Resumo
Neste tutorial, mostramos o processo de implantação e disponibilização de modelos Llama 3.1 e 3.2 usando o vLLM na Vertex AI. Ele foi projetado para ser usado em conjunto com dois notebooks separados: Serve Llama 3.1 com vLLM para implantar modelos Llama 3.1 somente de texto e Serve Multimodal Llama 3.2 com vLLM para implantar modelos Llama 3.2 multimodais que processam entradas de texto e imagem. As etapas descritas nesta página mostram como lidar de maneira eficiente com a inferência de modelos em GPUs e personalizar modelos para diversos aplicativos, fornecendo as ferramentas para integrar modelos de linguagem avançados aos seus projetos.
Ao final deste guia, você vai entender como:
- Baixe modelos Llama pré-criados do Hugging Face com o contêiner vLLM.
- Usar o vLLM para implantar esses modelos em instâncias de GPU no Google Cloud Model Garden da Vertex AI.
- Disponibilizar modelos de maneira eficiente para processar solicitações de inferência em grande escala.
- Executar a inferência em solicitações somente de texto e de texto/imagem.
- Faça a limpeza.
- Depurar a implantação.
Principais recursos do vLLM
| Recurso | Descrição |
|---|---|
| PagedAttention | Um mecanismo de atenção otimizado que gerencia a memória de maneira eficiente durante a inferência. Oferece suporte à geração de texto de alta capacidade alocando recursos de memória de maneira dinâmica, permitindo escalonabilidade para várias solicitações simultâneas. |
| Lotes contínuos | Consolida várias solicitações de entrada em um único lote para processamento paralelo, maximizando a utilização e a capacidade de processamento da GPU. |
| Streaming de token | Permite a saída de token por token em tempo real durante a geração de texto. Ideal para aplicativos que exigem baixa latência, como chatbots ou sistemas de IA interativos. |
| Compatibilidade de modelos | Compatível com uma ampla variedade de modelos pré-treinados em frameworks conhecidos, como o Hugging Face Transformers. Facilita a integração e o teste de diferentes LLMs. |
| Várias GPUs e vários hosts | Permite a veiculação eficiente de modelos distribuindo a carga de trabalho em várias GPUs em uma única máquina e em várias máquinas em um cluster, aumentando significativamente a capacidade e a escalonabilidade. |
| Implantação eficiente | Oferece integração perfeita com APIs, como conclusões de chat da OpenAI, facilitando a implantação para casos de uso de produção. |
| Integração perfeita com modelos do Hugging Face | O vLLM é compatível com o formato de artefatos do modelo do Hugging Face e oferece suporte ao carregamento do HF. Assim, é fácil implantar modelos Llama com outros modelos conhecidos, como Gemma, Phi e Qwen, em uma configuração otimizada. |
| Projeto de código aberto orientado pela comunidade | O vLLM é de código aberto e incentiva contribuições da comunidade, promovendo a melhoria contínua na eficiência da exibição de LLMs. |
Personalizações de vLLM da Vertex AI do Google: melhore a performance e a integração
A implementação do vLLM no Google Vertex AI Model Garden não é uma integração direta da biblioteca de código aberto. A Vertex AI mantém uma versão personalizada e otimizada do vLLM, especificamente adaptada para melhorar o desempenho, a confiabilidade e a integração perfeita no Google Cloud.
- Otimizações de performance:
- Download paralelo do Cloud Storage:acelera significativamente os tempos de carregamento e implantação de modelos ao ativar a recuperação paralela de dados do Cloud Storage, reduzindo a latência e melhorando a velocidade de inicialização.
- Melhorias nos recursos:
- LoRA dinâmica com cache aprimorado e suporte ao Cloud Storage:estende os recursos da LoRA dinâmica com mecanismos de cache de disco local e tratamento de erros robusto, além de oferecer suporte ao carregamento de pesos da LoRA diretamente de caminhos do Cloud Storage e URLs assinados. Isso simplifica o gerenciamento e a implantação de modelos personalizados.
- Análise de chamadas de função do Llama 3.1/3.2:implementa uma análise especializada para chamadas de função do Llama 3.1/3.2, melhorando a robustez da análise.
- Cache de prefixo de memória do host:o vLLM externo só é compatível com o cache de prefixo de memória da GPU.
- Decodificação especulativa:esse é um recurso vLLM atual, mas a Vertex AI realizou experimentos para encontrar configurações de modelo de alta performance.
Essas personalizações específicas da Vertex AI, embora muitas vezes transparentes para o usuário final, permitem maximizar o desempenho e a eficiência das implantações do Llama 3.1 no Model Garden da Vertex AI.
- Integração do ecossistema da Vertex AI:
- Suporte a formatos de entrada/saída de previsão da Vertex AI:garante compatibilidade perfeita com os formatos de entrada e saída de previsão da Vertex AI, simplificando o processamento de dados e a integração com outros serviços da Vertex AI.
- Reconhecimento de variáveis de ambiente da Vertex:respeita e aproveita as variáveis de ambiente da Vertex AI (
AIP_*) para configuração e gerenciamento de recursos, simplificando a implantação e garantindo um comportamento consistente no ambiente da Vertex AI. - Melhoria no tratamento de erros e na robustez:implementa mecanismos abrangentes de tratamento de erros, validação de entrada/saída e encerramento do servidor para garantir estabilidade, confiabilidade e operação perfeita no ambiente gerenciado da Vertex AI.
- Servidor Nginx para capacidade:integra um servidor Nginx ao servidor vLLM, facilitando a implantação de várias réplicas e aumentando a escalonabilidade e a alta disponibilidade da infraestrutura de serviço.
Outros benefícios do vLLM
- Comparativo de mercado de performance: o vLLM oferece uma performance competitiva em comparação com outros sistemas de disponibilização, como o text-generation-inference do Hugging Face e o FasterTransformer da NVIDIA em termos de capacidade de processamento e latência.
- Facilidade de uso: a biblioteca oferece uma API simples para integração com fluxos de trabalho atuais, permitindo implantar modelos Llama 3.1 e 3.2 com configuração mínima.
- Recursos avançados: o vLLM oferece suporte a saídas de streaming (gerando respostas token por token) e processa com eficiência comandos de comprimento variável, melhorando a interatividade e a capacidade de resposta em aplicativos.
Para uma visão geral do sistema vLLM, consulte o artigo.
Modelos compatíveis
O vLLM oferece suporte a uma ampla seleção de modelos de última geração, permitindo que você escolha o que melhor atende às suas necessidades. A tabela a seguir oferece uma seleção desses modelos. No entanto, para acessar uma lista completa de modelos compatíveis, incluindo aqueles para inferência somente de texto e multimodal, consulte o site oficial do vLLM.
| Categoria | Modelos |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B e variantes (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI (em inglês) | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) e variantes (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI (em inglês) | RedPajama, Pythia |
| Stability AI (em inglês) | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) (em inglês) | Falcon 7B, Falcon 40B e variantes (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras (link em inglês) | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Outros modelos importantes | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Introdução ao Model Garden
O contêiner de veiculação de GPUs do Cloud vLLM está integrado ao Grupo de modelos, o playground, a implantação com um clique e exemplos de notebooks do Colab Enterprise. Este tutorial se concentra na família de modelos Llama da Meta AI como exemplo.
Usar o bloco do Colab Enterprise
As implantações de playground e com um clique também estão disponíveis, mas não são abordadas neste tutorial.
- Acesse a página do card de modelo e clique em Abrir notebook.
- Selecione o notebook da Vertex Serving. O notebook está aberto no Colab Enterprise
- Execute o notebook para implantar um modelo usando o vLLM e envie solicitações de previsão ao endpoint.
Configuração e requisitos
Esta seção descreve as etapas necessárias para configurar seu projeto Google Cloud e garantir que você tenha os recursos necessários para implantar e veicular modelos vLLM.
1. Faturamento
- Ative o faturamento: verifique se o faturamento está ativado para o projeto. Consulte Ativar, desativar ou mudar o faturamento de um projeto.
2. Disponibilidade e cotas de GPU
- Para executar previsões usando GPUs de alta performance (NVIDIA A100 de 80 GB ou H100 de 80 GB), verifique suas cotas para essas GPUs na região selecionada:
| Tipo de máquina | Tipo de acelerador | Regiões recomendadas |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Configurar um projeto do Google Cloud
Execute o exemplo de código a seguir para garantir que seu ambiente Google Cloud esteja configurado corretamente. Esta etapa instala as bibliotecas Python necessárias e configura o acesso aos recursos do Google Cloud . incluindo estas ações:
- Instalação: faça upgrade da biblioteca
google-cloud-aiplatforme clone o repositório que contém funções utilitárias. - Configuração do ambiente: definição de variáveis para o ID do projeto Google Cloud , a região e um bucket exclusivo do Cloud Storage para armazenar artefatos do modelo.
- Ativação da API: ative as APIs Vertex AI e Compute Engine, que são essenciais para implantar e gerenciar modelos de IA.
- Configuração do bucket: crie um bucket do Cloud Storage ou verifique um bucket atual para garantir que ele esteja na região correta.
- Inicialização da Vertex AI: inicialize a biblioteca do cliente da Vertex AI com as configurações de projeto, local e bucket de preparo.
- Configuração da conta de serviço: identifique a conta de serviço padrão para executar jobs da Vertex AI e conceda a ela as permissões necessárias.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Usar o Hugging Face com o Meta Llama 3.1, 3.2 e vLLM
As coleções Llama 3.1 e 3.2 da Meta oferecem uma variedade de modelos de linguagem grandes (LLMs) multilíngues projetados para geração de texto de alta qualidade em vários casos de uso. Esses modelos são pré-treinados e ajustados por instruções, sendo excelentes em tarefas como diálogo multilíngue, resumo e recuperação de agentes. Antes de usar os modelos Llama 3.1 e 3.2, você precisa aceitar os Termos de Uso deles, conforme mostrado na captura de tela. A biblioteca vLLM oferece um ambiente de exibição simplificado de código aberto com otimizações para latência, eficiência de memória e escalonabilidade.
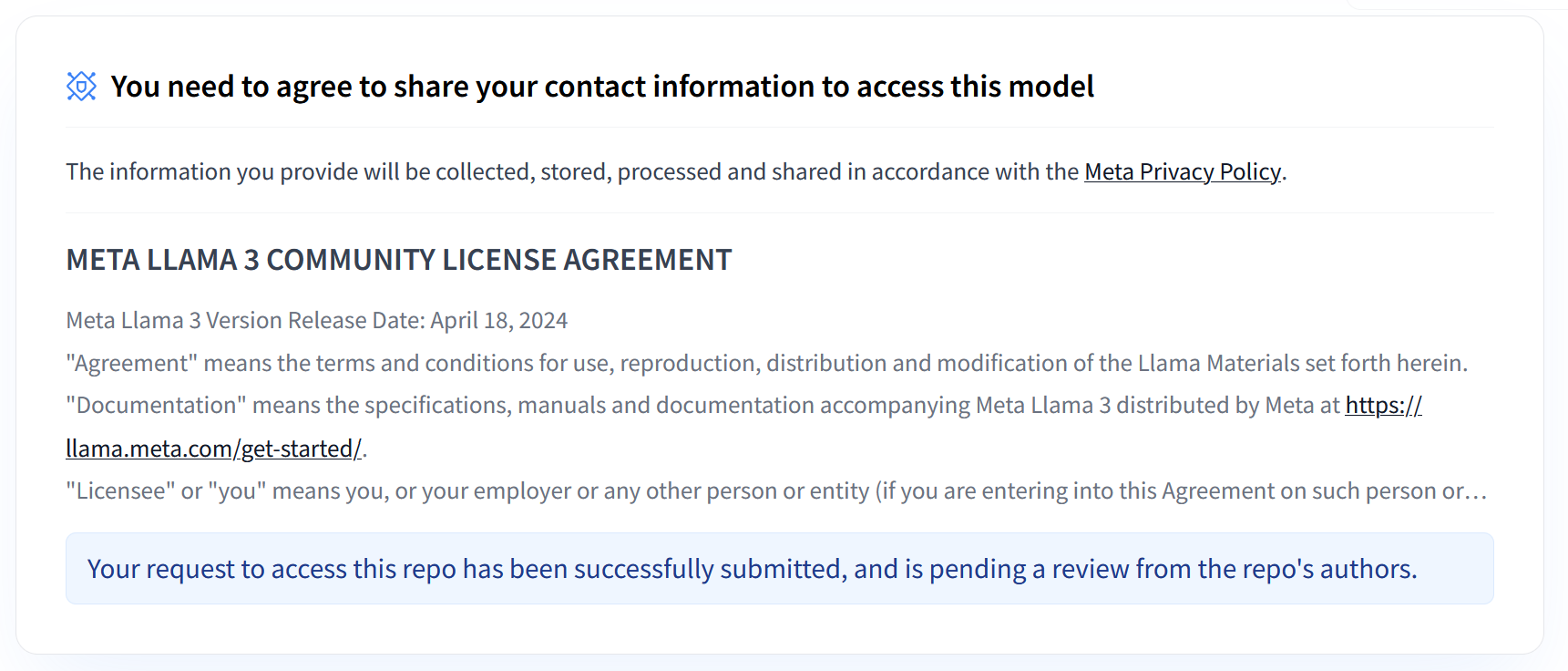 Figura 1: Contrato de licença da comunidade Meta Llama 3
Figura 1: Contrato de licença da comunidade Meta Llama 3
Visão geral das coleções Llama 3.1 e 3.2 da Meta
As coleções Llama 3.1 e 3.2 atendem a diferentes escalas de implantação e tamanhos de modelo, oferecendo opções flexíveis para tarefas de diálogo multilíngue e muito mais. Consulte a página de visão geral do Llama para mais informações.
- Somente texto: a coleção de modelos de linguagem grandes (LLMs) multilíngues Llama 3.2 é composta por modelos generativos pré-treinados e ajustados por instrução nos tamanhos 1B e 3B (entrada/saída de texto).
- Visão e instrução de visão: a coleção Llama 3.2-Vision de modelos de linguagem grandes (LLMs) multimodais é composta por modelos generativos de raciocínio de imagem pré-treinados e ajustados por instrução nos tamanhos 11B e 90B (texto + imagens na entrada, texto na saída). Otimização: assim como o Llama 3.1, os modelos 3.2 são feitos para diálogo multilíngue e têm bom desempenho em tarefas de recuperação e resumo, alcançando os melhores resultados em comparativos de mercado padrão.
- Arquitetura do modelo: o Llama 3.2 também apresenta uma estrutura de transformador autorregressivo, com SFT e RLHF aplicados para alinhar os modelos em termos de utilidade e segurança.
Tokens de acesso de usuário do Hugging Face
Este tutorial exige um token de acesso de leitura do Hub do Hugging Face para acessar os recursos necessários. Siga estas etapas para configurar a autenticação:
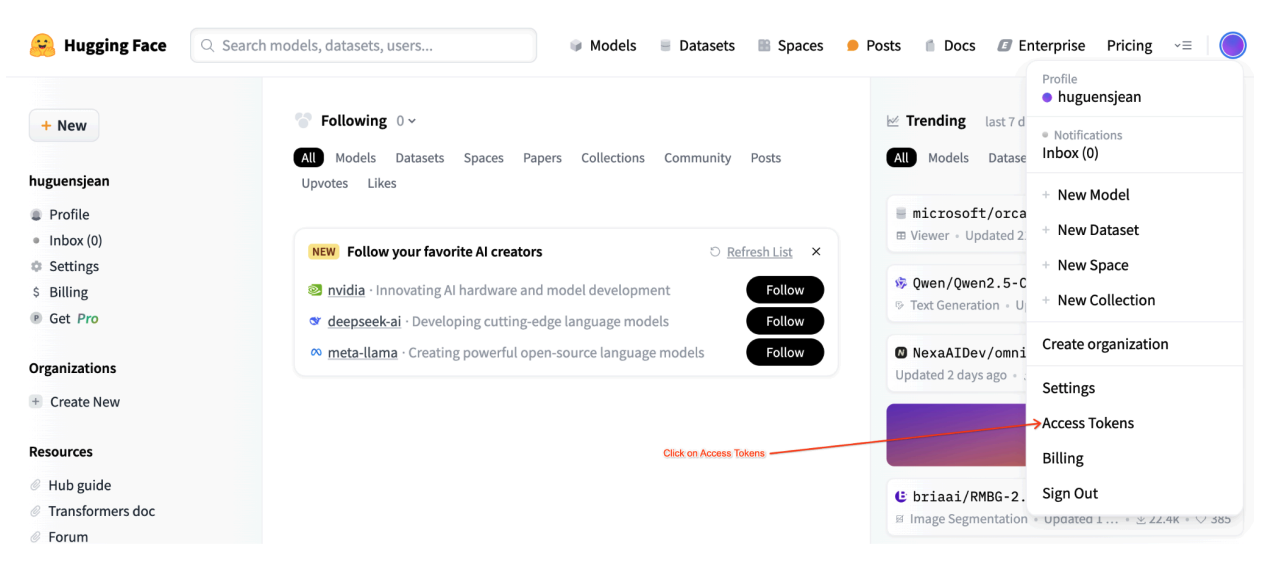 Figura 2: configurações do token de acesso do Hugging Face
Figura 2: configurações do token de acesso do Hugging Face
Gere um token de acesso de leitura:
- Acesse as configurações da sua conta do Hugging Face.
- Crie um token, atribua a ele a função de leitura e salve-o com segurança.
Use o token:
- Use o token gerado para autenticar e acessar repositórios públicos ou privados conforme necessário para o tutorial.
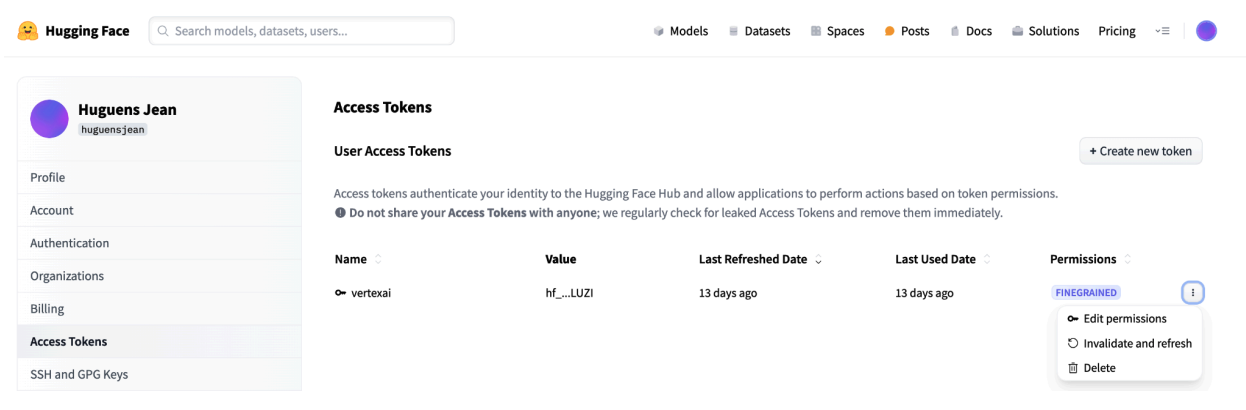 Figura 3: gerenciar o token de acesso do Hugging Face
Figura 3: gerenciar o token de acesso do Hugging Face
Essa configuração garante que você tenha o nível de acesso adequado sem permissões desnecessárias. Essas práticas aumentam a segurança e evitam a exposição acidental de tokens. Para mais informações sobre como configurar tokens de acesso, acesse a página de tokens de acesso do Hugging Face.
Evite compartilhar ou expor seu token publicamente ou on-line. Quando você define seu token como uma variável de ambiente durante a implantação, ele permanece privado para seu projeto. A Vertex AI garante a segurança ao impedir que outros usuários acessem seus modelos e endpoints.
Para mais informações sobre como proteger seu token de acesso, consulte as Práticas recomendadas de tokens de acesso do Hugging Face.
Implantar modelos do Llama 3.1 somente de texto com o vLLM
Para implantação de modelos de linguagem grandes em nível de produção, o vLLM oferece uma solução de disponibilização eficiente que otimiza o uso da memória, reduz a latência e aumenta a capacidade de processamento. Isso o torna especialmente adequado para processar os modelos maiores do Llama 3.1 e os modelos multimodais do Llama 3.2.
Etapa 1: escolher um modelo para implantação
Escolha a variante do modelo Llama 3.1 para implantar. As opções disponíveis incluem vários tamanhos e versões ajustadas por instruções:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Etapa 2: verificar o hardware e a cota de implantação
A função de implantação define a GPU e o tipo de máquina adequados com base no tamanho do modelo e verifica a cota nessa região para um projeto específico:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Verifique a disponibilidade de cota de GPU na região especificada:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Etapa 3: inspecionar o modelo usando o vLLM
A função a seguir faz upload do modelo para a Vertex AI, configura as implantações e as implanta em um endpoint usando o vLLM.
- Imagem do Docker: a implantação usa uma imagem do Docker vLLM pré-criada para veiculação eficiente.
- Configuração: configure a utilização da memória, o comprimento do modelo e outras configurações do vLLM. Para mais informações sobre os argumentos aceitos pelo servidor, acesse a página da documentação oficial do vLLM.
- Variáveis de ambiente: defina variáveis de ambiente para autenticação e origem de implantação.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Etapa 4: executar a implantação
Execute a função de implantação com o modelo e a configuração selecionados. Esta etapa implanta o modelo e retorna as instâncias de modelo e endpoint:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Depois de executar este exemplo de código, seu modelo Llama 3.1 será implantado na Vertex AI e poderá ser acessado pelo endpoint especificado. É possível interagir com ele para tarefas de inferência, como geração de texto, resumo e diálogo. Dependendo do tamanho do modelo, a implantação de um novo modelo pode levar até uma hora. Você pode verificar o progresso na previsão on-line.
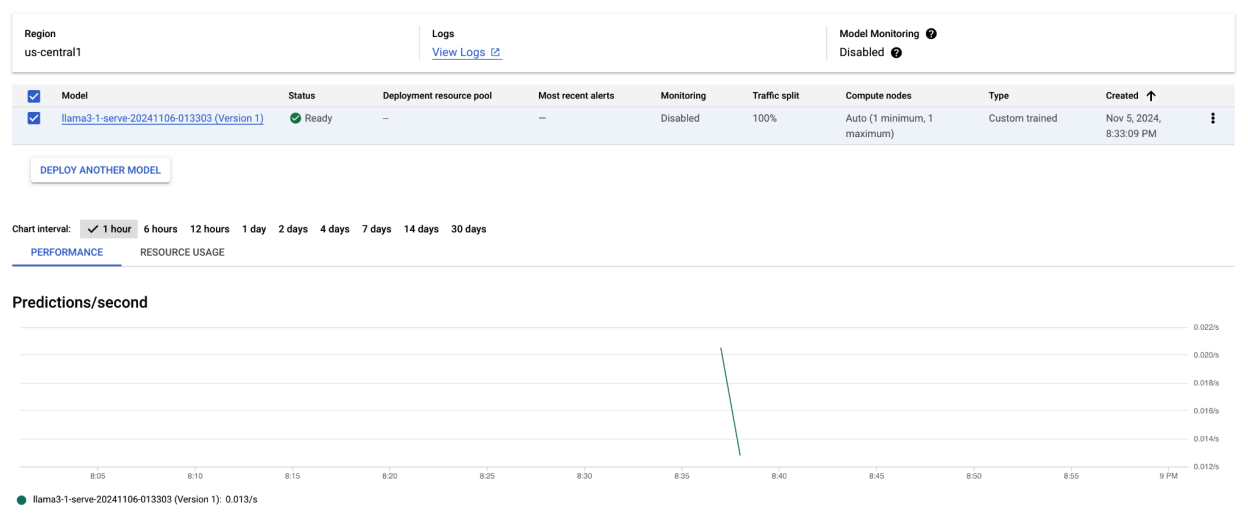 Figura 4: endpoint de implantação do Llama 3.1 no painel do Vertex
Figura 4: endpoint de implantação do Llama 3.1 no painel do Vertex
Fazer previsões com o Llama 3.1 na Vertex AI
Depois de implantar o modelo Llama 3.1 na Vertex AI, você pode começar a fazer previsões enviando comandos de texto ao endpoint. Esta seção fornece um exemplo de geração de respostas com vários parâmetros personalizáveis para controlar a saída.
Etapa 1: definir o comando e os parâmetros
Comece configurando o comando de texto e os parâmetros de amostragem para orientar a resposta do modelo. Confira os principais parâmetros:
prompt: o texto de entrada para o qual você quer que o modelo gere uma resposta. Por exemplo, comando = "O que é um carro?".max_tokens: o número máximo de tokens na saída gerada. Reduzir esse valor pode ajudar a evitar problemas de tempo limite.temperature: controla a aleatoriedade das previsões. Valores mais altos (por exemplo, 1,0) aumentam a diversidade, enquanto valores mais baixos (por exemplo, 0,5) tornam a saída mais focada.top_p: limita o pool de amostragem à probabilidade cumulativa mais alta. Por exemplo, definir top_p = 0,9 considera apenas tokens na massa de probabilidade dos 90% principais.top_k: limita a amostragem aos k tokens mais prováveis. Por exemplo, definir top_k = 50 só vai fazer a amostragem dos 50 principais tokens.raw_response: se for "True", vai retornar a saída bruta do modelo. Se for "False", aplique formatação adicional com a estrutura "Prompt:\n{prompt}\nOutput:\n{output}".lora_id(opcional): caminho para os arquivos de peso da LoRA para aplicar pesos de adaptação de baixa classificação (LoRA). Pode ser um bucket do Cloud Storage ou um URL do repositório Hugging Face. Isso só funciona se--enable-loraestiver definido nos argumentos de implantação. A LoRA dinâmica não é compatível com modelos multimodais.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Etapa 2: enviar a solicitação de previsão
Agora que a instância está configurada, é possível enviar a solicitação de previsão para o endpoint implantado da Vertex AI. Este exemplo mostra como fazer uma previsão e imprimir o resultado:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Exemplo de saída
Confira um exemplo de como o modelo pode responder ao comando "O que é um carro?":
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Outras observações
- Moderação: para garantir a segurança do conteúdo, você pode moderar o texto gerado com os recursos de moderação de texto da Vertex AI.
- Como lidar com tempos limite: se você encontrar problemas como
ServiceUnavailable: 503, tente reduzir o parâmetromax_tokens.
Essa abordagem oferece uma maneira flexível de interagir com o modelo Llama 3.1 usando diferentes técnicas de amostragem e adaptadores LoRA, o que o torna adequado para uma variedade de casos de uso, desde a geração de texto de uso geral até respostas específicas para tarefas.
Implantar modelos multimodais do Llama 3.2 com vLLM
Nesta seção, mostramos o processo de upload de modelos Llama 3.2 pré-criados para o Model Registry e a implantação deles em um endpoint da Vertex AI. O tempo de implantação pode levar até uma hora, dependendo do tamanho do modelo. Os modelos do Llama 3.2 estão disponíveis em versões multimodais que aceitam entradas de texto e imagem. O vLLM oferece suporte a:
- Formato somente texto
- Formato de imagem única + texto
Esses formatos tornam o Llama 3.2 adequado para aplicativos que exigem processamento de texto e visual.
Etapa 1: escolher um modelo para implantação
Especifique a variante do modelo Llama 3.2 que você quer implantar. O exemplo a seguir usa Llama-3.2-11B-Vision como o modelo selecionado, mas você pode escolher entre outras opções disponíveis com base nos seus requisitos.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Etapa 2: configurar hardware e recursos
Selecione o hardware adequado para o tamanho do modelo. O vLLM pode usar diferentes GPUs dependendo das necessidades computacionais do modelo:
- Modelos de 1B e 3B: use GPUs NVIDIA L4.
- Modelos de 11 bilhões de parâmetros: use GPUs NVIDIA A100.
- Modelos de 90 bilhões: use GPUs NVIDIA H100.
Este exemplo configura a implantação com base na seleção do modelo:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Verifique se você tem a cota de GPU necessária:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Etapa 3: implantar o modelo usando o vLLM
A função a seguir processa a implantação do modelo Llama 3.2 na Vertex AI. Ele configura o ambiente, a utilização da memória e as configurações do vLLM do modelo para uma exibição eficiente.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Etapa 4: executar a implantação
Execute a função de implantação com o modelo e as configurações configurados. A função retornará as instâncias de modelo e endpoint, que podem ser usadas para inferência.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
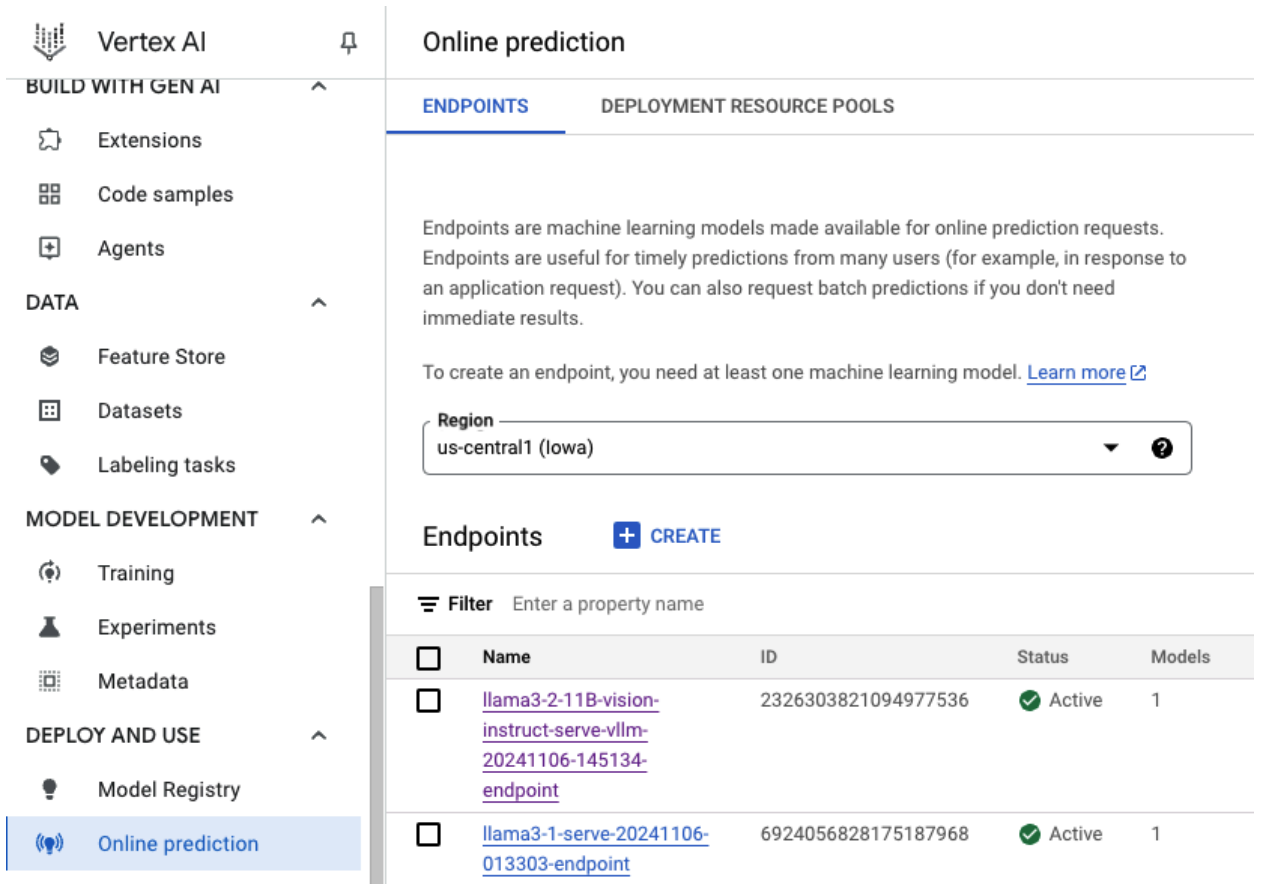 Figura 5: endpoint de implantação do Llama 3.2 no painel da Vertex
Figura 5: endpoint de implantação do Llama 3.2 no painel da Vertex
Dependendo do tamanho do modelo, a implantação pode levar até uma hora. Você pode verificar o progresso na previsão on-line.
Inferência com vLLM na Vertex AI usando a rota de previsão padrão
Esta seção mostra como configurar a inferência para o modelo Llama 3.2 Vision na Vertex AI usando a rota de previsão padrão. Você vai usar a biblioteca vLLM para disponibilização eficiente e interagir com o modelo enviando um comando visual em combinação com texto.
Para começar, verifique se o endpoint do modelo está implantado e pronto para previsões.
Etapa 1: definir o comando e os parâmetros
Este exemplo fornece um URL de imagem e um comando de texto, que o modelo vai processar para gerar uma resposta.
 Figura 6: exemplo de entrada de imagem para solicitar o Llama 3.2
Figura 6: exemplo de entrada de imagem para solicitar o Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Etapa 2: configurar parâmetros de previsão
Ajuste os seguintes parâmetros para controlar a resposta do modelo:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Etapa 3: preparar a solicitação de previsão
Configure a solicitação de previsão com o URL da imagem, o comando e outros parâmetros.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Etapa 4: fazer a previsão
Envie a solicitação para o endpoint da Vertex AI e processe a resposta:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Se você encontrar um problema de tempo limite (por exemplo, ServiceUnavailable: 503 Took too
long to respond when processing), tente reduzir o valor de max_tokens para um número menor, como 20, para reduzir o tempo de resposta.
Inferência com vLLM na Vertex AI usando a conclusão de chat da OpenAI
Esta seção mostra como realizar inferências em modelos Llama 3.2 Vision usando a API Chat Completions da OpenAI na Vertex AI. Essa abordagem permite usar recursos multimodais enviando comandos de texto e imagens ao modelo para respostas mais interativas.
Etapa 1: executar a implantação do modelo Llama 3.2 Vision Instruct
Execute a função de implantação com o modelo e as configurações configurados. A função retornará as instâncias de modelo e endpoint, que podem ser usadas para inferência.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Etapa 2: configurar o recurso de endpoint
Comece configurando o nome do recurso de endpoint para sua implantação da Vertex AI.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Etapa 3: instalar o SDK da OpenAI e as bibliotecas de autenticação
Para enviar solicitações usando o SDK da OpenAI, verifique se as bibliotecas necessárias estão instaladas:
!pip install -qU openai google-auth requests
Etapa 4: definir parâmetros de entrada para a conclusão do chat
Configure o URL da imagem e o comando de texto que serão enviados ao modelo. Ajuste max_tokens e temperature para controlar o tamanho e a aleatoriedade da resposta, respectivamente.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Etapa 5: configurar a autenticação e o URL base
Recupere suas credenciais e defina o URL de base para solicitações de API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Etapa 6: enviar uma solicitação de conclusão de chat
Usando a API Chat Completions do OpenAI, envie a imagem e o comando de texto para seu endpoint da Vertex AI:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(Opcional) Etapa 7: reconectar a um endpoint
Para se reconectar a um endpoint criado anteriormente, use o ID dele. Essa etapa é útil se você quiser reutilizar um endpoint em vez de criar um novo.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Essa configuração oferece flexibilidade para alternar entre endpoints recém-criados e existentes conforme necessário, permitindo testes e implantações simplificados.
Limpeza
Para evitar cobranças contínuas e liberar recursos, exclua os modelos e endpoints implantados e, opcionalmente, o bucket de armazenamento usado neste experimento.
Etapa 1: excluir endpoints e modelos
O código a seguir vai desfazer a implantação de cada modelo e excluir os endpoints associados:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Etapa 2: (opcional) excluir o bucket do Cloud Storage
Se você criou um bucket do Cloud Storage especificamente para este experimento, é possível excluí-lo definindo "delete_bucket" como "True". Essa etapa é opcional, mas recomendada se o bucket não for mais necessário.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Ao seguir estas etapas, você garante que todos os recursos usados neste tutorial sejam limpos, reduzindo custos desnecessários associados ao experimento.
Como depurar problemas comuns
Esta seção fornece orientações sobre como identificar e resolver problemas comuns encontrados durante a implantação e a inferência de modelos vLLM na Vertex AI.
Verificar os registros
Verifique os registros para identificar a causa raiz de falhas de implantação ou comportamento inesperado:
- Acesse o console de previsão da Vertex AI:acesse o console de previsão da Vertex AI no console Google Cloud .
- Selecione o endpoint:clique no endpoint que está com problemas. O status indica se a implantação falhou.
- Ver registros:clique no endpoint e navegue até a guia Registros ou clique em Ver registros. Isso direciona você ao Cloud Logging, filtrado para mostrar registros específicos desse endpoint e da implantação do modelo. Também é possível acessar os registros diretamente pelo serviço do Cloud Logging.
- Analise os registros:revise as entradas de registro em busca de mensagens de erro, avisos e outras informações relevantes. Confira os carimbos de data/hora para correlacionar entradas de registro com ações específicas. Procure problemas relacionados a restrições de recursos (memória e CPU), problemas de autenticação ou erros de configuração.
Problema comum 1: falta de memória (OOM) do CUDA durante a implantação
Os erros de falta de memória (OOM) do CUDA ocorrem quando o uso de memória do modelo excede a capacidade disponível da GPU.
No caso do modelo somente de texto, usamos os seguintes argumentos de mecanismo:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
No caso do modelo multimodal, usamos os seguintes argumentos de mecanismo:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
A implantação do modelo multimodal com max_num_seqs = 256, como fizemos no caso do modelo somente de texto, pode causar o seguinte erro:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
 Figura 7: registro de erros de GPU sem memória (OOM)
Figura 7: registro de erros de GPU sem memória (OOM)
Entenda a max_num_seqs e a memória da GPU:
- O parâmetro
max_num_seqsdefine o número máximo de solicitações simultâneas que o modelo pode processar. - Cada sequência processada pelo modelo consome memória da GPU. O uso total de memória é proporcional a
max_num_seqsvezes a memória por sequência. - Os modelos somente de texto (como Meta-Llama-3.1-8B) geralmente consomem menos memória por sequência do que os modelos multimodais (como Llama-3.2-11B-Vision-Instruct), que processam texto e imagens.
Analise o registro de erros (Figura 8):
- O registro mostra um
torch.OutOfMemoryErrorao tentar alocar memória na GPU. - O erro ocorre porque o uso de memória do modelo excede a capacidade disponível da GPU. A GPU NVIDIA L4 tem 24 GB, e definir o parâmetro
max_num_seqsmuito alto para o modelo multimodal causa um estouro. - O registro sugere definir
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truepara melhorar o gerenciamento de memória, embora o problema principal seja o alto uso de memória.
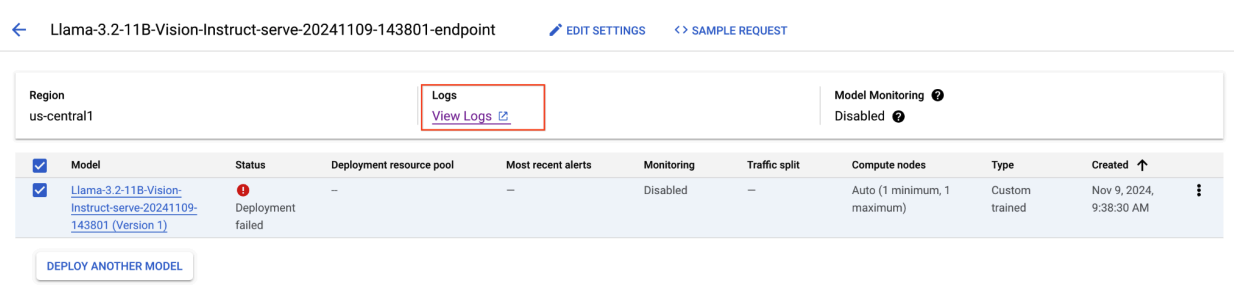 Figura 8: implantação do Llama 3.2 com falha
Figura 8: implantação do Llama 3.2 com falha
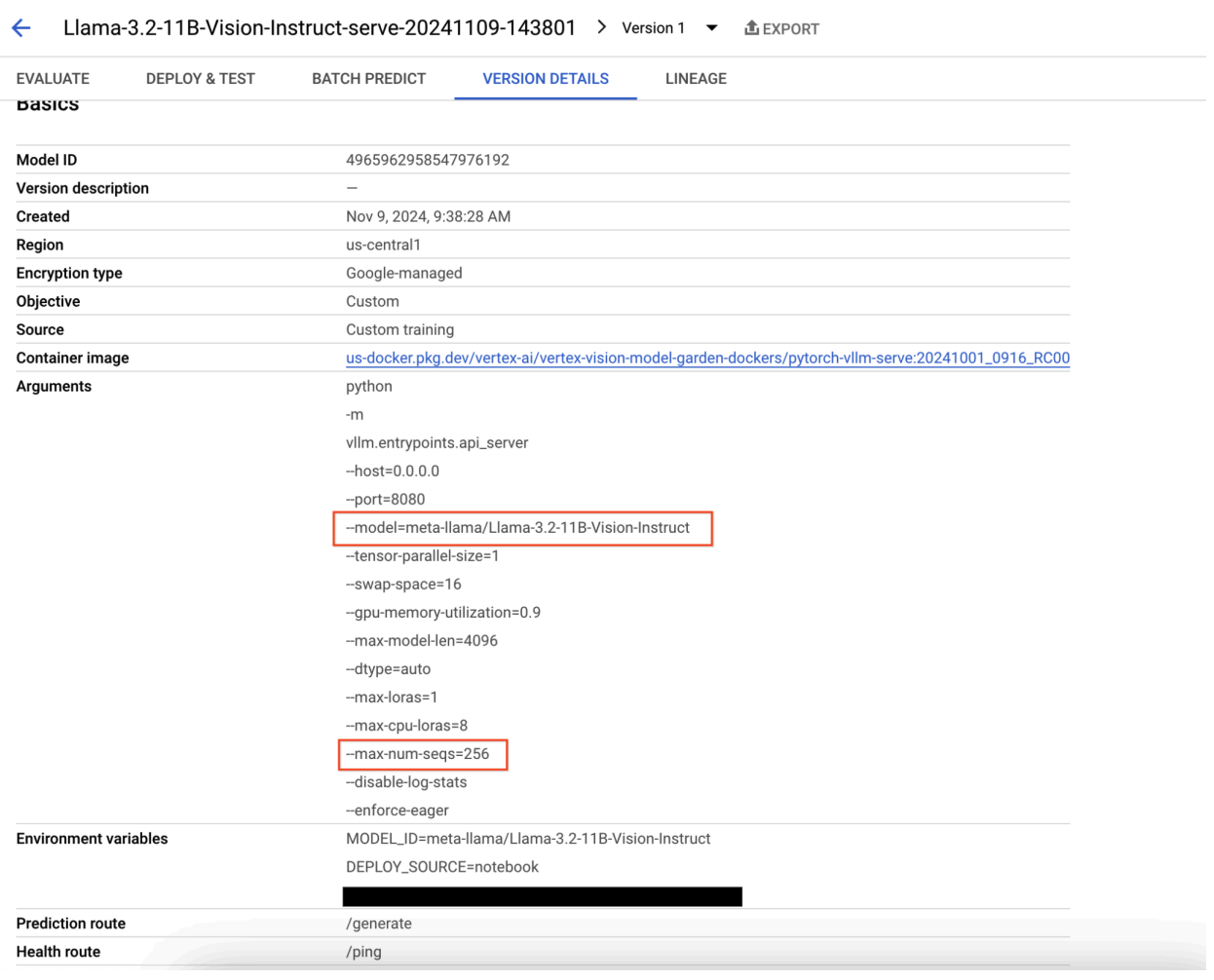 Figura 9: painel de detalhes da versão do modelo
Figura 9: painel de detalhes da versão do modelo
Para resolver esse problema, acesse o console de previsão da Vertex AI e clique no endpoint. O status deve indicar que a implantação falhou. Clique para ver os registros. Verifique se max-num-seqs = 256. Esse valor é muito alto para o Llama-3.2-11B-Vision-Instruct. Um valor mais adequado seria 12.
Problema comum 2: é necessário um token do Hugging Face
Os erros de token do Hugging Face ocorrem quando o modelo é restrito e exige credenciais de autenticação adequadas para acesso.
A captura de tela a seguir mostra uma entrada de registro no Explorador de registros do Google Cloud com uma mensagem de erro relacionada ao acesso ao modelo Meta LLaMA-3.2-11B-Vision hospedado no Hugging Face. O erro indica que o acesso ao modelo é restrito e exige autenticação para continuar. A mensagem diz especificamente "Não é possível acessar o repositório restrito para o URL", destacando que o modelo é restrito e exige credenciais de autenticação adequadas para ser acessado. Essa entrada de registro pode ajudar a resolver problemas de autenticação ao trabalhar com recursos restritos em repositórios externos.
 Figura 10: erro de token do Hugging Face
Figura 10: erro de token do Hugging Face
Para resolver esse problema, verifique as permissões do seu token de acesso do Hugging Face. Copie o token mais recente e implante um novo endpoint.
Problema comum 3: modelo de chat necessário
Os erros de modelo de chat ocorrem quando o modelo padrão não é mais permitido e um modelo personalizado precisa ser fornecido se o tokenizador não definir um.
Esta captura de tela mostra uma entrada de registro no Explorador de registros do Google Cloud, em que um ValueError ocorre devido a um modelo de chat ausente na biblioteca transformers versão 4.44. A mensagem de erro indica que o modelo de chat padrão não é mais permitido, e um modelo de chat personalizado precisa ser fornecido se o tokenizador não definir um. Esse erro destaca uma mudança recente na biblioteca que exige a definição explícita de um modelo de chat, útil para depurar problemas ao implantar aplicativos baseados em chat.
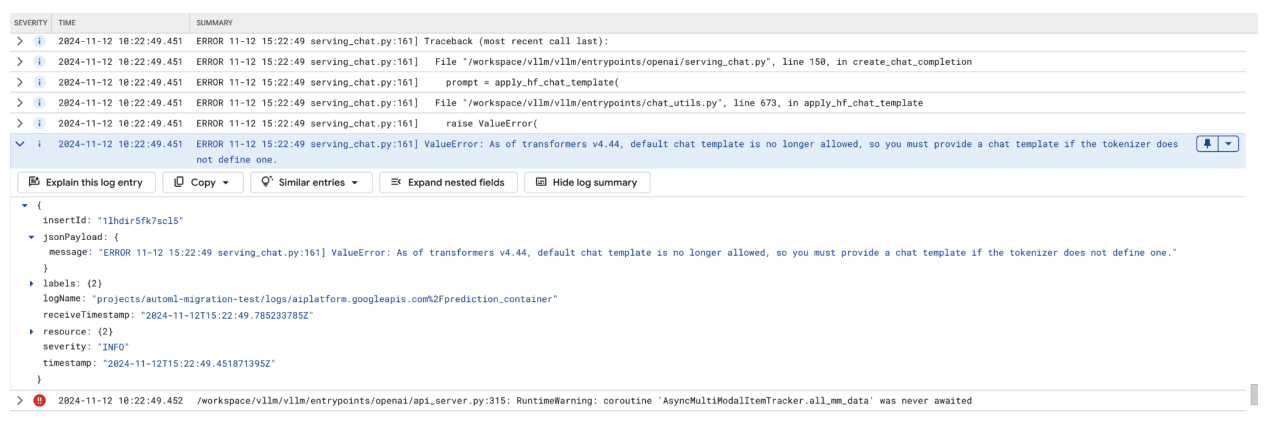 Figura 11: modelo de chat necessário
Figura 11: modelo de chat necessário
Para evitar isso, forneça um modelo de chat durante a implantação usando o argumento de entrada --chat-template. Os modelos de exemplo podem ser encontrados no repositório de exemplos do vLLM.
Problema comum 4: comprimento máximo da sequência do modelo
Os erros de comprimento máximo da sequência do modelo ocorrem quando o comprimento máximo da sequência do modelo (4096) é maior que o número máximo de tokens que podem ser armazenados no cache KV (2256).
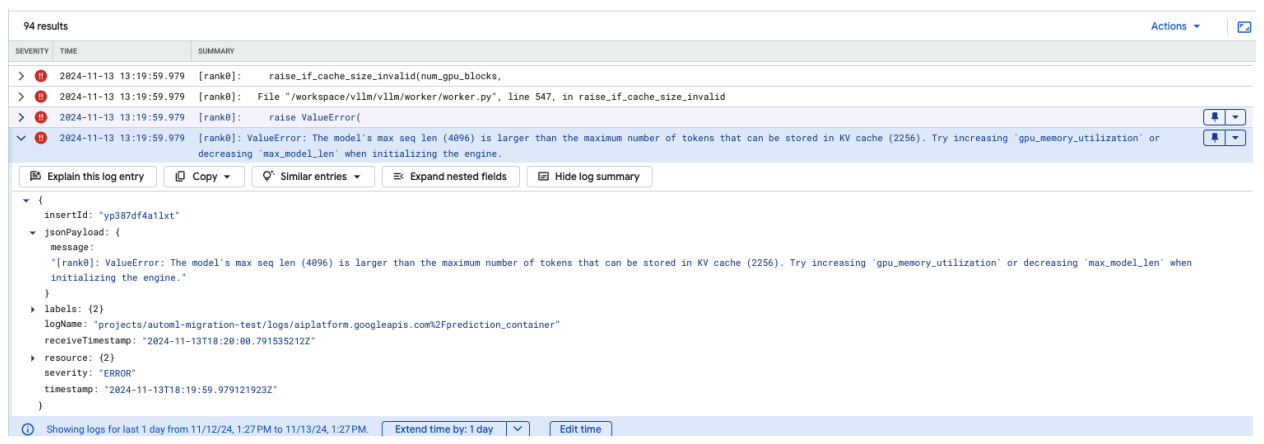 Figura 12: comprimento máximo da sequência muito grande
Figura 12: comprimento máximo da sequência muito grande
ValueError: O comprimento máximo da sequência do modelo (4096) é maior do que o número máximo de tokens que podem ser armazenados no cache KV (2256). Tente aumentar gpu_memory_utilization ou diminuir max_model_len ao inicializar o mecanismo.
Para resolver esse problema, defina max_model_len como 2048, que é menor que 2256. Outra solução para esse problema é usar mais GPUs ou GPUs maiores. O tensor-parallel-size precisará ser definido adequadamente se você optar por usar mais GPUs.
Notas da versão do contêiner vLLM do Model Garden
Principais lançamentos
vLLM padrão
Data de lançamento |
Arquitetura |
Versão do vLLM |
URI do contêiner |
|---|---|---|---|
| 17 de julho de 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 de julho de 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 de junho de 2025 | x86 |
Após a v0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 de junho de 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 de junho de 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 de maio de 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 29 de abril de 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17 de abril de 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 10 de abril de 2025 | x86 |
Após a v0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| Apr 7, 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| Apr 7, 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5 de abril de 2025 | x86 |
Past v0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 de março de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11 de março de 2025 | x86 |
Após a v0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3 de março de 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 de janeiro de 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 de dezembro de 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 de novembro de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 de outubro de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM otimizado
Data de lançamento |
Arquitetura |
URI do contêiner |
|---|---|---|
| Jan 21, 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 de outubro de 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Outras versões
A lista completa de versões de contêineres vLLM padrão de VMG pode ser encontrada na página do Artifact Registry.
As versões do vLLM-TPU em status experimental são marcadas com <yyyymmdd_hhmm_tpu_experimental_RC00>.