Questa pagina descrive come utilizzare la dashboard Query Insights per rilevare e analizzare i problemi di prestazioni. Per una panoramica di questa funzionalità, consulta Panoramica di Query Insights.
Puoi utilizzare Gemini Cloud Assist per monitorare e risolvere i problemi delle risorse AlloyDB. Per ulteriori informazioni, vedi Monitorare e risolvere i problemi con l'assistenza di Gemini.
Prima di iniziare
Se tu o altri utenti dovete visualizzare il piano di query o eseguire la tracciatura end-to-end, avete bisogno di autorizzazioni IAM (Identity and Access Management) specifiche. Puoi creare un ruolo personalizzato e aggiungervi le autorizzazioni IAM necessarie. Poi puoi aggiungere questo ruolo a ogni account utente che utilizza gli approfondimenti sulle query per risolvere un problema. Vedi Creare un ruolo personalizzato.
Il ruolo personalizzato deve disporre della seguente autorizzazione IAM: cloudtrace.traces.get.
Aprire la dashboard Query Insights
Per aprire la dashboard Approfondimenti sulle query:
- Nell'elenco di cluster e istanze, fai clic su un'istanza.
- Fai clic su Vai a Query Insight per informazioni più approfondite su query e prestazioni sotto il grafico delle metriche nella pagina Panoramica cluster oppure seleziona la scheda Query Insight nel riquadro di navigazione a sinistra.
Nella pagina successiva, puoi utilizzare le seguenti opzioni per filtrare i risultati:
- Selettore di istanze. Consente di selezionare l'istanza principale o le istanze del pool di lettura nel cluster. Per impostazione predefinita, è selezionata l'istanza principale. I dettagli mostrati sono aggregati per tutte le istanze del pool di lettura connesse e i relativi nodi.
- Database. Filtra il carico delle query su un database specifico o su tutti i database.
- Utente. Filtra il carico di query da account utente specifici.
- Indirizzo client. Filtra il carico delle query da un indirizzo IP specifico.
- Intervallo di tempo. I filtri caricano le query in base a intervalli di tempo, ad esempio ora, giorno, settimana o un intervallo personalizzato.
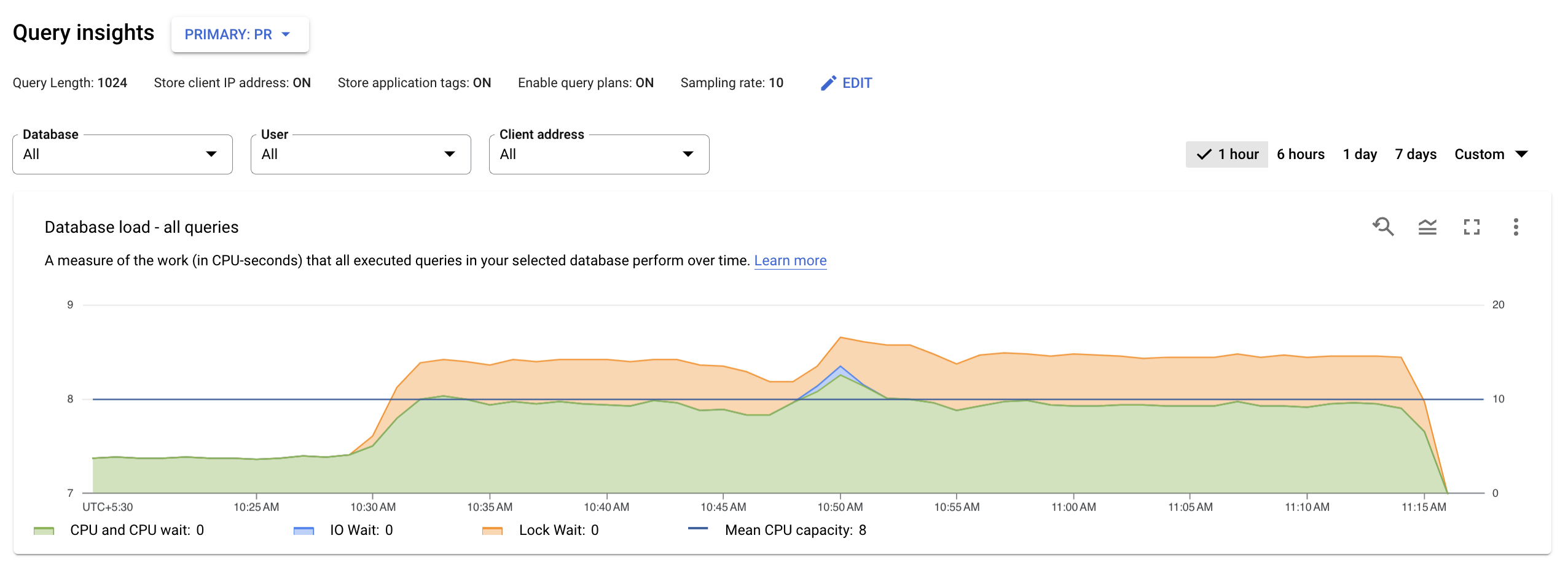
Modifica la configurazione di Query Insights
Query Insights è abilitato per impostazione predefinita sulle istanze AlloyDB. Puoi modificare la configurazione predefinita di Query Insights.
Per modificare la configurazione di Query Insights per un'istanza AlloyDB:
Console
Nella console Google Cloud , vai alla pagina Cluster.
Fai clic su un cluster nella colonna Nome risorsa.
Fai clic su Approfondimenti sulle query nel pannello di navigazione a sinistra.
Seleziona Primario o Pool di lettura dall'elenco Approfondimenti sulle query, quindi fai clic su Modifica.
Modifica i campi Query Insights:
Per modificare il limite predefinito di 1024 byte per la lunghezza delle query da analizzare per AlloyDB, inserisci un numero compreso tra 256 e 4500 nel campo Lunghezza delle query.
L'istanza viene riavviata dopo la modifica di questo campo.
Nota: limiti di lunghezza delle query più elevati richiedono più memoria.
Per personalizzare i set di funzionalità di Query Insights, modifica le seguenti opzioni:
Campionamento del piano di query: seleziona questa casella di controllo per visualizzare le operazioni utilizzate per completare un esempio di query. La frequenza di campionamento determina il numero massimo di query che AlloyDB può campionare al minuto per l'istanza per nodo.
Nel campo Frequenza di campionamento massima, inserisci un numero compreso tra 1 e 20. Per impostazione predefinita, la frequenza di campionamento è impostata su 5. Per disattivare il campionamento, deseleziona la casella di controllo Campionamento del piano di query.
Archivia gli indirizzi IP client: seleziona questa casella di controllo per sapere da dove provengono le query e raggruppare queste informazioni per generare le metriche.
Archivia i tag delle applicazioni: seleziona questa casella di controllo per sapere quali applicazioni con tag stanno effettuando richieste e per raggruppare queste informazioni per eseguire metriche. Per saperne di più sui tag delle applicazioni, consulta la specifica.
Fai clic su Aggiorna istanza.
gcloud
Per abilitare Query Insights per un'istanza AlloyDB utilizzando i comandi Google Cloud CLI, segui questi passaggi:
- Installa Google Cloud CLI.
- Per inizializzare gcloud CLI, esegui questo comando:
gcloud init
Se utilizzi una shell locale, crea credenziali di autenticazione locali per il tuo account utente:
gcloud auth application-default login
Non devi eseguire questa operazione se utilizzi Cloud Shell.
Per maggiori informazioni, vedi Configurare l'autenticazione per un ambiente di sviluppo locale.
Ecco un esempio:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressSostituisci quanto segue:
INSTANCE: l'ID dell'istanza da aggiornareCLUSTER: l'ID del cluster dell'istanzaPROJECT: l'ID del progetto del clusterREGION: la regione del cluster, ad esempious-central1QUERY_LENGTH: la lunghezza della query, compresa tra 256 e 4500QUERY_PLANS: il numero di piani di query da configurare al minuto.
Inoltre, utilizza uno o più dei seguenti flag facoltativi:
--insights-config-query-string-length: imposta il limite predefinito per la lunghezza delle query su un valore specificato compreso tra 256 e 4500 byte. La lunghezza predefinita delle query è di 1024 byte. Le query più lunghe sono più utili per le query analitiche, ma richiedono anche più memoria. La modifica della lunghezza della query richiede il riavvio dell'istanza. Puoi comunque aggiungere tag alle query che superano il limite di lunghezza.--insights-config-query-plans-per-minute: per impostazione predefinita, vengono acquisiti un massimo di cinque campioni di piano di query eseguiti al minuto su tutti i database dell'istanza. Modifica questo valore scegliendo un numero compreso tra 1 e 20. Per disattivare il campionamento, inserisci 0. È probabile che l'aumento della frequenza di campionamento fornisca più punti dati, ma potrebbe incrementare il sovraccarico delle prestazioni.--insights-config-record-client-address: archivia gli indirizzi IP client da cui provengono le query e ti aiuta a raggruppare i dati per eseguire metriche corrispondenti. Le query provengono da più host. L'esame dei grafici per le query provenienti da indirizzi IP client può aiutarti a identificare l'origine di un problema. Se non vuoi archiviare gli indirizzi IP client, utilizza--no-insights-config-record-client-address.--insights-config-record-application-tags: archivia i tag delle applicazioni che ti aiutano a determinare le API e le route modello-visualizzazione-controller (MVC) che effettuano le richieste e raggruppa i dati per generare le metriche corrispondenti. Questa opzione richiede di commentare le query con un insieme specifico di tag. Se non vuoi memorizzare i tag delle applicazioni, utilizza--no-insights-config-record-application-tags.
Terraform
Per utilizzare Terraform per configurare Query Insights, utilizza la risorsa google_alloydb_instance.
Ecco un esempio:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
Sostituisci quanto segue:
QUERY_STRING_LENGTH_VALUE: lunghezza della stringa di query. Il valore predefinito è1024. È valido qualsiasi numero intero compreso tra 256 e 4500.RECORD_APPLICATION_TAG_VALUE: registra il tag di applicazione per un'istanza. Il valore predefinito ètrue.RECORD_CLIENT_ADDRESS_VALUE: registra l'indirizzo client per un'istanza. Il valore predefinito ètrue.QUERY_PLANS_PER_MINUTE_VALUE: il numero di piani di esecuzione delle query acquisiti da Insights al minuto per tutte le query combinate. Il valore predefinito è5. È valido qualsiasi numero intero compreso tra 0 e 20.Per scoprire come applicare o rimuovere una configurazione Terraform, consulta Comandi Terraform di base.
La configurazione dell'istanza di esempio con la configurazione di Query Insights aggiunta dovrebbe essere visualizzata come segue:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
Questo esempio configura le impostazioni di osservabilità sull'istanza AlloyDB. Per un elenco completo dei parametri per questa chiamata, consulta Metodo: projects.locations.clusters.instances.patch.
Per configurare le impostazioni degli insight sulle query, modifica i campi facoltativi in base alle esigenze. Per un elenco completo dei campi per questa chiamata, consulta QueryInsightsInstanceConfig.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
CLUSTER_ID: l'ID del cluster che crei. Deve iniziare con una lettera minuscola e può contenere lettere minuscole, numeri e trattini.PROJECT_ID: l'ID del progetto in cui vuoi posizionare il cluster.LOCATION_ID: l'ID della regione del cluster.INSTANCE_ID: il nome dell'istanza primaria che vuoi creare.
Per modificare la configurazione dell'istanza, utilizza la seguente richiesta PATCH:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
Il corpo JSON della richiesta che configura tutti i campi di osservabilità ha il seguente aspetto:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
Miglioramento delle prestazioni delle query
Query Insights risolve i problemi delle query AlloyDB per cercare problemi di prestazioni. La dashboard degli approfondimenti sulle query mostra il carico delle query in base ai fattori che selezioni. Il carico delle query è una misura del lavoro totale per tutte le query nell'istanza nell'intervallo di tempo selezionato.
Query Insights consente di rilevare e analizzare i problemi di prestazioni delle query. Per risolvere i problemi relativi alle query con gli approfondimenti sulle query:
- Visualizza il carico del database per tutte le query.
- Identifica una query o un tag problematico.
- Esamina la query o il tag per identificare i problemi.
- Esamina una traccia generata da una query di esempio.
Visualizza il carico del database per tutte le query
La dashboard di approfondimento delle query di primo livello mostra il grafico Carico del database - tutte le query principali utilizzando i dati filtrati. Il carico delle query del database è una misura del lavoro (in secondi CPU) che le query eseguite nel database selezionato eseguono nel tempo. Ogni query in esecuzione utilizza o attende risorse di CPU, risorse I/O o risorse di blocco. Il carico delle query del database è il rapporto tra il tempo impiegato da tutte le query completate in un dato intervallo e le ore effettive.
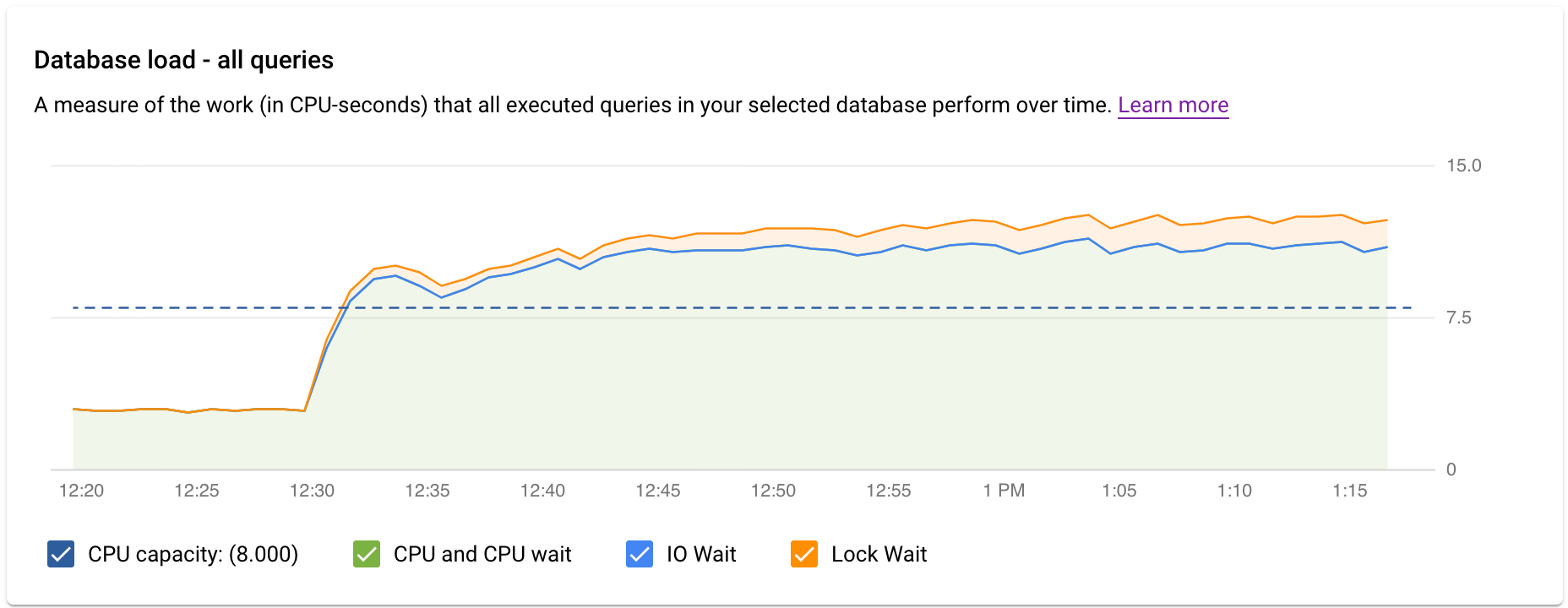
Le linee colorate nel grafico mostrano il carico delle query, suddiviso in quattro categorie:
- Capacità CPU: il numero di CPU disponibili sull'istanza.
CPU e Attesa CPU: il rapporto tra il tempo impiegato dalle query in uno stato attivo e le ore effettive. I tempi di attesa di I/O e blocchi non bloccano le query in stato attivo. Questa metrica potrebbe indicare che la query sta utilizzando la CPU o è in attesa che lo scheduler Linux pianifichi il processo del server che esegue la query mentre altri processi utilizzano la CPU.
Nota: il carico della CPU tiene conto sia del runtime sia del tempo di attesa della pianificazione di Linux per pianificare il processo del server in esecuzione. Di conseguenza, il carico della CPU può superare la linea del core massimo.
Attesa I/O: il rapporto tra il tempo impiegato dalle query in attesa di I/O e le ore effettive. L'attesa I/O include attesa di lettura I/O e attesa di scrittura I/O. Consulta la tabella degli eventi PostgreSQL. Se vuoi una suddivisione delle informazioni per le attese I/O, puoi visualizzarla in Cloud Monitoring. Per ulteriori informazioni, consulta i grafici delle metriche.
Attesa blocco: il rapporto tra il tempo impiegato dalle query in attesa di blocchi e le ore effettive. Include le attese per blocchi di tipo Lock, LwLock e BufferPin Lock. Se vuoi una suddivisione delle informazioni per le attese di blocco, puoi visualizzarla in Cloud Monitoring. Per ulteriori informazioni, consulta i grafici delle metriche.
Successivamente, esamina il grafico e utilizza le opzioni di filtro per rispondere a queste domande:
- Il carico della query è elevato? Il grafico mostra picchi o valori elevati nel tempo? Se non noti un carico elevato, il problema non riguarda le query.
- Da quanto tempo il carico è elevato? È solo alta ora? O è alta da molto tempo? Utilizza la selezione dell'intervallo per selezionare vari periodi di tempo per scoprire da quanto tempo si verifica il problema. In alternativa, puoi aumentare lo zoom per visualizzare una finestra temporale in cui si osservano picchi di carico delle query. Puoi diminuire lo zoom per visualizzare fino a una settimana della cronologia.
- Cosa sta causando il carico elevato? Puoi selezionare le opzioni per esaminare la capacità della CPU, l'attesa CPU, l'attesa di blocco o l'attesa IO. Il grafico per ciascuna di queste opzioni ha un colore diverso, in modo da poter vedere quale ha il carico più elevato. La linea blu scuro sul grafico mostra la capacità massima della CPU del sistema. Consente di confrontare il carico di query con la capacità massima della CPU del sistema. Questo confronto ti aiuta a sapere se un'istanza sta esaurendo le risorse CPU.
- Quale database sta riscontrando il carico? Seleziona database diversi dal menu a discesa Database per trovare quelli con i carichi più elevati.
- Utenti o indirizzi IP specifici causano carichi più elevati? Seleziona utenti e indirizzi diversi dai menu a discesa per confrontare quali causano carichi più elevati.
Filtrare il carico del database
Le sezioni Query e tag ti consentono di filtrare o ordinare il carico delle query per una query selezionata o un tag di query SQL.
Filtra per query
La tabella QUERY fornisce una panoramica delle query che causano il carico maggiore. La tabella mostra tutte le query normalizzate per la finestra temporale e le opzioni selezionate nella dashboard degli approfondimenti sulle query.
Per impostazione predefinita, la tabella ordina le query in base al tempo di esecuzione totale all'interno della finestra temporale selezionata.
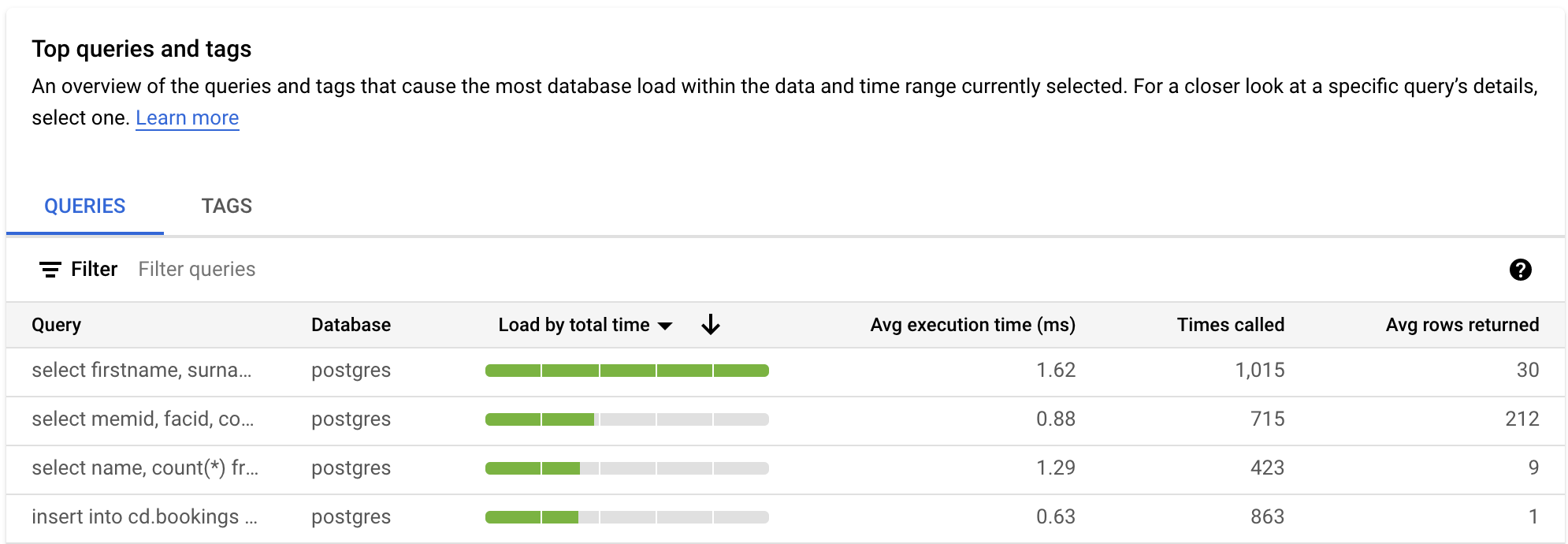
Per filtrare la tabella, seleziona una proprietà da Filtra query. Per ordinare la tabella, seleziona un'intestazione di colonna. La tabella mostra le seguenti proprietà:
Stringa di query. La stringa di query normalizzata. Per impostazione predefinita, gli approfondimenti sulle query mostrano 1024 caratteri nella stringa di query.
Le query etichettate
UTILITY COMMANDin genere includono comandiBEGIN,COMMITeEXPLAINo comandi wrapper.Database. Il database su cui è stata eseguita la query.
Carico per tempo totale/Carico per CPU/Carico per attesa IO/Carico per attesa blocco. Queste opzioni ti consentono di filtrare query specifiche per trovare il carico più elevato per ogni opzione.
Tempo di esecuzione medio (ms). Il tempo totale impiegato da tutte le attività secondarie in tutti i worker paralleli per completare la query. Per saperne di più, vedi Tempo e durata di esecuzione medi.
Volte in cui è stato chiamato. Il numero di volte in cui la query è stata chiamata dall'applicazione.
Media righe recuperate. Il numero medio di righe recuperate per la query.
Gli approfondimenti sulle query mostrano le query normalizzate, ovvero $1, $2 e così via sostituiscono i valori costanti letterali. Ad esempio:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
Il valore della costante viene ignorato in modo che gli approfondimenti sulle query possano aggregare query simili e rimuovere eventuali informazioni PII che la costante potrebbe mostrare.
Filtra per tag query
Per risolvere i problemi di un'applicazione, devi prima aggiungere tag alle query SQL.
Query Insights fornisce un monitoraggio incentrato sulle applicazioni per diagnosticare i problemi di prestazioni delle applicazioni create utilizzando ORM.
Se sei responsabile dell'intero stack di applicazioni, Query Insights fornisce il monitoraggio delle query da una visualizzazione dell'applicazione. Il tagging delle query ti aiuta a trovare problemi in costrutti di livello superiore, ad esempio utilizzando la logica di business, un microservizio o un altro costrutto. Puoi taggare le query in base alla logica di business, ad esempio utilizzando i tag pagamento, inventario, analisi aziendale o spedizione. Puoi quindi trovare il carico di query in cui vengono creati i vari tipi di logica di business. Ad esempio, potresti trovare eventi imprevisti, come picchi per un tag di analisi dell'attività alle 13:00. Oppure potresti notare una crescita inaspettata per un servizio di pagamento di tendenza rispetto alla settimana precedente.
I tag di carico delle query forniscono una suddivisione del carico delle query del tag selezionato nel tempo.
Per calcolare il carico del database per il tag, gli approfondimenti sulle query utilizzano la quantità di tempo impiegato da ogni query che utilizza il tag selezionato. Gli approfondimenti sulle query calcolano il tempo di completamento al limite del minuto utilizzando l'ora effettiva.
Nella dashboard degli approfondimenti sulle query, seleziona TAG per visualizzare la tabella dei tag. La tabella TAG ordina i tag in base al carico totale per tempo totale.

Puoi ordinare la tabella selezionando una proprietà da Filtra query o facendo clic su un'intestazione di colonna. La tabella mostra le seguenti proprietà:
- Azione, Controller, Framework, Route, Applicazione, Driver database. Ogni proprietà che hai aggiunto alle query viene visualizzata come colonna. Se vuoi filtrare in base ai tag, devi aggiungere almeno una di queste proprietà.
- Carico per tempo totale/Carico per CPU/Carico per attesa IO/Carico per attesa blocco. Queste opzioni ti consentono di filtrare query specifiche per trovare il carico più elevato per ogni opzione.
- Tempo di esecuzione medio (ms). Il tempo totale impiegato da tutte le attività secondarie in tutti i worker paralleli per completare la query. Per saperne di più, vedi Tempo e durata di esecuzione medi.
- Volte in cui è stato chiamato. Il numero di volte in cui la query è stata chiamata dall'applicazione.
- Media righe recuperate. Il numero medio di righe recuperate per la query.
- Database. Il database su cui è stata eseguita la query.
Esaminare una query o un tag specifico
Per determinare se una query o un tag è la causa principale del problema, procedi nel seguente modo dalla scheda Query o Tag, rispettivamente:
- Fai clic sull'intestazione Carico per tempo totale per ordinare l'elenco in ordine decrescente.
- Fai clic sulla query o sul tag che sembra avere il carico più elevato e che richiede più tempo rispetto agli altri.
Si apre una dashboard che mostra i dettagli della query o del tag selezionato.
Se hai selezionato una query, viene visualizzata una panoramica della query selezionata:

Se hai selezionato un tag, viene visualizzata una panoramica del tag selezionato.
Esaminare il carico per una query o un tag specifico
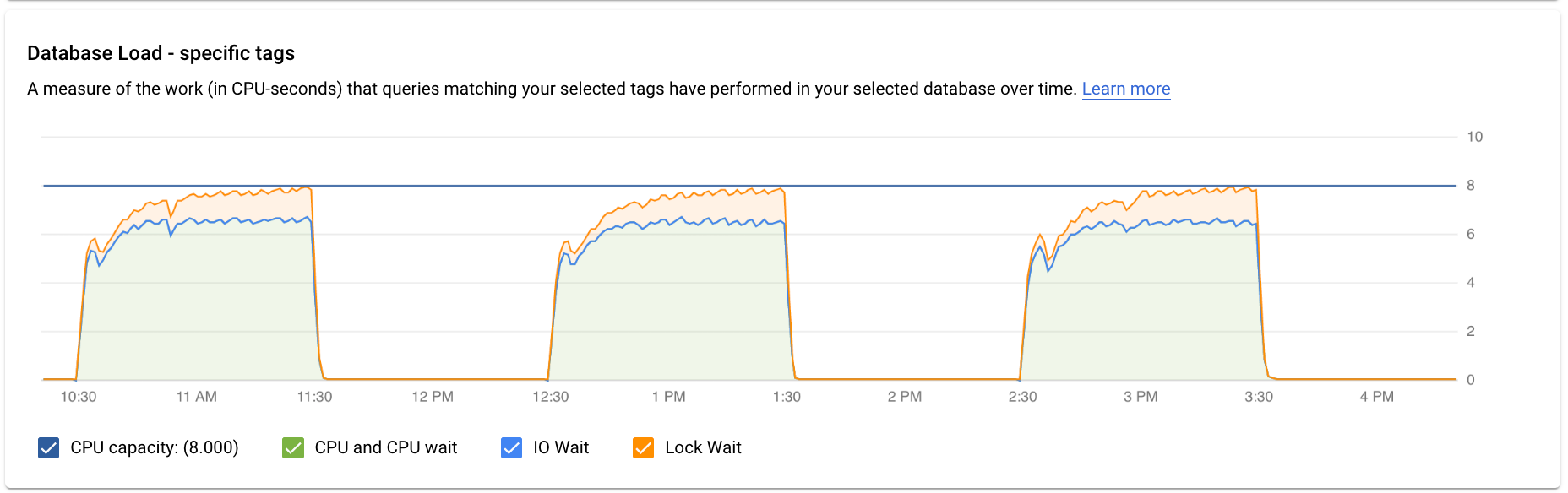
Il grafico Carico del database - Query specifica mostra una misura del lavoro (in secondi CPU) che la query normalizzata selezionata ha eseguito nella query selezionata nel tempo. Per calcolare il carico, utilizza il tempo impiegato dalle query normalizzate completate al limite del minuto rispetto al tempo effettivo. Nella parte superiore della tabella vengono visualizzati i primi 1024 caratteri della query normalizzata (in cui i valori letterali vengono rimossi per motivi di aggregazione e PII). Come per il grafico delle query totali, puoi filtrare il carico per una query specifica in base a Database, Utente e Indirizzo client. Il carico delle query è suddiviso in Capacità CPU, CPU e attesa CPU, Attesa I/O e Attesa blocco.
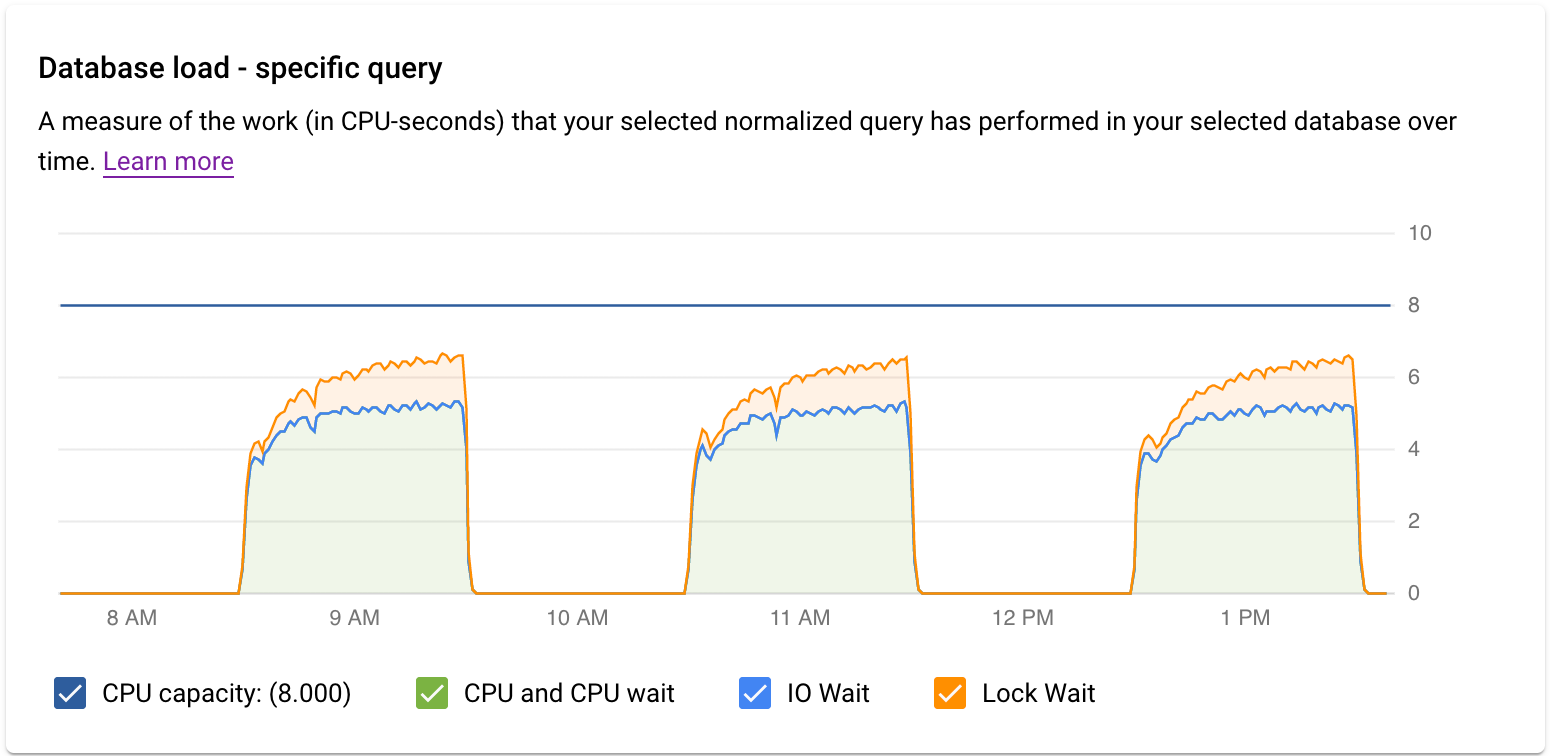
Il grafico Carico del database - Tag specifici mostra una misura del lavoro (in secondi CPU) che le query corrispondenti ai tag selezionati hanno eseguito nel corso del tempo all'interno del database selezionato. Come per il grafico delle query totali, puoi filtrare il carico per un tag specifico in base a Database, Utente e Indirizzo client.
Esamina la latenza
Utilizzi il grafico Latenza per esaminare la latenza della query o del tag. La latenza è il tempo impiegato dalla query normalizzata per il completamento, in ore effettive. La dashboard della latenza mostra la latenza del 50°, 95° e 99° percentile per trovare comportamenti anomali.
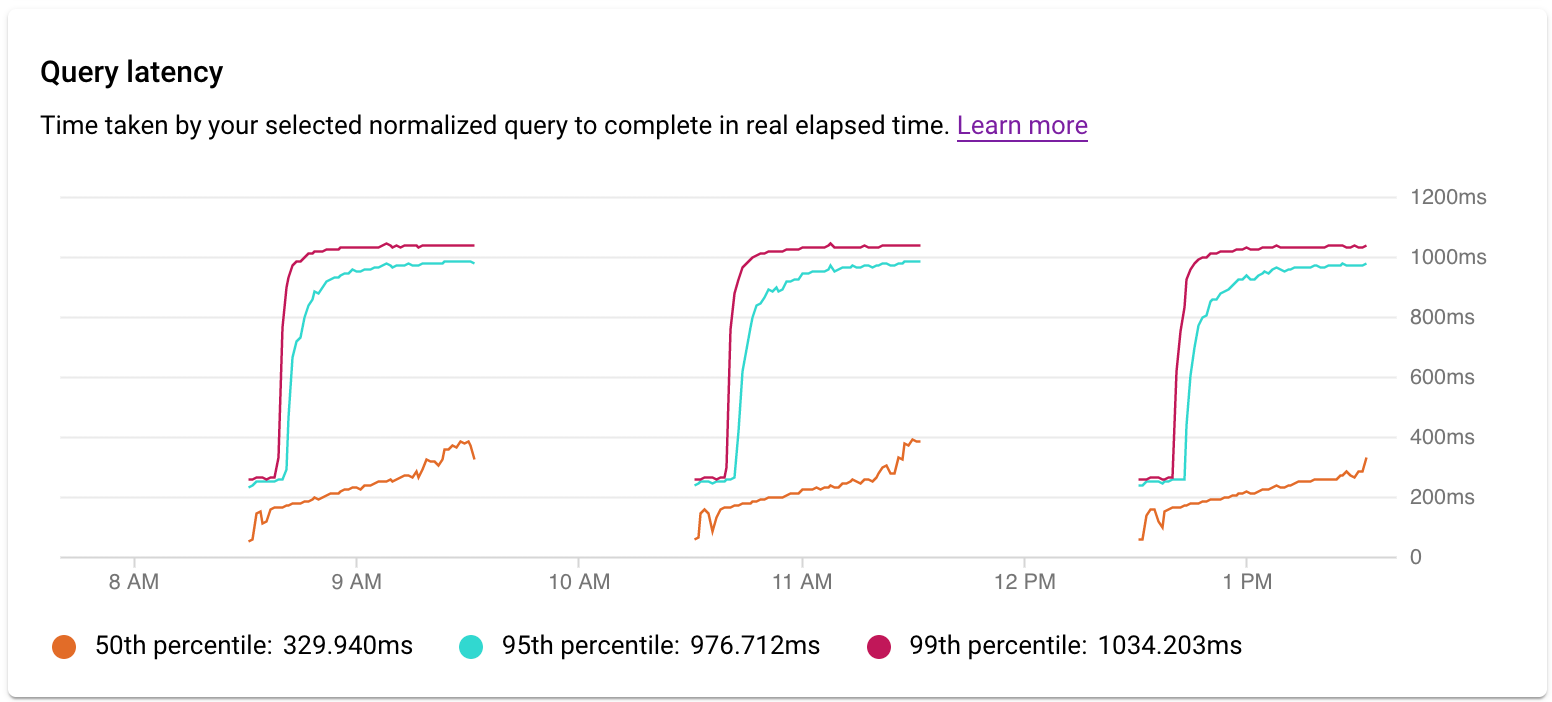
La latenza delle query parallele è misurata in ore effettive, anche se il carico della query può essere superiore per la query a causa dell'utilizzo di core multipli per l'esecuzione di una parte della query.
Prova a restringere il campo del problema esaminando quanto segue:
- Cosa sta causando il carico elevato? Seleziona le opzioni per esaminare la capacità della CPU, l'attesa CPU e CPU, l'attesa di blocco o l'attesa IO.
- Da quanto tempo il carico è elevato? È solo alta ora? O è alta da molto tempo? Modifica gli intervalli di tempo per trovare la data e l'ora in cui il caricamento ha iniziato a registrare un rendimento scarso.
- Si sono verificati picchi di latenza? Puoi modificare la finestra temporale per studiare la latenza storica della query normalizzata.
Quando trovi le aree e gli orari con il carico più elevato, puoi esaminare i dati in modo più dettagliato.
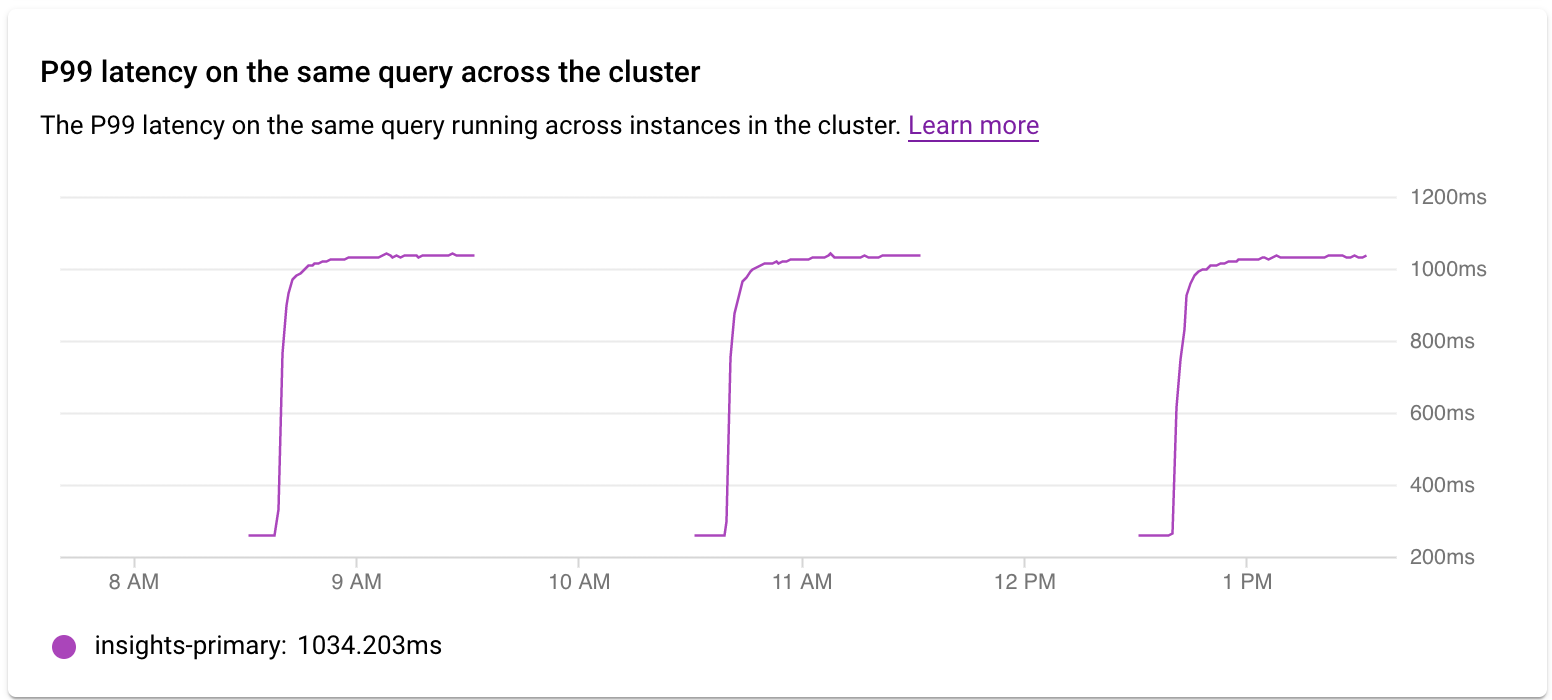
Esaminare la latenza in un cluster
Utilizza il grafico Latenza P99 per la stessa query all'interno del cluster per esaminare la latenza P99 per la query o il tag nelle istanze del cluster.
Esaminare le operazioni in un piano di query campionato
Un piano di query prende un campione della query e lo suddivide in singole operazioni. Spiega e analizza ogni operazione nella query. Il grafico Esempi di piano di query mostra tutti i piani di query in esecuzione in momenti particolari e la quantità di tempo impiegata per l'esecuzione di ciascun piano.
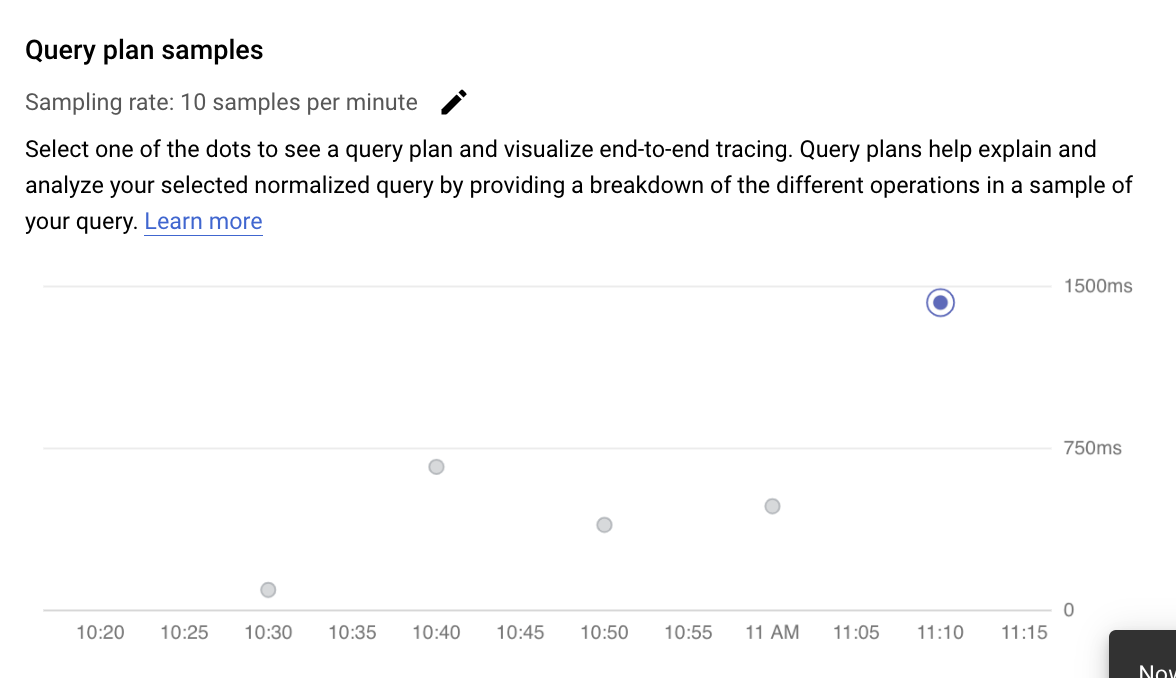
Per visualizzare i dettagli del piano di query di esempio, fai clic sui puntini nel grafico Piani di query di esempio. Esiste una visualizzazione dei piani di query di esempio eseguiti per la maggior parte delle query, ma non per tutte. I dettagli espansi mostrano un modello di tutte le operazioni nel piano di query. Ogni operazione mostra la latenza, le righe restituite e il costo dell'operazione. Quando selezioni un'operazione, puoi visualizzare ulteriori dettagli, ad esempio i blocchi di hit condivisi, il tipo di schema, i loop effettivi, le righe del piano e altro ancora.
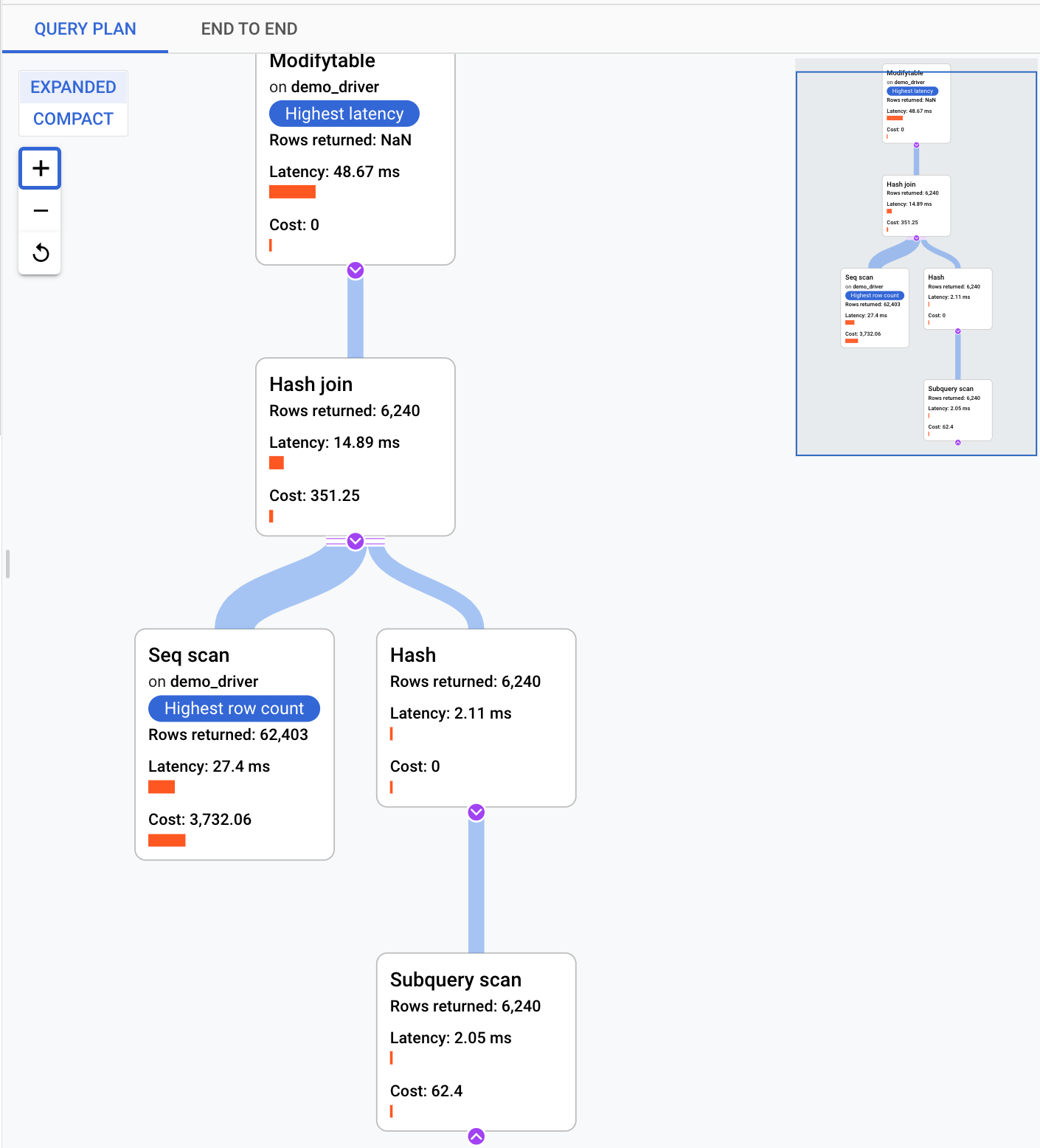
Prova a restringere il campo del problema rispondendo alle seguenti domande:
- Qual è il consumo di risorse?
- Qual è la sua relazione con altre query?
- Il consumo cambia nel tempo?
Esamina una traccia generata da una query di esempio
Oltre a visualizzare il piano di query di esempio, puoi utilizzare gli approfondimenti sulle query per visualizzare una traccia end-to-end in contesto per una query di esempio. Questa traccia può aiutarti a identificare l'origine di una query problematica mostrando l'attività del database per una richiesta specifica. Inoltre, le voci di log che l'applicazione invia a Cloud Logging durante la richiesta sono collegate alla traccia, il che ti aiuta nelle indagini.
Per visualizzare la traccia nel contesto:
Nel riquadro Query di esempio, fai clic sulla scheda Trace end-to-end. Questa scheda mostra un grafico di Gantt che descrive in dettaglio gli intervalli, ovvero i record delle singole operazioni, per la traccia generata dalla query.
Per visualizzare ulteriori dettagli su ogni intervallo, ad esempio attributi e metadati, fai clic sull'intervallo.
Puoi visualizzare la traccia anche nella pagina Esplora tracce. Per farlo, fai clic su Visualizza in Cloud Trace. Per informazioni dettagliate su come utilizzare la pagina Esplora tracce per esplorare i dati di traccia, vedi Trovare ed esplorare le tracce.
Aggiungere tag alle query SQL
Il tagging delle query SQL semplifica la risoluzione dei problemi delle applicazioni. Puoi utilizzare sqlcommenter per aggiungere tag alle query SQL automaticamente utilizzando il mapping relazionale degli oggetti (ORM) o manualmente.
Utilizzare sqlcommenter con ORM
Quando viene utilizzato ORM anziché scrivere direttamente query SQL, potresti non trovare codice dell'applicazione che causa problemi di prestazioni. Potresti anche avere difficoltà ad analizzare l'impatto del codice dell'applicazione sulle prestazioni delle query. Per risolvere questo problema, Query Insights fornisce una libreria open source chiamata sqlcommenter, una libreria di strumentazione ORM. Questa libreria è utile per gli sviluppatori che utilizzano ORM e per gli amministratori per rilevare quale codice dell'applicazione causa problemi di rendimento.
Se utilizzi ORM e sqlcommenter insieme, i tag vengono creati automaticamente senza che tu debba modificare o aggiungere codice personalizzato alla tua applicazione.
Puoi installare sqlcommenter sul server delle applicazioni. La libreria di strumentazione consente di propagare al database le informazioni dell'applicazione relative al framework MVC insieme alle query come commento SQL. Il database rileva questi tag e inizia a registrare e aggregare le statistiche per tag, che sono ortogonali rispetto alle statistiche aggregate per query normalizzate. Query Insights mostra i tag in modo da sapere quale applicazione sta causando il carico delle query. Queste informazioni ti aiutano a individuare il codice dell'applicazione che causa problemi di prestazioni.
Quando esamini i risultati nei log del database SQL, vengono visualizzati nel seguente modo:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
I tag supportati includono il nome del controller, la route, il framework e l'azione.
Il set di ORM in sqlcommenter è supportato per vari linguaggi di programmazione:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
Per maggiori informazioni su sqlcommenter e su come utilizzarlo nel framework ORM, consulta la documentazione di sqlcommenter su GitHub.
Utilizzare sqlcommenter per aggiungere tag manualmente
Se non utilizzi ORM, devi aggiungere manualmente i tag sqlcommenter alle query SQL. Nella query, devi aumentare ogni istruzione SQL con un commento contenente una coppia chiave-valore serializzata. Utilizza almeno uno dei seguenti tasti:
action=''controller=''framework=''route=''application=''db driver=''
Query Insights elimina tutte le altre chiavi. Consulta la documentazione di sqlcommenter per il formato corretto dei commenti SQL.
Tempo e durata dell'esecuzione
Gli insight sulle query forniscono una metrica Tempo di esecuzione medio (ms), che indica il tempo totale impiegato da tutte le attività secondarie in tutti i worker paralleli per completare la query. Questa metrica può aiutarti a ottimizzare l'utilizzo aggregato delle risorse dei database trovando e ottimizzando le query che creano il sovraccarico della CPU più elevato.
Per visualizzare il tempo trascorso, puoi misurare la durata di una query eseguendo il comando \timing sul client psql. Misura il tempo che intercorre tra
la ricezione della query e l'invio di una risposta da parte del server PostgreSQL. Questa metrica può
aiutarti ad analizzare perché una determinata query richiede troppo tempo e a decidere se
ottimizzarla per un'esecuzione più rapida.
Se una query viene completata in modalità single-thread da una singola attività, la durata e il tempo di esecuzione medio rimangono invariati.
Abilita le funzionalità avanzate di Query Insights per AlloyDB
La dashboard delle funzionalità avanzate di Query Insights per AlloyDB è integrata nella dashboard standard di Query Insights. Per saperne di più sull'attivazione delle funzionalità avanzate di Query Insights, consulta Migliorare le prestazioni delle query utilizzando le funzionalità avanzate di Query Insights.
Passaggi successivi
- Panoramica di Query Insights
- Migliora le prestazioni delle query utilizzando le funzionalità avanzate di Query Insights per AlloyDB
- Metriche AlloyDB
- Blog di SQL Commenter: Introducing Sqlcommenter: An open source ORM auto-instrumentation library
- Post del blog: attivare il tagging delle query con Sqlcommenter