オブジェクト検出モデルは、動画内の 500 種類を超えるオブジェクトを識別して特定できます。このモデルは、動画ストリームを入力として受け取り、検出結果を含むプロトコル バッファを BigQuery に出力します。モデルは 1 FPS で実行されます。オブジェクト検出モデルを使用するアプリを作成する場合は、予測出力を表示するために、モデル出力を BigQuery コネクタに転送する必要があります。
オブジェクト検出モデル アプリの仕様
次の手順で、Google Cloud コンソールでオブジェクト検出モデルを作成します。
コンソール
コンソールでアプリを作成する Google Cloud
オブジェクト検出アプリを作成するには、アプリケーションを作成するの手順に沿って操作します。
オブジェクト検出モデルを追加する
- モデルノードを追加するときに、事前トレーニング済みモデルのリストから [Object detector] を選択します。
BigQuery コネクタを追加する
出力を使用するには、アプリを BigQuery コネクタに接続します。
BigQuery コネクタの使用方法については、BigQuery にデータを接続して保存するをご覧ください。BigQuery の料金については、BigQuery の料金ページをご覧ください。
BigQuery で出力結果を表示する
モデルが BigQuery にデータを出力したら、BigQuery ダッシュボードで出力アノテーションを表示します。
BigQuery パスを指定しなかった場合、Vertex AI Vision の Studio ページでシステムによって作成されたパスを確認できます。
Google Cloud コンソールで、[BigQuery] ページを開きます。
ターゲット プロジェクト、データセット名、アプリケーション名の横にある [展開] を選択します。
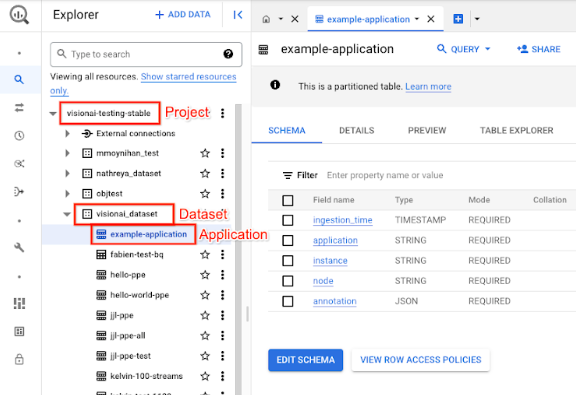
テーブルの詳細ビューで [プレビュー] をクリックします。結果は [アノテーション] 列に表示されます。出力形式の詳細については、モデル出力をご覧ください。
アプリは結果を時系列で保存します。最も古い結果がテーブルの先頭に、最新の結果がテーブルの末尾に追加されます。最新の結果を確認するには、ページ番号をクリックして最後のテーブル ページに移動します。
モデル出力
モデルは、各動画フレームの境界ボックス、オブジェクトのラベル、信頼度スコアを出力します。出力にはタイムスタンプも含まれます。出力ストリームのレートのレートは 1 秒あたり 1 フレームです。
次のプロトコル バッファの出力例で、次の点に注意してください。
- タイムスタンプ - タイムスタンプは、この推論結果の時間に対応しています。
- 検出されたボックス - ボックス ID、境界ボックス情報、信頼スコア、オブジェクト予測を含むメインの検出結果。
アノテーション出力の JSON オブジェクトの例
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
プロトコル バッファの定義
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
ベスト プラクティスと制限事項
オブジェクト検出機能を使用する際に最良の結果を得るには、データの取得とモデルの使用時に次の点を考慮してください。
ソースデータに関する推奨事項
推奨: 画像内のオブジェクトがはっきりと写っており、他のオブジェクトに覆われていたり、他のオブジェクトによって大きく隠れたりしていないことを確認します。
オブジェクト検出で正しく処理できる画像データのサンプル:

|
この画像データをモデルに送信すると、次のオブジェクト検出情報が返されます*。
* 次の画像のアノテーションは説明のみを目的としています。境界ボックス、ラベル、信頼スコアは手動で描画され、モデルやコンソール ツールによって追加されることはありません。 Google Cloud

推奨されない: フレーム内でキー オブジェクト アイテムが小さすぎる画像データは避けてください。
オブジェクト検出で正しく処理できない画像データのサンプル:

|
推奨されない: 主なオブジェクト アイテムが他のオブジェクトで部分的または完全に覆われている画像データは使用しないでください。
オブジェクト検出で正しく処理できない画像データのサンプル:

|
制限事項
- 動画の解像度: 推奨される入力動画の最大解像度は 1,920 x 1,080、推奨される最小解像度は 160 x 120 です。
- 照明: モデルのパフォーマンスは照明条件の影響を受けます。明るすぎる場所や暗すぎる場所では、検出品質が低下する可能性があります。
- オブジェクトのサイズ: オブジェクト検出には、検出可能な最小オブジェクト サイズがあります。ターゲット オブジェクトが動画データ内で十分な大きさで表示されていることを確認します。