本文档介绍如何在Google Cloud上使用 R 大规模开始进行数据科学研究。本文档面向拥有一定 R 和 Jupyter 笔记本经验且熟悉 SQL 的人员。
本文档重点介绍如何使用 Vertex AI Workbench 实例和 BigQuery 执行探索性数据分析。您可以在 GitHub 上的 Jupyter 笔记本中找到随附的代码。
概览
R 是统计建模中使用最广泛的编程语言之一。它拥有一个庞大的活跃数据科学家和机器学习 (ML) 专业人员社区。R 在综合 R 归档网络 (CRAN) 的开源代码库中拥有超过 20,000 个软件包,并且具有用于所有统计数据分析应用、机器学习和可视化的工具。在过去 20 年里,R 因其语法表现力及其数据和机器学习库的全面性而稳定增长。
作为数据科学家,您可能希望了解如何通过 R 使用技能集,以及如何充分利用数据科学的可伸缩全托管式云服务的优势。
架构
在此演练中,您将使用 Vertex AI Workbench 实例作为数据科学环境来执行探索性数据分析 (EDA)。您可将 R 用于在本演示中从 BigQuery(Google 的无服务器、可伸缩能力强且经济实惠的云数据仓库)提取的数据。分析和处理数据后,转换后的数据会存储在 Cloud Storage 中,以用于其他可能执行的机器学习任务。下图展示了此流程:

示例数据
本文档的示例数据是 BigQuery 纽约市出租车行程数据集。此公开数据集包含每年在纽约市发生的数百万次出租车行程的相关信息。在本文档中,您将使用 2022 年的数据,该数据位于 BigQuery 的 bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 表中。
本文档重点介绍 EDA 以及如何使用 R 和 BigQuery 进行可视化。本文档中的步骤可让您根据行程的多个因素设置机器学习目标,以预测出租车费金额(不含税费的金额、费用和其他额外费用)。本文档未介绍实际的模型创建过程。
Vertex AI Workbench
Vertex AI Workbench 是一项用于提供集成式 JupyterLab 环境的服务,具有以下功能:
- 一键式部署。您只需点击一下,即可启动预配置有最新机器学习和数据科学框架的 JupyterLab 实例。
- 按需扩缩。您可以从小型机器配置(例如,4 个 vCPU 和 16 GB RAM)开始,当数据量增长太多,一台机器已无法处理时,您可以添加 CPU、RAM 和 GPU 来纵向扩容。
- Google Cloud 集成。Vertex AI Workbench 实例与 BigQuery 等 Google Cloud 服务集成。通过此集成,您可以轻松进行数据注入、预处理和探索。
- 按用量计费。没有最低费用限制,也不要求预付费用。如需了解相关信息,请参阅 Vertex AI Workbench 的价格。 您还需要为笔记本中使用的 Google Cloud 资源(例如 BigQuery 和 Cloud Storage)付费。
Vertex AI Workbench 实例笔记本在 Deep Learning VM Image 映像上运行。本文档支持创建具有 R 4.3 的 Vertex AI Workbench 实例。
通过 R 使用 BigQuery
BigQuery 不需要基础架构管理,因此您可以专注于挖掘有意义的数据洞见。您可以使用 BigQuery 丰富的 SQL 分析功能大规模分析大量数据,并为机器学习准备数据集。
要使用 R 查询 BigQuery 数据,您可以使用 bigrquery(开源 R 库)。Bigrquery 软件包在 BigQuery 的基础上提供以下抽象层级:
- 低层级 API 在底层 BigQuery REST API 上提供瘦封装容器。
- DBI 接口可封装低层级 API,并让使用 BigQuery 与使用任何其他数据库系统类似。如果您希望在 BigQuery 中运行 SQL 查询或上传小于 100 MB 的数据,则这是最方便的层。
- dbplyr 接口让您可像处理内存中数据帧一样处理 BigQuery 表。如果您不想编写 SQL,而是希望 dbplyr 为您编写,则这是最方便的层。
本文档使用 bigrquery 中的低级层 API,而无需 DBI 或 dbplyr。
目标
- 创建支持 R 的 Vertex AI Workbench 实例。
- 使用 bigrquery R 库查询和分析 BigQuery 中的数据。
- 准备机器学习的数据并将其存储在 Cloud Storage 中。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
如需根据您的预计使用量来估算费用,请使用价格计算器。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 在 Google Cloud 控制台中,前往 Workbench 页面。
在实例标签页上,点击 新建。
在新实例窗口中,点击创建。在本演示中,请保留所有默认值。
Vertex AI Workbench 实例可能需要 2-3 分钟才能启动。准备就绪后,该实例会自动列在笔记本实例窗格中,并且实例名称旁边会显示打开 JupyterLab 链接。如果几分钟后,列表中仍未显示用于打开 JupyterLab 的链接,请刷新页面。
在实例列表中,点击打开 Jupyterlab。这将在浏览器中的另一个标签页中打开 JupyterLab 环境。
在 JupyterLab 环境中,点击 New Launcher,然后在启动器标签页上点击终端。
在终端窗格中,安装 R:
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2在安装过程中,每次看到继续提示时,都输入
y。安装可能需要几分钟才能完成。安装完成后,输出类似于以下内容:done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$其中,INSTANCE_NUMBER 是分配给 Vertex AI Workbench 实例的唯一编号。
命令在终端中执行完毕后,刷新浏览器页面,然后点击 New Launcher 打开启动器。
“启动器”标签页显示了在笔记本或控制台中启动 R 的选项,以及创建 R 文件的选项。
点击终端标签页,然后克隆 vertex-ai-samples GitHub 代码库:
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git命令完成后,您会在 JupyterLab 环境的文件浏览器窗格中看到
vertex-ai-samples文件夹。在文件浏览器中,依次打开
vertex-ai-samples>notebooks>community>exploratory_data_analysis。您会看到eda_with_r_and_bigquery.ipynb笔记本。在文件浏览器中,打开
eda_with_r_and_bigquery.ipynb笔记本。此笔记本介绍了如何使用 R 和 BigQuery 进行探索性数据分析。在本文档的其余部分中,您将在笔记本中工作,并运行在 Jupyter 笔记本中看到的代码。
检查笔记本使用的 R 版本:
version输出中的
version.string字段应显示您在上一个部分中安装的R version 4.3.2。检查并安装必要的 R 软件包(如果当前会话中尚无这些软件包):
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }加载所需的软件包:
# Load the required packages lapply(needed_packages, library, character.only = TRUE)使用带外身份验证对
bigrquery进行身份验证:bq_auth(use_oob = True)将
[YOUR-PROJECT-ID]替换为名称,设置您要为此笔记本使用的项目名称:# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"通过将
[YOUR-BUCKET-NAME]替换为全局唯一名称,设置用于存储输出数据的 Cloud Storage 存储桶的名称:BUCKET_NAME <- "[YOUR-BUCKET-NAME]"为稍后将在笔记本中生成的图表设置默认高度和宽度:
options(repr.plot.height = 9, repr.plot.width = 16)创建一个 BigQuery SQL 语句,以提取一些可能的预测器和目标预测变量,用于对部分行程进行预测。以下查询会过滤掉正在读入以进行分析的字段中的某些离群值或无意义值。
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "key列是根据trip_distance和fare_amount列的串联值生成的行标识符。运行查询并将相同的数据作为内存中 tibble(类似于数据框)检索。
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )查看检索到的结果:
