esempio, il valore predefinito è 2. Pertanto, se hai un numero maggiore di core CPU, puoi aumentare il numero di canali per le operazioni di backup parallele e impostare un numero maggiore.
Per saperne di più sulle impostazioni avanzate, vedi Configurare i dettagli e le impostazioni dell'applicazione per i database Oracle.
Oltre a queste impostazioni, puoi modificare il protocollo utilizzato dal disco di staging per mappare il disco dall'appliance di backup all'host. Vai alla pagina Gestisci > Host e seleziona l'host da modificare. Seleziona l'opzione Formato disco di staging per guest. Per impostazione predefinita è selezionato il formato Blocco, che mappa il disco di staging tramite iSCSI. In alternativa, è possibile impostare il formato NFS, in modo che il disco di staging utilizzi il protocollo NFS.
Le impostazioni predefinite dipendono dal formato del database. Se utilizzi ASM, il sistema utilizza
iSCSI per inviare il backup a un gruppo di dischi ASM. Se utilizzi un file system, il sistema
utilizza iSCSI per inviare il backup a un file system. Se vuoi utilizzare NFS o Direct NFS (dNFS), devi modificare le impostazioni di Host per il disco di staging in NFS. Se invece utilizzi l'impostazione predefinita, tutti i dischi di staging di backup utilizzano il formato di archiviazione a blocchi e iSCSI.
Avvia il job di backup
Nella console di gestione di Backup e RE, vai alla pagina App Manager > Applicazioni.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Fai clic con il tasto destro del mouse sul database Oracle che vuoi proteggere e scegli Gestisci piano di backup dal menu.
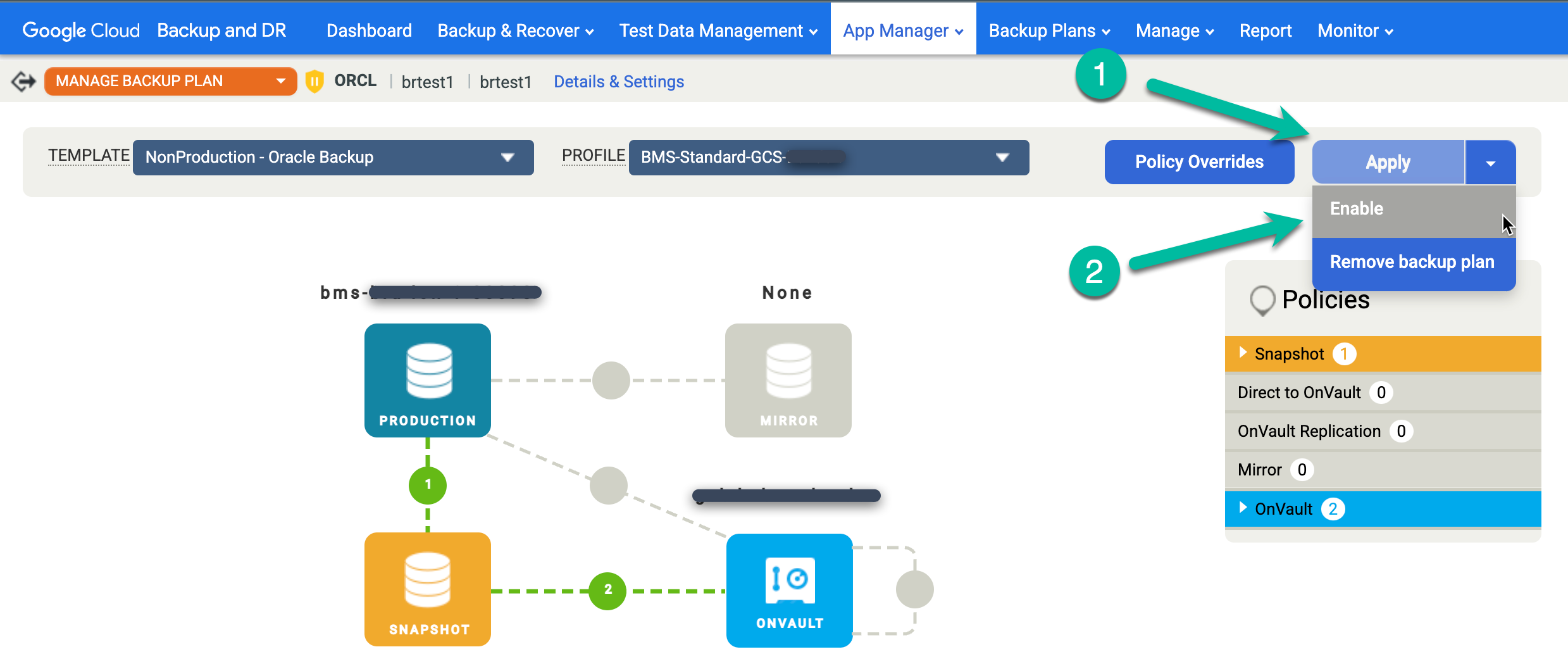
Fai clic sul menu Snapshot a destra e poi su Esegui ora. Viene avviato un job di backup on demand.
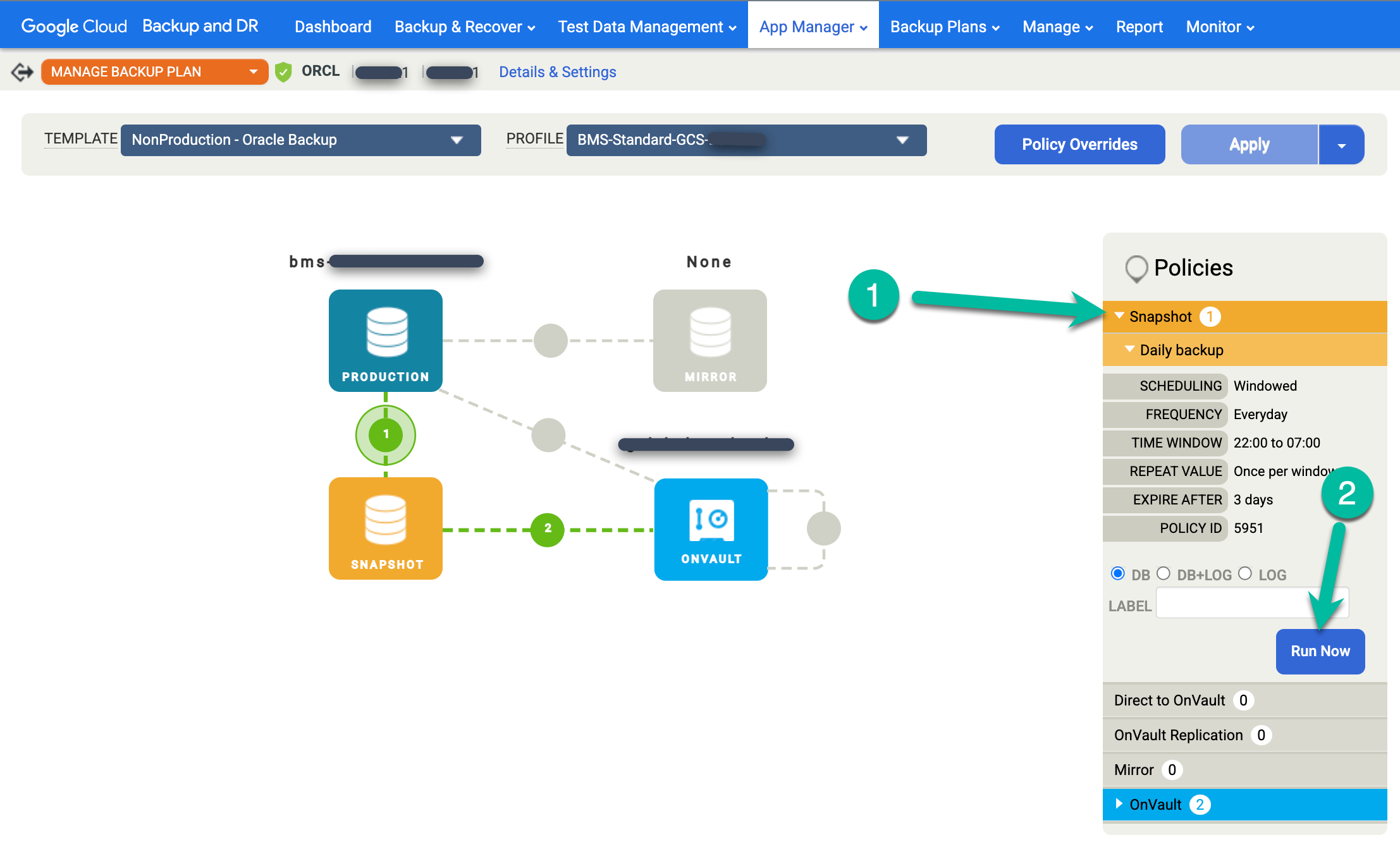
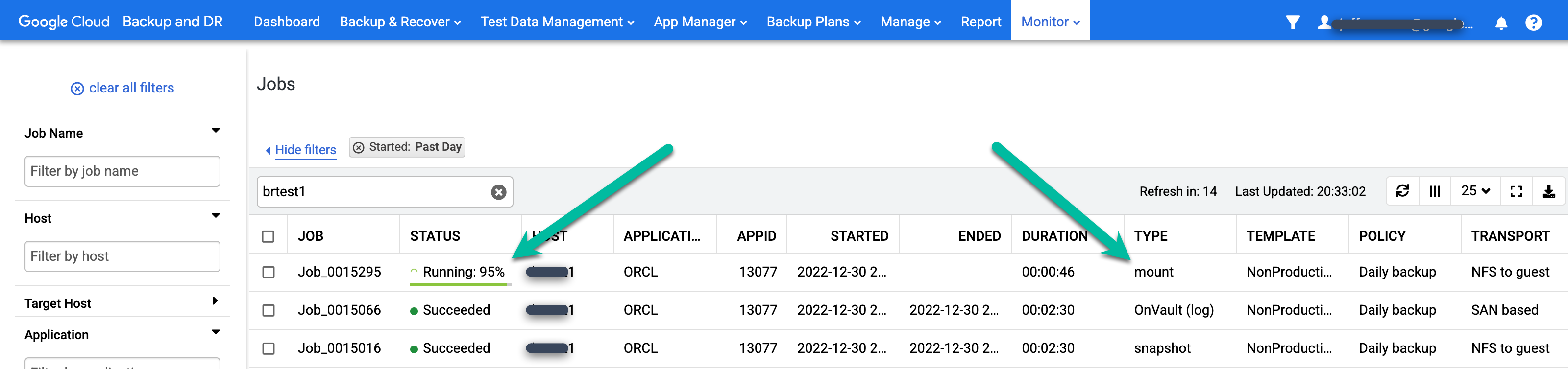
Per monitorare lo stato del job di backup, vai al menu Monitoraggio > Job e visualizza lo stato del job. Potrebbero essere necessari 5-10 secondi prima che un job venga visualizzato nell'elenco dei job. Di seguito è riportato un esempio di job in esecuzione:

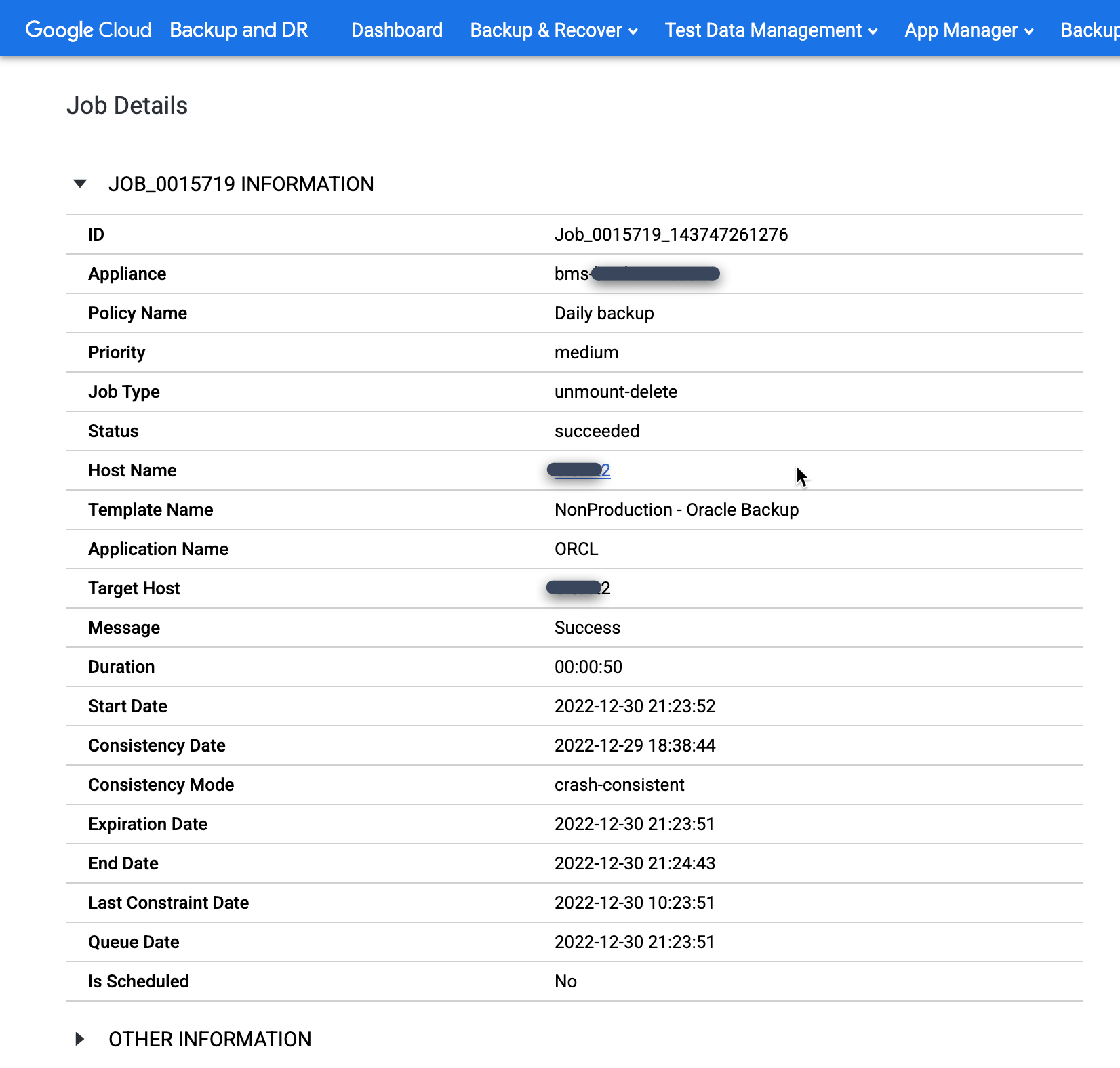
Quando un job ha esito positivo, puoi utilizzare i metadati per visualizzare i dettagli di un job specifico.
