本文說明如何開始使用 R 在Google Cloud上大規模進行資料科學作業。本教學課程適合具備 R 和 Jupyter 筆記本使用經驗,且熟悉 SQL 的使用者。
本文著重於使用 Vertex AI Workbench 執行個體和 BigQuery 進行探索性資料分析。您可以在 GitHub 上的 Jupyter 筆記本中找到隨附程式碼。
總覽
R 是最廣泛使用的統計模型程式設計語言之一。Kaggle 擁有龐大且活躍的數據資料學家和機器學習 (ML) 專業人士社群。Comprehensive R Archive Network (CRAN) 的開放原始碼存放區中,有超過 20,000 個套件,因此 R 具備適用於所有統計資料分析應用程式、機器學習和視覺化作業的工具。R 的語法具有表達力,且資料和機器學習程式庫相當全面,因此在過去二十年來穩定成長。
身為資料科學家,您可能想瞭解如何運用 R 語言的技能,以及如何充分利用可擴充的全代管雲端服務,提升資料科學的優勢。
架構
在本逐步導覽中,您會使用 Vertex AI Workbench 執行個體做為資料科學環境,執行探索性資料分析 (EDA)。在本逐步導覽中,您會從 BigQuery (Google 的無伺服器雲端資料倉儲,具備高度擴充性與成本效益) 擷取資料,並使用 R 語言處理這些資料。分析及處理資料後,轉換後的資料會儲存在 Cloud Storage 中,以供後續可能的 ML 工作使用。這個流程如下圖所示:

範例資料
本文範例資料為 BigQuery 紐約市計程車車程資料集。這個公開資料集包含每年在紐約市發生的數百萬趟計程車行程資訊。本文使用 2022 年的資料,這些資料位於 BigQuery 的 bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 資料表中。
本文著重於 EDA,以及使用 R 和 BigQuery 進行視覺化。本文的步驟可協助您設定 ML 目標,根據行程的許多因素預測計程車車資 (不含稅金、費用和其他額外費用)。本文不包含實際建立模型的內容。
Vertex AI Workbench
Vertex AI Workbench 是一項服務,提供整合式 JupyterLab 環境,具備下列功能:
- 一鍵部署。只要按一下滑鼠,即可啟動預先設定最新機器學習和資料科學架構的 JupyterLab 執行個體。
- 視需求調度資源。您可以先使用小型機器設定 (例如本文件中的 4 個 vCPU 和 16 GB 的 RAM),當資料量過大而無法在一台機器上處理時,再新增 CPU、RAM 和 GPU 來擴充規模。
- Google Cloud 整合。Vertex AI Workbench 執行個體已整合 BigQuery 等服務 Google Cloud 。這項整合功能可簡化從資料擷取到預先處理和探索的流程。
- 即付即用計費:沒有最低費用門檻,也不需要預付任何費用,如需相關資訊,請參閱 Vertex AI Workbench 定價。此外,您還需要為筆記本中使用的 Google Cloud 資源付費 (例如 BigQuery 和 Cloud Storage)。
Vertex AI Workbench 執行個體筆記本會在深度學習 VM 映像檔上執行。本文說明如何建立搭載 R 4.3 的 Vertex AI Workbench 執行個體。
使用 R 處理 BigQuery 資料
BigQuery 不需要管理基礎架構,因此您可以專注於發掘有意義的洞察資料。您可以運用 BigQuery 豐富的 SQL 分析功能,大規模分析大量資料,並準備機器學習資料集。
如要使用 R 查詢 BigQuery 資料,可以採用開放原始碼 R 程式庫 bigrquery。bigrquery 套件在 BigQuery 基礎上提供下列抽象層級:
- 低階 API 會在基礎 BigQuery REST API 上提供精簡的包裝函式。
- DBI 介面會包裝低階 API,讓您使用 BigQuery 時,就像使用任何其他資料庫系統一樣。如果您想在 BigQuery 中執行 SQL 查詢,或上傳小於 100 MB 的檔案,這個層級最方便。
- dbplyr 介面可讓您將 BigQuery 資料表視為記憶體內資料框架。如果您不想編寫 SQL,而是想讓 dbplyr 為您編寫,這是最方便的層。
本文使用 bigrquery 的低階 API,不需 DBI 或 dbplyr。
目標
- 建立支援 R 的 Vertex AI Workbench 執行個體。
- 使用 bigrquery R 程式庫查詢及分析 BigQuery 資料。
- 在 Cloud Storage 中準備及儲存機器學習資料。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 前往 Google Cloud 控制台的「Workbench」頁面。
在「執行個體」分頁中,按一下 「建立新項目」。
在「New instance」(新執行個體) 視窗中,按一下「Create」(建立)。在本逐步解說中,請保留所有預設值。
Vertex AI Workbench 執行個體可能需要 2 到 3 分鐘才能啟動。準備就緒後,執行個體會自動列在「Notebook instances」(筆記本執行個體) 窗格中,且執行個體名稱旁會顯示「Open JupyterLab」(開啟 JupyterLab) 連結。如果幾分鐘後,清單中仍未顯示開啟 JupyterLab 的連結,請重新整理頁面。
在執行個體清單中,按一下「Open Jupyterlab」。瀏覽器會開啟新分頁,顯示 JupyterLab 環境。
在 JupyterLab 環境中,依序點選「New Launcher」和「Launcher」分頁標籤中的「Terminal」。
在終端機窗格中安裝 R:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2安裝期間,每次系統提示您繼續時,請輸入
y。安裝作業可能需要幾分鐘才會完成。安裝完成後,輸出內容會類似以下內容:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$其中 INSTANCE_NUMBER 是指派給 Vertex AI Workbench 執行個體的專屬編號。
終端機執行完畢後,請重新整理瀏覽器頁面,然後按一下「New Launcher」(新版啟動器) ,開啟啟動器。
「啟動器」分頁會顯示在筆記本或控制台中啟動 R 的選項,以及建立 R 檔案的選項。
按一下「Terminal」分頁標籤,然後複製 vertex-ai-samples GitHub 存放區:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git指令執行完畢後,您會在 JupyterLab 環境的檔案瀏覽器窗格中看到
vertex-ai-samples資料夾。在檔案瀏覽器中,依序開啟
vertex-ai-samples>notebooks>community>exploratory_data_analysis。您會看到eda_with_r_and_bigquery.ipynb筆記本。在檔案瀏覽器中,開啟
eda_with_r_and_bigquery.ipynb筆記本。這個筆記本將逐步說明如何使用 R 和 BigQuery 進行探索性資料分析。在本文件的其餘部分,您會在筆記本中作業,並執行 Jupyter 筆記本中顯示的程式碼。
查看筆記本使用的 R 版本:
version輸出內容中的
version.string欄位應顯示R version 4.3.2,這是您在上一個章節中安裝的項目。檢查並安裝必要的 R 封裝函式 (如果目前工作階段中尚未提供):
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }載入必要套件:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)使用頻外驗證方式驗證
bigrquery:bq_auth(use_oob = True)將
[YOUR-PROJECT-ID]替換為名稱,設定要用於這個筆記本的專案名稱:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"將
[YOUR-BUCKET-NAME]替換為全域不重複的名稱,設定要儲存輸出資料的 Cloud Storage bucket 名稱:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"設定稍後在筆記本中產生的繪圖預設高度和寬度:
options(repr.plot.height = 9, repr.plot.width = 16)建立 BigQuery SQL 陳述式,從行程樣本中擷取一些可能的預測因子和目標預測變數。下列查詢會篩除要讀取以進行分析的欄位中,部分離群值或無意義的值。
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "key資料欄是根據trip_distance和fare_amount資料欄的串連值產生的資料列 ID。執行查詢並擷取與記憶體內資料表相同的資料,這類似於資料框架。
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )查看擷取的結果:
head(taxi_trip_data)輸出內容會是類似下圖的表格:
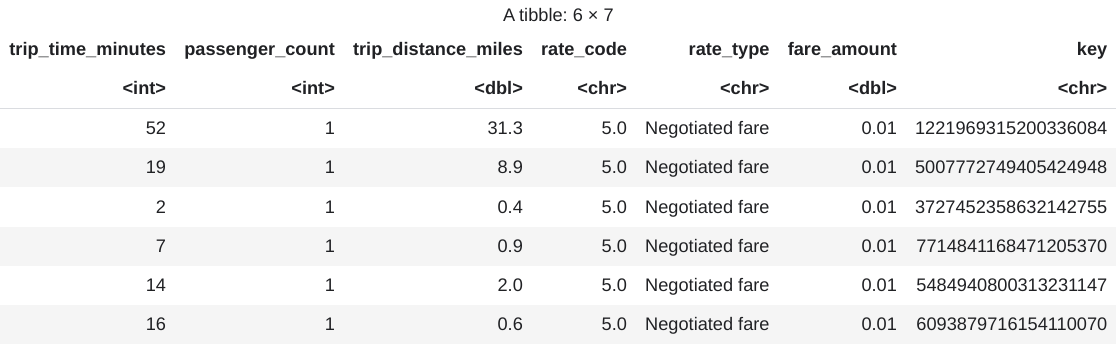
結果會顯示以下行程資料欄:
trip_time_minutes整數passenger_count整數trip_distance_miles二壘安打rate_code個字元rate_type個字元fare_amount二壘安打key個字元
查看各欄的列數和資料類型:
str(taxi_trip_data)輸出結果會與下列內容相似:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...查看擷取資料的摘要:
summary(taxi_trip_data)輸出結果會與下列內容相似:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50使用直方圖顯示
fare_amount值的分布情形:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)產生的圖表會類似下圖:
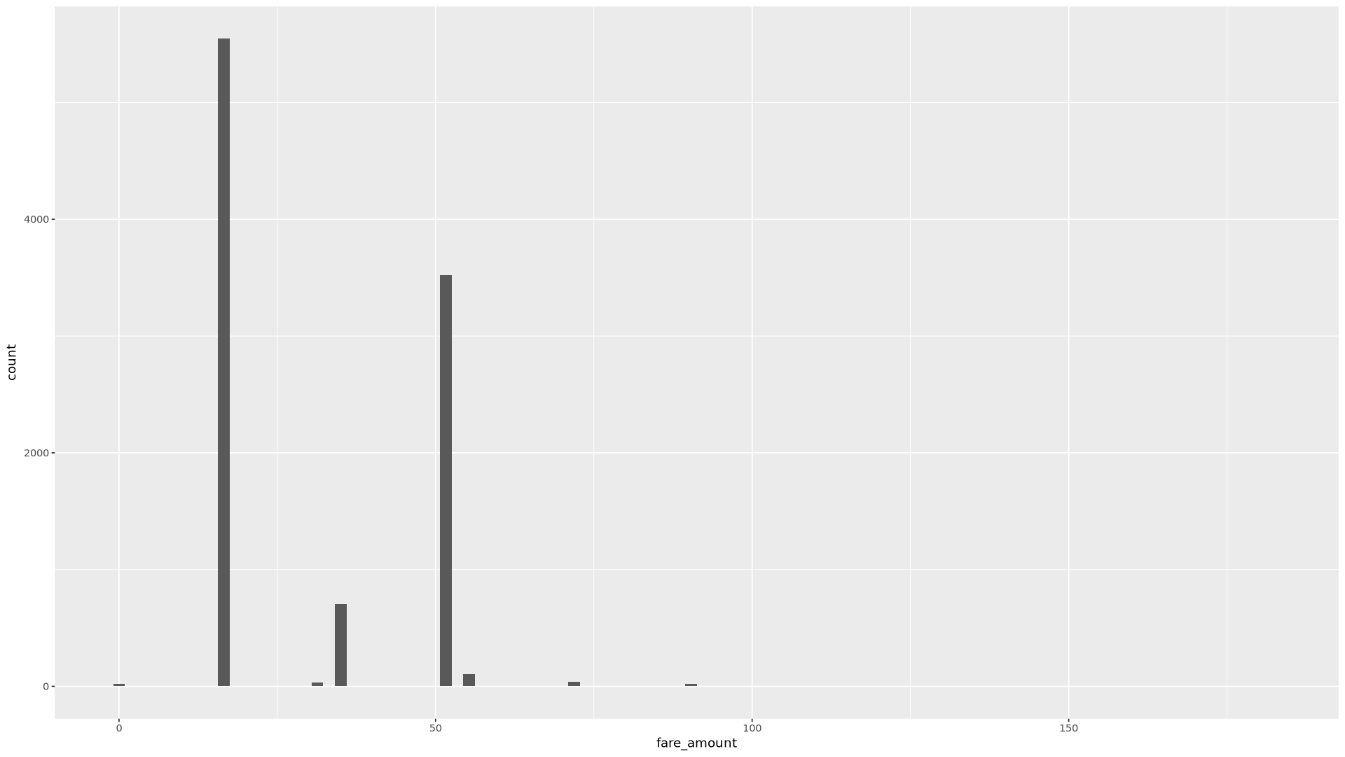
使用散布圖顯示「
trip_distance」和「fare_amount」之間的關聯:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")產生的圖表會類似下圖:
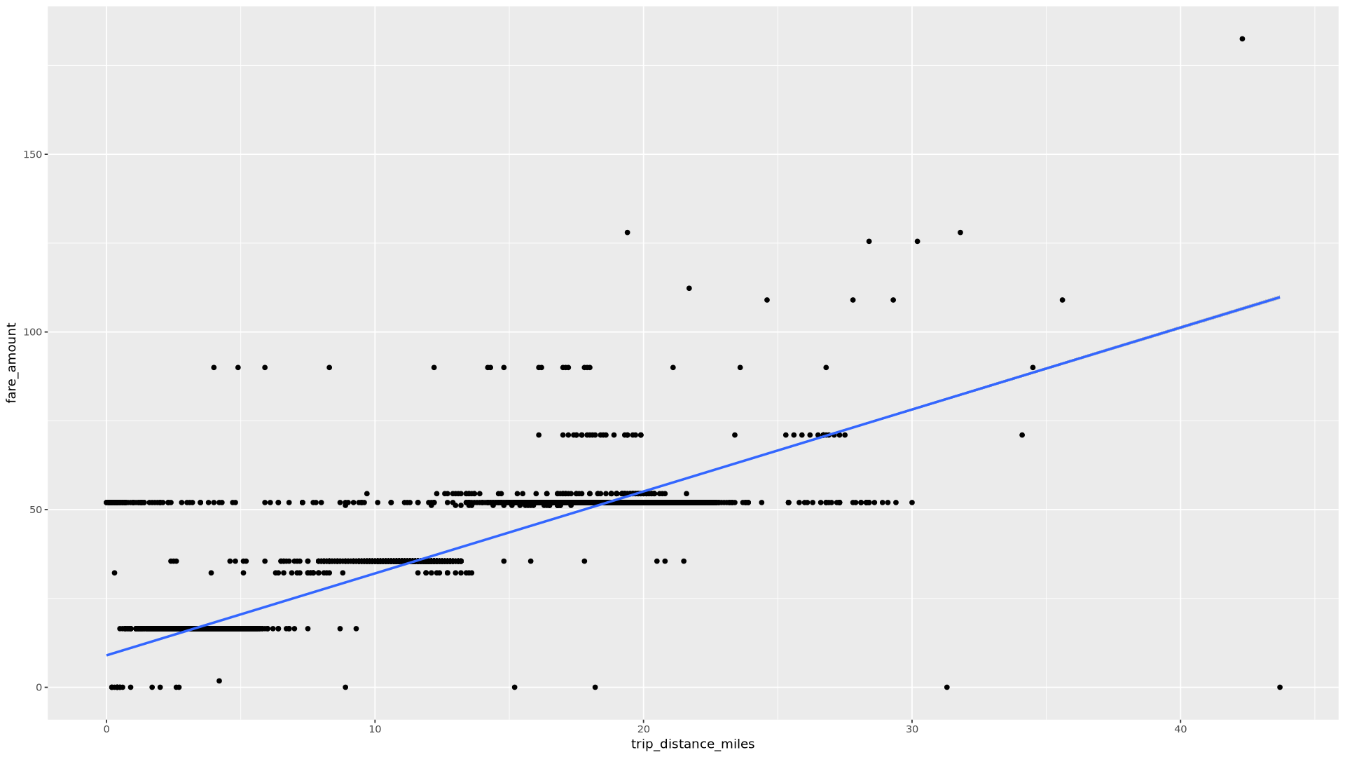
在筆記本中,建立函式來找出所選資料欄中每個值的行程數和平均車資金額:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }使用
trip_time_minutes欄叫用函式,該欄是使用 BigQuery 中的時間戳記功能定義:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()筆記本會顯示兩張圖表。第一個圖表會顯示各趟行程的長度 (以分鐘為單位)。第二張圖表顯示行程的平均車資金額 (依行程時間計算)。
第一個
ggplot指令的輸出內容如下,顯示按行程長度 (以分鐘為單位) 分類的行程數量: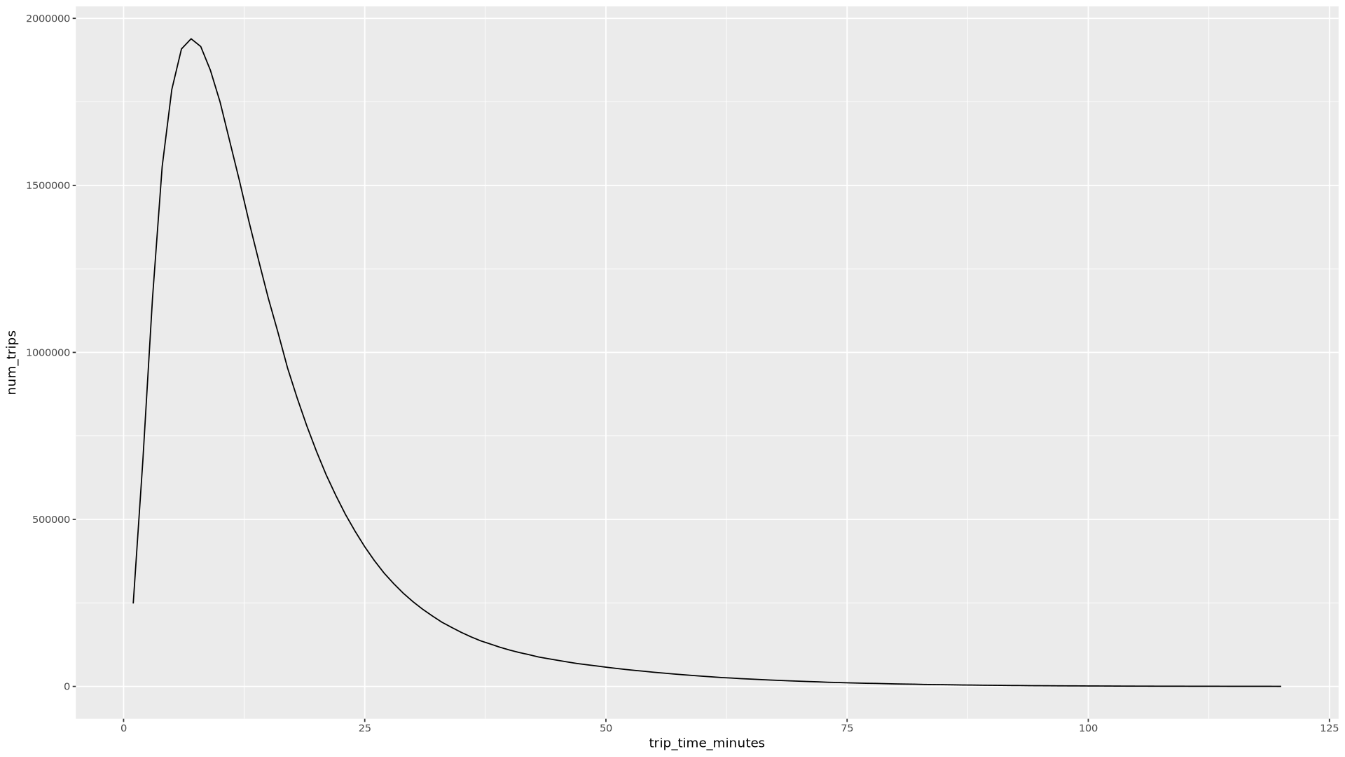
第二個
ggplot指令的輸出內容如下所示,顯示依行程時間計算的平均車資金額: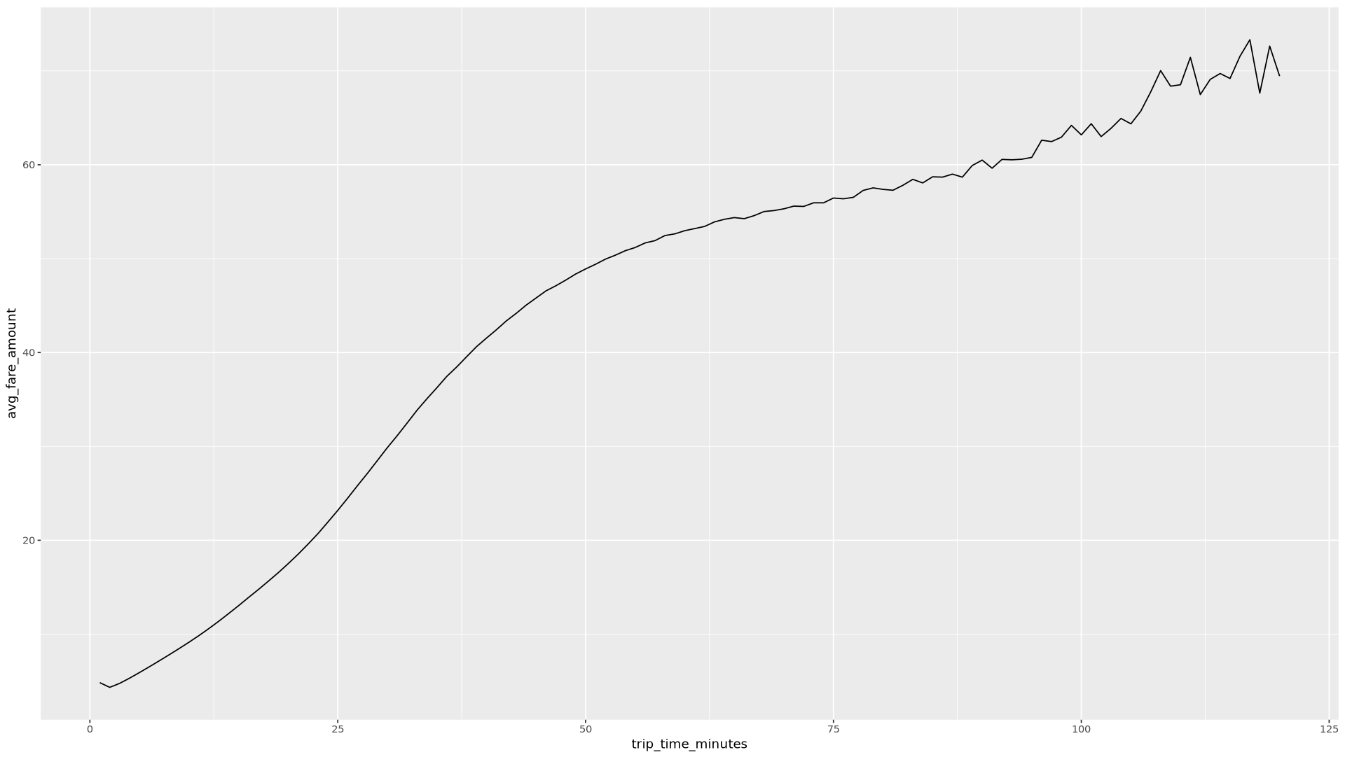
如要查看更多使用資料中其他欄位的視覺化範例,請參閱筆記本。
在筆記本中,將 BigQuery 中的訓練和評估資料載入 R:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )檢查每個資料集中的觀測值數量:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))大約 75% 的執行個體總數應用於訓練,其餘執行個體則大約有 25% 用於評估。
將資料寫入本機 CSV 檔案:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")將 CSV 檔案上傳至 Cloud Storage,方法是包裝傳遞至系統的
gsutil指令:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)您也可以使用 googleCloudStorageR 程式庫將 CSV 檔案上傳至 Cloud Storage,該程式庫會叫用 Cloud Storage JSON API。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如要進一步瞭解如何在 R 筆記本中使用 BigQuery 資料,請參閱 bigrquery 說明文件。
- 參閱機器學習的規則,瞭解機器學習工程的最佳做法。
- 如要瞭解適用於 Google Cloud中 AI 和機器學習工作負載的架構原則和建議,請參閱 Well-Architected Framework 中的AI 和機器學習觀點。
- 如要查看更多參考架構、圖表和最佳做法,請瀏覽 Cloud 架構中心。
- Jason Davenport | 開發人員服務代表
- Firat Tekiner | 資深產品經理
建立 Vertex AI Workbench 執行個體
第一步是建立 Vertex AI Workbench 執行個體,供您逐步完成本導覽課程。
開啟 JupyterLab 並安裝 R
如要在筆記本中完成導覽,您需要開啟 JupyterLab 環境、安裝 R、複製 vertex-ai-samples GitHub 存放區,然後開啟筆記本。
開啟筆記本並設定 R
查詢 BigQuery 資料
在本節的筆記本中,您會將執行 BigQuery SQL 陳述式的結果讀取到 R 中,並初步查看資料。
使用 ggplot2 製作資料圖表
在本節的筆記本中,您將使用 R 中的 ggplot2 程式庫,研究範例資料集中的部分變數。
從 R 處理 BigQuery 中的資料
處理大型資料集時,建議您盡可能在 BigQuery 中執行分析 (包括彙整、篩選、聯結、計算資料欄等),然後擷取結果。在 R 中執行這些工作效率較低。使用 BigQuery 進行分析可充分發揮 BigQuery 的擴充性和效能,並確保傳回的結果可放入 R 的記憶體中。
將資料儲存為 Cloud Storage 中的 CSV 檔案
下一個工作是將從 BigQuery 擷取的資料儲存為 Cloud Storage 中的 CSV 檔案,以便用於後續的機器學習工作。
您也可以使用 bigrquery,將資料從 R 寫回 BigQuery。通常在完成一些前置處理或產生結果後,會將資料寫回 BigQuery,以供進一步分析。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本文所用資源的費用,請將資源全數移除。
刪除專案
如要避免付費,最簡單的方法就是刪除您建立的專案。如想瞭解多種架構、教學課程或快速入門導覽課程,重複使用專案可避免超出專案配額限制。
後續步驟
貢獻者
作者:Alok Pattani | 開發人員服務代表
其他貢獻者: