Ce tutoriel explique comment utiliser la data science à grande échelle avec R surGoogle Cloud. Il est destiné aux personnes qui maîtrisent le langage R et les notebooks Jupyter, et qui sont familiarisées avec SQL.
Ce document porte sur l'analyse exploratoire des données à l'aide des instances Vertex AI Workbench et de BigQuery. Vous trouverez le code associé dans un notebook Jupyter disponible sur GitHub.
Présentation
R est l'un des langages de programmation les plus couramment utilisés pour la modélisation statistique. Il dispose d'une vaste et active communauté de data scientists et de professionnels du machine learning (ML). Avec plus de 20 000 packages dans le dépôt Open Source du Réseau d'archives R complet (CRAN), R comprend des outils pour toutes les applications d'analyse de données statistiques, le ML et la visualisation. L'utilisation de R fait l'objet d'une croissance exponentielle au cours des deux dernières décennies en raison de son expressivité de sa syntaxe et de l'étendue de ses données et de ses bibliothèques de ML.
En tant que data scientist, vous souhaiterez peut-être savoir comment utiliser vos compétences avec R et comment exploiter les avantages des services cloud entièrement gérés et évolutifs pour la data science.
Architecture
Dans ce tutoriel, vous allez utiliser des instances Vertex AI Workbench en tant qu'environnements de data science pour effectuer une analyse exploratoire des données (EDA). Vous utilisez le langage R sur les données que vous extrayez dans ce tutoriel à partir de BigQuery, l'entrepôt de données cloud sans serveur, hautement évolutif et économique de Google. Après avoir analysé et traité les données, les données transformées sont stockées dans Cloud Storage pour effectuer d'autres tâches de ML. Ce flux est illustré dans le schéma suivant :

Exemple de données
Les exemples de données de ce document proviennent de l'ensemble de données BigQuery sur les trajets en taxi à New York.
Cet ensemble de données public inclut des informations sur les millions de courses de taxi effectuées chaque année à New York. Dans ce document, vous allez utiliser les données de 2022, qui se trouvent dans la table bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022 de BigQuery.
Ce tutoriel se concentre sur l'EDA et sur la visualisation à l'aide de R et BigQuery. Les étapes décrites dans ce document vous préparent à un objectif de ML qui consiste à prédire le montant d'une course en taxi (le montant avant taxes, frais et autres suppléments), en fonction de plusieurs facteurs concernant le trajet. La création de modèles proprement dite n'est pas abordée dans ce document.
Vertex AI Workbench
Vertex AI Workbench est un service qui propose un environnement JupyterLab intégré, avec les fonctionnalités suivantes :
- Déploiement en un clic Vous pouvez utiliser un seul clic pour démarrer une instance JupyterLab préconfigurée avec les derniers frameworks de machine learning et de data science.
- Évolutivité à la demande Vous pouvez commencer avec une configuration de petite machine (par exemple, 4 processeurs virtuels et 16 Go de RAM, comme dans ce document). Lorsque vos données deviennent trop volumineuses pour une seule machine, vous pouvez augmenter le nombre de processeurs, de RAM et de GPU.
- Google Cloud integration. Les instances Vertex AI Workbench sont intégrées aux services Google Cloud tels que BigQuery. Cette intégration permet de passer facilement de l'ingestion de données au prétraitement, puis à l'exploration.
- Tarification à l'utilisation Il n'y a pas de frais minimums ni d'engagement préalable. Pour en savoir plus, consultez les tarifs de Vertex AI Workbench. Vous payez également les ressources Google Cloud que vous utilisez dans les notebooks (comme BigQuery et Cloud Storage).
Les notebooks d'instances Vertex AI Workbench s'exécutent sur Deep Learning VM Images. Ce document permet de créer une instance Vertex AI Workbench avec la version R 4.3.
Travailler avec BigQuery à l'aide de R
BigQuery ne nécessite pas de gestion d'infrastructure. Vous pouvez donc vous concentrer sur la découverte d'informations significatives. Vous pouvez analyser de grandes quantités de données à grande échelle et préparer des ensembles de données pour le ML à l'aide des fonctionnalités d'analyse SQL approfondies de BigQuery.
Pour interroger des données BigQuery à l'aide de R, vous pouvez utiliser bigrquery, une bibliothèque R Open Source. Le package bigrquery fournit les niveaux d'abstraction suivants en plus de BigQuery :
- L'API de bas niveau fournit des wrappers fins sur l 'API REST BigQuery sous-jacente.
- L'interface DBI encapsule l'API de bas niveau et rend l'utilisation de BigQuery semblable à celle de tout autre système de base de données. Il s'agit de la couche la plus pratique si vous souhaitez exécuter des requêtes SQL dans BigQuery ou importer moins de 100 Mo.
- L'interface dbplyr vous permet de traiter des tables BigQuery telles que des cadres de données en mémoire. Il s'agit de la couche la plus pratique si vous ne souhaitez pas écrire avec SQL et que vous souhaitez que dbplyr l'écrive pour vous.
Ce tutoriel utilise l'API de bas niveau de Bigrquery, sans avoir besoin de DBI ni de dbplyr.
Objectifs
- Créez une instance Vertex AI Workbench compatible avec R.
- Interrogez et analysez les données de BigQuery à l'aide de la bibliothèque Bigrquery R.
- Préparez et stockez des données pour le ML dans Cloud Storage.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
- BigQuery
- Vertex AI Workbench instances. You are also charged for resources used within notebooks, including compute resources, BigQuery, and API requests.
- Cloud Storage
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Dans la console Google Cloud , accédez à la page Workbench.
Dans l'onglet Instances, cliquez sur Créer.
Dans la fenêtre Nouvelle instance, cliquez sur Créer. Pour ce tutoriel, conservez toutes les valeurs par défaut.
Le démarrage de l'instance Vertex AI Workbench peut prendre deux à trois minutes. Lorsqu'elle est prête, l'instance est automatiquement listée dans le volet Instances de notebook, et un lien Ouvrir JupyterLab s'affiche à côté du nom de l'instance. Si le lien permettant d'ouvrir JupyterLab n'apparaît pas dans la liste au bout de quelques minutes, actualisez la page.
Dans la liste des instances, cliquez sur Ouvrir Jupyterlab. L'environnement JupyterLab s'ouvre dans un autre onglet de votre navigateur.
Dans l'environnement JupyterLab, cliquez sur Nouveau lanceur d'applications, puis sur l'onglet Lanceur d'applications, cliquez sur Terminal.
Dans le volet du terminal, installez R :
conda create -n r conda activate r conda install -c r r-essentials r-base=4.3.2Pendant l'installation, saisissez
ychaque fois que vous êtes invité à continuer. L'installation peut prendre quelques minutes. Une fois l'installation terminée, le résultat ressemble à ce qui suit :done Executing transaction: done ® jupyter@instance-INSTANCE_NUMBER:~$Où INSTANCE_NUMBER est le numéro unique attribué à votre instance Vertex AI Workbench.
Une fois les commandes exécutées dans le terminal, actualisez la page de votre navigateur, puis ouvrez le lanceur en cliquant sur Nouveau lanceur.
L'onglet "Launcher" (Lanceur) affiche des options permettant de lancer R dans un notebook ou dans la console, et de créer un fichier R.
Cliquez sur l'onglet Terminal, puis clonez le dépôt GitHub vertex-ai-samples :
git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.gitUne fois la commande terminée, le dossier
vertex-ai-sampless'affiche dans le volet de l'explorateur de fichiers de l'environnement JupyterLab.Dans l'explorateur de fichiers, ouvrez
vertex-ai-samples>notebooks>community>exploratory_data_analysis. Le notebookeda_with_r_and_bigquery.ipynbs'affiche.Dans l'explorateur de fichiers, ouvrez le notebook
eda_with_r_and_bigquery.ipynb.Ce notebook présente l'analyse exploratoire des données avec R et BigQuery. Dans le reste de ce document, vous travaillerez dans le notebook et exécuterez le code affiché dans le notebook Jupyter.
