En esta página se describe cómo usar el panel de control Estadísticas de las consultas para detectar y analizar problemas de rendimiento. Para obtener una descripción general de esta función, consulta Información valiosa sobre las consultas.
Puedes usar Gemini Cloud Assist para monitorizar y solucionar problemas de tus recursos de AlloyDB. Para obtener más información, consulta Monitorizar y solucionar problemas con la ayuda de Gemini.
Antes de empezar
Si tú u otros usuarios necesitáis ver el plan de consulta o realizar un seguimiento integral, debéis tener permisos de gestión de identidades y accesos (IAM) específicos. Puedes crear un rol personalizado y añadirle los permisos de IAM necesarios. Después, puedes añadir este rol a cada cuenta de usuario que utilice estadísticas de las consultas para solucionar un problema. Consulta Crear un rol personalizado.
El rol personalizado debe tener el siguiente permiso de gestión de identidades y accesos: cloudtrace.traces.get.
Abrir el panel de control Estadísticas de las consultas
Para abrir el panel de control Estadísticas de consultas, sigue estos pasos:
- En la lista de clústeres e instancias, haz clic en una instancia.
- Haga clic en Ir a Información valiosa sobre las consultas para obtener detalles sobre las consultas y el rendimiento debajo del gráfico de métricas de la página Información general del clúster o seleccione la pestaña Información valiosa sobre las consultas en el panel de navegación de la izquierda.
En la página siguiente, puede usar las siguientes opciones para filtrar los resultados:
- Selector de instancias. Te permite seleccionar la instancia principal o las instancias de lectura del clúster. De forma predeterminada, se selecciona la instancia principal. Los detalles que se muestran se agregan de todas las instancias de grupo de lectura conectadas y sus nodos.
- Base de datos. Filtra la carga de consultas en una base de datos específica o en todas las bases de datos.
- Usuario. Filtra la carga de consultas de cuentas de usuario específicas.
- Dirección del cliente. Filtra la carga de consultas de una dirección IP específica.
- Periodo. Filtra la carga de las consultas por intervalos de tiempo, como horas, días, semanas o un intervalo personalizado.
Editar la configuración de estadísticas de consultas
La información útil sobre las consultas está habilitada de forma predeterminada en las instancias de AlloyDB. Puede editar la configuración predeterminada de Estadísticas de consultas.
Para editar la configuración de Información útil sobre las consultas de una instancia de AlloyDB, sigue estos pasos:
Consola
En la Google Cloud consola, ve a la página Clusters.
Haga clic en un clúster de la columna Nombre del recurso.
En el panel de navegación de la izquierda, haga clic en Estadísticas de las consultas.
Selecciona Principal o Grupo de lectura en la lista Estadísticas de consultas y, a continuación, haz clic en Editar.
Edita los campos de Información valiosa sobre las consultas:
Para cambiar el límite predeterminado de 1024 bytes de la longitud de las consultas que AlloyDB puede analizar, en el campo Longitud de las consultas, introduce un número entre 256 y 4500.
La instancia se reinicia después de editar este campo.
Nota: Cuanto más largos sean los límites de las consultas, más memoria se necesitará.
Para personalizar los conjuntos de funciones de estadísticas de consultas, ajusta las siguientes opciones:
Muestreo de planes de consultas: selecciona esta casilla para visualizar las operaciones que se han usado para completar una muestra de una consulta. La frecuencia de muestreo determina el número máximo de consultas que AlloyDB puede muestrear por minuto para la instancia por nodo.
En el campo Frecuencia de muestreo máxima, introduce un número del 1 al 20. De forma predeterminada, la frecuencia de muestreo es 5. Para inhabilitar el muestreo, desmarca la casilla Muestreo de planes de consultas.
Almacenar las direcciones IP de los clientes: marque esta casilla para saber de dónde proceden sus consultas y agrupar esa información para generar métricas.
Almacenar etiquetas de aplicaciones: marca esta casilla para saber qué aplicaciones con etiquetas realizan solicitudes y para agrupar esa información con el fin de generar métricas. Para obtener más información sobre las etiquetas de aplicación, consulta la especificación.
Haz clic en Actualizar instancia.
gcloud
Para habilitar Estadísticas de consultas en una instancia de AlloyDB mediante comandos de la CLI de Google Cloud, haz lo siguiente:
- Instala Google Cloud CLI.
- Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init
Si usas un shell local, crea credenciales de autenticación local para tu cuenta de usuario:
gcloud auth application-default login
No es necesario que lo hagas si usas Cloud Shell.
Para obtener más información, consulta Configurar la autenticación en un entorno de desarrollo local.
Veamos un ejemplo:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressHaz los cambios siguientes:
INSTANCE: el ID de la instancia que se va a actualizarCLUSTER: el ID del clúster de la instanciaPROJECT: el ID del proyecto del clústerREGION: la región del clúster (por ejemplo,us-central1).QUERY_LENGTH: la longitud de la consulta, que va de 256 a 4500QUERY_PLANS: número de planes de consulta que se deben configurar por minuto.
También puedes usar una o varias de las siguientes marcas opcionales:
--insights-config-query-string-length: define el límite de longitud de consulta predeterminado en un valor especificado entre 256 y 4500 bytes. La longitud de consulta predeterminada es de 1024 bytes. Las consultas más largas son más útiles para las analíticas, pero también requieren más memoria. Si cambias la longitud de las consultas, tendrás que reiniciar la instancia. Aun así, puede añadir etiquetas a las consultas que superen el límite de longitud.--insights-config-query-plans-per-minute: de forma predeterminada, se capturan un máximo de cinco muestras de planes de consulta ejecutados por minuto en todas las bases de datos de la instancia. Cambia este valor por un número del 1 al 20. Para inhabilitar el muestreo, introduce 0. Si aumenta la frecuencia de muestreo, es probable que obtenga más puntos de datos, pero puede que se añada una sobrecarga de rendimiento.--insights-config-record-client-address: almacena las direcciones IP de los clientes de donde proceden las consultas y te ayuda a agrupar esos datos para generar métricas al respecto. Las consultas proceden de más de un host. Revisar los gráficos de las consultas de las direcciones IP de los clientes puede ayudar a identificar el origen de un problema. Si no quieres almacenar direcciones IP de cliente, usa--no-insights-config-record-client-address.--insights-config-record-application-tags: almacena etiquetas de aplicaciones que te ayudan a determinar las APIs y las rutas de controlador de vistas de modelo (MVC) que realizan solicitudes, así como a agrupar los datos para generar métricas al respecto. Para usar esta opción, debes añadir comentarios a las consultas con un conjunto específico de etiquetas. Si no quieres almacenar etiquetas de aplicación, usa--no-insights-config-record-application-tags.
Terraform
Para usar Terraform y configurar Estadísticas de las consultas, usa el recurso google_alloydb_instance.
Veamos un ejemplo:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
Haz los cambios siguientes:
QUERY_STRING_LENGTH_VALUE: longitud de la cadena de consulta. El valor predeterminado es1024. Se puede usar cualquier número entero entre 256 y 4500.RECORD_APPLICATION_TAG_VALUE: registra la etiqueta de aplicación de una instancia. El valor predeterminado estrue.RECORD_CLIENT_ADDRESS_VALUE: registra la dirección del cliente de una instancia. El valor predeterminado estrue.QUERY_PLANS_PER_MINUTE_VALUE: el número de planes de ejecución de consultas capturados por Estadísticas por minuto de todas las consultas combinadas. El valor predeterminado es5. Se puede introducir cualquier número entero entre 0 y 20.Para saber cómo aplicar o quitar una configuración de Terraform, consulta Comandos básicos de Terraform.
La configuración de la instancia de ejemplo con la configuración de estadísticas de consultas añadida debería tener el siguiente aspecto:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
En este ejemplo se configuran los ajustes de observabilidad en tu instancia de AlloyDB. Para ver la lista completa de parámetros de esta llamada, consulta Método: projects.locations.clusters.instances.patch.
Para configurar los ajustes de estadísticas de consultas, modifique los campos opcionales según sea necesario. Para ver una lista completa de los campos de esta llamada, consulta QueryInsightsInstanceConfig.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
CLUSTER_ID: el ID del clúster que crees. Debe empezar por una letra minúscula y puede contener letras minúsculas, números y guiones.PROJECT_ID: el ID del proyecto en el que quieres colocar el clúster.LOCATION_ID: el ID de la región del clúster.INSTANCE_ID: el nombre de la instancia principal que quieras crear.
Para modificar la configuración de tu instancia, usa la siguiente solicitud PATCH:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
El cuerpo JSON de la solicitud que configura todos los campos de observabilidad tiene el siguiente aspecto:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
Mejorar el rendimiento de las consultas
Información valiosa sobre las consultas soluciona problemas de las consultas de AlloyDB para buscar problemas de rendimiento. El panel de control Estadísticas de consultas muestra la carga de consultas en función de los factores que selecciones. La carga de consultas es una medida del trabajo total de todas las consultas de la instancia en el intervalo de tiempo seleccionado.
Las estadísticas de las consultas te ayudan a detectar y analizar problemas de rendimiento de las consultas. Para solucionar problemas con las consultas mediante las estadísticas de consultas, sigue estos pasos:
- Consulta la carga de la base de datos de todas las consultas.
- Identifica una consulta o una etiqueta que dé problemas.
- Examine la consulta o la etiqueta para identificar los problemas.
- Examina un rastreo generado por una consulta de ejemplo.
Ver la carga de la base de datos de todas las consultas
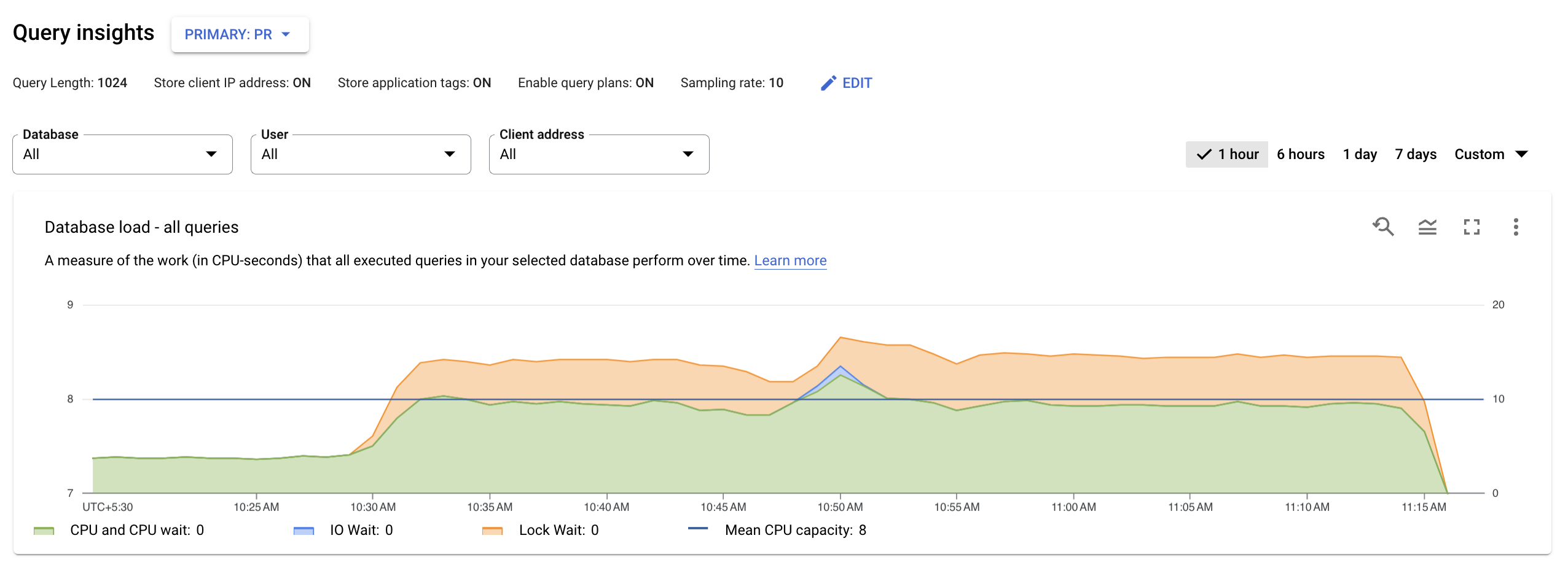
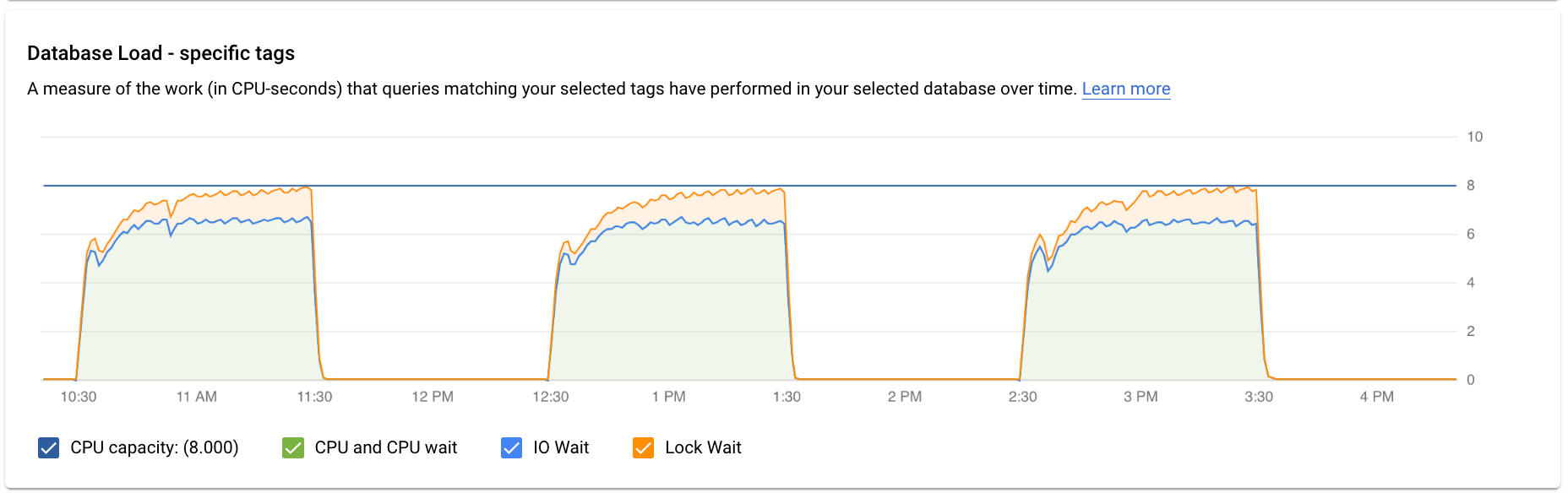
El panel de control Estadísticas de consultas de nivel superior muestra el gráfico Carga de la base de datos: todas las consultas principales con datos filtrados. La carga de consultas de la base de datos es una medida del trabajo (en segundos de CPU) que realizan las consultas ejecutadas en la base de datos seleccionada a lo largo del tiempo. Cada consulta en ejecución usa o espera recursos de CPU, recursos de E/S o recursos de bloqueo. La carga de consultas de la base de datos es la proporción de tiempo que requieren todas las consultas que se completan en un periodo determinado en relación con el tiempo real transcurrido.
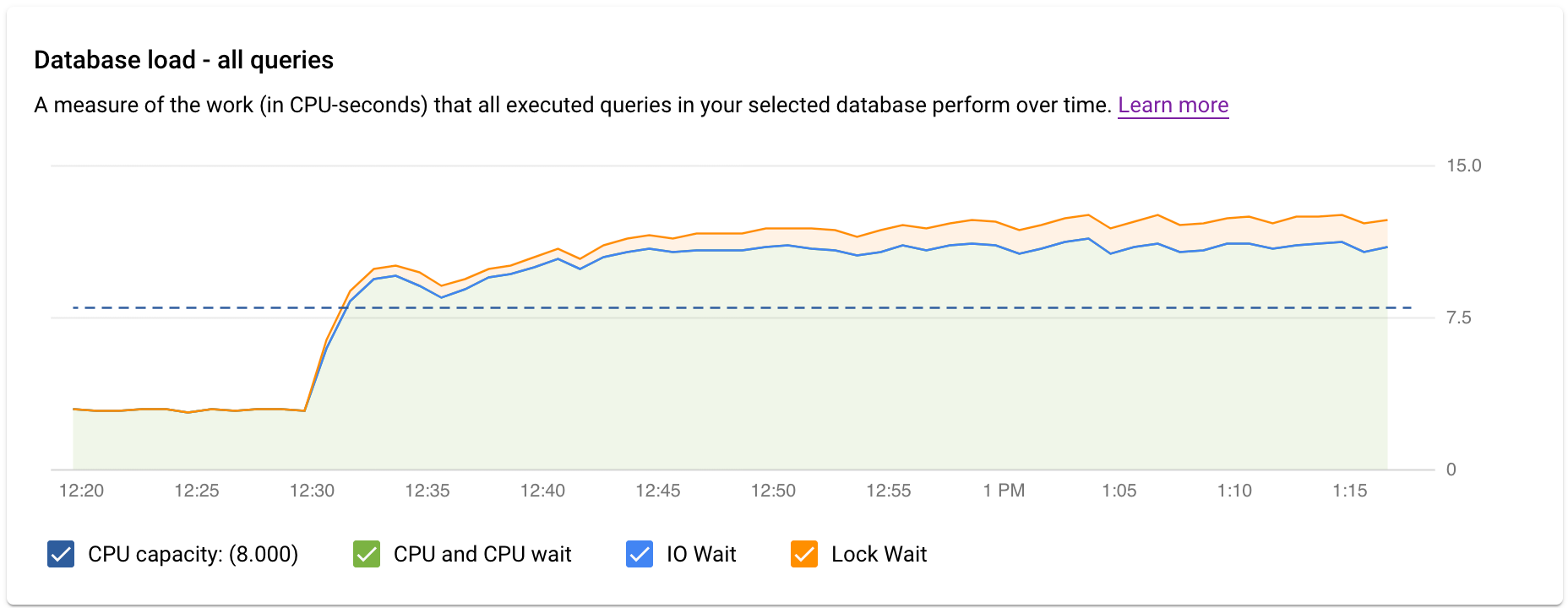
Las líneas de colores del gráfico muestran la carga de consultas, dividida en cuatro categorías:
- Capacidad de CPU: el número de CPUs disponibles en la instancia.
CPU y espera de CPU: la proporción de tiempo que requieren las consultas en un estado activo en relación con el tiempo real transcurrido. Las esperas de E/S y de bloqueo no bloquean las consultas que están activas. Esta métrica puede significar que la consulta está usando la CPU o esperando a que el programador de Linux programe el proceso del servidor que ejecuta la consulta mientras otros procesos usan la CPU.
Nota: La carga de la CPU tiene en cuenta tanto el tiempo de ejecución como el tiempo de espera para que el programador de Linux programe el proceso del servidor que se está ejecutando. Por lo tanto, la carga de la CPU puede superar la línea del núcleo máximo.
Espera de E/S: la proporción de tiempo que requieren las consultas que están esperando la E/S en relación con el tiempo real transcurrido. La espera de E/S incluye la espera de E/S de lectura y de escritura. Consulta la tabla de eventos de PostgreSQL. Si quieres ver un desglose de la información sobre las esperas de E/S, puedes consultarlo en Cloud Monitoring. Para obtener más información, consulta los gráficos de métricas.
Espera de bloqueo: la proporción de tiempo que requieren las consultas que están esperando los bloqueos en relación con el tiempo real transcurrido. Incluye las esperas de bloqueo, de LwLock y de BufferPin. Si quieres ver un desglose de la información sobre las esperas de bloqueo, puedes consultarlo en Cloud Monitoring. Para obtener más información, consulta los gráficos de métricas.
A continuación, revisa el gráfico y usa las opciones de filtrado para responder a estas preguntas:
- ¿La carga de consultas es alta? ¿El gráfico muestra picos o valores elevados a lo largo del tiempo? Si no ves una carga alta, el problema no está en tus consultas.
- ¿Cuánto tiempo lleva la carga alta? ¿Solo es alto ahora? ¿O ha estado alta durante mucho tiempo? Usa la selección de intervalo para elegir varios periodos y averiguar cuánto tiempo lleva ocurriendo el problema. También puedes ampliar la vista para ver un periodo en el que se observan picos de carga de consultas. Puedes reducir la imagen para ver hasta una semana de la cronología.
- ¿Qué está provocando la carga elevada? Puedes seleccionar opciones para ver la capacidad de la CPU, la CPU y la espera de la CPU, la espera de bloqueo o la espera de E/S. El gráfico de cada una de estas opciones tiene un color diferente para que puedas ver cuál tiene la carga más alta. La línea azul oscuro del gráfico muestra la capacidad máxima de CPU del sistema. Te permite comparar la carga de consultas con la capacidad máxima de la CPU del sistema. Esta comparación te ayuda a saber si una instancia se está quedando sin recursos de CPU.
- ¿Qué base de datos está experimentando la carga? Seleccione diferentes bases de datos en el menú desplegable Bases de datos para encontrar las bases de datos con las cargas más altas.
- ¿Hay usuarios o direcciones IP concretos que estén provocando cargas más elevadas? Seleccione otros usuarios y direcciones en los menús desplegables para comparar cuáles están provocando cargas más elevadas.
Filtrar la carga de la base de datos
Las secciones Consultas y etiquetas le permiten filtrar u ordenar la carga de consultas de una consulta seleccionada o de una etiqueta de consulta SQL.
Filtrar por consultas
La tabla CONSULTAS ofrece un resumen de las consultas que provocan la mayor carga de consultas. En la tabla se muestran todas las consultas normalizadas del periodo y las opciones seleccionadas en el panel de control Estadísticas de las consultas.
De forma predeterminada, la tabla ordena las consultas por el tiempo total de ejecución en el periodo que hayas seleccionado.
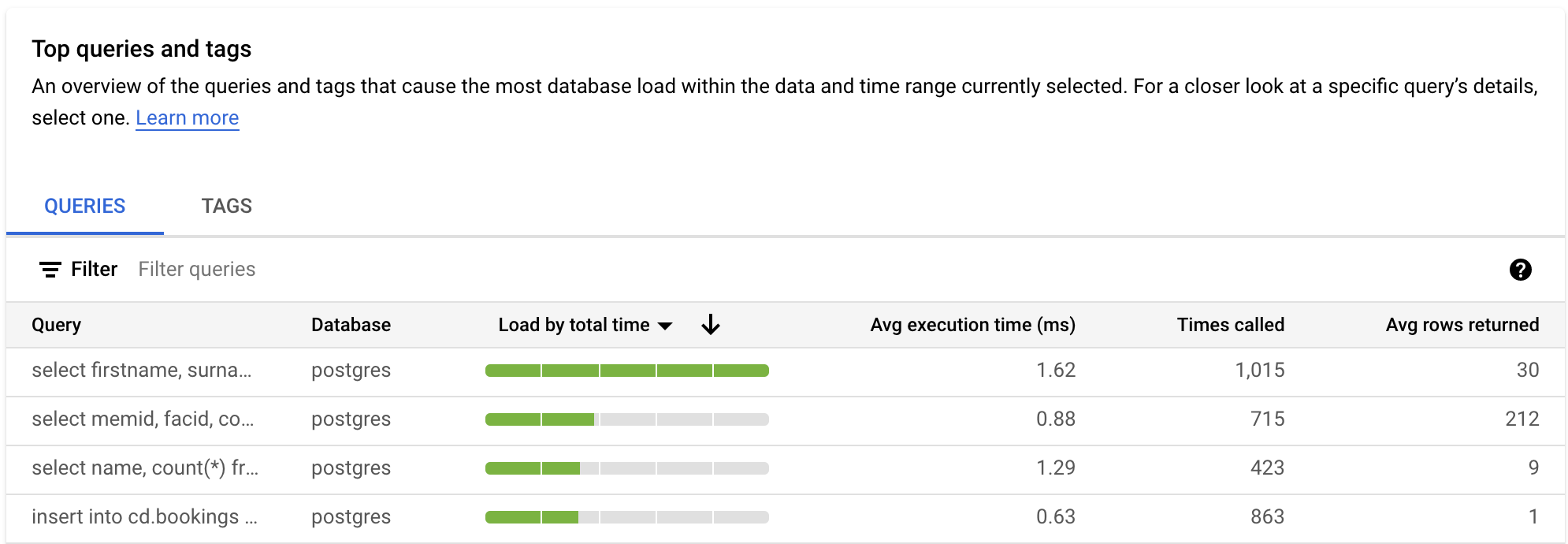
Para filtrar la tabla, selecciona una propiedad en Filtrar consultas. Para ordenar la tabla, selecciona el encabezado de una columna. En la tabla se muestran las siguientes propiedades:
Cadena de consulta. Cadena de consulta normalizada. Estadísticas de consultas solo muestra 1024 caracteres en la cadena de consulta de forma predeterminada.
Las consultas etiquetadas como
UTILITY COMMANDsuelen incluir comandosBEGIN,COMMITyEXPLAIN, o comandos envolventes.Base de datos. La base de datos en la que se ha ejecutado la consulta.
Carga por tiempo total, Carga por CPU, Carga por espera de E/S o Carga por espera de bloqueo. Estas opciones te permiten filtrar consultas específicas para encontrar la carga más grande de cada opción.
Tiempo medio de ejecución (ms). Tiempo total que tardan todas las subtareas en completarse en todos los trabajadores paralelos para completar la consulta. Para obtener más información, consulta Tiempo y duración medios de ejecución.
Veces que se ha llamado. Número de veces que la aplicación ha llamado a la consulta.
Media de filas obtenidas. Número medio de filas obtenidas en la consulta.
En Estadísticas de consultas se muestran las consultas normalizadas, es decir, los valores constantes literales se sustituyen por $1, $2, etc. Por ejemplo:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
El valor de la constante se ignora para que las estadísticas de las consultas puedan agregar consultas similares y eliminar cualquier información personal identificable que pueda mostrar la constante.
Filtrar por etiquetas de consulta
Para solucionar problemas de una aplicación, primero debes añadir etiquetas a tus consultas SQL.
Las estadísticas de las consultas ofrecen una monitorización centrada en las aplicaciones para diagnosticar problemas de rendimiento de las aplicaciones creadas con ORMs.
Si eres responsable de toda la pila de aplicaciones, Estadísticas de consultas te ofrece una monitorización de consultas desde la vista de la aplicación. El etiquetado de consultas te ayuda a encontrar problemas en construcciones de nivel superior, como la lógica empresarial, un microservicio u otra construcción. Por ejemplo, puede etiquetar las consultas según la lógica empresarial con las etiquetas de pago, inventario, analíticas empresariales o envío. A continuación, puede consultar la carga de consultas que se crea para los distintos tipos de lógica empresarial. Por ejemplo, puede que encuentres eventos inesperados, como picos en una etiqueta de analíticas de una empresa a las 13:00. También puede que observes un crecimiento inesperado en un servicio de pago que haya sido tendencia durante la semana anterior.
Las etiquetas de carga de consultas proporcionan un desglose de la carga de consultas de la etiqueta seleccionada a lo largo del tiempo.
Para calcular la carga de la base de datos de la etiqueta, las estadísticas de las consultas usan la cantidad de tiempo que tarda cada consulta que usa la etiqueta que seleccionas. Estadísticas de las consultas calcula el tiempo de finalización en el límite del minuto mediante el tiempo real.
En el panel de control Estadísticas de las consultas, seleccione ETIQUETAS para ver la tabla de etiquetas. La tabla ETIQUETAS ordena las etiquetas por su carga total y por el tiempo total.

Puede ordenar la tabla seleccionando una propiedad en Filtrar consultas o haciendo clic en el encabezado de una columna. En la tabla se muestran las siguientes propiedades:
- Acción, controlador, framework, ruta, aplicación y controlador de la base de datos. Cada propiedad que haya añadido a sus consultas se muestra como una columna. Debe añadir al menos una de estas propiedades si quiere filtrar por etiquetas.
- Carga por tiempo total, Carga por CPU, Carga por espera de E/S o Carga por espera de bloqueo. Estas opciones te permiten filtrar consultas específicas para encontrar la carga más grande de cada opción.
- Tiempo medio de ejecución (ms). Tiempo total que tardan todas las subtareas en completarse en todos los trabajadores paralelos para completar la consulta. Para obtener más información, consulta Tiempo y duración medios de ejecución.
- Veces que se ha llamado. Número de veces que la aplicación ha llamado a la consulta.
- Media de filas obtenidas. Número medio de filas obtenidas en la consulta.
- Base de datos. La base de datos en la que se ha ejecutado la consulta.
Examinar una consulta o una etiqueta concretas
Para determinar si una consulta o una etiqueta es la causa principal del problema, haga lo siguiente en la pestaña Consultas o Etiquetas, respectivamente:
- Haz clic en el encabezado Carga por tiempo total para ordenar la lista en orden descendente.
- Haga clic en la consulta o etiqueta que parezca tener la carga más alta y que tarde más que las demás.
Se abrirá un panel de control con los detalles de la consulta o la etiqueta seleccionada.
Si has seleccionado una consulta, se muestra un resumen de la consulta seleccionada:

Si ha seleccionado una etiqueta, se mostrará un resumen de la etiqueta seleccionada.
Examinar la carga de una consulta o una etiqueta concretas
El gráfico Carga de la base de datos: consulta específica muestra una medida del trabajo (en segundos de CPU) que ha realizado la consulta normalizada seleccionada en la consulta elegida a lo largo del tiempo. Para calcular la carga, se usa el tiempo que tardan las consultas normalizadas en completarse en el límite del minuto en relación con el tiempo real transcurrido. En la parte superior de la tabla, se muestran los primeros 1024 caracteres de la consulta normalizada (en la que se han quitado los literales por motivos de agregación e información personal). Al igual que en el gráfico de consultas totales, puede filtrar la carga de una consulta específica por Base de datos, Usuario y Dirección del cliente. La carga de las consultas se divide en capacidad de CPU, CPU y espera de CPU, espera de E/S y espera de bloqueo.
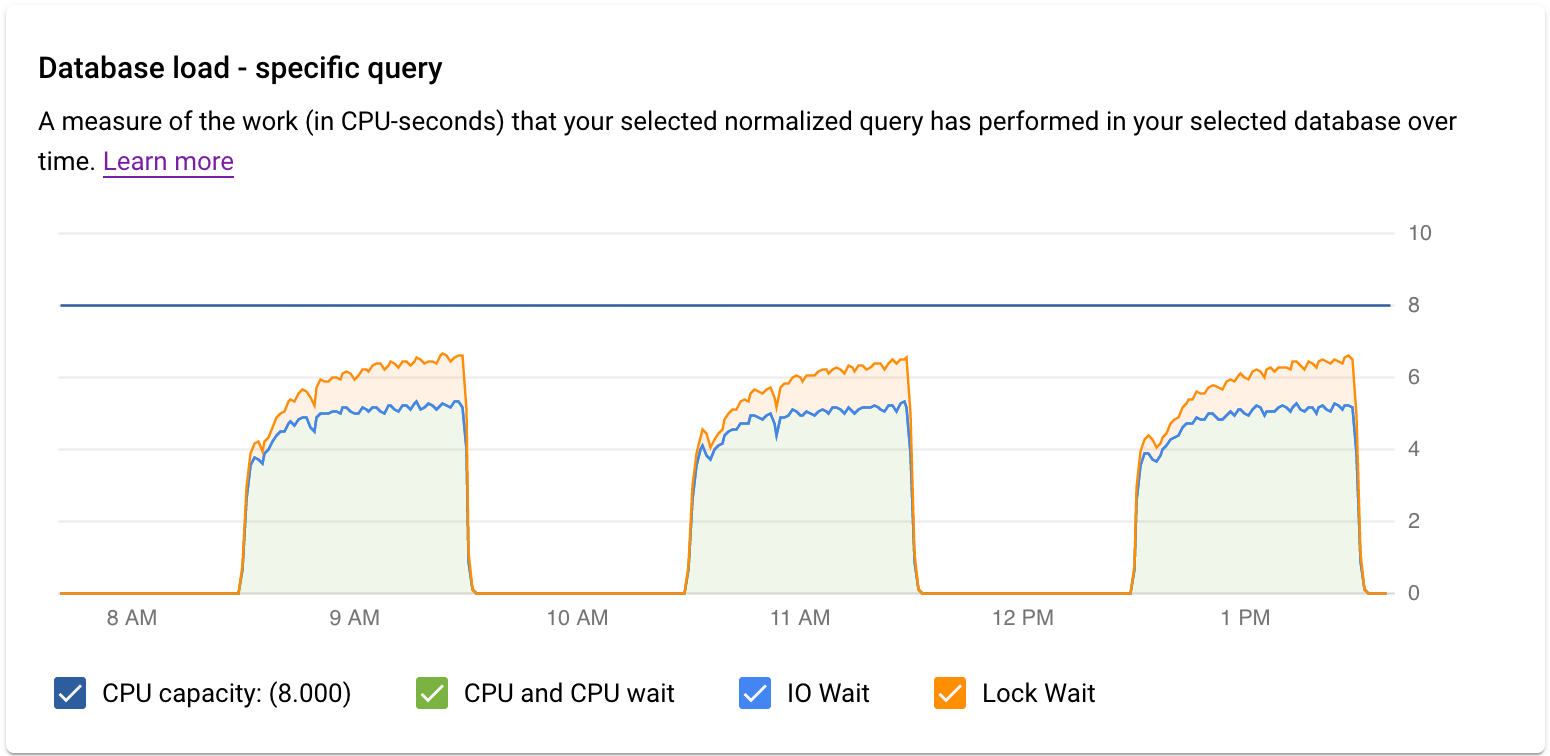
El gráfico Carga de la base de datos: etiquetas específicas muestra una medida del volumen de trabajo (medido en segundos de CPU) que las consultas que coinciden con las etiquetas seleccionadas han realizado en la base de datos elegida a lo largo del tiempo. Al igual que en el gráfico de consultas totales, puede filtrar la carga de una etiqueta específica por Base de datos, Usuario y Dirección del cliente.
Analizar la latencia
Usa el gráfico Latencia para examinar la latencia de la consulta o la etiqueta. La latencia es el tiempo que tarda en completarse la consulta normalizada, medido en tiempo real. El panel de control de latencia muestra los percentiles 50, 95 y 99 de la latencia para detectar comportamientos atípicos.
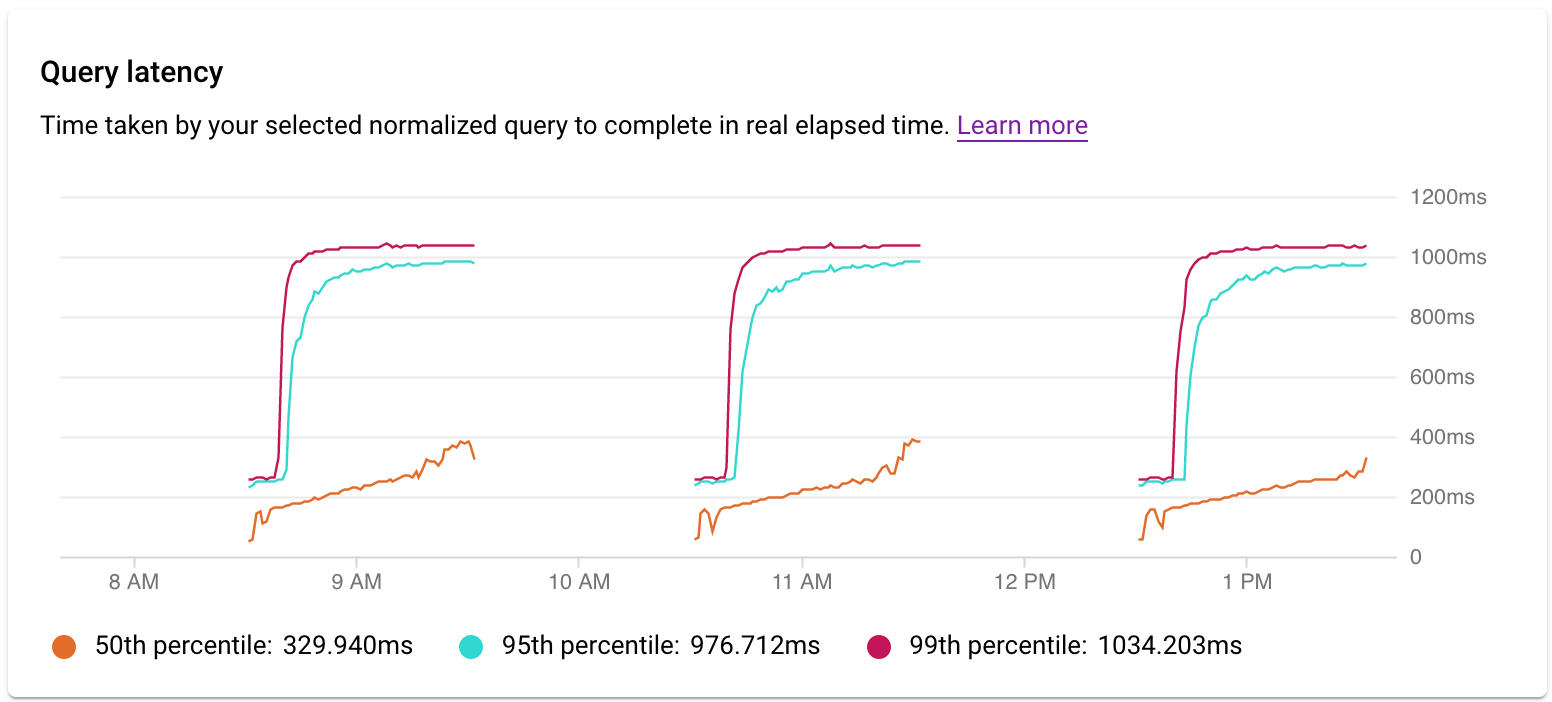
La latencia de las consultas paralelas se mide en tiempo de reloj, aunque la carga de la consulta puede ser mayor debido a que se usan varios núcleos para ejecutar parte de la consulta.
Intenta acotar el problema analizando lo siguiente:
- ¿Qué está provocando la carga elevada? Selecciona las opciones para ver la capacidad de la CPU, la CPU y la espera de la CPU, la espera de bloqueo o la espera de E/S.
- ¿Cuánto tiempo lleva la carga alta? ¿Solo es alto ahora? ¿O ha estado alta durante mucho tiempo? Cambia los intervalos de tiempo para encontrar la fecha y la hora en las que el carga empezó a funcionar mal.
- ¿Ha habido picos de latencia? Puedes cambiar el periodo para estudiar la latencia histórica de la consulta normalizada.
Cuando encuentres las zonas y las horas de mayor carga, podrás desglosar la información.
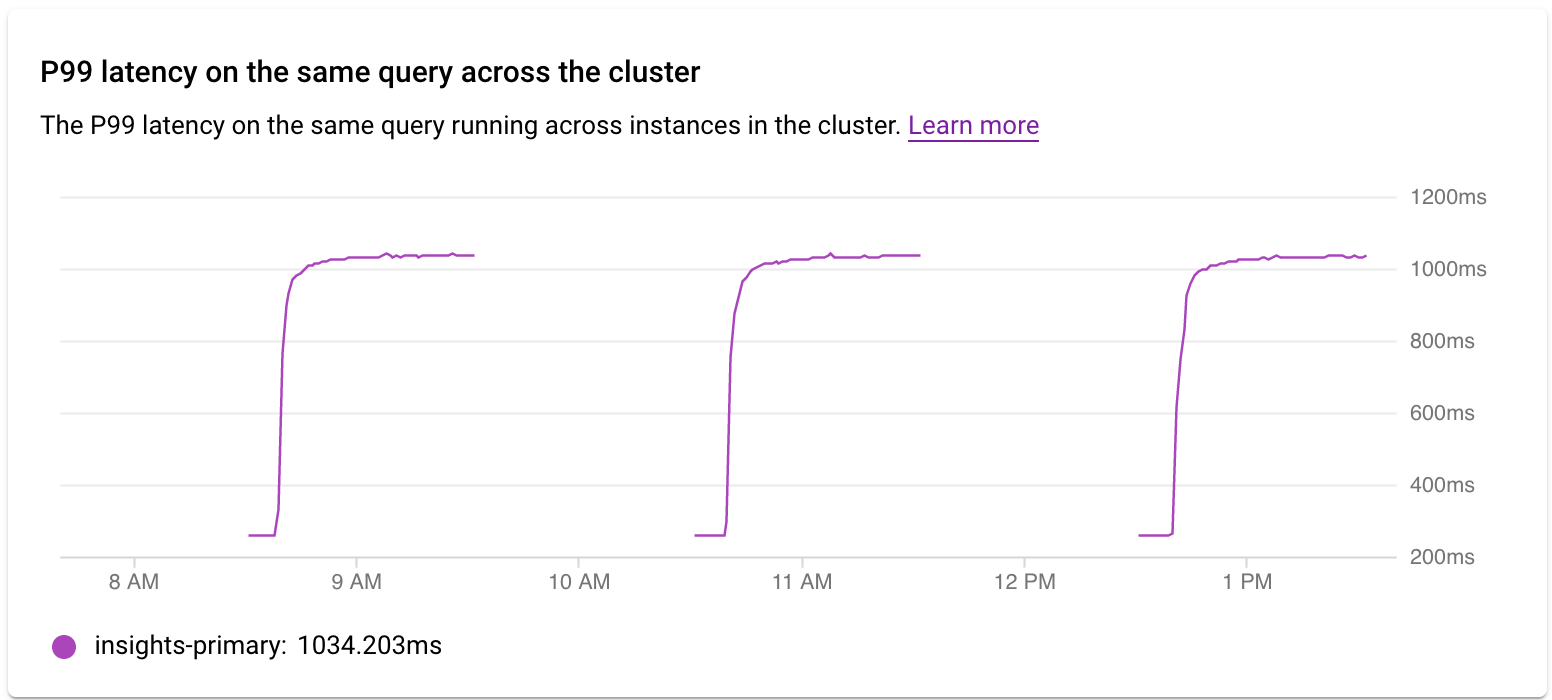
Examinar la latencia de un clúster
El gráfico Latencia del percentil 99 de la misma consulta en todo el clúster se usa para examinar la latencia del percentil 99 de la consulta o la etiqueta en las instancias del clúster.
Examinar las operaciones de un plan de consultas muestreado
Un plan de consultas toma una muestra de tu consulta y la desglosa en operaciones individuales. Explica y analiza cada operación de la consulta. El gráfico Ejemplos de planes de consultas muestra todos los planes de consultas que se ejecutan en momentos concretos y el tiempo que tarda en ejecutarse cada plan.
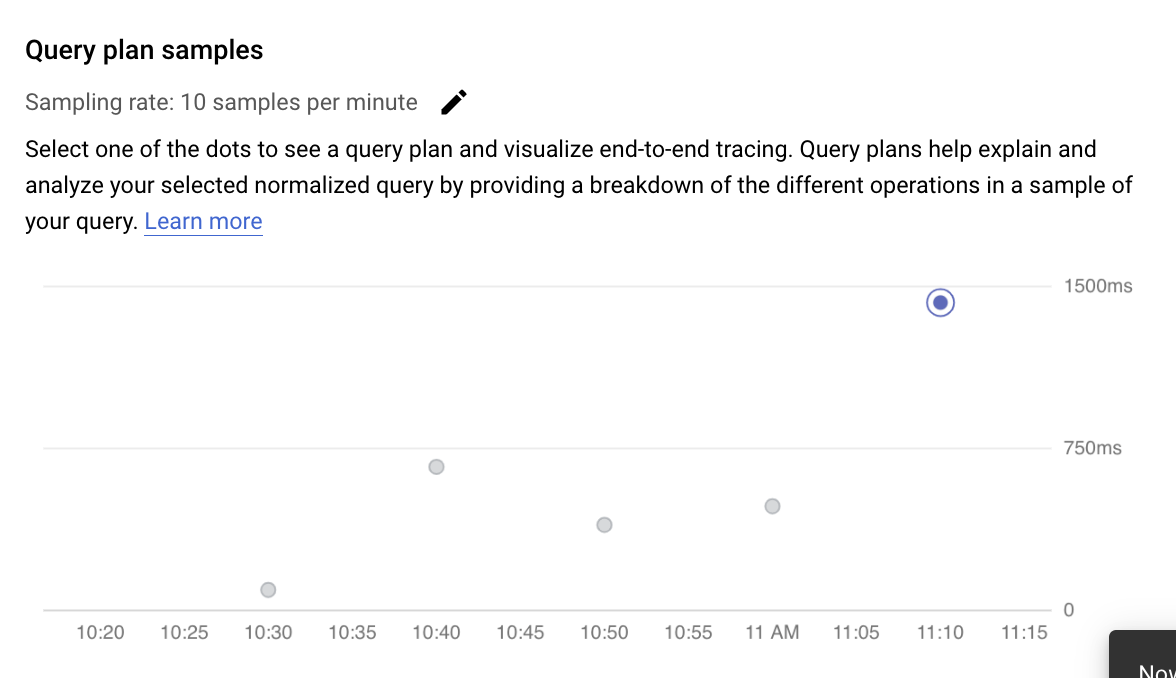
Para ver los detalles del plan de consulta de muestra, haz clic en los puntos del gráfico Planes de consulta de muestra. Hay una vista de los planes de consulta de ejemplo ejecutados para la mayoría de las consultas, pero no para todas. En los detalles ampliados se muestra un modelo de todas las operaciones del plan de consulta. En cada operación se muestra la latencia, las filas devueltas y el coste de esa operación. Cuando selecciona una operación, puede ver más detalles, como los bloques de aciertos compartidos, el tipo de esquema, los bucles reales, las filas de planes y más.
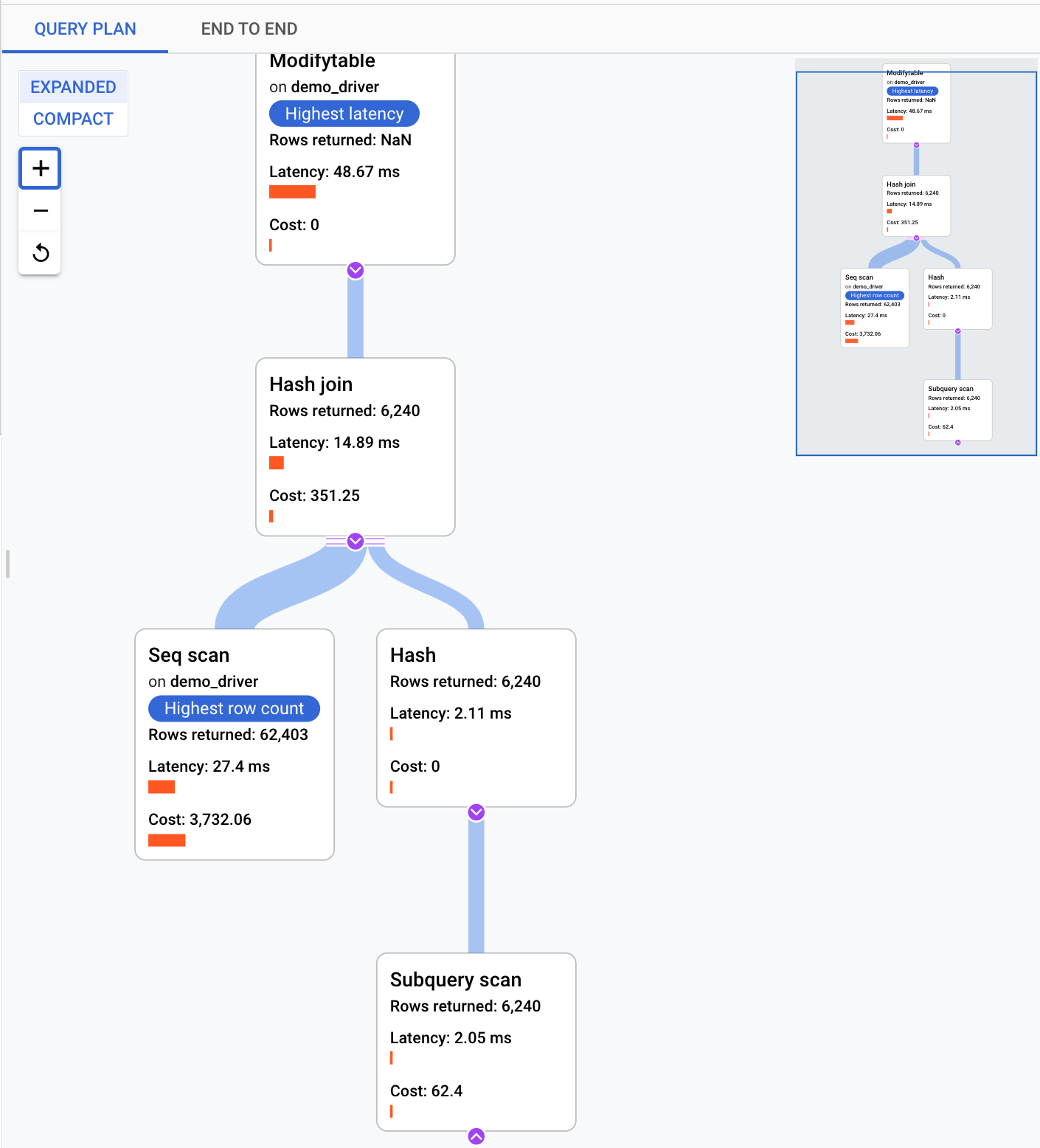
Intenta acotar el problema respondiendo a las siguientes preguntas:
- ¿Cuál es el consumo de recursos?
- ¿Qué relación tiene con otras consultas?
- ¿El consumo cambia con el tiempo?
Examinar un rastreo generado por una consulta de ejemplo
Además de ver el plan de consultas de ejemplo, puedes usar Estadísticas de consultas para ver una traza de aplicación integral y contextual de una consulta de ejemplo. Este rastreo puede ayudarte a identificar el origen de una consulta problemática mostrando la actividad de la base de datos de una solicitud específica. Además, las entradas de registro que la aplicación envía a Cloud Logging durante la solicitud se vinculan al rastreo, lo que te ayuda en tu investigación.
Para ver el rastreo contextual, sigue estos pasos:
En el panel Consulta de ejemplo, haga clic en la pestaña Trace de extremo a extremo. En esta pestaña se muestra un gráfico de Gantt que detalla los intervalos, que son registros de operaciones individuales, de la traza generada por la consulta.
Para ver más detalles sobre cada intervalo, como los atributos y los metadatos, haz clic en el intervalo.
También puedes ver el rastreo en la página Explorador de rastreos. Para hacerlo, haga clic en Ver en Cloud Trace. Para obtener información sobre cómo usar la página Explorador de trazas para explorar los datos de trazas, consulta Buscar y explorar trazas.
Añadir etiquetas a consultas de SQL
Etiquetar consultas SQL simplifica la solución de problemas de las aplicaciones. Puedes usar sqlcommenter para añadir etiquetas a tus consultas SQL de forma automática mediante la asignación relacional de objetos (ORM) o manualmente.
Usar sqlcommenter con ORM
Si se usa ORM en lugar de escribir directamente consultas SQL, es posible que no encuentres el código de la aplicación que está causando problemas de rendimiento. También puede tener problemas para analizar cómo afecta el código de su aplicación al rendimiento de las consultas. Para solucionar este problema, Query Insights proporciona una biblioteca de código abierto llamada sqlcommenter, que es una biblioteca de instrumentación ORM. Esta biblioteca es útil para los desarrolladores que usan ORM y para los administradores, ya que les permite detectar qué código de aplicación está causando problemas de rendimiento.
Si usa ORM y sqlcommenter juntos, las etiquetas se crearán automáticamente sin que tenga que cambiar ni añadir código personalizado a su aplicación.
Puedes instalar sqlcommenter en el servidor de aplicaciones. La biblioteca de instrumentación permite que la información de la aplicación relacionada con tu framework MVC se propague a la base de datos junto con las consultas como comentario SQL. La base de datos recoge estas etiquetas y empieza a registrar y agregar estadísticas por etiquetas, que son ortogonales a las estadísticas agregadas por consultas normalizadas. Las estadísticas de consultas muestran las etiquetas para que sepas qué aplicación está provocando la carga de consultas. Esta información te ayuda a identificar qué código de aplicación está causando problemas de rendimiento.
Cuando examinas los resultados en los registros de la base de datos SQL, aparecen de la siguiente manera:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
Entre las etiquetas admitidas se incluyen el nombre del controlador, la ruta, el framework y la acción.
El conjunto de ORMs de sqlcommenter es compatible con varios lenguajes de programación:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
Para obtener más información sobre sqlcommenter y cómo usarlo en tu framework ORM, consulta la documentación de sqlcommenter en GitHub.
Usar sqlcommenter para añadir etiquetas manualmente
Si no usa ORM, debe añadir manualmente etiquetas sqlcommenter a sus consultas SQL. En su consulta, debe aumentar cada instrucción SQL con un comentario que contenga un par clave-valor serializado. Usa al menos una de las siguientes teclas:
action=''controller=''framework=''route=''application=''db driver=''
La información valiosa de las consultas elimina todas las demás claves. Consulta la documentación de sqlcommenter para ver el formato correcto de los comentarios de SQL.
Tiempo y duración de la ejecución
Las estadísticas de consultas proporcionan la métrica Tiempo medio de ejecución (ms), que indica el tiempo total que tardan todas las subtareas en completarse en todos los trabajadores paralelos para completar la consulta. Esta métrica puede ayudarte a optimizar el uso agregado de recursos de las bases de datos. Para ello, busca y optimiza las consultas que generan la mayor sobrecarga de CPU.
Para ver el tiempo transcurrido, puedes medir la duración de una consulta ejecutando el comando \timing en el cliente psql. Mide el tiempo transcurrido entre la recepción de la consulta y el envío de una respuesta por parte del servidor PostgreSQL. Esta métrica puede ayudarte a analizar por qué una consulta tarda demasiado y a decidir si quieres optimizarla para que se ejecute más rápido.
Si una tarea completa una consulta con un solo subproceso, la duración y el tiempo medio de ejecución no cambian.
Habilitar las funciones de información valiosa sobre las consultas avanzadas en AlloyDB
Las funciones de información útil sobre las consultas avanzadas del panel de control de AlloyDB están integradas en el panel de control estándar de información útil sobre las consultas. Para obtener más información sobre cómo habilitar las funciones avanzadas de estadísticas de consultas, consulta el artículo Mejorar el rendimiento de las consultas con las funciones avanzadas de estadísticas de consultas.
Siguientes pasos
- Información general sobre Estadísticas de las consultas
- Mejorar el rendimiento de las consultas con las funciones de información útil sobre las consultas avanzadas de AlloyDB
- Métricas de AlloyDB
- Blog de SQL Commenter: presentamos Sqlcommenter, una biblioteca de instrumentación automática de ORM de código abierto
- Blog de instrucciones: habilita el etiquetado de consultas con Sqlcommenter