本教程介绍了如何使用 Google Cloud 控制台在 AlloyDB for PostgreSQL 中设置和执行向量搜索。其中包含一些示例,用于展示向量搜索功能,这些示例仅用于演示目的。
如需了解如何使用过滤的向量搜索来优化相似度搜索,请参阅 AlloyDB for PostgreSQL 中的过滤向量搜索。
如需了解如何使用 Vertex AI 嵌入执行向量搜索,请参阅开始使用 AlloyDB AI 处理向量嵌入。
目标
- 创建 AlloyDB 集群和主实例。
- 连接到您的数据库并安装所需的扩展程序。
- 创建
product和product inventory表。 - 将数据插入
product和product inventory表,并执行基本向量搜索。 - 在商品表上创建 ScaNN 索引。
- 执行简单向量搜索。
- 执行包含过滤条件和联接的复杂向量搜索。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
您可使用价格计算器根据您的预计使用情况来估算费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
启用结算功能和必需的 API
在 Google Cloud 控制台中,前往集群页面。
启用创建和连接到 AlloyDB for PostgreSQL 所需的 Cloud API。
- 在确认项目步骤中,点击下一步以确认您要更改的项目的名称。
在启用 API 步骤中,点击启用以启用以下内容:
- AlloyDB API
- Compute Engine API
- Service Networking API
- Vertex AI API
创建 AlloyDB 集群和主实例
在 Google Cloud 控制台中,前往集群页面。
点击创建集群。
在集群 ID 中,输入
my-cluster。输入密码。请记下此密码,因为您将在本教程中使用它。
选择区域,例如
us-central1 (Iowa)。选择默认网络。
如果您具有专用访问连接,请继续执行下一步。否则,请点击设置连接,然后按照以下步骤操作:
- 在分配 IP 范围中,点击使用自动分配的 IP 范围。
- 点击继续,然后点击创建连接。
在可用区级可用性中,选择单个可用区。
选择
2 vCPU,16 GB机器类型。在连接中,选择启用公共 IP。
点击创建集群。AlloyDB 可能需要几分钟的时间来创建集群并将其显示在主集群概览页面上。
在集群中的实例中,展开连接窗格。请记下连接 URI,因为您将在本教程中使用它。
连接 URI 的格式为
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary。
向 AlloyDB 服务代理授予 Vertex AI 用户权限
如需使 AlloyDB 能够使用 Vertex AI 文本嵌入模型,您必须为集群和实例所在项目的 AlloyDB 服务代理添加 Vertex AI 用户权限。
如需详细了解如何添加权限,请参阅向 AlloyDB 服务代理授予 Vertex AI 用户权限。
使用网络浏览器连接到数据库
在 Google Cloud 控制台中,前往集群页面。
在资源名称列中,点击集群的名称
my-cluster。在导航窗格中,点击 AlloyDB Studio。
在登录 AlloyDB Studio 页面中,按以下步骤操作:
- 选择
postgres数据库。 - 选择
postgres用户。 - 输入您在创建集群及其主实例中创建的密码。
- 点击身份验证。探索器窗格会显示
postgres数据库中的对象列表。
- 选择
点击 + 新的 SQL 编辑器标签页或 + 新标签页以打开新标签页。
安装必需的扩展程序
运行以下查询以安装 vector 和 alloydb_scann 扩展程序:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
插入商品和商品目录数据,并执行基本向量搜索
运行以下语句,以创建执行以下操作的
product表:- 存储基本商品信息。
- 包含
embedding向量列,用于计算和存储每个商品的商品说明的嵌入向量。
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );如有需要,您可以使用 Logs Explorer 查看日志并排查错误。
运行以下查询,以创建一个
product_inventory表,用于存储有关可用商品目录和相应价格的信息。在本教程中,我们将使用product_inventory和product表运行复杂的向量搜索查询。CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );运行以下查询,以将商品数据插入
product表中:INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');可选:运行以下查询,以验证数据是否已插入
product表中:SELECT * FROM product;运行以下查询,以将商品目录数据插入
product_inventory表中:INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);运行以下向量搜索查询,尝试查找与字词
music类似的商品。这意味着,即使商品说明中未明确提及music一词,结果也会显示与查询相关的商品:SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;查询结果如下所示:
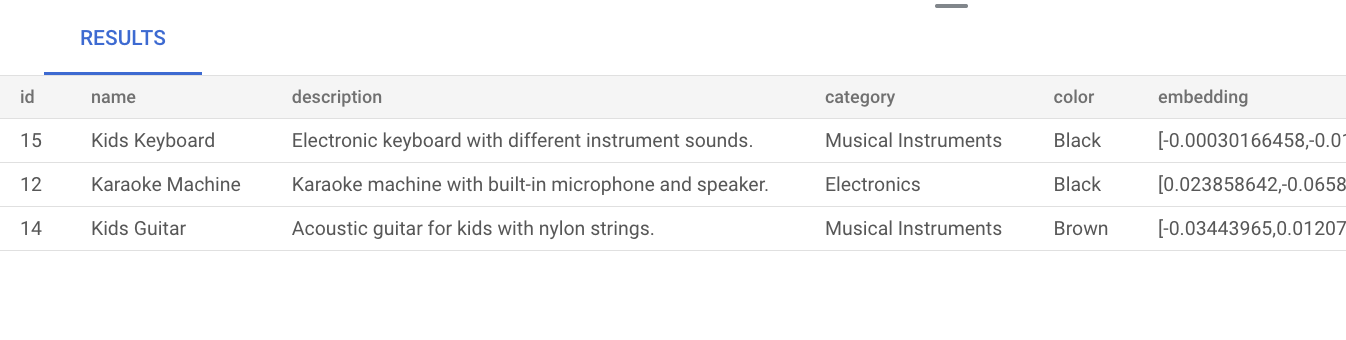
在未创建索引的情况下执行基本向量搜索会使用精确最近邻搜索 (KNN),从而提供高效的召回率。大规模使用 KNN 可能会影响性能。为了获得更好的查询性能,我们建议您使用 ScaNN 索引进行近似最近邻 (ANN) 搜索,该索引可在低延迟的情况下提供高召回率。
在未创建索引的情况下,AlloyDB 默认使用精确最近邻搜索 (KNN)。
如需详细了解如何大规模使用 ScaNN,请参阅开始使用 AlloyDB AI 处理向量嵌入。
在商品表上创建 ScaNN 索引
运行以下查询,以在 product 表上创建 product_index ScaNN 索引:
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (num_leaves=5);
num_leaves 参数表示基于树的索引构建索引时使用的叶节点数量。如需详细了解如何对此参数进行调优,请参阅调优向量查询性能。
执行向量搜索
运行以下向量搜索查询,尝试查找与自然语言查询 music 类似的商品。即使商品说明中未包含 music 字词,结果也会显示与查询相关的商品:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
查询结果如下:

scann.num_leaves_to_search 查询参数用于控制在相似度搜索期间搜索的叶节点数量。num_leaves 和 scann.num_leaves_to_search 参数值有助于在性能和召回率之间取得平衡。
执行使用过滤条件和联接的向量搜索
即使使用 ScaNN 索引,您也可以高效运行过滤的向量搜索查询。运行以下复杂的向量搜索查询,该查询会返回满足查询条件的相关结果,即使具有过滤条件也是如此:
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
加快过滤的向量搜索速度
在数据库中,当列式引擎与高选择性谓词过滤(例如使用 LIKE)相结合时,可以提高向量相似度搜索(尤其是 K 最近邻 [KNN] 搜索)的性能。在本部分中,您将使用 vector 扩展程序和 AlloyDB google_columnar_engine 扩展程序。
性能提升得益于列式引擎在扫描大型数据集和应用过滤条件(例如 LIKE 谓词)方面的内置效率,以及它使用向量支持预过滤行的能力。此功能可减少后续 KNN 向量距离计算所需的数据子集数量,并有助于优化涉及标准过滤和向量搜索的复杂分析查询。
如需比较启用列式引擎前后按 LIKE 谓词过滤的 KNN 向量搜索的执行时间,请按照以下步骤操作:
启用
vector扩展程序以支持向量数据类型和运算。运行以下语句以创建一个示例表 (items),其中包含 ID、文本说明和 512 维向量嵌入列。CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );通过运行以下语句将 100 万行数据插入示例
items表中,来填充数据。-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;衡量不使用列式引擎时的向量相似度搜索基准性能。
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;在 Google Cloud CLI 中运行以下命令,以启用列式引擎和向量支持。如需使用 gcloud CLI,您可以安装并初始化 gcloud CLI。
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=on将
items表添加到列式引擎:SELECT google_columnar_engine_add('items');使用列式引擎衡量向量相似度搜索的性能。重新运行之前运行的查询,以衡量基准性能。
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;如需检查查询是否使用列式引擎运行,请运行以下命令:
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;