Ce document explique comment tester et surveiller les performances de diffusion en ligne des modèles de machine learning (ML) déployés sur AI Platform Prediction. Ce document utilise Locust, un outil Open Source permettant de tester la charge.
Ce document est destiné aux data scientists et aux ingénieurs MLOps qui souhaitent surveiller la charge de travail de service, la latence et l'utilisation des ressources de leurs modèles de ML en production.
Dans le présent document, nous partons du principe que vous avez une certaine expérience de Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring et des notebooks Jupyter.
Le document est accompagné d'un dépôt GitHub contenant le code et un guide de déploiement pour la mise en œuvre du système décrit. Les tâches sont intégrées aux notebooks Jupyter.
Coûts
Les notebooks que vous utilisez dans ce document utilisent les composants facturables suivants de Google Cloud:
- Notebooks Vertex AI Workbench gérés par l'utilisateur
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Présentation de l'architecture
Le schéma suivant illustre l'architecture système permettant de déployer le modèle de ML pour la prédiction en ligne, d'exécuter le test de charge, et de collecter et analyser les métriques pour les performances de diffusion du modèle de ML.
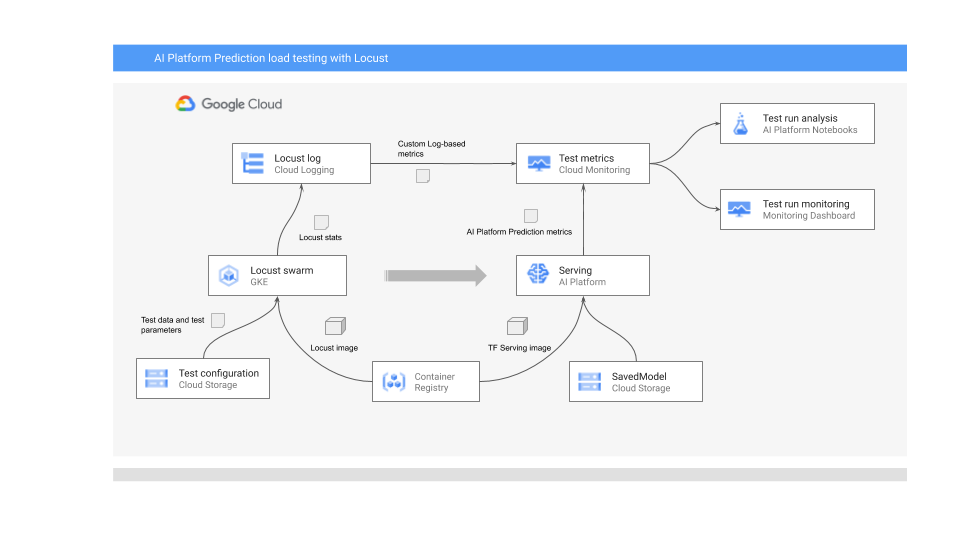
Ce flux est représenté dans le diagramme suivant :
- Le modèle entraîné peut être dans Cloud Storage, par exemple, un modèle SavedModel TensorFlow ou scikit-learn joblib. Il peut également être intégré à un conteneur de diffusion personnalisé dans Container Registry, par exemple, TorchServe pour la diffusion de modèles PyTorch.
- Le modèle est déployé dans AI Platform Prediction en tant qu'API REST. AI Platform Prediction est un service entièrement géré pour la diffusion de modèles. Il est compatible avec différents types de machines, ainsi qu'avec l'autoscaling basé sur l'utilisation des ressources et avec divers accélérateurs GPU.
- Locust est utilisé pour implémenter une tâche de test (comportement de l'utilisateur). Pour ce faire, il appelle le modèle de ML déployé sur AI Platform Prediction et l'exécute à grande échelle sur Google Kubernetes Engine (GKE). Cette opération simule de nombreux appels utilisateur simultanés pour tester le service de prédiction de modèles. Vous pouvez suivre la progression des tests à l'aide de l'interface Web Locust.
- Les journaux Locust testent les statistiques dans Cloud Logging. Les entrées de journal créées par le test Locust sont utilisées pour définir un ensemble de métriques basées sur les journaux dans Cloud Monitoring. Ces métriques complètent les statistiques standards d'AI Platform Prediction.
- Les métriques AI Platform et Locust personnalisées sont disponibles pour une visualisation en temps réel dans un tableau de bord Cloud Monitoring. Une fois le test terminé, les métriques sont également collectées par programmation afin que vous puissiez les analyser et les visualiser dans Notebooks Vertex AI Workbench gérés par l'utilisateur.
Notebooks Jupyter pour ce scénario
Toutes les tâches de préparation et de déploiement du modèle, d'exécution du test Locust, ainsi que de collecte et d'analyse des résultats du test, sont codées dans les notebooks Jupyter suivants. Pour ce faire, vous devez exécuter la séquence de cellules de chaque notebook.
01-prepare-and-deploy.ipynb. Vous exécutez ce notebook pour préparer un fichier SavedModel TensorFlow pour la diffusion et pour déployer le modèle sur AI Platform Prediction.02-perf-testing.ipynb. Vous allez exécuter ce notebook pour créer des métriques basées sur les journaux dans Cloud Monitoring pour le test Locust, et pour déployer le test Locust sur GKE et l'exécuter.03-analyze-results.ipynb. Vous allez exécuter ce notebook pour collecter et analyser les résultats du test de charge Locust à partir des métriques standards d'AI Platform créées par Cloud Monitoring et à partir de métriques Locust personnalisées.
Initialiser l'environnement
Comme décrit dans le fichier README.md du dépôt GitHub associé, vous devez effectuer les étapes suivantes pour préparer l'environnement d'exécution des notebooks:
- Dans votre projet Google Cloud, créez un bucket Cloud Storage, nécessaire pour stocker le modèle entraîné et la configuration de test Locust. Notez le nom que vous utilisez pour le bucket, car vous en aurez besoin plus tard.
- Créez un espace de travail Cloud Monitoring dans votre projet.
- Créez un cluster Google Kubernetes Engine disposant des processeurs nécessaires. Le pool de nœuds doit avoir accès aux API Cloud.
- Créez une instance de notebooks gérés par l'utilisateur Vertex AI Workbench qui utilise TensorFlow 2. Pour ce tutoriel, vous n'avez pas besoin de GPU, car vous n'entraînez pas le modèle. (Les GPU peuvent être utiles dans d'autres scénarios, en particulier pour accélérer l'entraînement de vos modèles.)
Ouvrir JupyterLab
Pour parcourir les tâches du scénario, vous devez ouvrir l'environnement JupyterLab et récupérer les notebooks.
Dans Google Cloud Console, accédez à la page Notebooks.
Dans l'onglet Notebooks gérés par l'utilisateur, cliquez sur Ouvrir Jupyterlab à côté de l'environnement de notebook que vous avez créé.
Cela ouvre l'environnement JupyterLab dans votre navigateur.
Pour lancer un onglet de terminal, cliquez sur l'icône Terminal dans l'onglet Launcher (Lanceur d'applications).
Dans le terminal, clonez le dépôt GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitUne fois la commande terminée, le dossier
mlops-on-gcps'affiche dans le navigateur de fichiers. Dans ce dossier, les notebooks avec lesquels vous travaillez dans ce document s'affichent.
Configurer les paramètres du notebook
Dans cette section, vous allez définir des variables dans le notebook avec des valeurs propres à votre contexte, et préparer l'environnement pour exécuter le code du scénario.
- Accédez au répertoire
model_serving/caip-load-testing: - Pour chacun des trois notebooks, procédez comme suit :
- Ouvrez le notebook.
- Exécutez les cellules sous Configurer les paramètres de l'environnement Google Cloud.
Les sections suivantes mettent en évidence les parties clés du processus, et expliquent les aspects de la conception et du code.
Diffuser le modèle pour la prédiction en ligne
Le modèle de ML utilisé dans ce document utilise le modèle de classification d'images ResNet V2 101 pré-entraîné fourni par TensorFlow Hub. Toutefois, vous pouvez adapter les techniques et les modèles de conception système de ce document à d'autres domaines et à d'autres types de modèles.
Le code de préparation et de diffusion du modèle ResNet 101 se trouve dans le notebook 01-prepare-and-deploy.ipynb. Vous exécutez les cellules du notebook pour effectuer les tâches suivantes :
- Téléchargez et exécutez le modèle ResNet à partir de TensorFlow Hub.
- Créez des signatures de diffusion pour le modèle.
- Exportez le modèle en tant que modèle SavedModel.
- Déployez le modèle SavedModel dans AI Platform Prediction.
- Validez le modèle déployé.
Les sections suivantes de ce document fournissent des informations détaillées sur la préparation du modèle ResNet et son déploiement.
Préparer le modèle ResNet pour le déploiement
Le modèle ResNet de TensorFlow Hub n'a pas de signature de diffusion, car il est optimisé pour la recomposition et les réglages précis. Par conséquent, vous devez créer des signatures de diffusion pour le modèle afin de pouvoir le diffuser pour les prédictions en ligne.
En outre, pour diffuser le modèle, nous vous recommandons d'intégrer la logique d'ingénierie des caractéristiques dans l'interface de diffusion. Cela garantit l'affinité entre le prétraitement et la diffusion du modèle, au lieu de dépendre de l'application cliente pour prétraiter les données au format requis. Vous devez également inclure le post-traitement dans l'interface de diffusion, par exemple la conversion d'un ID de classe en libellé de classe.
