In questa pagina vengono descritte le opzioni a tua alta disponibilità in Cluster Anthos su VMware (GKE on-prem), la configurazione di determinati cluster Anthos sui componenti VMware per l'alta disponibilità e il ripristino in caso di emergenza.
Funzionalità di base
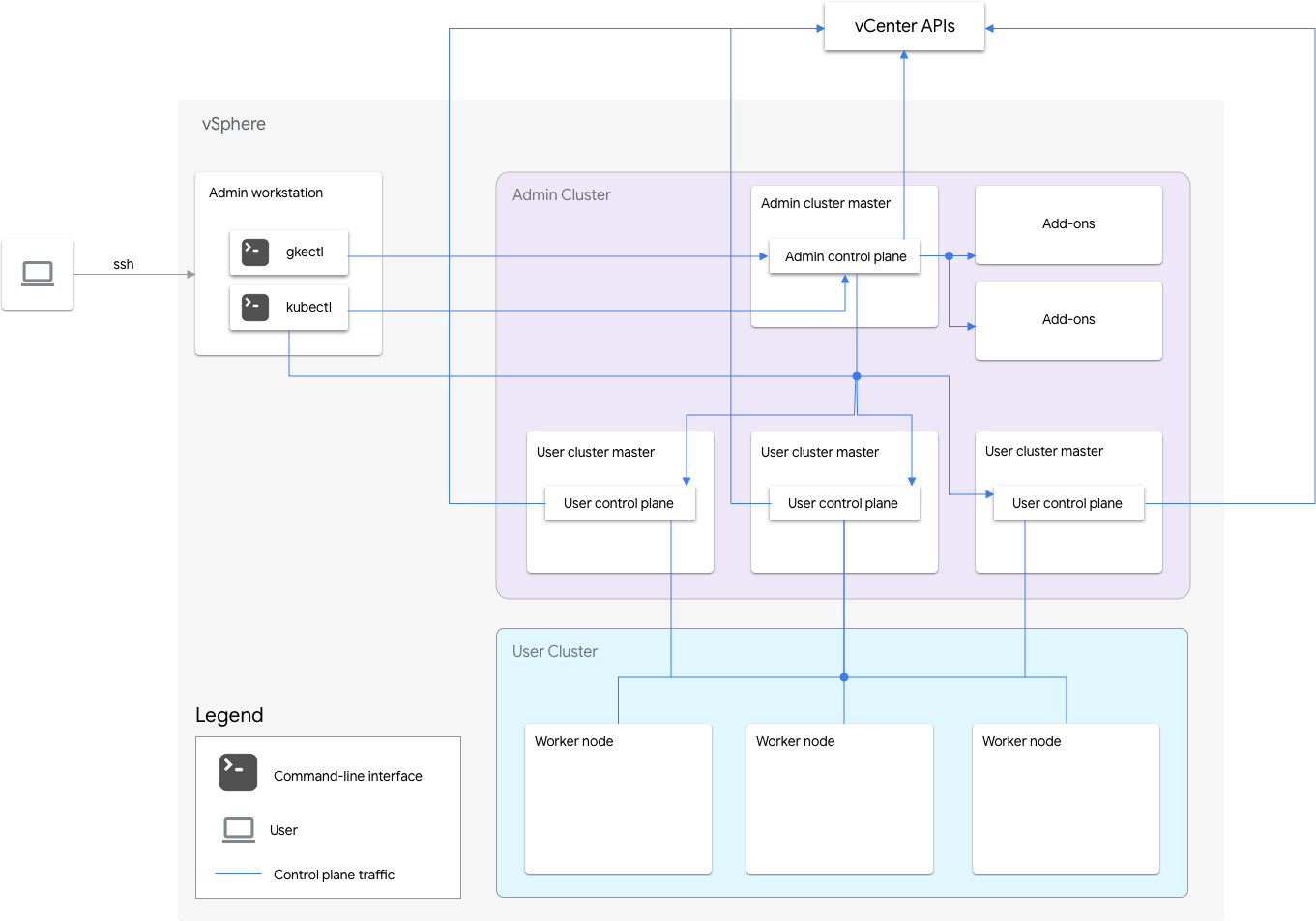
I cluster Anthos su VMware includono un cluster di amministrazione e uno o più cluster utente.
Il cluster di amministrazione gestisce il ciclo di vita dei cluster utente, inclusi creazione, aggiornamenti, upgrade ed eliminazione dei cluster utente. Nel cluster di amministrazione, il master dell'amministratore gestisce i nodi worker dell'amministratore, inclusi i master degli utenti (nodi che eseguono il piano di controllo dei cluster utente gestiti) e i nodi dei componenti aggiuntivi (nodi che eseguono i componenti aggiuntivi che supportano la funzionalità del cluster di amministrazione).
Per ogni cluster utente, il cluster di amministrazione ha un nodo non ad alta disponibilità o tre nodi ad alta disponibilità che eseguono il piano di controllo. Il piano di controllo include il server API, lo scheduler Kubernetes, il gestore del controller Kubernetes e diversi controller critici per il cluster utente di Kubernetes.
La disponibilità del piano di controllo del cluster utente è fondamentale per le operazioni del carico di lavoro, ad esempio la creazione, lo scale up e lo scale down dei carichi di lavoro e la terminazione. In altre parole, un'interruzione del piano di controllo non interferisce con i carichi di lavoro in esecuzione, ma i carichi di lavoro esistenti perdono le capacità di gestione dal server API Kubernetes se non è presente il piano di controllo.
Il deployment dei carichi di lavoro e dei servizi containerizzati viene eseguito nei nodi worker del cluster utente. Qualsiasi nodo worker non dovrebbe essere fondamentale per la disponibilità dell'applicazione, purché venga eseguito il deployment dell'applicazione con pod ridondanti pianificati su più nodi worker.
I cluster Anthos su VMware sono progettati per garantire che gli errori siano isolati il più possibile in un'area funzionale e per dare priorità alle funzionalità fondamentali per la continuità aziendale.
La funzionalità di base dei cluster Anthos su VMware include le seguenti categorie:
Ciclo di vita delle applicazioni
I carichi di lavoro esistenti possono essere eseguiti in modo continuo. Questa è la funzionalità più importante per garantire la continuità aziendale.
Puoi creare, aggiornare ed eliminare i carichi di lavoro. Questa è la seconda funzionalità più importante perché i cluster Anthos su VMware devono scalare i carichi di lavoro quando il traffico aumenta.
Ciclo di vita dei cluster utente
Puoi aggiungere, aggiornare, eseguire l'upgrade ed eliminare i cluster utente. Questo aspetto è meno importante, perché l'impossibilità di modificare i cluster utente non influisce sui carichi di lavoro degli utenti.
Ciclo di vita del cluster di amministrazione
Puoi aggiornare ed eseguire l'upgrade del cluster di amministrazione. Questo è il meno importante perché il cluster di amministrazione non ospita carichi di lavoro utente.
Modalità non riuscite
I seguenti tipi di errori possono influire sulle prestazioni dei cluster Anthos sui cluster VMware.
Errore host ESXi
Un host ESXi che esegue istanze di macchine virtuali (VM) che ospitano nodi Kubernetes potrebbe non funzionare più o diventare partizionato in rete.
| Carichi di lavoro esistenti | Creazione, aggiornamento ed eliminazione dei carichi di lavoro | Ciclo di vita del cluster utente | Ciclo di vita del cluster di amministrazione |
|---|---|---|---|
| Possibile interruzione + recupero automatico |
Possibile interruzione + recupero automatico |
Interruzione + recupero automatico |
Interruzione + recupero automatico |
I pod in esecuzione sulle VM ospitate dall'host in errore vengono interrotti e ripianificati automaticamente su altre VM integre. Se le applicazioni utente hanno una capacità di carico di lavoro insufficiente e sono distribuite su più nodi, l'interruzione non è osservabile dai client che implementano i nuovi tentativi. |
Se l'errore dell'host interessa la VM del piano di controllo in un cluster utente non ad alta disponibilità o più di una VM del piano di controllo in un cluster utente ad alta disponibilità, si verifica un'interruzione. | Se l'errore dell'host interessa la VM del piano di controllo o le VM worker nel cluster di amministrazione, si verifica un'interruzione. | Se l'errore dell'host interessa la VM del piano di controllo nel cluster di amministrazione, si verifica un'interruzione. |
| vSphere HA riavvia automaticamente le VM negli host integri. | vSphere HA riavvia automaticamente le VM negli host integri. | vSphere HA riavvia automaticamente le VM negli host integri. | vSphere HA riavvia automaticamente le VM negli host integri. |
| Esegui il deployment dei carichi di lavoro in modo da ridurre al minimo le possibilità di interruzione. | Utilizza i cluster utente ad alta disponibilità per ridurre al minimo le possibilità di interruzione. |
Errore VM
Potrebbe verificarsi l'eliminazione imprevista di una VM o il disco di avvio potrebbe danneggiarsi. Inoltre, una VM potrebbe essere compromessa a causa di problemi del sistema operativo.
| Carichi di lavoro esistenti | Creazione, aggiornamento ed eliminazione dei carichi di lavoro | Ciclo di vita del cluster utente | Ciclo di vita del cluster di amministrazione |
|---|---|---|---|
| Possibile interruzione + recupero automatico |
Possibile interruzione + recupero automatico |
Interruzione + ripristino automatico/manuale |
Interruzione + recupero manuale |
I pod in esecuzione sulle VM worker non riuscite vengono arrestati e vengono automaticamente ripianificati su altre VM integre da Kubernetes. Se le applicazioni utente hanno una capacità di carico di lavoro insufficiente e sono distribuite su più nodi, l'interruzione non è osservabile dai client che implementano i nuovi tentativi. |
Se la VM del piano di controllo in un cluster utente non ad alta disponibilità o più di una VM del piano di controllo in un cluster utente ad alta disponibilità ha esito negativo, si verifica un'interruzione. | Se la VM del piano di controllo o le VM worker nel cluster di amministrazione hanno esito negativo, si verifica un'interruzione. | Se la VM del piano di controllo nel cluster di amministrazione ha esito negativo, si verifica un'interruzione. |
| La VM non riuscita viene recuperata automaticamente se la riparazione automatica dei nodi è abilitata nel cluster utente. | La VM non riuscita viene recuperata automaticamente se la riparazione automatica dei nodi è abilitata nel cluster di amministrazione. | La VM del worker non riuscita nel cluster di amministrazione viene recuperata automaticamente se la riparazione automatica dei nodi è abilitata nel cluster di amministrazione. Per recuperare la VM del piano di controllo del cluster di amministrazione, consulta la sezione Riparare la VM del piano di controllo del cluster di amministrazione. |
Per recuperare la VM del piano di controllo del cluster di amministrazione, consulta la sezione Riparare la VM del piano di controllo del cluster di amministrazione. |
| Esegui il deployment dei carichi di lavoro in modo da ridurre al minimo le possibilità di interruzione. | Utilizza i cluster utente ad alta disponibilità per ridurre al minimo le possibilità di interruzione. |
Errore di archiviazione
Il contenuto in un file VMDK potrebbe essere danneggiato a causa di un arresto anomalo di una VM o un errore del datastore potrebbe causare la perdita dei dati etcd e dei volume permanenti (PV).
errore etcd
| Carichi di lavoro esistenti | Creazione, aggiornamento ed eliminazione dei carichi di lavoro | Ciclo di vita del cluster utente | Ciclo di vita del cluster di amministrazione |
|---|---|---|---|
| Nessuna interruzione | Possibile interruzione + Ripristino manuale |
Interruzione + Ripristino manuale |
Interruzione + Ripristino manuale |
| Se l'archivio etcd in un cluster utente non ad alta disponibilità o più di una replica etcd in un cluster utente ad alta disponibilità non riesce, si verifica un'interruzione. | Se l'archivio etcd in un cluster utente non ad alta disponibilità o più di una replica etcd in un cluster utente ad alta disponibilità non riesce, si verifica un'interruzione. Se la replica etcd in un cluster di amministrazione ha esito negativo, si verifica un'interruzione. |
Se la replica etcd in un cluster di amministrazione ha esito negativo, si verifica un'interruzione. | |
| I cluster Anthos su VMware forniscono un processo manuale per recuperare l'errore. | I cluster Anthos su VMware forniscono un processo manuale per il ripristino in seguito all'errore. | I cluster Anthos su VMware forniscono un processo manuale per il ripristino in seguito all'errore. |
Errore PV applicazione utente
| Carichi di lavoro esistenti | Creazione, aggiornamento ed eliminazione dei carichi di lavoro | Ciclo di vita del cluster utente | Ciclo di vita del cluster di amministrazione |
|---|---|---|---|
| Possibile interruzione | Nessuna interruzione | Nessuna interruzione | Nessuna interruzione |
Sono interessati i carichi di lavoro che utilizzano il volume permanente non riuscito. Esegui il deployment dei carichi di lavoro nel modo ad alta disponibilità per ridurre al minimo le possibilità di interruzione. |
Errore del bilanciatore del carico
Un errore del bilanciatore del carico potrebbe interessare i carichi di lavoro degli utenti che espongono servizi di tipo LoadBalancer.
| Carichi di lavoro esistenti | Creazione, aggiornamento ed eliminazione dei carichi di lavoro | Ciclo di vita del cluster utente | Ciclo di vita del cluster di amministrazione |
|---|---|---|---|
| Interruzione + Ripristino manuale |
|||
|
Ci sono alcuni secondi di interruzione del servizio fino a quando il bilanciatore del carico in standby non recupera la connessione VIP del piano di controllo dell'amministratore. L'interruzione del servizio potrebbe durare fino a 2 secondi quando utilizzi Seesaw e fino a 300 secondi quando utilizzi F5. Seesaw HA rileva automaticamente l'errore e non riesce a utilizzare l'istanza di backup. I cluster Anthos su VMware forniscono un processo manuale per il ripristino da un errore di Seesaw. |
|||
Abilitare l'alta disponibilità
I cluster vSphere e Anthos su VMware forniscono una serie di funzionalità che contribuiscono all'alta disponibilità (HA).
vSphere HA e vMotion
Ti consigliamo di abilitare le due funzionalità seguenti nel cluster vCenter che ospita i tuoi cluster Anthos sui cluster VMware:
Queste funzionalità migliorano la disponibilità e il recupero in caso di errore di un host ESXi.
vCenter HA utilizza più host ESXi configurati come cluster per fornire un
recupero rapido da interruzioni e alta disponibilità a basso costo per le applicazioni
in esecuzione su macchine virtuali. Ti consigliamo di eseguire il provisioning del tuo cluster vCenter
con host aggiuntivi e di
attivare il monitoraggio host vSphere HA
con Host Failure Response impostato su Restart VMs. In questo modo, le VM possono essere riavviate automaticamente in caso di errore dell'host ESXi.
vMotion consente la migrazione live delle VM da un host ESXi all'altro senza tempi di inattività. Per la manutenzione pianificata dell'host, puoi utilizzare la migrazione live vMotion per evitare completamente il tempo di inattività dell'applicazione e la continuità aziendale.
Cluster di amministrazione
I cluster Anthos su VMware non supportano l'esecuzione di più piani di controllo per il cluster di amministrazione. Tuttavia, la mancata disponibilità del piano di controllo dell'amministratore non influisce sulla funzionalità dei cluster utente esistenti o sui carichi di lavoro in esecuzione nei cluster utente.
In un cluster di amministrazione sono presenti due nodi aggiuntivi. Se non lo è, l'altro può ancora gestire le operazioni di cluster di amministrazione. Per la ridondanza, Anthos cluster su VMware distribuisce servizi aggiuntivi critici, come kube-dns, su entrambi i nodi dei componenti aggiuntivi.
Se imposti antiAffinityGroups.enabled su true nel file di configurazione del cluster di amministrazione, i cluster Anthos su VMware creano automaticamente regole di anti-affinità vSphere DRS per i nodi aggiuntivi, che ne fanno sì che siano distribuiti in due host fisici per l'alta disponibilità.
Cluster utente
Puoi abilitare l'alta disponibilità per un cluster utente impostando masterNode.replicas su 3 nel
file di configurazione del cluster utente. Questo comporta tre nodi nel cluster di amministrazione, ognuno dei quali esegue un piano di controllo per il cluster utente. Ciascuno di questi nodi esegue anche una replica etcd. Il cluster utente continua a funzionare finché è in esecuzione un piano di controllo e un quorum etcd. Un quod etcd richiede che due delle tre repliche etcd funzionino.
Se imposti antiAffinityGroups.enabled su true nel file di configurazione del cluster di amministrazione, i cluster Anthos su VMware creano automaticamente regole di anti-affinità vSphere DRS per i tre nodi che eseguono il piano di controllo del cluster utente.
In questo modo, le VM vengono distribuite tra tre host fisici.
I cluster Anthos su VMware creano inoltre regole di anti-affinità vSphere DRS per i nodi worker nel cluster utente, determinando la loro distribuzione tra almeno tre host fisici. In base al numero di nodi, vengono utilizzate più regole di anti-affinità DRS per ogni pool di nodi del cluster utente. Questo garantisce che i nodi worker possano trovare host su cui eseguire, anche quando il numero di host è inferiore al numero di VM nel pool di nodi del cluster utente. Ti consigliamo di includere host fisici aggiuntivi nel tuo cluster vCenter. Configura inoltre la DRS in modo che sia completamente automatizzata in modo che, nel caso in cui un host non sia più disponibile, la DRS potrà riavviare automaticamente le VM su altri host disponibili senza violare le regole di anti-affinità e VM.
I cluster Anthos su VMware mantiene un'etichetta speciale del nodo,
onprem.gke.io/failure-domain-name, il cui valore è impostato sul nome host ESXi sottostante. Le applicazioni utente che vogliono l'alta disponibilità possono configurare le regole
podAntiAffinity con questa etichetta, in topologyKey, per garantire che i loro pod dell'applicazione siano distribuiti su VM diverse e host fisici.
Puoi anche configurare più pool di nodi per un cluster utente con datastore diversi ed etichette speciali per i nodi. Analogamente, puoi configurare podAntiAffinityregole con quella speciale etichetta del nodo come topologyKey per ottenere una disponibilità più elevata in caso di errori del datastore.
Per disporre di alta disponibilità per i carichi di lavoro degli utenti, assicurati che il cluster utente abbia un numero sufficiente di repliche in nodePools.replicas, che assicura il numero desiderato di nodi worker del cluster utente in condizione di esecuzione.
Puoi utilizzare datastore separati per i cluster di amministrazione e i cluster utente per isolare i rispettivi errori.
Bilanciatore del carico
Esistono due tipi di bilanciatori del carico che puoi utilizzare per l'alta disponibilità.
Bilanciatore del carico di Seesaw in bundle
Per il bilanciatore del carico di Seesaw in bundle, puoi abilitare l'alta disponibilità impostando loadBalancer.seesaw.enableHA su true nel file di configurazione del cluster.
Devi anche abilitare una combinazione di apprendimento MAC, trasmissioni contraffatte e modalità promiscua sul gruppo di porte del bilanciatore del carico.
Con l'alta disponibilità, due bilanciatori del carico sono configurati in modalità passiva attiva. Se il bilanciatore del carico attivo presenta un problema, il traffico non riesce verso il bilanciatore del carico passivo.
Durante un upgrade di un bilanciatore del carico, si verifica un tempo di inattività. Se l'alta disponibilità è abilitata per il bilanciatore del carico, il tempo di inattività massimo è di due secondi.
Bilanciatore del carico BIG-IP F5 integrato
La piattaforma F5 BIG-IP offre vari servizi per aiutarti a migliorare la sicurezza, la disponibilità e le prestazioni delle tue applicazioni. Per i cluster Anthos su VMware, BIG-IP fornisce accesso esterno e servizi di bilanciamento del carico L3/4.
Per maggiori informazioni, consulta la pagina relativa all'alta disponibilità di BI-IP.
Ripristino di un cluster danneggiato
Le sezioni seguenti descrivono come recuperare un cluster danneggiato.
Recupero da errori host ESXi
I cluster Anthos su VMware si basano su vSphere HA per fornire il ripristino da un errore dell'host ESXi. vSphere HA può monitorare continuamente gli host ESXi e riavviare automaticamente le VM su altri host quando necessario. Questo è trasparente per i cluster Anthos sugli utenti VMware.
Ripristino da errori delle VM
Gli errori VM possono includere i seguenti:
Eliminazione imprevista di una VM.
Il disco di avvio della VM è danneggiato; ad esempio, un disco di avvio è diventato di sola lettura a causa dei log del journal dello spam.
Errore di avvio della VM a causa di problemi di configurazione del disco o della disco a basso rendimento. Ad esempio, una VM non può essere avviata perché per qualche motivo non è possibile assegnargli un indirizzo IP.
danneggiamento del file system Docker.
Perdita della VM del piano di controllo dell'amministratore a causa di un errore di upgrade.
Problemi relativi al sistema operativo.
Gli errori VM descritti in questa sezione non includono il danneggiamento o la perdita dei dati nel disco dati PV o etcd collegato alla VM. Per ulteriori informazioni, vedi Eseguire il ripristino da errori di archiviazione.
I cluster Anthos su VMware forniscono un meccanismo di recupero automatico per i nodi aggiuntivi per gli amministratori, i piani di controllo utente e i nodi utente. Questa funzionalità di riparazione automatica dei nodi può essere abilitata per cluster di amministrazione e cluster utente.
La VM del piano di controllo dell'amministratore è speciale, nel senso che non è gestita da un cluster Kubernetes e la sua disponibilità non influisce sulla continuità aziendale. Per il recupero degli errori VM del piano di controllo dell'amministratore, contatta l'Assistenza Google.
Ripristino da errori di archiviazione
Alcuni degli errori di archiviazione possono essere mitigati da vSphere HA e vSAN senza che ciò influisca sui cluster Anthos su VMware. Tuttavia, determinati errori di archiviazione potrebbero emergere dal livello vSphere causando la perdita o il danneggiamento dei dati su vari cluster Anthos sui componenti VMware.
Le informazioni stateful di un cluster e dei carichi di lavoro degli utenti vengono archiviate nelle seguenti posizioni:
etcd
Ogni cluster (cluster di utenti e cluster di amministrazione) ha un database etcd che archivia lo stato (oggetti Kubernetes) del cluster.
oggetti PersistentVolume
Utilizzato sia dai componenti di sistema sia dai carichi di lavoro degli utenti.
Recupero in seguito a perdita o danneggiamento dei dati etcd
etcd è il database utilizzato da Kubernetes per archiviare lo stato di tutti i cluster, inclusi i manifest delle applicazioni utente. Le operazioni del ciclo di vita delle applicazioni non funzioneranno più se il database etcd del cluster utente è danneggiato o perso. Le operazioni del ciclo di vita del cluster utente smetteranno di funzionare se il database etcd del cluster di amministrazione è danneggiato o perso.
etcd non fornisce un meccanismo integrato affidabile per il rilevamento dei danni ai dati. Esamina i log dei pod etcd se sospetti che i dati etcd siano danneggiati o vadano persi.
Un pod etcd in attesa/errore/losh di arresto anomalo non significa sempre che i dati etcd sono danneggiati o andranno persi. Il problema potrebbe essere dovuto a errori nelle VM che ospitano i pod etcetc. Dovresti eseguire la seguente procedura di recupero di etcd solo per il danneggiamento o la perdita di dati.
Per recuperare (in uno stato recente del cluster) la danneggiamento o la perdita dei dati etcd, è necessario eseguire il backup dei dati etcd dopo qualsiasi operazione del ciclo di vita nel cluster (ad esempio, creazione, aggiornamento o upgrade). Per eseguire il backup dei dati etcd, consulta Backup di un cluster di amministrazione e Backup di un cluster utente.
Il ripristino dei dati etcd ripristina lo stato precedente del cluster. In altre parole, se viene eseguito un backup prima del deployment di un'applicazione e, successivamente, per eseguire il ripristino del cluster, l'applicazione non sarà in esecuzione nel cluster ripristinato. Ad esempio, se utilizzi l'istantanea etcd di un cluster di amministrazione con un'istantanea prima di creare un cluster utente, nel cluster di amministrazione ripristinato viene rimosso il piano di controllo del cluster utente. Di conseguenza, consigliamo di eseguire il backup del cluster dopo ogni operazione critica del cluster.
Il danneggiamento o la perdita dei dati etcd possono verificarsi nei seguenti scenari:
Un singolo nodo di un cluster etcd a tre nodi (cluster utente HA) è danneggiato in modo permanente a causa del danneggiamento o della perdita di dati. In questo caso, solo un nodo è inaccessibile e il quorum etcd esiste ancora. Questo può verificarsi in un cluster ad alta disponibilità, in cui i dati di una replica etcd sono danneggiati o persi. Il problema può essere risolto senza alcuna perdita di dati sostituendo la replica etcd non riuscita con una nuova, nello stato pulito. Per maggiori informazioni, consulta la sezione Sostituire una replica etcd non riuscita.
I due nodi di un cluster etcd a tre nodi (cluster utente HA) sono danneggiati in modo permanente a causa del danneggiamento o della perdita di dati. Il quorum è smarrito, quindi sostituire le repliche etcd non riuscite con nuove. Lo stato del cluster deve essere ripristinato dai dati di backup. Per scoprire di più, consulta Ripristinare un cluster utente da un backup (HA).
Un cluster etcd a nodo singolo (cluster di amministrazione o cluster non ad alta disponibilità) viene danneggiato in modo permanente a causa del danneggiamento o della perdita dei dati. Il quorum è perso, quindi devi creare un nuovo cluster dal backup. Per ulteriori informazioni, consulta Ripristinare un cluster utente da un backup (non ad alta disponibilità).
Ripristino in caso di perdita o danneggiamento dell'applicazione utente
I cluster Anthos sui clienti VMware possono utilizzare determinate soluzioni di archiviazione dei partner per effettuare il backup e il ripristino di volumi permanenti delle applicazioni utente.
Per l'elenco dei partner di archiviazione che sono stati qualificati per i cluster Anthos su VMware, consulta Partner Anthos Ready Storage.
Ripristino da errori del bilanciatore del carico
Per il bilanciamento del carico in bundle (Seesaw), puoi eseguire il ripristino in caso di errore ricreando il bilanciatore del carico. Per ricreare il bilanciatore del carico, esegui l'upgrade di Seesaw alla stessa versione indicata in Eseguire l'upgrade del bilanciatore del carico per il cluster di amministrazione.
In caso di errori del bilanciatore del carico del cluster di amministrazione, il piano di controllo potrebbe non essere raggiungibile. Di conseguenza, devi eseguire l'upgrade sulla VM del piano di controllo dell'amministratore da cui è possibile accedere al piano di controllo.
Per i bilanciatori del carico integrati (F5), consulta l'assistenza F5.
Utilizzo di più cluster per il ripristino di emergenza
Il deployment di applicazioni in più cluster su più vCenter o piattaforme Anthos può fornire una disponibilità globale più elevata e limitare il raggio di esplosione durante le interruzioni.
Questa configurazione utilizza il cluster Anthos esistente nel data center secondario per il ripristino di emergenza anziché la configurazione di un nuovo cluster. Di seguito è riportato un riepilogo generale a questo scopo:
Crea un altro cluster di amministrazione e un cluster utente nel data center secondario. In questa architettura multi-cluster, richiediamo agli utenti di avere due cluster di amministrazione in ogni data center e ogni cluster di amministrazione esegue un cluster utente.
Il cluster utente secondario ha un numero minimo di nodi worker (tre) ed è in modalità standby attivo (sempre in esecuzione).
I deployment delle applicazioni possono essere replicati tra i due vCenter utilizzando Anthos Config Management. In alternativa, l'approccio preferito consiste nell'utilizzare una toolchain di applicazioni esistente (CI/CD, Spinnaker).
In caso di emergenza, il cluster utente può essere ridimensionato in base al numero di nodi.
È inoltre necessario un cambio di DNS per instradare il traffico tra i cluster al data center secondario.