Vérifiez la version de R utilisée par le notebook :
versionLe champ
version.stringdans le résultat doit afficherR version 4.3.2, que vous avez installé dans la section précédente.Recherchez et installez les packages R nécessaires s'ils ne sont pas déjà disponibles dans la session actuelle :
# List the necessary packages needed_packages <- c("dplyr", "ggplot2", "bigrquery") # Check if packages are installed installed_packages <- .packages(all.available = TRUE) missing_packages <- needed_packages[!(needed_packages %in% installed_packages)] # If any packages are missing, install them if (length(missing_packages) > 0) { install.packages(missing_packages) }Chargez les packages requis :
# Load the required packages lapply(needed_packages, library, character.only = TRUE)Authentifiez
bigrqueryà l'aide de l'authentification hors bande :bq_auth(use_oob = True)Définissez le nom du projet que vous souhaitez utiliser pour ce notebook en remplaçant
[YOUR-PROJECT-ID]par un nom :# Set the project ID PROJECT_ID <- "[YOUR-PROJECT-ID]"Définissez le nom du bucket Cloud Storage dans lequel stocker les données de sortie en remplaçant
[YOUR-BUCKET-NAME]par un nom unique au niveau mondial :BUCKET_NAME <- "[YOUR-BUCKET-NAME]"Définissez la hauteur et la largeur par défaut des graphiques qui seront générés ultérieurement dans le notebook :
options(repr.plot.height = 9, repr.plot.width = 16)Créez une instruction SQL BigQuery qui extrait certains prédicteurs possibles et la variable de prédiction cible pour un échantillon de trajets. La requête suivante filtre certaines valeurs aberrantes ou illogiques dans les champs qui sont lus pour l'analyse.
sql_query_template <- " SELECT TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes, passenger_count, ROUND(trip_distance, 1) AS trip_distance_miles, rate_code, /* Mapping from rate code to type from description column in BigQuery table schema */ (CASE WHEN rate_code = '1.0' THEN 'Standard rate' WHEN rate_code = '2.0' THEN 'JFK' WHEN rate_code = '3.0' THEN 'Newark' WHEN rate_code = '4.0' THEN 'Nassau or Westchester' WHEN rate_code = '5.0' THEN 'Negotiated fare' WHEN rate_code = '6.0' THEN 'Group ride' /* Several NULL AND some '99.0' values go here */ ELSE 'Unknown' END) AS rate_type, fare_amount, CAST(ABS(FARM_FINGERPRINT( CONCAT( CAST(trip_distance AS STRING), CAST(fare_amount AS STRING) ) )) AS STRING) AS key FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` /* Filter out some outlier or hard to understand values */ WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) LIMIT %s "La colonne
keyest un identifiant de ligne généré basé sur les valeurs concaténées des colonnestrip_distanceetfare_amount.Exécutez la requête et récupérez les mêmes données en tant que tibble en mémoire, qui est semblable à un DataFrame.
sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) taxi_trip_data <- bq_table_download( bq_project_query( PROJECT_ID, query = sql_query ) )Afficher les résultats récupérés :
head(taxi_trip_data)Le résultat est un tableau semblable à l'image suivante :

Les résultats affichent les colonnes de données de trajet suivantes :
trip_time_minutesentierpassenger_countentiertrip_distance_milesdoublerate_codecaractèrerate_typecaractèrefare_amountdoublekeycaractère
Affichez le nombre de lignes et les types de données de chaque colonne :
str(taxi_trip_data)Le résultat ressemble à ce qui suit :
tibble [10,000 x 7] (S3: tbl_df/tbl/data.frame) $ trip_time_minutes : int [1:10000] 52 19 2 7 14 16 1 2 2 6 ... $ passenger_count : int [1:10000] 1 1 1 1 1 1 1 1 3 1 ... $ trip_distance_miles: num [1:10000] 31.3 8.9 0.4 0.9 2 0.6 1.7 0.4 0.5 0.2 ... $ rate_code : chr [1:10000] "5.0" "5.0" "5.0" "5.0" ... $ rate_type : chr [1:10000] "Negotiated fare" "Negotiated fare" "Negotiated fare" "Negotiated fare" ... $ fare_amount : num [1:10000] 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ... $ key : chr [1:10000] "1221969315200336084" 5007772749405424948" "3727452358632142755" "77714841168471205370" ...Affichez un résumé des données récupérées :
summary(taxi_trip_data)Le résultat ressemble à ce qui suit :
trip_time_minutes passenger_count trip_distance_miles rate_code Min. : 1.00 Min. :1.000 Min. : 0.000 Length:10000 1st Qu.: 20.00 1st Qu.:1.000 1st Qu.: 3.700 Class :character Median : 24.00 Median :1.000 Median : 4.800 Mode :character Mean : 30.32 Mean :1.465 Mean : 9.639 3rd Qu.: 39.00 3rd Qu.:2.000 3rd Qu.:17.600 Max. :120.00 Max. :9.000 Max. :43.700 rate_type fare_amount key Length:10000 Min. : 0.01 Length:10000 Class :character 1st Qu.: 16.50 Class :character Mode :character Median : 16.50 Mode :character Mean : 31.22 3rd Qu.: 52.00 Max. :182.50Affichez la distribution des valeurs
fare_amountà l'aide d'un histogramme :ggplot( data = taxi_trip_data, aes(x = fare_amount) ) + geom_histogram(bins = 100)Le tracé obtenu est semblable au graphique de l'image suivante :

Affichez la relation entre
trip_distanceetfare_amountà l'aide d'un nuage de points :ggplot( data = taxi_trip_data, aes(x = trip_distance_miles, y = fare_amount) ) + geom_point() + geom_smooth(method = "lm")Le tracé obtenu est semblable au graphique de l'image suivante :
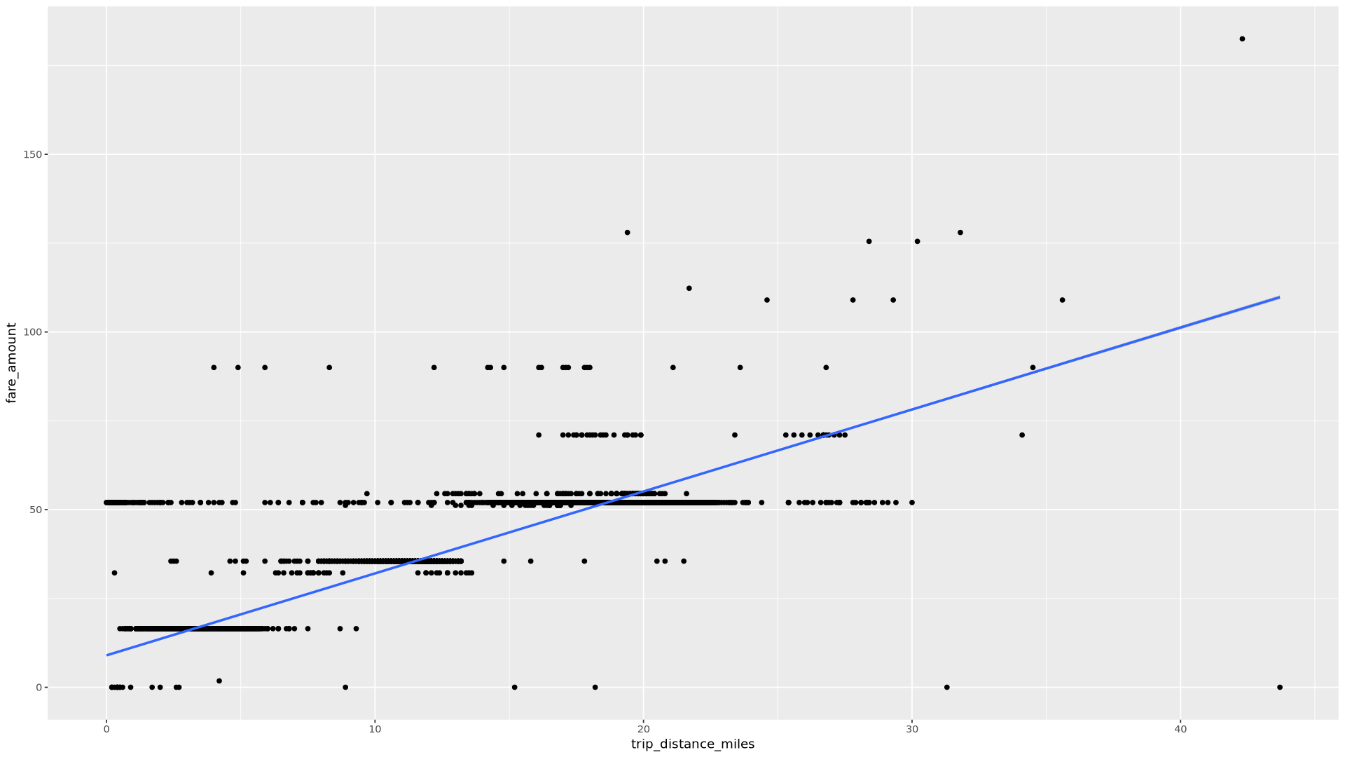
Dans le notebook, créez une fonction qui trouve le nombre de trajets et le montant moyen des tarifs pour chaque valeur de la colonne choisie :
get_distinct_value_aggregates <- function(column) { query <- paste0( 'SELECT ', column, ', COUNT(1) AS num_trips, AVG(fare_amount) AS avg_fare_amount FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2022` WHERE (TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) BETWEEN 0.01 AND 120) AND (passenger_count BETWEEN 1 AND 10) AND (trip_distance BETWEEN 0.01 AND 100) AND (fare_amount BETWEEN 0.01 AND 250) GROUP BY 1 ' ) bq_table_download( bq_project_query( PROJECT_ID, query = query ) ) }Appelez la fonction à l'aide de la colonne
trip_time_minutesdéfinie à l'aide de la fonctionnalité d'horodatage dans BigQuery :df <- get_distinct_value_aggregates( 'TIMESTAMP_DIFF(dropoff_datetime, pickup_datetime, MINUTE) AS trip_time_minutes') ggplot( data = df, aes(x = trip_time_minutes, y = num_trips) ) + geom_line() ggplot( data = df, aes(x = trip_time_minutes, y = avg_fare_amount) ) + geom_line()Le notebook affiche deux graphiques. Le premier graphique indique le nombre de trajets par durée en minutes. Le deuxième graphique indique le montant moyen des trajets en fonction de leur durée.
Le résultat de la première commande
ggplotest présenté ci-dessous. Il indique le nombre de trajets en fonction de leur durée (en minutes) :
Le résultat de la deuxième commande
ggplotest le suivant, indiquant le montant moyen des courses en fonction de leur durée :
Pour voir d'autres exemples de visualisation avec d'autres champs de données, reportez-vous au notebook.
Dans le notebook, chargez les données d'entraînement et d'évaluation de BigQuery vers le langage R :
# Prepare training and evaluation data from BigQuery sample_size <- 10000 sql_query <- sprintf(sql_query_template, sample_size) # Split data into 75% training, 25% evaluation train_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) <= 75') eval_query <- paste('SELECT * FROM (', sql_query, ') WHERE MOD(CAST(key AS INT64), 100) > 75') # Load training data to data frame train_data <- bq_table_download( bq_project_query( PROJECT_ID, query = train_query ) ) # Load evaluation data to data frame eval_data <- bq_table_download( bq_project_query( PROJECT_ID, query = eval_query ) )Vérifiez le nombre d'observations dans chaque ensemble de données :
print(paste0("Training instances count: ", nrow(train_data))) print(paste0("Evaluation instances count: ", nrow(eval_data)))Environ 75 % du nombre total d'instances doivent être utilisées pour l'entraînement, et environ 25 % des instances restantes pour l'évaluation.
Écrivez les données dans un fichier CSV local :
# Write data frames to local CSV files, with headers dir.create(file.path('data'), showWarnings = FALSE) write.table(train_data, "data/train_data.csv", row.names = FALSE, col.names = TRUE, sep = ",") write.table(eval_data, "data/eval_data.csv", row.names = FALSE, col.names = TRUE, sep = ",")Importez les fichiers CSV dans Cloud Storage en encapsulant les commandes
gsutiltransmises au système :# Upload CSV data to Cloud Storage by passing gsutil commands to system gcs_url <- paste0("gs://", BUCKET_NAME, "/") command <- paste("gsutil mb", gcs_url) system(command) gcs_data_dir <- paste0("gs://", BUCKET_NAME, "/data") command <- paste("gsutil cp data/*_data.csv", gcs_data_dir) system(command) command <- paste("gsutil ls -l", gcs_data_dir) system(command, intern = TRUE)Vous pouvez également importer des fichiers CSV dans Cloud Storage à l'aide de la bibliothèque googleCloudStorageR, qui appelle l'API JSON Cloud Storage.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Pour plus d'informations sur l'utilisation des données BigQuery dans les notebooks R, consultez la documentation sur bigrquery.
- Découvrez les bonnes pratiques en matière d'ingénierie de ML dans les Règles du machine learning.
- Pour obtenir une présentation des principes et des recommandations d'architecture spécifiques aux charges de travail d'IA et de ML dans Google Cloud, consultez la perspective de l'IA et du ML dans le framework Well-Architected.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
- Jason Davenport | Developer Advocate
- Firat Tekiner | Responsable produit senior
Créer une instance Vertex AI Workbench
La première étape consiste à créer une instance Vertex AI Workbench que vous pourrez utiliser pour ce tutoriel.
Ouvrir JupyterLab et installer R
Pour suivre le tutoriel dans le notebook, vous devez ouvrir l'environnement JupyterLab, installer R, cloner le dépôt GitHub vertex-ai-samples, puis ouvrir le notebook.
Ouvrir le notebook et configurer R
Interroger des données à partir de BigQuery
Dans cette section du notebook, vous allez lire les résultats de l'exécution d'une instruction SQL BigQuery dans le langage R et examiner de manière préliminaire les données.
Visualiser des données à l'aide de ggplot2
Dans cette section du notebook, vous allez utiliser la bibliothèque ggplot2 en R pour examiner certaines des variables de l'ensemble de données exemple.
Traiter des données dans BigQuery à partir de R
Lorsque vous utilisez des ensembles de données volumineux, nous vous recommandons d'effectuer autant d'analyses que possible (agrégation, filtrage, jointure, colonnes de calcul, etc.) dans BigQuery, puis d'extraire les résultats. L'exécution de ces tâches en R est moins efficace. L'utilisation de BigQuery pour l'analyse exploite l'évolutivité et les performances de BigQuery, et garantit que les résultats renvoyés peuvent tenir dans la mémoire en R.
Enregistrer des données au format CSV dans Cloud Storage
La tâche suivante consiste à enregistrer les données extraites de BigQuery sous forme de fichiers CSV dans Cloud Storage afin de pouvoir les utiliser pour d'autres tâches de ML.
Vous pouvez également utiliser bigrquery pour réécrire des données de R dans BigQuery. L'écriture dans BigQuery est généralement effectuée après avoir terminé un prétraitement ou généré des résultats à utiliser pour une analyse plus approfondie.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce document soient facturées sur votre compte Google Cloud , vous pouvez les supprimer.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé. Si vous envisagez d'explorer plusieurs architectures, tutoriels et guides de démarrage rapide, réutiliser des projets peut vous aider à ne pas dépasser les limites de quotas des projets.
Étapes suivantes
Contributeurs
Auteur : Alok Pattani | Developer Advocate
Autres contributeurs :