Auf dieser Seite wird beschrieben, wie Sie mit dem Query Insights-Dashboard Leistungsprobleme erkennen und analysieren. Einen Überblick über diese Funktion finden Sie unter Übersicht zu Query Insights.
Sie können Gemini Cloud Assist verwenden, um Ihre AlloyDB-Ressourcen zu überwachen und Fehler zu beheben. Weitere Informationen finden Sie unter Mit Gemini überwachen und Fehler beheben.
Hinweise
Wenn Sie oder andere Nutzer den Abfrageplan sehen oder ein End-to-End-Tracing benötigen, brauchen Sie bestimmte IAM-Berechtigungen (Identity and Access Management). Sie können eine benutzerdefinierte Rolle erstellen und ihr die erforderlichen IAM-Berechtigungen hinzufügen. Sie können diese Rolle dann jedem Nutzerkonto hinzufügen, das Query Insights zur Behebung von Problemen verwendet. Weitere Informationen finden Sie im Hilfeartikel Benutzerdefinierte Rollen erstellen
Die benutzerdefinierte Rolle muss die folgende IAM-Berechtigung haben: cloudtrace.traces.get.
Query Insights-Dashboard öffnen
So öffnen Sie das Query Insights-Dashboard:
- Klicken Sie in der Liste der Cluster und Instanzen auf eine Instanz.
- Klicken Sie entweder unter der Messwertgrafik auf der Seite „Clusterübersicht“ auf Zu „Query Insights“ für ausführliche Informationen über Abfragen und zur Leistung oder wählen Sie im linken Navigationsbereich den Tab Query Insights aus.
Auf der nächsten Seite haben Sie die folgenden Möglichkeiten, die Ergebnisse zu filtern:
- Instanzauswahl: Hiermit können Sie entweder die primäre Instanz oder Lesepoolinstanzen im Cluster auswählen. Standardmäßig ist die primäre Instanz ausgewählt. Die angezeigten Details werden für alle verbundenen Lesepoolinstanzen und deren Knoten aggregiert.
- Datenbank. Filtert die Abfragelast für eine bestimmte Datenbank oder für alle Datenbanken.
- Nutzer. Mit diesem Filter wird die Abfragelast aus bestimmten Nutzerkonten gefiltert.
- Client-Adresse Filtert die Abfragelast von einer bestimmten IP-Adresse.
- Zeitraum. Filtert die Abfragelast nach Zeiträumen (z. B. Stunde, Tag, Woche oder benutzerdefinierter Bereich).
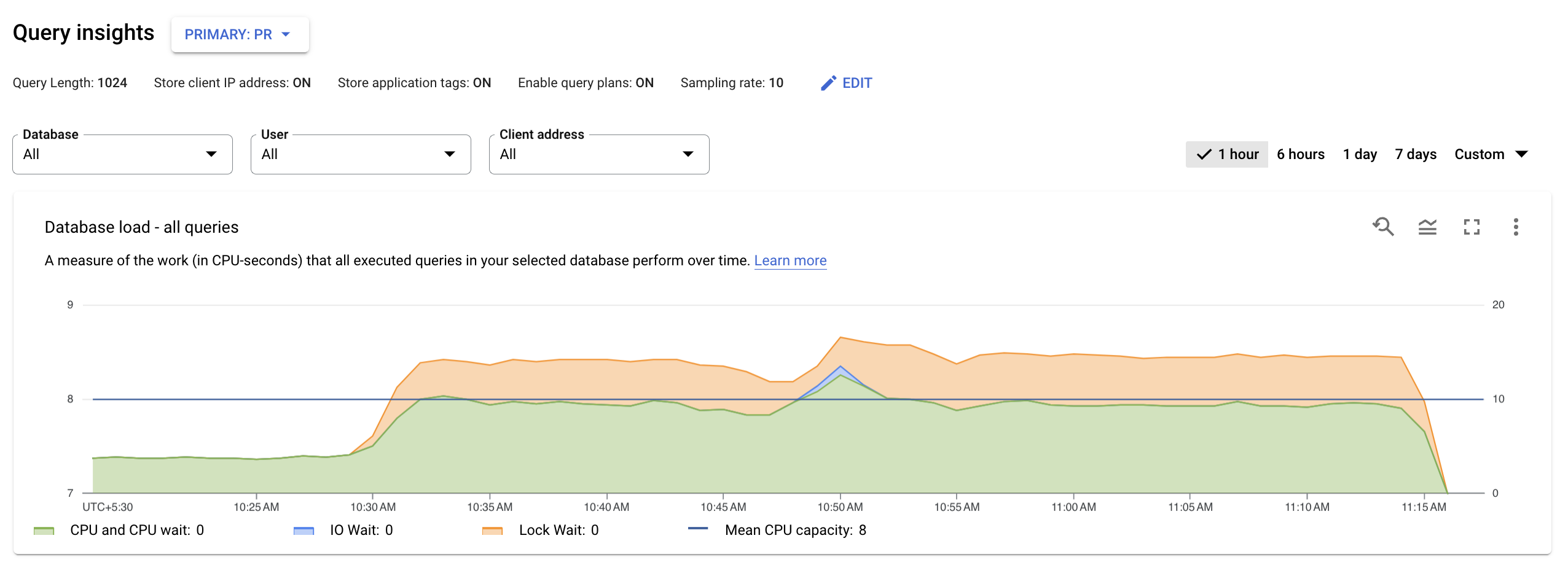
Konfiguration für Abfragestatistiken bearbeiten
Query Insights sind standardmäßig für AlloyDB-Instanzen aktiviert. Sie können die Standardkonfiguration für Abfragestatistiken bearbeiten.
So bearbeiten Sie die Query Insights-Konfiguration für eine AlloyDB-Instanz:
Konsole
Rufen Sie in der Google Cloud Console die Seite Cluster auf.
Klicken Sie in der Spalte Ressourcenname auf einen Cluster.
Klicken Sie im linken Navigationsbereich auf Abfrage-Statistiken.
Wählen Sie in der Liste Query insights (Abfrage-Insights) die Option Primary (Primär) oder Read pool (Lesepool) aus und klicken Sie dann auf Edit (Bearbeiten).
Bearbeiten Sie die Felder unter Query Insights:
Wenn Sie das Standardlimit von 1.024 Byte für die Länge von AlloyDB-Abfragen ändern möchten, die analysiert werden sollen, geben Sie im Feld Länge der Abfrage eine Zahl zwischen 256 und 4.500 ein.
Die Instanz wird neu gestartet, nachdem Sie dieses Feld bearbeitet haben.
Hinweis: Höhere Grenzwerte für die Abfragelänge erfordern mehr Arbeitsspeicher.
Wenn Sie die Features von Query Insights anpassen möchten, ändern Sie die folgenden Optionen:
Stichproben für Abfragepläne: Wählen Sie dieses Kästchen aus, um die Vorgänge zu visualisieren, die zum Ausführen einer Abfragestichprobe verwendet werden. Die Stichprobenrate bestimmt die maximale Anzahl von Abfragen, die AlloyDB pro Minute und Knoten für die Instanz als Stichprobe erfassen kann.
Geben Sie im Feld Maximale Abtastrate eine Zahl zwischen 1 und 20 ein. Standardmäßig ist die Sampling-Rate auf 5 festgelegt. Wenn Sie die Stichprobenerhebung deaktivieren möchten, entfernen Sie das Häkchen aus dem Kästchen Abfrageplanstichproben.
Client-IP-Adressen speichern: Wenn Sie dieses Kästchen anklicken, können Sie ermitteln, woher Ihre Anfragen stammen, und diese Informationen gruppieren, um Messwerte zu erstellen.
Anwendungs-Tags speichern: Wenn Sie dieses Kästchen anklicken, können Sie ermitteln, welche getaggten Anwendungen Anfragen stellen, und diese Informationen gruppieren, um Messwerte zu erstellen. Weitere Informationen zu Anwendungstags finden Sie in der Spezifikation.
Klicken Sie auf Instanz aktualisieren.
gcloud
So aktivieren Sie Query Insights für eine AlloyDB-Instanz mit Google Cloud CLI-Befehlen:
- Installieren Sie die Google Cloud CLI.
- Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
Wenn Sie eine lokale Shell verwenden, erstellen Sie lokale Anmeldedaten zur Authentifizierung für Ihr Nutzerkonto:
gcloud auth application-default login
Wenn Sie Cloud Shell verwenden, müssen Sie das nicht tun.
Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Beispiel:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressErsetzen Sie Folgendes:
INSTANCE: die ID der zu aktualisierenden InstanzCLUSTER: Die ID des Clusters der Instanz.PROJECT: die ID des Projekts des ClustersREGION: Die Region des Clusters, z. B.us-central1QUERY_LENGTH: die Länge der Anfrage, die zwischen 256 und 4.500 Zeichen liegtQUERY_PLANS: Die Anzahl der Abfragepläne, die pro Minute konfiguriert werden sollen.
Verwenden Sie außerdem eines oder mehrere der folgenden optionalen Flags:
--insights-config-query-string-length: Legt die maximale Länge der Abfragelänge auf einen angegebenen Wert von 256 bis 4.500 Byte fest. Die Standardlänge der Abfrage beträgt 1.024 Byte. Höhere Abfragelängen sind hilfreich für analytische Abfragen, erfordern aber auch mehr Arbeitsspeicher. Zum Ändern der Abfragelänge müssen Sie die Instanz neu starten. Sie können weiterhin Tags zu Abfragen hinzufügen, die die Längenbegrenzung überschreiten.--insights-config-query-plans-per-minute: Standardmäßig werden in allen Datenbanken der Instanz maximal fünf ausgeführte Abfrageplanstichproben pro Minute erfasst. Ändern Sie diesen Wert in eine Zahl zwischen 1 und 20. Geben Sie 0 ein, um die Stichprobenerhebung zu deaktivieren. Wenn Sie die Stichprobenrate erhöhen, erhalten Sie wahrscheinlich mehr Datenpunkte. Allerdings kann dies zu Leistungseinbußen führen.--insights-config-record-client-address: Speichert die Client-IP-Adressen, von denen Abfragen stammen, und gruppiert diese Daten, um Messwerte damit auszuführen. Abfragen stammen von mehr als einem Host. Anhand der Grafiken zu Abfragen von Client-IP-Adressen können Sie die Ursache eines Problems ermitteln. Wenn Sie keine Client-IP-Adressen speichern möchten, verwenden Sie--no-insights-config-record-client-address.--insights-config-record-application-tags: Speichert Anwendungs-Tags, die Ihnen dabei helfen, die APIs und MVC-Routen (Model-View-Controller) zu bestimmen, die Anfragen stellen, und die Daten zu gruppieren, um sie mit Messwerten zu vergleichen. Bei dieser Option müssen Abfragen mit einem bestimmten Satz von Tags kommentiert werden. Wenn Sie keine Anwendungstags speichern möchten, verwenden Sie--no-insights-config-record-application-tags.
Terraform
Wenn Sie Terraform verwenden möchten, um Query Insights zu konfigurieren, verwenden Sie die Ressource google_alloydb_instance.
Beispiel:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
Ersetzen Sie Folgendes:
QUERY_STRING_LENGTH_VALUE: Länge des Abfragestrings. Der Standardwert ist1024. Ganzzahlen zwischen 256 und 4.500 sind gültig.RECORD_APPLICATION_TAG_VALUE: Anwendungs-Tag für eine Instanz aufzeichnen. Der Standardwert isttrue.RECORD_CLIENT_ADDRESS_VALUE: Die Clientadresse für eine Instanz aufzeichnen. Der Standardwert isttrue.QUERY_PLANS_PER_MINUTE_VALUE: Die Anzahl der Abfrageausführungspläne, die von Insights pro Minute für alle Abfragen zusammen erfasst werden. Der Standardwert ist5. Ganzzahlen zwischen 0 und 20 sind gültig.Informationen zum Anwenden oder Entfernen einer Terraform-Konfiguration finden Sie unter Grundlegende Terraform-Befehle.
Die Beispielkonfiguration der Instanz mit der hinzugefügten Konfiguration für Suchanfragen sollte so aussehen:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST Version 1
In diesem Beispiel werden die Einstellungen für die Beobachtbarkeit für Ihre AlloyDB-Instanz konfiguriert. Eine vollständige Liste der Parameter für diesen Aufruf finden Sie unter Methode: projects.locations.clusters.instances.patch.
Wenn Sie die Einstellungen für Query Insights konfigurieren möchten, ändern Sie die optionalen Felder nach Bedarf. Eine vollständige Liste der Felder für diesen Aufruf finden Sie unter QueryInsightsInstanceConfig.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
CLUSTER_ID: die ID des Clusters, den Sie erstellen. Sie muss mit einem Kleinbuchstaben beginnen und darf Kleinbuchstaben, Ziffern und Bindestriche enthalten.PROJECT_ID: die ID des Projekts, in dem Sie den Cluster platzieren möchten.LOCATION_ID: Die ID der Region des Clusters.INSTANCE_ID: Name der primären Instanz, die Sie erstellen möchten.
Verwenden Sie die folgende PATCH-Anfrage, um die Konfiguration Ihrer Instanz zu ändern:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
Der JSON-Text der Anfrage, mit dem alle Felder für die Beobachtbarkeit konfiguriert werden, sieht so aus:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
Abfrageleistung verbessern
Query Insights behebt Fehler in AlloyDB-Abfragen, um Leistungsprobleme zu erkennen. Im Query Insights-Dashboard wird die Abfragelast basierend auf von Ihnen ausgewählten Faktoren angezeigt. Die Abfragelast ist ein Maß für die Gesamtarbeit aller Abfragen in der Instanz im ausgewählten Zeitraum.
Mit Query Insights können Sie Probleme mit der Abfrageleistung erkennen und analysieren. So beheben Sie Probleme mit Abfragen mithilfe von Query Insights:
- Datenbanklast für alle Abfragen ansehen
- Problematische Abfrage oder problematisches Tag identifizieren
- Abfrage oder Tag ansehen, um Probleme zu ermitteln
- Von einer Beispielanfrage generierten Trace untersuchen
Datenbanklast für alle Abfragen ansehen
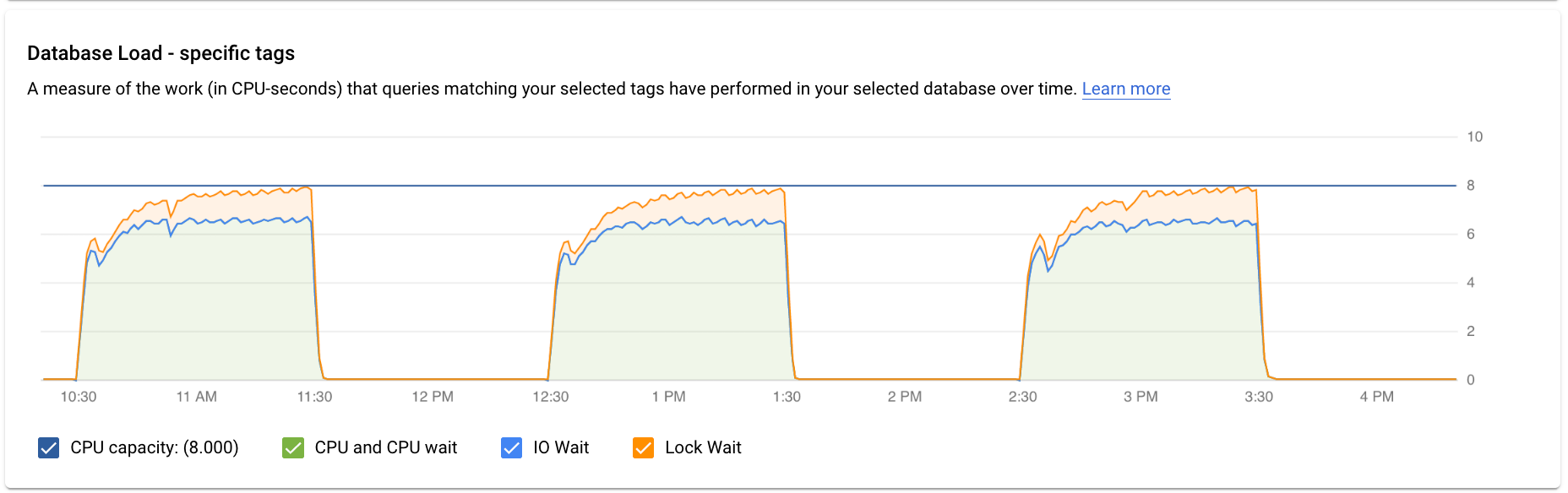
Das Dashboard „Query Insights“ der obersten Ebene zeigt das Diagramm Datenbanklast – alle Top-Abfragen mit gefilterten Daten. Die Anzahl der Datenbankabfragen ist eine Messung der Arbeit (in CPU-Sekunden), die von den ausgeführten Abfragen in der ausgewählten Datenbank im Zeitverlauf ausgeführt wird. Bei jeder ausgeführten Abfrage werden entweder CPU-Ressourcen, E/A-Ressourcen oder Sperren von CPU-Ressourcen verwendet oder darauf gewartet. Die Datenbankabfragelast ist das Verhältnis der Zeit, die von allen innerhalb eines bestimmten Zeitfensters abgeschlossenen Abfragen benötigt wird, zur tatsächlich verstrichenen Zeit.
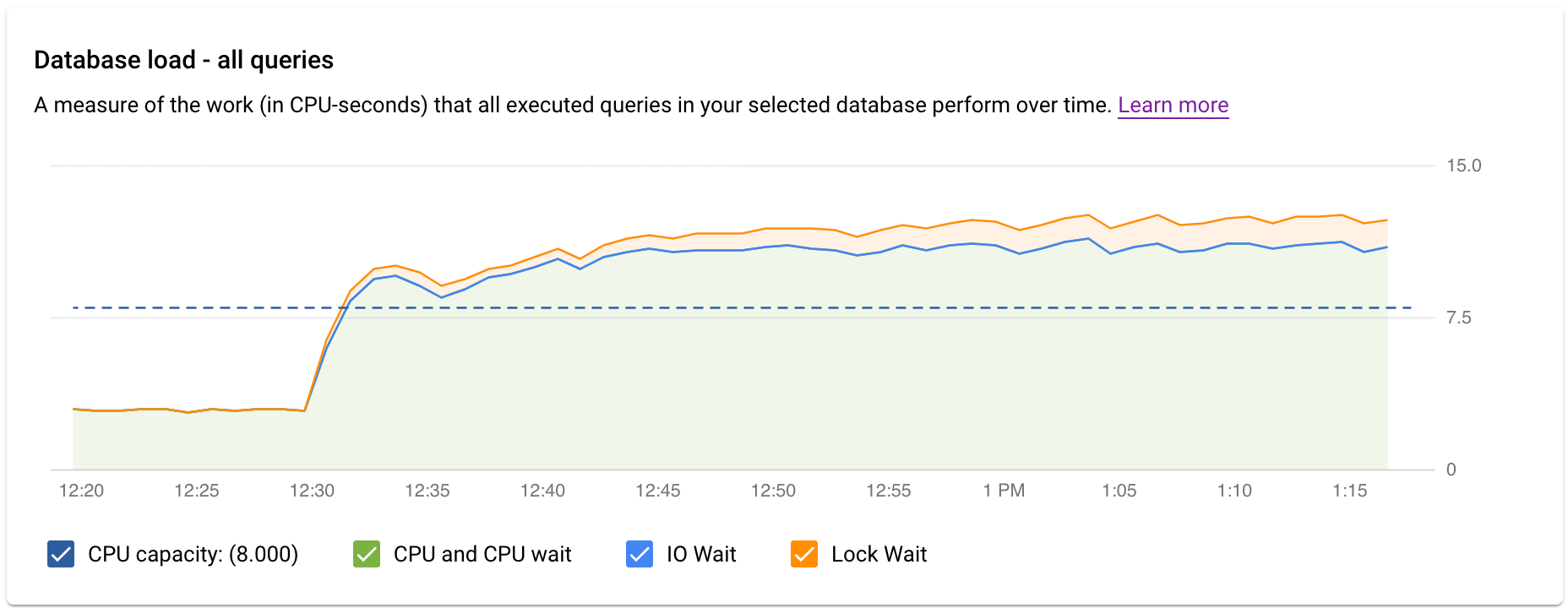
Die farbigen Linien in der Grafik zeigen die Abfragelast, in vier Kategorien unterteilt:
- CPU-Kapazität: Die Anzahl der CPUs, die auf der Instanz verfügbar sind.
CPU und CPU-Wartezeit: Verhältnis der Zeit, die Abfragen in einem aktiven Zustand benötigen, zur tatsächlich verstrichenen Zeit. IO- und Sperrwartet blockieren keine Abfragen, die aktiv sind. Dieser Messwert kann bedeuten, dass die Abfrage entweder die CPU verwendet oder wartet, bis der Linux-Planer den Serverprozess plant, der die Abfrage ausführt, während andere Prozesse die CPU verwenden.
Hinweis: CPU-Lasten berücksichtigen sowohl die Laufzeit als auch die Zeit, die auf den Linux-Planer gewartet wird, um den laufenden Serverprozess zu planen. Daher kann die CPU-Auslastung die maximale Kernlinie überschreiten.
IO Wait: Das Verhältnis der Zeit, die Abfragen auf IO warten, zur tatsächlich verstrichenen Zeit. IO Wait beinhaltet Read IO Wait und Write IO Wait. Weitere Informationen finden Sie in der PostgreSQL-Ereignistabelle. Eine Gliederung der Informationen zu IO Waits nach Sperrung können Sie in Cloud Monitoring anzeigen. Weitere Informationen finden Sie unter Messwertdiagramme.
Lock Wait: Das Verhältnis der Zeit, die Abfragen auf Sperren warten, zur tatsächlich verstrichenen Zeit. Dies beinhaltet Wartezeiten nach Sperrung, LwLock-Wartezeiten und BufferPin-Wartezeiten nach Sperrung. Eine Gliederung der Informationen zu Wartezeiten nach Sperrung können Sie in Cloud Monitoring anzeigen. Weitere Informationen finden Sie unter Messwertdiagramme.
Sehen Sie sich nun das Diagramm an und beantworten Sie die folgenden Fragen mithilfe der Filteroptionen:
- Ist die Abfragelast hoch? Ist eine Spitze oder ein Anstieg im Zeitverlauf zu sehen? Wenn keine hohe Last angezeigt wird, liegt das Problem nicht bei Ihren Abfragen.
- Wie lange war die Last hoch? Ist sie nur jetzt hoch? Oder ist sie schon lange hoch? Verwenden Sie die Bereichsauswahl, um verschiedene Zeiträume auszuwählen, um zu ermitteln, wie lange das Problem aufgetreten ist. Sie können auch heranzoomen, um ein Zeitfenster anzuzeigen, in dem die Spitzen der Abfragelasten beobachtet werden. Sie können herauszoomen, um bis zu einer Woche auf der Zeitachse zu sehen.
- Wodurch wird die hohe Last verursacht? Sie können zur Auswahl der CPU-Kapazität, der CPU- und CPU-Wartezeit, der Schloss-Wartezeit oder der E/A-Wartezeit wählen. Die Grafik für diese Optionen hat eine andere Farbe, sodass Sie sehen können, welche die höchste Auslastung aufweist. Die dunkelblaue Linie im Diagramm zeigt die maximale CPU-Kapazität des Systems an. Sie können die Abfragelast mit der maximalen CPU-Systemkapazität vergleichen. Anhand dieses Vergleichs können Sie feststellen, ob die CPU-Ressourcen einer Instanz erschöpft sind.
- Welche Datenbank hat die Auslastung? Wählen Sie im Drop-down-Menü "Datenbanken" verschiedene Datenbanken aus, um die Datenbanken mit den höchsten Lasten zu finden.
- Verursachen bestimmte Nutzer oder IP-Adressen höhere Lasten? Wählen Sie in den Drop-down-Menüs verschiedene Nutzer und Adressen aus, um zu vergleichen, welche die höchste Last verursachen.
Datenbanklast filtern
In den Bereichen Abfragen und Tags können Sie die Abfragelast entweder nach einer ausgewählten Abfrage oder einem SQL-Abfrage-Tag filtern oder sortieren.
Nach Abfragen filtern
Die Tabelle ABFRAGEN bietet einen Überblick über die Abfragen, die die meisten Abfragelasten verursachen. Die Tabelle enthält alle normalisierten Abfragen für das Zeitfenster und die Optionen, die im Query Insights-Dashboard ausgewählt wurden.
Standardmäßig werden die Abfragen in der Tabelle nach der Gesamtausführungszeit im ausgewählten Zeitraum sortiert.
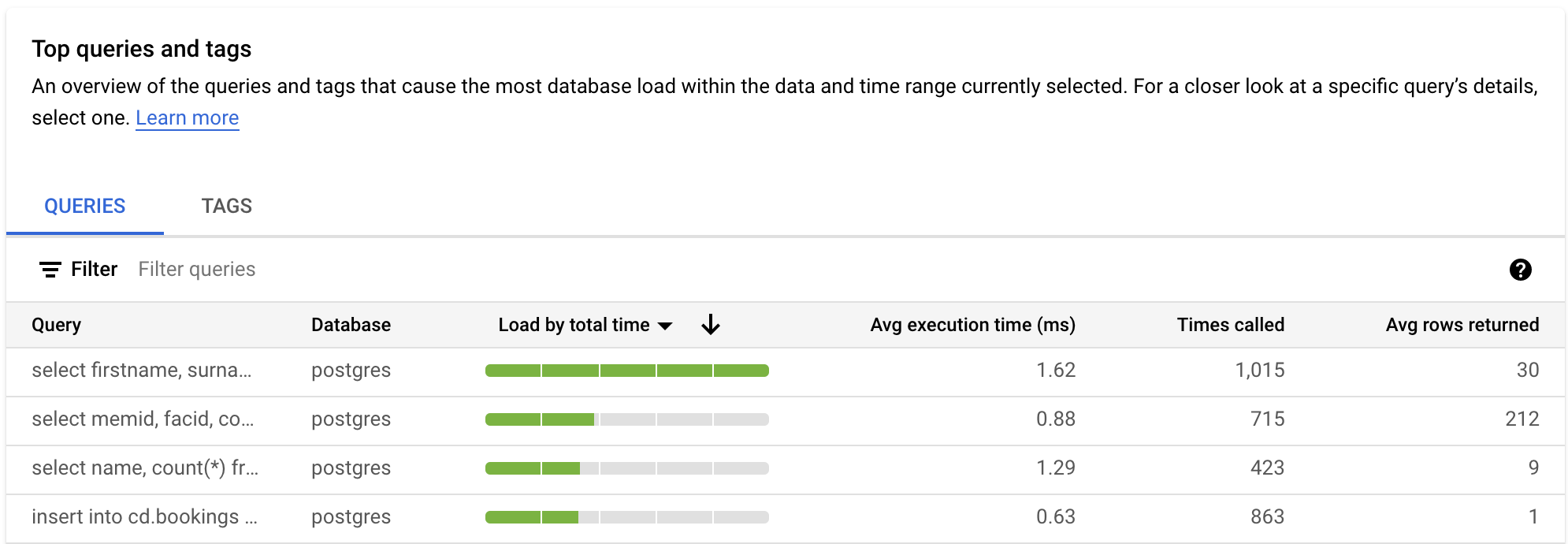
Wählen Sie zum Filtern der Tabelle ein Attribut aus Filterabfragen aus. Wählen Sie eine Spaltenüberschrift aus, um die Tabelle zu sortieren. Die Tabelle enthält die folgenden Attribute:
Abfragestring. Der normalisierte Abfragestring. Query Insights zeigt standardmäßig nur 1.024 Zeichen im Abfragestring an.
Abfragen mit dem Label
UTILITY COMMANDenthalten in der Regel die BefehleBEGIN,COMMITundEXPLAINoder Wrapper-Befehle.Datenbank. Die Datenbank, für die die Abfrage ausgeführt wurde.
Last nach Gesamtzeit/Last nach CPU/Last nach E/A-Wartezeit/Last nach Wartezeit der Sperre. Mit diesen Optionen können Sie bestimmte Abfragen filtern, um die höchste Last für jede Option zu ermitteln.
Durchschnittliche Ausführungszeit (ms). Die Gesamtzeit, die alle untergeordneten Aufgaben über alle parallelen Worker hinweg benötigen, um die Abfrage abzuschließen. Weitere Informationen finden Sie unter Durchschnittliche Ausführungszeit und ‑dauer.
Anzahl an Aufrufen. Die Häufigkeit, mit der die Abfrage von der Anwendung aufgerufen wurde.
Durchschn. abgerufene Zeilen. Die durchschnittliche Anzahl der für die Abfrage abgerufenen Zeilen.
Query Insights zeigt normalisierte Abfragen an – $1, $2 usw. ersetzen also die Werte der Literalkonstanten. Beispiel:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
Der Wert der Konstante wird ignoriert, damit in Query Insights ähnliche Abfragen aggregiert und personenidentifizierbare Informationen entfernt werden können, die die Konstante möglicherweise anzeigt.
Nach Abfrage-Tags filtern
Zur Behebung von Fehlern in Anwendungen müssen Sie zuerst Tags zu SQL-Abfragen hinzufügen.
Query Insights bietet anwendungsorientiertes Monitoring zur Diagnose von Leistungsproblemen für Anwendungen, die mit ORMs erstellt wurden.
Wenn Sie für das gesamte Anwendungspaket verantwortlich sind, können Sie mit Query Insights Abfragen in einer Anwendungsansicht verfolgen. Mit der Tag-Kennzeichnung von Abfragen können Sie Probleme auf höherer Ebene ermitteln, z. B. mit der Geschäftslogik, einem Mikrodienst oder einem anderen Konstrukt. Sie können Abfragen nach der Geschäftslogik taggen, z. B. mithilfe der Tags für Zahlungen, Inventar, Geschäftsanalysen oder Versand. Anschließend können Sie die Abfragelast ermitteln, die die verschiedenen Arten von Geschäftslogik erstellt haben. Beispielsweise kann es zu unerwarteten Ereignissen kommen, z. B. zu Spitzenspitzen für ein Business Analytics-Tag um 13:00 Uhr. Oder es kann zu einem unerwarteten Wachstum für einen Zahlungsdienst in der vergangenen Woche kommen.
Abfragelasttags ermöglichen eine Aufschlüsselung der Abfragelast des ausgewählten Tags im Zeitverlauf.
Zur Berechnung der Datenbanklast für Tag verwendet Query Insights die Zeit, die jede Abfrage mit dem von Ihnen ausgewählten Tag benötigt. Query Insights berechnet die benötigte Zeit anhand der tatsächlich verstrichenen Zeit.
Wählen Sie im Dashboard „Query Insights“ die Option TAGS aus, um die Tag-Tabelle aufzurufen. Die Tabelle TAGS sortiert Tags nach der Gesamtlast nach der Gesamtzeit.

Sie können die Tabelle sortieren, indem Sie unter Filterabfragen ein Attribut auswählen oder auf eine Spaltenüberschrift klicken. Die Tabelle enthält die folgenden Attribute:
- Action, Controller, Framework, Route, Application, DB Driver. Jedes Attribut, das Sie Ihren Abfragen hinzugefügt haben, wird als Spalte angezeigt. Sie müssen mindestens eine dieser Eigenschaften hinzufügen, wenn Sie nach Tags filtern möchten.
- Last nach Gesamtzeit/Last nach CPU/Last nach E/A-Wartezeit/Last nach Wartezeit der Sperre. Mit diesen Optionen können Sie bestimmte Abfragen filtern, um die höchste Last für jede Option zu ermitteln.
- Durchschnittliche Ausführungszeit (ms). Die Gesamtzeit, die alle untergeordneten Aufgaben über alle parallelen Worker hinweg benötigen, um die Abfrage abzuschließen. Weitere Informationen finden Sie unter Durchschnittliche Ausführungszeit und ‑dauer.
- Anzahl an Aufrufen. Die Häufigkeit, mit der die Abfrage von der Anwendung aufgerufen wurde.
- Durchschn. abgerufene Zeilen. Die durchschnittliche Anzahl der für die Abfrage abgerufenen Zeilen.
- Datenbank. Die Datenbank, für die die Abfrage ausgeführt wurde.
Bestimmte Abfrage oder bestimmtes Tag prüfen
Führen Sie auf dem Tab Abfragen oder Tags Folgendes aus, um die Ursache des Problemszu ermitteln:
- Klicken Sie auf den Header Last nach Gesamtzeit, um die Liste in absteigender Reihenfolge zu sortieren.
- Klicken Sie auf die Abfrage oder das Tag, das vermeintlich die höchste Last hat und mehr Zeit als die anderen benötigt.
Es wird ein Dashboard mit den Details der ausgewählten Abfrage bzw. des ausgewählten Tags geöffnet.
Wenn Sie eine Abfrage ausgewählt haben, wird eine Übersicht über die ausgewählte Abfrage angezeigt:

Wenn Sie ein Tag ausgewählt haben, wird eine Übersicht über das ausgewählte Tag angezeigt.
Last für eine bestimmte Abfrage oder ein bestimmtes Tag prüfen
Das Diagramm Datenbanklast – bestimmte Abfrage zeigt eine Messung der Arbeit (in CPU-Sekunden) an, die Ihre ausgewählte normalisierte Abfrage im Zeitverlauf in der ausgewählten Abfrage ausgeführt hat. Zur Berechnung der Last wird die von normalisierten Abfragen benötigte Zeit zur tatsächlich verstrichenen Zeit verwenden. Am Anfang der Tabelle werden die ersten 1024 Zeichen der normalisierten Abfrage angezeigt. Literale werden dabei wegen Aggregation und personenidentifizierbaren Informationen entfernt. Wie beim Diagramm zur Gesamtzeit der Abfragen können Sie die Last für eine bestimmte Abfrage nach Datenbank, Nutzer und Clientadresse filtern. Die Abfragelast wird in CPU-Kapazität, CPU und CPU-Wartezeit, E/A-Wartezeit und Wartezeit nach Sperrung aufgeteilt.
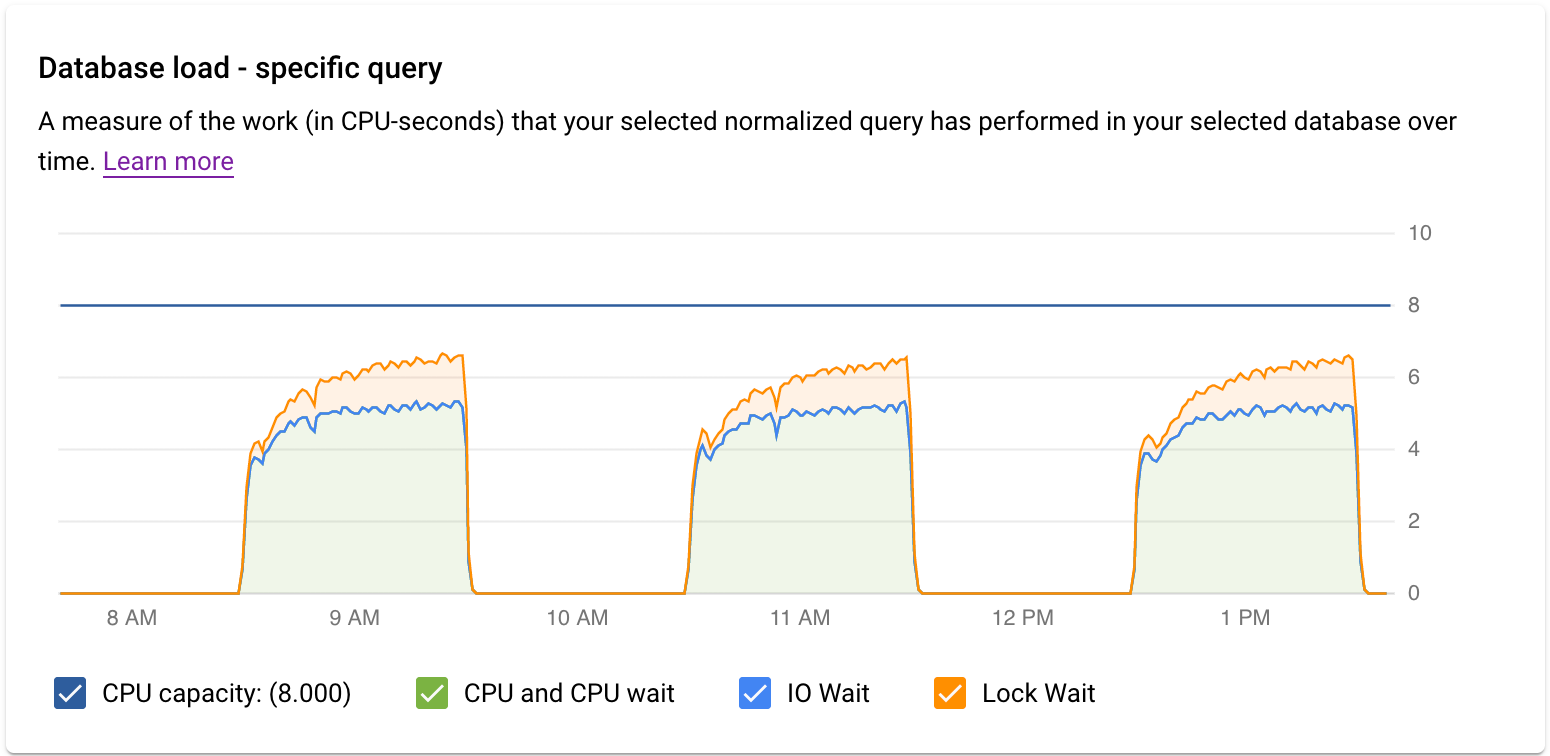
Das Diagramm Datenbanklast – bestimmte Tags zeigt eine Messung der Arbeit (in CPU-Sekunden) an, die Abfragen, die mit Ihren ausgewählten Tags übereinstimmen, in der ausgewählten Datenbank im Laufe der Zeit ausgeführt haben. Wie beim Diagramm zur Gesamtzeit der Abfragen können Sie die Last für eine bestimmte Abfrage nach Datenbank, Nutzer und Clientadresse filtern.
Latenz prüfen
Mit dem Diagramm Latenz können Sie die Latenz der Abfrage oder des Tags untersuchen. Latenz ist die tatsächlich verstrichene Zeit, die für den Abschluss der normalisierten Abfrage benötigt wird. Im Latenz-Dashboard werden die Latenzen für das 50., 95. und 99. Perzentil angezeigt, um Ausreißerverhalten zu ermitteln.
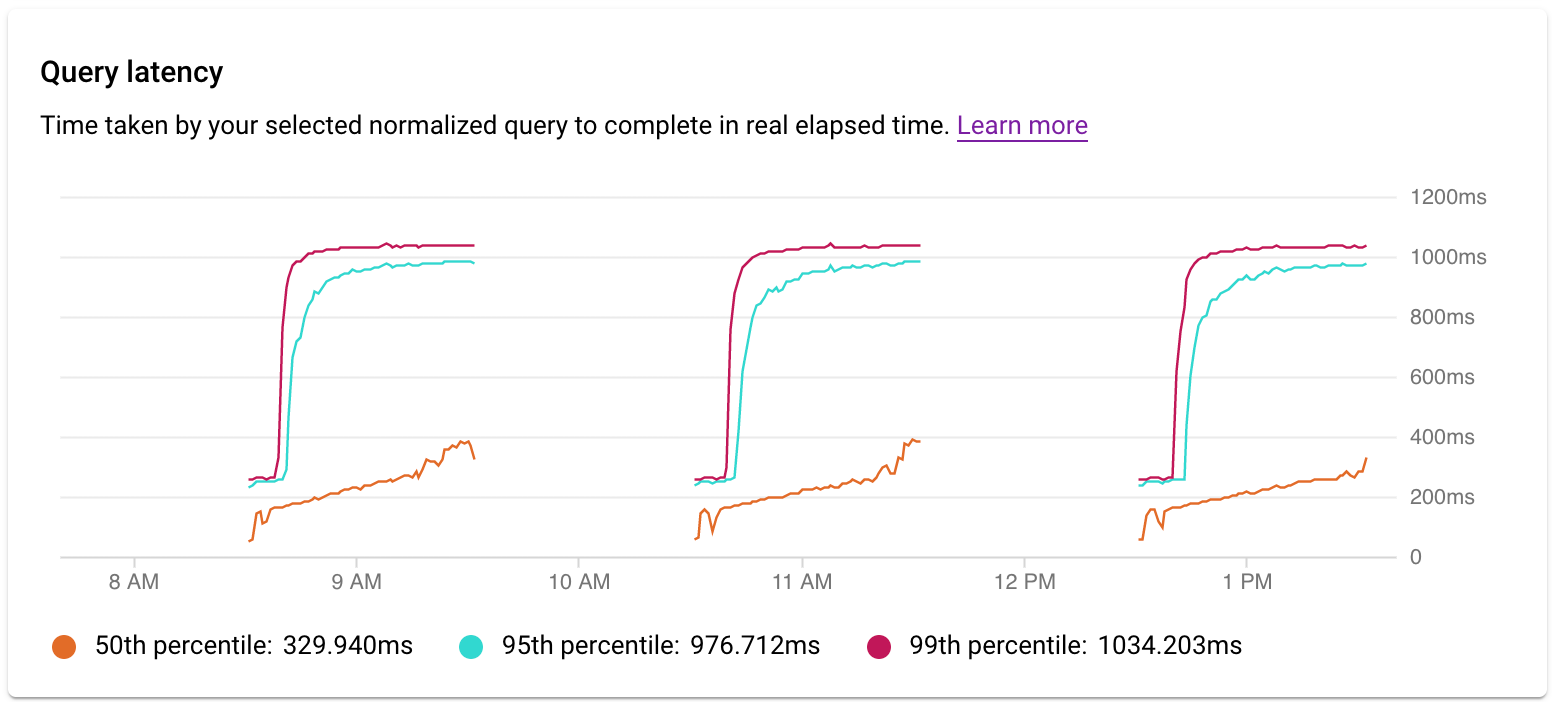
Die Latenz der parallelen Abfragen wird in der tatsächlich verstrichenen Zeit gemessen, obwohl die Datenbanklast für die Abfrage höher sein kann, da mehrere Kerne zum Ausführen bestimmter Teile der Abfrage verwendet werden.
Versuchen Sie, das Problem folgendermaßen einzugrenzen:
- Wodurch wird die hohe Last verursacht? Wählen Sie Optionen aus, um die CPU-Kapazität, die CPU und CPU-Wartezeit sowie die E/A-Wartezeit und Wartezeit nach Sperrung zu sehen.
- Wie lange war die Last hoch? Ist sie nur jetzt hoch? Oder ist sie schon lange hoch? Ändern Sie die Zeiträume, um das Datum und die Uhrzeit zu ermitteln, zu der sich die Leistung der Last verschlechterte.
- Gibt es Latenzspitzen? Sie können das Zeitfenster ändern, um die bisherige Latenz für die normalisierte Abfrage zu untersuchen.
Wenn Sie die Bereiche und Zeiten für die höchste Last ermittelt haben, können Sie die Informationen weiter aufschlüsseln.
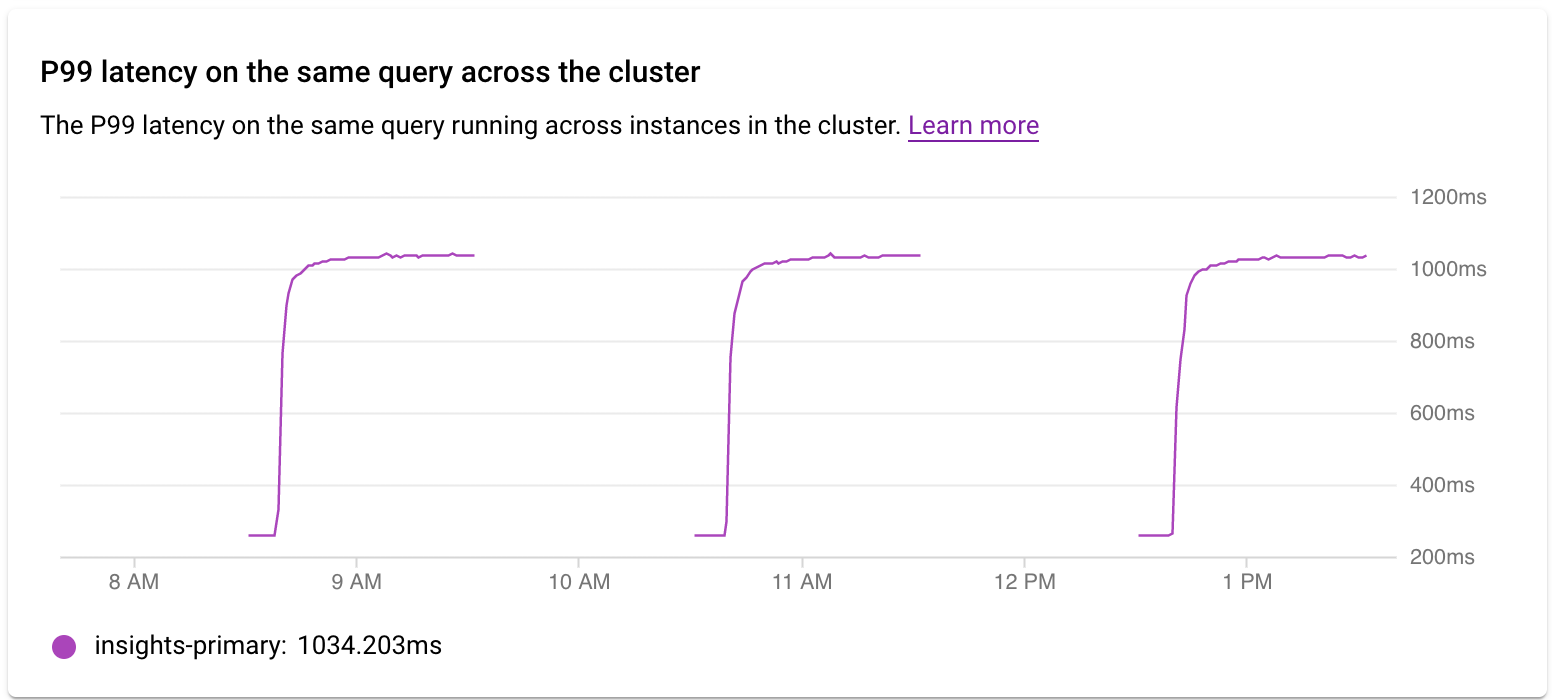
Latenz in einem Cluster untersuchen
Mit dem Diagramm P99-Latenz für dieselbe Abfrage im gesamten Cluster können Sie die P99-Latenz der Abfrage oder des Tags auf verschiedenen Instanzen im Cluster untersuchen.
Vorgänge in einem Beispielabfrageplan prüfen
Mit einem Abfrageplan wird eine Stichprobe Ihrer Abfrage erstellt und in einzelne Vorgänge unterteilt. Die einzelnen Vorgänge in der Abfrage werden erläutert. Das Diagramm Abfrageplanbeispiele zeigt alle Abfragepläne, die zu bestimmten Zeiten ausgeführt werden, sowie die Zeit, die jeder Plan benötigt hat.
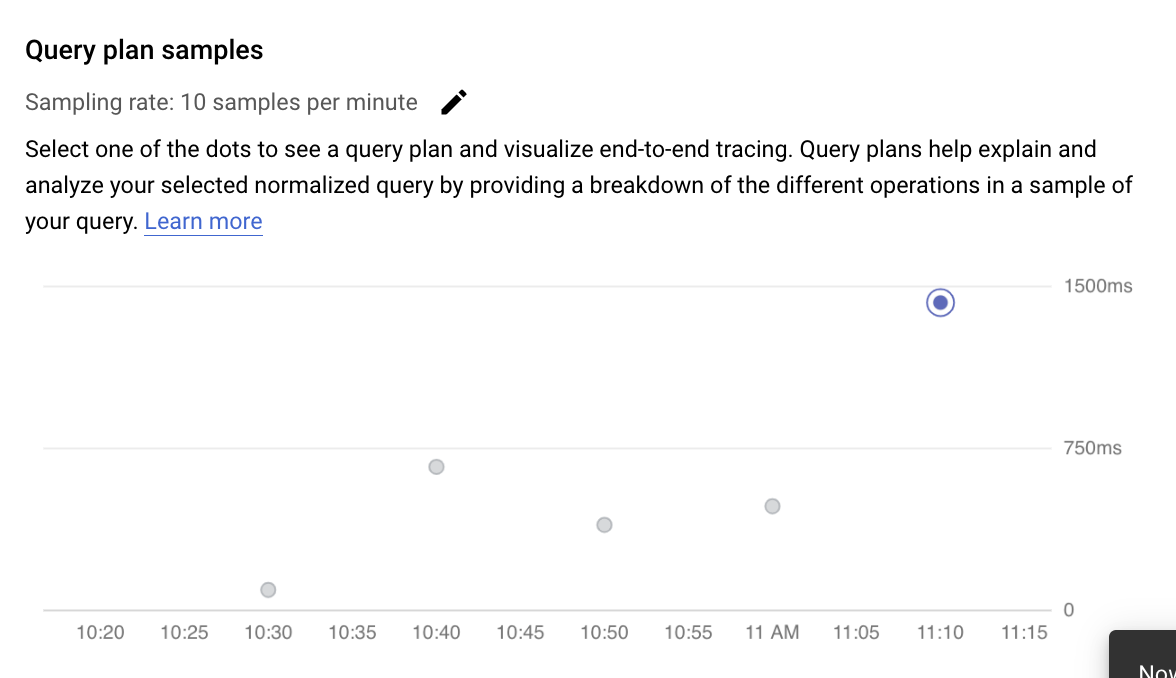
Um Details für den Beispielabfrageplan anzuzeigen, klicken Sie auf die Punkte im Diagramm Beispielabfragepläne. Die meisten ausgeführten Abfragepläne werden angezeigt, allerdings nicht alle. Erweiterte Details zeigen ein Modell aller Vorgänge im Abfrageplan. Jeder Vorgang zeigt die Latenz, die zurückgegebenen Zeilen und die Kosten für diesen Vorgang an. Wenn Sie einen Vorgang auswählen, sehen Sie weitere Details wie gemeinsame Treffer, den Typ des Schemas, die tatsächlichen Schleifen, die Planzeilen und vieles mehr.
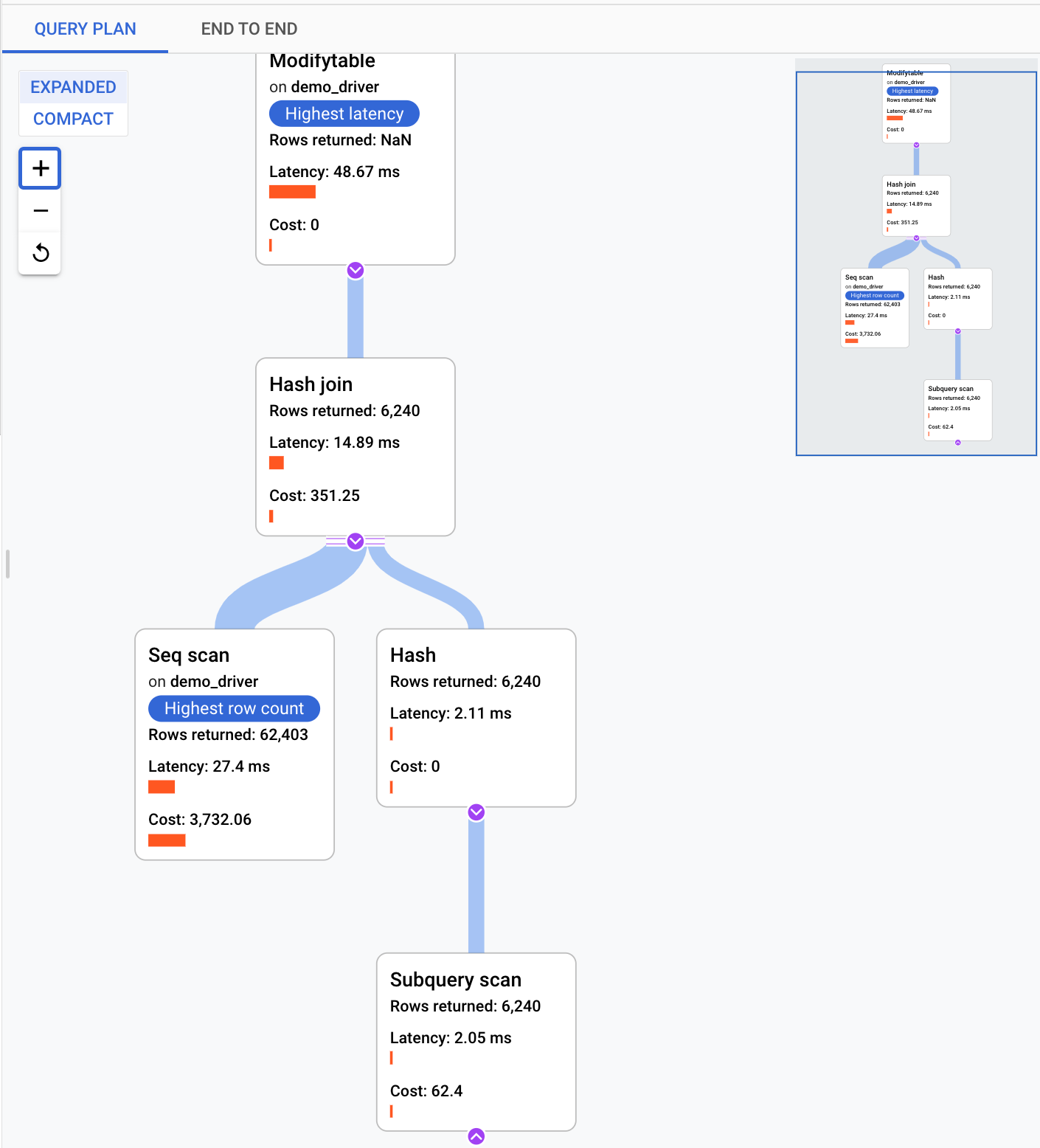
Versuchen Sie, das Problem anhand der folgenden Fragen einzugrenzen:
- Wie hoch ist der Ressourcenverbrauch?
- Wie hängt er mit anderen Abfragen zusammen?
- Ändert sich der Verbrauch im Laufe der Zeit?
Trace einer Beispielabfrage untersuchen
Zusätzlich zum Beispielabfrageplan können Sie mit Abfrage-Insights einen kontextbezogenen End-to-End-Anwendungs-Trace für eine Beispielabfrage aufrufen. Anhand dieses Traces können Sie die Quelle einer problematischen Abfrage ermitteln, da die Datenbankaktivität für eine bestimmte Anfrage angezeigt wird. Außerdem werden Logeinträge, die die Anwendung während der Anfrage an Cloud Logging sendet, mit dem Trace verknüpft, was Ihnen bei der Untersuchung hilft.
So rufen Sie den In-Context-Trace auf:
Klicken Sie im Bereich Beispielabfrage auf den Tab End-to-End-Trace. Auf diesem Tab sehen Sie ein Gantt-Diagramm mit den Spannen, die Datensätze einzelner Vorgänge für den von der Abfrage generierten Trace sind.
Wenn Sie weitere Details zu den einzelnen Spans aufrufen möchten, z. B. Attribute und Metadaten, klicken Sie auf den entsprechenden Span.
Sie können sich den Trace auch auf der Seite Trace Explorer ansehen. Klicken Sie dazu auf In Cloud Trace ansehen. Weitere Informationen zur Verwendung der Seite Trace-Explorer zum Untersuchen Ihrer Tracedaten finden Sie unter Traces suchen und untersuchen.
Tags zu SQL-Abfragen hinzufügen
Das Taggen von SQL-Abfragen vereinfacht die Fehlerbehebung in Anwendungen. Sie können sqlcommenter verwenden, um Ihren SQL-Abfragen Tags entweder automatisch mithilfe der objektrelationalen Zuordnung (Object-relational Mapping, ORM) oder manuell hinzuzufügen.
sqlcommenter mit ORM verwenden
Wenn Sie ORM verwenden, anstatt SQL-Abfragen direkt zu schreiben, finden Sie möglicherweise keinen Anwendungscode, der Leistungsprobleme verursacht. Unter Umständen können Sie auch nicht analysieren, wie sich Ihr Anwendungscode auf die Abfrageleistung auswirkt. Um dies zu vermeiden, bietet Query Insights eine Open-Source-Bibliothek mit dem Namen sqlcommenter, einer ORM-Instrumentierungsbibliothek. Diese Bibliothek ist für Entwickler nützlich, die ORMs verwenden, und für Administratoren, die ermitteln möchten, welcher Anwendungscode Leistungsprobleme verursacht.
Wenn Sie ORM und sqlcommenter zusammen verwenden, werden die Tags automatisch erstellt, ohne dass Sie benutzerdefinierten Code ändern oder zu Ihrer Anwendung hinzufügen müssen.
Sie können sqlcommenter auf dem Anwendungsserver installieren. Die Instrumentierungsbibliothek ermöglicht die Weitergabe von Anwendungsinformationen in Verbindung mit Ihrem Modell, Ihrer Ansicht und Ihrem MVC-Framework zusammen mit den Abfragen als SQL-Kommentar. Die Datenbank ruft diese Tags ab und beginnt die Aufzeichnung und Aggregation von Statistiken nach Tags. Dies sind orthogonale Statistiken mit normalisierten Abfragen. Query Insights zeigt die Tags an, damit Sie wissen, welche Anwendung die Abfragelast verursacht. Mithilfe dieser Informationen können Sie herausfinden, welcher Anwendungscode Leistungsprobleme verursacht.
Ergebnisse in SQL-Datenbanklogs werden so angezeigt:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
Zu den unterstützten Tags gehören der Controllername, die Route, das Framework und die Aktion.
Die Gruppe von ORMs in sqlcommenter wird für verschiedene Programmiersprachen unterstützt:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
Weitere Informationen über sqlcommenter und dessen Verwendung in Ihrem ORM-Framework finden Sie in der sqlcommenter-Dokumentation in GitHub.
Tags mit sqlcommenter manuell hinzufügen
Wenn Sie ORM nicht verwenden, müssen Sie Ihren SQL-Abfragen manuell sqlcommenter-Tags hinzufügen. In der Abfrage müssen Sie jede SQL-Anweisung mit einem Kommentar erweitern, der ein serialisiertes Schlüssel/Wert-Paar enthält. Verwenden Sie mindestens einen der folgenden Schlüssel:
action=''controller=''framework=''route=''application=''db driver=''
Query Insights löst alle anderen Schlüssel ab. Das richtige SQL-Kommentarformat finden Sie in der Dokumentation zu sqlcommenter.
Ausführungszeit und ‑dauer
Query Insights bietet den Messwert Durchschnittliche Ausführungszeit (ms), der die Gesamtzeit angibt, die alle untergeordneten Aufgaben über alle parallelen Worker hinweg benötigen, um die Abfrage abzuschließen. Mit diesem Messwert können Sie die aggregierte Ressourcennutzung von Datenbanken optimieren, indem Sie Abfragen mit dem höchsten CPU-Overhead finden und optimieren.
Um die verstrichene Zeit zu sehen, können Sie die Dauer einer Abfrage messen, indem Sie den Befehl \timing im psql-Client ausführen. Sie misst die Zeit, die zwischen dem Empfang der Anfrage und dem Senden einer Antwort durch den PostgreSQL-Server vergeht. Anhand dieses Messwerts können Sie analysieren, warum eine bestimmte Abfrage zu lange dauert, und entscheiden, ob Sie sie optimieren möchten, damit sie schneller ausgeführt wird.
Wenn eine Abfrage von einer einzelnen Aufgabe im Single-Thread-Modus ausgeführt wird, bleiben Dauer und durchschnittliche Ausführungszeit gleich.
Erweiterte Query Insights-Funktionen für AlloyDB aktivieren
Das Dashboard für erweiterte Query Insights-Funktionen für AlloyDB ist in das Standard-Dashboard für Query Insights integriert. Weitere Informationen zum Aktivieren erweiterter Funktionen für Abfragestatistiken finden Sie unter Abfrageleistung mit erweiterten Funktionen für Abfragestatistiken verbessern.
Nächste Schritte
- Übersicht über Query Insights
- Abfrageleistung mit erweiterten Query Insights-Funktionen für AlloyDB verbessern
- AlloyDB-Messwerte
- SQL-Kommentarer-Blog: Einführung von Sqlcommenter: Eine Open-Source-Bibliothek mit ORM-Instrumentierung
- Blogpost mit Anleitung: "Abfrage-Tagging mit Sqlcommenter aktivieren"