CCAI 텍스트 변환을 사용하면 스트리밍 오디오 데이터를 실시간으로 텍스트로 변환할 수 있습니다. Agent Assist는 텍스트를 기반으로 추천을 제공하므로 오디오 데이터를 사용하려면 먼저 변환해야 합니다. 또한 Conversational Insights에서 스크립트가 작성된 스트리밍 오디오를 사용하여 상담사 대화에 관한 실시간 데이터 (예: 주제 모델링)를 수집할 수 있습니다.
CCAI에서 사용할 스트리밍 오디오를 트랜스크립션하는 방법에는 두 가지가 있습니다. SIPREC 기능을 사용하거나 오디오 데이터를 페이로드로 사용하여 gRPC 호출을 하는 것입니다. 이 페이지에서는 gRPC 호출을 사용하여 스트리밍 오디오 데이터를 텍스트로 변환하는 프로세스를 설명합니다.
CCAI 텍스트 변환은 Speech-to-Text 스트리밍 음성 인식을 사용하여 작동합니다. Speech-to-Text는 표준 및 고급 등 여러 인식 모델을 제공합니다. CCAI 스크립트 작성은 전화 통신 모델과 함께 사용되는 경우에만 GA 수준에서 지원됩니다.
기본 요건
- Google Cloud에서 프로젝트를 만듭니다.
- Dialogflow API를 사용 설정합니다.
- 계정에서 Speech-to-Text 향상된 모델에 액세스할 수 있는지 Google 담당자에게 문의하세요.
대화 프로필 만들기
대화 프로필을 만들려면 Agent Assist 콘솔을 사용하거나 ConversationProfile 리소스에서 create 메서드를 직접 호출합니다.
CCAI 트랜스크립션의 경우 대화에서 오디오 데이터를 전송할 때 ConversationProfile.stt_config를 기본 InputAudioConfig로 구성하는 것이 좋습니다.
![]()
대화 런타임에 텍스트 변환 가져오기
대화 런타임에 스크립트를 가져오려면 대화의 참가자를 만들고 각 참가자의 오디오 데이터를 전송해야 합니다.
참여자 만들기
참여자에는 세 가지 유형이 있습니다.
역할에 대한 자세한 내용은 참조 문서를 참고하세요. participant에서 create 메서드를 호출하고 role를 지정합니다. END_USER 또는 HUMAN_AGENT 참여자만 StreamingAnalyzeContent를 호출할 수 있으며, 이는 스크립트를 가져오는 데 필요합니다.
오디오 데이터를 전송하고 스크립트 가져오기
StreamingAnalyzeContent를 사용하여 다음 매개변수로 참여자의 오디오를 Google에 전송하고 텍스트 변환을 받을 수 있습니다.
스트림의 첫 번째 요청은
InputAudioConfig이어야 합니다. (여기에서 구성된 필드는ConversationProfile.stt_config의 해당 설정을 재정의합니다.) 두 번째 요청이 있을 때까지 오디오 입력을 전송하지 마세요.audioEncoding은AUDIO_ENCODING_LINEAR_16또는AUDIO_ENCODING_MULAW로 설정해야 합니다.model: 오디오를 텍스트로 변환하는 데 사용할 Speech-to-Text 모델입니다. 이 필드를telephony로 설정합니다. 변형은 스크립트 품질에 영향을 미치지 않으므로 음성 모델 변형을 지정하지 않거나 사용 가능한 최적의 모델 사용을 선택하면 됩니다.singleUtterance은 최상의 스크립트 품질을 위해false로 설정해야 합니다.singleUtterance이false인 경우END_OF_SINGLE_UTTERANCE을 기대해서는 안 되지만StreamingAnalyzeContentResponse.recognition_result내에서isFinal==true에 의존하여 스트림을 절반 닫을 수 있습니다.- 선택적 추가 매개변수: 다음 매개변수는 선택사항입니다. 이러한 매개변수에 액세스하려면 Google 담당자에게 문의하세요.
languageCode: 오디오의language_code입니다. 기본값은en-US입니다.alternativeLanguageCodes: 미리보기 기능입니다. 오디오에서 감지될 수 있는 추가 언어입니다. Agent Assist는language_code필드를 사용하여 오디오 시작 시 언어를 자동으로 감지하고 이후 모든 대화 차례에서 기본값으로 설정합니다.alternativeLanguageCodes필드를 사용하면 Agent Assist에서 선택할 수 있는 옵션을 더 많이 지정할 수 있습니다.phraseSets: Speech-to-Text 모델 적응phraseSet리소스 이름입니다. CCAI Transcription에서 모델 적응을 사용하려면 먼저 Speech-to-Text API를 사용하여phraseSet를 만들고 여기에 리소스 이름을 지정해야 합니다.
오디오 페이로드와 함께 두 번째 요청을 보낸 후 스트림에서
StreamingAnalyzeContentResponses를 수신하기 시작해야 합니다.StreamingAnalyzeContentResponse.recognition_result에서is_final이true으로 설정된 것을 확인하면 스트림을 절반만 닫거나 (또는 Python과 같은 일부 언어에서는 전송을 중지) 할 수 있습니다.- 스트림을 절반 닫으면 서버에서 최종 스크립트가 포함된 응답과 Dialogflow 제안 또는 Agent Assist 제안을 다시 전송합니다.
최종 스크립트는 다음 위치에서 확인할 수 있습니다.
StreamingAnalyzeContentResponse.message.content개- Pub/Sub 알림을 사용 설정하면 Pub/Sub에서 스크립트를 확인할 수도 있습니다.
이전 스트림이 닫힌 후 새 스트림을 시작합니다.
- 오디오 재전송:
is_final=true이 포함된 대답의 마지막speech_end_offset이후에 생성된 오디오 데이터는 최상의 스크립트 품질을 위해 새 스트림 시작 시간으로StreamingAnalyzeContent에 다시 전송해야 합니다.
- 오디오 재전송:
다음은 스트림의 작동 방식을 보여주는 다이어그램입니다.
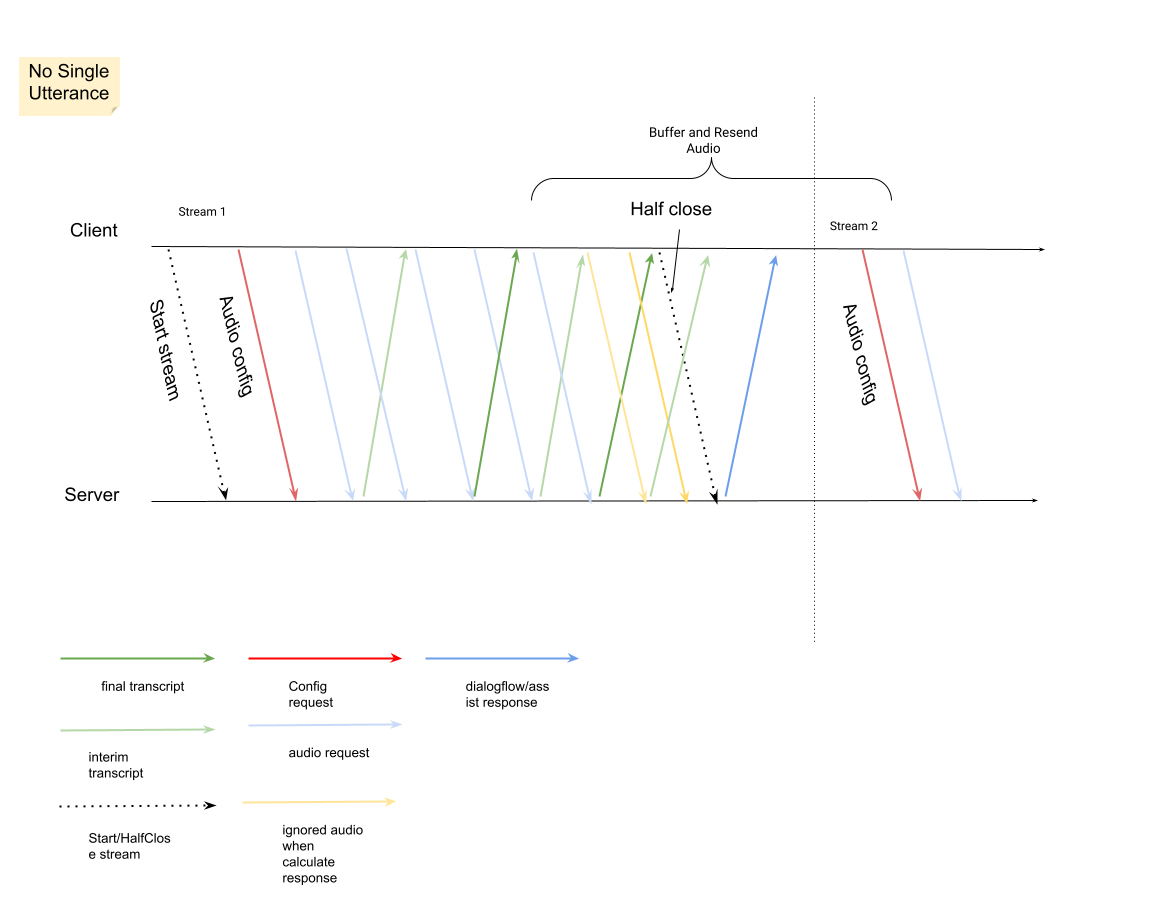
스트리밍 인식 요청 코드 샘플
다음 코드 샘플은 스트리밍 텍스트 변환 요청을 보내는 방법을 보여줍니다.
Python
Agent Assist에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.