- Applica filtri e aggiungi termini di ricerca per trovare i lavori che ti interessano. L'esempio seguente utilizza i filtri Riuscito e Ultimo giorno, insieme a una ricerca dell'host test1.
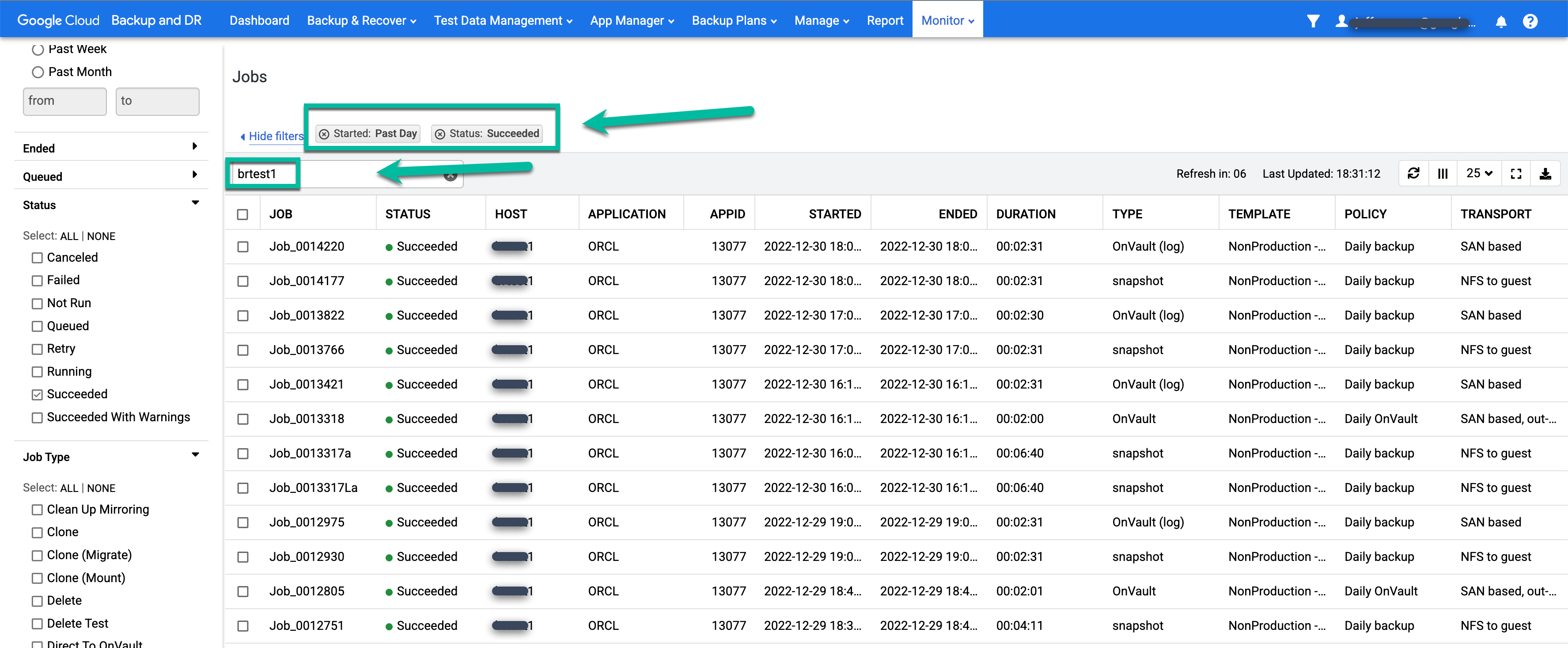
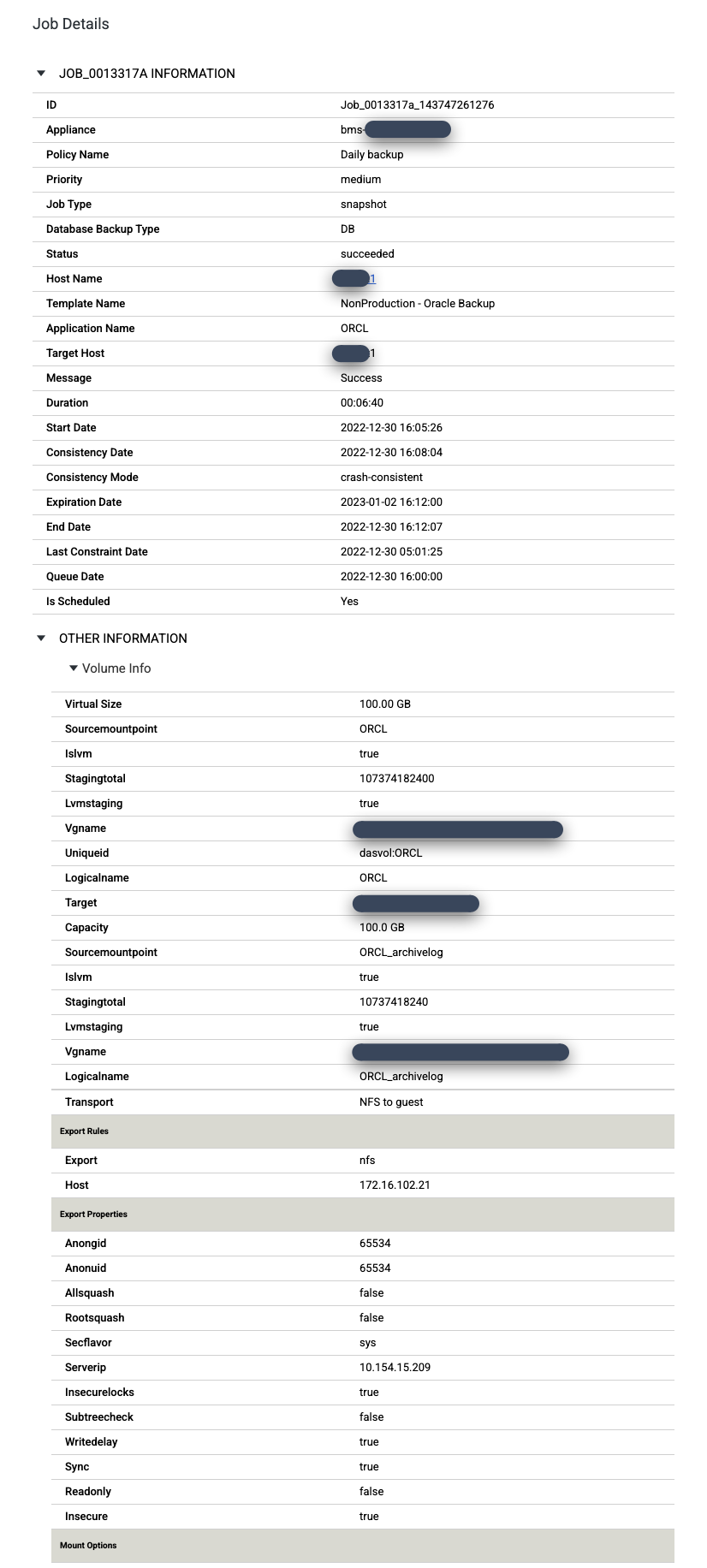
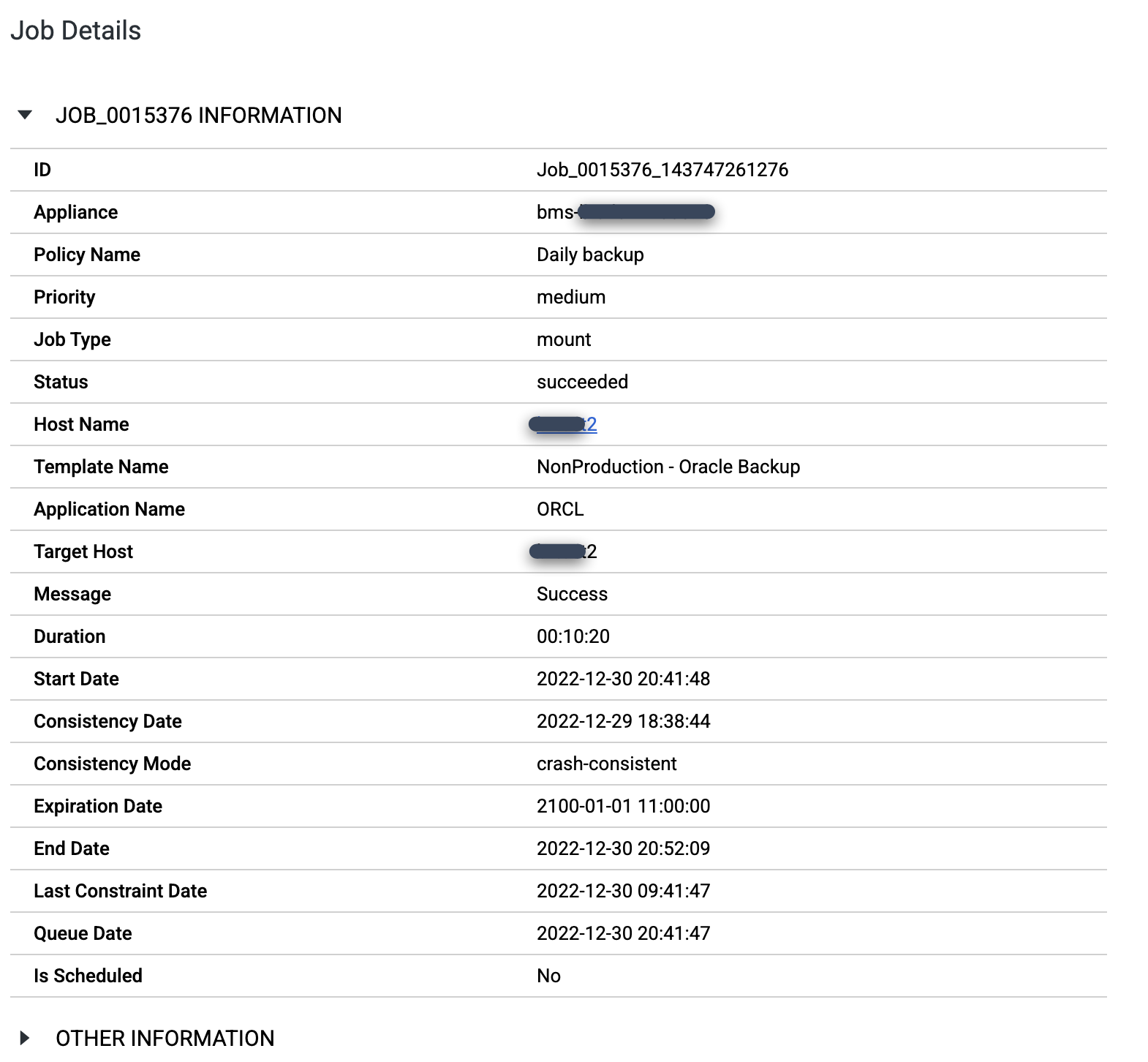
Per esaminare più da vicino un job specifico, fai clic sul job nella colonna Job. Nella nuova finestra visualizzata, Come puoi vedere nell'esempio seguente, ogni job di backup acquisisce una grande quantità di informazioni.
Monta e ripristina un database Oracle
Google Cloud Backup e RE offre diverse funzionalità per accedere a una copia di un database Oracle. I due metodi principali sono i seguenti:
- Supporti consapevoli delle app
- Ripristini (montaggio e migrazione e ripristino tradizionale)
Ciascuno di questi metodi presenta vantaggi diversi, quindi devi selezionare quello che vuoi utilizzare in base al caso d'uso, ai requisiti di rendimento e al periodo di tempo per cui devi conservare la copia del database. Le sezioni seguenti contengono alcuni consigli per ogni funzionalità.
Supporti consapevoli delle app
Utilizzi i mount per accedere rapidamente a una copia virtuale di un database Oracle. Puoi configurare un montaggio quando il rendimento non è fondamentale e la copia del database è disponibile solo per poche ore o pochi giorni.
Il vantaggio principale di un montaggio è che non consuma grandi quantità di spazio di archiviazione aggiuntivo. Il montaggio utilizza invece uno snapshot del pool di dischi di backup, che può essere un pool di snapshot su un Persistent Disk o un pool OnVault in Cloud Storage. L'utilizzo della funzionalità di snapshot della copia virtuale riduce al minimo il tempo di accesso ai dati perché non è necessario copiarli prima. Il disco di backup gestisce tutte le letture e un disco nel pool di snapshot memorizza tutte le scritture. Di conseguenza, le copie virtuali montate sono rapidamente accessibili e non sovrascrivono la copia del disco di backup. I montaggi sono ideali per lo sviluppo, i test e le attività DBA in cui le modifiche o gli aggiornamenti dello schema devono essere convalidati prima di essere implementati nell'ambiente di produzione.