Pour rendre le modèle ResNet diffusable, vous devez mettre en œuvre des signatures de diffusion décrivant les méthodes d'inférence du modèle. Par conséquent, le code du notebook ajoute deux signatures :
- Signature par défaut. Cette signature expose la méthode
predictpar défaut du modèle ResNet V2 101 ; la méthode par défaut n'utilise pas de logique de prétraitement ou de post-traitement. - Signature de prétraitement et de post-traitement. Les entrées attendues dans cette interface nécessitent un prétraitement relativement complexe, y compris l'encodage, le scaling et la normalisation de l'image. Par conséquent, le modèle expose également une signature alternative qui intègre la logique de prétraitement et de post-traitement. Cette signature accepte les images brutes non traitées et renvoie la liste des libellés de classe classées et les probabilités de libellé associées.
Les signatures sont créées dans une classe de module personnalisé. La classe est dérivée de la classe de base tf.Module qui encapsule le modèle ResNet. La classe personnalisée étend la classe de base à l'aide d'une méthode qui met en œuvre la logique de prétraitement et de sortie du post-traitement des images. La méthode par défaut du module personnalisé est mappée sur la méthode par défaut du modèle ResNet de base pour maintenir l'interface analogue. Le module personnalisé est exporté en tant que SavedModel, qui inclut le modèle d'origine, la logique de prétraitement et deux signatures de diffusion.
La mise en œuvre de la classe de module personnalisé est illustrée dans l'extrait de code suivant :
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
L'extrait de code suivant montre comment le modèle est exporté en tant que SavedModel avec les signatures de diffusion définies précédemment :
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Déployer le modèle sur AI Platform Prediction
Lorsque le modèle est exporté en tant que SavedModel, les tâches suivantes sont effectuées :
- Le modèle est importé dans Cloud Storage.
- Un objet de modèle est créé dans AI Platform Prediction.
- Une version de modèle est créée pour le SavedModel.
L'extrait de code suivant du notebook montre les commandes qui effectuent ces tâches.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
La commande crée un type de machine n1-standard-8 pour le service de prédiction de modèles et un accélérateur GPU nvidia-tesla-p4.
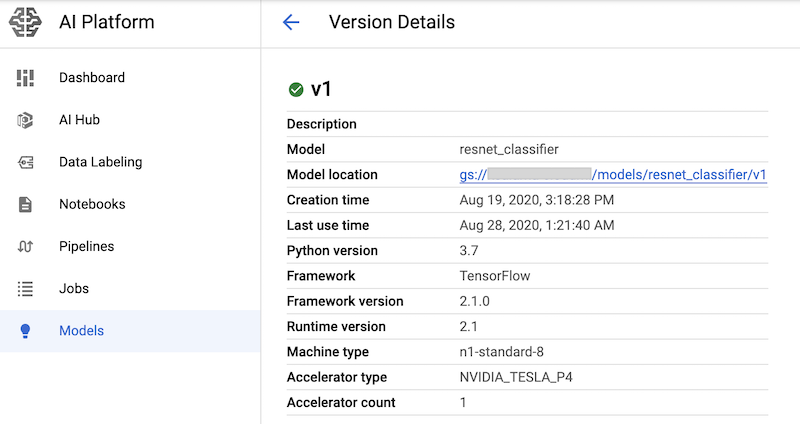
Après avoir exécuté les cellules du notebook contenant ces commandes, vous pouvez vérifier que la version du modèle est déployée en l'affichant sur la page Modèles AI Platform de la console Google Cloud. Le résultat ressemble à ce qui suit :
Créer des métriques Cloud Monitoring
Une fois le modèle configuré pour la diffusion, vous pouvez configurer des métriques qui vous permettent de surveiller les performances de diffusion. Le code de configuration des métriques se trouve dans le notebook 02-perf-testing.ipynb.
La première partie du notebook 02-perf-testing.ipynb crée des métriques personnalisées basées sur les journaux dans Cloud Monitoring, à l'aide du SDK Cloud Logging pour Python.
Les métriques sont basées sur les entrées de journal générées par la tâche Locust.
La méthode log_stats écrit les entrées de journal dans un journal Cloud Logging nommé locust.
