En esta página, se describe qué es Vertex AI RAG Engine y cómo funciona.
| Descripción | Consola |
|---|---|
| Si deseas obtener información para usar el SDK de Vertex AI para ejecutar tareas de Vertex AI RAG Engine, consulta la guía de inicio rápido de RAG para Python. |
Descripción general
El motor de RAG de Vertex AI, un componente de la plataforma de Vertex AI, facilita la generación mejorada por recuperación (RAG). Vertex AI RAG Engine también es un framework de datos para desarrollar aplicaciones de modelos de lenguaje grandes (LLM) adaptados al contexto. El aumento del contexto se produce cuando se aplica un LLM a tus datos. Esto implemente generación aumentada y de recuperación (RAG).
Un problema común con los LLM es que no comprenden el conocimiento privado, es decir, los datos de tu organización. Con Vertex AI RAG Engine, puedes enriquecer el contexto del LLM con información privada adicional, ya que el modelo puede reducir las alucinaciones y responder a las preguntas con mayor precisión.
Cuando se combinan fuentes de conocimiento adicionales con el conocimiento existente que tienen los LLM, se proporciona un mejor contexto. El contexto mejorado junto con la búsqueda aumenta la calidad de la respuesta del LLM.
En la siguiente imagen, se ilustran los conceptos clave para comprender el motor de RAG de Vertex AI.
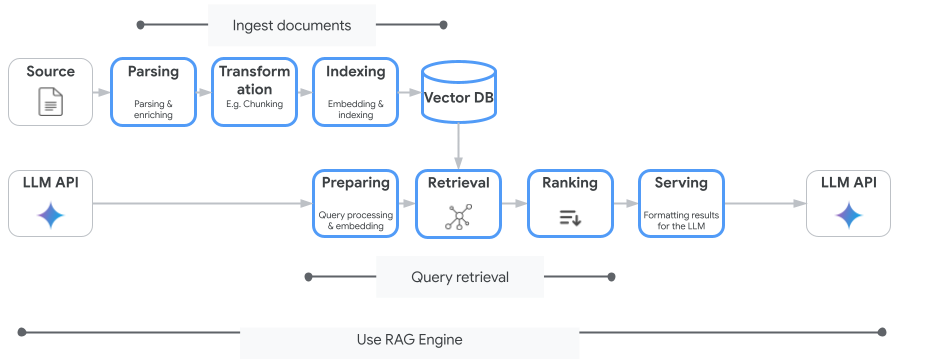
Estos conceptos se enumeran en el orden del proceso de generación mejorada por recuperación (RAG).
Transferencia de datos: Ingresa datos de diferentes fuentes de datos. Por ejemplo, archivos locales, Cloud Storage y Google Drive.
Transformación de datos: Conversión de los datos en preparación para la indexación. Por ejemplo, los datos se dividen en fragmentos.
Embedding: Representaciones numéricas de palabras o fragmentos de texto. Estos números capturan el significado semántico y el contexto del texto. Las palabras o textos similares o relacionados tienden a tener incrustaciones similares, lo que significa que están más cerca unas de otras en el espacio vectorial de alta dimensión.
Indexación de datos: El motor de RAG de Vertex AI crea un índice llamado corpus. El índice estructura la base de conocimientos para optimizar la búsqueda. Por ejemplo, el índice es como el índice detallado de un libro de consulta masiva.
Recuperación: Cuando un usuario hace una pregunta o proporciona una instrucción, el componente de recuperación en Vertex AI RAG Engine busca en su base de conocimiento información relevante para la consulta.
Generación: La información recuperada se convierte en el contexto que se agrega a la búsqueda original del usuario como guía para que el modelo de IA generativa genere respuestas fácticas fundamentadas y pertinentes.
Regiones admitidas
El motor de RAG de Vertex AI es compatible con las siguientes regiones:
| Región | Ubicación | Descripción | Etapa de lanzamiento |
|---|---|---|---|
us-central1 |
Iowa | Se admiten las versiones v1 y v1beta1. |
Lista de anunciantes permitidos |
us-east4 |
Virginia | Se admiten las versiones v1 y v1beta1. |
DG |
europe-west3 |
Fráncfort, Alemania | Se admiten las versiones v1 y v1beta1. |
DG |
europe-west4 |
Puerto de Ems, Países Bajos | Se admiten las versiones v1 y v1beta1. |
DG |
us-central1cambió aAllowlist. Si quieres experimentar con Vertex AI RAG Engine, prueba con otras regiones. Si planeas incorporar tu tráfico de producción aus-central1, comunícate convertex-ai-rag-engine-support@google.com.
Borra el motor de RAG de Vertex AI
En las siguientes muestras de código, se explica cómo borrar un motor de RAG de Vertex AI para la consola, Python y REST: Google Cloud
Parámetros y muestras de código de la versión 1 (v1) de la API
Parámetros y muestras de código de la API de v1beta1
Enviar comentarios
Para chatear con el equipo de asistencia de Google, ve al grupo de asistencia de Vertex AI RAG Engine.
Para enviar un correo electrónico, usa la dirección vertex-ai-rag-engine-support@google.com.
¿Qué sigue?
- Si deseas obtener información para usar el SDK de Vertex AI para ejecutar tareas de Vertex AI RAG Engine, consulta la guía de inicio rápido de RAG para Python.
- Para obtener más información sobre la fundamentación, consulta Descripción general de la fundamentación.
- Para obtener más información sobre las respuestas de RAG, consulta Resultados de recuperación y generación del motor de RAG de Vertex AI.
- Para obtener información sobre la arquitectura de RAG, haz lo siguiente: