Auf dieser Seite werden Best Practices für die Entwicklung Ihrer Dataflow-Pipelines beschrieben. Die Verwendung dieser Best Practices hat folgende Vorteile:
- Beobachtbarkeit und Leistung der Pipeline verbessern
- Entwicklerproduktivität steigern
- Pipeline-Testbarkeit verbessern
In den Apache Beam-Codebeispielen auf dieser Seite wird Java verwendet. Der Inhalt gilt jedoch für die Apache Beam Java, Python und Go SDKs.
Zu berücksichtigende Fragen:
Berücksichtigen Sie beim Entwerfen Ihrer Pipeline die folgenden Fragen:
- Wo sind die Eingabedaten Ihrer Pipeline gespeichert? Wie viele Sätze an Eingabedaten haben Sie?
- Wie sehen meine Daten aus?
- Was möchte ich mit meinen Daten tun?
- Wo sollten die Ausgabedaten Ihrer Pipeline liegen?
- Verwendet Ihr Dataflow-Job Assured Workloads?
Vorlagen verwenden
Verwenden Sie zum Beschleunigen der Pipelineentwicklung nach Möglichkeit eine Dataflow-Vorlage, statt eine Pipeline durch Schreiben von Apache Beam-Code zu erstellen. Vorlagen haben folgende Vorteile:
- Vorlagen können wiederverwendet werden.
- Mit Vorlagen können Sie jeden Job anpassen, indem Sie bestimmte Pipelineparameter ändern.
- Jeder, dem Sie Berechtigungen zuweisen, kann die Vorlage zum Bereitstellen der Pipeline verwenden. Beispielsweise kann ein Entwickler einen Job aus einer Vorlage erstellen und ein Data Scientist in der Organisation kann diese Vorlage später bereitstellen.
Sie können eine von Google bereitgestellte Vorlage verwenden oder eine eigene Vorlage erstellen. Einige von Google bereitgestellte Vorlagen ermöglichen Ihnen, benutzerdefinierte Logik als Pipelineschritt hinzuzufügen. Die Vorlage Pub/Sub für BigQuery enthält beispielsweise einen Parameter, um eine in Cloud Storage gespeicherte benutzerdefinierte JavaScript-Funktion (UDF) auszuführen.
Von Google bereitgestellte Vorlagen sind Open-Source-Ressourcen unter der Apache-Lizenz 2.0, sodass Sie sie als Grundlage für neue Pipelines verwenden können. Die Vorlagen sind auch als Codebeispiele nützlich. Sehen Sie sich den Vorlagencode im GitHub-Repository an.
Assured Workloads
Assured Workloads hilft bei der Durchsetzung von Sicherheits- und Compliance-Anforderungen für Google Cloud-Kunden. Beispiel: EU-Regionen und -Support mit Datenhoheitskontrollen helfen bei der Durchsetzung der Anforderungen an Datenstandort und Datenhoheit für Kunden in der EU. Um diese Funktionen bereitzustellen, sind einige Dataflow-Funktionen eingeschränkt oder begrenzt. Wenn Sie Assured Workloads mit Dataflow verwenden, müssen sich alle Ressourcen, auf die Ihre Pipeline zugreift, im Assured Workloads-Projekt oder -Ordner Ihrer Organisation befinden. Zu diesen Ressourcen gehören:
- Cloud Storage-Buckets
- BigQuery-Datasets
- Pub/Sub-Themen und -Abos
- Firestore-Datasets
- E/A-Connectors
In Dataflow werden bei Streamingjobs, die nach dem 7. März 2024 erstellt wurden, alle Nutzerdaten mit CMEK verschlüsselt.
Bei Streamingjobs, die vor dem 7. März 2024 erstellt wurden, sind Datenschlüssel, die für schlüsselbasierte Vorgänge wie Windowing, Gruppierung und Joining verwendet werden, nicht durch eine CMEK-Verschlüsselung geschützt. Um diese Verschlüsselung für Ihre Jobs zu aktivieren, beenden Sie den Job per Drain oder brechen Sie den Job ab und starten Sie ihn dann neu. Weitere Informationen finden Sie unter Verschlüsselung von Pipelinestatus-Artefakten.
Daten in mehreren Pipelines freigeben
Es gibt keinen Dataflow-spezifischen pipelineübergreifenden Kommunikationsmechanismus zum Teilen von Daten oder zum Verarbeiten von Kontextinformationen zwischen Pipelines. Sie können eine langfristige Speichermöglichkeit wie Cloud Storage oder einen In-Memory-Cache wie App Engine für den Austausch von Daten zwischen Pipelineinstanzen verwenden.
Jobs planen
Sie können die Pipelineausführung auf folgende Arten automatisieren:
- Verwenden Sie Cloud Scheduler.
- Verwenden Sie den Dataflow Operator von Apache Airflow, einen von mehreren Google Cloud-Operatoren in einem Cloud Composer-Workflow.
- Benutzerdefinierte Cronjob-Prozesse in Compute Engine ausführen.
Best Practices für das Schreiben von Pipelinecode
In den folgenden Abschnitten finden Sie Best Practices für die Erstellung von Pipelines durch Schreiben von Apache Beam-Code.
Apache Beam-Code strukturieren
Zum Erstellen von Pipelines ist es üblich, die generische Apache Beam-Transformation ParDo zu verwenden.
Wenn Sie eine ParDo-Transformation anwenden, geben Sie Code in Form eines DoFn-Objekts an. DoFn ist eine Apache Beam SDK-Klasse, die eine verteilte Verarbeitungsfunktion definiert.
Sie können sich den DoFn-Code als kleine, unabhängige Entitäten vorstellen. Es besteht die Möglichkeit, zahlreiche Instanzen auf unterschiedlichen Maschinen auszuführen, ohne dass diesen die Existenz der anderen Instanzen bekannt ist. Daher empfehlen wir, reine Funktionen zu erstellen, die sich ideal für die parallele und verteilte Natur von DoFn-Elementen eignen.
Reine Funktionen haben folgende Eigenschaften:
- Reine Funktionen hängen nicht vom verborgenen oder externen Status ab.
- Sie haben keine erkennbaren Nebenwirkungen.
- Sie sind deterministisch.
Das reine Funktionsmodell ist nicht strikt starr. Wenn Ihr Code nicht von Dingen abhängt, für die der Dataflow-Dienst sorgt, können Statusinformationen oder externe Initialisierungsdaten für DoFn und andere Funktionsobjekte gültig sein.
Beachten Sie beim Strukturieren der ParDo-Transformationen und beim Erstellen der DoFn-Elemente die folgenden Richtlinien:
- Wenn Sie die genau einmalige Verarbeitung verwenden, garantiert der Dataflow-Dienst, dass jedes Element in Ihrer Eingabe
PCollectionvon einer InstanzDoFngenau einmal verarbeitet wird. - Der Dataflow-Dienst garantiert nicht, wie oft eine
DoFnaufgerufen wird. - Der Dataflow-Dienst gibt keine genaue Garantie dafür, wie die verteilten Elemente gruppiert werden. Es wird nicht dafür gesorgt, dass Elemente zusammen verarbeitet werden.
- Der Dataflow-Dienst sorgt nicht für die genaue Anzahl von
DoFn-Instanzen, die im Verlauf einer Pipeline erstellt werden. - Der Dataflow-Dienst toleriert Fehler. Wenn bei den Workern Probleme auftreten, kann die Ausführung des Codes mehrfach wiederholt werden.
- Der Dataflow-Dienst kann Sicherungskopien Ihres Codes erstellen. Probleme können bei manuellen Nebeneffekten auftreten, z. B. wenn Ihr Code auf temporäre Dateien mit nicht eindeutigen Namen basiert oder solche Dateien erstellt.
- Der Dataflow-Dienst serialisiert die Elementverarbeitung pro
DoFn-Instanz. Der Code muss nicht zwingend threadsicher sein, aber jeglicher Status, der von mehrerenDoFn-Instanzen gemeinsam genutzt wird, muss threadsicher sein.
Bibliotheken wiederverwendbarer Transformationen erstellen
Mit dem Apache Beam-Programmiermodell können Sie Transformationen wiederverwenden. Durch das Erstellen einer gemeinsam genutzten Bibliothek mit allgemeinen Transformationen können Sie die Wiederverwendbarkeit, Testbarkeit und Codeinhaberschaft für verschiedene Teams verbessern.
Sehen Sie sich dazu die folgenden zwei Java-Codebeispiele an, die beide Zahlungsereignisse lesen. Sofern beide Pipelines dieselbe Verarbeitung ausführen, können sie dieselben Transformationen über eine gemeinsam genutzte Bibliothek für die verbleibenden Verarbeitungsschritte verwenden.
Das erste Beispiel stammt aus einer unbegrenzten Pub/Sub-Quelle:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
Das zweite Beispiel stammt aus einer begrenzten relationalen Datenbankquelle:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
Wie Sie Best Practices für die Wiederverwendbarkeit von Code umsetzen, variiert je nach Programmiersprache und Build-Tool. Wenn Sie beispielsweise Maven verwenden, lässt sich der Transformationscode in ein eigenes Modul ausgliedern. Anschließend können Sie das Modul als Submodul in größere Projekte mit mehreren Modulen für verschiedene Pipelines einbinden, wie im folgenden Codebeispiel gezeigt:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
Weitere Informationen finden Sie auf den folgenden Apache Beam-Dokumentationsseiten:
- Anforderungen für das Schreiben von Nutzercode für Apache Beam-Transformationen
PTransform-Styleguide: Ein Styleguide für Autoren neuer wiederverwendbarerPTransform-Sammlungen.
Dead-Letter-Warteschlangen für die Fehlerbehandlung verwenden
Manchmal kann Ihre Pipeline keine Elemente verarbeiten. Eine häufige Ursache sind Datenprobleme. So kann ein Element mit falsch formatiertem JSON-Code zu Parsing-Fehlern führen.
Sie können zwar Ausnahmen in der Methode DoFn.ProcessElement abfangen, den Fehler protokollieren und das Element entfernen, jedoch gehen bei diesem Ansatz die Daten verloren und es wird verhindert, dass die Daten später zur manuellen Verarbeitung oder Fehlerbehebung geprüft werden,
Verwenden Sie stattdessen ein Muster, das als Dead-Letter-Warteschlange (Warteschlange für unverarbeitete Nachrichten) bezeichnet wird.
Fangen Sie Ausnahmen in der Methode DoFn.ProcessElement ab und protokollieren Sie Fehler. Anstatt das fehlgeschlagene Element zu löschen, verwenden Sie verzweigte Ausgaben, um fehlgeschlagene Elemente in ein separates PCollection-Objekt zu schreiben. Diese Elemente werden dann über eine separate Transformation zur späteren Prüfung und Verarbeitung in eine Datensenke geschrieben.
Das folgende Java-Codebeispiel zeigt, wie das Muster für Dead-Letter-Warteschlangen implementiert wird.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Mithilfe von Cloud Monitoring lassen sich verschiedene Monitoring- und Benachrichtigungsrichtlinien für die Dead-Letter-Warteschlange der Pipeline anwenden. Sie können beispielsweise die Anzahl und Größe der von Ihrer Dead-Letter-Transformation verarbeiteten Elemente visualisieren und Benachrichtigungen so konfigurieren, dass sie ausgelöst werden, wenn bestimmte Grenzwertbedingungen erfüllt sind.
Schemamutationen verarbeiten
Sie können Daten, die unerwartete (aber gültige) Schemas haben, mithilfe eines Dead-Letter-Musters verarbeiten, das fehlgeschlagene Elemente in ein separates PCollection-Objekt schreibt.
In einigen Fällen ist es sinnvoll, Elemente, die ein mutiertes Schema widerspiegeln, automatisch als gültige Elemente zu verarbeiten. Wenn beispielsweise das Schema eines Elements eine Mutation wie die Ergänzung neuer Felder enthält, können Sie das Schema der Datensenke so anpassen, dass Mutationen berücksichtigt werden.
Die automatische Schemamutation basiert auf dem Ansatz für verzweigte Ausgaben, der vom Dead-Letter-Muster verwendet wird. In diesem Fall wird jedoch eine Transformation ausgelöst, die das Zielschema ändert, wenn additive Schemas gefunden werden. Ein Beispiel für diesen Ansatz finden Sie unter How to handle mutating JSON schemas in a streaming pipeline, with Square Enix im Google Cloud-Blog.
Entscheiden, wie Datasets verknüpft werden sollen
Dataset-Joins werden bei Datenpipelines häufig angewendet. Sie können Nebeneingaben oder die CoGroupByKey-Transformation verwenden, um Joins in Ihrer Pipeline durchzuführen.
Beide Wege haben Vor- und Nachteile.
Nebeneingaben stellen eine flexible Möglichkeit dar, gängige Datenverarbeitungsprobleme wie Datenanreicherung und schlüsselbasierte Lookups zu lösen. Im Gegensatz zu PCollection-Objekten sind Nebeneingaben änderbar und können zur Laufzeit bestimmt werden. So lassen sich die Werte in einer Nebeneingabe von einem anderen Zweig in der Pipeline berechnen oder durch Aufrufen eines Remote-Dienstes bestimmen.
Zur Unterstützung von Nebeneingaben legt Dataflow Daten in einem nichtflüchtigen Speicher (ähnlich einem freigegebenen Laufwerk) dauerhaft ab. Durch diese Konfiguration steht die komplette Nebeneingabe allen Workern zur Verfügung.
Nebeneingaben können jedoch sehr groß sein und passen möglicherweise nicht in den Worker-Arbeitsspeicher. Lesevorgänge aus einer großen Nebeneingabe können zu Leistungsproblemen führen, wenn Worker ständig aus dem nichtflüchtigen Speicher lesen müssen.
Die CoGroupByKey-Transformation ist eine Apache Beam-Kerntransformation, die mehrere PCollection-Objekte zusammenführt (vereinfacht) und Elemente gruppiert, die einen gemeinsamen Schlüssel haben. Im Gegensatz zu einer Nebeneingabe, die jedem Worker alle Daten einer Nebeneingabe zur Verfügung stellt, führt CoGroupByKey einen Shuffle-Vorgang (Gruppierung) aus, um Daten auf Worker zu verteilen. Daher ist CoGroupByKey ideal, wenn die zu verknüpfenden PCollection-Objekte sehr groß sind und nicht in den Worker-Arbeitsspeicher passen.
Orientieren Sie sich an den folgenden Richtlinien, wenn Sie sich für die Verwendung von Nebeneingaben oder CoGroupByKey entscheiden:
- Verwenden Sie Nebeneingaben, wenn eines der zu verknüpfenden
PCollection-Objekte unverhältnismäßig kleiner als die anderen ist und das kleinerePCollection-Objekt in den Worker-Arbeitsspeicher passt. Wenn die gesamte Nebeneingabe im Cache gespeichert wird, können Elemente schnell und effizient abgerufen werden. - Verwenden Sie Nebeneingaben, wenn Sie ein
PCollection-Objekt haben, das in der Pipeline mehrmals verknüpft werden muss. Statt mehrereCoGroupByKey-Transformationen zu verwenden, erstellen Sie eine einzelne Nebeneingabe, die von mehrerenParDo-Transformationen wiederverwendet werden kann. - Verwenden Sie
CoGroupByKey, wenn Sie einen großen Teil einesPCollection-Objekts abrufen müssen, das den Worker-Arbeitsspeicher erheblich überschreitet.
Weitere Informationen finden Sie unter Fehlerbehebung bei Dataflow-Fehlern aufgrund von fehlerhaftem Arbeitsspeicher.
Aufwendige Vorgänge pro Element minimieren
Eine DoFn-Instanz verarbeitet Batches von Elementen, die als Bundles bezeichnet werden. Dies sind atomare Arbeitseinheiten, die aus null oder mehr Elementen bestehen. Einzelne Elemente werden dann von der Methode DoFn.ProcessElement verarbeitet, die für jedes Element ausgeführt wird. Da die Methode DoFn.ProcessElement für jedes Element aufgerufen wird, werden alle von dieser Methode aufgerufenen zeit- oder rechenintensiven Vorgänge für jedes einzelne Element ausgeführt, das von der Methode verarbeitet wird.
Wenn Sie kostspielige Vorgänge nur für einen Satz von Elementen durchführen müssen, sollten Sie diese Vorgänge in der DoFn.Setup-Methode oder der DoFn.StartBundle-Methode statt im DoFn.ProcessElement-Element einschließen. Beispiele hierfür sind die folgenden Vorgänge:
Parsen einer Konfigurationsdatei, die einige Verhaltensweisen der
DoFn-Instanz steuert. Rufen Sie diese Aktion nur einmal auf, wenn die InstanzDoFnüber die MethodeDoFn.Setupinitialisiert wird.Instanziieren eines kurzlebigen Clients, der für alle Elemente in einem Bundle wiederverwendet wird, z. B. wenn alle Elemente im Bundle über eine einzige Netzwerkverbindung gesendet werden. Rufen Sie diese Aktion mit der Methode
DoFn.StartBundleeinmal pro Bundle auf.
Batchgrößen und gleichzeitige Aufrufe externer Dienste begrenzen
Wenn Sie externe Dienste aufrufen, können Sie mithilfe der GroupIntoBatches-Transformation den Overhead pro Aufruf reduzieren. Diese Transformation erstellt Sätze von Elementen einer bestimmten Größe.
Batching sendet Elemente als eine einzige Nutzlast statt einzeln an einen externen Dienst.
In Kombination mit Batching begrenzen Sie die maximale Anzahl paralleler (gleichzeitiger) Aufrufe des externen Dienstes, indem Sie geeignete Schlüssel zum Partitionieren der eingehenden Daten auswählen. Die Anzahl der Partitionen bestimmt die maximale Parallelisierung. Wenn beispielsweise jedes Element denselben Schlüssel erhält, wird eine nachgelagerte Transformation zum Aufrufen des externen Dienstes nicht parallel ausgeführt.
Sie können einen der folgenden Ansätze verwenden, um Schlüssel für Elemente zu erstellen:
- Wählen Sie ein Attribut des Datasets aus, das als Datenschlüssel verwendet werden soll, z. B. Nutzer-IDs.
- Generieren Sie Datenschlüssel, um Elemente nach dem Zufallsprinzip auf eine feste Anzahl von Partitionen aufzuteilen, wobei die Anzahl der möglichen Schlüsselwerte die Anzahl der Partitionen bestimmt. Sie müssen genügend Partitionen für die Parallelisierung erstellen.
Jede Partition muss genügend Elemente enthalten, damit die Transformation
GroupIntoBatchesnützlich ist.
Das folgende Java-Codebeispiel zeigt, wie Elemente nach dem Zufallsprinzip auf 10 Partitionen aufgeteilt werden:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Leistungsprobleme aufgrund zusammengeführter Schritte identifizieren
Dataflow erstellt eine Grafik der Schritte, die Ihre Pipeline darstellen, auf Basis der Transformationen und Daten, die Sie zum Erstellen der Pipeline verwendet haben. Diese Grafik wird als Ausführungsgrafik der Pipeline bezeichnet.
Wenn Sie die Pipeline bereitstellen, ändert Dataflow möglicherweise die Ausführungsgrafik der Pipeline, um die Leistung zu verbessern. Beispielsweise kann Dataflow einige Vorgänge zusammenführen – ein Prozess, der als Zusammenführungsoptimierung bezeichnet wird. Damit sollen die Leistungs- und Kostenauswirkungen vermieden werden, die mit dem Schreiben eines jeden PCollection-Zwischenobjekts in der Pipeline einhergehen.
In einigen Fällen kann Dataflow eine falsche optimale Zusammenführung von Vorgängen in der Pipeline ermitteln. Dies kann die Fähigkeit Ihres Jobs einschränken, alle verfügbaren Worker zu verwenden. In diesen Fällen können Sie das Zusammenführen von Vorgängen verhindern.
Sehen Sie sich den folgenden Apache Beam-Beispielcode an. Eine GenerateSequence-Transformation erstellt ein kleines begrenztes PCollection-Objekt, das wiederum von zwei nachgelagerten ParDo-Transformationen verarbeitet wird.
Die Find Primes Less-than-N-Transformation kann rechenintensiv sein und wird bei großen Zahlen wahrscheinlich langsam ausgeführt. Im Gegensatz dazu wird die Transformation Increment Number wahrscheinlich schnell abgeschlossen.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
Das folgende Diagramm zeigt eine grafische Darstellung der Pipeline in der Dataflow-Monitoring-Oberfläche.
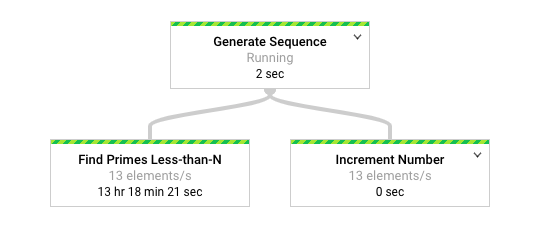
Die Dataflow-Monitoring-Oberfläche zeigt, dass für beide Transformationen dieselbe langsame Verarbeitungsrate auftritt, insbesondere 13 Elemente pro Sekunde. Man könnte erwarten, dass die Increment Number-Transformation Elemente schnell verarbeitet, stattdessen scheint sie aber an die gleiche Verarbeitungsrate wie Find Primes Less-than-N gebunden zu sein.
Dies liegt daran, dass Dataflow die Schritte zu einer einzigen Phase zusammengeführt hat und damit verhindert, dass sie unabhängig voneinander ausgeführt werden. Mit dem Befehl gcloud dataflow jobs describe können Sie weitere Informationen abrufen:
gcloud dataflow jobs describe --full job-id --format json
In der resultierenden Ausgabe werden die zusammengeführten Schritte im Objekt ExecutionStageSummary im Array ComponentTransform beschrieben:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
Da die Find Primes Less-than-N-Transformation den langsamen Schritt darstellt, ist in diesem Szenario die Teilung der Zusammenführung vor diesem Schritt sinnvoll. Eine Methode zum Aufheben der Zusammenführung von Schritten besteht darin, vor dem Schritt eine GroupByKey-Transformation einzufügen und die Gruppierung aufzuheben, wie im folgenden Java-Codebeispiel gezeigt.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
Sie können diese Schritte zum Aufheben der Zusammenführung auch zu einer wiederverwendbaren zusammengesetzten Transformation kombinieren.
Nachdem Sie die Zusammenführung der Schritte aufgehoben haben, ist Increment Number beim Ausführen der Pipeline in wenigen Sekunden abgeschlossen. Die viel länger laufende Find Primes Less-than-N-Transformation wird dann in einer separaten Phase ausgeführt.
In diesem Beispiel wird der Vorgang zum Gruppieren und Aufheben der Gruppierung angewendet, um die Zusammenführung von Schritten aufzuheben.
In anderen Situationen können Sie andere Ansätze verwenden. Im obigen Fall stellt die Verarbeitung doppelter Ausgaben aufgrund der aufeinanderfolgenden Ausgabe der GenerateSequence-Transformation kein Problem dar.
KV-Objekte mit doppelten Schlüsseln werden zu einem einzigen Schlüssel in den Transformationen zum Gruppieren (GroupByKey) und Aufheben der Gruppierung (Keys) dedupliziert. Wenn Sie Duplikate nach den Vorgängen zum Gruppieren und Aufheben der Gruppierung beibehalten möchten, erstellen Sie Schlüssel/Wert-Paare mithilfe der folgenden Schritte:
- Verwenden Sie einen zufälligen Schlüssel und die ursprüngliche Eingabe als Wert.
- Gruppieren Sie mit dem zufälligen Schlüssel.
- Geben Sie die Werte für jeden Schlüssel als Ausgabe aus.
Außerdem können Sie eine Reshuffle-Transformation verwenden, um die Zusammenführung von umgebenden Transformationen zu verhindern. Allerdings sind die Nebeneffekte der Reshuffle-Transformation nicht auf verschiedene Apache Beam-Runner übertragbar.
Weitere Informationen zur Parallelität und Zusammenführungsoptimierung finden Sie unter Pipeline-Lebenszyklus.
Pipeline-Statistiken mithilfe von Apache Beam-Messwerten erfassen
Apache Beam-Messwerte sind eine Dienstprogrammklasse, die Messwerte zum Melden der Attribute einer ausgeführten Pipeline erzeugt. Wenn Sie Cloud Monitoring verwenden, stehen Apache Beam-Messwerte als benutzerdefinierte Cloud Monitoring-Messwerte zur Verfügung.
Das folgende Beispiel zeigt Counter-Messwerte von Apache Beam, die in einer abgeleiteten Klasse DoFn verwendet werden.
Im Beispielcode werden zwei Zähler verwendet. Der eine Zähler verfolgt JSON-Parsing-Fehler (malformedCounter) und der andere Zähler verfolgt, ob die JSON-Nachricht gültig ist, aber eine leere Nutzlast enthält (emptyCounter). In Cloud Monitoring lauten die Namen der benutzerdefinierten Messwerte custom.googleapis.com/dataflow/malformedJson und custom.googleapis.com/dataflow/emptyPayload. Sie können die benutzerdefinierten Messwerte verwenden, um Visualisierungen und Benachrichtigungsrichtlinien in Cloud Monitoring zu erstellen.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Weitere Informationen
Auf den folgenden Seiten erfahren Sie mehr darüber, wie Sie Ihre Pipeline strukturieren, wie Sie die Transformationen auswählen, die auf Ihre Daten angewendet werden sollen, und was Sie bei der Auswahl der Eingabe- und Ausgabemethoden Ihrer Pipeline berücksichtigen sollten.
Weitere Informationen zum Erstellen von Nutzercode finden Sie unter Anforderungen für vom Nutzer bereitgestellte Funktionen.