Chaque entrée de journal inclut un ensemble de paires clé-valeur au format JSON, comme indiqué dans le tableau suivant. Les métriques sont basées sur le sous-ensemble de clés de l'entrée de journal.
| Clé | Description de la valeur | Utilisation |
|---|---|---|
test_id
|
ID d'un test | Filtrage des attributs |
model |
Nom du modèle AI Platform Prediction | |
model_version |
Version du modèle AI Platform Prediction | |
latency
|
Temps de réponse du 95e centile, calculé sur une fenêtre glissante de 10 secondes | Valeurs de la métrique |
num_requests |
Nombre total de requêtes depuis le début du test | |
num_failures |
Nombre total d'échecs depuis le début du test | |
user_count |
Nombre d'utilisateurs simulés | |
rps |
Requêtes par seconde |
L'extrait de code suivant montre la fonction create_locust_metric du notebook qui crée une métrique personnalisée basée sur les journaux.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
L'extrait de code suivant montre comment la méthode create_locust_metric est appelée dans le notebook pour créer les quatre métriques Locust personnalisées qui sont affichées dans le tableau précédent.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
Le notebook crée un tableau de bord Cloud Monitoring personnalisé appelé AI Platform Prediction et Locust. Le tableau de bord combine les métriques AI Platform Prediction standards et les métriques personnalisées créées à partir des journaux Locust.
Pour en savoir plus, consultez la documentation de l'API Cloud Logging.
Ce tableau de bord et ses graphiques peuvent être créés manuellement.
Toutefois, le notebook fournit un moyen automatisé de le créer à l'aide du modèle JSON monitoring-template.json. Le code utilise la classe DashboardsServiceClient pour charger le modèle JSON et créer le tableau de bord dans Cloud Monitoring, comme indiqué dans l'extrait de code suivant:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Une fois le tableau de bord créé, il apparaît dans la liste des tableaux de bord Cloud Monitoring de la console Google Cloud :
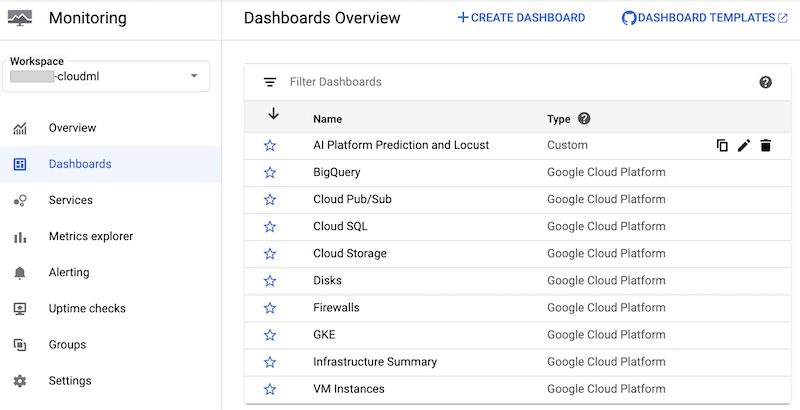
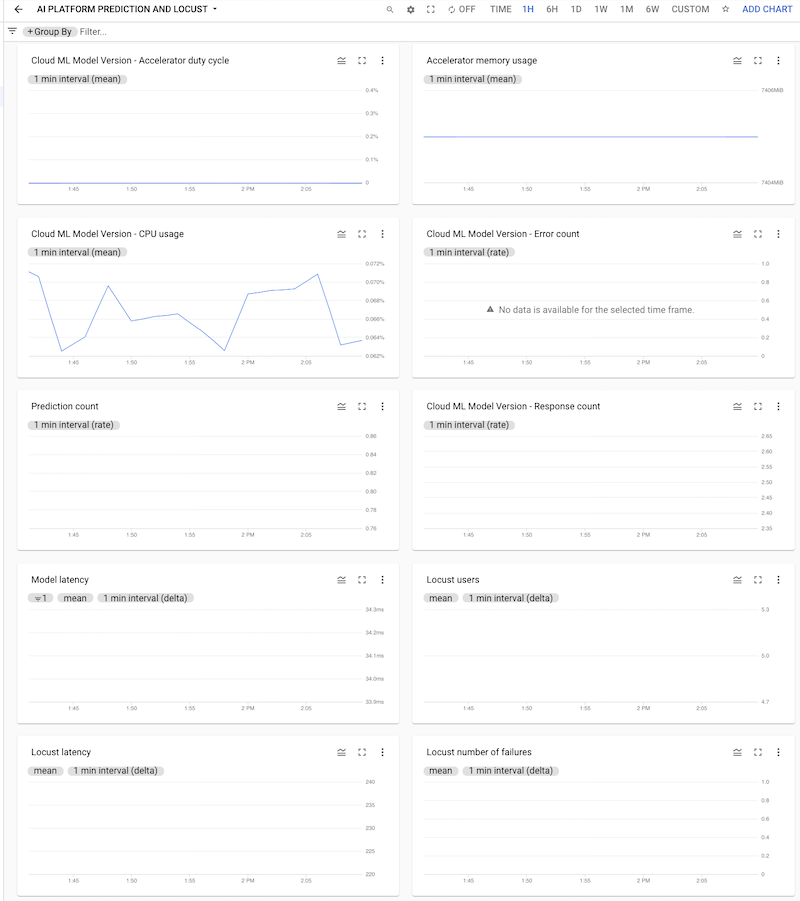
Vous pouvez cliquer sur le tableau de bord pour l'ouvrir et afficher les graphiques. Chaque graphique affiche une métrique à partir d'AI Platform Prediction ou des journaux Locust, comme illustré dans les captures d'écran suivantes.
Déployer le test Locust sur le cluster GKE
Avant de déployer le système Locust sur GKE, vous devez créer l'image de conteneur Docker contenant la logique de test intégrée au fichier task.py. L'image est dérivée de l'image baseline locust.io et est utilisée pour le maître et les pods de nœuds de calcul Locust.
La logique de création et de déploiement se trouve dans le notebook sous 3. Déployer Locust sur un cluster GKE. L'image est créée à l'aide du code suivant :
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
Le processus de déploiement décrit dans le notebook a été défini à l'aide de Kustomize. Les fichiers manifestes de déploiement Kustomize de Locust définissent les fichiers suivants qui définissent les composants:
locust-master. Ce fichier définit un déploiement qui héberge une interface Web dans laquelle vous démarrez le test et consultez les statistiques en direct.locust-worker. Ce fichier définit un déploiement qui exécute une tâche pour tester votre service de prédiction de modèle de ML. En règle générale, plusieurs nœuds de calcul sont créés pour simuler l'effet de plusieurs utilisateurs simultanés effectuant des appels vers votre API de service de prédiction.locust-worker-service. Ce fichier définit un service qui accède à l'interface Web danslocust-mastervia un équilibreur de charge HTTP.
Vous devez mettre à jour le fichier manifeste par défaut avant de déployer le cluster. Le fichier manifeste par défaut se compose des fichiers kustomization.yaml et patch.yaml. Vous devez apporter des modifications dans les deux fichiers.
Dans le fichier kustomization.yaml, procédez comme suit :
- Définissez le nom de l'image personnalisée Locust. Définissez le champ
newNamede la sectionimagessur le nom de l'image personnalisée que vous avez créée précédemment. - Vous pouvez également définir le nombre de pods de nœuds de calcul. La configuration par défaut déploie 32 pods de nœuds de calcul. Pour modifier le nombre, modifiez le champ
countdans la sectionreplicas. Assurez-vous que votre cluster GKE dispose d'un nombre suffisant de processeurs pour les nœuds de calcul Locust. - Définissez le bucket Cloud Storage pour les fichiers de configuration de test et de charge utile. Dans la section
configMapGenerator, assurez-vous que les éléments suivants sont définis :LOCUST_TEST_BUCKETDéfinissez ce paramètre sur le nom du bucket Cloud Storage que vous avez créé précédemment.LOCUST_TEST_CONFIGSaisissez le nom du fichier de configuration de test. Dans le fichier YAML, ce paramètre est défini surtest-config.json, mais vous pouvez le modifier si vous souhaitez utiliser un autre nom.LOCUST_TEST_PAYLOADDéfinissez ce paramètre sur le nom du fichier de charge utile de test. Dans le fichier YAML, ce paramètre est défini surtest-payload.json, mais vous pouvez le modifier si vous souhaitez utiliser un autre nom.
Dans le fichier patch.yaml, procédez comme suit :
- Vous pouvez également modifier le pool de nœuds qui héberge le maître et les nœuds de calcul Locust. Si vous déployez la charge de travail Locust sur un pool de nœuds autre que
default-pool, recherchez la sectionmatchExpressions, puis, sousvalues, mettez à jour le nom du pool de nœuds sur lequel la charge de travail Locust sera déployée.
Une fois ces modifications effectuées, vous pouvez créer vos personnalisations dans les fichiers manifestes Kustomize et appliquer le déploiement Locust (locust-master, locust-worker etlocust-master-service) sur le cluster GKE. La commande suivante dans le notebook effectue ces tâches :
!kustomize build locust/manifests | kubectl apply -f -
Vous pouvez vérifier les charges de travail déployées dans la console Google Cloud. Le résultat ressemble à ce qui suit :
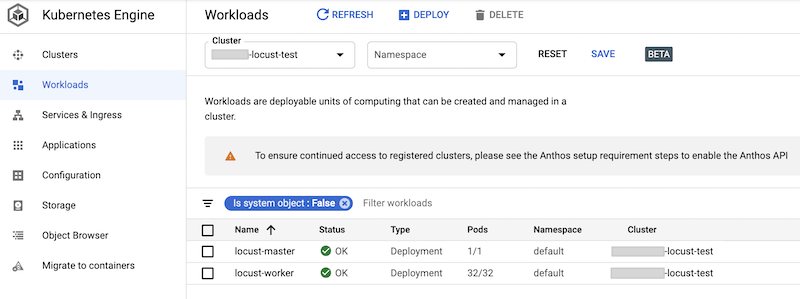
Mettre en œuvre le test de charge Locust
La tâche de test pour Locust consiste à appeler le modèle déployé sur AI Platform Prediction.
Cette tâche est implémentée dans la classe AIPPClient du module task.py situé dans le dossier /locust/locust-image/. L'extrait de code suivant montre la mise en œuvre de la classe.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
La classe AIPPUser du fichier task.py hérite de la classe locust.User pour simuler le comportement des utilisateurs pour l'appel du modèle AI Platform Prediction. Ce comportement est mis en œuvre dans la méthode predict_task. La méthode on_start de la classe AIPPUser télécharge les fichiers suivants à partir d'un bucket Cloud Storage spécifié dans la variable LOCUST_TEST_BUCKET du fichier task.py :
test-config.jsonCe fichier JSON inclut les configurations suivantes pour le test :test_id,project_id,modeletversion.test-payload.jsonCe fichier JSON inclut, avec la signature cible, les instances de données au format attendu par AI Platform Prediction.
Le code permettant de préparer les données de test et la configuration de test est inclus dans le notebook 02-perf-testing.ipynb sous 4. Configurer un test Locust.
Les configurations de test et les instances de données sont utilisées comme paramètres pour la méthode predict dans la classe AIPPClient afin de tester le modèle cible à l'aide des données de test requises. La classe AIPPUser
simule un temps d'attente de 1 à 2 secondes entre les appels d'un seul utilisateur.
Exécuter le test Locust
Après avoir exécuté les cellules de notebook pour déployer la charge de travail Locust sur le cluster GKE, créé, puis importé les fichiers test-config.json et test-payload.json dans Cloud Storage, vous pouvez démarrer, arrêter et configurer un nouveau test de charge Locust à l'aide de son interface Web.
Le code du notebook récupère l'URL de l'équilibreur de charge externe qui expose l'interface Web à l'aide de la commande suivante :
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
Pour effectuer le test, procédez comme suit :
- Dans un navigateur, saisissez l'URL que vous avez récupérée.
Pour simuler votre charge de travail de test à l'aide de configurations différentes, saisissez des valeurs dans l'interface Locust, semblable à ce qui suit :
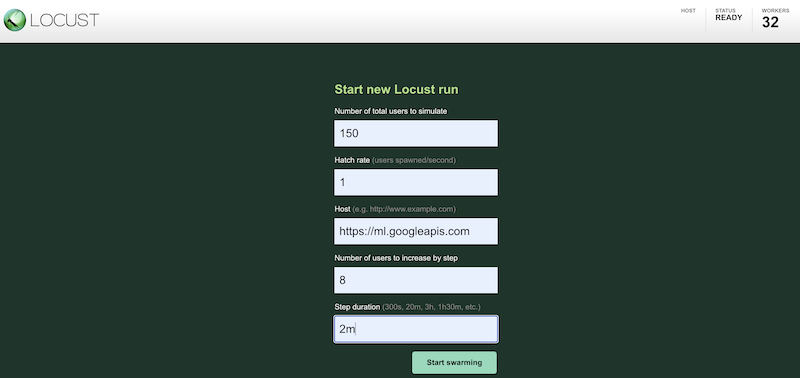
La capture d'écran précédente montre les valeurs de configuration suivantes :
- Nombre total d'utilisateurs à simuler :
150 - Taux d'apparition:
1 - Hôte :
http://ml.googleapis.com - Nombre d'utilisateurs à augmenter par étape :
10 - Durée de l'étape :
2m
- Nombre total d'utilisateurs à simuler :
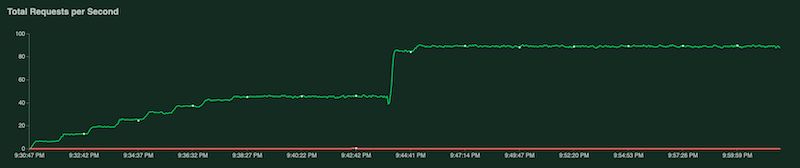
Lors de l'exécution du test, vous pouvez le surveiller en examinant les graphiques Locust. Les captures d'écran suivantes montrent comment les valeurs s'affichent.
Un graphique indique le nombre total de requêtes par seconde :
Un autre graphique indique le temps de réponse en millisecondes :
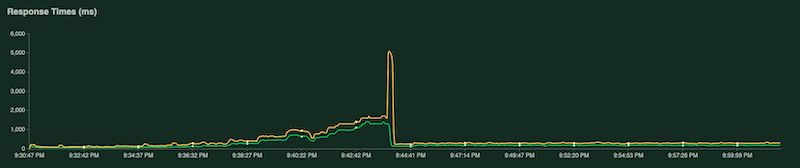
Comme indiqué précédemment, ces statistiques sont également consignées dans Cloud Logging afin que vous puissiez créer des métriques personnalisées basées sur les journaux Cloud Monitoring.
Collecter et analyser les résultats du test
La tâche suivante consiste à collecter et analyser les métriques Cloud Monitoring calculées à partir des journaux de résultats sous la forme d'un objet DataFrame pandas afin de pouvoir visualiser et analyser les résultats dans le notebook. Le code permettant d'effectuer cette tâche se trouve dans le notebook 03-analyze-results.ipynb.
Le code utilise le SDK Python Cloud Monitoring Query pour filtrer et récupérer les valeurs de métrique, en fonction des valeurs transmises dans les paramètres project_id, test_id, start_time, end_time, model, model_version et log_name.
L'extrait de code suivant montre les méthodes de récupération des métriques AI Platform Prediction et des métriques personnalisées basées sur les journaux Locust.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
Les données de métriques sont récupérées en tant qu'objet DataFrame pandas pour chaque métrique. Les trames de données individuelles sont ensuite fusionnées en un seul objet DataFrame. L'objet DataFrame final avec les résultats fusionnés ressemble à ce qui suit dans votre notebook :
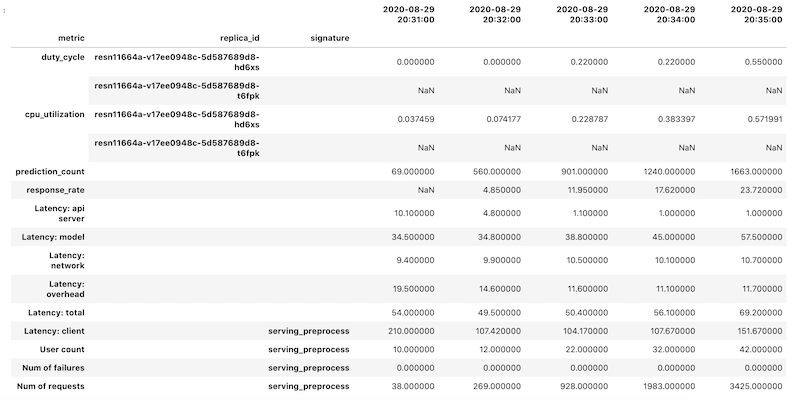
L'objet DataFrame récupéré utilise l'indexation hiérarchique des noms de colonnes. En effet, certaines métriques contiennent plusieurs séries temporelles.
Par exemple, la métrique GPU duty_cycle inclut une série temporelle de mesures pour chaque GPU utilisé dans le déploiement, indiqué par replica_id. Le niveau supérieur de l'index de colonne indique le nom d'une métrique individuelle. Le deuxième niveau correspond à un ID d'instance dupliquée. Le troisième niveau correspond à la signature d'un modèle. Toutes les métriques sont alignées sur la même chronologie.
Les graphiques suivants illustrent l'utilisation du GPU, l'utilisation du processeur et la latence telle qu'elles apparaissent dans le notebook.
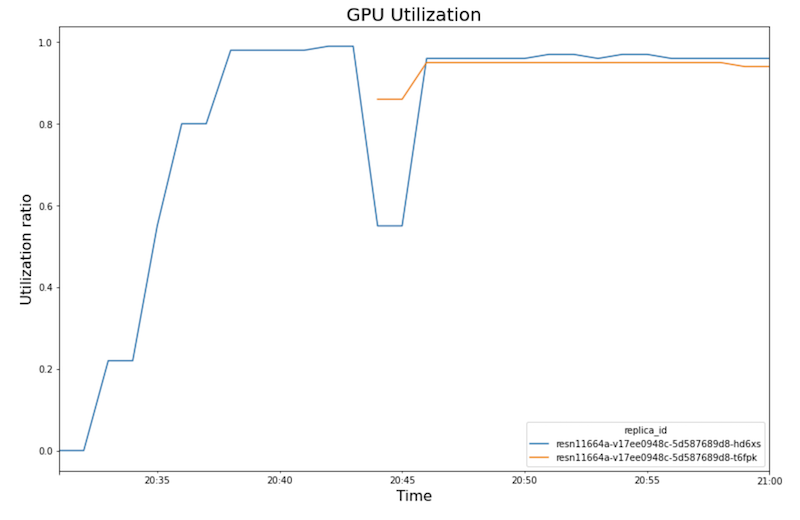
Utilisation GPU :
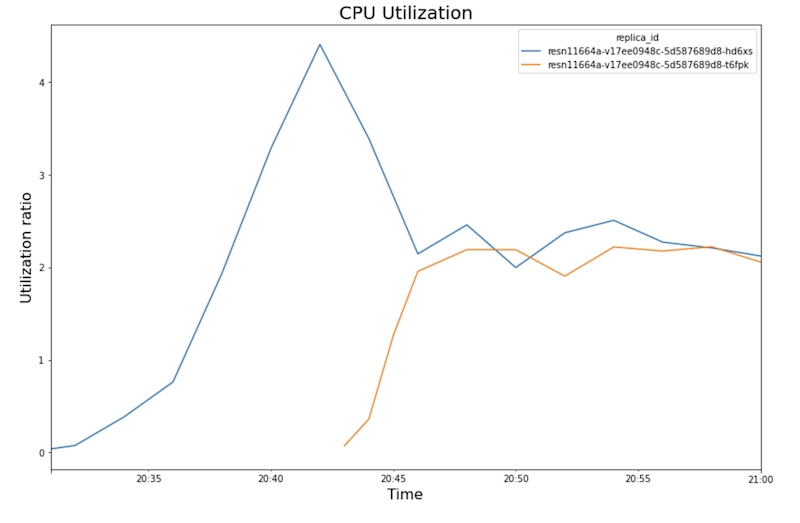
Utilisation du processeur :
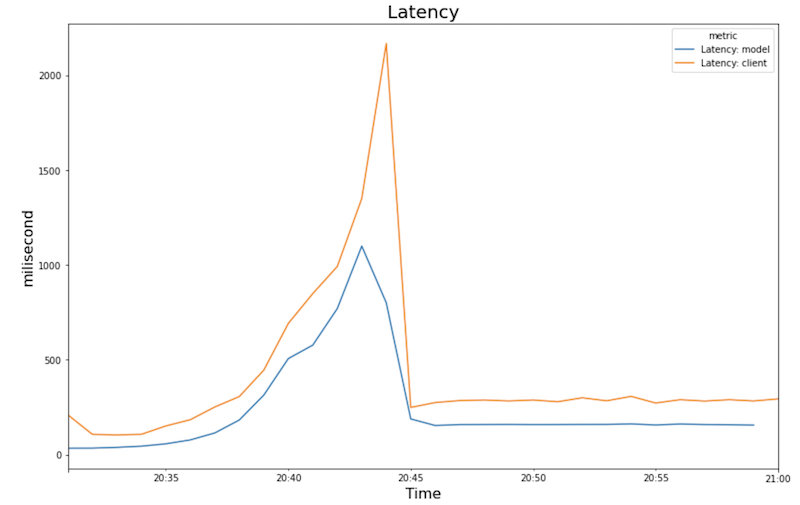
Latence :
Les graphiques montrent le comportement et la séquence suivants :
- À mesure que la charge de travail (nombre d'utilisateurs) augmente, l'utilisation du processeur et GPU augmente. Par conséquent, la latence augmente et la différence entre la latence du modèle et la latence totale augmente jusqu'à atteindre un pic autour de 20h40.
- À 20h40, l'utilisation GPU atteint 100 %, tandis que le graphique du processeur indique que l'utilisation atteint 4 processeurs. L'exemple utilise une machine
n1-standard-8dans ce test, dotée de huit processeurs. Ainsi, l'utilisation du processeur atteint 50 %. - À ce stade, l'autoscaling ajoute de la capacité : un nouveau nœud de diffusion est ajouté avec une instance dupliquée GPU supplémentaire. La première utilisation de l'instance dupliquée GPU diminue, et l'utilisation de la deuxième est plus importante.
- La latence diminue à mesure que la nouvelle instance dupliquée commence à diffuser des prédictions, convergeant à environ 200 millisecondes.
- L'utilisation du processeur converge à environ 250 % pour chaque instance dupliquée, c'est-à-dire que 2,5 processeurs sont utilisés sur huit. Cette valeur indique que vous pouvez utiliser une machine
n1-standard-4au lieu d'une machinen1-standard-8.
Nettoyer
Pour éviter que les ressources utilisées dans ce document soient facturées sur votre Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Si vous souhaitez conserver le projet Google Cloud, mais supprimer les ressources que vous avez créées, supprimez le cluster Google Kubernetes Engine et le modèle AI Platform déployé.
Étape suivante
- Apprenez-en davantage sur les MLOps et les pipelines de livraison continue et d'automatisation dans le machine learning.
- Apprenez-en davantage sur l'architecture des MLOps avec TFX, Kubeflow Pipelines et Cloud Build.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.