Auf dieser Seite wird beschrieben, wie Sie mithilfe der Merkmalwichtigkeit Einblick in die Vorhersagen des Modells erhalten.
Weitere Informationen zu AI-Erklärungen finden Sie unter Einführung in AI-Erklärungen für AI Platform.
Einleitung
Wenn Sie ein ML-Modell verwenden, um Geschäftsentscheidungen zu treffen, ist es wichtig zu verstehen, wie Ihre Trainingsdaten zum endgültigen Modell beigetragen haben und wie das Modell zu individuellen Vorhersagen gelangt ist. Mit diesem Verständnis können Sie sicherstellen, dass Ihr Modell fair und genau ist.
AutoML Tables zeigt die Wichtigkeit von Merkmalen, manchmal auch als Featureattribute bezeichnet. So können Sie sehen, welche Merkmale am meisten zum Modelltraining (Wichtigkeit von Modellfunktionen) und zu individuellen Vorhersagen (Wichtigkeit lokaler Funktionen) beigetragen haben.
AutoML Tables berechnet die Merkmalwichtigkeit mithilfe der Stichproben-Shapley-Methode. Weitere Informationen zur Erklärung von Modellen finden Sie unter Einführung in KI-Erläuterungen.
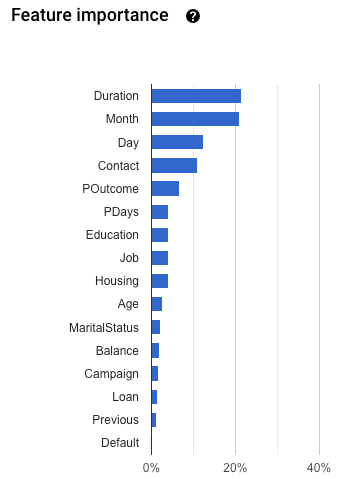
Wichtigkeit des Modellfeatures
Mithilfe der Merkmalwichtigkeit des Models können Sie gewährleisten, dass die für das Modelltraining verwendeten Features für Ihre Daten- und Geschäftsprobleme sinnvoll sind. Alle Features mit einer hohen Merkmalwichtigkeit sollten ein gültiges Signal für die Vorhersage darstellen und konsistent in Ihren Vorhersageanfragen enthalten sein.
Die Merkmalwichtigkeit wird für jedes Element als Prozentsatz angegeben: Je höher der Prozentsatz, desto stärker hat sich das Merkmal auf das Modelltraining ausgewirkt.
Merkmalwichtigkeit abrufen
Console
So rufen Sie die Werte der Featurewichtigkeit Ihres Modells in der Google Cloud Console auf:
Rufen Sie in der Google Cloud Console die Seite „AutoML Tables“ auf.
Wählen Sie im linken Navigationsbereich den Tab Model (Modell) aus und klicken Sie auf das Modell, für das die Bewertungsmesswerte abgerufen werden sollen.
Öffnen Sie den Tab Evaluate (Bewerten).
Scrollen Sie nach unten zum Diagramm Merkmalwichtigkeit.
REST
Verwenden Sie die Methode model.get, um die Merkmalwichtigkeit für ein Modell abzurufen.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. -
model-id: Die ID des Modells, für das Sie die Informationen zur Merkmalwichtigkeit abrufen möchten.
Beispiel:
TBL543.
HTTP-Methode und URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
Senden Sie die Anfrage mithilfe einer der folgenden Optionen:
curl
Führen Sie folgenden Befehl aus:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
Führen Sie folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Node.js
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Python
Die Clientbibliothek für AutoML Tables enthält zusätzliche Python-Methoden, die die Verwendung der AutoML Tables API vereinfachen. Diese Methoden verweisen auf Datasets und Modelle anhand des Namens und nicht der ID. Dataset- und Modellnamen dürfen nur einmal vorkommen. Weitere Informationen finden Sie in der Kundenreferenz.
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Wichtigkeit von lokalem Feature
Die lokale Merkmalwichtigkeit gibt Ihnen Aufschluss darüber, wie sich die einzelnen Funktionen in einer bestimmten Vorhersageanfrage auf die resultierende Vorhersage ausgewirkt haben.
Zuerst wird der Basis-Vorhersagewert berechnet, um den Wert jeder lokalen Merkmalwichtigkeit zu ermitteln. Die Basiswerte werden aus den Trainingsdaten berechnet, wobei der Medianwert für numerische Features und der Modus für kategoriale Features verwendet werden. Die aus den Basiswerten generierte Vorhersage ist der Basis-Vorhersagewert.
Bei Klassifizierungsmodellen gibt die lokale Merkmalwichtigkeit an, wie stark jedes Merkmal der Wahrscheinlichkeit, die der Klasse mit der höchsten Punktzahl zugewiesen ist, im Vergleich zum Basis-Vorhersagewert hinzugefügt oder davon abgezogen wurde. Die Punktzahlwerte liegen zwischen 0,0 und 1,0. Die lokale Merkmalwichtigkeit für Klassifizierungsmodelle liegt also immer zwischen -1,0 und 1,0 (einschließlich).
Bei Regressionsmodellen gibt die lokale Merkmalwichtigkeit für eine Vorhersage an, wie viel die einzelnen Features zum Ergebnis im Vergleich zum Basis-Vorhersagewert hinzuaddiert oder davon abgezogen haben.
Die lokale Merkmalwichtigkeit ist sowohl für Online- als auch für Batchvorhersagen verfügbar.
Lokale Merkmalwichtigkeit für Onlinevorhersagen abrufen
Console
Führen Sie die Schritte unter Onlinevorhersage abrufen aus, um lokale Merkmalwichtigkeitswerte für eine Onlinevorhersage mit der Google Cloud Console abzurufen. Klicken Sie dabei das Kästchen Merkmalwichtigkeit generieren an.

REST
Um die lokale Merkmalwichtigkeit für eine Onlinevorhersageanfrage zu ermitteln, verwenden Sie die Methode model.predict und setzen den Parameter feature_importance auf "true".
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. - model-id: Die ID des Modells. Beispiel:
TBL543. - valueN: Die Werte für jede Spalte in der richtigen Reihenfolge.
HTTP-Methode und URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
JSON-Text der Anfrage:
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
Wenn eine Spalte bei der Merkmalwichtigkeit einen Wert von 0 aufweist, wird die Merkmalwichtigkeit für diese Spalte nicht angezeigt.
Java
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Node.js
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Python
Die Clientbibliothek für AutoML Tables enthält zusätzliche Python-Methoden, die die Verwendung der AutoML Tables API vereinfachen. Diese Methoden verweisen auf Datasets und Modelle anhand des Namens und nicht der ID. Dataset- und Modellnamen dürfen nur einmal vorkommen. Weitere Informationen finden Sie in der Kundenreferenz.
Wenn sich Ihre Ressourcen in der EU-Region befinden, müssen Sie den Endpunkt explizit festlegen. Weitere Informationen
Lokale Merkmalwichtigkeit für Batchvorhersagen abrufen
Console
Wenn Sie über die Google Cloud Console lokale Merkmalwichtigkeitswerte für eine Batchvorhersage abrufen möchten, führen Sie die Schritte unter Batchvorhersage anfordern aus. Klicken Sie dabei das Kästchen Merkmalwichtigkeit generieren an.
Die Merkmalwichtigkeit eines Elements wird zurückgegeben, indem für jedes Element eine neue Spalte namens feature_importance.<feature_name> hinzugefügt wird.
REST
Verwenden Sie die Methode model.batchPredict, um die lokale Merkmalwichtigkeit für eine Batchvorhersageanfrage zu ermitteln und den Parameter feature_importance auf "true" zu setzen.
Im folgenden Beispiel wird BigQuery für die Anfragedaten und die Ergebnisse verwendet. verwenden Sie denselben zusätzlichen Parameter für Anfragen mit Cloud Storage.
Bevor Sie die Anfragedaten verwenden, ersetzen Sie die folgenden Werte:
-
endpoint:
automl.googleapis.comfür den globalen Standort undeu-automl.googleapis.comfür die EU-Region. - project-id ist Ihre Google Cloud-Projekt-ID.
- location: Der Standort für die Ressource:
us-central1für global odereufür die EU. - model-id: Die ID des Modells. Beispiel:
TBL543. - dataset-id: die ID des BigQuery-Datasets, in dem sich die Vorhersagedaten befinden.
-
table-id: Die ID der BigQuery-Tabelle, in der sich die Vorhersagedaten befinden.
AutoML Tables erstellt in project-id.dataset-id.table-id einen Unterordner mit dem Namen
prediction-<model_name>-<timestamp>für die Vorhersageergebnisse.
HTTP-Methode und URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
JSON-Text der Anfrage:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
Wenn Sie die Anfrage senden möchten, wählen Sie eine der folgenden Optionen aus:
curl
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Speichern Sie den Anfragetext in einer Datei mit dem Namen request.json und führen Sie den folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Die Merkmalwichtigkeit eines Elements wird zurückgegeben, indem für jedes Element eine neue Spalte namens feature_importance.<feature_name> hinzugefügt wird.
Überlegungen zur Verwendung lokaler Merkmalwichtigkeit:
Die Ergebnisse für die lokale Merkmalwichtigkeit sind nur für Modelle verfügbar, die am oder nach dem 15. November 2019 trainiert wurden.
Das Aktivieren der lokalen Merkmalwichtigkeit für eine Batchvorhersageanfrage mit mehr als 1.000.000 Zeilen oder 300 Spalten wird nicht unterstützt.
Jeder Wert für die lokale Merkmalwichtigkeit zeigt nur an, wie stark sich das Feature auf die Vorhersage für diese Zeile auswirkt. Um das Gesamtverhalten des Modells zu verstehen, verwenden Sie die Merkmalwichtigkeit für Modelle.
Werte für lokale Merkmalwichtigkeit sind immer relativ zum Basiswert. Achten Sie darauf, dass Sie den Ausgangswert referenzieren, wenn Sie die Ergebnisse der lokalen Merkmalwichtigkeit bewerten. Der Referenzwert ist nur in der Google Cloud Console verfügbar.
Die Werte der lokalen Merkmalwichtigkeit hängen vollständig vom Modell und den Daten ab, die zum Trainieren des Modells verwendet werden. Sie können nur die Muster erkennen, die in den Daten gefunden wurden, und keine grundlegenden Beziehungen in den Daten erkennen. Das Vorhandensein einer hohen Merkmalwichtigkeit für ein bestimmtes Feature zeigt also keine Beziehung zwischen diesem Feature und dem Ziel. Es zeigt lediglich, dass das Modell das Feature in seinen Vorhersagen verwendet.
Wenn eine Vorhersage Daten enthält, die vollständig außerhalb des Bereichs der Trainingsdaten liegen, liefert die lokale Merkmalwichtigkeit möglicherweise keine aussagekräftigen Ergebnisse.
Das Erstellen einer Merkmalwichtigkeit erhöht die für Ihre Vorhersage erforderlichen Zeit- und Rechenressourcen. Darüber hinaus wird für Ihre Anfrage ein anderes Kontingent verwendet als für Vorhersageanfragen ohne Merkmalwichtigkeit. Weitere Informationen
Werte der Merkmalwichtigkeit allein sagen nicht aus, ob Ihr Modell fair, unvoreingenommen oder von guter Qualität ist. Sie sollten zusätzlich zur Merkmalwichtigkeit Ihr Trainings-Dataset, die Verfahrens- und Bewertungsmesswerte sorgfältig abwägen.