
Das Objektdetektormodell kann mehr als 500 Objekttypen in einem Video erkennen und lokalisieren. Das Modell nimmt einen Videostream als Eingabe entgegen und gibt einen Protokollpuffer mit den Erkennungsergebnissen an BigQuery aus. Das Modell wird mit einer Framerate von 1 fps ausgeführt. Wenn Sie eine App erstellen, in der das Objekterkennungsmodell verwendet wird, müssen Sie die Modellausgabe an einen BigQuery-Connector weiterleiten, um die Vorhersageausgabe aufzurufen.
App-Spezifikationen für Objekterkennungsmodelle
Folgen Sie der folgenden Anleitung, um ein Objekterkennungsmodell in derGoogle Cloud -Konsole zu erstellen.
Console
App in der Google Cloud Console erstellen
Folgen Sie der Anleitung unter Anwendung erstellen, um eine Objekterkennungs-App zu erstellen.
Objekterkennungsmodell hinzufügen
- Wenn Sie Modellknoten hinzufügen, wählen Sie in der Liste der vortrainierten Modelle Objektdetektor aus.
BigQuery-Connector hinzufügen
Wenn Sie die Ausgabe verwenden möchten, stellen Sie eine Verbindung zwischen der App und einem BigQuery-Connector her.
Informationen zur Verwendung des BigQuery-Connectors finden Sie unter Verbinden und Daten in BigQuery speichern. Informationen zu den Preisen für BigQuery finden Sie auf der Seite BigQuery-Preise.
Ausgabeergebnisse in BigQuery ansehen
Nachdem das Modell Daten nach BigQuery exportiert hat, können Sie die Anmerkungen zur Ausgabe im BigQuery-Dashboard aufrufen.
Wenn Sie keinen BigQuery-Pfad angegeben haben, können Sie den vom System erstellten Pfad auf der Seite Vertex AI Vision Studio aufrufen.
Öffnen Sie in der Google Cloud Console die Seite „BigQuery“.
Wählen Sie neben dem Zielprojekt, dem Dataset-Namen und dem Anwendungsnamen die Option Maximieren aus.
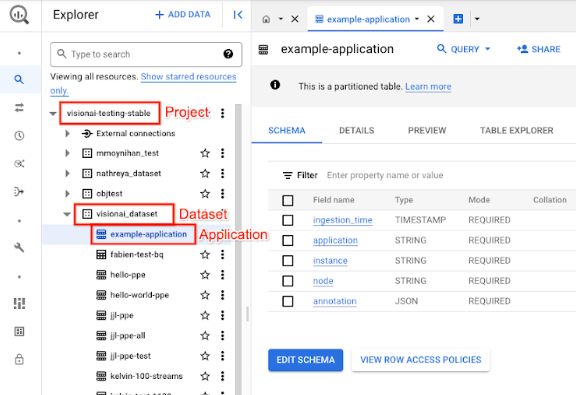
Klicken Sie in der Detailansicht der Tabelle auf Vorschau. Die Ergebnisse finden Sie in der Spalte annotation. Eine Beschreibung des Ausgabeformats finden Sie unter Modellausgabe.
Die Anwendung speichert die Ergebnisse in chronologischer Reihenfolge. Die ältesten Ergebnisse stehen am Anfang der Tabelle, die neuesten am Ende. Wenn Sie die neuesten Ergebnisse sehen möchten, klicken Sie auf die Seitenzahl, um die letzte Tabellenseite aufzurufen.
Modellausgabe
Das Modell gibt für jeden Videoframe Begrenzungsrahmen, ihre Objektlabels und Konfidenzwerte aus. Die Ausgabe enthält auch einen Zeitstempel. Die Rate des Ausgabestreams beträgt ein Frame pro Sekunde.
Beachten Sie im folgenden Beispiel für die Ausgabe des Protokoll-Buffers Folgendes:
- Zeitstempel: Der Zeitstempel entspricht der Zeit für dieses Inferenzergebnis.
- Identifizierte Boxen: Das Haupterkennungsergebnis, das die Box-Identität, Informationen zum Begrenzungsrahmen, den Konfidenzwert und die Objektvorhersage enthält.
Beispiel für ein JSON-Objekt für die Annotationsausgabe
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
Definition des Protokollpuffers
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
Best Practices und Einschränkungen
Damit Sie mit dem Objekterkennungstool die besten Ergebnisse erzielen, sollten Sie beim Erheben von Daten und Verwenden des Modells Folgendes beachten.
Empfehlungen für Quelldaten
Empfohlen:Achten Sie darauf, dass die Objekte auf dem Bild gut zu sehen sind und nicht von anderen Objekten verdeckt oder weitgehend verdeckt werden.
Beispielbilddaten, die der Objekterkennungsalgorithmus korrekt verarbeiten kann:

|
Wenn Sie diese Bilddaten an das Modell senden, werden die folgenden Informationen zur Objekterkennung zurückgegeben*:
* Die Anmerkungen in der folgenden Abbildung dienen nur zur Veranschaulichung. Die Begrenzungsboxen, Labels und Konfidenzwerte werden manuell gezeichnet und nicht vom Modell oder einem Google Cloud Console-Tool hinzugefügt.

Nicht empfohlen:Verwenden Sie keine Bilddaten, in denen die wichtigsten Objektelemente im Bild zu klein sind.
Beispielbilddaten, die vom Objekterkennungssystem nicht richtig verarbeitet werden können:

|
Nicht empfohlen:Verwenden Sie keine Bilddaten, in denen die wichtigsten Objektelemente teilweise oder vollständig von anderen Objekten verdeckt sind.
Beispielbilddaten, die vom Objekterkennungssystem nicht richtig verarbeitet werden können:

|
Beschränkungen
- Videoauflösung: Die empfohlene maximale Videoauflösung beträgt 1920 × 1080 und die empfohlene Mindestauflösung 160 × 120.
- Beleuchtung: Die Modellleistung ist von den Lichtverhältnissen abhängig. Extreme Helligkeit oder Dunkelheit kann zu einer geringeren Erkennungsqualität führen.
- Objektgröße: Der Objektdetektor hat eine minimale Größe, die erkannt werden kann. Achten Sie darauf, dass die Zielobjekte in Ihren Videodaten ausreichend groß und sichtbar sind.