O Google Distributed Cloud inclui várias opções para geração de registros e monitoramento de cluster, incluindo serviços gerenciados baseados na nuvem, ferramentas de código aberto e compatibilidade validada com soluções comerciais de terceiros. Nesta página, explicamos essas opções e fornecemos algumas orientações básicas sobre como selecionar a solução adequada para seu ambiente.
Opções do Google Distributed Cloud
Há várias opções de geração de registros e monitoramento para o Google Distributed Cloud:
- Cloud Logging e Cloud Monitoring, ativados por padrão nos componentes do sistema Bare Metal.
- O Prometheus e o Grafana estão disponíveis no Cloud Marketplace.
- Configurações validadas com soluções de terceiros
Cloud Logging e Cloud Monitoring
O Google Cloud Observability é a solução de observabilidade integrada do Google Cloud. Ele oferece uma solução de geração de registros totalmente gerenciada, coleta de métricas, monitoramento, uso de painéis e emissão de alertas. O Cloud Monitoring monitora os clusters do Google Distributed Cloud de maneira semelhante aos clusters do GKE baseados na nuvem.
É possível configurar os agentes para alterar o escopo de geração de registros e monitoramento, bem como o nível de métricas coletadas:
- O escopo de geração de registros e monitoramento só pode ser definido como componentes do sistema (padrão) ou para componentes e aplicativos do sistema.
- O nível das métricas coletadas pode ser configurado para um conjunto otimizado de métricas (padrão) ou para métricas completas.
Consulte Como configurar agentes do Stackdriver para o Google Distributed Cloud neste documento para mais informações.
O Logging e o Monitoring oferecem uma solução de observabilidade única, fácil de configurar e avançada, baseada na nuvem. É altamente recomendável o Logging e o Monitoring ao executar cargas de trabalho no Google Distributed Cloud. Para aplicativos com componentes em execução no Google Distributed Cloud e na infraestrutura local padrão, considere outras soluções para ter uma visão completa desses aplicativos.
Para mais detalhes sobre arquitetura, configuração e quais dados são replicados para seu projeto do Google Cloud por padrão, consulte Como funcionam o Logging e o Monitoring para o Google Distributed Cloud.
Para mais informações sobre o Logging, consulte a documentação do Cloud Logging.
Para mais informações sobre o Monitoring, consulte a documentação do Cloud Monitoring.
Para saber como visualizar e usar as métricas de utilização de recursos do Cloud Monitoring do Google Distributed Cloud no nível da frota, consulte Usar a visão geral da edição Enterprise do Google Kubernetes Engine (GKE).
Prometheus e Grafana
O Prometheus e o Grafana são dois produtos de monitoramento de código aberto conhecidos disponíveis no Cloud Marketplace:
O Prometheus coleta métricas de aplicativos e sistemas.
O Alertmanager processa o envio de alertas com vários mecanismos de alerta diferentes.
Grafana é uma ferramenta de painéis.
Recomendamos que você use o Google Cloud Managed Service para Prometheus, baseado no Cloud Monitoring, para todas as suas necessidades de monitoramento. Com o Google Cloud Managed Service para Prometheus, é possível monitorar componentes do sistema sem custo financeiro. O Google Cloud Managed Service para Prometheus também é compatível com o Grafana. No entanto, se você preferir um sistema de monitoramento local puro, poderá optar por instalar o Prometheus e o Grafana nos clusters.
Se você instalou o Prometheus localmente e quer coletar métricas de componentes do sistema, conceda permissão à sua instância local do Prometheus para acessar os endpoints de métricas desses componentes:
Vincule a conta de serviço da instância do Prometheus ao ClusterRole
gke-metrics-agentpredefinido e use o token da conta de serviço como credencial para coletar as métricas dos seguintes componentes do sistema:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Use a chave de cliente e o certificado armazenados no secret
kube-system/stackdriver-prometheus-etcd-scrapepara autenticar a extração de métrica do etcd.Crie uma NetworkPolicy para permitir o acesso do seu namespace a kube-state-metrics.
Soluções de terceiros
O Google trabalhou com vários provedores de soluções de monitoramento e geração de registros de terceiros para ajudar os produtos a funcionar bem com o Google Distributed Cloud. Entre eles, Datadog, Elastic e Splunk. Outros terceiros validados serão adicionados no futuro.
Os guias de solução a seguir estão disponíveis para o uso de soluções de terceiros com o Google Distributed Cloud:
- Como monitorar o Google Distributed Cloud com o Elastic Stack
- Coletar registros no Google Distributed Cloud com o Splunk Connect
Como funcionam o Logging e o Monitoring para o Google Distributed Cloud
O Cloud Logging e o Cloud Monitoring são instalados e ativados em cada cluster quando você cria um novo cluster de administrador ou de usuário.
Os agentes do Stackdriver incluem vários componentes em cada cluster:
Operador do Stackdriver (
stackdriver-operator-*). Gerencia o ciclo de vida de todos os outros agentes do Stackdriver implantados no cluster.Recurso personalizado do Stackdriver. Um recurso criado automaticamente como parte do processo de instalação do Google Distributed Cloud.
Agente de métricas do GKE (
gke-metrics-agent-*). Um DaemonSet baseado no OpenTelemetry Collector que copia métricas de cada nó para o Cloud Monitoring. Um DaemonSetnode-exportere uma implantaçãokube-state-metricstambém estão incluídos para fornecer mais métricas sobre o cluster.Encaminhamento de registros do Stackdriver (
stackdriver-log-forwarder-*). Um DaemonSet do Fluent Bit que encaminha os registros de cada máquina para o Cloud Logging. O encaminhador de registro armazena em buffer as entradas de registro no nó localmente e as envia por até quatro horas. Se o buffer ficar cheio ou se o encaminhador de registro não conseguir acessar a API Cloud Logging por mais de quatro horas, os registros serão descartados.Agente de metadados (
stackdriver-metadata-agent-). Uma implantação que envia metadados para recursos do Kubernetes, como pods, implantações ou nós, para a API Config Monitoring for Ops. Esses dados são usados para enriquecer consultas de métricas, permitindo que você faça consultas por nome de implantação, nome de nó ou até mesmo nome de serviço do Kubernetes.
Veja os agentes instalados pelo Stackdriver executando o seguinte comando:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
A saída deste comando é semelhante a:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Métricas do Cloud Monitoring
Para uma lista de métricas coletadas pelo Cloud Monitoring, consulte Ver métricas do Google Distributed Cloud.
Como configurar agentes do Stackdriver para o Google Distributed Cloud
Os agentes do Stackdriver instalados com o Google Distributed Cloud coletam dados sobre os componentes do sistema com o objetivo de manter e solucionar problemas com os clusters. As seções a seguir descrevem os modos de configuração e operação do Stackdriver.
Somente componentes do sistema (modo padrão)
Após a instalação, os agentes do Stackdriver são configurados, por padrão, para coletar registros e métricas, incluindo detalhes de desempenho (por exemplo, uso de CPU e memória) e metadados semelhantes dos componentes de sistema fornecidos pelo Google. Isso inclui todas as cargas de trabalho no cluster de administrador e, para clusters de usuário, as cargas de trabalho nos namespaces kube-system, gke-system, gke-connect, istio-system e config-management-system.
Componentes do sistema e aplicativos.
Para ativar a geração de registros e o monitoramento de aplicativos no modo padrão, siga as etapas em Ativar a geração de registros e o monitoramento de aplicativos.
Métricas otimizadas (métricas padrão)
Por padrão, as implantações kube-state-metrics em execução no cluster coletam e relatam um conjunto otimizado de métricas do kube para a observabilidade do Google Cloud (antigo Stackdriver).
Menos recursos são necessários para coletar esse conjunto otimizado de métricas, o que melhora o desempenho e a escalonabilidade geral.
Para desativar as métricas otimizadas (não recomendado), modifique a configuração padrão no recurso personalizado do Stackdriver.
Use o Google Cloud Managed Service para Prometheus em componentes selecionados do sistema
O Google Cloud Managed Service para Prometheus faz parte do Cloud Monitoring e está disponível como uma opção para componentes do sistema. Os benefícios do Google Cloud Managed Service para Prometheus incluem:
É possível continuar usando o monitoramento atual baseado no Prometheus sem alterar os alertas e os painéis do Grafana.
Se você usa o GKE e o Google Distributed Cloud, é possível utilizar a mesma linguagem de consulta do Prometheus (PromQL) para métricas em todos os clusters. Também é possível usar a guia PromQL no Metrics Explorer no console do Google Cloud.
Ativar e desativar o Google Cloud Managed Service para Prometheus
O Google Cloud Managed Service para Prometheus é ativado por padrão no Google Distributed Cloud.
Para desativar o Google Cloud Managed Service para Prometheus, faça o seguinte:
Abra o objeto Stackdriver chamado
stackdriverpara edição:kubectl --kubeconfig CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriverAdicione o portão de recurso
enableGMPForSystemMetricse defina-o comofalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: featureGates: enableGMPForSystemMetrics: falseFeche a sessão de edição.
Conferir dados da métrica
Quando enableGMPForSystemMetrics é definido como true, as métricas dos componentes a seguir têm um formato diferente de armazenamento e consulta no Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet e cadvisor
- kube-state-metrics
- exportador de nós
No novo formato, é possível consultar as métricas anteriores usando o PromQL ou a Linguagem de consulta do Monitoring (MQL):
PromQL
Exemplo de consulta PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
MQL
Para usar o MQL, defina o recurso monitorado como prometheus_target, use o nome da métrica com o prefixo kubernetes.io/anthos e adicione o tipo de Prometheus como um sufixo ao nome da métrica.
fetch prometheus_target
| metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram'
| align delta(5m)
| every 5m
| group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Como configurar painéis do Grafana com o Google Cloud Managed Service para Prometheus
Para usar o Grafana com dados de métricas do Google Cloud Managed Service para Prometheus, primeiro configure e autentique a fonte de dados do Grafana. Para configurar e autenticar a fonte de dados, use o sincronizador da fonte de dados (datasource-syncer) para gerar credenciais do OAuth2 e sincronizá-las com o Grafana por meio da API de fonte de dados do Grafana. O sincronizador da fonte de dados define a
API Cloud Monitoring como o URL do servidor do Prometheus (o valor do URL começa com
https://monitoring.googleapis.com) na fonte de dados no Grafana.
Siga as etapas em Consultar usando o Grafana para autenticar e configurar uma fonte de dados do Grafana para consultar dados do Google Cloud Managed Service para Prometheus.
Um conjunto de painéis de amostra do Grafana é fornecido no repositório anthos-samples no GitHub. Para instalar os painéis de amostra, faça o seguinte:
Faça o download dos arquivos JSON de amostra:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Se a fonte de dados Grafana tiver sido criada com um nome diferente de
Managed Service for Prometheus, mude o campodatasourceem todos os arquivos JSON:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Substitua [DATASOURCE_NAME] pelo nome da fonte de dados no Grafana que foi apontada para o serviço
frontenddo Prometheus.Acesse a IU do Grafana no navegador e selecione + Importar no menu Painéis.
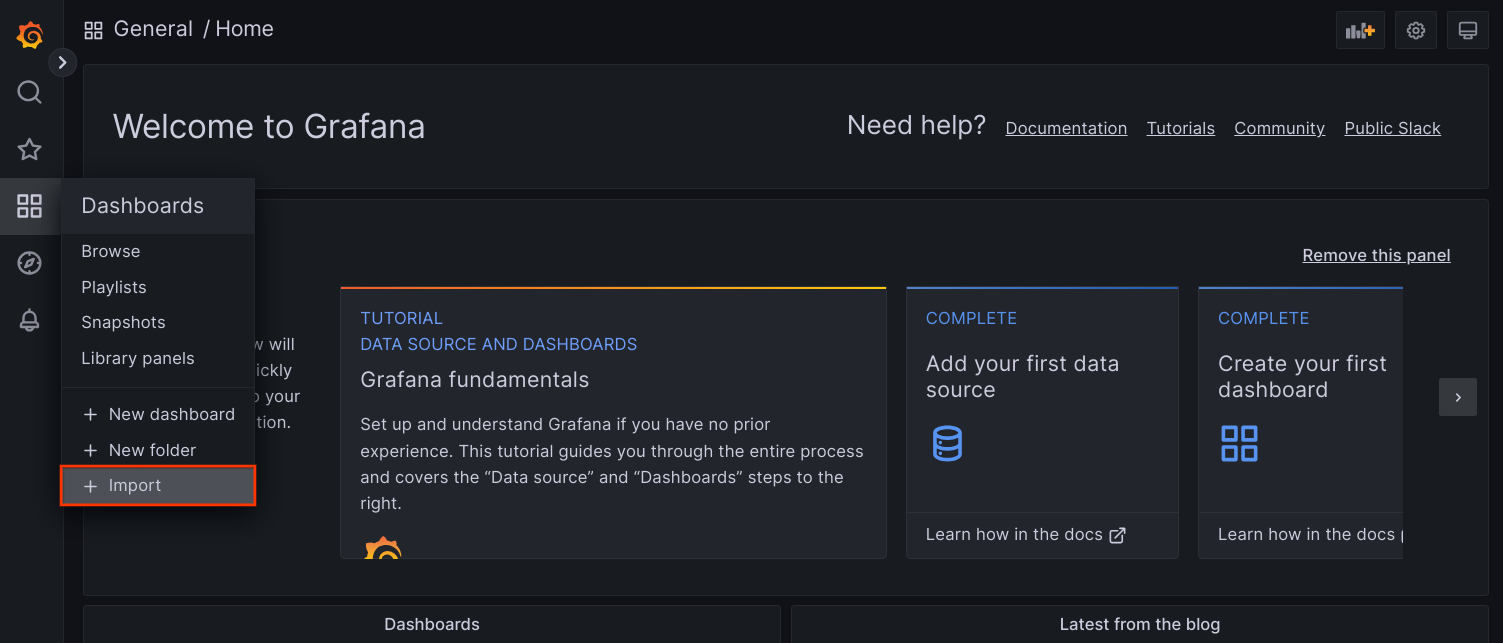
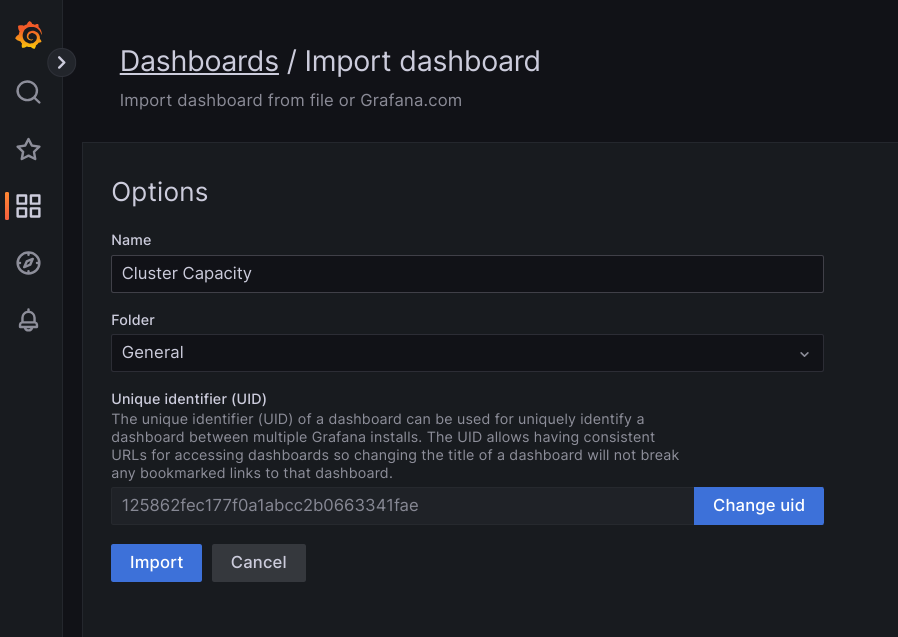
Faça upload do arquivo JSON ou copie e cole o conteúdo do arquivo e selecione Carregar. Depois que o conteúdo do arquivo for carregado, selecione Importar. Também é possível alterar o nome do painel e o UID antes de importar.
O painel importado será carregado se o Google Distributed Cloud e a fonte de dados estiverem configurados corretamente. Por exemplo, a captura de tela a seguir mostra o painel configurado por
cluster-capacity.json.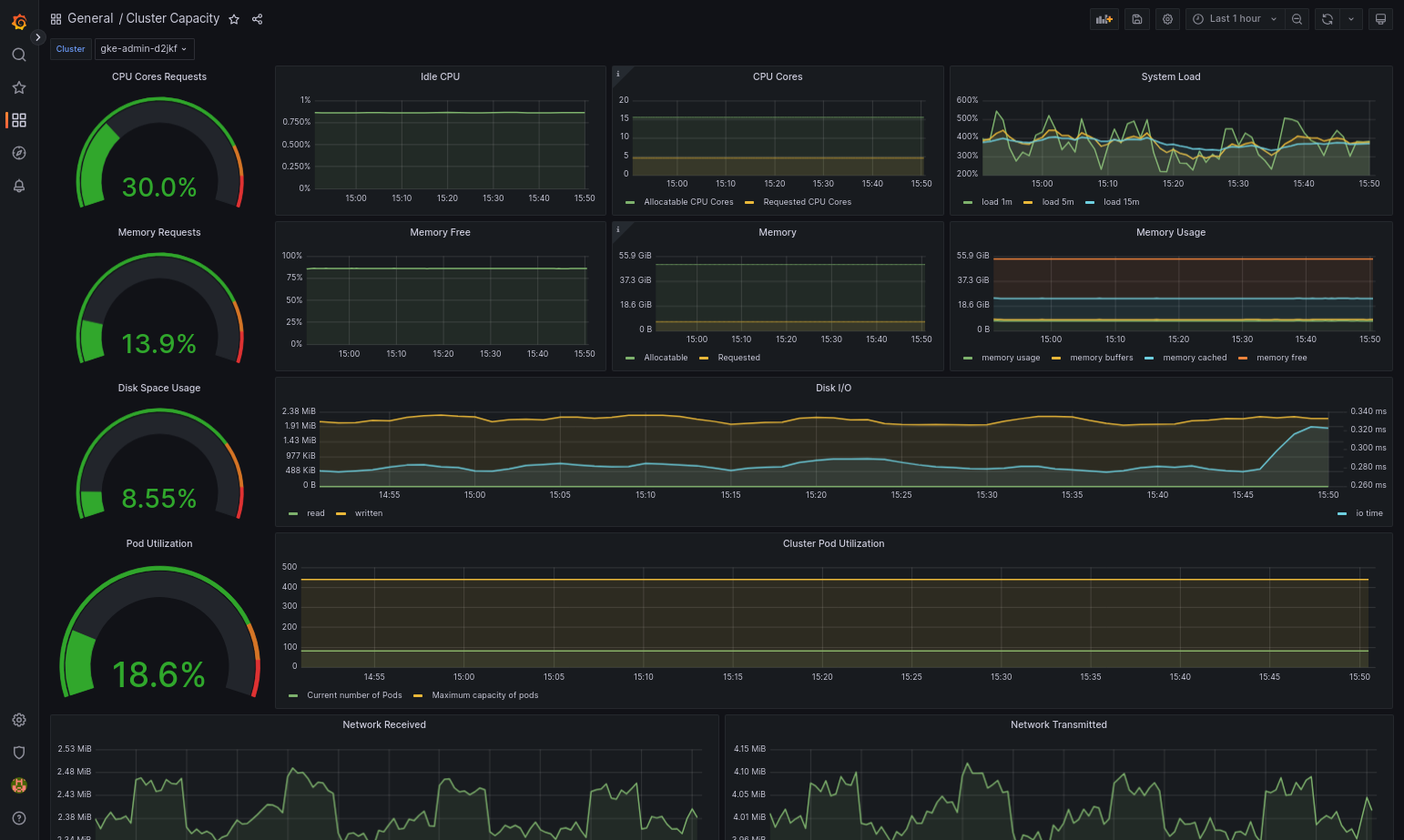
Recursos adicionais
Para mais informações sobre o Google Cloud Managed Service para Prometheus, consulte:
As métricas do plano de controle do GKE são compatíveis com PromQL
Como usar o Managed Service para Prometheus em aplicativos de usuário no Google Distributed Cloud
Como configurar recursos do componente Stackdriver
Quando você cria um cluster, o Google Distributed Cloud cria automaticamente um recurso personalizado do Stackdriver. É possível editar a especificação no recurso personalizado para substituir os valores padrão das solicitações e limites de CPU e memória de um componente do Stackdriver, além de substituir separadamente a configuração padrão de métricas otimizadas.
Como modificar as solicitações e os limites padrão de CPU e memória para um componente do Stackdriver.
Os clusters com alta densidade de pods introduzem sobrecarga de geração de registros e monitoramento. Em casos extremos, os componentes do Stackdriver podem relatar perto do limite de CPU e de utilização de memória ou podem estar sujeitos a reinicializações constantes devido a limites de recursos. Nesse caso, para substituir os valores padrão de solicitações e limites de CPU e memória de um componente do Stackdriver, use as seguintes etapas:
Execute o seguinte comando para abrir o recurso personalizado do Stackdriver em um editor de linha de comando:
kubectl -n kube-system edit stackdriver stackdriver
No recurso personalizado do Stackdriver, adicione a seção
resourceAttrOverrideno campospec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYObserve que a seção
resourceAttrOverridesubstitui todos os limites e solicitações padrão existentes do componente que você especificar. Os seguintes componentes são compatíveis comresourceAttrOverride:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Um arquivo de exemplo será parecido com o seguinte:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiPara salvar as alterações no recurso personalizado do Stackdriver, salve e saia do editor de linha de comando.
Para verificar a integridade do pod:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Uma resposta para um pod íntegro é semelhante a esta:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Para verificar a especificação do pod do componente para garantir que os recursos estão configurados corretamente:
kubectl -n kube-system describe pod POD_NAME
Substitua
POD_NAMEpelo nome do pod que você acabou de alterar. Por exemplo,gke-metrics-agent-4th8r.A resposta é semelhante a esta:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Desativar métricas otimizadas
Por padrão, as implantações kube-state-metrics em execução no cluster coletam e informam um
conjunto otimizado de métricas do kube para o Stackdriver. Se você precisar de mais métricas, recomendamos que encontre uma substituta na lista de métricas do Google Distributed Cloud.
Veja alguns exemplos de substituições que podem ser usadas:
| Métrica desativada | Substituição |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Para desativar a configuração padrão de métricas otimizadas (não recomendado), faça o seguinte:
Abra o recurso personalizado do Stackdriver em um editor de linha de comando:
kubectl -n kube-system edit stackdriver stackdriver
Defina o campo
optimizedMetricscomofalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Salve as alterações e saia do editor da linha de comando.
Servidor de métricas
O Metrics Server é a fonte das métricas de recursos do contêiner para vários pipelines de escalonamento automático. O Metrics Server recupera métricas de kubelets e as expõe por meio da API Metrics do Kubernetes. O HPA e o VPA usam essas métricas para determinar quando acionar o escalonamento automático. O servidor de métricas é escalonado usando o complemento de redimensionamento.
Em casos extremos em que a alta densidade de pods cria sobrecarga de geração de registros e monitoramento, o servidor de métricas pode ser interrompido e reiniciado devido a limitações de recursos. Nesse caso, é possível alocar mais recursos para o servidor de métricas editando o configmap metrics-server-config no namespace gke-managed-metrics-server e alterando o valor de cpuPerNode e memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
O conteúdo de exemplo do ConfigMap é:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Depois de atualizar o ConfigMap, recrie os pods do metric-server com o seguinte comando:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Requisitos de configuração do Logging e do Monitoring
Há vários requisitos de configuração para ativar o Cloud Logging e o Cloud Monitoring com o Google Distributed Cloud. Estas etapas estão incluídas em Como configurar uma conta de serviço para uso com o Logging e o Monitoring na página de ativação dos serviços do Google e na lista a seguir:
- É preciso criar um espaço de trabalho do Cloud Monitoring no projeto do Google Cloud. Para isso, clique em Monitoramento no console do Google Cloud e siga o fluxo de trabalho.
Você precisa ativar as seguintes APIs do Stackdriver:
Você precisa atribuir os seguintes papéis de IAM à conta de serviço usada pelos agentes do Stackdriver:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Preços
Os registros e as métricas do sistema da edição Google Kubernetes Engine (GKE) Enterprise não são cobrados.
Em um cluster do Google Distributed Cloud, os registros e as métricas do sistema da edição Google Kubernetes Engine (GKE) Enterprise incluem o seguinte:
- Registros e métricas de todos os componentes em um cluster de administrador
- Registros e métricas de componentes nesses namespaces em um cluster de usuário:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system
Para mais informações, consulte Preços de observabilidade do Google Cloud.
Para saber mais sobre o crédito para métricas do Cloud Logging, entre em contato com a equipe de vendas e receba mais informações sobre preços.