Monta un database Oracle
Nella console di gestione di Backup e RE, vai alla pagina Backup e ripristino > Ripristina.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
Nell'elenco Applicazione, individua il database che vuoi montare, fai clic con il tasto destro del mouse sul nome del database e fai clic su Avanti:
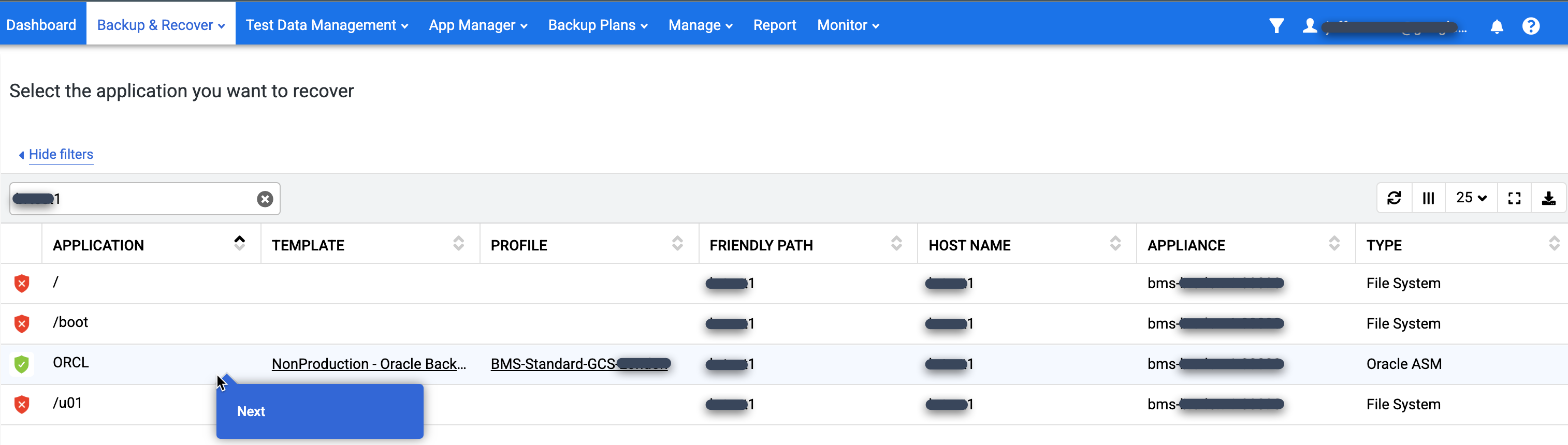
Viene visualizzata la visualizzazione della rampa della sequenza temporale, che mostra tutte le immagini disponibili in un determinato momento. Puoi anche scorrere indietro per visualizzare le immagini di conservazione a lungo termine se non vengono visualizzate nella visualizzazione della rampa. Il sistema seleziona l'immagine più recente per impostazione predefinita.
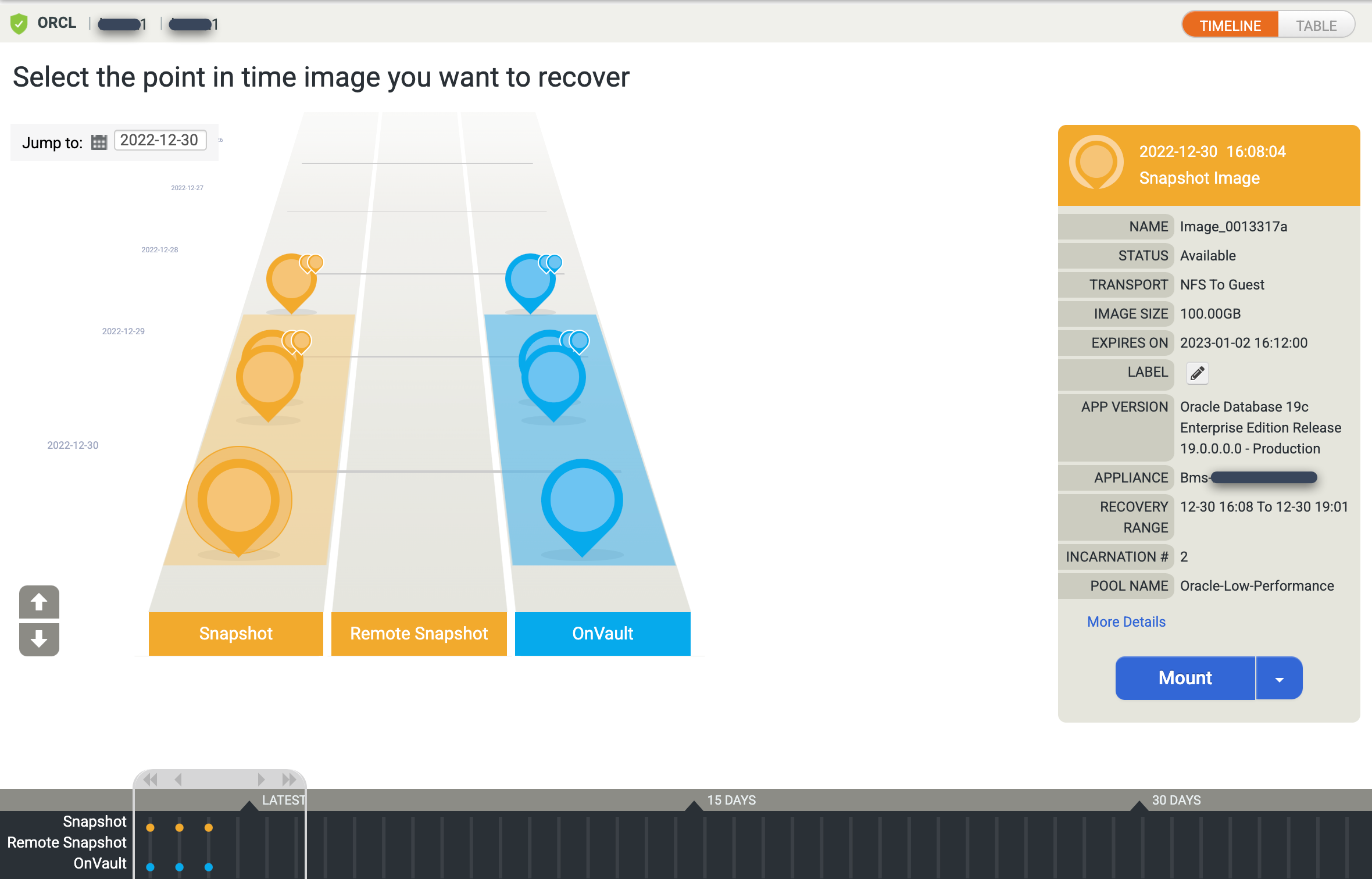
Se preferisci visualizzare una tabella per le immagini in un determinato momento, fai clic sull'opzione Tabella per modificare la visualizzazione:
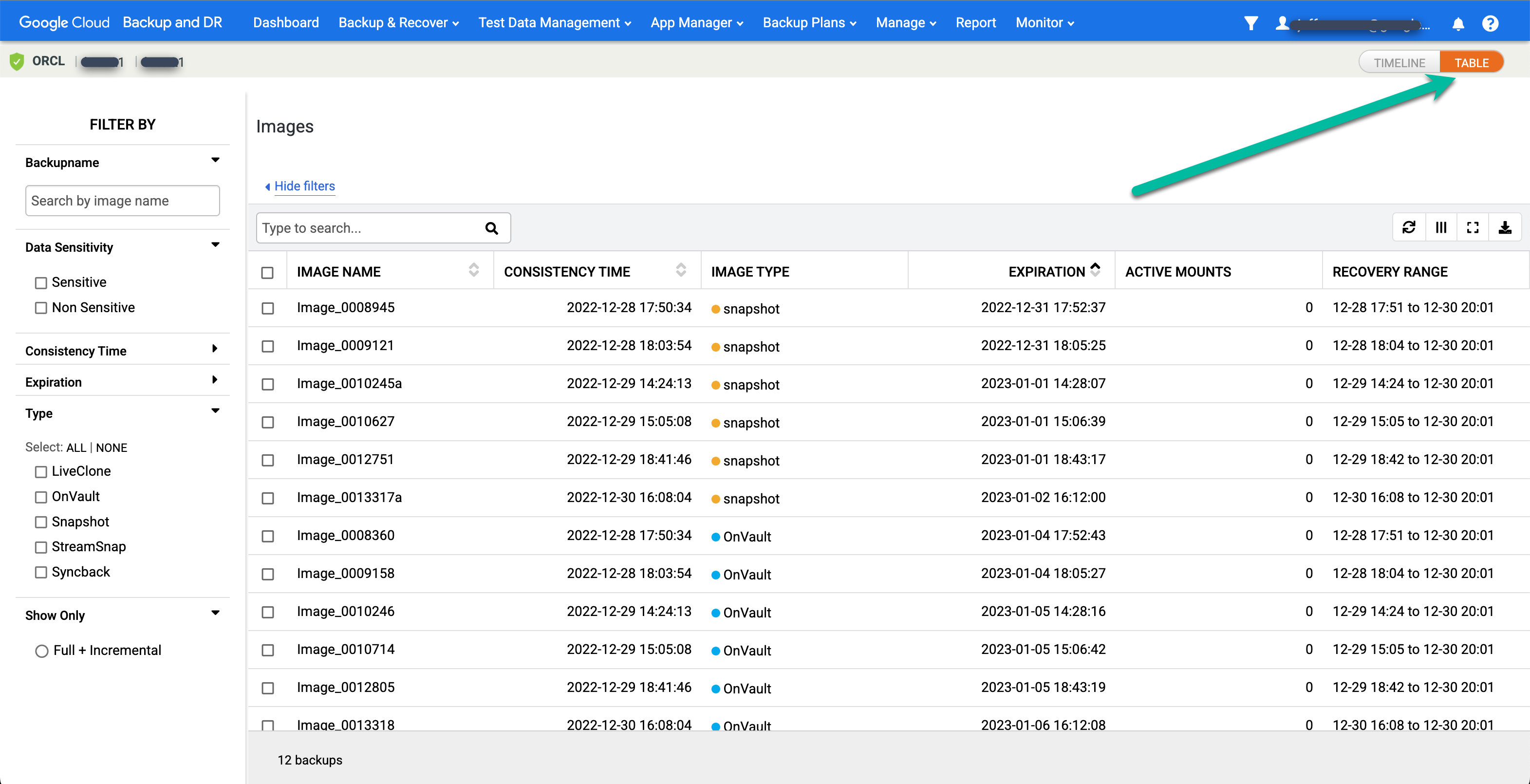
Trova l'immagine che preferisci e seleziona Monta:
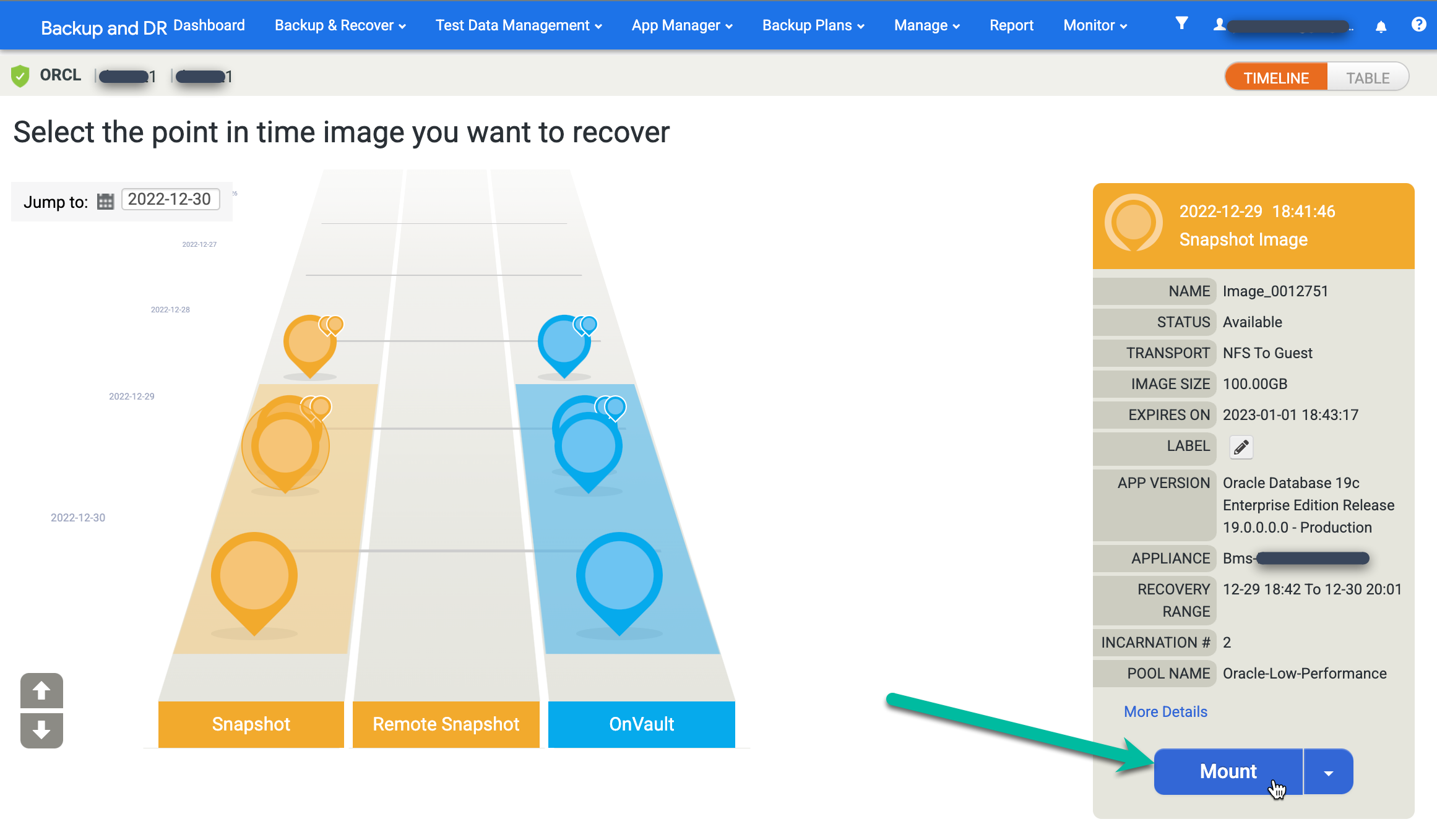
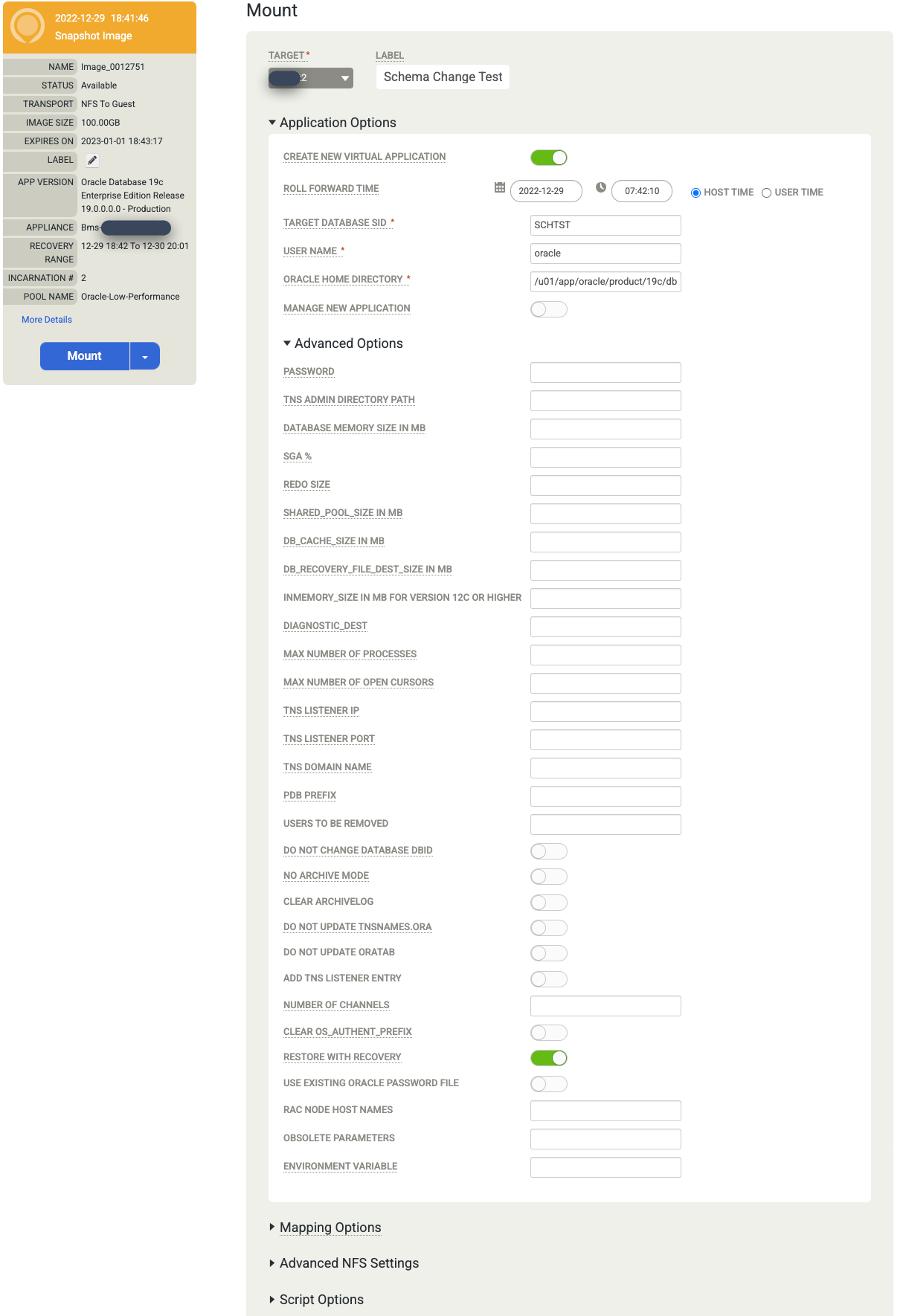
Scegli le opzioni dell'applicazione per il database che monti.
- Seleziona l'host di destinazione dal menu a discesa. Gli host vengono visualizzati in questo elenco se li hai aggiunti in precedenza.
- (Facoltativo) Inserisci un'etichetta.
- Nel campo Target Database SID (SID database di destinazione), inserisci l'identificatore del database di destinazione.
- Imposta Nome utente su oracle. Questo nome diventa il nome utente del sistema operativo per l'autenticazione.
- Inserisci la home directory di Oracle. Per questo esempio, utilizza
/u01/app/oracle/product/19c/dbhome_1. - Se configuri il backup dei log di database, diventa disponibile l'ora di rollforward. Fai clic sul selettore di orologio/ora e scegli il punto di roll forward.
- Ripristina con il recupero è abilitato per impostazione predefinita. Questa opzione monta e apre il database.
Al termine dell'inserimento delle informazioni, fai clic su Invia per avviare la procedura di montaggio.
Monitorare l'avanzamento e l'esito dei job
