Questa pagina descrive cos'è Vertex AI RAG Engine e come funziona.
| Descrizione | Console |
|---|---|
| Per scoprire come utilizzare l'SDK Vertex AI per eseguire le attività di Vertex AI RAG Engine, consulta la guida rapida RAG per Python. |
Panoramica
Vertex AI RAG Engine, un componente della piattaforma Vertex AI, facilita la generazione RAG (Retrieval-Augmented Generation). Vertex AI RAG Engine è anche un framework di dati per lo sviluppo di applicazioni basate su modelli linguistici di grandi dimensioni (LLM) con aggiunta del contesto. L'aggiunta del contesto si verifica quando un modello LLM viene applicato ai dati. È così che viene implementata la generazione RAG (Retrieval-Augmented Generation).
Un problema comune con i modelli linguistici di grandi dimensioni è che non comprendono le conoscenze private, ovvero i dati della tua organizzazione. Con Vertex AI RAG Engine, puoi arricchire il contesto del modello LLM con informazioni private aggiuntive, perché il modello può ridurre le allucinazioni e rispondere alle domande in modo più preciso.
Combinando fonti di conoscenza aggiuntive con le conoscenze esistenti degli LLM, viene fornito un contesto migliore. Il contesto migliorato insieme alla query migliora la qualità della risposta dell'LLM.
La seguente immagine illustra i concetti chiave per comprendere Vertex AI RAG Engine.
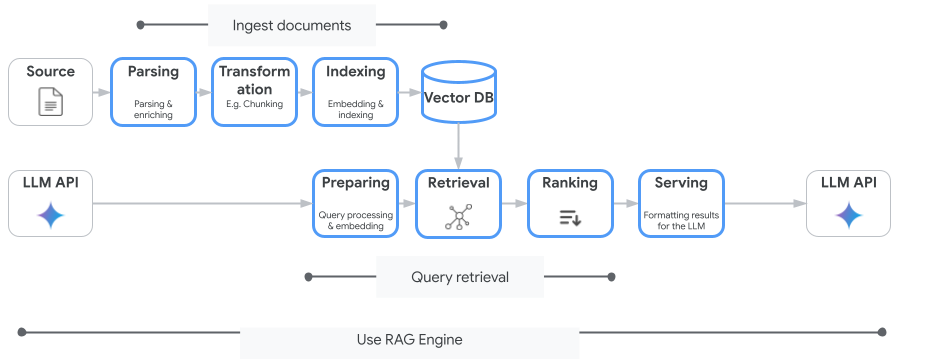
Questi concetti sono elencati nell'ordine del processo di generazione RAG (Retrieval-Augmented Generation).
Importazione dei dati: importazione dei dati da diverse origini dati. Ad esempio, file locali, Cloud Storage e Google Drive.
Trasformazione dei dati: Conversione dei dati in preparazione dell'indicizzazione. Ad esempio, i dati vengono suddivisi in blocchi.
Incorporamento: rappresentazioni numeriche di parole o parti di testo. Questi numeri acquisiscono il significato semantico e il contesto del testo. Parole o testi simili o correlati tendono ad avere incorporamenti simili, il che significa che sono più vicini nello spazio vettoriale di grandi dimensioni.
Indicizzazione dei dati: Vertex AI RAG Engine crea un indice chiamato corpus. L'indice struttura la knowledge base in modo che sia ottimizzata per la ricerca. Ad esempio, l'indice è come un indice dettagliato per un enorme libro di consultazione.
Recupero: quando un utente pone una domanda o fornisce un prompt, il componente di recupero in Vertex AI RAG Engine esegue ricerche nella knowledge base per trovare informazioni pertinenti alla query.
Generazione: le informazioni recuperate diventano il contesto aggiunto alla query utente originale come guida per il modello di AI generativa per generare risposte basate sui fatti e pertinenti.
Aree geografiche supportate
Vertex AI RAG Engine è supportato nelle seguenti regioni:
| Regione | Località | Descrizione | Fase di avvio |
|---|---|---|---|
us-central1 |
Iowa | Sono supportate le versioni v1 e v1beta1. |
Lista consentita |
us-east4 |
Virginia | Sono supportate le versioni v1 e v1beta1. |
GA |
europe-west3 |
Francoforte, Germania | Sono supportate le versioni v1 e v1beta1. |
GA |
europe-west4 |
Eemshaven, Paesi Bassi | Sono supportate le versioni v1 e v1beta1. |
GA |
us-central1è stato modificato inAllowlist. Se vuoi sperimentare con Vertex AI RAG Engine, prova altre regioni. Se prevedi di eseguire l'onboarding del traffico di produzione suus-central1, contattavertex-ai-rag-engine-support@google.com.
Elimina Vertex AI RAG Engine
I seguenti esempi di codice mostrano come eliminare un motore Vertex AI RAG per la console Google Cloud , Python e REST:
Parametri dell'API versione 1 (v1) e esempi di codice.
Parametri dell'API v1beta1 e esempi di codice.
Invia feedback
Per chattare con l'assistenza Google, vai al gruppo di assistenza motore RAG di Vertex AI.
Per inviare un'email, utilizza l'indirizzo email
vertex-ai-rag-engine-support@google.com.
Passaggi successivi
- Per scoprire come utilizzare l'SDK Vertex AI per eseguire le attività di Vertex AI RAG Engine, consulta la guida rapida di RAG per Python.
- Per scoprire di più sul grounding, consulta la panoramica del grounding.
- Per saperne di più sulle risposte di RAG, consulta Output di recupero e generazione del motore RAG di Vertex AI.
- Per scoprire di più sull'architettura RAG: