Artifact Registry no monitoriza los registros de terceros para detectar actualizaciones de las imágenes que copies en Artifact Registry. Si quieres incorporar una versión más reciente de una imagen a tu canalización, debes enviarla a Artifact Registry.
Información general sobre la migración
La migración de tus imágenes de contenedor incluye los siguientes pasos:
- Configura los requisitos previos.
- Identifica las imágenes que quieras migrar.
- Busca en tus archivos Dockerfile y manifiestos de implementación referencias a registros de terceros.
- Determina la frecuencia de extracción de imágenes de registros de terceros mediante Cloud Logging y BigQuery.
- Copia las imágenes identificadas en Artifact Registry.
- Verifica que los permisos del registro estén configurados correctamente, sobre todo si Artifact Registry y tu entorno de implementación de Google Cloudestán en proyectos diferentes.
- Actualiza los manifiestos de tus implementaciones.
- Vuelve a desplegar tus cargas de trabajo.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
-
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
- Si no tienes un repositorio de Artifact Registry, sigue estos pasos: Crea un repositorio. Configura la autenticación para los clientes de terceros que necesiten acceder al repositorio.
- Verifica tus permisos. Debes tener el rol de gestión de identidades y accesos Propietario o Editor en los proyectos a los que vas a migrar imágenes de Artifact Registry.
- Exporta las siguientes variables de entorno:
export PROJECT=$(gcloud config get-value project)
- Comprueba que tienes instalada la versión 1.13 de Go o una posterior.
go version - En el directorio que contiene los manifiestos de GKE o Cloud Run, ejecuta el siguiente comando:
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1 - Para enumerar las imágenes que se están ejecutando en un clúster, ejecuta el siguiente comando:
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'
- image: nginx image: nginx:latest - image: nginx - image: nginx -
En la Google Cloud consola, ve a la página Explorador de registros:
Ve al Explorador de registros.
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Registro.
Elige un Google Cloud proyecto.
En la pestaña Creador de consultas, introduce la siguiente consulta:
resource.type="k8s_pod" jsonPayload.reason="Pulling"Cambie el filtro del historial de cambios de Última hora a Últimos 7 días.
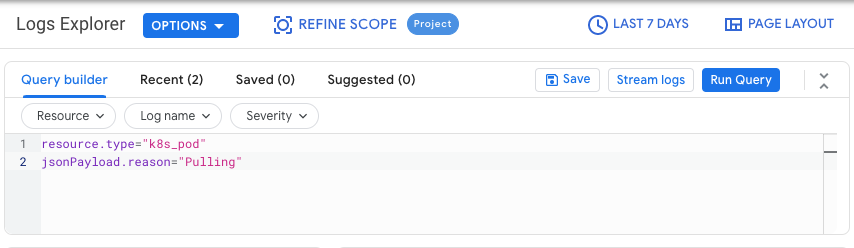
Haz clic en Ejecutar consulta.
Después de verificar que los resultados se muestran correctamente, haz clic en Acciones > Crear receptor.
En el cuadro de diálogo Detalles del receptor, haga lo siguiente:
- En el campo Nombre del receptor, introduce
image_pull_logs. - En Descripción del receptor, introduce una descripción del receptor.
- En el campo Nombre del receptor, introduce
Haz clic en Siguiente.
En el cuadro de diálogo Destino del sumidero, selecciona los siguientes valores:
- En el campo Select Sink service (Seleccionar servicio de receptor), selecciona BigQuery dataset (Conjunto de datos de BigQuery).
- En el campo Seleccionar conjunto de datos de BigQuery, selecciona Crear un conjunto de datos de BigQuery y completa la información necesaria en el cuadro de diálogo que se abre. Para obtener más información sobre cómo crear un conjunto de datos de BigQuery, consulta el artículo Crear conjuntos de datos.
- Haz clic en Crear conjunto de datos.
Haz clic en Siguiente.
En la sección Seleccionar los registros que se incluirán en el sumidero, la consulta coincide con la consulta que ha ejecutado en la pestaña Generador de consultas.
Haz clic en Siguiente.
Opcional: Elige los registros que se excluirán del sumidero. Para obtener más información sobre cómo consultar y filtrar datos de Cloud Logging, consulta el lenguaje de consultas de registro.
Haz clic en Crear sumidero.
Se ha creado el receptor de registro.
Ejecuta los siguientes comandos en Cloud Shell:
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' donedonde
- PROJECT-LIST es una lista de IDs de proyectos Google Cloud separados por espacios. Por ejemplo,
project1 project2 project3. - DATASET-PROJECT es el proyecto en el que quieres almacenar el conjunto de datos.
- DATASET-NAME es el nombre del conjunto de datos, por ejemplo,
image_pull_logs.
- PROJECT-LIST es una lista de IDs de proyectos Google Cloud separados por espacios. Por ejemplo,
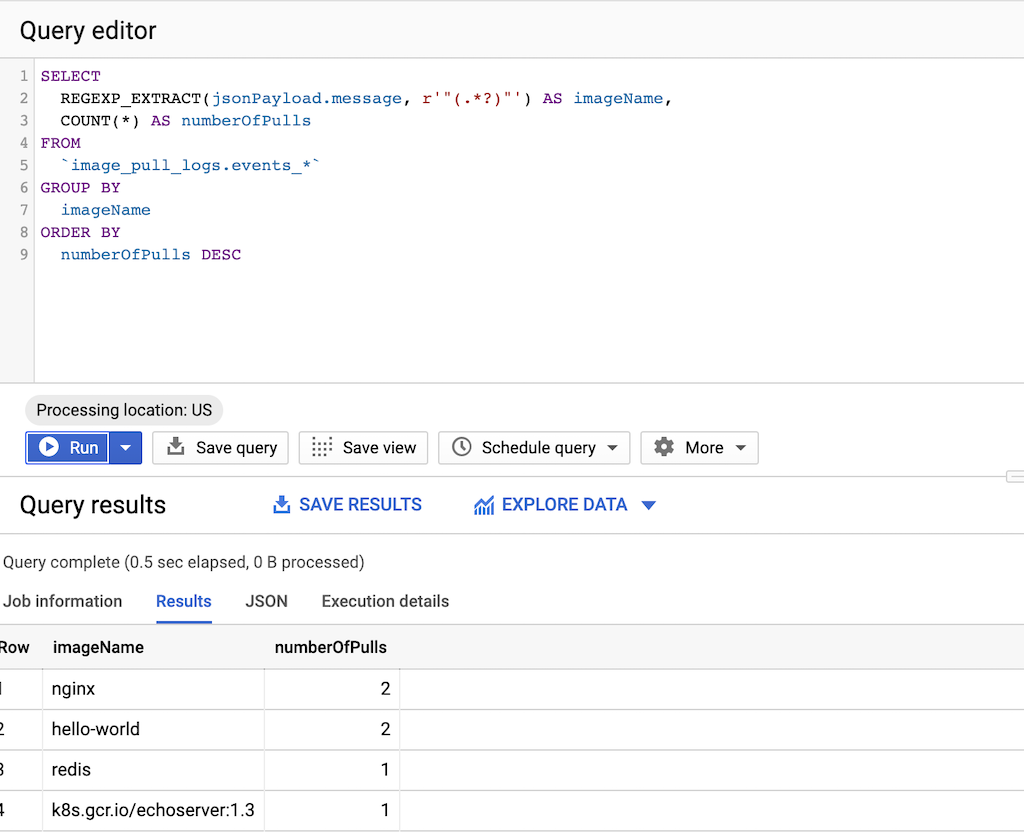
Ejecuta la siguiente consulta:
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCdonde
- DATASET-PROJECT es el proyecto que contiene el conjunto de datos.
- DATASET-NAME es el nombre del conjunto de datos.
Crea un archivo de texto
images.txtcon los nombres de las imágenes que has identificado. Por ejemplo:ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookDescarga gcrane.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneCrea una secuencia de comandos llamada
copy_images.shpara copiar tu lista de archivos.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} doneSustituye
LOCATIONpor la ubicación regional o multirregional del repositorio.Haz que la secuencia de comandos sea ejecutable:
chmod +x copy_images.shEjecuta la secuencia de comandos para copiar los archivos:
AR_PROJECT=${PROJECT} ./copy_images.sh
Costes
En esta guía se usan los siguientes componentes facturables de Google Cloud:
Identificar las imágenes que se van a migrar
Busca en los archivos que usas para compilar e implementar tus imágenes de contenedor referencias a registros de terceros y, a continuación, comprueba con qué frecuencia extraes las imágenes.
Identificar referencias en Dockerfiles
Realiza este paso en una ubicación donde se almacenen tus archivos Dockerfile. Puede que sea donde se haya extraído tu código de forma local o en Cloud Shell si los archivos están disponibles en una VM.En el directorio que contiene tus Dockerfiles, ejecuta el siguiente comando:
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
La salida tiene el siguiente aspecto:
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
Este comando busca todos los Dockerfiles de tu directorio e identifica la línea "FROM". Ajusta el comando según sea necesario para que coincida con la forma en que almacenas tus archivos Dockerfile.
Identificar referencias en manifiestos
Sigue estos pasos en la ubicación donde se almacenan tus manifiestos de GKE o Cloud Run. Puede que sea donde se haya extraído tu código localmente o en Cloud Shell si los archivos están disponibles en una VM.Ejecuta los comandos anteriores en todos los clústeres de GKE de todos los proyectosGoogle Cloud para obtener una cobertura total.
Identificar la frecuencia de extracción de un registro de terceros
En los proyectos que extraen datos de registros de terceros, use la información sobre la frecuencia de extracción de imágenes para determinar si su uso se acerca o supera los límites de frecuencia que aplique el registro de terceros.
Recoger datos de registro
Crea un sumidero de registros para exportar datos a BigQuery. Un sumidero de registros incluye un destino y una consulta que selecciona las entradas de registro que se van a exportar. Puedes crear un receptor consultando proyectos individuales o usar una secuencia de comandos para recoger datos de varios proyectos.
Para crear un receptor de un solo proyecto, sigue estos pasos:
Para crear un receptor para varios proyectos, sigue estos pasos:
Después de crear un receptor, los datos tardan en llegar a las tablas de BigQuery, en función de la frecuencia con la que se extraigan las imágenes.
Consulta sobre la frecuencia de extracción
Una vez que tengas una muestra representativa de las extracciones de imágenes que realizan tus compilaciones, ejecuta una consulta de frecuencia de extracción.
Copiar imágenes en Artifact Registry
Una vez que haya identificado las imágenes de los registros de terceros, podrá copiarlas en Artifact Registry. La herramienta gcrane te ayuda con el proceso de copia.
Verificar permisos
Asegúrate de que los permisos estén configurados correctamente antes de actualizar y volver a implementar tus cargas de trabajo.
Para obtener más información, consulta la documentación sobre el control de acceso.
Actualizar los manifiestos para que hagan referencia a Artifact Registry
Actualiza tus archivos Dockerfile y tus manifiestos para que hagan referencia a Artifact Registry en lugar del registro de terceros.
En el siguiente ejemplo se muestra un manifiesto que hace referencia a un registro de terceros:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Esta versión actualizada del archivo de manifiesto apunta a una imagen en us-docker.pkg.dev.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
Si tienes muchos manifiestos, usa sed u otra herramienta que pueda gestionar las actualizaciones de muchos archivos de texto.
Volver a desplegar cargas de trabajo
Vuelve a desplegar las cargas de trabajo con los manifiestos actualizados.
Para hacer un seguimiento de las nuevas extracciones de imágenes, ejecute la siguiente consulta en la consola de BigQuery:
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
Todas las nuevas extracciones de imágenes deben proceder de Artifact Registry y contener la cadena
docker.pkg.dev.