Puoi monitorare il job in esecuzione andando alla pagina Monitoraggio > Job.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
La pagina mostra lo stato e il tipo di job.
Al termine del job di montaggio, puoi visualizzare i dettagli del job facendo clic sul numero di job:
Per visualizzare i processi pmon per l'SID che hai creato, accedi all'host di destinazione ed esegui il comando
ps -ef |grep pmon. Nel seguente esempio di output, il database SCHTEST è operativo e ha un ID processo di 173953.[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asm_pmon_+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Smontare un database Oracle
Dopo aver terminato di utilizzare il database, devi smontarlo ed eliminarlo. Esistono due metodi per trovare un database montato:
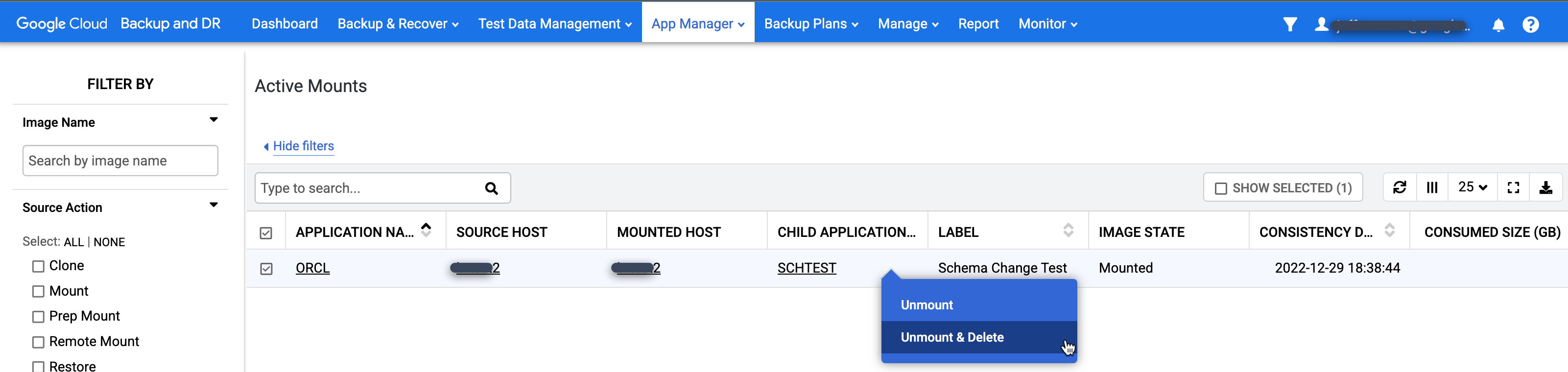
Vai alla pagina App Manager > Active Mounts (Gestione app > Montaggi attivi).
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
Questa pagina contiene una visualizzazione globale di tutte le applicazioni (file system e database) attualmente in uso.
Fai clic con il tasto destro del mouse sul montaggio che vuoi pulire e seleziona Smonta ed elimina dal menu. Questa azione non eliminerà i dati di backup. Rimuove solo il database virtuale montato dall'host di destinazione e il disco della cache degli snapshot che conteneva le scritture archiviate per il database.
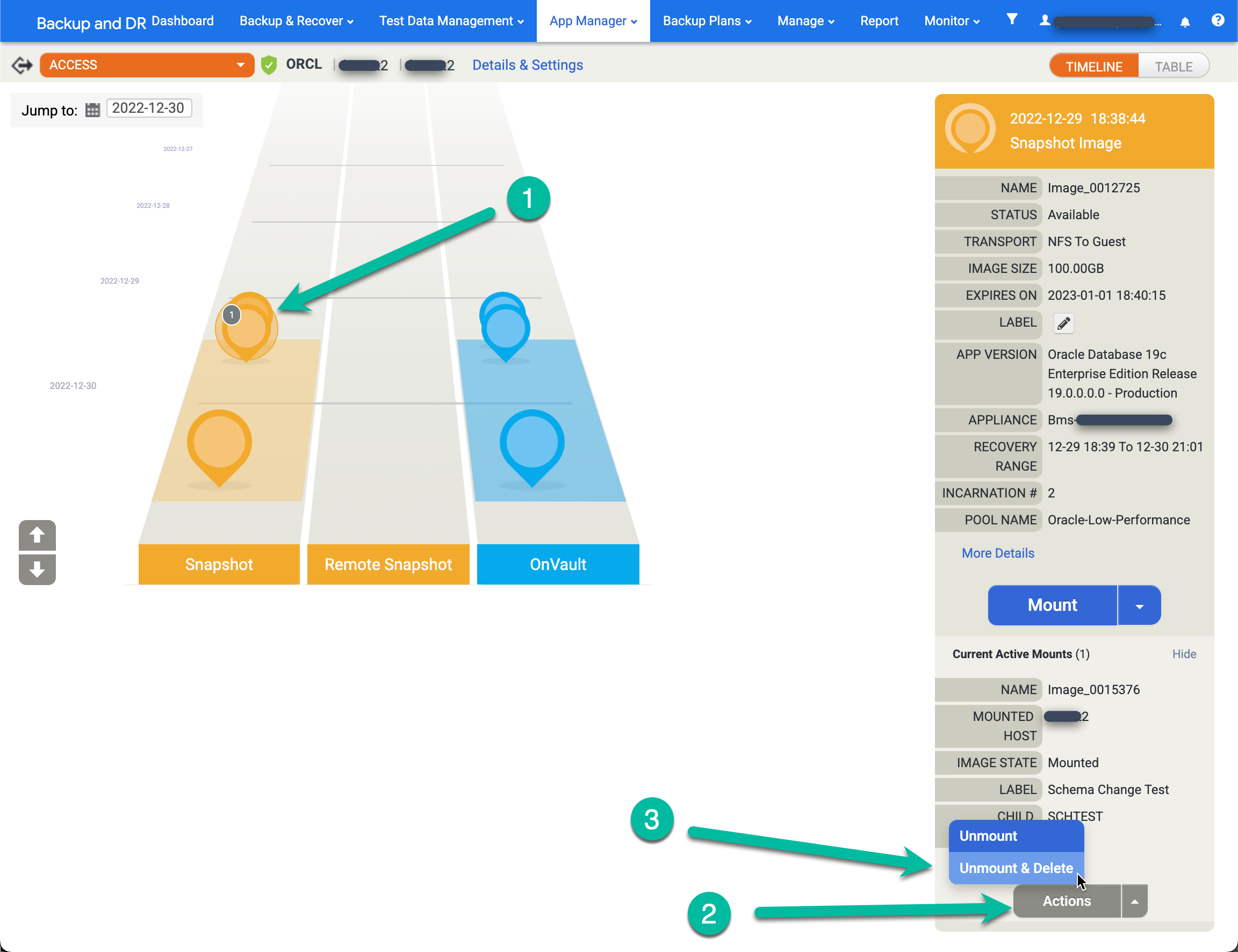
Vai alla pagina App Manager > Applicazioni.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
- Fai clic con il tasto destro del mouse sull'app (database) di origine e seleziona Accesso.
- Nella rampa a sinistra, vedi un cerchio grigio con un numero all'interno che indica il numero di supporti attivi da questo momento in poi. Fai clic sull'immagine e viene visualizzato un nuovo menu.
- Fai clic su Azioni.
- Fai clic su Smonta ed elimina.
- Fai clic su Invia e conferma l'azione nella schermata successiva.
Qualche minuto dopo, il sistema rimuove il database dall'host di destinazione, pulisce e rimuove tutti i dischi. Questa azione libera lo spazio su disco nel pool di snapshot utilizzato per le scritture sul disco di ripristino per i montaggi attivi.
Puoi monitorare i job non montati come qualsiasi altro job. Vai al menu Monitoraggio > Job per monitorare l'avanzamento del job di disattivazione e verificare che il job venga completato.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
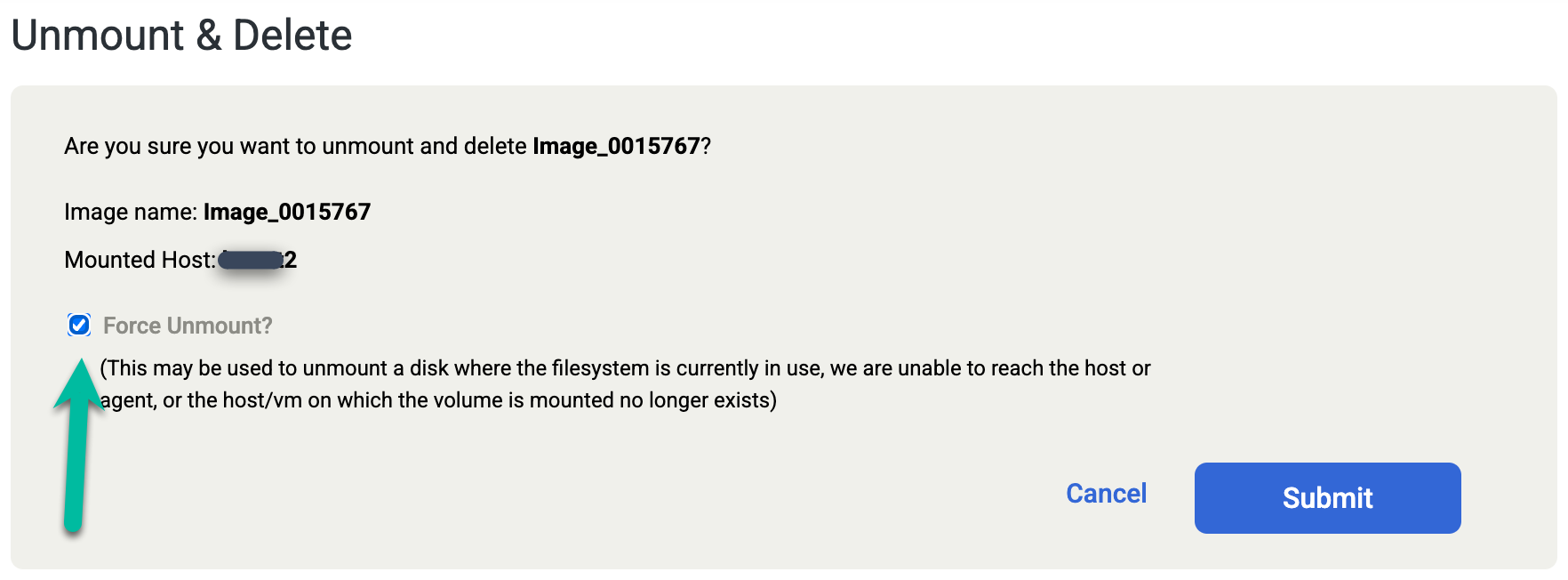
Se elimini accidentalmente il database Oracle manualmente o lo arresti prima di eseguire il job Smonta ed elimina, esegui di nuovo il job Smonta ed elimina e seleziona l'opzione Forza smontaggio nella schermata di conferma. Questa azione rimuove forzatamente il disco di gestione temporanea di ripetizione dall'host di destinazione ed elimina il disco dal pool di snapshot.
Ripristini
Utilizzi i ripristini per recuperare i database di produzione quando si verifica un problema o un danneggiamento e devi copiare tutti i file del database in un host locale da una copia di backup. In genere, esegui un ripristino dopo un evento di tipo disastro o per copie di test non di produzione. In questo caso, i tuoi clienti in genere devono attendere che tu copi di nuovo i file precedenti nell'host di origine prima di riavviare i database. Tuttavia, Google Cloud Backup e RE supporta anche una funzionalità di ripristino (copia i file e avvia il database) e una funzionalità di montaggio e migrazione, in cui monti il database (il tempo di accesso è rapido) e puoi copiare i file di dati sulla macchina locale mentre il database è montato e accessibile. La funzionalità di montaggio e migrazione è utile per scenari con Recovery Time Objective (RTO) basso.
Montare ed eseguire la migrazione
Il recupero basato sul montaggio e sulla migrazione prevede due fasi:
- Fase 1–La fase di montaggio del ripristino fornisce l'accesso immediato al database a partire dalla copia montata.
- Fase 2: la fase di migrazione del ripristino esegue la migrazione del database nella posizione di archiviazione di produzione mentre il database è online.
Ripristino del supporto - Fase 1
Questa fase ti consente di accedere immediatamente al database da un'immagine selezionata presentata dall'appliance di backup/ripristino.
- Una copia dell'immagine di backup selezionata viene mappata al server di database di destinazione e presentata al livello ASM o del file system in base al formato dell'immagine di backup del database di origine.
- Utilizza l'API RMAN per eseguire le seguenti attività:
- Ripristina il file di controllo e il file di log di ripristino nella posizione specificata del file di controllo locale e del file di ripristino (gruppo di dischi ASM o file system).
- Passa al database alla copia dell'immagine presentata dall'appliance di backup/ripristino.
- Esegui il roll forward di tutti i log degli archivi disponibili fino al punto di ripristino specificato.
- Apri il database in modalità di lettura e scrittura.
- Il database viene eseguito dalla copia mappata dell'immagine di backup presentata dall'appliance di backup/ripristino.
- Il file di controllo e il file di log di ripristino del database vengono inseriti nella posizione di archiviazione di produzione locale selezionata (gruppo di dischi ASM o file system) nella destinazione.
- Dopo un'operazione di montaggio del ripristino riuscita, il database diventa disponibile per le operazioni di produzione. Puoi utilizzare l'API Oracle online datafile move per spostare i dati nella posizione di archiviazione di produzione (gruppo di dischi ASM o file system) mentre il database e l'applicazione sono in esecuzione.
Ripristino della migrazione - Fase 2
Sposta online il file di dati del database nello spazio di archiviazione di produzione:
- La migrazione dei dati viene eseguita in background. Utilizza l'API Oracle online datafile move per eseguire la migrazione dei dati.
- Sposta i file di dati dalla copia dell'immagine di backup presentata da Backup e RE allo spazio di archiviazione del database di destinazione selezionato (gruppo di dischi ASM o file system).
- Al termine del job di migrazione, il sistema rimuove e annulla il mapping della copia dell'immagine di backup presentata da Backup and RE (gruppo di dischi ASM o file system) dalla destinazione e il database viene eseguito dallo spazio di archiviazione di produzione.
Per ulteriori informazioni sul montaggio e sulla migrazione del recupero, vedi: Monta e migra un'immagine di backup Oracle per il recupero immediato su qualsiasi destinazione.
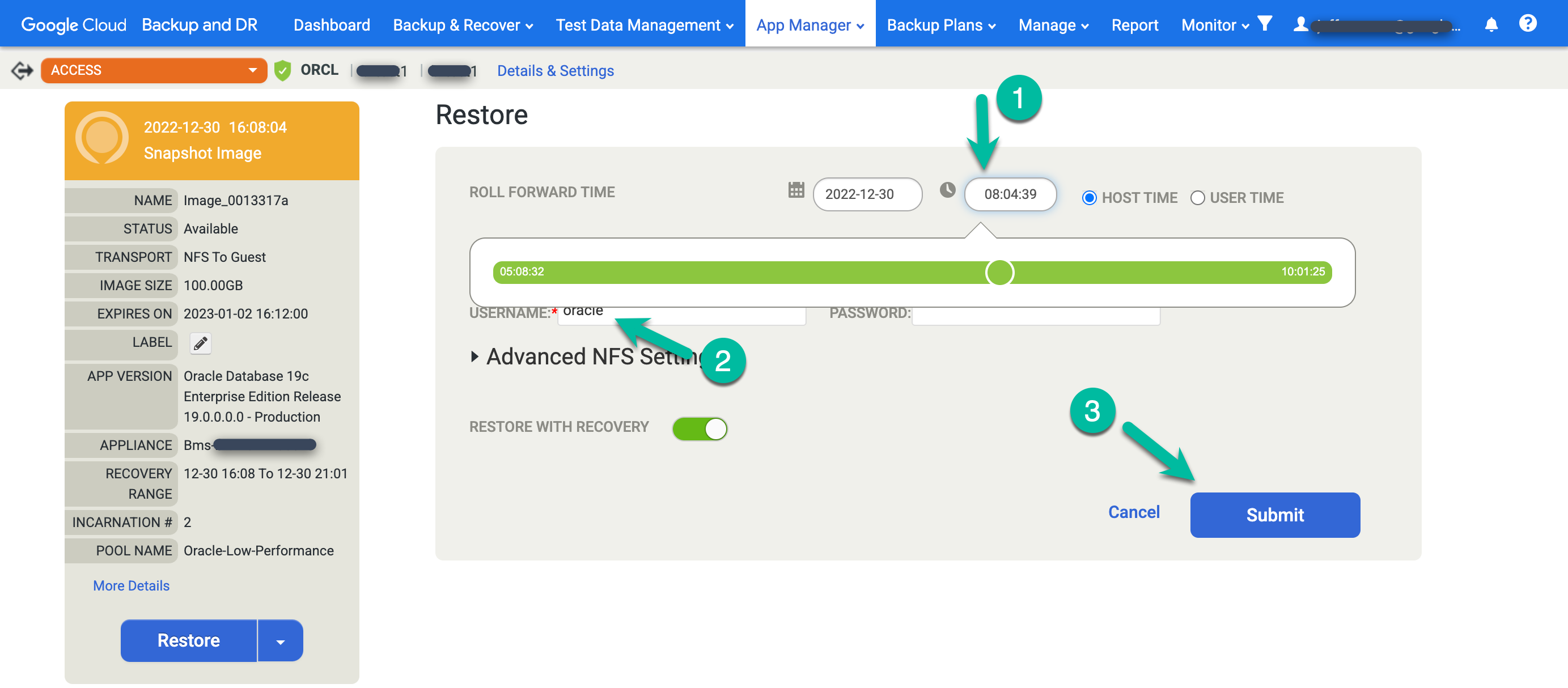
Ripristinare un database Oracle
Nella console di gestione di Backup e RE, vai alla pagina Backup e ripristino > Ripristina.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
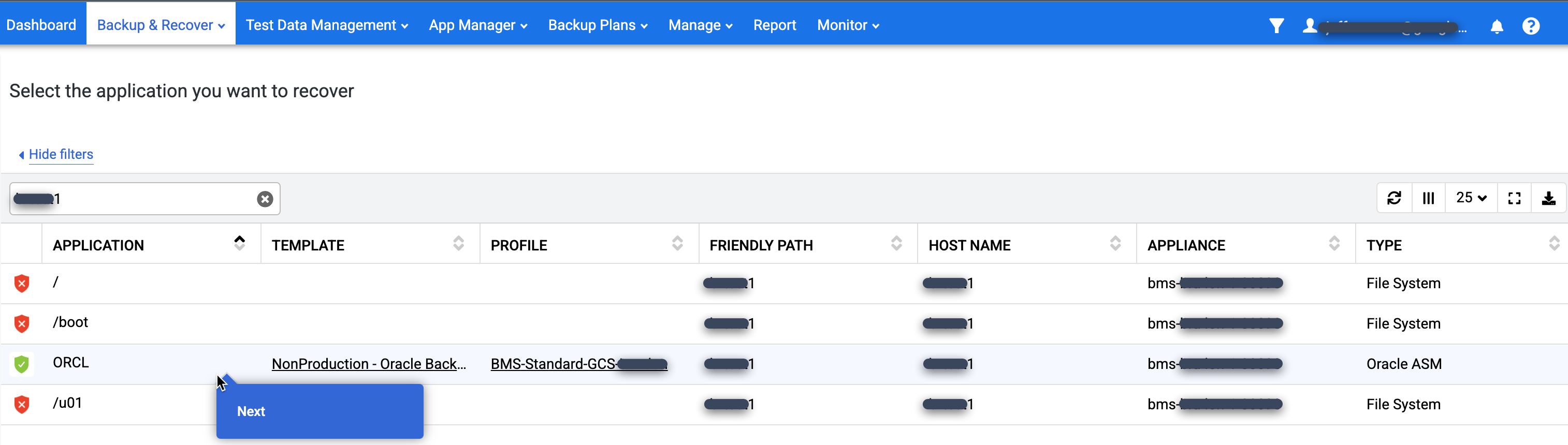
Nell'elenco Applicazione, fai clic con il tasto destro del mouse sul nome del database che vuoi ripristinare e seleziona Avanti:
Viene visualizzata la visualizzazione della rampa della sequenza temporale, che mostra tutte le immagini istantanee disponibili. Puoi anche scorrere indietro se devi visualizzare le immagini di conservazione a lungo termine che non vengono visualizzate nell'implementazione graduale. Il sistema seleziona sempre l'immagine più recente per impostazione predefinita.
Per ripristinare un'immagine, fai clic sul menu Monta e seleziona Ripristina:
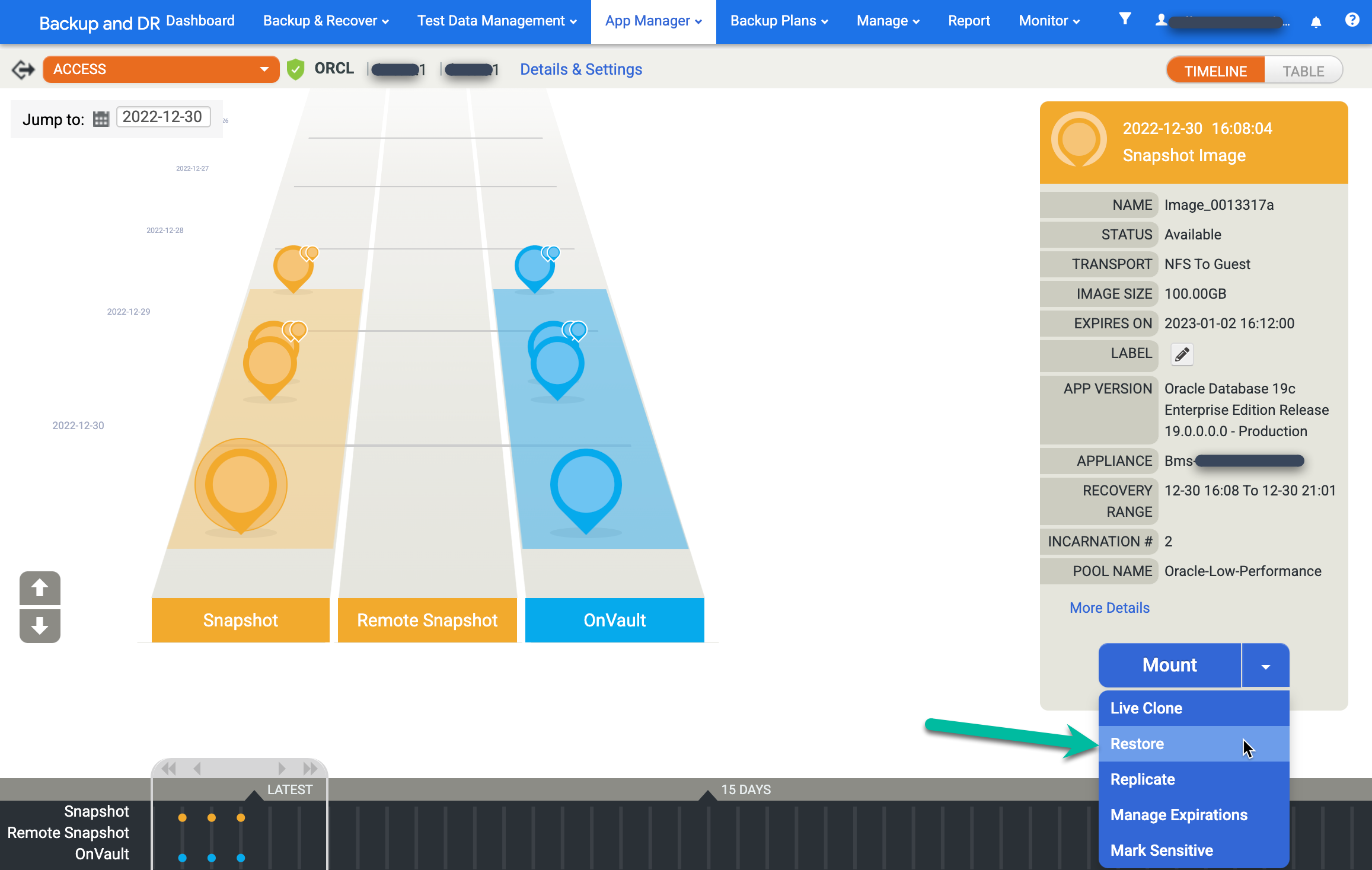
Scegli le opzioni di ripristino.
- Seleziona l'ora di roll forward. Fai clic sull'orologio e scegli il momento che ti interessa.
- Inserisci il nome utente che prevedi di utilizzare per Oracle.
- Se il tuo sistema utilizza l'autenticazione del database, inserisci una password.
Per avviare il job, fai clic su Invia.
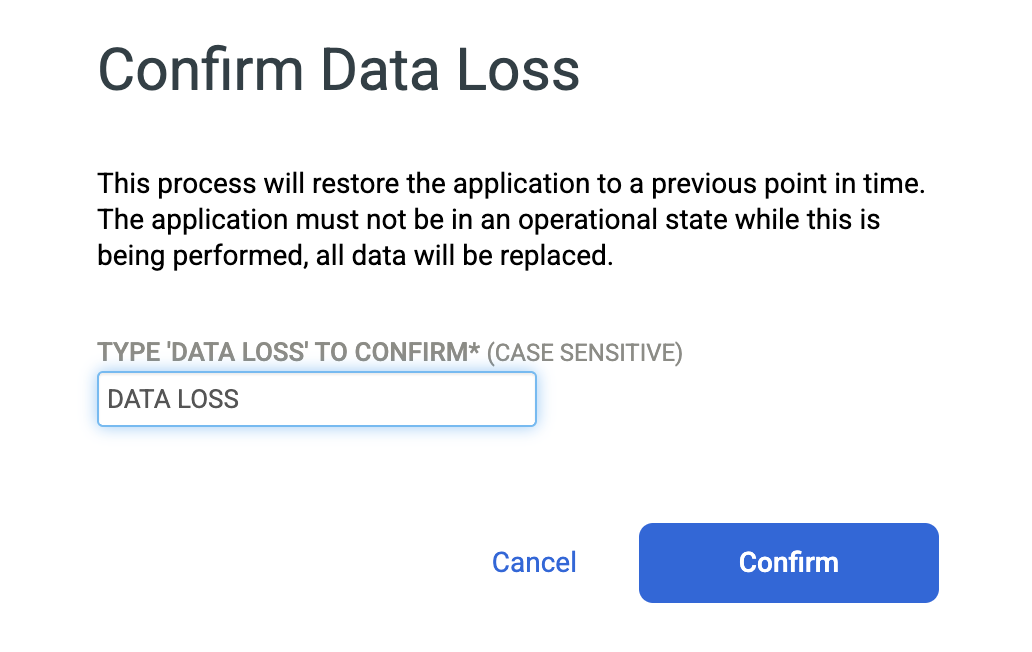
Digita DATA LOSS per confermare che vuoi sovrascrivere il database di origine e fai clic su Conferma.
Monitorare l'avanzamento e l'esito dei job
Per monitorare il job, vai alla pagina Monitoraggio > Job.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
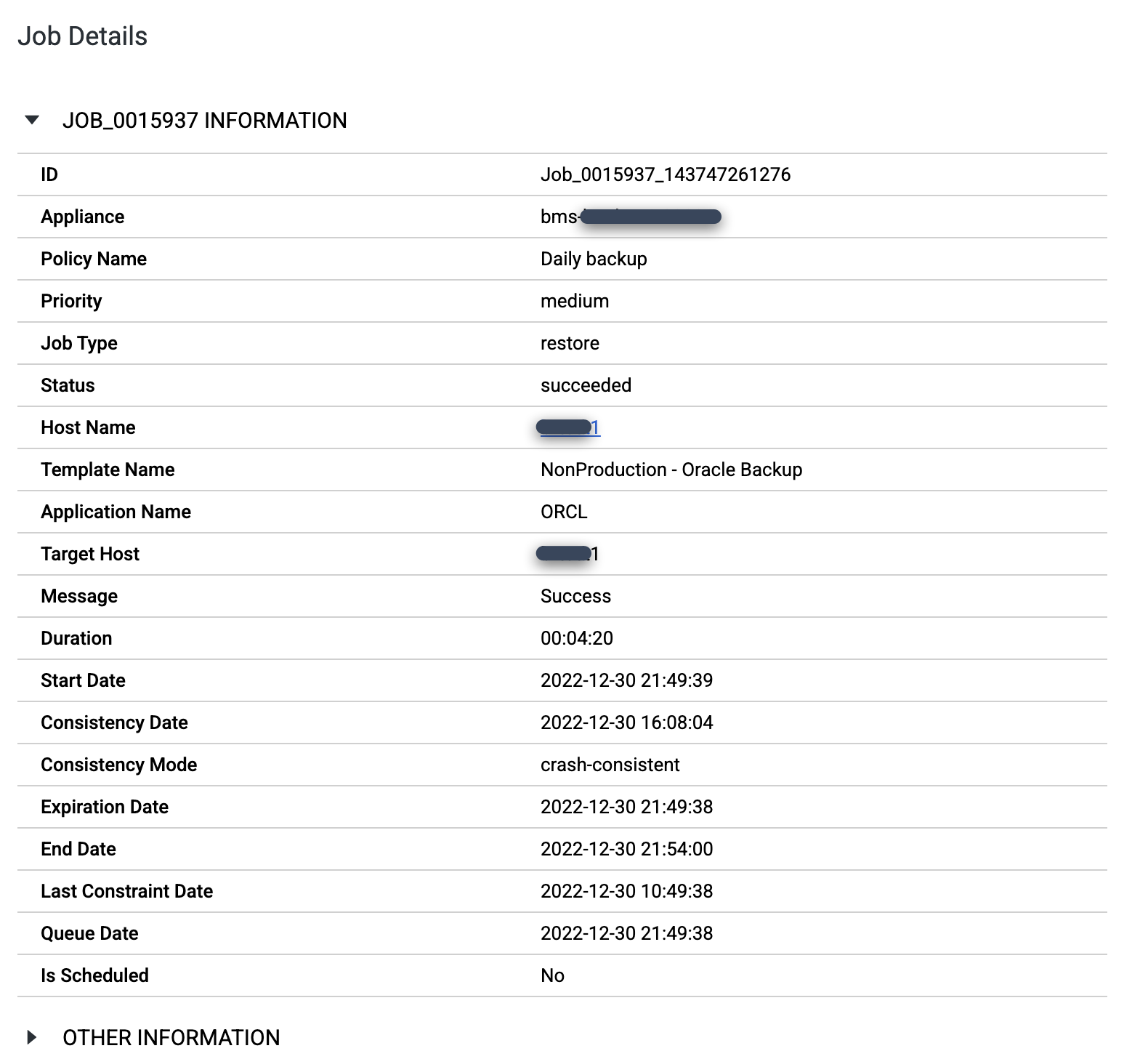
Al termine del job, fai clic su Numero job per esaminare i dettagli e i metadati del job.
Proteggere il database ripristinato
Al termine del job di ripristino del database, il sistema non esegue automaticamente il backup del database dopo il ripristino. In altre parole, quando ripristini un database che in precedenza aveva un piano di backup, il piano di backup non viene attivato per impostazione predefinita.
Per verificare che il piano di backup non sia in esecuzione, vai alla pagina App Manager > Applicazioni.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Trova il database ripristinato nell'elenco. L'icona di protezione passa dal verde al giallo, il che indica che il sistema non è pianificato per eseguire i job di backup per il database.
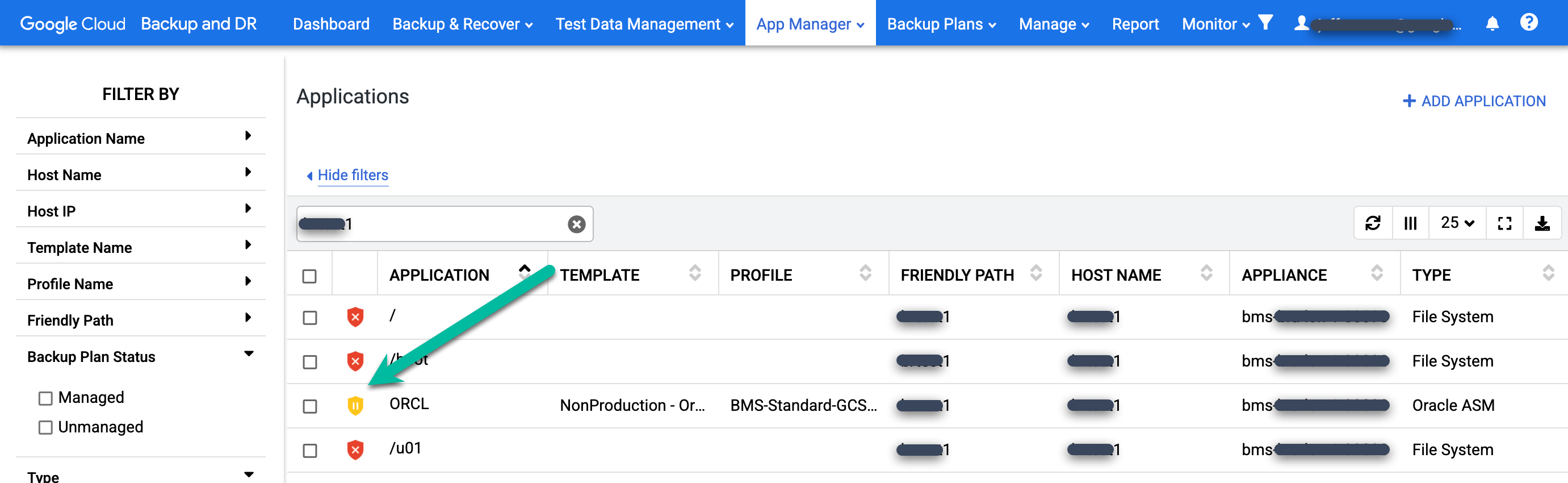
Per proteggere il database ripristinato, cerca nella colonna Applicazione il database che vuoi proteggere. Fai clic con il tasto destro del mouse sul nome del database e seleziona Gestisci piano di backup.
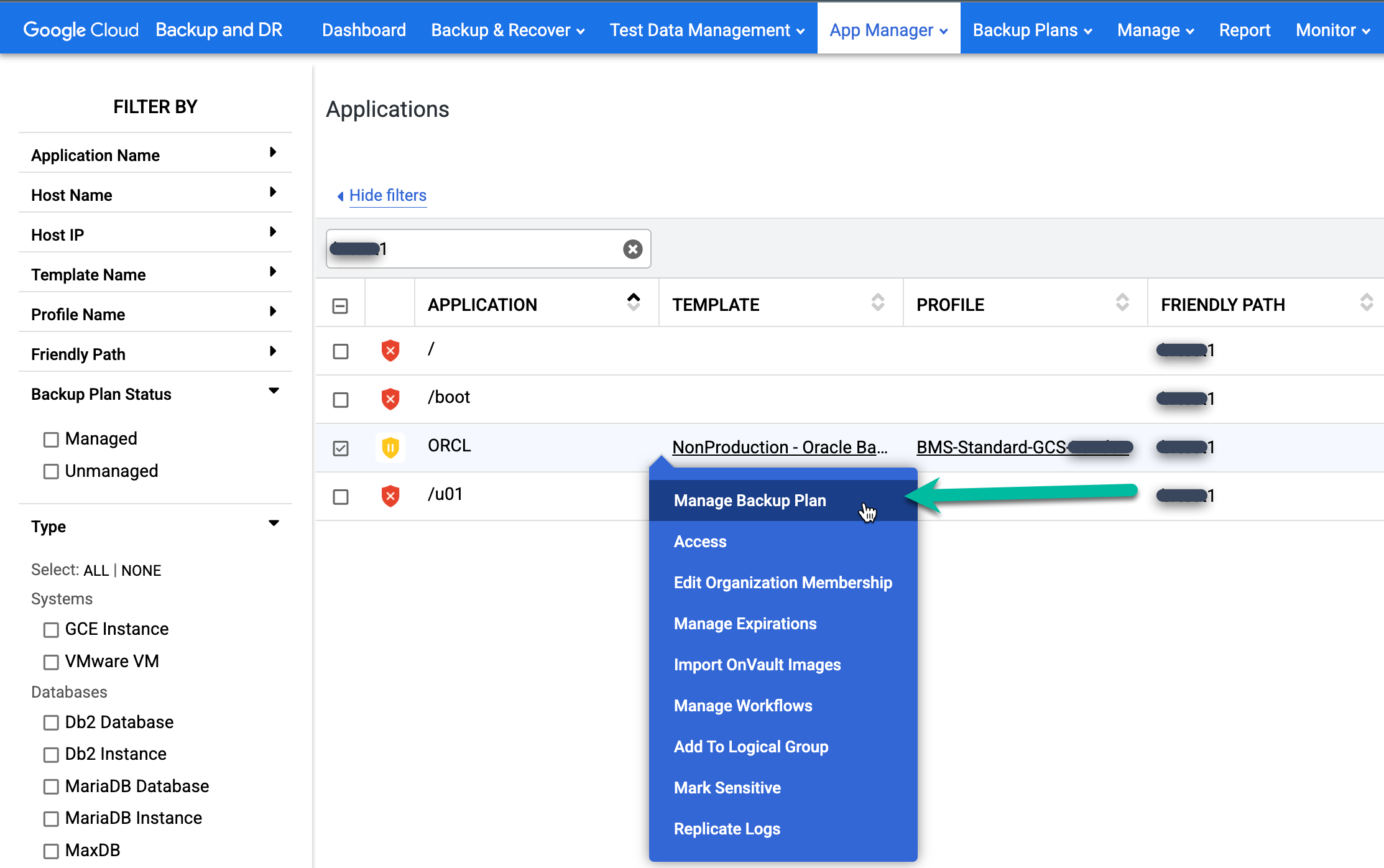
Riattiva il job di backup pianificato per il database ripristinato.
- Fai clic sul menu Applica e seleziona Attiva.
Conferma le impostazioni avanzate di Oracle e fai clic su Attiva piano di backup.
Risoluzione dei problemi e ottimizzazione
Questa sezione fornisce alcuni suggerimenti utili per aiutarti a risolvere i problemi relativi ai backup Oracle, ottimizzare il sistema e valutare gli aggiustamenti per gli ambienti RAC e Data Guard.
Risoluzione dei problemi di backup di Oracle
Le configurazioni Oracle contengono una serie di dipendenze per garantire la riuscita dell'attività di backup. I passaggi riportati di seguito forniscono diversi suggerimenti per configurare le istanze, i listener e i database Oracle per garantire il successo.
Per verificare che il listener Oracle per il servizio e l'istanza che vuoi proteggere sia configurato e in esecuzione, esegui il comando
lsnrctl status:[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
Verifica di aver configurato il database Oracle in modalità ARCHIVELOG. Se il database viene eseguito in una modalità diversa, potresti visualizzare job non riusciti con il messaggio Codice di errore 5556 come segue:
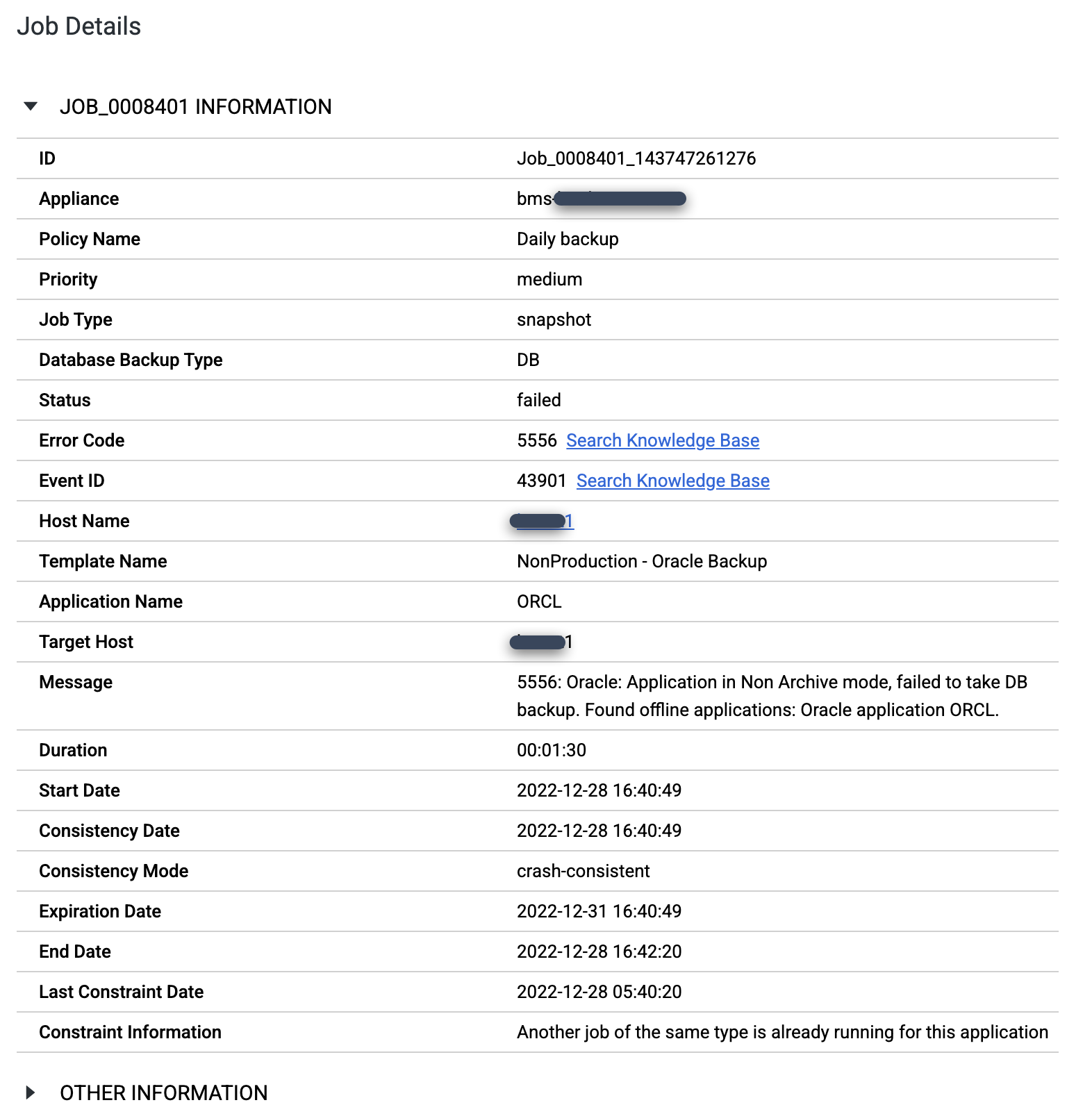
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Abilita il monitoraggio delle modifiche dei blocchi nel database Oracle. Sebbene non sia obbligatorio per il funzionamento della soluzione, l'attivazione del monitoraggio delle modifiche ai blocchi evita la necessità di eseguire una notevole quantità di lavoro di post-elaborazione per calcolare i blocchi modificati e contribuisce a ridurre i tempi dei job di backup:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Verifica che il database utilizzi
spfile:sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Attiva Direct NFS (dnfs) per gli host del database Oracle. Sebbene non sia obbligatorio, se hai bisogno del metodo più veloce per eseguire il backup e il ripristino dei database Oracle, dnfs è la scelta preferita. Per migliorare ulteriormente il throughput, puoi modificare il disco di staging in base all'host e attivare dnfs per Oracle.
Configura tnsnames per la risoluzione degli host del database Oracle. Se non includi questa impostazione, i comandi RMAN spesso non vanno a buon fine. Di seguito è riportato un esempio di output:
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
Il campo
SERVICE_NAMEè importante per le configurazioni RAC. Il nome del servizio rappresenta l'alias utilizzato per pubblicizzare il sistema alle risorse esterne che comunicano con il cluster. Nelle opzioni Dettagli e impostazioni per il database protetto, utilizza l'impostazione avanzata per il nome del servizio Oracle. Inserisci il nome del servizio specifico che vuoi utilizzare sui nodi che eseguono il job di backup.Il database Oracle utilizza il nome del servizio solo per l'autenticazione del database. Il database non utilizza il nome del servizio per l'autenticazione del sistema operativo. Ad esempio, il nome del database potrebbe essere CLU1_S e il nome dell'istanza potrebbe essere CLU1_S.
Se il nome del servizio Oracle non è elencato, crea una voce del nome del servizio sui server nel file tnsnames.ora che si trova in
$ORACLE_HOME/network/admino in$GRID_HOME/network/adminaggiungendo la seguente voce:CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) Se il file tnsnames.ora si trova in una posizione non standard, fornisci il percorso assoluto del file nella pagina Dettagli e impostazioni dell'applicazione descritta in Configurare i dettagli e le impostazioni dell'applicazione per i database Oracle.
Verifica di aver configurato correttamente la voce del nome del servizio per il database. Accedi a Oracle Linux e configura l'ambiente Oracle:
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
Esamina l'account utente del database per assicurarti che la connessione all'applicazione Backup and RE sia riuscita:
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Nella pagina Dettagli e impostazioni dell'applicazione descritta in Dettagli e impostazioni dell'applicazione per i database Oracle, inserisci il nome del servizio che hai creato (CLU1_S) nel campo Nome servizio Oracle:
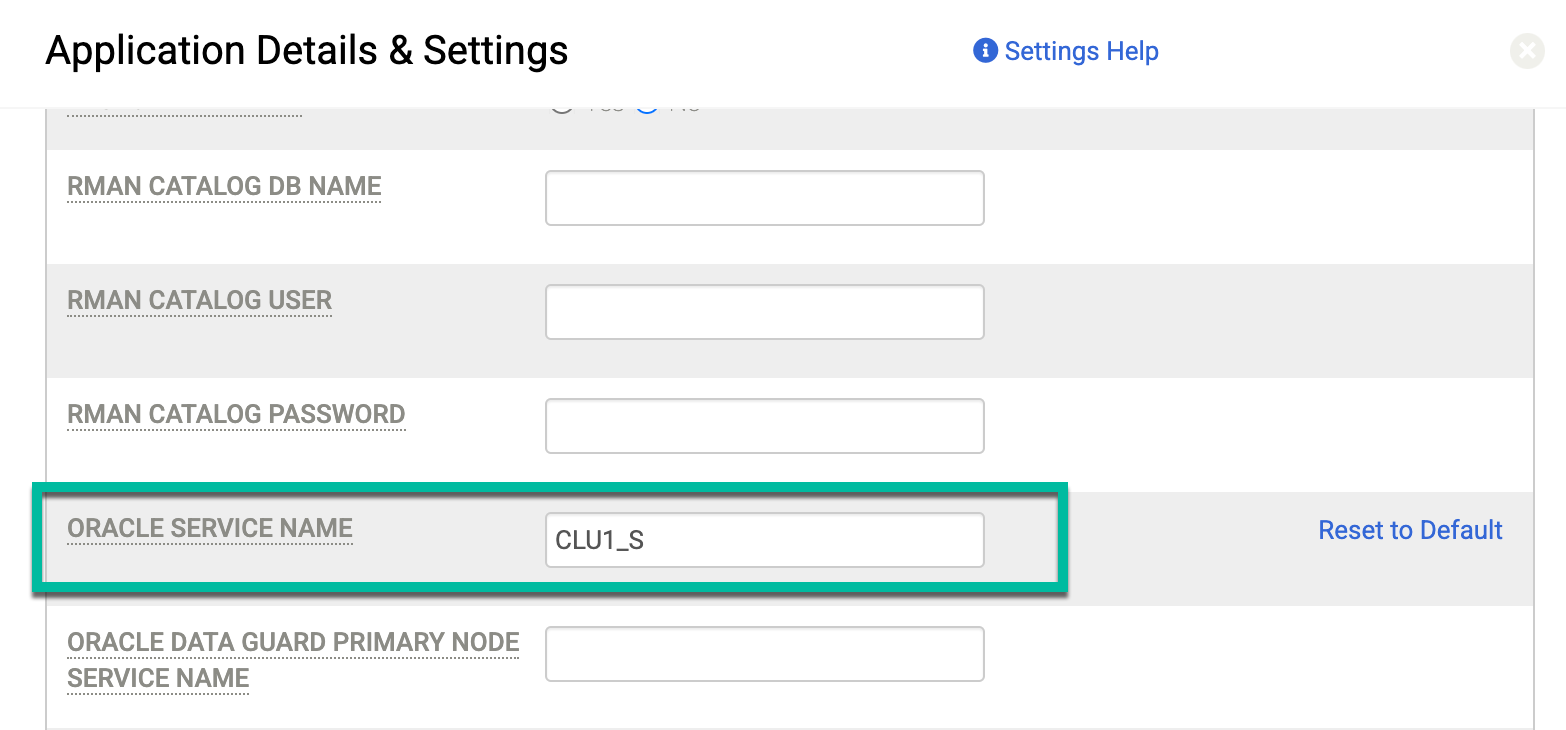
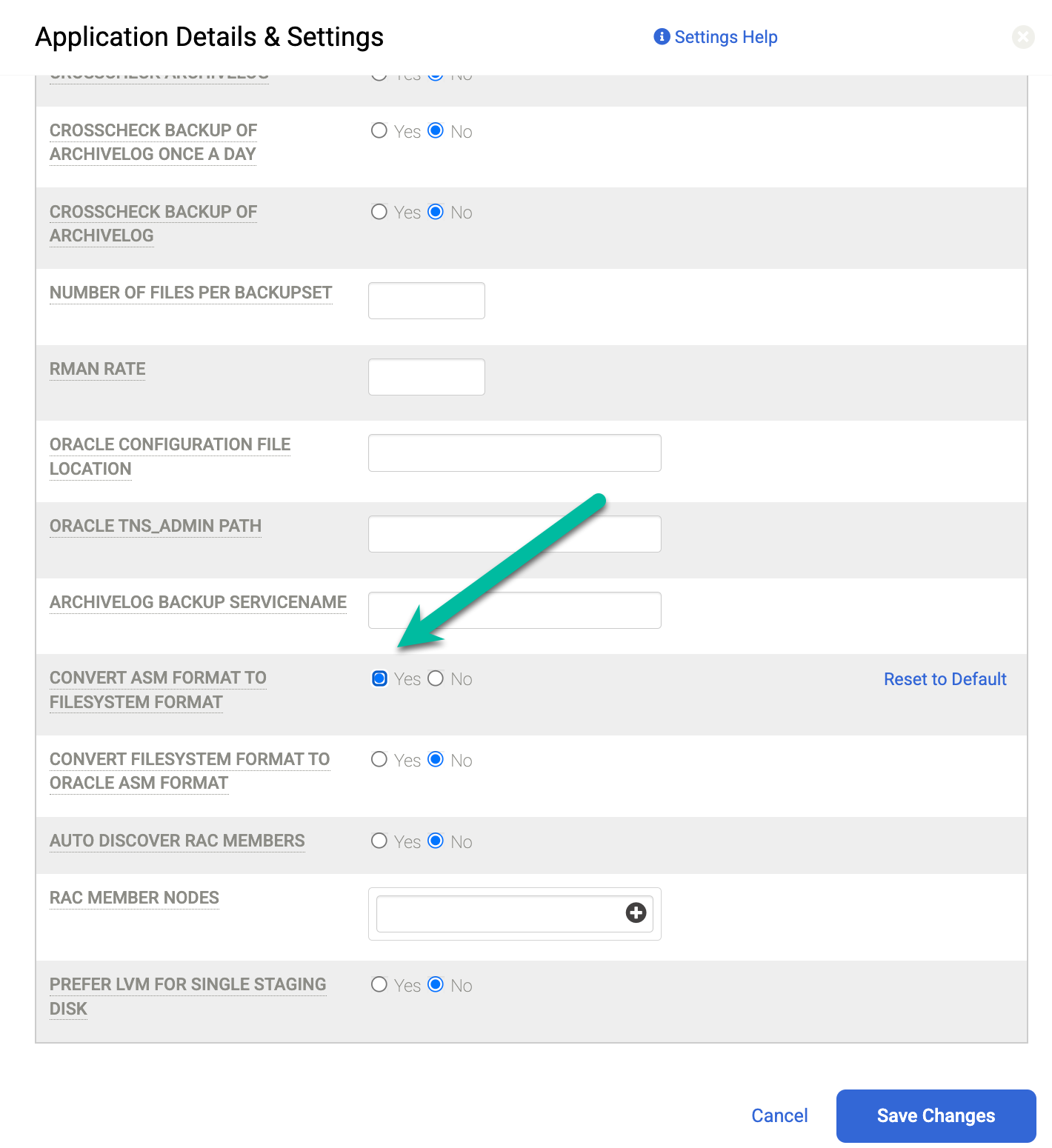
Il codice di errore 870 indica che "i backup ASM con ASM sui dischi di staging NFS non sono supportati". Se ricevi questo errore, non hai configurato l'impostazione corretta in Dettagli e impostazioni per l'istanza che vuoi proteggere. In questa configurazione errata, l'host utilizza NFS per il disco di staging, ma il database di origine viene eseguito su ASM.

Per risolvere il problema, imposta il campo Converti formato ASM in formato file system su Sì. Dopo aver modificato questa impostazione, esegui di nuovo il job di backup.
Il codice di errore 15 indica che il sistema Backup e RE "Non è stato possibile connettersi all'host di backup". Se ricevi questo errore, indica uno dei tre problemi seguenti:
- Il firewall tra l'appliance di backup/recupero e l'host su cui hai installato l'agente non consente la porta TCP 5106 (la porta di ascolto dell'agente).
- Non hai installato l'agente.
- L'agente non è in esecuzione.
Per risolvere il problema, riconfigura le impostazioni del firewall in base alle esigenze e assicurati che l'agente funzioni. Dopo aver risolto la causa principale, esegui il comando
service udsagent status. Il seguente esempio di output mostra che il servizio dell'agente Backup e RE è in esecuzione correttamente:[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
I messaggi di log dei backup possono aiutarti a diagnosticare i problemi. Puoi accedere ai log sull'host di origine in cui vengono eseguiti i job di backup. Per i backup del database Oracle, sono disponibili due file di log principali nella directory
/var/act/log:- UDSAgent.log:Google Cloud log dell'agente Backup e RE che registra le richieste API, le statistiche dei job in esecuzione e altri dettagli.
- SID_rman.log: log Oracle RMAN che registra tutti i comandi RMAN.
Considerazioni aggiuntive su Oracle
Quando implementi Backup and RE per i database Oracle, tieni presente le seguenti considerazioni quando esegui il deployment di Data Guard e RAC.
Considerazioni su Data Guard
Puoi eseguire il backup dei nodi Data Guard primari e di standby. Tuttavia, se scegli di proteggere i database solo dai nodi di standby, devi utilizzare l'autenticazione del database Oracle anziché l'autenticazione del sistema operativo quando esegui il backup del database.
Considerazioni relative a RAC
La soluzione Backup e RE non supporta il backup simultaneo da più nodi in un database RAC se il disco di staging è impostato sulla modalità NFS. Se il tuo sistema richiede il backup simultaneo da più nodi RAC, utilizza Blocco (iSCSI) come modalità disco di staging e impostala in base all'host.
Per un database Oracle RAC che utilizza ASM, devi inserire il file di controllo dello snapshot
nei dischi condivisi. Per verificare questa configurazione, connettiti a RMAN ed esegui il comando show all:
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
In un ambiente RAC, devi mappare il file di controllo dello snapshot a un gruppo di dischi ASM condiviso. Per assegnare il file al gruppo di dischi ASM, utilizza il comando
Configure Snapshot Controlfile Name:
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
Consigli
A seconda dei tuoi requisiti, potresti dover prendere decisioni in merito a determinate funzionalità che hanno un effetto sulla soluzione complessiva. Alcune decisioni possono influire sul prezzo, che a sua volta può influire sulle prestazioni, ad esempio la scelta di dischi permanenti standard (pd-standard) o dischi permanenti ad alte prestazioni (pd-ssd) per i pool di snapshot dell'appliance di backup/recupero.
In questa sezione condividiamo le nostre scelte consigliate per aiutarti a garantire prestazioni ottimali per la velocità effettiva del backup del database Oracle.
Seleziona il tipo di macchina e il tipo di Persistent Disk ottimali
Quando utilizzi un'appliance di backup/recupero con un'applicazione come un file system o un database, puoi misurare il rendimento in base alla velocità di trasferimento dei dati dell'istanza host tra le istanze Compute Engine.
- Le velocità dei dispositivi Persistent Disk di Compute Engine si basano su tre fattori: il tipo di macchina, la quantità totale di memoria collegata all'istanza e il numero di vCPU dell'istanza.
- Il numero di vCPU in un'istanza determina la velocità di rete allocata a un'istanza Compute Engine. La velocità varia da 1 Gbps per una vCPU condivisa fino a 16 Gbps per 8 o più vCPU.
- Combinando questi limiti, Google Cloud Backup and RE utilizza per impostazione predefinita un tipo di macchina e2-standard-16 per un'appliance di backup/recupero. Da questo punto di partenza, hai tre opzioni per l'allocazione del disco:
Choice |
Pool Disk |
Scritture sostenute massime |
Maximum Sustained Reads |
Minimo |
10 GB |
N/D |
N/D |
Standard |
4096 GB |
400 MiB/s |
1200 MiB/s |
SSD |
4096 GB |
1000 MiB/s |
1200 MiB/s |
Le istanze Compute Engine utilizzano fino al 60% della rete allocata per l'I/O ai dischi permanenti collegati e riservano il 40% per altri utilizzi. Per maggiori dettagli, vedi Altri fattori che influiscono sulle prestazioni.
Suggerimento: la selezione di un tipo di macchina e2-standard-16 e di un disco DP-SSD con un minimo di 4096 GB offre le prestazioni migliori per gli appliance di backup/recupero. Come seconda scelta, puoi selezionare un tipo di macchina n2-standard-16 per l'appliance di backup/recupero. Questa opzione offre ulteriori vantaggi in termini di prestazioni nell'intervallo del 10-20%, ma comporta costi aggiuntivi. Se questo corrisponde al tuo caso d'uso, contatta l'assistenza clienti Google Cloud per apportare questa modifica.
Ottimizzare gli snapshot
Per aumentare la produttività di un singolo dispositivo di backup/recupero, puoi eseguire job di snapshot simultanei da più origini. Ogni singolo job riduce la velocità. Tuttavia, con un numero sufficiente di job, puoi raggiungere il limite di scrittura sostenuta per i volumi di Persistent Disk nel pool di snapshot.
Quando utilizzi iSCSI per il disco di staging, puoi eseguire il backup di una singola istanza di grandi dimensioni in un'appliance di backup/recupero con una velocità di scrittura sostenuta di circa 300-330 MB/s. Nei nostri test, abbiamo verificato che ciò è vero per tutto, da 2 TB a 80 TB in uno snapshot, supponendo che tu configuri l'host di origine e l'appliance di backup/recupero a una dimensione ottimale e che si trovino nella stessa regione e zona.
Scegliere il disco di gestione temporanea corretto
Se hai bisogno di prestazioni e velocità effettiva significative, Direct NFS può aggiungere un vantaggio significativo rispetto a iSCSI come scelta del disco di staging da utilizzare per i backup del database Oracle. Direct NFS consolida il numero di connessioni TCP, il che migliora la scalabilità e le prestazioni di rete.
Quando abiliti Direct NFS per un database Oracle, configura una CPU di origine sufficiente (ad esempio 8 vCPU e 8 canali RMAN) e stabilisci un collegamento da 10 GB tra l'estensione regionale della Bare Metal Solution e Google Cloud, puoi eseguire il backup di un singolo database Oracle con una velocità effettiva maggiore, compresa tra 700 e 900+ MB/s. Anche le velocità di ripristino RMAN traggono vantaggio da Direct NFS, dove puoi vedere i livelli di velocità effettiva raggiungere l'intervallo di 850 MB/s e oltre.
Bilanciare costi e velocità effettiva
È inoltre importante sapere che tutti i dati di backup vengono archiviati in un formato compresso nel pool di snapshot dell'appliance di backup/recupero, per ridurre i costi. I sovraccarichi di prestazioni per questo vantaggio di compressione sono marginali. Tuttavia, per i dati criptati (TDE) o i set di dati fortemente compressi, è probabile che si verifichi un impatto misurabile, anche se marginale, sulle cifre di throughput.
Comprendere i fattori che influiscono sul rendimento della rete e dei server di backup
I seguenti elementi influiscono sull'I/O di rete tra Oracle su Bare Metal Solution e i server di backup in Google Cloud:
Memoria flash
Analogamente al Google Cloud disco permanente, gli array di archiviazione flash che forniscono lo spazio di archiviazione per i sistemi Bare Metal Solution aumentano le funzionalità di I/O in base alla quantità di spazio di archiviazione assegnata all'host. Più spazio di archiviazione allochi, migliore sarà l'I/O. Per risultati coerenti, ti consigliamo di eseguire il provisioning di almeno 8 TB di spazio di archiviazione flash.
Latenza di rete
Google Cloud I job di backup e RE sono sensibili alla latenza di rete tra gli host Bare Metal Solution e l'appliance di backup/recupero in Google Cloud. Piccoli aumenti della latenza possono comportare grandi variazioni dei tempi di backup e ripristino. Le diverse zone Compute Engine offrono latenze di rete diverse agli host di Bare Metal Solution. È consigliabile testare ogni zona per il posizionamento ottimale dell'appliance di backup/recupero.
Numero di processori utilizzati
I server Bare Metal Solution sono disponibili in diverse dimensioni. Ti consigliamo di scalare i canali RMAN in base alle CPU disponibili, con una velocità maggiore possibile dai sistemi più grandi.
Cloud Interconnect
L'interconnessione ibrida tra Bare Metal Solution e Google Cloud è disponibile in varie dimensioni, ad esempio 5 Gbps, 10 Gbps e 2x10 Gbps, con prestazioni complete dall'opzione dual 10 GB. È anche possibile configurare un collegamento di interconnessione dedicato che verrà utilizzato esclusivamente per le operazioni di backup e ripristino. Questa opzione è consigliata ai clienti che vogliono isolare il traffico di backup dal traffico di database o applicazioni che potrebbe attraversare lo stesso link oppure garantire la larghezza di banda completa quando le operazioni di backup e ripristino sono fondamentali per garantire il rispetto dell'obiettivo del punto di ripristino (RPO) e dell'obiettivo del tempo di ripristino (RTO).
Passaggi successivi
Ecco alcuni link e informazioni aggiuntive su Google Cloud Backup e RE che potrebbero esserti utili.
- Per ulteriori passaggi relativi alla configurazione di Google Cloud Backup e RE, consulta la documentazione del prodotto Backup e DR.
- Per visualizzare le dimostrazioni dell'installazione e delle funzionalità del prodotto, consulta la playlist di video di Backup e RE di Google Cloud.
- Per visualizzare le informazioni sulla compatibilità di Google Cloud Backup e RE, consulta la matrice di supporto: Backup e DR. È importante verificare di utilizzare versioni supportate di Linux e delle istanze del database Oracle.
- Per ulteriori passaggi relativi alla protezione del database Oracle, vedi Backup e RE per i database Oracle e Proteggere un database Oracle rilevato.
- Anche i file system come NFS, CIFS, ext3 ed ext4 possono essere protetti con Google Cloud Backup e RE Per visualizzare le opzioni disponibili, consulta Applicare un piano di backup per proteggere un file system.
- Per attivare gli avvisi per Google Cloud Backup e RE, consulta Configurare un avviso basato sui log e guarda il video Configurazione delle notifiche di avviso di Google Cloud Backup e DR.
- Per aprire una richiesta di assistenza, contatta l'assistenza clienti Google Cloud.