Lösungsleitfaden: Google Cloud Backup and DR für Oracle auf der Bare-Metal-Lösung
Übersicht
Um die Ausfallsicherheit Ihrer Oracle-Datenbanken in einer Bare-Metal-Lösungsumgebung zu gewährleisten, benötigen Sie eine klare Strategie für Datenbanksicherungen und Notfallwiederherstellung. Um Sie bei der Erfüllung dieser Anforderung zu unterstützen, hat das Solution Architect-Team beiGoogle Cloud Google Cloud umfassende Tests des Backup- und DR-Dienstes durchgeführt und die Ergebnisse in diesem Leitfaden zusammengefasst. Daher zeigen wir Ihnen die besten Möglichkeiten, Ihre Sicherungs- und Wiederherstellungsoptionen für Oracle-Datenbanken in einer Bare-Metal-Lösungsumgebung mit dem Backup- und DR-Dienst bereitzustellen, zu konfigurieren und zu optimieren. Wir stellen auch einige Leistungszahlen aus unseren Testergebnissen zur Verfügung, damit Sie einen Benchmark für den Vergleich mit Ihrer eigenen Umgebung haben. Diese Anleitung ist hilfreich, wenn Sie Sicherungsadministrator,Google Cloud -Administrator oder Oracle-DBA sind.
Hintergrund
Im Juni 2022 begann das Solution Architect-Team mit einem Proof-of-Concept (PoC) für Google Cloud Backup und DR für einen Enterprise-Kunden. Um die Erfolgskriterien zu erfüllen, mussten wir die Wiederherstellung der 50 TB großen Oracle-Datenbank unterstützen und die Datenbank innerhalb von 24 Stunden wiederherstellen.
Dieses Ziel stellte eine Reihe von Herausforderungen dar, aber die meisten am PoC Beteiligten waren der Meinung, dass wir dieses Ergebnis erreichen könnten und dass wir mit dem PoC fortfahren sollten. Wir waren der Meinung, dass das Risiko relativ gering war, da wir bereits Testdaten vom Backup and DR-Entwicklungsteam hatten, die zeigten, dass es möglich war, diese Ergebnisse zu erzielen. Wir haben die Ergebnisse des Tests auch mit dem Kunden geteilt, damit er sich bei der Durchführung des PoC wohlfühlt.
Während des PoC haben wir gelernt, wie mehrere Elemente in einer Bare-Metal-Lösungsumgebung erfolgreich zusammen konfiguriert werden – Oracle, Google Cloud Backup & DR, Speicher und Links zur regionalen Erweiterung. Wenn Sie die Best Practices, die wir gelernt haben, befolgen, können Sie Ihre eigenen Erfolge erzielen.
Die Ergebnisse in diesem Dokument sind nur als Orientierungshilfe zu verstehen. Wir möchten Ihnen einige Erkenntnisse aus unserer Arbeit mitgeben und Ihnen zeigen, worauf Sie sich konzentrieren sollten, was Sie vermeiden sollten und in welchen Bereichen Sie nachforschen sollten, wenn Sie nicht die gewünschte Leistung oder die gewünschten Ergebnisse erzielen. Wir hoffen, dass dieser Leitfaden Ihnen hilft, Vertrauen in die vorgeschlagenen Lösungen zu gewinnen und Ihre Anforderungen zu erfüllen.
Architektur
Abbildung 1 zeigt eine vereinfachte Ansicht der Infrastruktur, die Sie erstellen müssen, wenn Sie Backup and DR bereitstellen, um Oracle-Datenbanken zu schützen, die in einer Bare-Metal-Lösungsumgebung ausgeführt werden.
Abbildung 1: Komponenten für die Verwendung von Backup and DR mit Oracle-Datenbanken in einer Bare-Metal-Lösungsumgebung

Wie im Diagramm zu sehen ist, sind für diese Lösung die folgenden Komponenten erforderlich:
- Regionale Erweiterung der Bare Metal Solution: Damit können Sie Oracle-Datenbanken in einem Rechenzentrum eines Drittanbieters ausführen, das sich neben einem Google Cloud Rechenzentrum befindet, und Ihre vorhandenen lokalen Softwarelizenzen verwenden.
- Backup- und DR-Dienstprojekt: Ermöglicht es Ihnen, Ihre Sicherungs-/Wiederherstellungs-Appliance und Sicherungen von Bare-Metal-Lösung und Google Cloud -Arbeitslasten in Cloud Storage-Buckets zu hosten.
- Compute-Dienstprojekt: Hier können Sie Ihre Compute Engine-VMs ausführen.
- Backup and DR Service: Bietet die Backup and DR-Verwaltungskonsole, mit der Sie Ihre Sicherungen und Notfallwiederherstellung verwalten können.
- Hostprojekt: Ermöglicht das Erstellen regionaler Subnetze in einer freigegebenen VPC, über die die regionale Erweiterung der Bare-Metal-Lösung mit dem Backup and DR Service, der Sicherungs-/Wiederherstellungs-Appliance, Ihren Cloud Storage-Buckets und Ihren Compute Engine-VMs verbunden werden kann.
Google Cloud Backup und DR installieren
Für die Backup and DR-Lösung sind mindestens die folgenden zwei Hauptkomponenten erforderlich:
- Backup- und DR-Verwaltungskonsole: Eine HTML5-Benutzeroberfläche und ein API-Endpunkt, mit denen Sie Sicherungen in derGoogle Cloud -Konsole erstellen und verwalten können.
- Sicherungs-/Wiederherstellungs-Appliance: Dieses Gerät fungiert als Task-Worker beim Ausführen der Sicherungen sowie beim Mounten und Wiederherstellen von Aufgaben.
Google Cloud verwaltet die Backup- und DR-Verwaltungskonsole. Sie müssen die Verwaltungskonsole in einem Dienstersteller-Projekt (Google Cloud Verwaltungsseite) und die Sicherungs-/Wiederherstellungs-Appliance in einem Dienstnutzer-Projekt (Kundenseite) bereitstellen. Weitere Informationen zu Backup und DR finden Sie unter Backup und DR-Bereitstellung einrichten und planen. Die Definitionen von Dienstanbieter und Dienstnutzer finden Sie im Google Cloud-Glossar.
Hinweise
Bevor Sie den Google Cloud Backup and DR Service installieren, müssen Sie die folgenden Konfigurationsschritte ausführen:
- Aktivieren Sie eine Zugriffsverbindung für private Dienste. Sie müssen diese Verbindung herstellen, bevor Sie mit der Installation beginnen können. Auch wenn Sie bereits ein Subnetz für den Zugriff auf private Dienste konfiguriert haben, muss es mindestens ein
/23-Subnetz haben. Wenn Sie beispielsweise bereits ein/24-Subnetz für die Verbindung für den Zugriff auf private Dienste konfiguriert haben, empfehlen wir, ein/23-Subnetz hinzuzufügen. Noch besser ist es, wenn Sie ein/20-Subnetz hinzufügen, damit Sie später weitere Dienste hinzufügen können. - Konfigurieren Sie Cloud DNS so, dass es im VPC-Netzwerk verfügbar ist, in dem Sie die Sicherungs-/Wiederherstellungs-Appliance bereitstellen. So wird die korrekte Auflösung von googleapis.com (über private oder öffentliche Suche) sichergestellt.
- Konfigurieren Sie die Standardrouten und Firewallregeln des Netzwerks so, dass ausgehender Traffic an
*.googleapis.com(über öffentliche IP-Adressen) oderprivate.googleapis.com(199.36.153.8/30) über TCP-Port 443 oder ein expliziter Ausgang für0.0.0.0/0zugelassen wird. Auch hier müssen Sie die Routen und die Firewall im VPC-Netzwerk konfigurieren, in dem Sie Ihre Sicherungs-/Wiederherstellungs-Appliance installieren. Wir empfehlen außerdem, den privaten Google-Zugriff zu verwenden. Weitere Informationen finden Sie unter Privaten Google-Zugriff konfigurieren. - Aktivieren Sie die folgenden APIs in Ihrem Verbraucherprojekt:
- Compute Engine API
- Cloud Key Management Service (KMS) API
- Cloud Resource Manager API (für Host- und Dienstprojekt, falls verwendet)
- Identity and Access Management API
- Workflows API
- Cloud Logging API
- Wenn Sie Organisationsrichtlinien aktiviert haben, müssen Sie Folgendes konfigurieren:
constraints/cloudkms.allowedProtectionLevelsenthältSOFTWAREoderALL.
- Konfigurieren Sie die folgenden Firewallregeln:
- Eingehender Traffic von der Sicherungs-/Wiederherstellungs-Appliance in der Compute Engine-VPC zum Linux-Host (Agent) über den TCP-Port 5106.
- Wenn Sie einen blockbasierten Sicherungsdatenträger mit iSCSI verwenden, erfolgt der Egress vom Linux-Host (Agent) in der Bare-Metal-Lösung zur Sicherungs-/Wiederherstellungs-Appliance in der Compute Engine-VPC über den Port TCP-3260.
- Wenn Sie eine NFS- oder dNFS-basierte Sicherungsfestplatte verwenden, erfolgt der Egress vom Linux-Host (Agent) in der Bare-Metal-Lösung zur Sicherungs-/Wiederherstellungs-Appliance in der Compute Engine-VPC über die folgenden Ports:
- TCP/UDP-111 (rpcbind)
- TCP/UDP-756 (Status)
- TCP/UDP-2049 (nfs)
- TCP/UDP-4001 (mountd)
- TCP/UDP-4045 (nlockmgr)
- Konfigurieren Sie Google Cloud DNS, um Bare-Metal-Lösung-Hostnamen und ‑Domains aufzulösen, damit die Namensauflösung für Bare-Metal-Lösung-Server, VMs und Compute Engine-basierte Ressourcen wie den Backup and DR Service einheitlich ist.
Backup- und DR-Verwaltungskonsole installieren
- Aktivieren Sie die Backup and DR Service API, falls sie noch nicht aktiviert ist.
Rufen Sie in der Google Cloud Console über das Navigationsmenü den Bereich Vorgänge auf und wählen Sie Backup & DR aus:
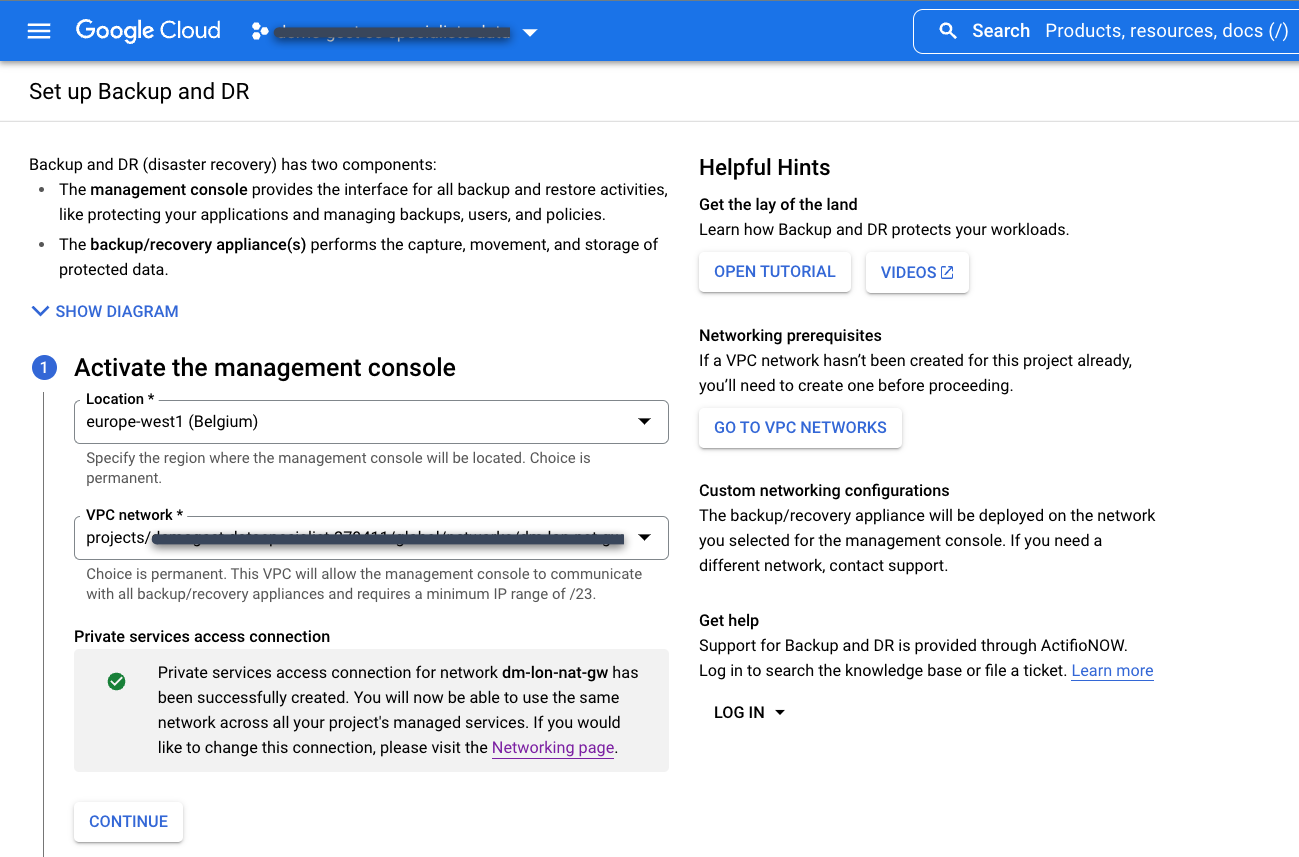
Wählen Sie Ihre vorhandene Verbindung für den Zugriff auf private Dienste aus, die Sie zuvor erstellt haben.
Wählen Sie den Standort für die Backup & DR-Verwaltungskonsole aus. Dies ist die Region, in der Sie die Benutzeroberfläche der Backup and DR-Verwaltungskonsole in einem Dienstproduzentenprojekt bereitstellen. Google Cloud ist Eigentümer und Administrator der Ressourcen der Verwaltungskonsole.
Wählen Sie das VPC-Netzwerk im Dienstnutzerprojekt aus, mit dem Sie eine Verbindung zum Backup and DR Service herstellen möchten. Dies ist in der Regel ein Projekt mit freigegebener VPC oder ein Hostprojekt.
Nachdem Sie bis zu einer Stunde gewartet haben, sollten Sie nach Abschluss der Bereitstellung den folgenden Bildschirm sehen.
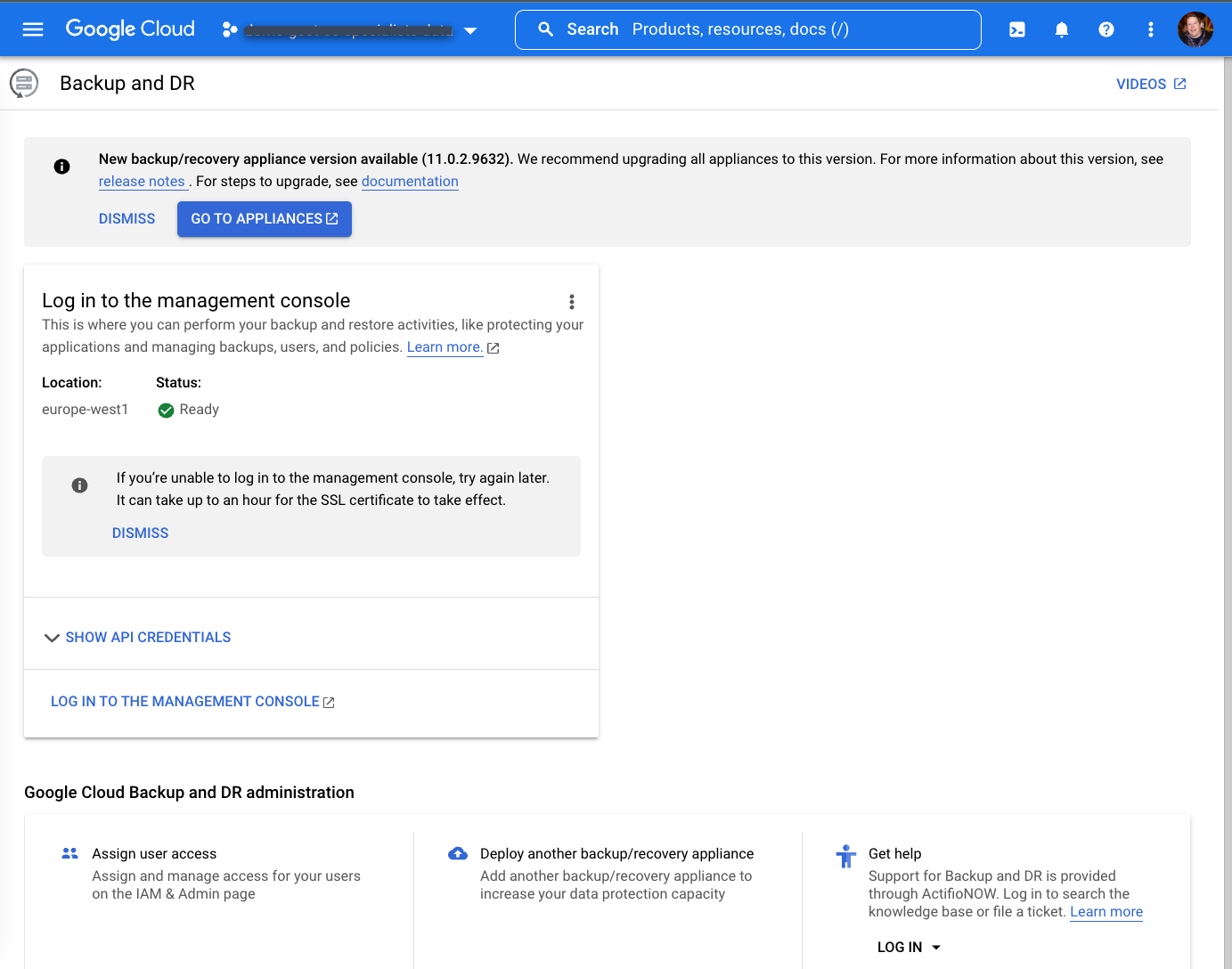
Sicherungs-/Wiederherstellungs-Appliance installieren
Klicken Sie auf der Seite Backup & DR auf In der Verwaltungskonsole anmelden:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Rufen Sie auf der Hauptseite der Backup and DR-Verwaltungskonsole die Seite Appliances auf:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Geben Sie den Namen der Sicherungs‑/Wiederherstellungs-Appliance ein. Google Cloud fügt automatisch zusätzliche Zufallszahlen am Ende des Namens hinzu, sobald die Bereitstellung beginnt.
Wählen Sie das Consumer-Projekt aus, in dem Sie die Sicherungs-/Wiederherstellungs-Appliance installieren möchten.
Wählen Sie Ihre bevorzugte Region, Zone und Ihr bevorzugtes Subnetzwerk aus.
Wählen Sie einen Speichertyp aus. Wir empfehlen, für PoCs Nichtflüchtiger Standardspeicher und für eine Produktionsumgebung Nichtflüchtiger SSD-Speicher auszuwählen.
Klicken Sie auf die Schaltfläche Installation starten. Es kann bis zu einer Stunde dauern, bis sowohl die Backup- und DR-Verwaltungskonsole als auch die erste Sicherungs-/Wiederherstellungs-Appliance bereitgestellt sind.
Nach Abschluss der Ersteinrichtung können Sie weitere Sicherungs-/Wiederherstellungsgeräte in anderen Regionen oder Zonen hinzufügen.
Google Cloud Backup und DR konfigurieren
In diesem Abschnitt erfahren Sie, wie Sie den Backup- und DR-Dienst konfigurieren und Ihre Arbeitslasten schützen.
Dienstkonto konfigurieren
Ab Version 11.0.2 (Dezember 2022-Version von Backup and DR) können Sie ein einzelnes Dienstkonto verwenden, um die Sicherungs-/Wiederherstellungs-Appliance auszuführen und auf Cloud Storage-Buckets zuzugreifen sowie Ihre Compute Engine-VMs zu schützen (nicht in diesem Dokument behandelt).
Dienstkontorollen
Google Cloud Backup and DR verwendet Google Cloud Identity and Access Management (IAM) für die Autorisierung und Authentifizierung von Nutzern und Dienstkonten. Sie können vordefinierte Rollen verwenden, um verschiedene Sicherungsfunktionen zu aktivieren. Die beiden wichtigsten sind:
- Cloud Storage-Operator für Sicherung und DR: Weisen Sie diese Rolle den Dienstkonten zu, die von einer Sicherungs-/Wiederherstellungs-Appliance verwendet werden, die eine Verbindung zu den Cloud Storage-Bucket herstellt. Mit der Rolle können Cloud Storage-Buckets für Compute Engine-Snapshot-Sicherungen erstellt und auf Buckets mit vorhandenen agentenbasierten Sicherungsdaten zugegriffen werden, um Arbeitslasten wiederherzustellen.
- Backup and DR Compute Engine Operator: Weisen Sie diese Rolle den Dienstkonten zu, die von einem Sicherungs-/Wiederherstellungsgerät verwendet werden, um Snapshots von nichtflüchtigem Speicher für Compute Engine-VMs zu erstellen. Mit dieser Rolle kann das Dienstkonto nicht nur Snapshots erstellen, sondern auch VMs im selben Quellprojekt oder in alternativen Projekten wiederherstellen.
Sie finden Ihr Dienstkonto, indem Sie die Compute Engine-VM, auf der Ihr Sicherungs-/Wiederherstellungsgerät ausgeführt wird, in Ihrem Consumer-/Dienstprojekt aufrufen und den im Abschnitt API und Identitätsverwaltung aufgeführten Dienstkontowert ansehen.
Um Ihren Sicherungs-/Wiederherstellungsgeräten die erforderlichen Berechtigungen zu erteilen, rufen Sie die Seite Identity and Access Management auf und weisen Sie dem Dienstkonto Ihres Sicherungs-/Wiederherstellungsgeräts die folgenden IAM-Rollen (Identity and Access Management) zu.
- Operator von Sicherungen und Notfallwiederherstellungen in Cloud Storage
- Compute Engine-Operator für Sicherungen und Notfallwiederherstellungen (optional)
Speicherpools konfigurieren
In Speicherpools werden Daten an physischen Speicherorten gespeichert. Sie sollten Persistent Disk für Ihre neuesten Daten (1–14 Tage) und Cloud Storage für die langfristige Aufbewahrung (Tage, Wochen, Monate und Jahre) verwenden.
Cloud Storage
Erstellen Sie einen regionalen oder multiregionalen Standard-Bucket an dem Speicherort, an dem Sie die Sicherungsdaten speichern möchten.
So erstellen Sie einen Cloud Storage-Bucket:
- Geben Sie auf der Seite Cloud Storage-Buckets einen Namen für den Bucket ein.
- Wählen Sie den Speicherort aus.
- Wählen Sie eine Speicherklasse aus: „Standard“, „Nearline“ oder „Coldline“.
- Wenn Sie Nearline- oder Coldline-Speicher auswählen, legen Sie den Modus Zugriffssteuerung auf Detailliert fest. Akzeptieren Sie für den Standardspeicher den Standardmodus für die Zugriffssteuerung Einheitlich.
Konfigurieren Sie schließlich keine zusätzlichen Datenschutzoptionen und klicken Sie auf Erstellen.
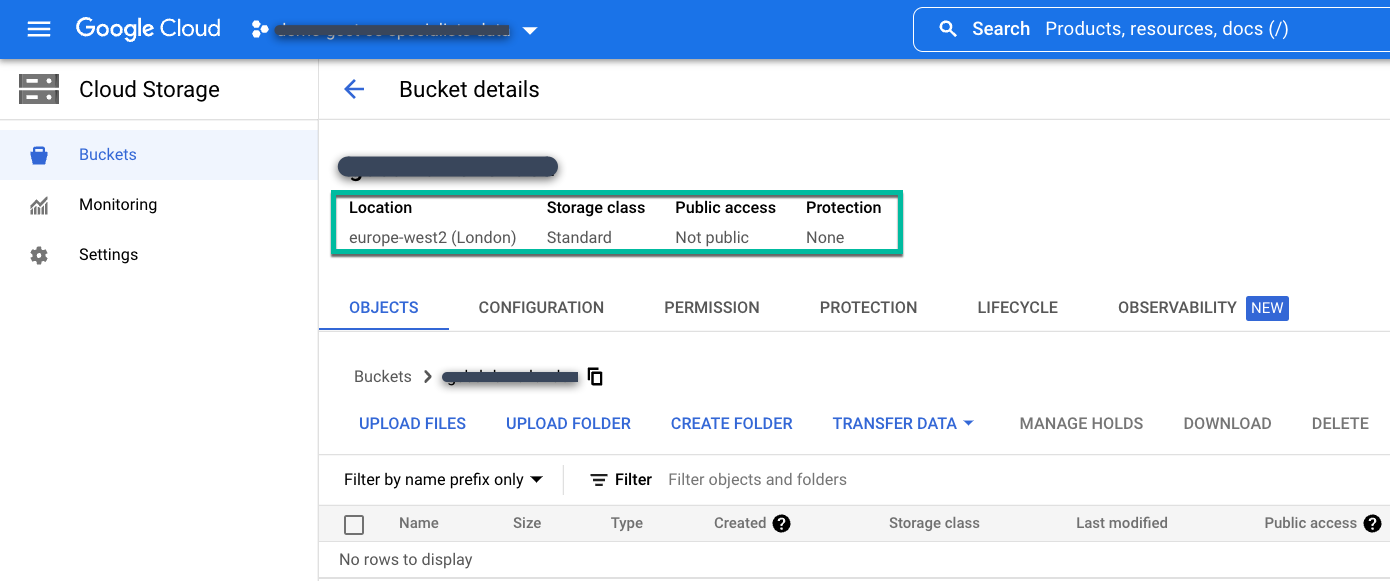
Fügen Sie diesen Bucket als Nächstes der Sicherungs-/Wiederherstellungs-Appliance hinzu. Rufen Sie die Backup- und DR-Verwaltungskonsole auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Wählen Sie den Menüpunkt Verwalten > Speicherpools aus.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
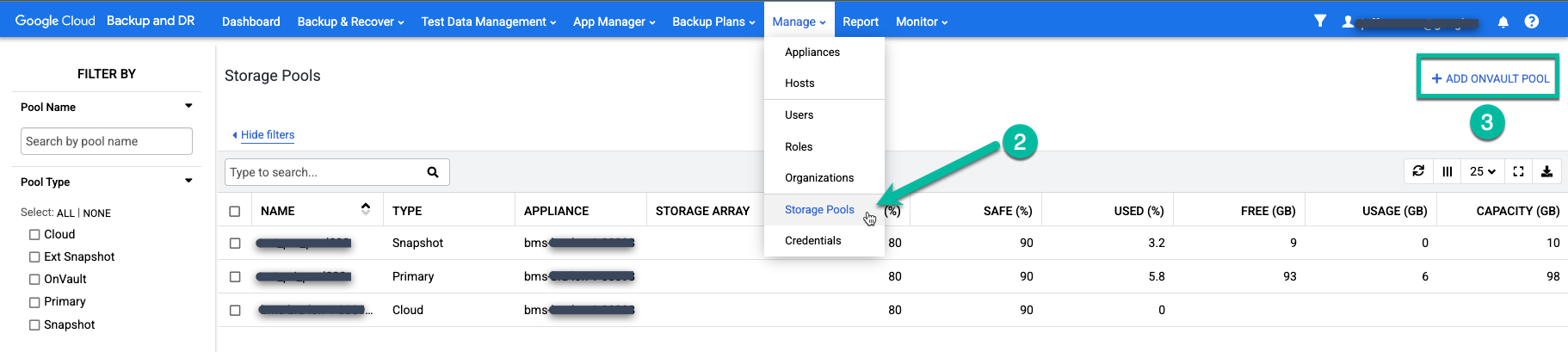
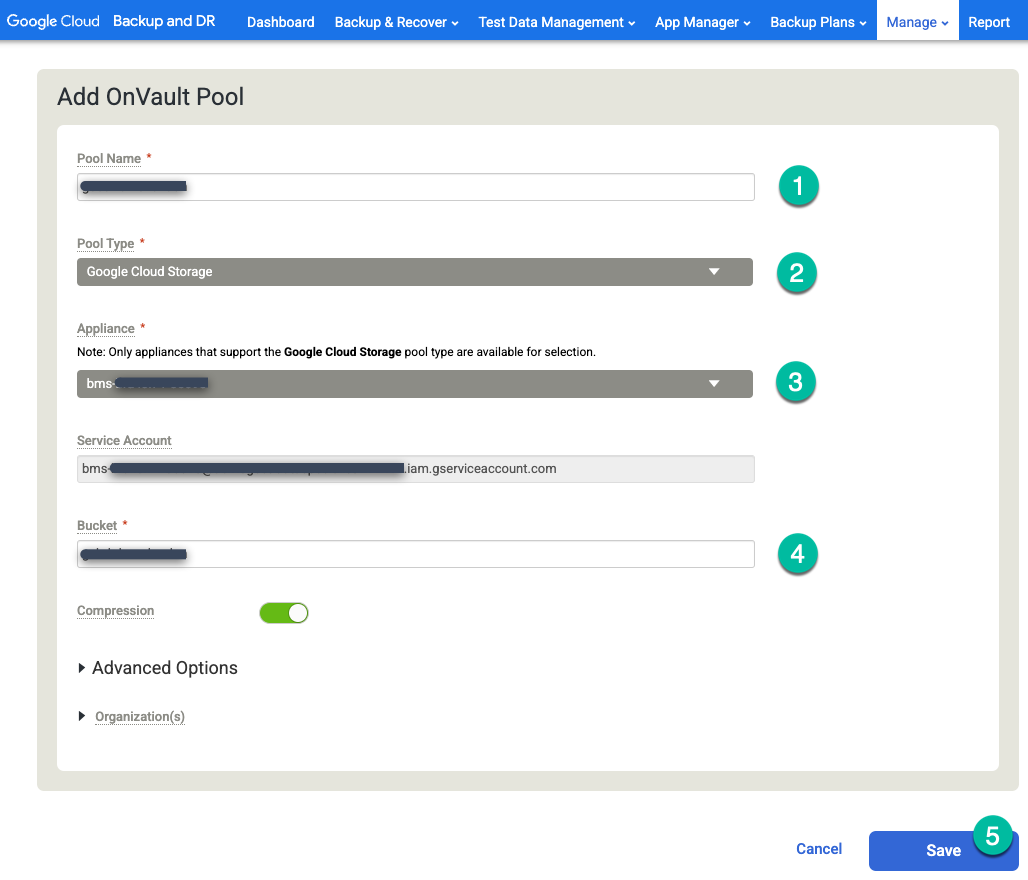
Klicken Sie ganz rechts auf die Option + OnVault-Pool hinzufügen.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- Geben Sie einen Namen für den Poolnamen ein.
- Wählen Sie Cloud Storage als Pool Type (Pooltyp) aus.
- Wählen Sie die Appliance aus, die Sie an den Cloud Storage-Bucket anhängen möchten.
- Geben Sie den Namen des Cloud Storage-Bucket ein.
Klicken Sie auf Speichern.
Persistent Disk-Snapshot-Pools
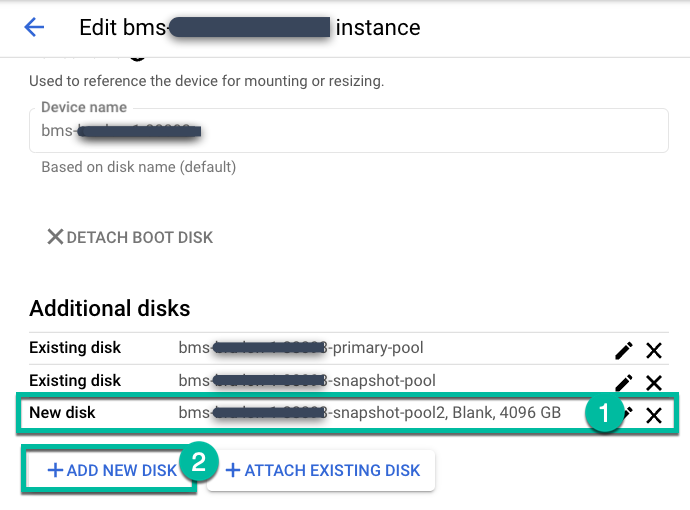
Wenn Sie die Appliance für Sicherung und Wiederherstellung mit Standard- oder SSD-Optionen bereitgestellt haben, ist der Snapshot-Pool für nichtflüchtige Speicher standardmäßig 4 TB groß. Wenn für Ihre Quelldatenbanken oder ‑dateisysteme ein größerer Pool erforderlich ist, können Sie die Einstellungen für Ihre bereitgestellte Sicherungs-/Wiederherstellungs-Appliance bearbeiten, einen neuen nichtflüchtigen Speicher hinzufügen und entweder einen neuen benutzerdefinierten Pool erstellen oder einen anderen Standardpool konfigurieren.
Rufen Sie die Seite Verwalten > Geräte auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Bearbeiten Sie die Sicherungsserver-Instanz und klicken Sie auf + Neues Laufwerk hinzufügen.
- Geben Sie einen Namen für das Laufwerk ein.
- Wählen Sie einen leeren Laufwerktyp aus.
- Wählen Sie je nach Bedarf „Standard“, „Ausgewogen“ oder „SSD“ aus.
- Geben Sie die benötigte Laufwerksgröße ein.
Klicken Sie auf Speichern.
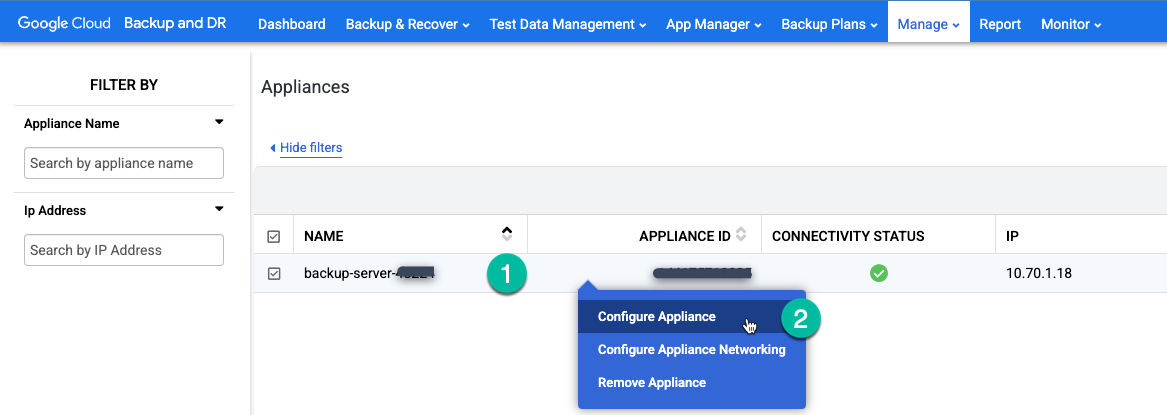
Rufen Sie in der Backup and DR-Verwaltungskonsole die Seite Verwalten > Appliances auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Klicken Sie mit der rechten Maustaste auf den Namen des Geräts und wählen Sie im Menü Gerät konfigurieren aus.
Sie können das Laufwerk entweder dem vorhandenen Snapshot-Pool hinzufügen (Erweiterung) oder einen neuen Pool erstellen. Mischen Sie jedoch nicht verschiedene Persistent Disk-Typen im selben Pool. Klicken Sie zum Maximieren rechts oben auf das Symbol für den gewünschten Pool.
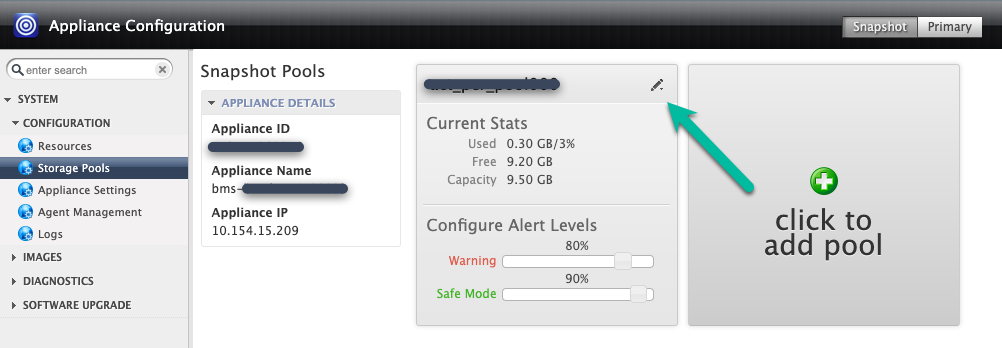
In diesem Beispiel erstellen Sie einen neuen Pool mit der Option Klicken Sie hier, um einen Pool hinzuzufügen. Klicken Sie auf diese Schaltfläche und warten Sie 20 Sekunden, bis die nächste Seite geöffnet wird.
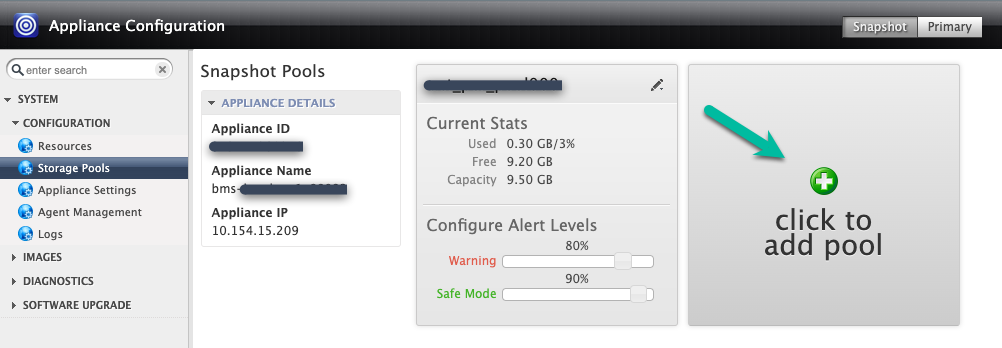
In diesem Schritt konfigurieren Sie den neuen Pool.
- Geben Sie dem Pool einen Namen und klicken Sie auf das grüne +-Symbol, um das Laufwerk dem Pool hinzuzufügen.
- Klicken Sie auf Senden.
- Bestätigen Sie, dass Sie fortfahren möchten, indem Sie PROCEED in Großbuchstaben eingeben, wenn Sie dazu aufgefordert werden.
Klicken Sie auf Bestätigen.
Ihr Pool wird jetzt mit der Persistent Disk erweitert oder erstellt.
Sicherungspläne konfigurieren
Mit Sicherungsplänen können Sie zwei wichtige Elemente für die Sicherung von Datenbanken, VMs oder Dateisystemen konfigurieren. Sicherungspläne enthalten Profile und Vorlagen.
- Mit Profilen können Sie festlegen, wann etwas gesichert werden soll und wie lange die Sicherungsdaten aufbewahrt werden sollen.
- Vorlagen bieten ein Konfigurationselement, mit dem Sie entscheiden können, welche Sicherungs-/Wiederherstellungs-Appliance und welcher Speicherpool (Persistent Disk, Cloud Storage usw.) für die Sicherungsaufgabe verwendet werden soll.
Profil erstellen
Rufen Sie in der Backup- und DR-Verwaltungskonsole die Seite Backup Plans > Profiles (Sicherungspläne > Profile) auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
Es werden bereits zwei Profile erstellt. Sie können ein Profil für Compute Engine-VM-Snapshots verwenden und das andere Profil bearbeiten und für Bare-Metal-Lösung-Sicherungen verwenden. Sie können mehrere Profile haben. Das ist nützlich, wenn Sie viele Datenbanken sichern, für die unterschiedliche Festplatten-Tiers für die Sicherung erforderlich sind. Sie können beispielsweise einen Pool für SSDs (höhere Leistung) und einen Pool für Standard-Persistent Disks (Standardleistung) erstellen. Für jedes Profil können Sie einen anderen Snapshot-Pool auswählen.
Klicken Sie mit der rechten Maustaste auf das Standardprofil mit dem Namen LocalProfile und wählen Sie Bearbeiten aus.
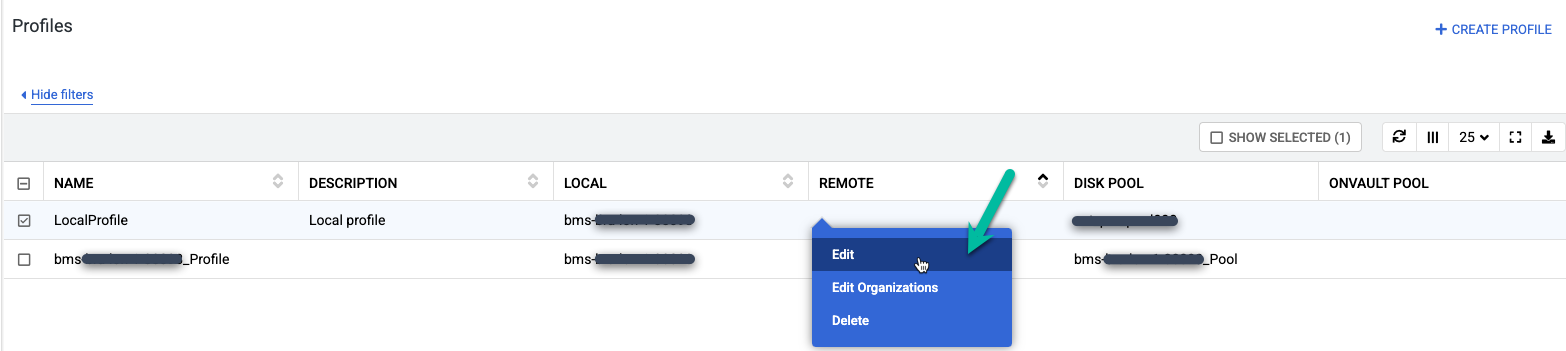
Nehmen Sie die folgenden Änderungen vor:
- Aktualisieren Sie die Einstellungen für Profile mit einem aussagekräftigeren Profilnamen und einer aussagekräftigeren Beschreibung. Sie können die zu verwendende Festplattenstufe, den Speicherort der Cloud Storage-Bucket oder andere Informationen angeben, die den Zweck dieses Profils erläutern.
- Ändern Sie den Snapshot-Pool in den erweiterten oder neuen Pool, den Sie zuvor erstellt haben.
- Wählen Sie für dieses Profil einen OnVault-Pool (Cloud Storage-Bucket) aus.
Klicken Sie auf Profil speichern.
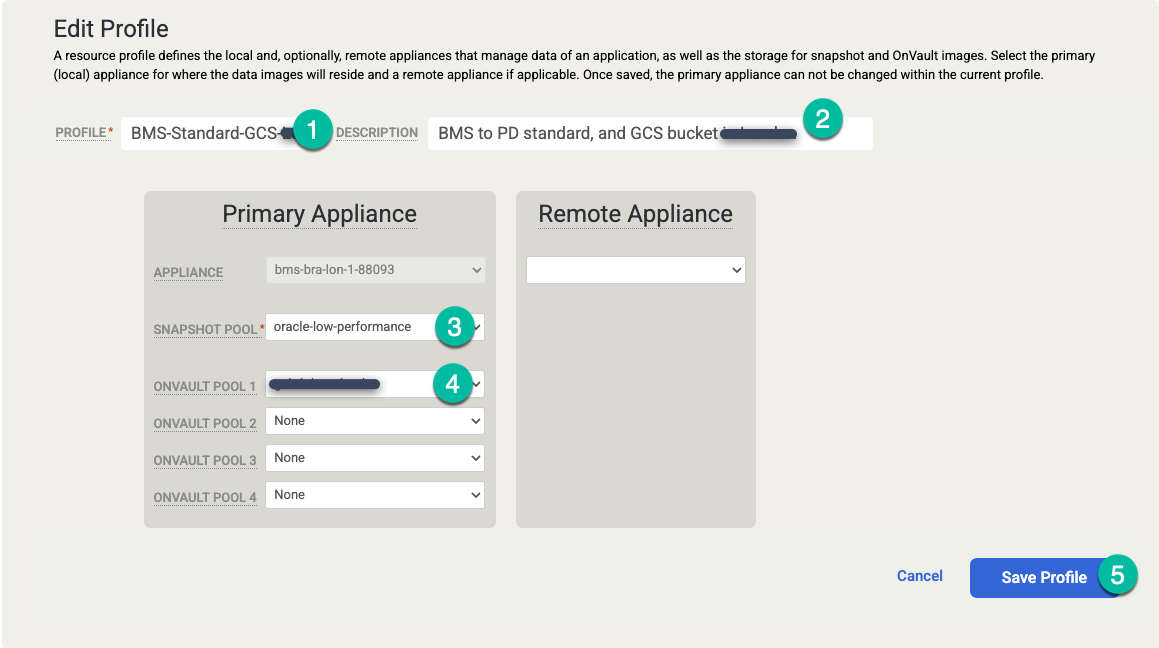
Vorlage erstellen
Rufen Sie in der Konsole für das Sicherungs‑ und Notfallwiederherstellungsmanagement das Menü Sicherungspläne > Vorlagen auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
Klicken Sie auf + Vorlage erstellen.
- Geben Sie einen Namen für die Vorlage ein.
- Wählen Sie für Überschreibungen von Richtlinieneinstellungen zulassen die Option Ja aus.
- Fügen Sie eine Beschreibung für diese Vorlage hinzu.
Klicken Sie auf Vorlage speichern.
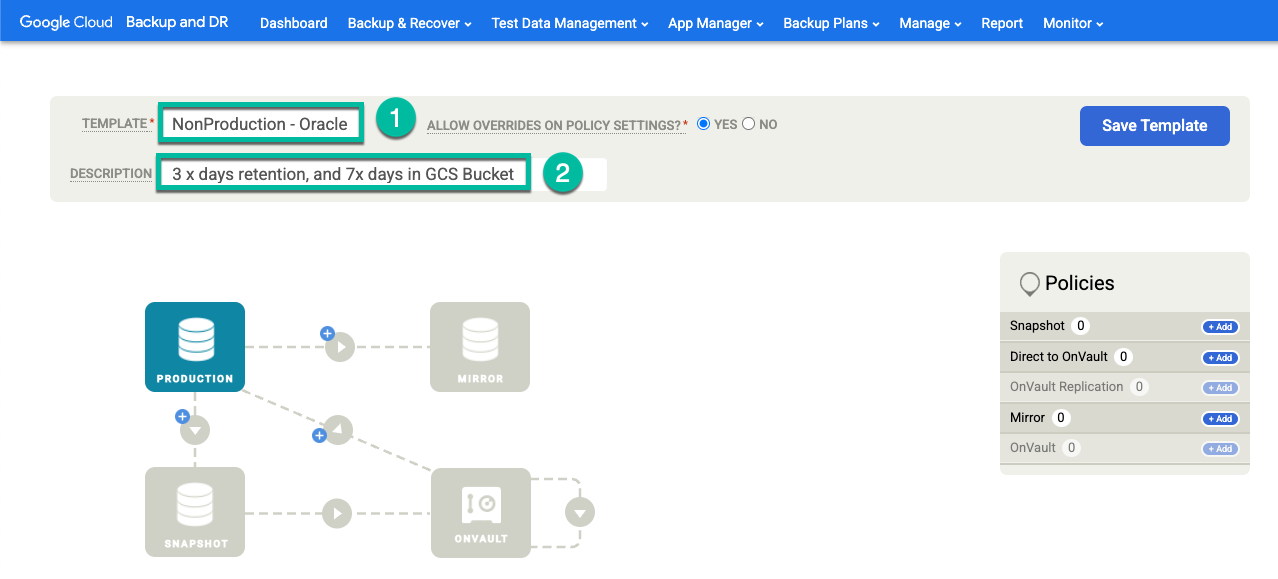
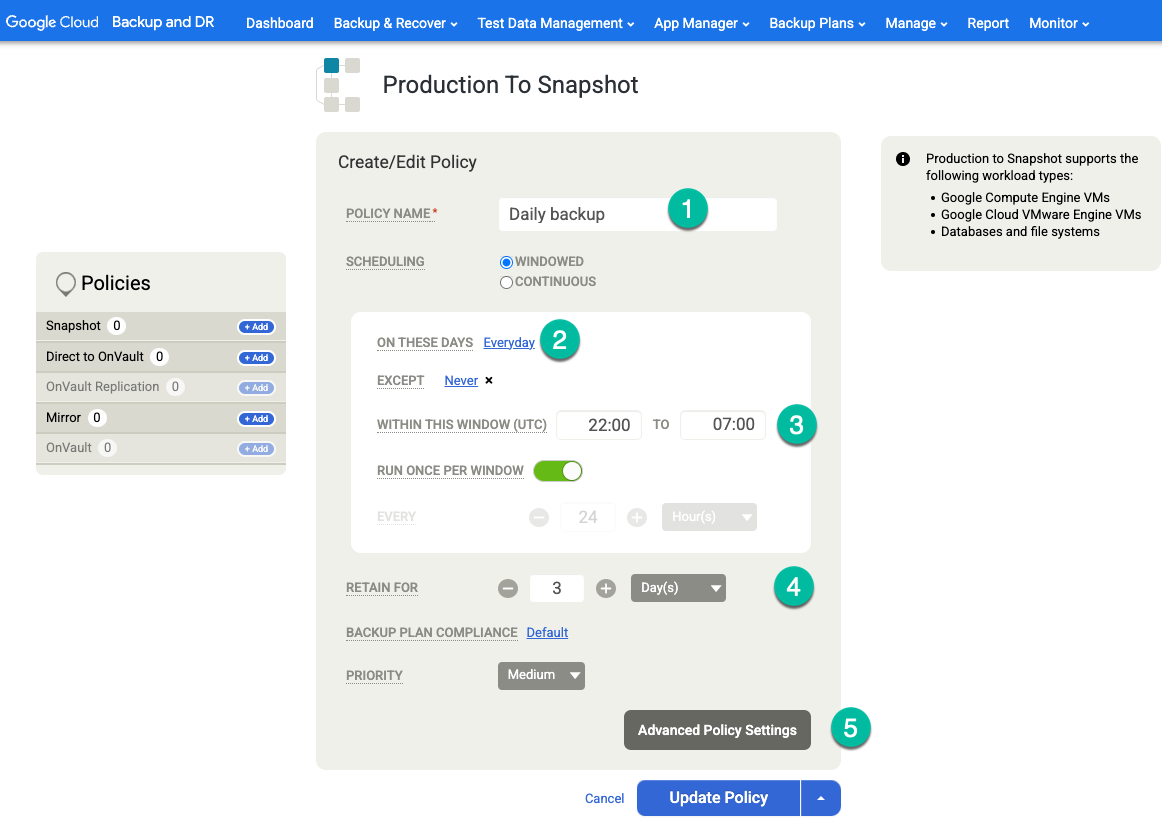
Konfigurieren Sie in Ihrer Vorlage Folgendes:
- Klicken Sie rechts im Bereich Richtlinien auf + Hinzufügen.
- Geben Sie einen Richtliniennamen an.
- Klicken Sie das Kästchen für die Tage an, an denen die Richtlinie ausgeführt werden soll, oder lassen Sie die Standardeinstellung Täglich beibehalten.
- Bearbeiten Sie das Zeitfenster für die Jobs, die in diesem Zeitraum ausgeführt werden sollen.
- Wählen Sie eine Aufbewahrungsdauer aus.
Klicken Sie auf Erweiterte Richtlinieneinstellungen.
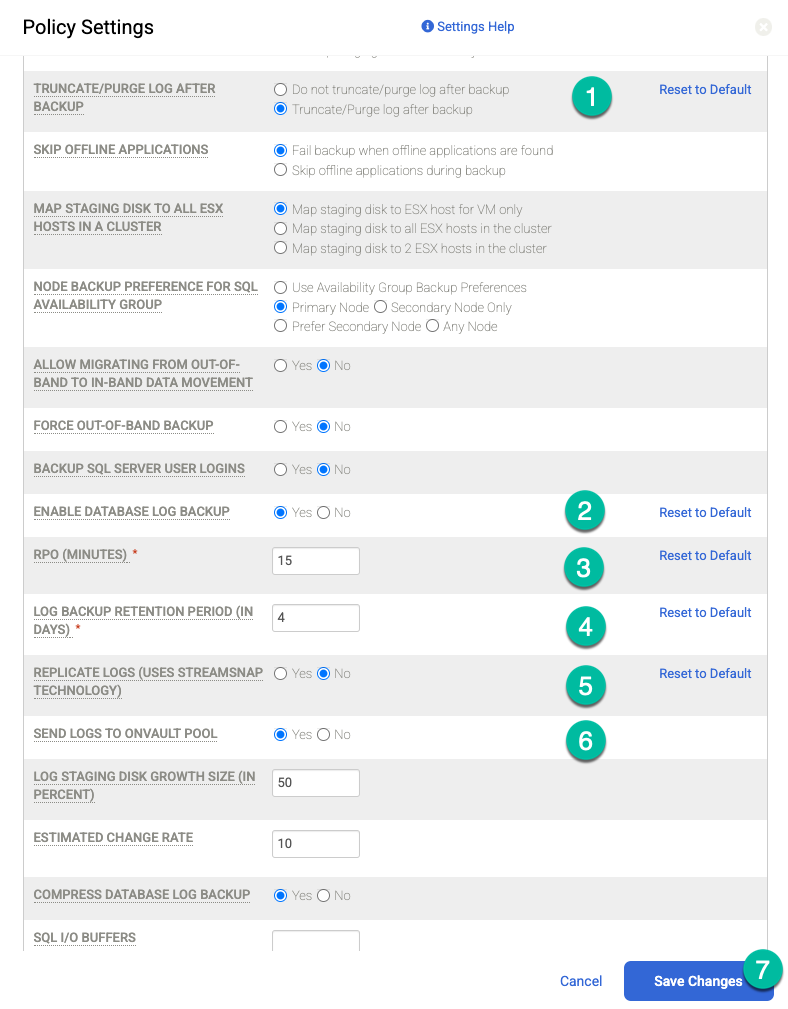
Wenn Sie Archivlogsicherungen in regelmäßigen Abständen (z. B. alle 15 Minuten) durchführen und die Archivlogs in Cloud Storage replizieren möchten, müssen Sie die folgenden Richtlinieneinstellungen aktivieren:
- Legen Sie Log nach Sicherung kürzen/löschen auf Kürzen fest, wenn Sie das möchten.
- Setzen Sie Enable Database Log Backup (Datenbank-Log-Sicherung aktivieren) bei Bedarf auf Yes (Ja).
- Legen Sie RPO (Minutes) auf das gewünschte Sicherungsintervall für Archivprotokolle fest.
- Legen Sie Zeitraum für die Aufbewahrung von Logsicherungen (in Tagen) auf den gewünschten Aufbewahrungszeitraum fest.
- Setzen Sie Replicate Logs (Uses Streamsnap Technology) (Logs replizieren (Streamsnap-Technologie wird verwendet)) auf No (Nein).
- Setzen Sie Logs an OnVault-Pool senden auf Ja, wenn Sie Logs an Ihren Cloud Storage-Bucket senden möchten. Wählen Sie andernfalls Nein aus.
Klicken Sie auf Änderungen speichern.
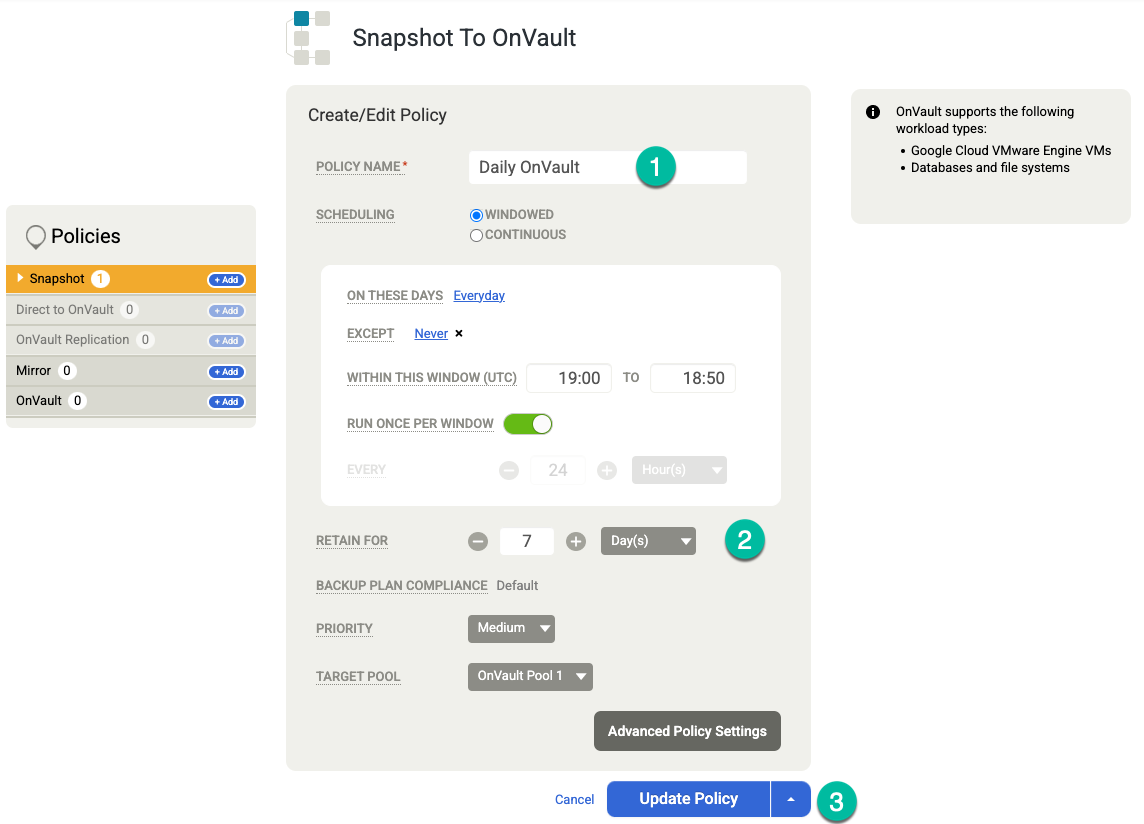
Klicken Sie auf Richtlinie aktualisieren, um die Änderungen zu speichern.
Führen Sie für OnVault auf der rechten Seite die folgenden Aktionen aus:
- Klicken Sie auf Hinzufügen.
- Geben Sie den Richtliniennamen ein.
- Legen Sie die Aufbewahrungsdauer in Tagen, Wochen, Monaten oder Jahren fest.
Klicken Sie auf Richtlinie aktualisieren.
Optional: Wenn Sie weitere Aufbewahrungsoptionen hinzufügen möchten, erstellen Sie zusätzliche Richtlinien für die wöchentliche, monatliche und jährliche Aufbewahrung. So fügen Sie eine weitere Aufbewahrungsrichtlinie hinzu:
- Klicken Sie rechts neben OnVault auf +Add (+ Hinzufügen).
- Geben Sie einen Richtliniennamen ein.
- Ändern Sie den Wert für An diesen Tagen in den Tag, an dem dieser Job ausgelöst werden soll.
- Legen Sie die Aufbewahrungsdauer in Tagen, Wochen, Monaten oder Jahren fest.
Klicken Sie auf Richtlinie aktualisieren.
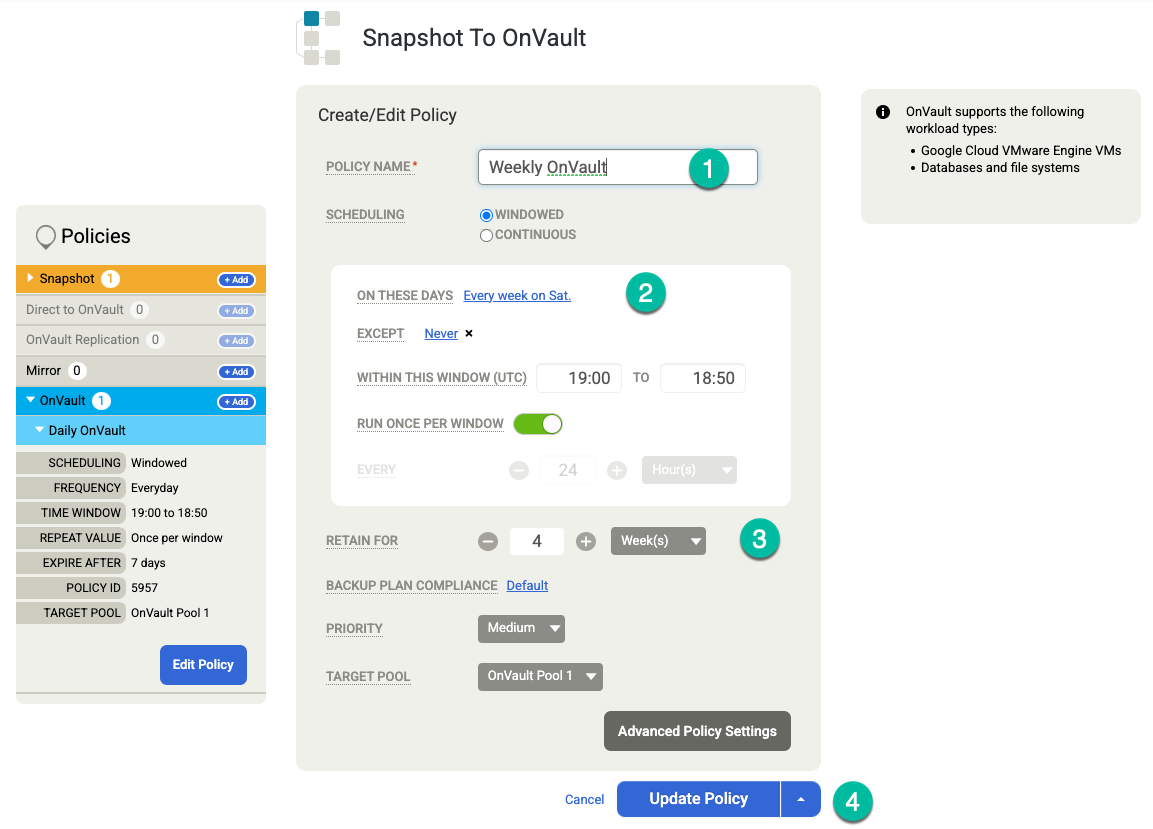
Klicken Sie auf Vorlage speichern. Im folgenden Beispiel sehen Sie eine Snapshot-Richtlinie, die Sicherungen für 3 Tage im Tier „Nichtflüchtiger Speicher“, für 7 Tage für OnVault-Jobs und insgesamt für 4 Wochen aufbewahrt. Die wöchentliche Sicherung wird samstags nachts ausgeführt.
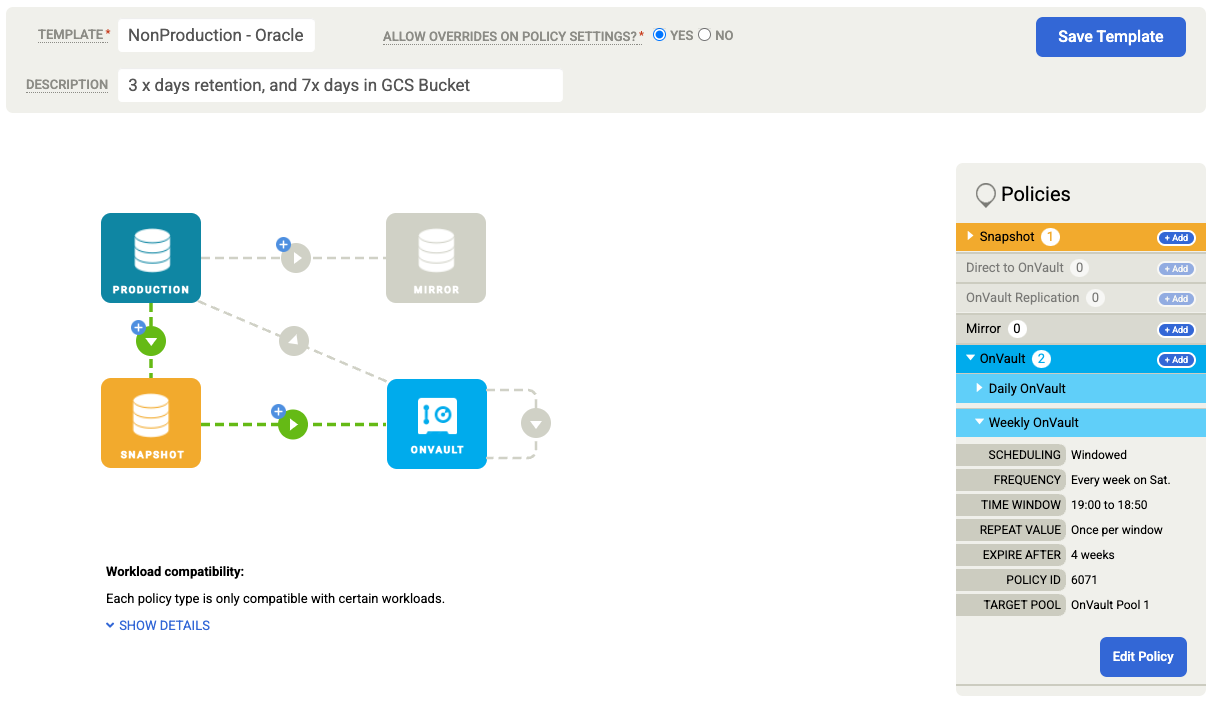
Oracle-Datenbank sichern
Die Google Cloud Backup and DR-Architektur bietet anwendungskonsistente, inkrementelle Oracle-Sicherungen für Google Cloudsowie sofortige Wiederherstellung und Klonen für Oracle-Datenbanken mit mehreren Terabyte.
Google Cloud Backup und DR verwendet die folgenden Oracle-APIs:
- RMAN Image Copy API: Das Wiederherstellen einer Image-Kopie einer Datendatei ist viel schneller, da die physische Struktur der Datendatei bereits vorhanden ist. Mit der RMAN-Anweisung (Recovery Manager) BACKUP AS COPY werden Image-Kopien für alle Datendateien der gesamten Datenbank erstellt und das Datendateiformat beibehalten.
- ASM- und CRS-API: Mit der ASM- (Automatic Storage Management) und CRS-API (Cluster Ready Services) können Sie die ASM-Sicherungslaufwerksgruppe verwalten.
- RMAN Archive Log Backup API: Mit dieser API werden Archivprotokolle generiert, auf einer Staging-Festplatte gesichert und aus dem Produktionsarchivspeicherort gelöscht.
Oracle-Hosts konfigurieren
Die Schritte zum Einrichten Ihrer Oracle-Hosts umfassen das Installieren des Agents, das Hinzufügen der Hosts zu Backup & DR, das Konfigurieren der Hosts und das Ermitteln der Oracle-Datenbanken. Sobald alles eingerichtet ist, können Sie Ihre Oracle-Datenbanken mit Backup und DR sichern.
Sicherungs-Agent installieren
Die Installation des Backup and DR-Agents ist relativ einfach. Sie müssen den Agent nur beim ersten Verwenden des Hosts installieren. Nachfolgende Upgrades können dann über die Backup and DR-Benutzeroberfläche in der Google Cloud -Konsole durchgeführt werden. Sie müssen als root-Nutzer angemeldet sein oder eine sudo-authentifizierte Sitzung verwenden, um einen Agent zu installieren. Sie müssen den Host nicht neu starten, um die Installation abzuschließen.
Laden Sie den Sicherungsagenten entweder über die Benutzeroberfläche oder über die Seite Verwalten > Appliances herunter.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Klicken Sie mit der rechten Maustaste auf den Namen der Sicherungs‑/Wiederherstellungs-Appliance und wählen Sie Appliance konfigurieren aus. Ein neues Browserfenster wird geöffnet.
Klicken Sie auf das Symbol Linux 64 Bit, um den Sicherungsagenten auf den Computer herunterzuladen, auf dem Ihre Browsersitzung ausgeführt wird. Verwenden Sie scp (Secure Copy), um die heruntergeladene Agent-Datei zur Installation auf die Oracle-Hosts zu verschieben.
Alternativ können Sie den Sicherungsagenten in einem Cloud Storage-Bucket speichern, Downloads aktivieren und
wget- odercurl-Befehle verwenden, um den Agenten direkt auf Ihre Linux-Hosts herunterzuladen.curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
Verwenden Sie den Befehl
rpm -ivh, um den Sicherungs-Agent zu installieren.Es ist sehr wichtig, dass Sie den automatisch generierten geheimen Schlüssel kopieren. Fügen Sie den geheimen Schlüssel über die Backup and DR-Verwaltungskonsole den Hostmetadaten hinzu.
Die Ausgabe dieses Befehls sieht in etwa so aus:
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
Wenn Sie den Befehl
iptablesverwenden, öffnen Sie die Ports für die Firewall des Sicherungs-Agents (TCP 5106) und die Oracle-Dienste (TCP 1521):sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
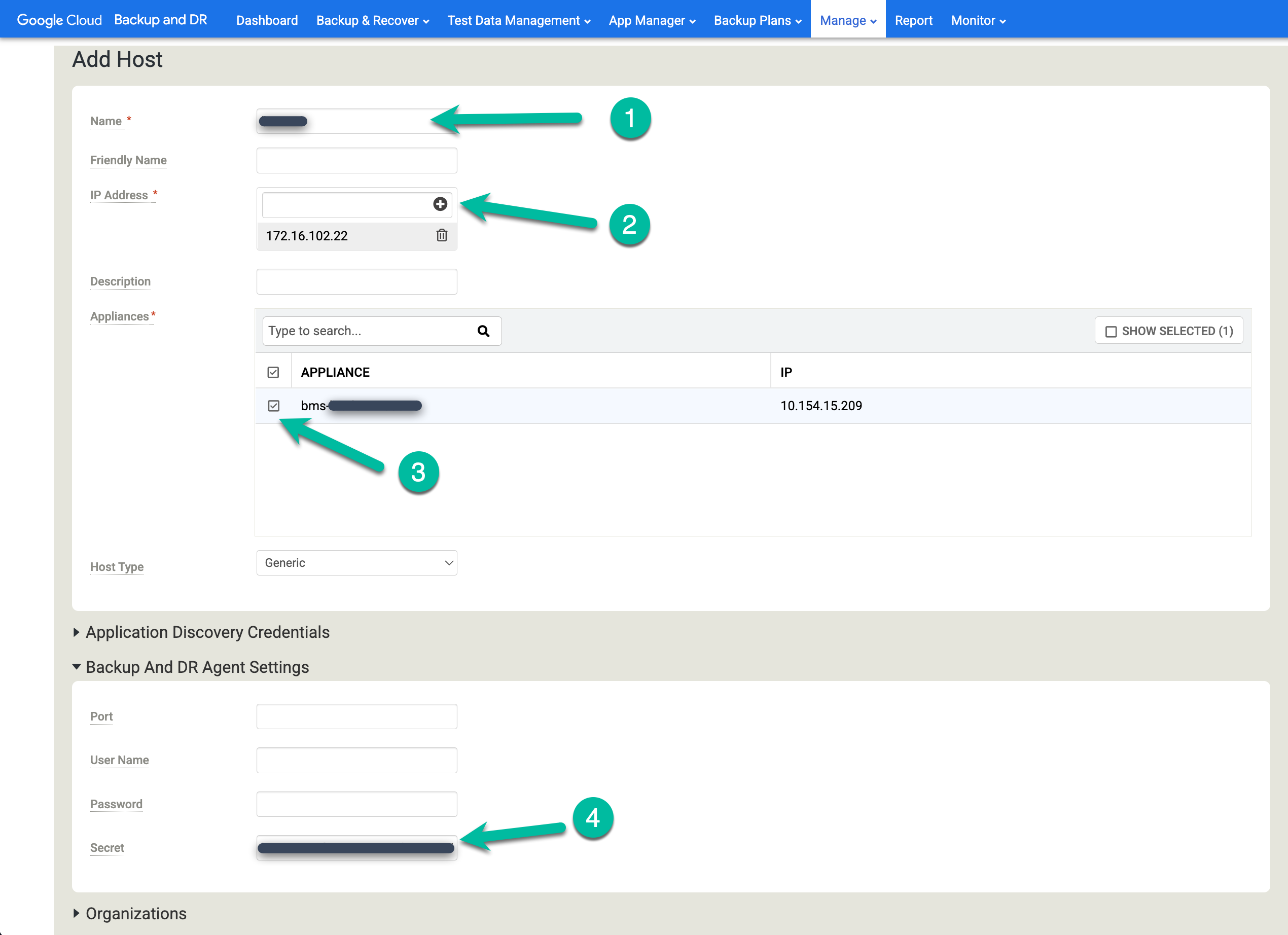
Hosts zu Backup und DR hinzufügen
Rufen Sie in der Backup & DR-Verwaltungskonsole Verwalten > Hosts auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
- Klicken Sie auf + Host hinzufügen.
- Fügen Sie den Hostnamen hinzu.
- Fügen Sie eine IP-Adresse für den Host hinzu und klicken Sie auf die Schaltfläche +, um die Konfiguration zu bestätigen.
- Klicken Sie auf das Gerät bzw. die Geräte, dem/denen Sie den Host hinzufügen möchten.
- Fügen Sie den geheimen Schlüssel ein. Sie müssen diese Aufgabe innerhalb von zwei Stunden nach der Installation des Sicherungs-Agents und der Generierung des geheimen Schlüssels ausführen.
Klicken Sie auf Hinzufügen, um den Host zu speichern.
Wenn Sie eine Fehlermeldung oder die Meldung Teilerfolg erhalten, versuchen Sie es mit den folgenden Problemumgehungen:
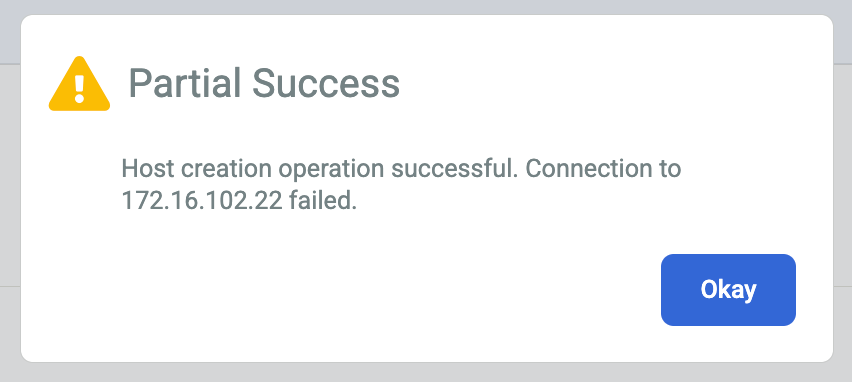
Der geheime Verschlüsselungsschlüssel des Sicherungs-Agents ist möglicherweise abgelaufen. Wenn Sie den geheimen Schlüssel nicht innerhalb von zwei Stunden nach der Erstellung zum Host hinzugefügt haben. Sie können einen neuen geheimen Schlüssel auf dem Linux-Host mit der folgenden Befehlszeilensyntax generieren:
/opt/act/bin/udsagent secret --reset --restart
Die Firewall, die die Kommunikation zwischen der Sicherungs-/Wiederherstellungs-Appliance und dem auf dem Host installierten Agenten ermöglicht, ist möglicherweise nicht richtig konfiguriert. Folgen Sie der Anleitung, um die Ports für die Firewall des Sicherungs-Agents und die Oracle-Dienste zu öffnen.
Die NTP-Konfiguration (Network Time Protocol) für Ihre Linux-Hosts ist möglicherweise falsch konfiguriert. Prüfen Sie, ob Ihre NTP-Einstellungen korrekt sind.
Wenn Sie das zugrunde liegende Problem beheben, sollte sich der Zertifikatsstatus von Nicht zutreffend in Gültig ändern.

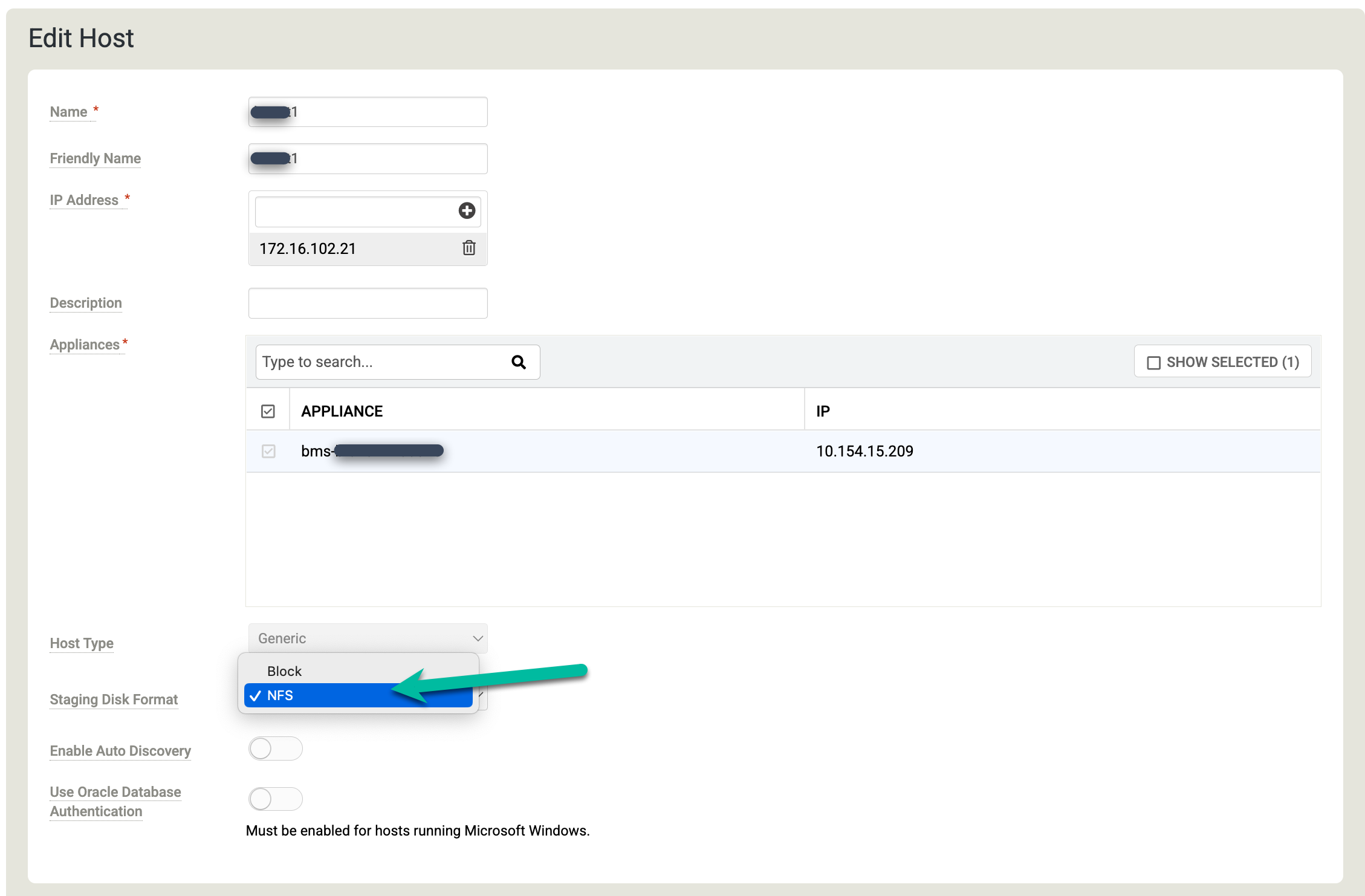
Hosts konfigurieren
Rufen Sie in der Backup and DR-Verwaltungskonsole Verwalten > Hosts auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
Klicken Sie mit der rechten Maustaste auf den Linux-Host, auf dem Sie Ihre Oracle-Datenbanken sichern möchten, und wählen Sie Bearbeiten aus.
Klicken Sie auf Staging Disk Format (Format der Staging-Festplatte) und wählen Sie NFS aus.
Scrollen Sie nach unten zum Abschnitt Gefundene Anwendungen und klicken Sie auf Anwendungen erkennen, um den Erkennungsprozess zwischen Appliance und Agent zu starten.
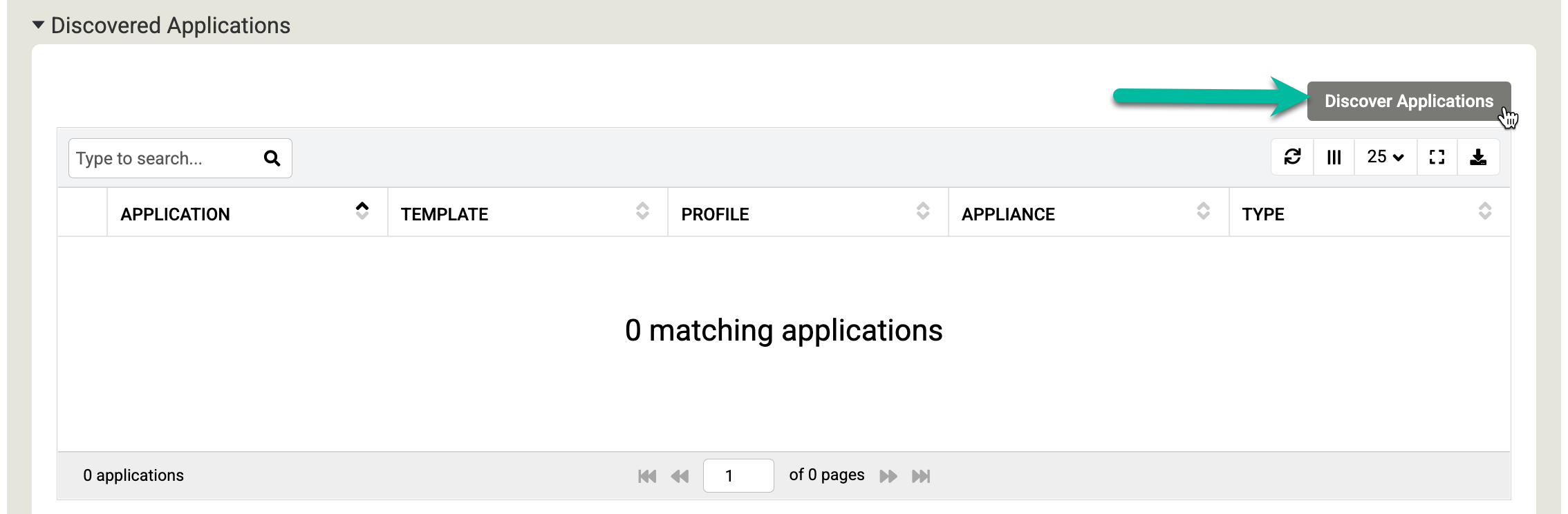
Klicken Sie auf Entdecken, um den Vorgang zu starten. Die Suche kann bis zu 5 Minuten dauern. Nach Abschluss des Vorgangs werden die erkannten Dateisysteme und Oracle-Datenbanken im Anwendungsfenster angezeigt.
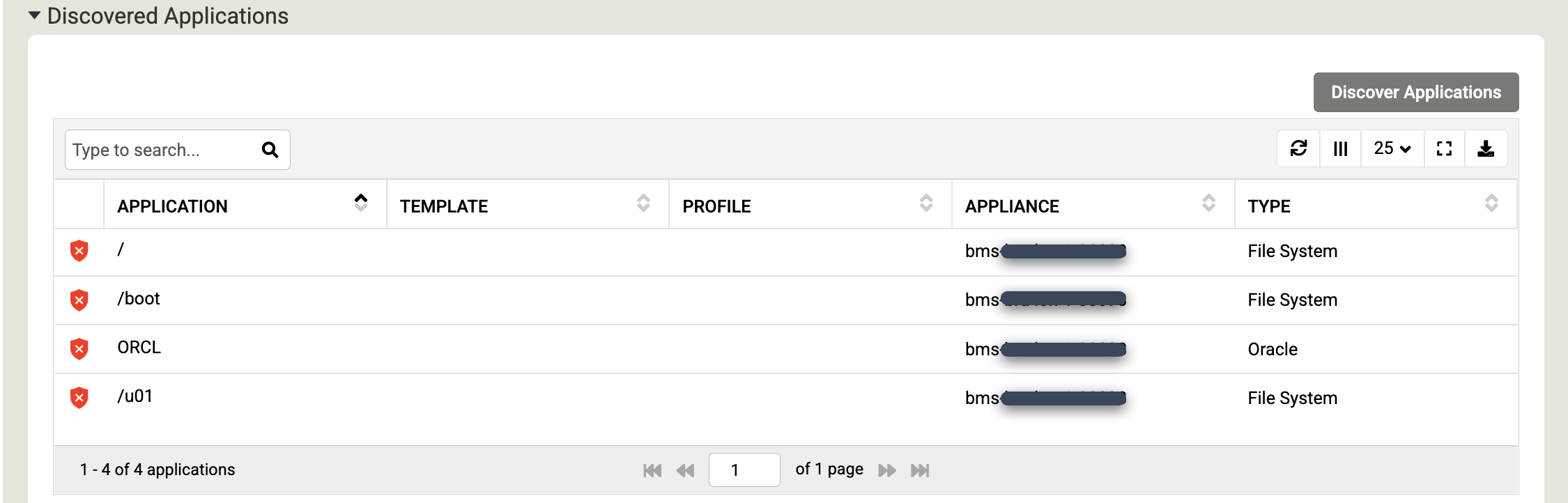
Klicken Sie auf Speichern, um die Änderungen an Ihren Hosts zu übernehmen.
Linux-Host vorbereiten
Wenn Sie iSCSI- oder NFS-Dienstprogramm-Pakete auf Ihrem Linux-basierten Host installieren, können Sie eine Staging-Festplatte einem Gerät zuordnen, auf das die Sicherungsdaten geschrieben werden. Verwenden Sie die folgenden Befehle, um iSCSI- und NFS-Dienstprogramme zu installieren. Sie können entweder eine oder beide Gruppen von Dienstprogrammen verwenden. Mit diesem Schritt wird jedoch sichergestellt, dass Sie das haben, was Sie benötigen, wenn Sie es benötigen.
Führen Sie den folgenden Befehl aus, um die iSCSI-Dienstprogramme zu installieren:
sudo yum install -y iscsi-initiator-utils
Führen Sie den folgenden Befehl aus, um die NFS-Dienstprogramme zu installieren:
sudo yum install -y nfs-utils
Oracle-Datenbank vorbereiten
In diesem Leitfaden wird davon ausgegangen, dass Sie bereits eine Oracle-Instanz und -Datenbank eingerichtet und konfiguriert haben. Google Cloud Backup and DR unterstützt den Schutz von Datenbanken, die in Dateisystemen, ASM, Real Application Clusters (RAC) und vielen anderen Konfigurationen ausgeführt werden. Weitere Informationen finden Sie unter Sicherung und Notfallwiederherstellung für Oracle-Datenbanken.
Bevor Sie den Sicherungsjob starten, müssen Sie einige Elemente konfigurieren. Einige dieser Aufgaben sind optional. Wir empfehlen jedoch die folgenden Einstellungen, um eine optimale Leistung zu erzielen:
- Stellen Sie mit SSH eine Verbindung zum Linux-Host her und melden Sie sich als Oracle-Nutzer mit su-Berechtigungen an.
Legen Sie die Oracle-Umgebung für Ihre spezifische Instanz fest:
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
Stellen Sie mit dem Konto
sysdbaeine Verbindung zu SQL*Plus her:sqlplus / as sysdba
Verwenden Sie die folgenden Befehle, um den ARCHIVELOG-Modus zu aktivieren. Die Ausgabe der Befehle sieht in etwa so aus:
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Direct NFS für den Linux-Host konfigurieren:
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
Blockänderungs-Tracking konfigurieren. Prüfen Sie zuerst, ob sie aktiviert oder deaktiviert ist. Im folgenden Beispiel ist die Blockänderungsüberwachung deaktiviert:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
Geben Sie bei Verwendung eines Dateisystems den folgenden Befehl ein:
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
Prüfen Sie, ob die Blockänderungsnachverfolgung jetzt aktiviert ist:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Oracle-Datenbank schützen
Rufen Sie in der Backup & DR Management Console die Seite App Manager > Applications auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
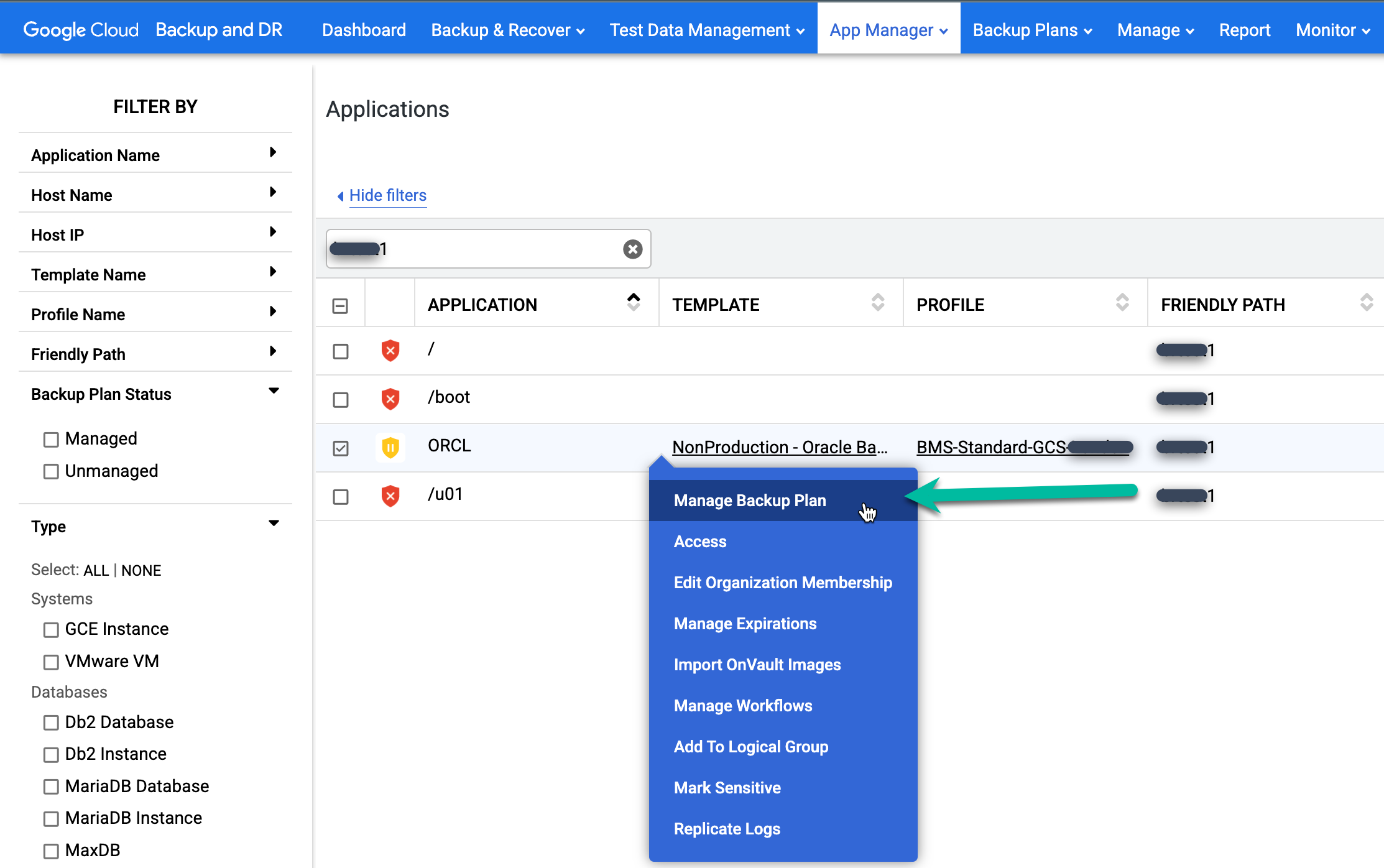
Klicken Sie mit der rechten Maustaste auf den Namen der Oracle-Datenbank, die Sie schützen möchten, und wählen Sie im Menü Manage Backup Plan (Sicherungsplan verwalten) aus.
Wählen Sie die gewünschte Vorlage und das gewünschte Profil aus und klicken Sie auf Sicherungsplan anwenden.
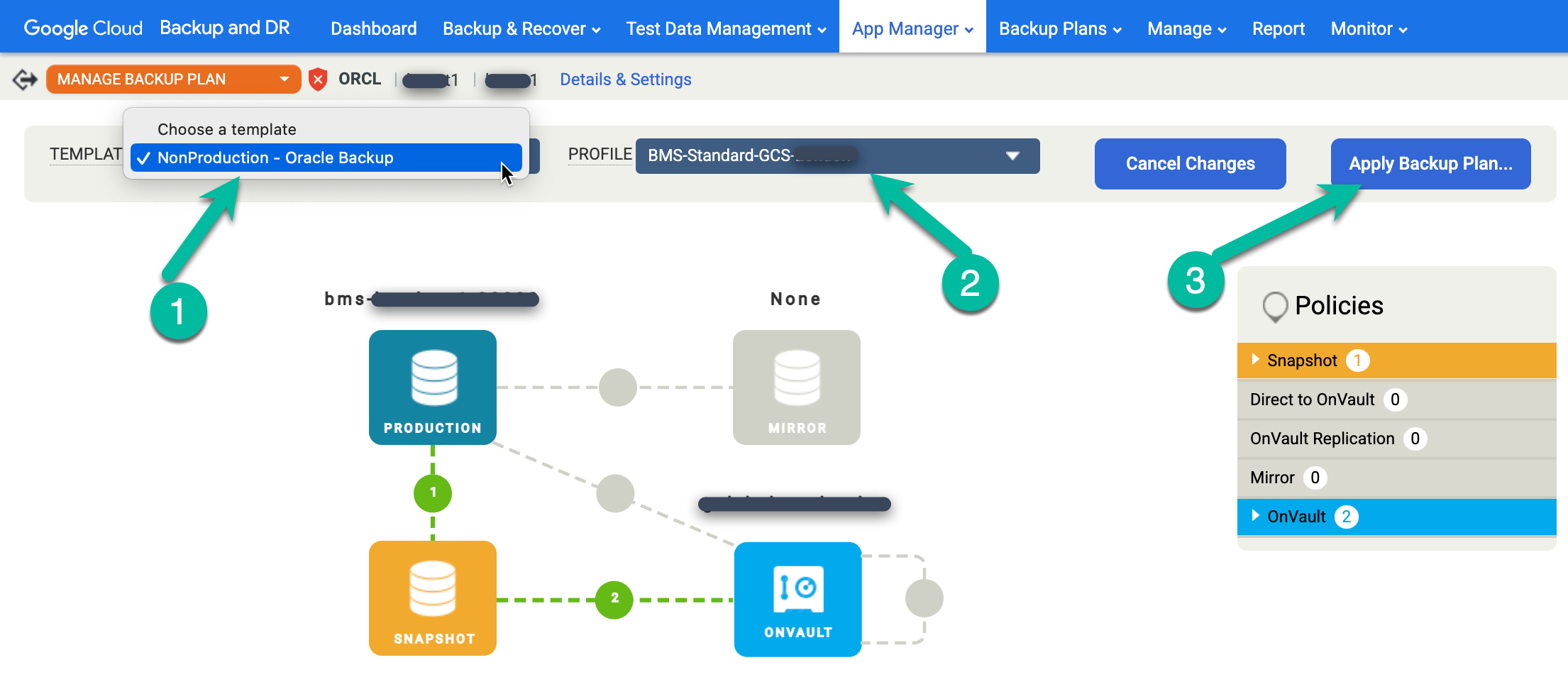
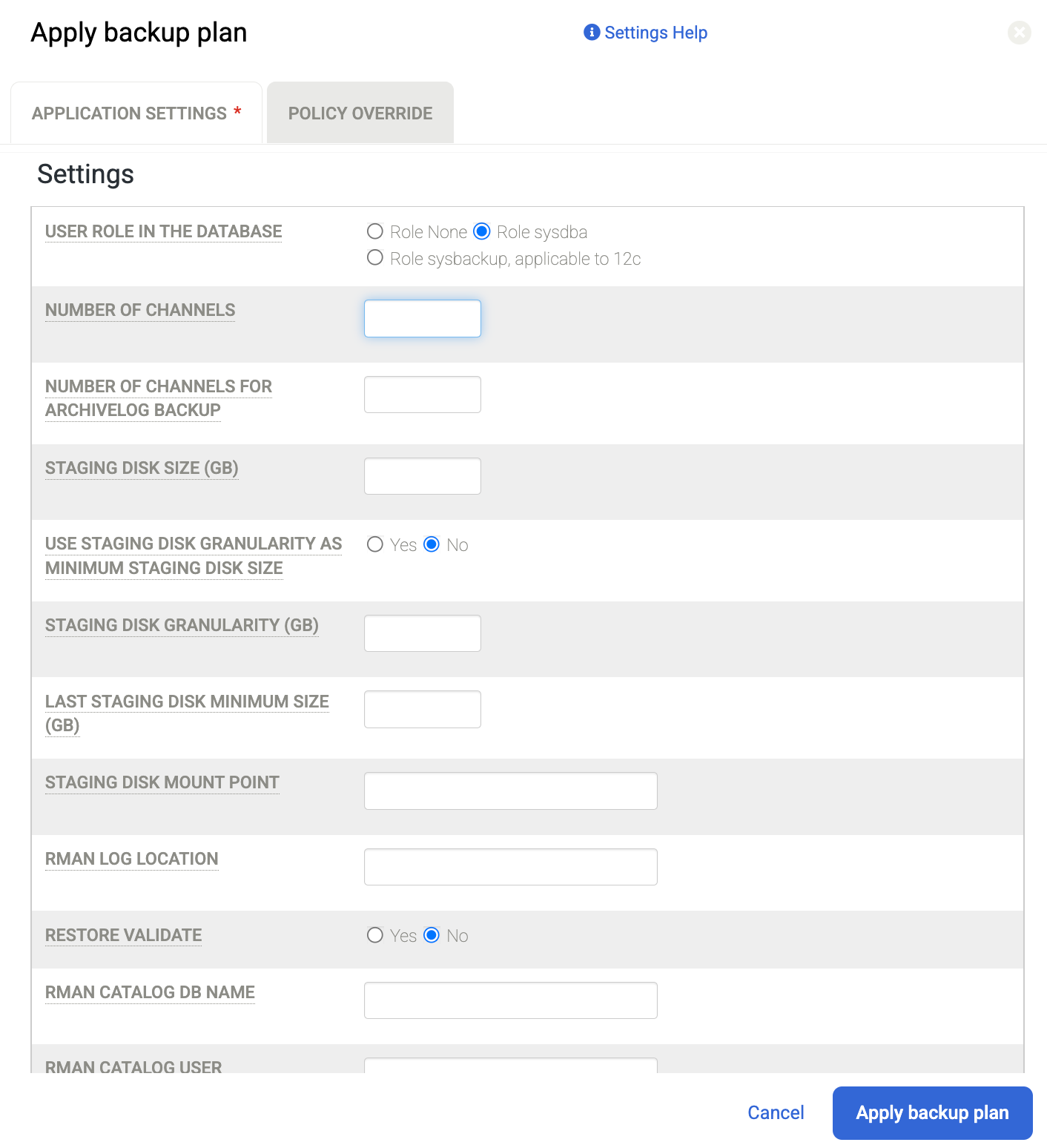
Legen Sie bei entsprechender Aufforderung alle Advanced Settings (Erweiterte Einstellungen) fest, die für Ihre Konfiguration für Oracle und RMAN erforderlich sind. Klicken Sie abschließend auf Sicherungsplan anwenden.
Die Anzahl der Channels ist beispielsweise standardmäßig auf 2 festgelegt. Wenn Sie also eine größere Anzahl von CPU-Kernen haben, können Sie die Anzahl der Kanäle für parallele Sicherungsvorgänge erhöhen und einen höheren Wert festlegen.
Weitere Informationen zu erweiterten Einstellungen finden Sie unter Anwendungsdetails und -einstellungen für Oracle-Datenbanken konfigurieren.
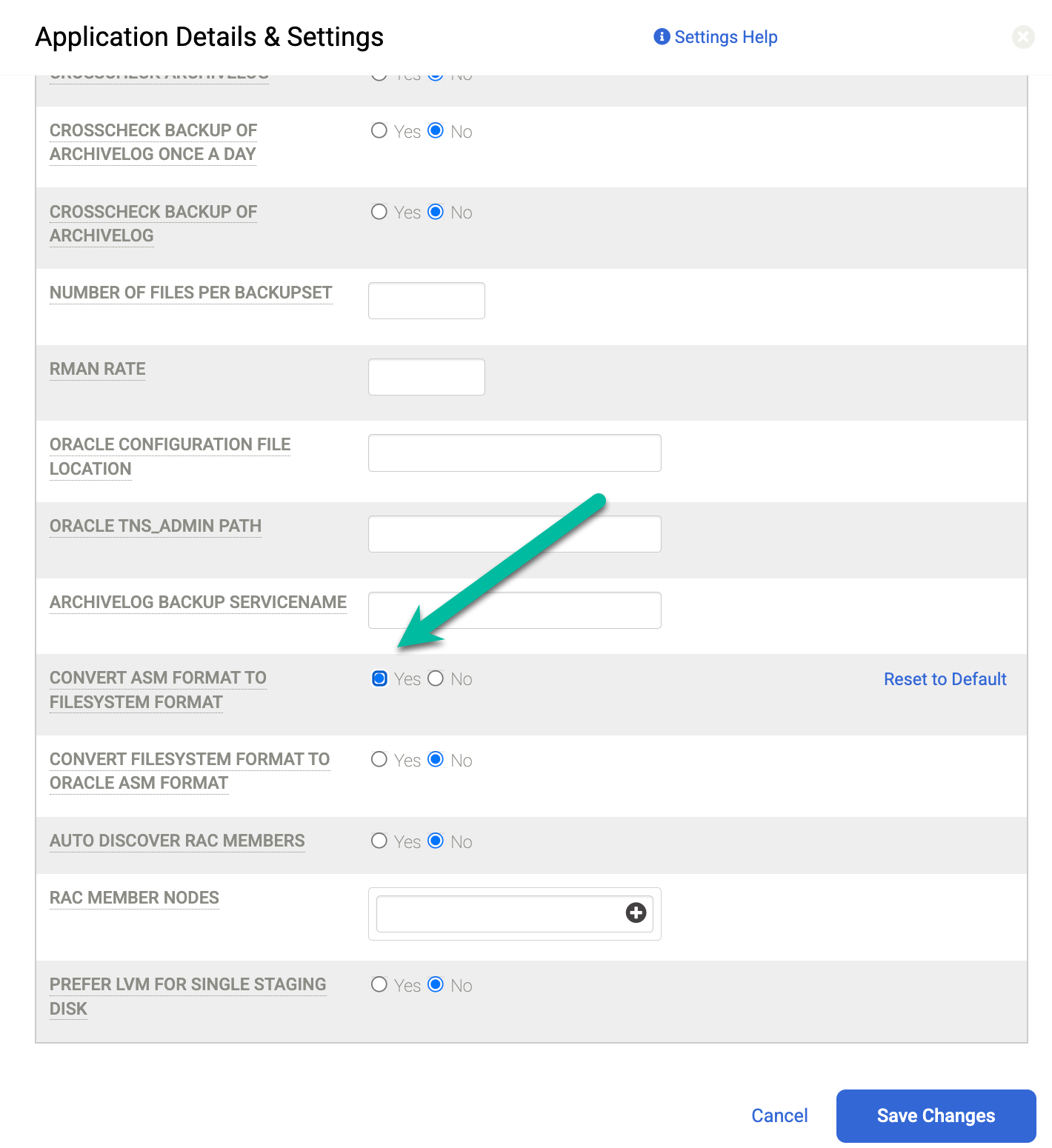
Zusätzlich zu diesen Einstellungen können Sie das Protokoll ändern, das vom Staging-Laufwerk verwendet wird, um das Laufwerk von der Backup Appliance dem Host zuzuordnen. Rufen Sie die Seite Verwalten > Hosts auf und wählen Sie den Host aus, den Sie bearbeiten möchten. Aktivieren Sie die Option Staging Disk Format to Guest (Staging-Festplattenformat für Gast). Standardmäßig ist das Format Block ausgewählt, wodurch die Staging-Festplatte über iSCSI zugeordnet wird. Alternativ kann dies in NFS geändert werden. In diesem Fall wird für die Staging-Festplatte das NFS-Protokoll verwendet.
Die Standardeinstellungen hängen vom Datenbankformat ab. Wenn Sie ASM verwenden, wird iSCSI verwendet, um die Sicherung an eine ASM-Laufwerksgruppe zu senden. Wenn Sie ein Dateisystem verwenden, wird iSCSI verwendet, um die Sicherung an ein Dateisystem zu senden. Wenn Sie NFS oder Direct NFS (dNFS) verwenden möchten, müssen Sie die Hosts-Einstellungen für die Staging-Festplatte in NFS ändern. Wenn Sie die Standardeinstellung verwenden, nutzen alle Backup-Staging-Festplatten stattdessen das Blockspeicherformat und iSCSI.
Sicherungsjob starten
Rufen Sie in der Backup & DR Management Console die Seite App Manager > Applications auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Klicken Sie mit der rechten Maustaste auf die Oracle-Datenbank, die Sie schützen möchten, und wählen Sie im Menü Manage Backup Plan (Sicherungsplan verwalten) aus.
Klicken Sie rechts auf das Menü Snapshot und dann auf Jetzt ausführen. Dadurch wird ein On-Demand-Sicherungsjob gestartet.
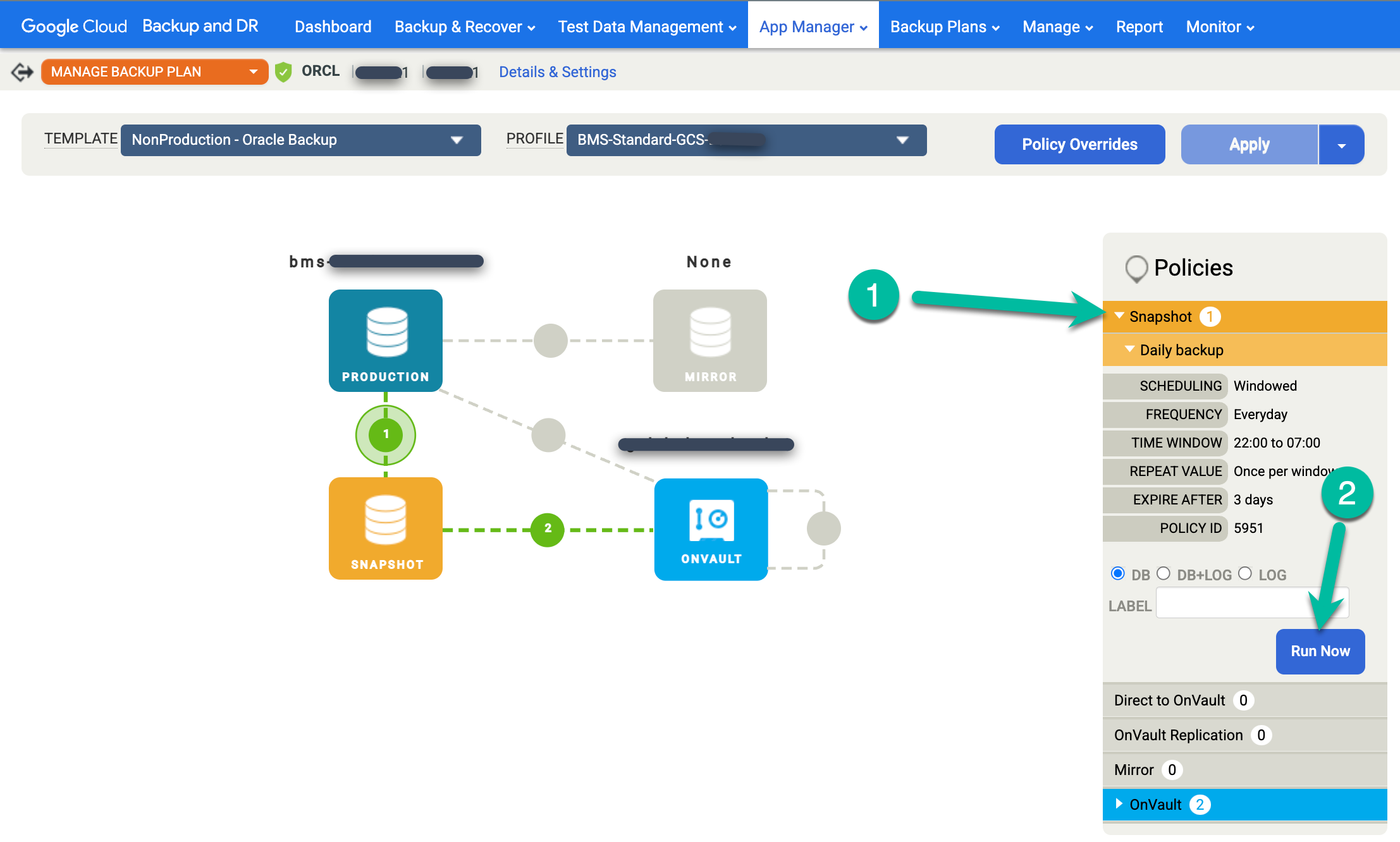
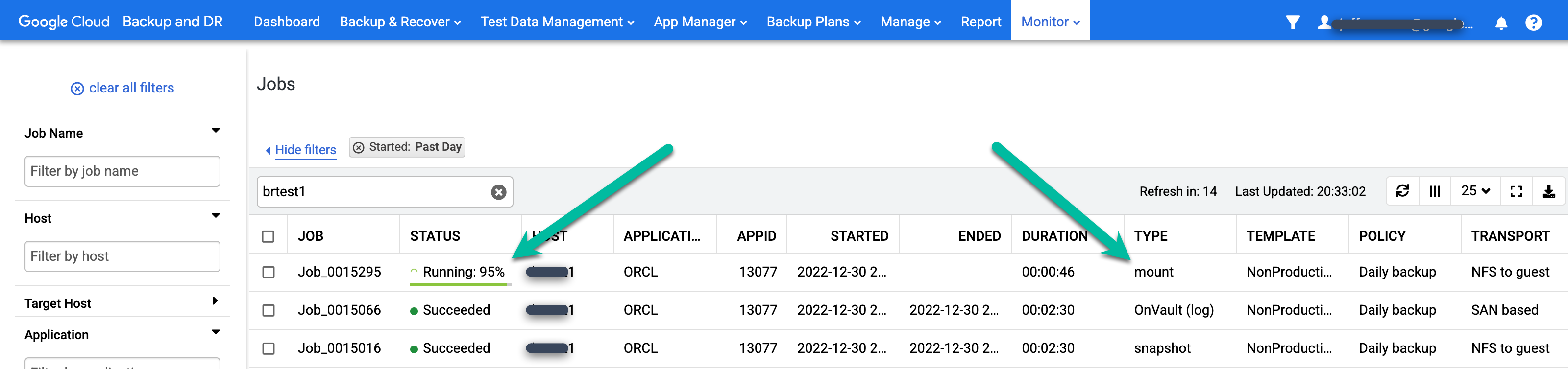
Rufen Sie das Menü Monitor > Jobs auf, um den Status von Sicherungsjobs zu überwachen. Es kann 5 bis 10 Sekunden dauern, bis ein Job in der Jobliste angezeigt wird. Das folgende Beispiel zeigt einen laufenden Job:

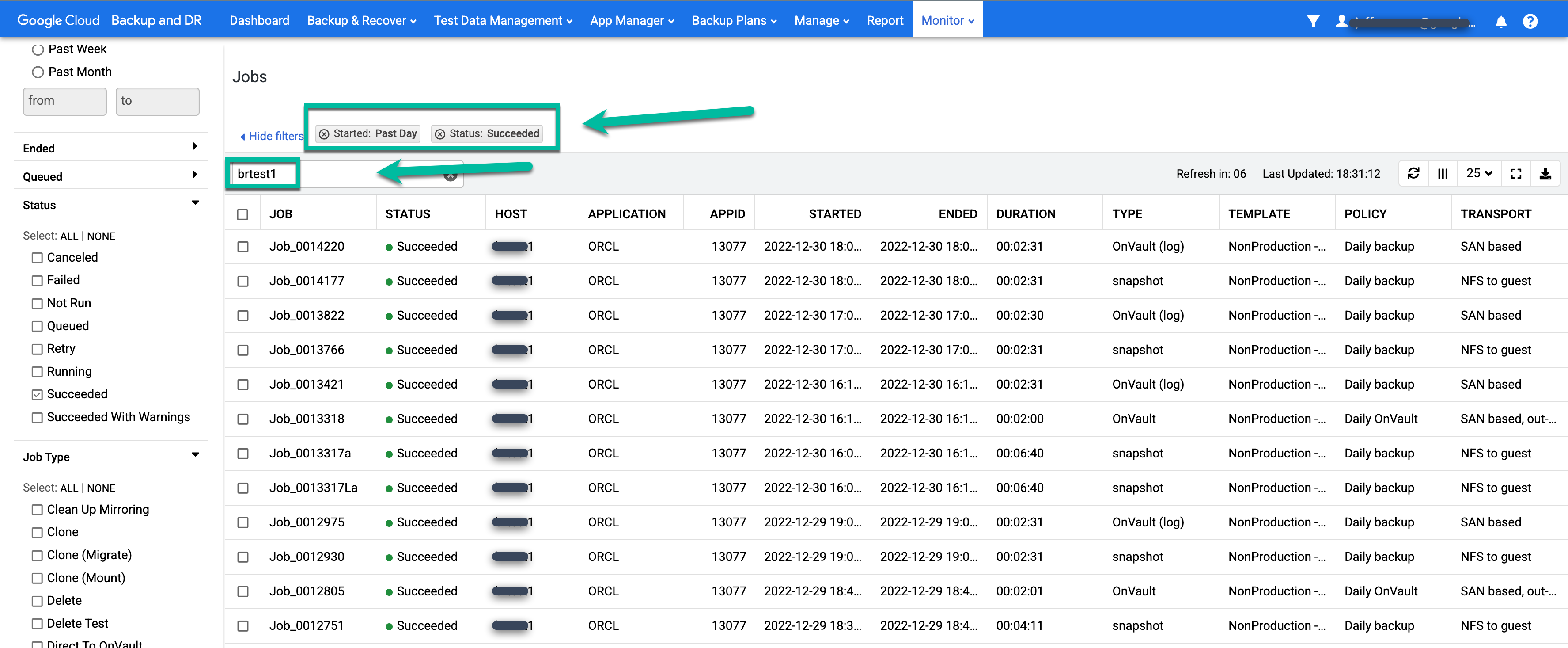
Wenn ein Job erfolgreich ist, können Sie Metadaten verwenden, um die Details für einen bestimmten Job aufzurufen.
- Mit Filtern und Suchbegriffen können Sie Jobs finden, die Sie interessieren. Im folgenden Beispiel werden die Filter Erfolgreich und Letzter Tag sowie eine Suche nach dem Host test1 verwendet.
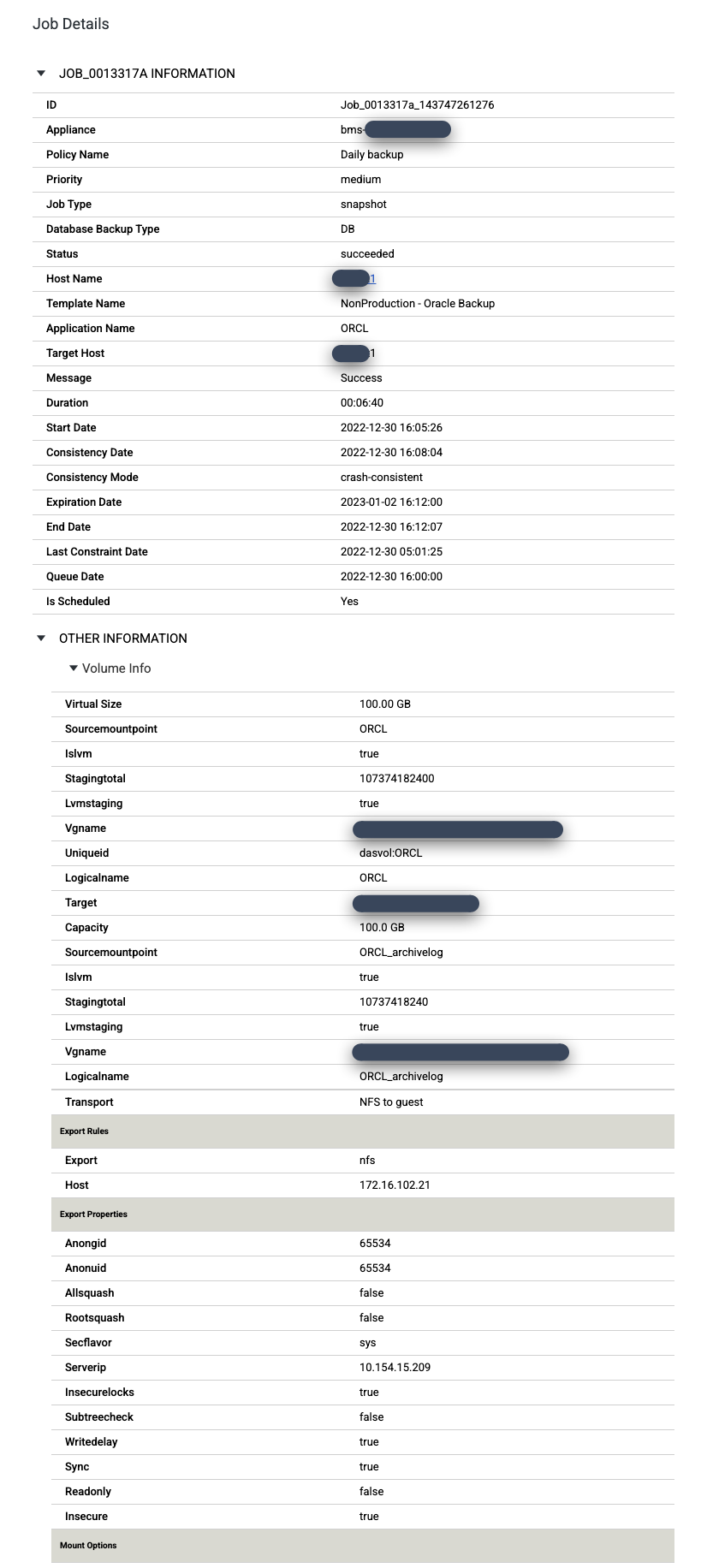
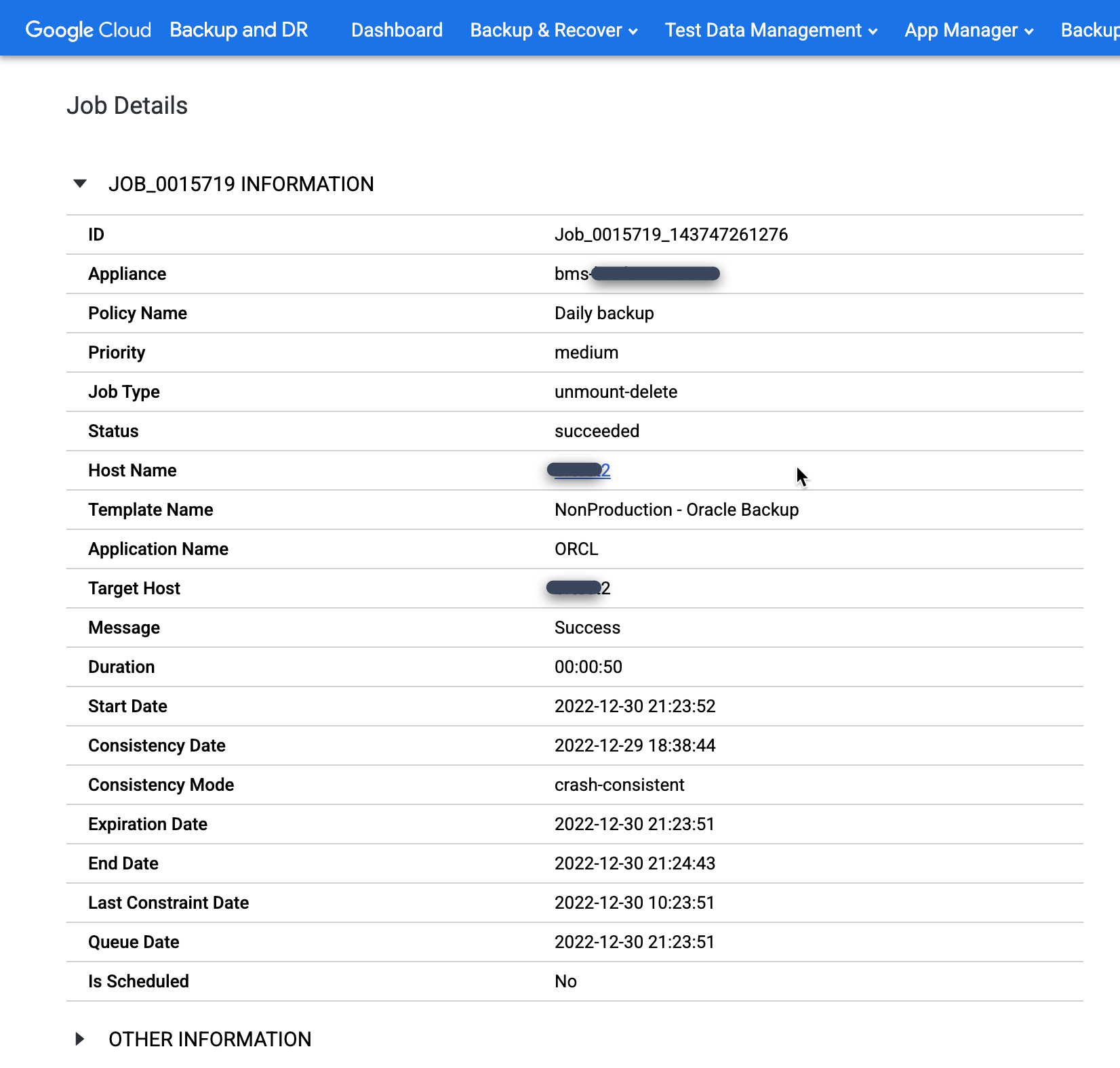
Wenn Sie sich einen bestimmten Job genauer ansehen möchten, klicken Sie in der Spalte Job auf den Job. Ein neues Fenster wird geöffnet. Wie im folgenden Beispiel zu sehen ist, werden bei jedem Sicherungsjob viele Informationen erfasst.
Oracle-Datenbank bereitstellen und wiederherstellen
Google Cloud Backup and DR bietet eine Reihe verschiedener Funktionen für den Zugriff auf eine Kopie einer Oracle-Datenbank. Die beiden Hauptmethoden sind:
- App-kompatible Halterungen
- Wiederherstellungen (Mount and Migrate und traditionelle Wiederherstellung)
Jede dieser Methoden hat unterschiedliche Vorteile. Welche Sie verwenden, hängt von Ihrem Anwendungsfall, den Leistungsanforderungen und davon ab, wie lange Sie die Datenbankkopie aufbewahren müssen. In den folgenden Abschnitten finden Sie einige Empfehlungen für die einzelnen Funktionen.
App-kompatible Halterungen
Mit Bereitstellungen erhalten Sie schnellen Zugriff auf eine virtuelle Kopie einer Oracle-Datenbank. Sie können ein Mount konfigurieren, wenn die Leistung nicht kritisch ist und die Datenbankkopie nur einige Stunden bis einige Tage lang vorhanden ist.
Der Hauptvorteil eines Mounts besteht darin, dass er nicht viel zusätzlichen Speicherplatz belegt. Stattdessen wird für die Bereitstellung ein Snapshot aus dem Sicherungslaufwerkpool verwendet. Das kann ein Snapshot-Pool auf einem nichtflüchtigen Speicher oder ein OnVault-Pool in Cloud Storage sein. Durch die Verwendung der Snapshot-Funktion für virtuelle Kopien wird die Zeit für den Zugriff auf die Daten minimiert, da die Daten nicht zuerst kopiert werden müssen. Das Sicherungslaufwerk verarbeitet alle Lesevorgänge und ein Laufwerk im Snapshot-Pool speichert alle Schreibvorgänge. Daher ist der Zugriff auf bereitgestellte virtuelle Kopien schnell und die Sicherungsfestplattenkopie wird nicht überschrieben. Bereitstellungen eignen sich ideal für Entwicklungs-, Test- und DBA-Aktivitäten, bei denen Schemaänderungen oder ‑aktualisierungen validiert werden müssen, bevor sie in der Produktion eingeführt werden.
Oracle-Datenbank einbinden
Rufen Sie in der Backup- und DR-Verwaltungskonsole die Seite Backup and Recover > Recover auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
Suchen Sie in der Liste Anwendung nach der Datenbank, die Sie einbinden möchten, klicken Sie mit der rechten Maustaste auf den Datenbanknamen und dann auf Weiter:
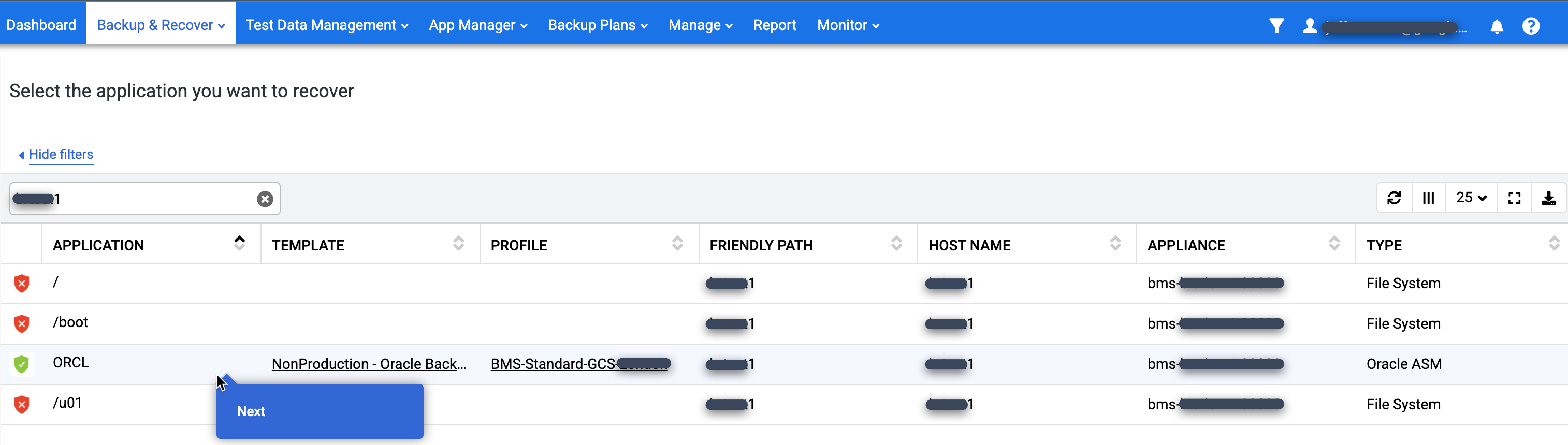
Die Zeitachsen-Rampenansicht wird angezeigt und enthält alle verfügbaren Momentaufnahmen. Sie können auch zurückscrollen, um Bilder mit langfristiger Speicherung zu sehen, wenn sie nicht in der Rampenansicht angezeigt werden. Das System wählt standardmäßig das neueste Bild aus.
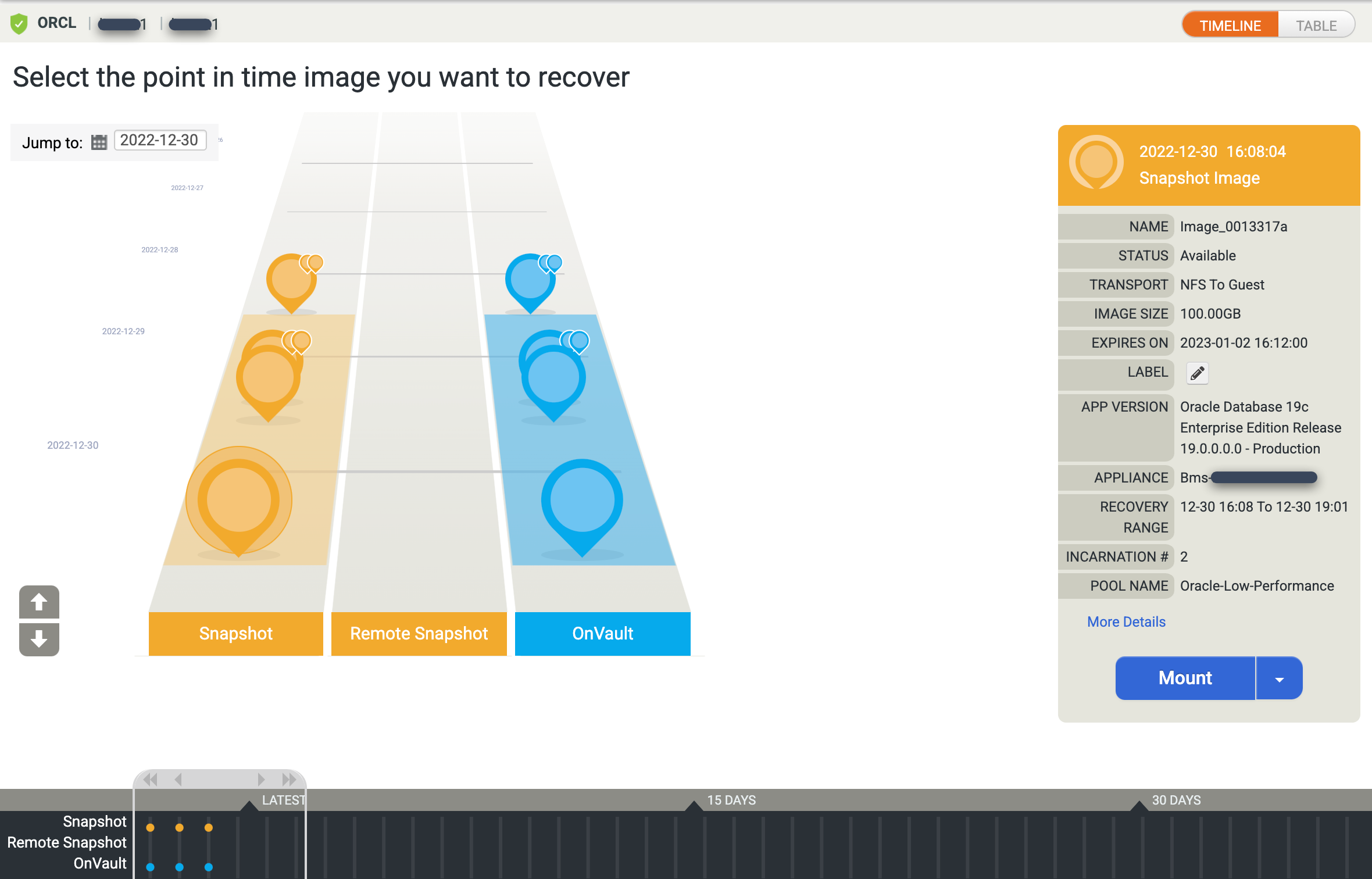
Wenn Sie lieber eine Tabellenansicht der Point-in-Time-Bilder sehen möchten, klicken Sie auf die Option Tabelle, um die Ansicht zu ändern:
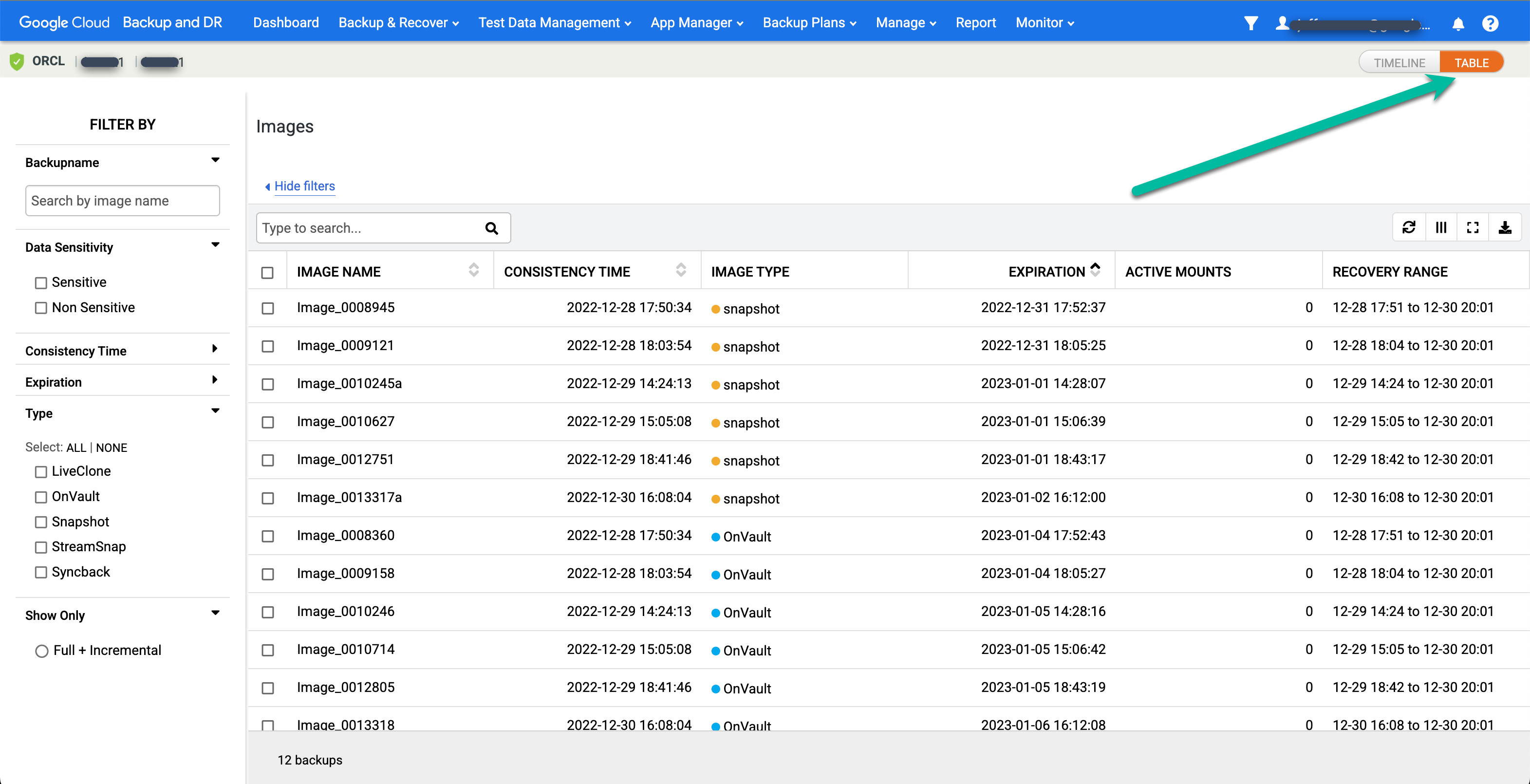
Suchen Sie das gewünschte Bild und wählen Sie Mount (Bereitstellen) aus:
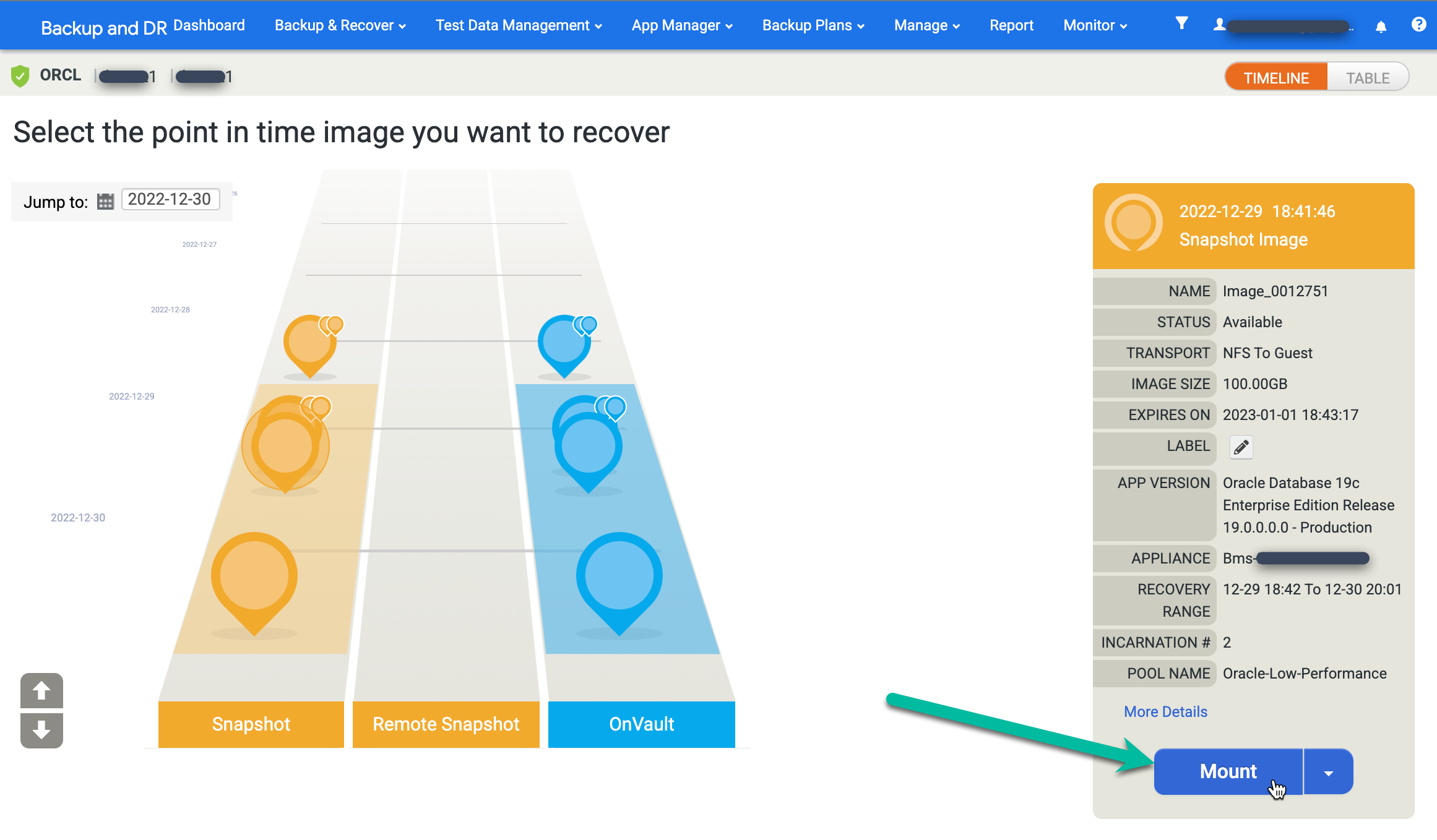
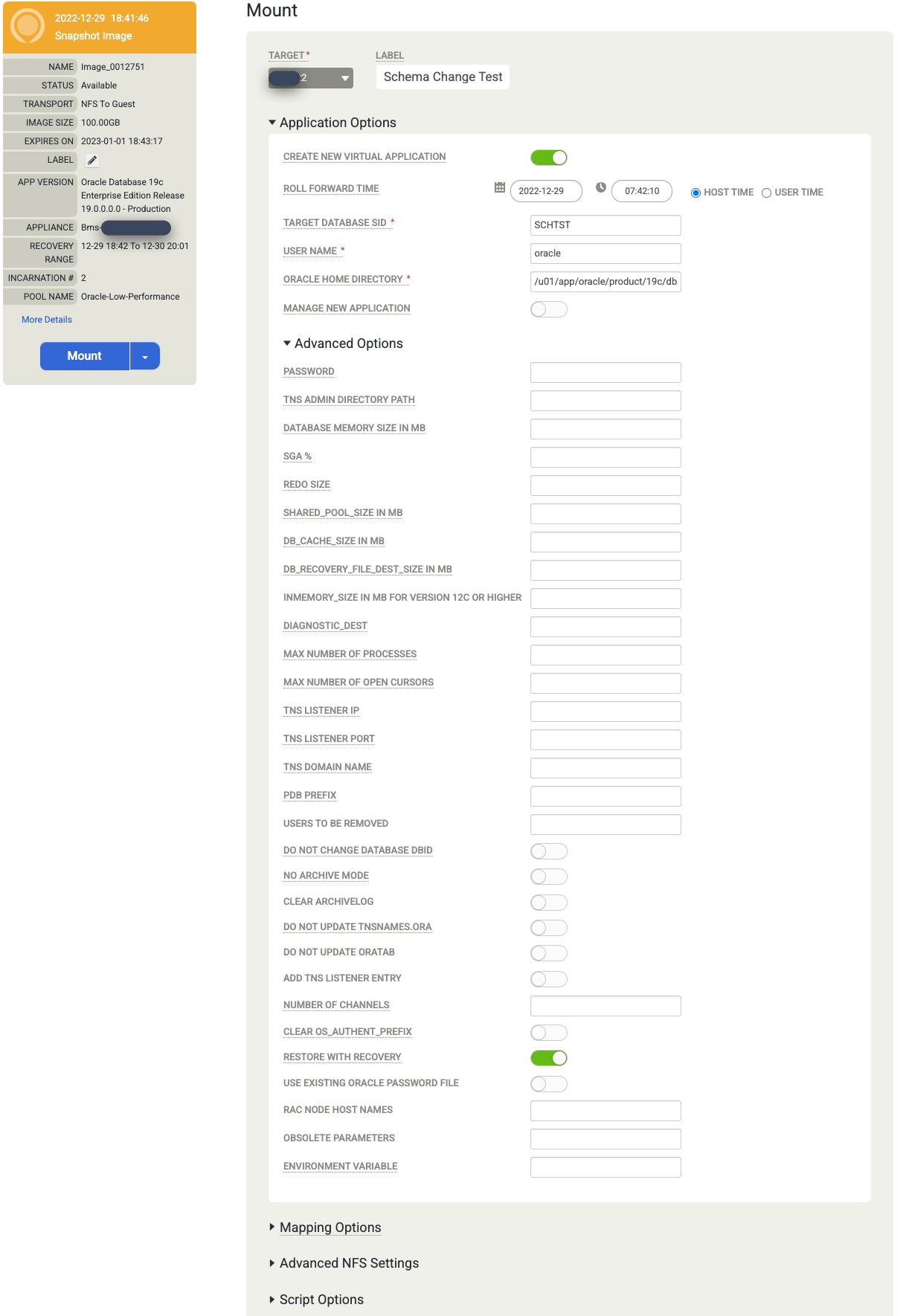
Wählen Sie die Anwendungsoptionen für die Datenbank aus, die Sie einbinden.
- Wählen Sie im Drop-down-Menü den Zielhost aus. Hosts werden in dieser Liste angezeigt, wenn Sie sie zuvor hinzugefügt haben.
- Optional: Geben Sie ein Label ein.
- Geben Sie im Feld Target Database SID (SID der Zieldatenbank) die Kennung für die Zieldatenbank ein.
- Legen Sie User Name auf „oracle“ fest. Dieser Name wird zum Betriebssystem-Nutzername für die Authentifizierung.
- Geben Sie das Oracle-Home-Verzeichnis ein. Verwenden Sie für dieses Beispiel
/u01/app/oracle/product/19c/dbhome_1. - Wenn Sie die Sicherung der Datenbanklogs konfigurieren, wird die Roll Forward Time (Zeit für Vorwärts-Rollout) verfügbar. Klicken Sie auf die Uhr/Zeitauswahl und wählen Sie den Roll-Forward-Punkt aus.
- Mit Recovery wiederherstellen ist standardmäßig aktiviert. Mit dieser Option wird die Datenbank bereitgestellt und geöffnet.
Wenn Sie alle Informationen eingegeben haben, klicken Sie auf Senden, um den Einbindungsvorgang zu starten.
Jobfortschritt und ‑erfolg überwachen
Sie können den laufenden Job auf der Seite Monitor > Jobs (Überwachen > Jobs) beobachten.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
Auf der Seite werden der Status und der Jobtyp angezeigt.
Wenn der Mount-Job abgeschlossen ist, können Sie die Jobdetails aufrufen, indem Sie auf die Jobnummer klicken:
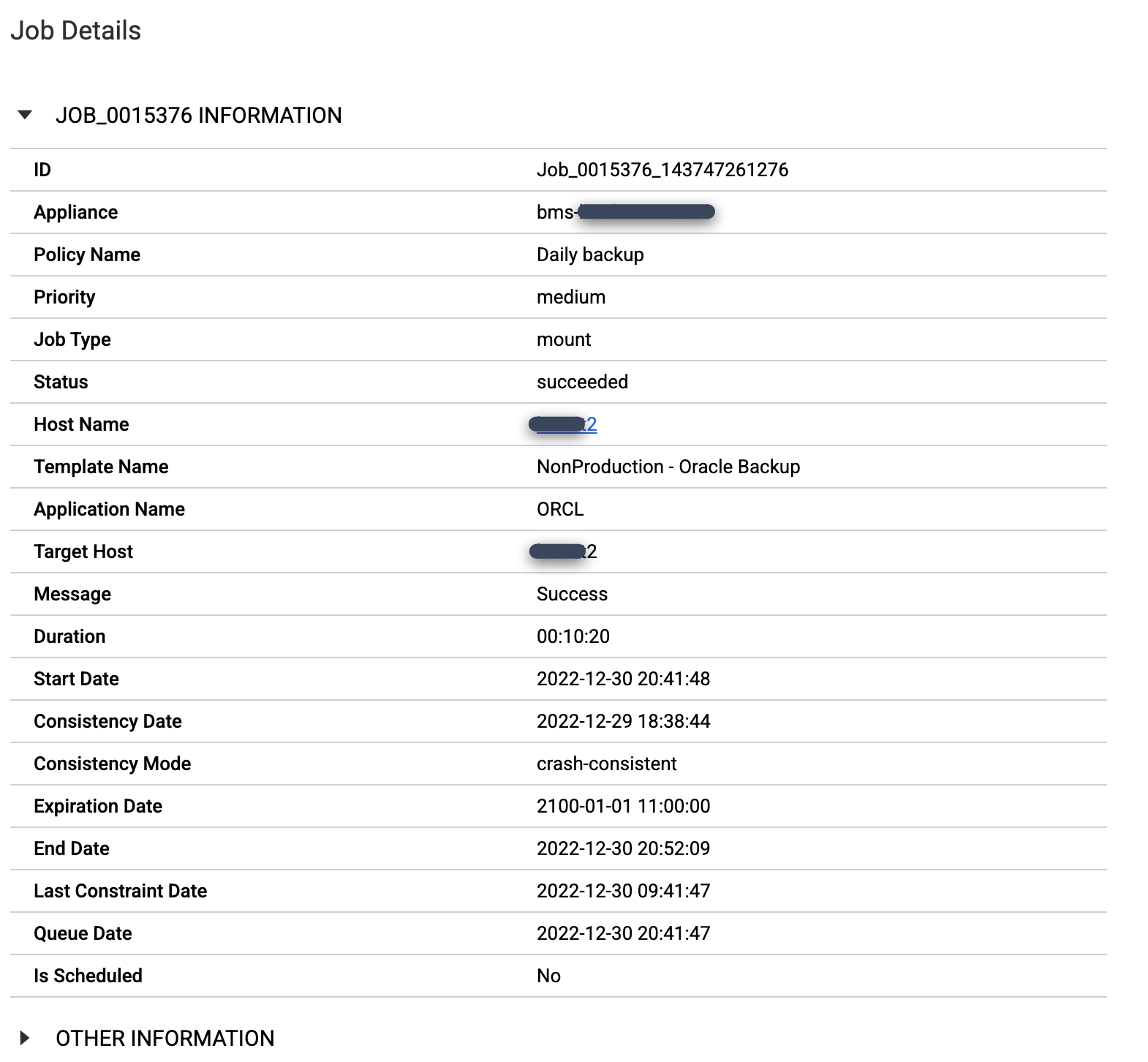
Wenn Sie die PMON-Prozesse für die von Ihnen erstellte SID aufrufen möchten, melden Sie sich auf dem Zielhost an und führen Sie den Befehl
ps -ef |grep pmonaus. Im folgenden Beispielauszug ist die Datenbank SCHTEST betriebsbereit und hat die Prozess-ID 173953.[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asm_pmon_+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Oracle-Datenbank unmounten
Wenn Sie die Datenbank nicht mehr benötigen, sollten Sie sie aushängen und löschen. Es gibt zwei Möglichkeiten, eine eingebundene Datenbank zu finden:
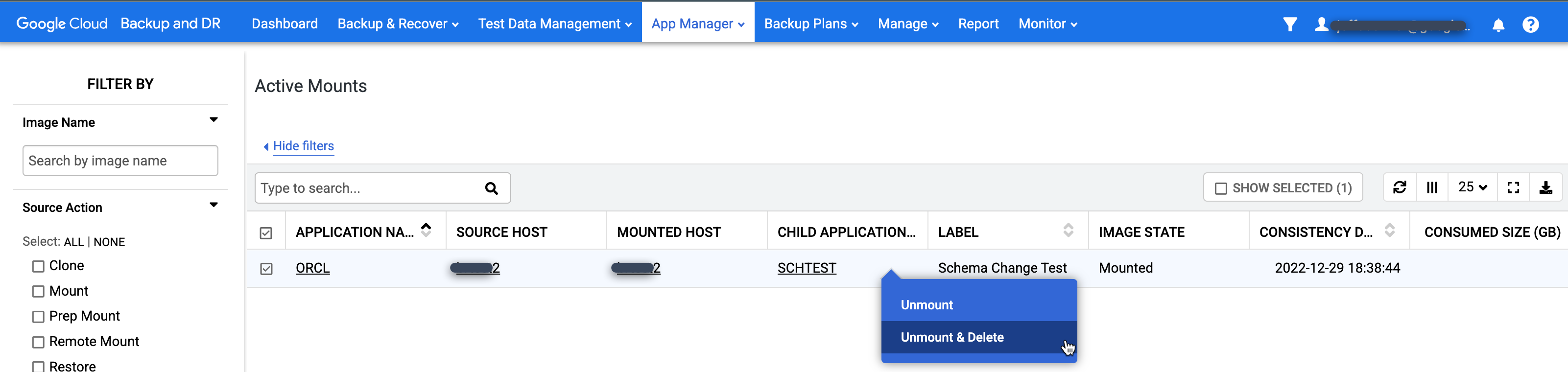
Rufen Sie die Seite App Manager > Active Mounts auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
Auf dieser Seite finden Sie eine globale Ansicht aller eingebundenen Anwendungen (Dateisysteme und Datenbanken), die derzeit verwendet werden.
Klicken Sie mit der rechten Maustaste auf die Bereitstellung, die Sie bereinigen möchten, und wählen Sie im Menü Unmount and Delete (Aushängen und löschen) aus. Bei dieser Aktion werden keine Sicherungsdaten gelöscht. Es werden nur die virtuell gemountete Datenbank vom Zielhost und die Snapshot-Cache-Festplatte entfernt, die die gespeicherten Schreibvorgänge für die Datenbank enthielt.
Rufen Sie die Seite App Manager > Anwendungen auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
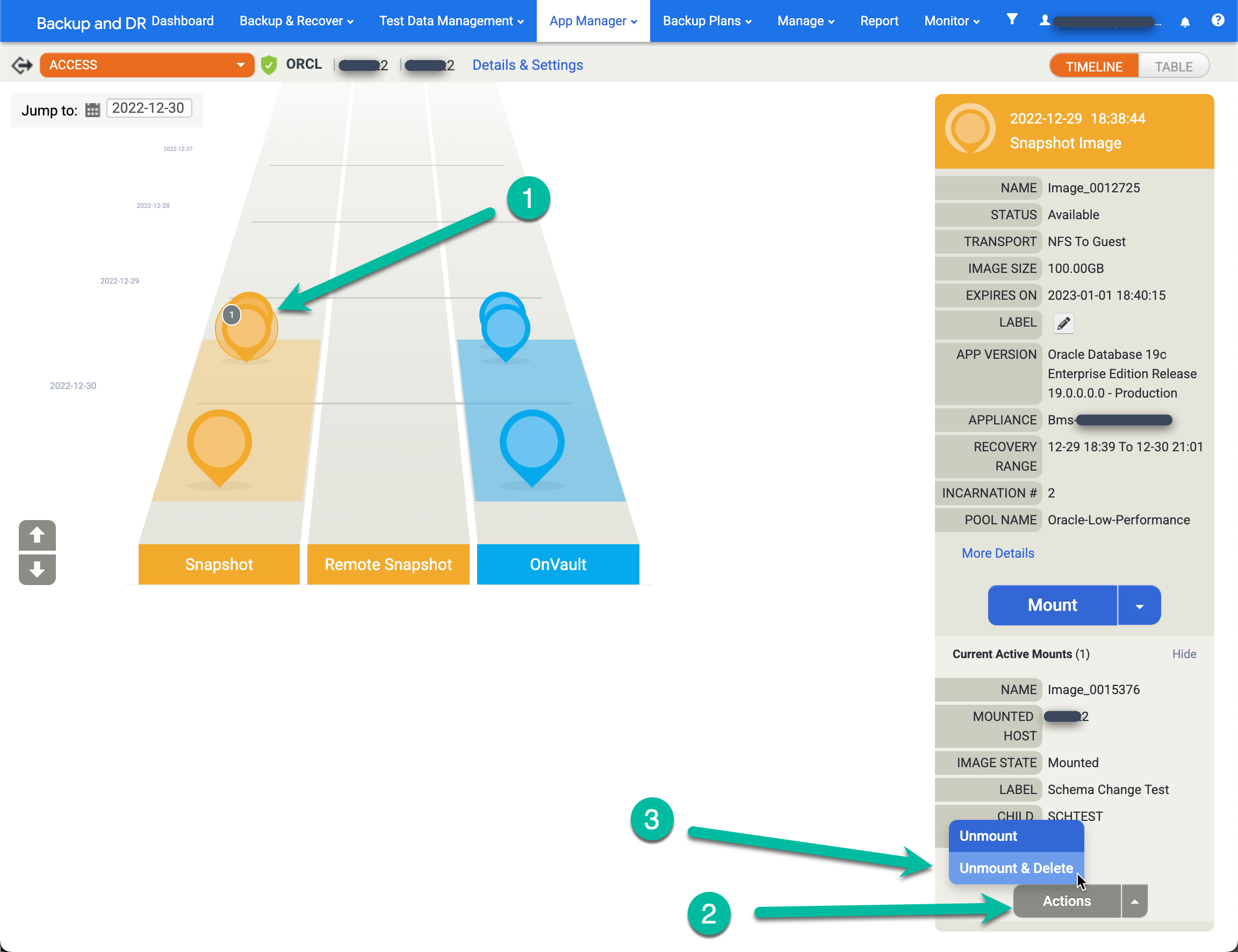
- Klicken Sie mit der rechten Maustaste auf die Quellanwendung (Datenbank) und wählen Sie Zugriff aus.
- Auf der linken Seite sehen Sie einen grauen Kreis mit einer Zahl darin, die die Anzahl der aktiven Bereitstellungen ab diesem Zeitpunkt angibt. Klicken Sie auf das Bild. Daraufhin wird ein neues Menü angezeigt.
- Klicken Sie auf Aktionen.
- Klicken Sie auf Aushängen und löschen.
- Klicken Sie auf Senden und bestätigen Sie die Aktion auf dem nächsten Bildschirm.
Einige Minuten später wird die Datenbank vom Zielhost entfernt und alle Festplatten werden bereinigt und entfernt. Durch diese Aktion wird der Speicherplatz im Snapshot-Pool freigegeben, der für Schreibvorgänge auf der Redo-Festplatte für aktive Mounts verwendet wird.
Sie können nicht bereitgestellte Jobs wie jeden anderen Job überwachen. Rufen Sie das Menü Monitor > Jobs auf, um den Fortschritt des Jobs zu überwachen, der unmountet wird, und zu bestätigen, dass der Job abgeschlossen ist.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
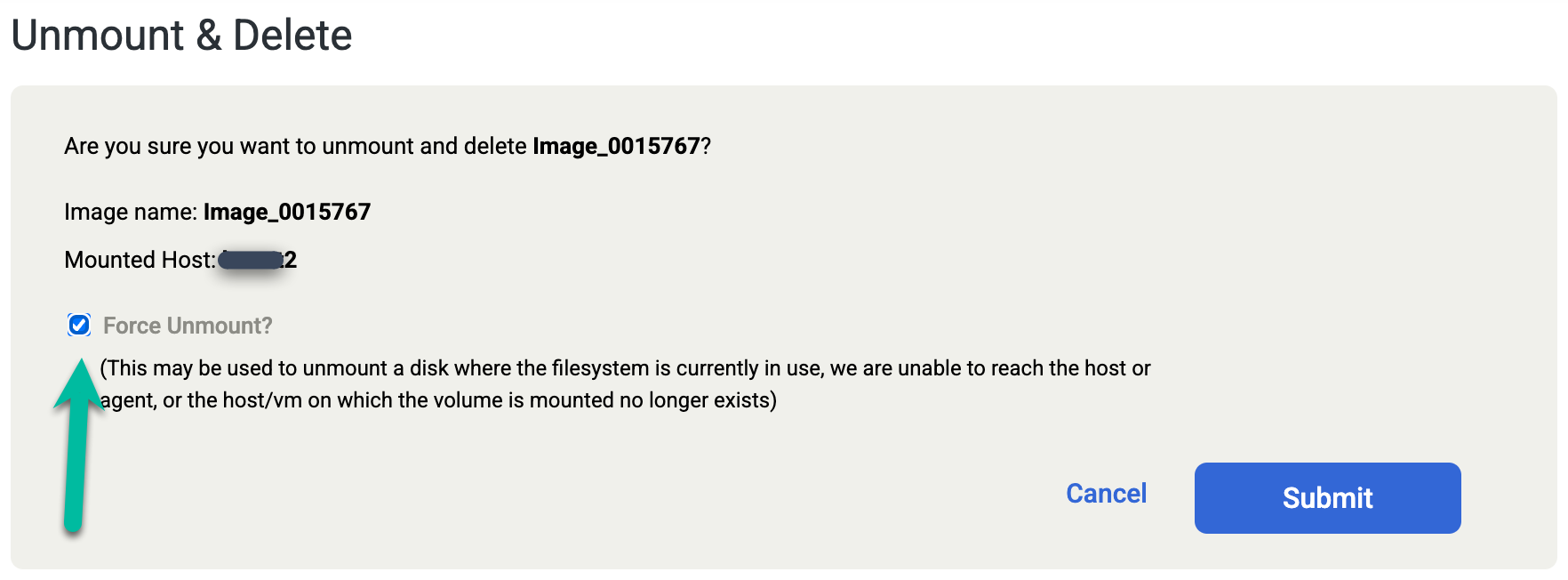
Wenn Sie die Oracle-Datenbank versehentlich manuell löschen oder die Datenbank herunterfahren, bevor Sie den Job Unmount and Delete (Aushängen und löschen) ausführen, führen Sie den Job Unmount and Delete noch einmal aus und wählen Sie auf dem Bestätigungsbildschirm die Option Force Unmount (Aushängen erzwingen) aus. Durch diese Aktion wird die Staging-Festplatte für die Wiederholung vom Zielhost entfernt und die Festplatte aus dem Snapshot-Pool gelöscht.
Wiederherstellungen
Mit Wiederherstellungen können Sie Produktionsdatenbanken wiederherstellen, wenn ein Problem oder eine Beschädigung auftritt und Sie alle Dateien für die Datenbank aus einer Sicherungskopie auf einen lokalen Host kopieren müssen. Eine Wiederherstellung wird normalerweise nach einem Notfall oder für Testkopien für Nichtproduktionsumgebungen durchgeführt. In diesem Fall müssen Ihre Kunden in der Regel warten, bis Sie die vorherigen Dateien auf den Quellhost zurückkopiert haben, bevor sie ihre Datenbanken neu starten können. Google Cloud Backup and DR unterstützt jedoch auch eine Wiederherstellungsfunktion (Dateien kopieren und Datenbank starten) sowie eine Funktion zum Einbinden und Migrieren, mit der Sie die Datenbank einbinden können (schneller Zugriff) und Daten auf den lokalen Computer kopieren können, während die Datenbank eingebunden und zugänglich ist. Die Funktion „Bereitstellen und migrieren“ ist nützlich für Szenarien mit niedrigem Recovery Time Objective (RTO).
Mounten und migrieren
Die Wiederherstellung auf Grundlage von Mount und Migration umfasst zwei Phasen:
- Phase 1: In der Phase für die Bereitstellung der Wiederherstellung wird sofortiger Zugriff auf die Datenbank gewährt, indem mit der bereitgestellten Kopie begonnen wird.
- Phase 2: In der Phase der Migrationswiederherstellung wird die Datenbank an den Produktionsspeicherort migriert, während sie online ist.
Bereitstellung wiederherstellen – Phase 1
In dieser Phase haben Sie sofortigen Zugriff auf die Datenbank über ein ausgewähltes Image, das von der Sicherungs-/Wiederherstellungs-Appliance bereitgestellt wird.
- Eine Kopie des ausgewählten Sicherungs-Image wird dem Zieldatenbankserver zugeordnet und der ASM- oder Dateisystemebene basierend auf dem Sicherungs-Image-Format der Quelldatenbank präsentiert.
- Verwenden Sie die RMAN API, um die folgenden Aufgaben auszuführen:
- Stellen Sie die Steuerdatei und die Wiederherstellungs-Logdatei am angegebenen lokalen Speicherort für die Steuerdatei und die Wiederherstellungsdatei (ASM-Laufwerksgruppe oder Dateisystem) wieder her.
- Stellen Sie die Datenbank auf die Kopie des Images um, die von der Sicherungs-/Wiederherstellungs-Appliance bereitgestellt wird.
- Alle verfügbaren Archivierungsprotokolle bis zum angegebenen Wiederherstellungspunkt vorwärts rollen.
- Öffnen Sie die Datenbank im Lese- und Schreibmodus.
- Die Datenbank wird über die zugeordnete Kopie des Sicherungs-Images ausgeführt, die von der Sicherungs-/Wiederherstellungs-Appliance bereitgestellt wird.
- Die Kontrolldatei und die Redo-Log-Datei der Datenbank werden am ausgewählten lokalen Produktionsspeicherort (ASM-Diskgroup oder Dateisystem) auf dem Ziel platziert.
- Nach einem erfolgreichen Mount-Vorgang für die Wiederherstellung ist die Datenbank für Produktionsvorgänge verfügbar. Sie können die Oracle Online Datafile Move API verwenden, um die Daten zurück zum Produktionsspeicherort (ASM-Festplattengruppe oder Dateisystem) zu verschieben, während die Datenbank und die Anwendung ausgeführt werden.
Migration wiederherstellen – Phase 2
Verschiebt die Datenbankdatendatei online in den Produktionsspeicher:
- Die Datenmigration wird im Hintergrund ausgeführt. Verwenden Sie die Oracle Online Datafile Move API, um die Daten zu migrieren.
- Sie verschieben die Datendateien aus der von Backup and DR präsentierten Kopie des Sicherungs-Image in den ausgewählten Zieldatenbankspeicher (ASM-Diskgroup oder Dateisystem).
- Wenn der Migrationsjob abgeschlossen ist, entfernt das System die von Backup and DR bereitgestellte Sicherungskopie (ASM-Diskgroup oder Dateisystem) vom Ziel und hebt die Zuordnung auf. Die Datenbank wird dann von Ihrem Produktionsspeicher aus ausgeführt.
Weitere Informationen zur Mount-and-Migrate-Wiederherstellung finden Sie unter Oracle-Sicherungs-Image für die sofortige Wiederherstellung auf einem beliebigen Ziel bereitstellen und migrieren.
Oracle-Datenbank wiederherstellen
Rufen Sie in der Backup- und DR-Verwaltungskonsole die Seite Backup and Recover > Recover auf.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
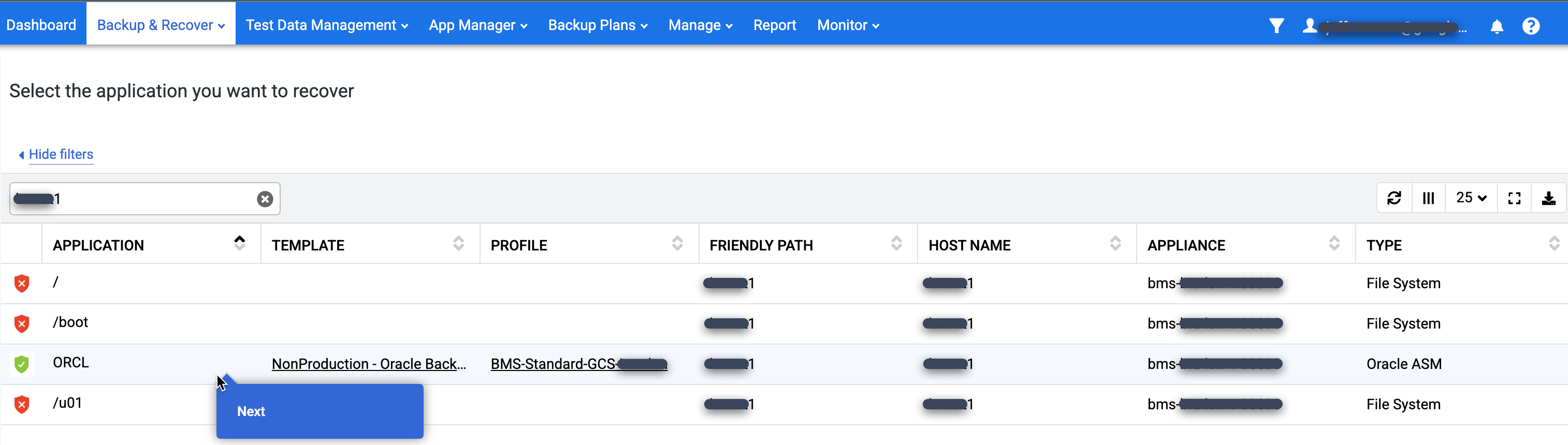
Klicken Sie in der Liste Anwendung mit der rechten Maustaste auf den Namen der Datenbank, die Sie wiederherstellen möchten, und wählen Sie Weiter aus:
Die Zeitachsen-Rampenansicht wird mit allen verfügbaren Momentaufnahmen angezeigt. Sie können auch zurückscrollen, wenn Sie die Bilder mit langfristiger Aufbewahrung sehen möchten, die nicht im Ramp angezeigt werden. Das System wählt standardmäßig immer das neueste Bild aus.
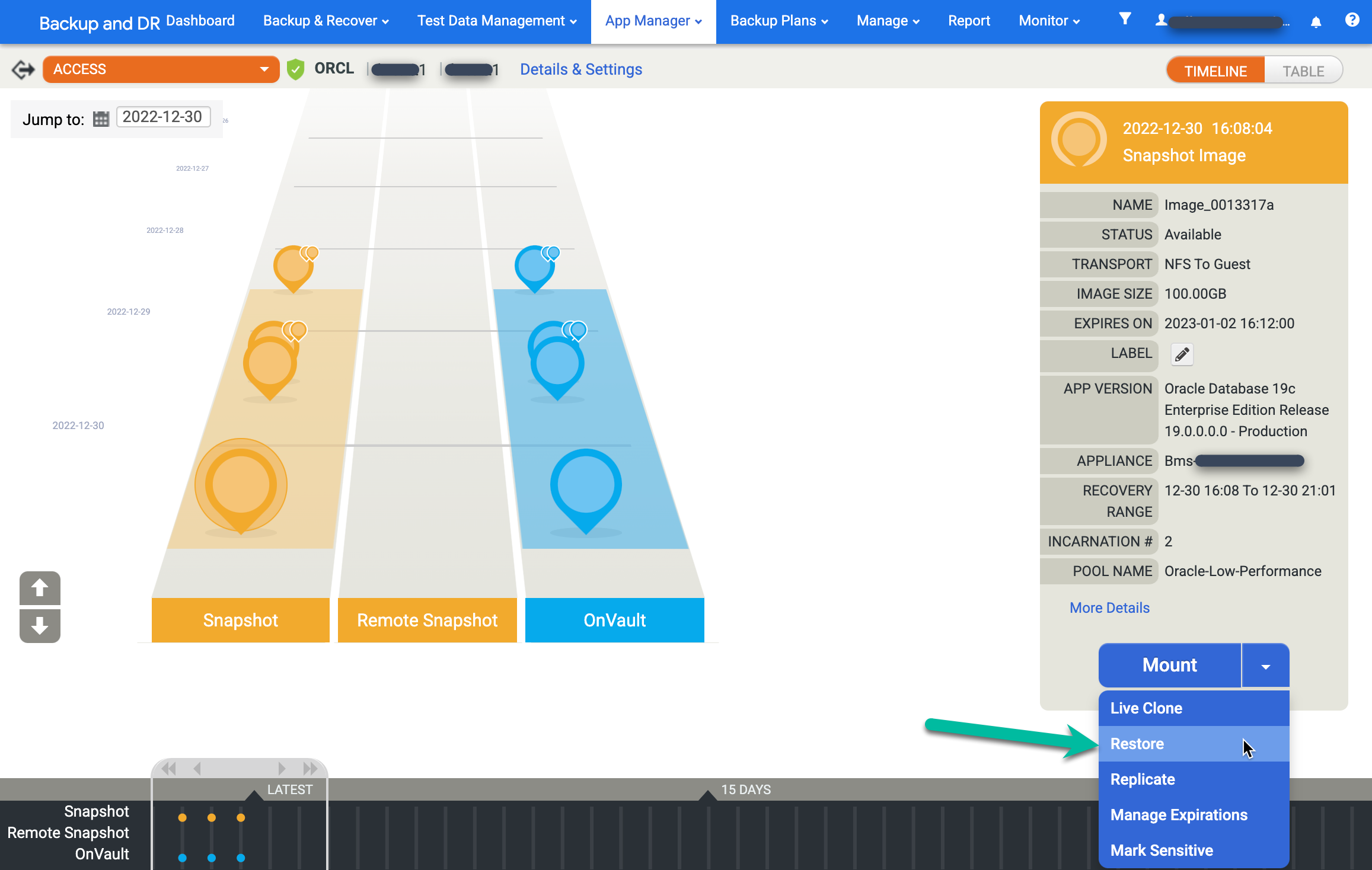
Wenn Sie ein Bild wiederherstellen möchten, klicken Sie auf das Menü Mount (Bereitstellen) und wählen Sie Restore (Wiederherstellen) aus:
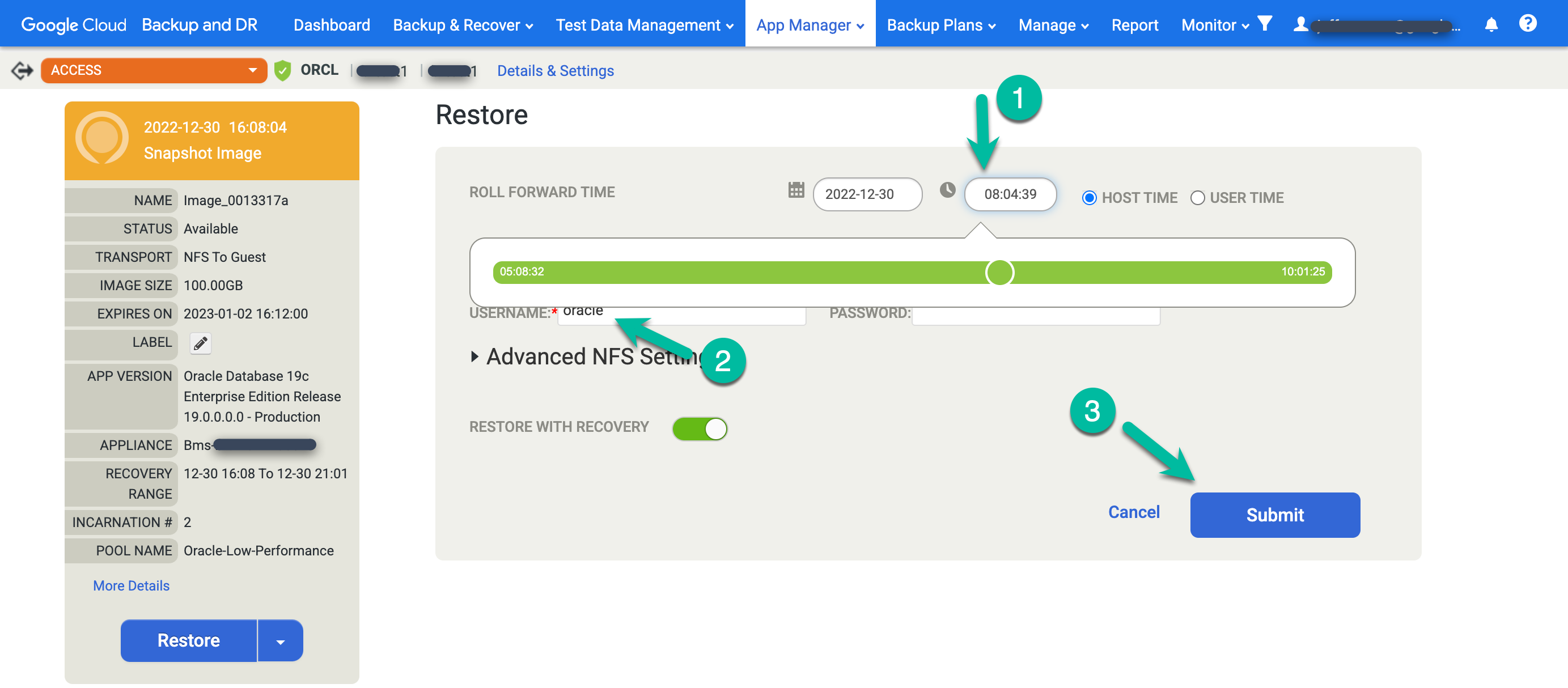
Wählen Sie die gewünschten Wiederherstellungsoptionen aus.
- Wählen Sie die Roll Forward Time (Zeit für die Übertragung) aus. Klicken Sie auf die Uhr und wählen Sie den gewünschten Zeitpunkt aus.
- Geben Sie den Nutzernamen ein, den Sie für Oracle verwenden möchten.
- Wenn Ihr System die Datenbankauthentifizierung verwendet, geben Sie ein Passwort ein.
Klicken Sie auf Senden, um den Job zu starten.
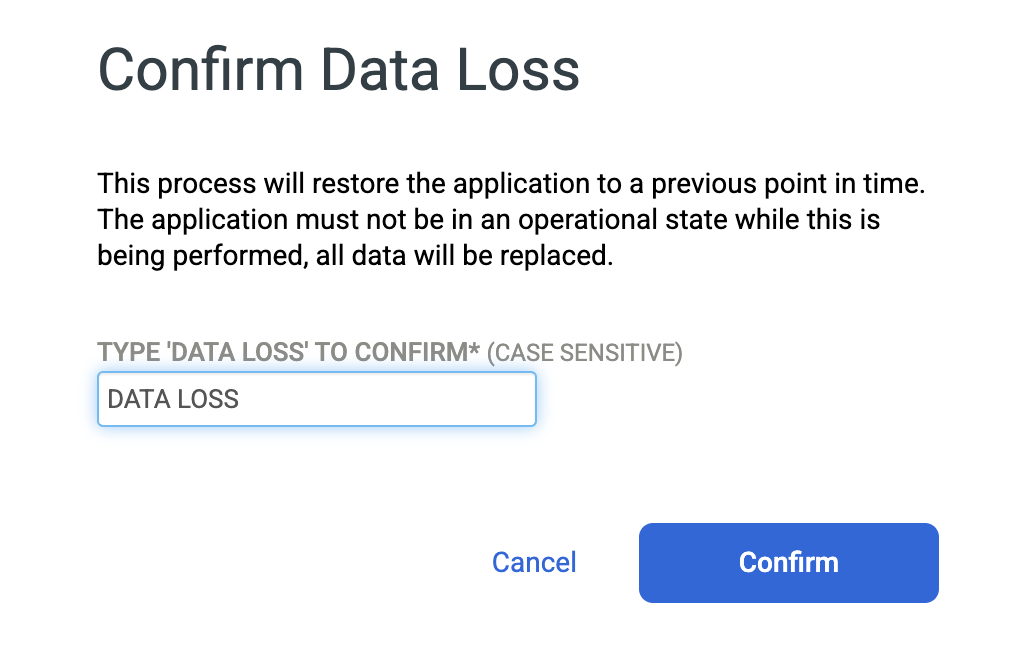
Geben Sie DATA LOSS ein, um zu bestätigen, dass Sie die Quelldatenbank überschreiben möchten, und klicken Sie auf Bestätigen.
Jobfortschritt und ‑erfolg überwachen
Rufen Sie die Seite Monitor > Jobs auf, um den Job zu überwachen.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
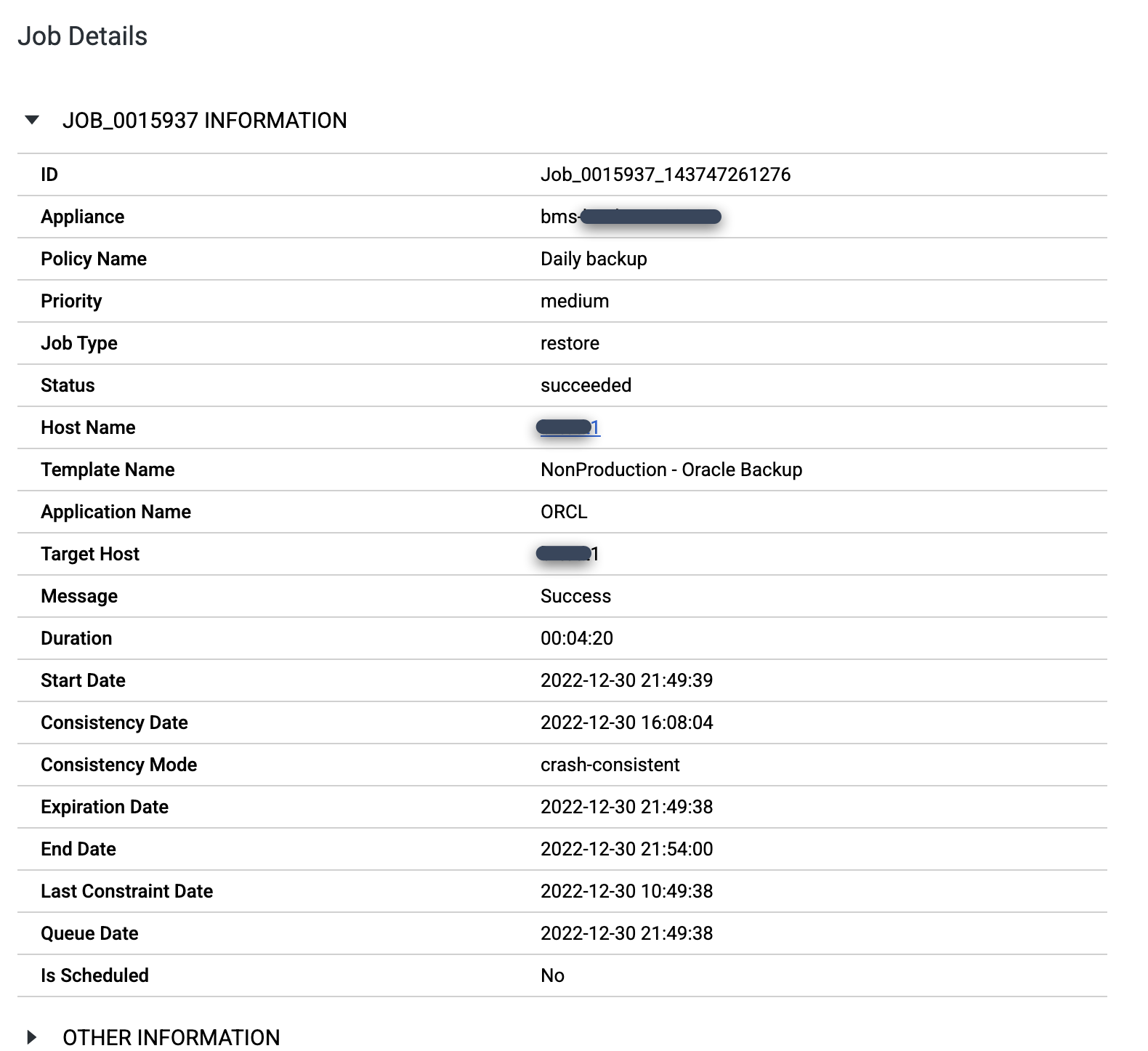
Klicken Sie, wenn der Job abgeschlossen ist, auf die Jobnummer, um die Jobdetails und Metadaten aufzurufen.
Wiederhergestellte Datenbank schützen
Wenn der Datenbankwiederherstellungsjob abgeschlossen ist, wird die Datenbank nach der Wiederherstellung nicht automatisch gesichert. Wenn Sie also eine Datenbank wiederherstellen, für die zuvor ein Sicherungsplan vorhanden war, wird der Sicherungsplan nicht standardmäßig aktiviert.
Rufen Sie die Seite App Manager > Anwendungen auf, um zu prüfen, ob der Sicherungsplan ausgeführt wird.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Suchen Sie in der Liste nach der wiederhergestellten Datenbank. Das Schutzsymbol ändert sich von Grün zu Gelb. Das bedeutet, dass für die Datenbank keine Sicherungsjobs geplant sind.
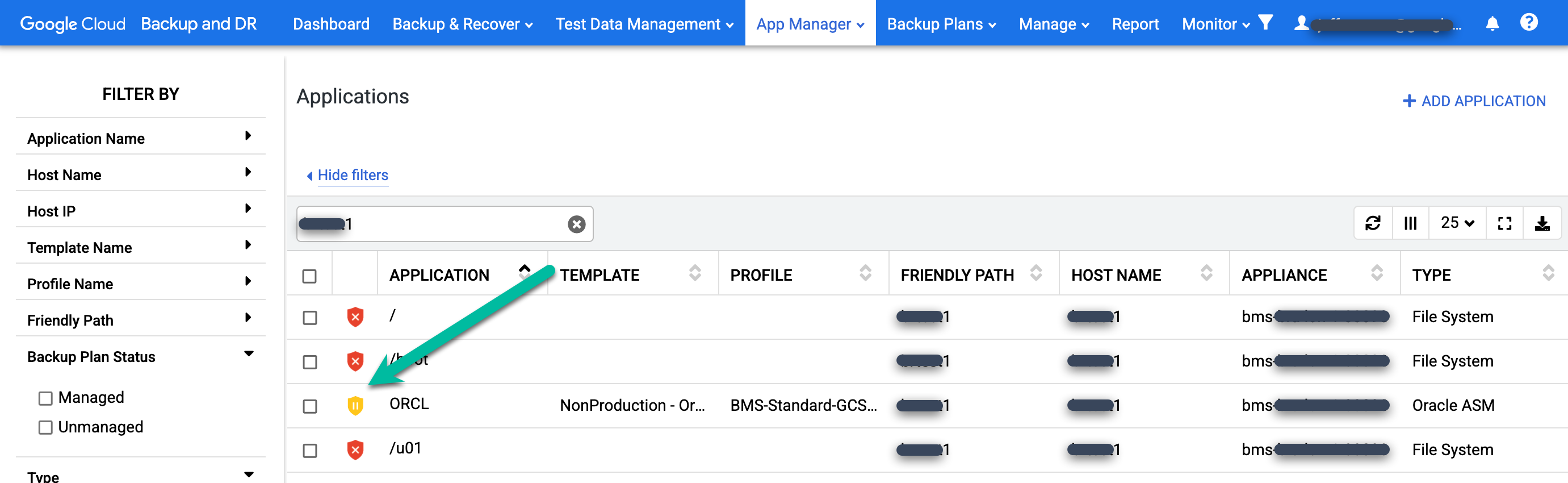
Suchen Sie in der Spalte Anwendung nach der Datenbank, die Sie schützen möchten. Klicken Sie mit der rechten Maustaste auf den Datenbanknamen und wählen Sie Manage Backup Plan (Sicherungsplan verwalten) aus.
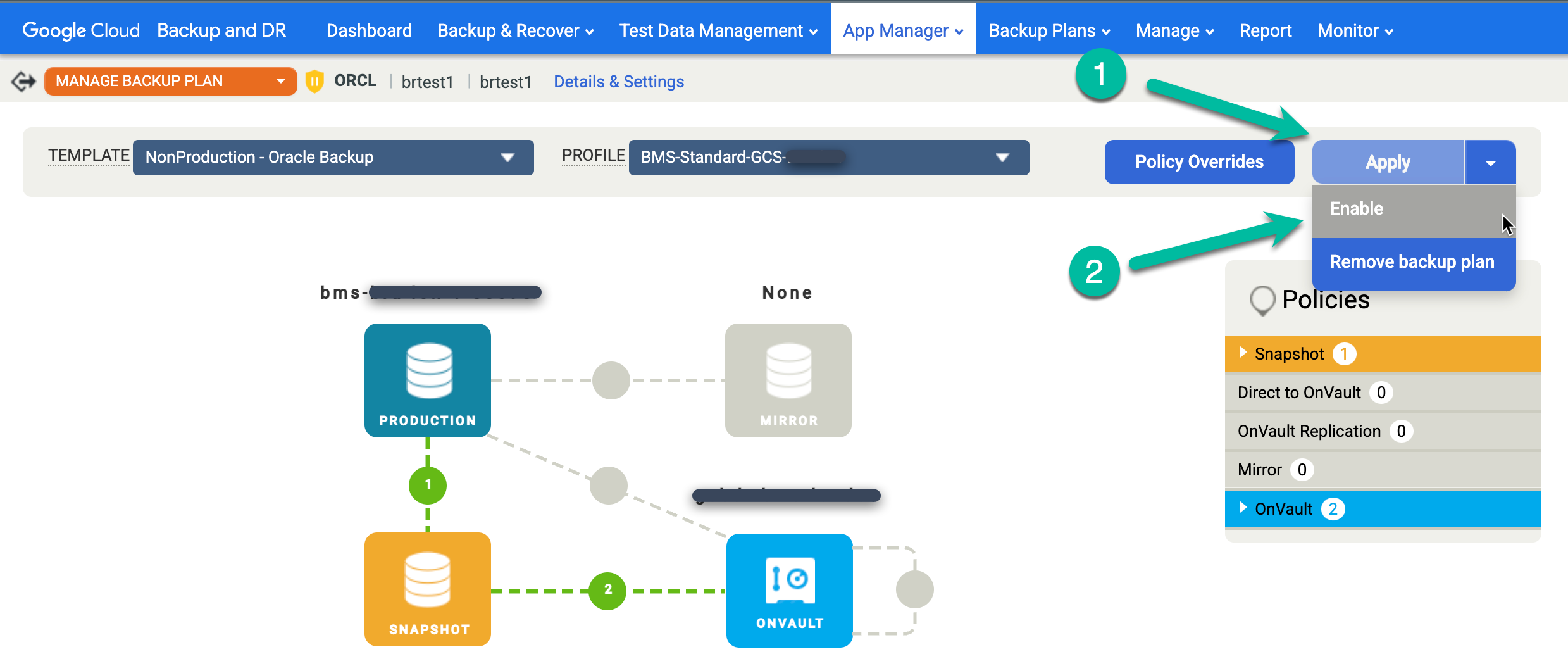
Reaktivieren Sie den geplanten Sicherungsjob für die wiederhergestellte Datenbank.
- Klicken Sie auf das Menü Übernehmen und wählen Sie Aktivieren aus.
Bestätigen Sie alle erweiterten Oracle-Einstellungen und klicken Sie auf Sicherungsplan aktivieren.
Fehlerbehebung und Optimierung
Dieser Abschnitt enthält einige hilfreiche Tipps zur Fehlerbehebung bei Oracle-Sicherungen, zur Optimierung Ihres Systems und zu Anpassungen für RAC- und Data Guard-Umgebungen.
Fehlerbehebung bei Oracle-Sicherungen
Oracle-Konfigurationen enthalten eine Reihe von Abhängigkeiten, damit die Sicherungsaufgabe erfolgreich ausgeführt wird. In den folgenden Schritten finden Sie mehrere Vorschläge zum Konfigurieren der Oracle-Instanzen, Listener und Datenbanken, um den Erfolg zu gewährleisten.
Führen Sie den Befehl
lsnrctl statusaus, um zu prüfen, ob der Oracle-Listener für den Dienst und die Instanz, die Sie schützen möchten, konfiguriert ist und ausgeführt wird:[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
Prüfen Sie, ob Sie die Oracle-Datenbank im Modus ARCHIVELOG konfiguriert haben. Wenn die Datenbank in einem anderen Modus ausgeführt wird, werden möglicherweise fehlgeschlagene Jobs mit der Meldung Fehlercode 5556 angezeigt:
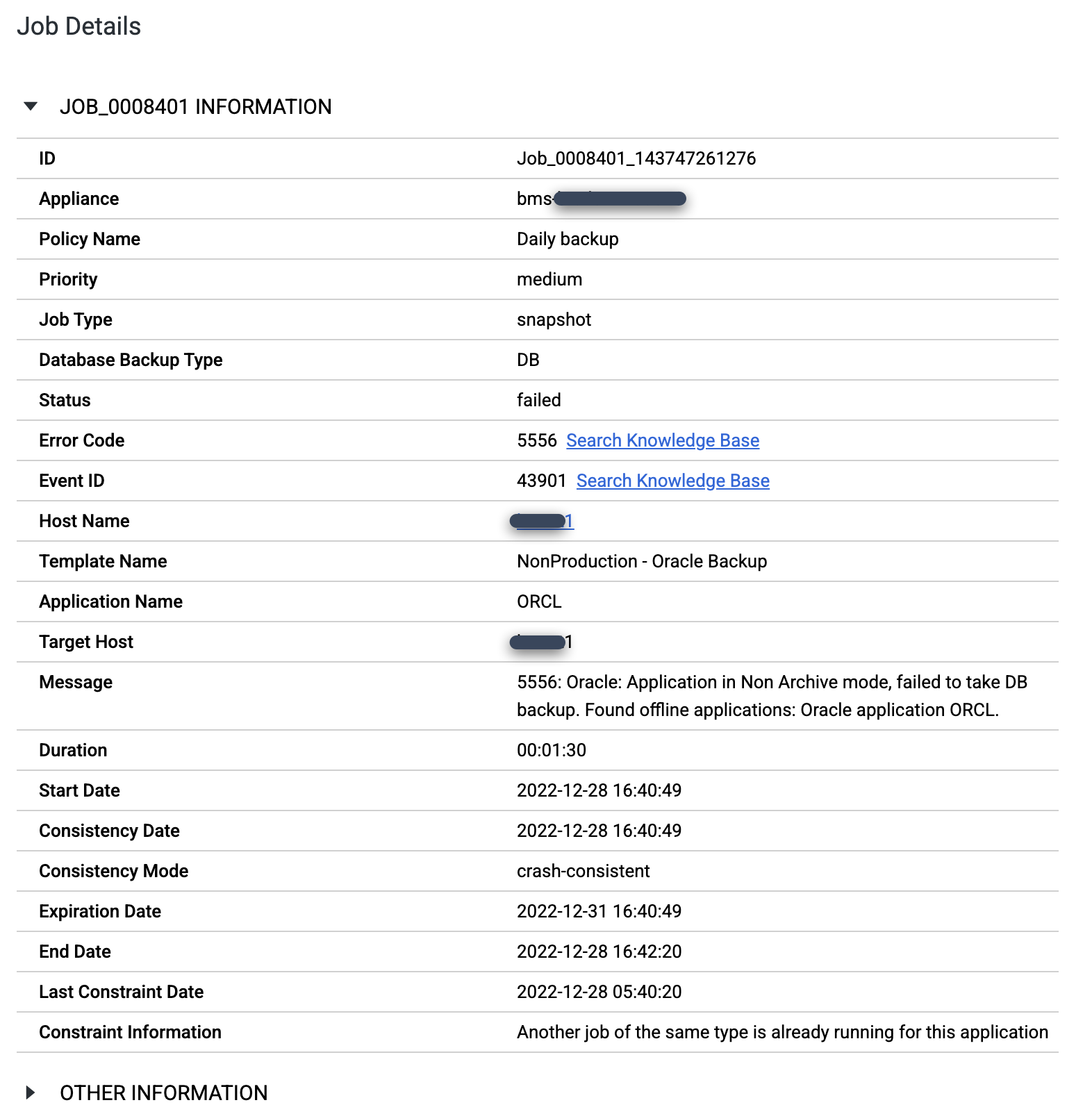
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Aktivieren Sie die Blockänderungsverfolgung für die Oracle-Datenbank. Das ist zwar nicht zwingend erforderlich, damit die Lösung funktioniert, aber durch die Aktivierung der Blockänderungsüberwachung muss nicht so viel Nachbearbeitung erfolgen, um geänderte Blöcke zu berechnen. Außerdem werden die Backup-Jobzeiten verkürzt:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Prüfen Sie, ob die Datenbank
spfileverwendet:sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Aktivieren Sie Direct NFS (dnfs) für Oracle-Datenbankhosts. dnfs ist zwar nicht zwingend erforderlich, aber die bevorzugte Wahl, wenn Sie die schnellste Methode zum Sichern und Wiederherstellen der Oracle-Datenbanken benötigen. Um den Durchsatz noch weiter zu verbessern, können Sie das Staging-Laufwerk pro Host ändern und DNFS für Oracle aktivieren.
Konfigurieren Sie tnsnames für die Auflösung für Oracle-Datenbankhosts. Wenn Sie diese Einstellung nicht angeben, schlagen RMAN-Befehle oft fehl. Hier ein Beispiel für die Ausgabe:
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
Das Feld
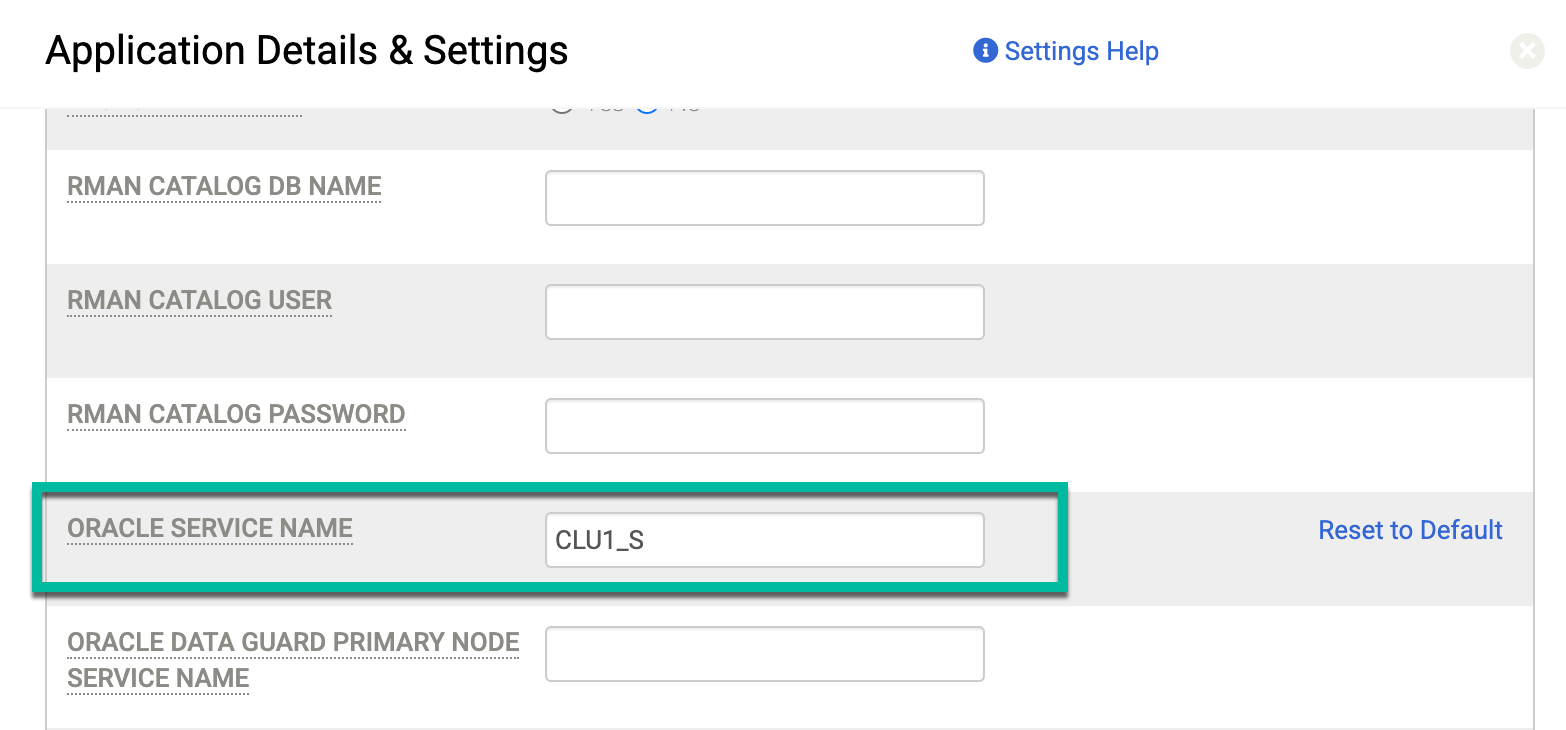
SERVICE_NAMEist für RAC-Konfigurationen wichtig. Der Dienstname ist der Alias, der verwendet wird, um das System für externe Ressourcen zu bewerben, die mit dem Cluster kommunizieren. Verwenden Sie in den Optionen Details und Einstellungen für die geschützte Datenbank die erweiterte Einstellung für den Oracle-Dienstnamen. Geben Sie den Namen des Dienstes ein, den Sie auf den Knoten verwenden möchten, auf denen der Sicherungsjob ausgeführt wird.Die Oracle-Datenbank verwendet den Dienstnamen nur für die Datenbankauthentifizierung. Die Datenbank verwendet den Dienstnamen nicht für die Betriebssystemauthentifizierung. Der Datenbankname könnte beispielsweise CLU1_S und der Instanzname CLU1_S sein.
Wenn der Oracle-Dienstname nicht aufgeführt ist, erstellen Sie auf dem Server bzw. den Servern in der Datei „tnsnames.ora“ unter
$ORACLE_HOME/network/adminoder$GRID_HOME/network/admineinen Dienstnameneintrag, indem Sie den folgenden Eintrag hinzufügen:CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) Wenn sich die Datei „tnsnames.ora“ an einem nicht standardmäßigen Speicherort befindet, geben Sie den absoluten Pfad zur Datei auf der Seite Anwendungsdetails und ‑einstellungen an, die unter Anwendungsdetails und ‑einstellungen für Oracle-Datenbanken konfigurieren beschrieben wird.
Prüfen Sie, ob Sie den Dienstnameneintrag für die Datenbank richtig konfiguriert haben. Melden Sie sich bei Oracle Linux an und konfigurieren Sie die Oracle-Umgebung:
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
Prüfen Sie das Datenbanknutzerkonto, um eine erfolgreiche Verbindung zur Backup and DR-Anwendung sicherzustellen:
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Geben Sie auf der Seite Application Details and Settings (Anwendungsdetails und ‑einstellungen), die unter Anwendungsdetails und ‑einstellungen für Oracle-Datenbanken beschrieben wird, den von Ihnen erstellten Dienstnamen (CLU1_S) in das Feld Oracle Service Name (Oracle-Dienstname) ein:
Fehlercode 870 besagt, dass „ASM-Backups mit ASM auf NFS-Staging-Festplatten nicht unterstützt werden“. Wenn Sie diesen Fehler erhalten, ist in Details und Einstellungen für die Instanz, die Sie schützen möchten, nicht die richtige Einstellung konfiguriert. Bei dieser Fehlkonfiguration verwendet der Host NFS für die Staging-Festplatte, die Quelldatenbank wird jedoch auf ASM ausgeführt.

Um dieses Problem zu beheben, setzen Sie das Feld ASM-Format in Dateisystemformat konvertieren auf Ja. Führen Sie den Sicherungsjob nach dem Ändern dieser Einstellung noch einmal aus.
Fehlercode 15 gibt an, dass das Backup and DR-System keine Verbindung zum Sicherungshost herstellen konnte. Wenn Sie diese Fehlermeldung erhalten, deutet das auf eines von drei Problemen hin:
- Die Firewall zwischen der Sicherungs-/Wiederherstellungs-Appliance und dem Host, auf dem Sie den Agent installiert haben, lässt den TCP-Port 5106 (den Agent-Listener-Port) nicht zu.
- Sie haben den Agent nicht installiert.
- Der Agent wird nicht ausgeführt.
Konfigurieren Sie die Firewalleinstellungen nach Bedarf neu und sorgen Sie dafür, dass der Agent funktioniert, um dieses Problem zu beheben. Führen Sie nach dem Beheben der Ursache den Befehl
service udsagent statusaus. Das folgende Beispiel zeigt, dass der Backup and DR-Agent-Dienst korrekt ausgeführt wird:[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
Logmeldungen aus Ihren Backups können Ihnen bei der Diagnose von Problemen helfen. Sie können auf die Logs auf dem Quellhost zugreifen, auf dem die Sicherungsjobs ausgeführt werden. Für Oracle-Datenbanksicherungen sind im Verzeichnis
/var/act/logzwei Hauptprotokolldateien verfügbar:- UDSAgent.log:Google Cloud Das Backup and DR-Agent-Log, in dem API-Anfragen, Statistiken zu laufenden Jobs und andere Details aufgezeichnet werden.
- SID_rman.log: Oracle RMAN-Logbuch, in dem alle RMAN-Befehle aufgezeichnet werden.
Zusätzliche Überlegungen zu Oracle
Wenn Sie Backup and DR für Oracle-Datenbanken implementieren, sollten Sie die folgenden Aspekte berücksichtigen, wenn Sie Data Guard und RAC bereitstellen.
Überlegungen zu Data Guard
Sie können sowohl primäre als auch Stand-by-Data Guard-Knoten sichern. Wenn Sie jedoch Datenbanken nur von den Standby-Knoten aus schützen möchten, müssen Sie bei der Sicherung der Datenbank Oracle Database Authentication anstelle der Betriebssystemauthentifizierung verwenden.
Hinweise zu RAC
Die Backup and DR-Lösung unterstützt keine gleichzeitige Sicherung von mehreren Knoten in einer RAC-Datenbank, wenn die Staging-Festplatte auf den NFS-Modus eingestellt ist. Wenn Ihr System eine gleichzeitige Sicherung von mehreren RAC-Knoten erfordert, verwenden Sie Block (iSCSI) als Staging-Laufwerkmodus und legen Sie diesen pro Host fest.
Bei einer Oracle RAC-Datenbank mit ASM müssen Sie die Snapshot-Steuerdatei auf den freigegebenen Laufwerken ablegen. Stellen Sie eine Verbindung zu RMAN her und führen Sie den Befehl show all aus, um diese Konfiguration zu überprüfen:
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
In einer RAC-Umgebung müssen Sie die Snapshot-Steuerdatei einer freigegebenen ASM-Laufwerksgruppe zuordnen. Weisen Sie die Datei mit dem Befehl Configure Snapshot Controlfile Name der ASM-Laufwerksgruppe zu:
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
Empfehlungen
Je nach Ihren Anforderungen müssen Sie möglicherweise Entscheidungen in Bezug auf bestimmte Funktionen treffen, die sich auf die Gesamtlösung auswirken. Einige Entscheidungen können sich auf den Preis auswirken, was wiederum die Leistung beeinflussen kann. Das ist beispielsweise der Fall, wenn Sie nichtflüchtige Standardspeicher (pd-standard) oder leistungsstarke nichtflüchtige Speicher (pd-ssd) für die Snapshot-Pools der Sicherungs-/Wiederherstellungs-Appliance auswählen.
In diesem Abschnitt finden Sie unsere Empfehlungen, mit denen Sie eine optimale Leistung für den Durchsatz von Oracle-Datenbanksicherungen erzielen können.
Optimalen Maschinentyp und Persistent Disk-Typ auswählen
Wenn Sie eine Sicherungs-/Wiederherstellungs-Appliance mit einer Anwendung wie einem Dateisystem oder einer Datenbank verwenden, können Sie die Leistung daran messen, wie schnell die Daten der Hostinstanz zwischen den Compute Engine-Instanzen übertragen werden.
- Die Geschwindigkeiten von Compute Engine-Persistent Disk-Geräten basieren auf drei Faktoren: dem Maschinentyp, der Gesamtspeichermenge, die an die Instanz angehängt ist, und der Anzahl der vCPUs der Instanz.
- Die Anzahl der vCPUs in einer Instanz bestimmt die einer Compute Engine-Instanz zugewiesene Netzwerkgeschwindigkeit. Die Geschwindigkeit reicht von 1 Gbit/s für eine gemeinsam genutzte vCPU bis zu 16 Gbit/s für 8 oder mehr vCPUs.
- In Kombination mit diesen Limits wird standardmäßig der Maschinentyp e2-standard-16 für eine Sicherungs-/Wiederherstellungs-Appliance in Standardgröße verwendet. Google Cloud Von hier aus haben Sie drei Möglichkeiten für die Festplattenzuweisung:
Choice |
Pool-Laufwerk |
Maximale Anzahl von Schreibvorgängen |
Maximale Anzahl von Lesezugriffen |
Minimal |
10 GB |
– |
– |
Standard |
4.096 GB |
400 MiB/s |
1.200 MiB/s |
SSD |
4.096 GB |
1.000 MiB/s |
1.200 MiB/s |
Compute Engine-Instanzen nutzen bis zu 60% ihres zugewiesenen Netzwerks für E/A-Vorgänge auf ihren angehängten Persistent Disks und reservieren 40% für andere Zwecke. Weitere Informationen finden Sie unter Andere Faktoren, die sich auf die Leistung auswirken.
Empfehlung: Wenn Sie einen Maschinentyp e2-standard-16 und mindestens 4096 GB an PD-SSD auswählen, erhalten Sie die beste Leistung für Sicherungs-/Wiederherstellungsgeräte. Als zweite Option können Sie den Maschinentyp n2-standard-16 für Ihre Sicherungs-/Wiederherstellungs-Appliance auswählen. Diese Option bietet zusätzliche Leistungsvorteile im Bereich von 10–20 %, ist aber mit zusätzlichen Kosten verbunden. Wenn dies Ihrem Anwendungsfall entspricht, wenden Sie sich an Cloud Customer Care, um diese Änderung vorzunehmen.
Schnappschüsse optimieren
Um die Produktivität einer einzelnen Sicherungs-/Wiederherstellungs-Appliance zu steigern, können Sie gleichzeitig Snapshot-Jobs aus mehreren Quellen ausführen. Jeder einzelne Job wird langsamer. Bei genügend Jobs können Sie jedoch die Obergrenze für das kontinuierliche Schreiben für die nichtflüchtigen Speicher-Volumes im Snapshot-Pool erreichen.
Wenn Sie iSCSI für die Staging-Festplatte verwenden, können Sie eine einzelne große Instanz auf einem Sicherungs-/Wiederherstellungsgerät mit einer anhaltenden Schreibgeschwindigkeit von etwa 300–330 MB/s sichern. In unseren Tests hat sich gezeigt, dass dies für alles von 2 TB bis zu 80 TB in einem Snapshot gilt, vorausgesetzt, dass Sie sowohl den Quellhost als auch die Sicherungs-/Wiederherstellungs-Appliance in einer optimalen Größe konfigurieren und sie sich in derselben Region und Zone befinden.
Die richtige Staging-Festplatte auswählen
Wenn Sie eine hohe Leistung und einen hohen Durchsatz benötigen, kann Direct NFS im Vergleich zu iSCSI als Staging-Laufwerk für Oracle-Datenbanksicherungen einen erheblichen Vorteil bieten. Bei Direct NFS wird die Anzahl der TCP-Verbindungen konsolidiert, was die Skalierbarkeit und Netzwerkleistung verbessert.
Wenn Sie Direct NFS für eine Oracle-Datenbank aktivieren, konfigurieren Sie ausreichend Quell-CPU (z. B. 8 vCPUs und 8 RMAN-Channels) und stellen Sie eine 10-GB-Verbindung zwischen Ihrer regionalen Erweiterung der Bare-Metal-Lösung und Google Cloudher. So können Sie eine einzelne Oracle-Datenbank mit einem erhöhten Durchsatz von 700–900 MB/s und mehr sichern. Auch die RMAN-Wiederherstellungsgeschwindigkeit profitiert von Direct NFS. Hier können Sie Durchsatzwerte von 850 MB/s und mehr erreichen.
Kosten und Durchsatz in Einklang bringen
Außerdem ist es wichtig zu wissen, dass alle Sicherungsdaten im komprimierten Format im Snapshot-Pool der Appliance für Sicherung und Wiederherstellung gespeichert werden, um die Kosten zu senken. Die Leistungseinbußen durch diese Komprimierung sind gering. Bei verschlüsselten Daten (TDE) oder stark komprimierten Datasets ist jedoch wahrscheinlich ein messbarer, wenn auch geringfügiger Einfluss auf Ihre Durchsatzwerte zu erwarten.
Faktoren, die sich auf die Leistung des Netzwerks und der Sicherungsserver auswirken
Die folgenden Elemente wirken sich auf die Netzwerk-E/A zwischen Oracle auf Bare-Metal-Lösung und Ihren Sicherungsservern in Google Cloudaus:
Flash-Speicher
Ähnlich wie bei Google Cloud nichtflüchtigem Speicher werden die E/A-Funktionen der Flash-Speicherarrays, die den Speicher für Bare-Metal-Lösungssysteme bereitstellen, je nach der Menge des Speichers, den Sie dem Host zuweisen, erhöht. Je mehr Speicherplatz Sie zuweisen, desto besser ist die E/A. Für konsistente Ergebnisse empfehlen wir, mindestens 8 TB Flash-Speicher bereitzustellen.
Netzwerklatenz
Google Cloud Backup- und DR-Sicherungsjobs reagieren empfindlich auf die Netzwerklatenz zwischen den Bare-Metal-Lösung-Hosts und dem Sicherungs-/Wiederherstellungsgerät in Google Cloud. Kleine Latenzerhöhungen können zu großen Änderungen bei den Sicherungs- und Wiederherstellungszeiten führen. Verschiedene Compute Engine-Zonen bieten unterschiedliche Netzwerklatenzen für die Bare-Metal-Lösungshosts. Es empfiehlt sich, jede Zone zu testen, um den optimalen Standort für die Sicherungs-/Wiederherstellungs-Appliance zu ermitteln.
Anzahl der verwendeten Prozessoren
Die Bare-Metal-Lösungsserver sind in verschiedenen Größen verfügbar. Wir empfehlen, die RMAN-Channels an die verfügbaren CPUs anzupassen. Bei größeren Systemen ist eine höhere Geschwindigkeit möglich.
Cloud Interconnect
Die Hybridverbindung zwischen der Bare-Metal-Lösung und Google Cloud ist in verschiedenen Größen verfügbar, z. B. mit 5 Gbit/s, 10 Gbit/s und 2 × 10 Gbit/s. Die Option mit 2 × 10 GB bietet die volle Leistung. Es ist auch möglich, eine dedizierte Interconnect-Verbindung zu konfigurieren, die ausschließlich für Sicherungs- und Wiederherstellungsvorgänge verwendet wird. Diese Option wird Kunden empfohlen, die ihren Sicherungstraffic von Datenbank- oder Anwendungstraffic isolieren möchten, der möglicherweise über dieselbe Verbindung läuft, oder die volle Bandbreite garantieren möchten, wenn Sicherungs- und Wiederherstellungsvorgänge kritisch sind, um das Recovery Point Objective (RPO) und das Recovery Time Objective (RTO) zu erreichen.
Weitere Informationen
Hier finden Sie einige zusätzliche Links und Informationen zu Google Cloud Backup & DR, die für Sie hilfreich sein könnten.
- Weitere Schritte zum Einrichten von Google Cloud Backup and DR finden Sie in der Produktdokumentation zu Backup and DR.
- Produktinstallationen und Funktionsdemonstrationen finden Sie in der Videoplaylist zu Google Cloud Backup and DR.
- Kompatibilitätsinformationen für Google Cloud Backup & DR finden Sie in der Supportmatrix: Backup & DR. Es ist wichtig, dass Sie unterstützte Versionen von Linux und Oracle-Datenbankinstanzen verwenden.
- Weitere Schritte zum Schutz von Oracle-Datenbanken finden Sie unter Backup and DR for Oracle Databases und Protect a discovered Oracle database.
- Dateisysteme wie NFS, CIFS, ext3 und ext4 können auch mitGoogle Cloud Backup and DR geschützt werden. Die verfügbaren Optionen finden Sie unter Sicherungsplan zum Schutz eines Dateisystems anwenden.
- Informationen zum Aktivieren von Benachrichtigungen für Google Cloud Backup and DR finden Sie unter Logbasierte Benachrichtigungen konfigurieren und im Video Google Cloud Backup and DR Alert Notifications setup.
- Wenn Sie eine Supportanfrage stellen möchten, wenden Sie sich an Cloud Customer Care.