head(taxi_trip_data)输出是一个类似于下图的表:

结果会显示以下列的行程数据:
trip_time_minutes整数passenger_count整数trip_distance_miles双精度rate_code个字符rate_type个字符fare_amount双精度key个字符
查看每列的行数和数据类型:
str(taxi_trip_data)输出内容类似如下:
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...查看检索到的数据摘要:
summary(taxi_trip_data)输出类似于以下内容:
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50使用直方图显示
fare_amount值的分布:ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)生成的图表类似于下图中的图表:
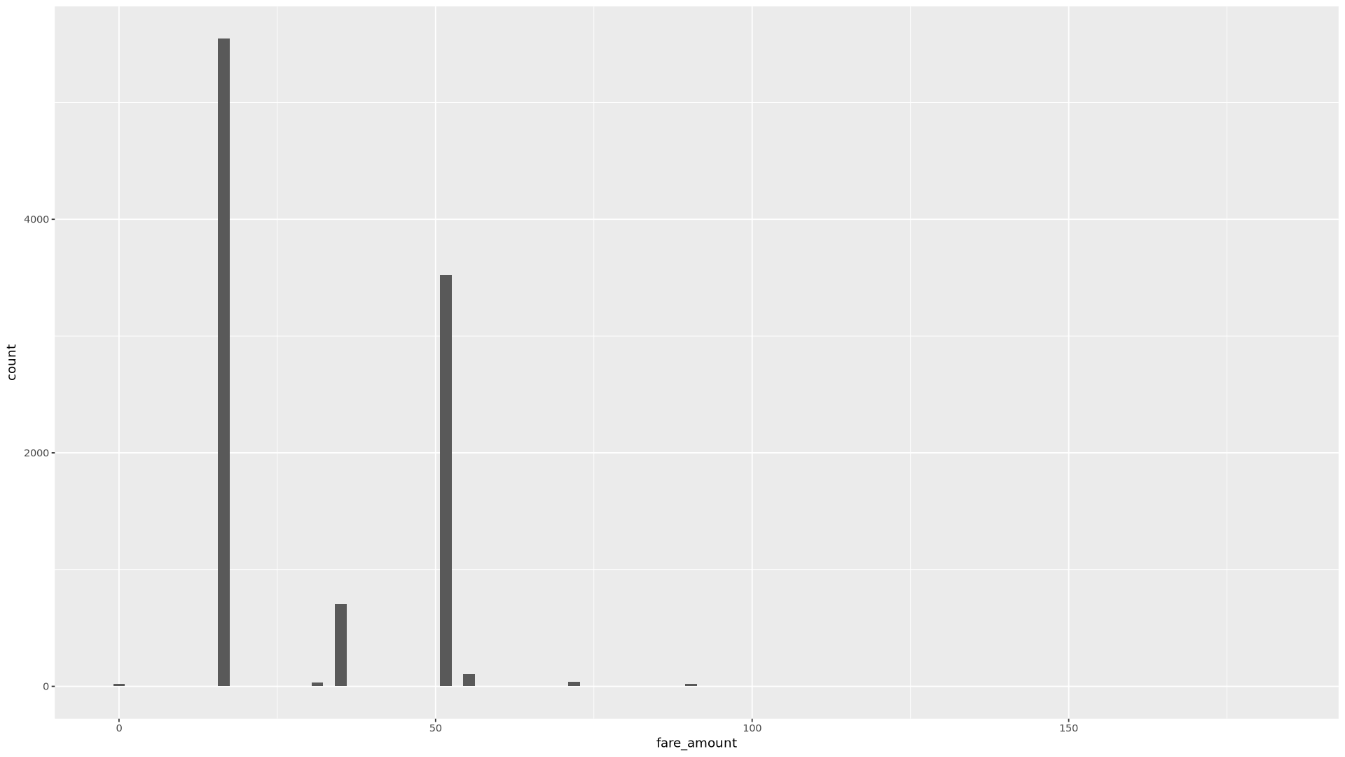
使用散点图显示
trip_distance和fare_amount之间的关系:ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")生成的图表类似于下图中的图表:
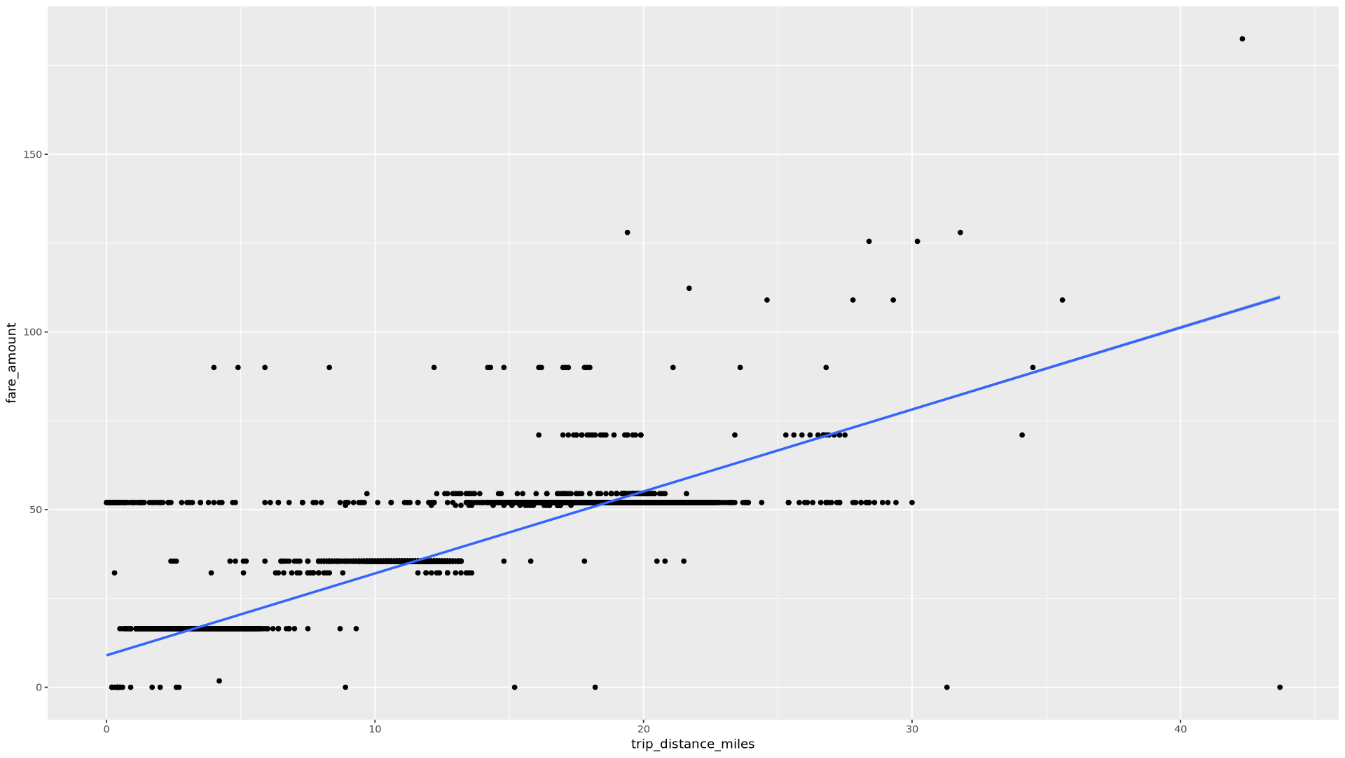
在笔记本中,创建一个函数,用于查找所选列的每个值的行程数和平均车费金额:
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }使用通过 BigQuery 中的时间戳功能定义的
trip_time_minutes列调用该函数:df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()笔记本显示了两个图表。第一个图表按行程时长(以分钟为单位)显示了行程数。第二个图表按行程时间显示了行程的平均车费金额。
第一个
ggplot命令的输出如下所示,其中按行程时长(以分钟为单位)显示了行程数: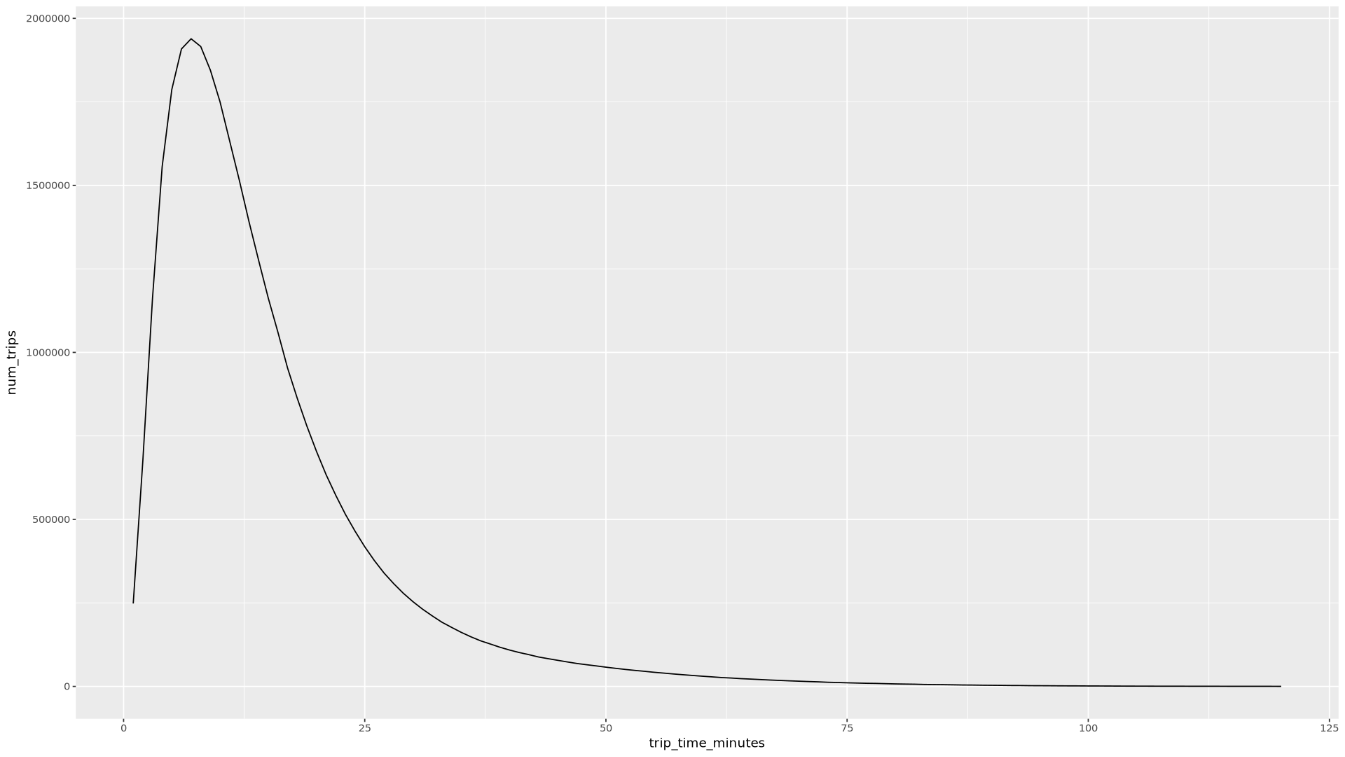
第二个
ggplot命令的输出如下所示,其中按行程时间显示了行程的平均车费金额:
如需查看包含数据中其他字段的更多可视化示例,请参阅笔记本。
在笔记本中,将训练和评估数据从 BigQuery 加载到 R 中:
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )检查每个数据集中的观测次数:
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))总实例中大约 75% 应用于训练,其余大约 25% 的实例用于评估。
将数据写入本地 CSV 文件:
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")通过封装传递给系统的
gsutil命令将 CSV 文件上传到 Cloud Storage:# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)您还可以使用 googleCloudStorageR 库(用于调用 Cloud Storage JSON API)将 CSV 文件上传到 Cloud Storage。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如需详细了解如何在 R 笔记本中使用 BigQuery 数据,请参阅 bigrquery 文档。
- 阅读机器学习规则,了解机器学习工程中的最佳做法。
- 如需简要了解 Google Cloud中特定于 AI 和机器学习工作负载的架构原则和建议,请参阅 Well-Architected Framework 中的 AI 和机器学习视角。
- 如需查看更多参考架构、图表和最佳实践,请浏览 Cloud 架构中心。
- Jason Davenport | 开发技术推广工程师
- Firat Tekiner | 高级产品经理
创建 Vertex AI Workbench 实例
第一步是创建可用于本演示的 Vertex AI Workbench 实例。
打开 JupyterLab 并安装 R
如需完成笔记本中的演示,您需要打开 JupyterLab 环境,安装 R,克隆 vertex-ai-samples GitHub 代码库,然后打开笔记本。
打开笔记本并设置 R
查询 BigQuery 中的数据
在本笔记本的这一部分中,您将读取将 BigQuery SQL 语句执行到 R 中的结果,并初步了解数据。
使用 ggplot2 直观呈现数据
在本笔记本的这一部分中,您将使用 R 中的 ggplot2 库研究示例数据集中的某些变量。
从 R 处理 BigQuery 中的数据
在处理大型数据集时,我们建议您在 BigQuery 中执行尽可能多的分析(聚合、过滤、联接、计算列等),然后检索结果。在 R 中执行这些任务的效率较低。使用 BigQuery 进行分析可利用 BigQuery 的可伸缩性和性能,并确保返回的结果能够适合 R 中的内存。
将数据另存为 CSV 文件到 Cloud Storage
下一个任务是将提取的数据从 BigQuery 保存为 Cloud Storage 中的 CSV 文件,以便将其用于其他机器学习任务。
您还可以使用 bigrquery 将 R 中的数据写回 BigQuery。通常,在完成一些预处理或生成要用于进一步分析的结果后,将数据写回 BigQuery。
清理
为避免因本文档中使用的资源导致您的 Google Cloud 账号产生费用,您应该移除这些资源。
删除项目
为了避免产生费用,最简单的方法是删除您创建的项目。如果您打算探索多个架构、教程或快速入门,则重复使用项目可以帮助您避免超出项目配额上限。
后续步骤
贡献者
作者:Alok Pattani | 开发技术推广工程师
其他贡献者: