Resumen
En este instructivo, se explica el proceso de implementación y entrega de los modelos Llama 3.1 y 3.2 con vLLM en Vertex AI. Está diseñado para usarse junto con dos notebooks independientes: Serve Llama 3.1 with vLLM para implementar modelos Llama 3.1 de solo texto y Serve Multimodal Llama 3.2 with vLLM para implementar modelos multimodales Llama 3.2 que administran entradas de imagen y texto. En esta página, se indican los pasos para administrar de manera eficiente la inferencia de modelos en GPUs y personalizar modelos para diversas aplicaciones. De esta manera, contarás con las herramientas necesarias para integrar modelos de lenguaje avanzados en tus proyectos.
Al final de esta guía, podrás hacer lo siguiente:
- Descargar modelos Llama compilados previamente de Hugging Face con el contenedor de vLLM
- Usar vLLM para implementar estos modelos en instancias de GPU en Google Cloud Vertex AI Model Garden
- Entrega modelos de forma eficiente para procesar solicitudes de inferencia a gran escala.
- Ejecutar inferencias en solicitudes de solo texto y solicitudes de imagen y texto
- Realizar una limpieza
- Depurar la implementación
Funciones clave de vLLM
| Función | Descripción |
|---|---|
| PagedAttention | Un mecanismo de atención optimizado que administra la memoria de manera eficiente durante la inferencia. Admite la generación de texto de alto rendimiento a través de la asignación dinámica de recursos de memoria, lo que permite la escalabilidad para múltiples solicitudes simultáneas. |
| Agrupación en lotes continua | Consolida varias solicitudes de entrada en un solo lote para el procesamiento en paralelo, lo que maximiza el uso y la capacidad de procesamiento de la GPU. |
| Transmisión de tokens | Habilita la salida de token por token en tiempo real durante la generación de texto. Es ideal para aplicaciones que requieren baja latencia, como chatbots o sistemas de IA interactivos. |
| Compatibilidad del modelo | Admite una amplia variedad de modelos previamente entrenados en frameworks populares, como Hugging Face Transformers. Facilita la integración y la experimentación con diferentes LLMs. |
| Multi-GPU y multi-host | Permite la entrega eficiente de modelos, ya que distribuye la carga de trabajo en varias GPUs dentro de una sola máquina y en varias máquinas en un clúster, lo que aumenta significativamente el rendimiento y la escalabilidad. |
| Implementación eficiente | Ofrece una integración perfecta con las APIs, como las de OpenAI chat completions, lo que facilita la implementación para casos de uso de producción. |
| Integración continua con modelos de Hugging Face | vLLM es compatible con el formato de artefactos de modelos de Hugging Face y admite la carga desde HF, lo que facilita la implementación de modelos de Llama junto con otros modelos populares, como Gemma, Phi y Qwen, en un entorno optimizado. |
| Proyecto de código abierto impulsado por la comunidad | vLLM es de código abierto y fomenta las contribuciones de la comunidad, lo que promueve la mejora continua en la eficiencia de la entrega de LLM. |
Personalizaciones de vLLM de Google Vertex AI: Mejora el rendimiento y la integración
La implementación de vLLM en Google Vertex AI Model Garden no es una integración directa de la biblioteca de código abierto. Vertex AI mantiene una versión personalizada y optimizada de vLLM que se adapta específicamente para mejorar el rendimiento, la confiabilidad y la integración perfecta dentro de Google Cloud.
- Optimizaciones del rendimiento:
- Descarga paralela desde Cloud Storage: Acelera significativamente los tiempos de carga y la implementación de modelos, ya que permite la recuperación paralela de datos desde Cloud Storage, lo que reduce la latencia y mejora la velocidad de inicio.
- Mejoras en las funciones:
- LoRA dinámico con almacenamiento en caché mejorado y compatibilidad con Cloud Storage: Extiende las capacidades de LoRA dinámico con mecanismos de almacenamiento en caché en disco local y manejo de errores sólido, además de la compatibilidad para cargar pesos de LoRA directamente desde rutas de Cloud Storage y URLs firmadas. Esto simplifica la administración y la implementación de modelos personalizados.
- Análisis de llamadas a funciones de Llama 3.1/3.2: Implementa un análisis especializado para las llamadas a funciones de Llama 3.1/3.2, lo que mejora la solidez del análisis.
- Almacenamiento en caché de prefijos de memoria del host: El vLLM externo solo admite el almacenamiento en caché de prefijos de memoria de la GPU.
- Decodificación especulativa: Esta es una función existente de vLLM, pero Vertex AI realizó experimentos para encontrar configuraciones de modelos de alto rendimiento.
Estas personalizaciones específicas de Vertex AI, aunque a menudo son transparentes para el usuario final, te permiten maximizar el rendimiento y la eficiencia de tus implementaciones de Llama 3.1 en Vertex AI Model Garden.
- Integración en el ecosistema de Vertex AI:
- Compatibilidad con los formatos de entrada y salida de predicciones de Vertex AI: Garantiza una compatibilidad perfecta con los formatos de entrada y salida de predicciones de Vertex AI, lo que simplifica el manejo de datos y la integración con otros servicios de Vertex AI.
- Reconocimiento de variables de entorno de Vertex: Respeta y aprovecha las variables de entorno de Vertex AI (
AIP_*) para la configuración y la administración de recursos, lo que optimiza la implementación y garantiza un comportamiento coherente dentro del entorno de Vertex AI. - Control de manejo de errores y solidez mejorados: Se implementan mecanismos integrales de manejo de errores, validación de entrada y salida, y finalización del servidor para garantizar la estabilidad, la confiabilidad y el funcionamiento sin problemas dentro del entorno administrado de Vertex AI.
- Servidor Nginx para la capacidad: Integra un servidor Nginx sobre el servidor vLLM, lo que facilita la implementación de varias réplicas y mejora la escalabilidad y la alta disponibilidad de la infraestructura de servicio.
Beneficios adicionales de vLLM
- Rendimiento de referencia: vLLM ofrece un rendimiento competitivo en comparación con otros sistemas de servicio, como Hugging Face text-generation-inference y FasterTransformer de NVIDIA en términos de capacidad de procesamiento y latencia.
- Facilidad de uso: La biblioteca proporciona una API sencilla para la integración con flujos de trabajo existentes, lo que te permite implementar los modelos de Llama 3.1 y 3.2 con una configuración mínima.
- Funciones avanzadas: vLLM admite la transmisión de resultados (generación de respuestas token por token) y controla de manera eficiente las instrucciones de longitud variable, lo que mejora la interactividad y la capacidad de respuesta en las aplicaciones.
Para obtener una descripción general del sistema vLLM, consulta el artículo.
Modelos compatibles
vLLM admite una amplia selección de modelos de vanguardia, lo que te permite elegir el que mejor se adapte a tus necesidades. En la siguiente tabla, se ofrece una selección de estos modelos. Sin embargo, para acceder a una lista completa de los modelos compatibles, incluidos los de inferencia multimodal y solo de texto, puedes consultar el sitio web oficial de vLLM.
| Categoría | Modelos |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2 y Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B y sus variantes (Instruct, Chat), Mistral-tiny, Mistral-small y Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) y variantes (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4 y GPT-NeoX |
| Together AI | RedPajama y Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B y variantes (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM y BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B) y PaLM 2 | |
| Salesforce | CodeT5 y CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo y Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Otros modelos destacados | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus |
Primeros pasos con Model Garden
El contenedor de entrega de GPU de Cloud de vLLM está integrado en Model Garden, el entorno de pruebas, la implementación con un clic y los ejemplos de notebooks de Colab Enterprise. En este instructivo, nos enfocamos en la familia de modelos Llama de Meta AI como ejemplo.
Usa el notebook de Colab Enterprise
También están disponibles las implementaciones de Playground y de un solo clic, pero no se describen en este instructivo.
- Navega a la página de la tarjeta de modelo y haz clic en Abrir notebook.
- Selecciona el notebook de Vertex Serving. Se abre el notebook en Colab Enterprise.
- Ejecuta el notebook para implementar un modelo con vLLM y envía solicitudes de predicción al extremo.
Configuración y requisitos
En esta sección, se describen los pasos necesarios para configurar tu proyecto Google Cloudy garantizar que tengas los recursos necesarios para implementar y entregar modelos de vLLM.
1. Facturación
- Habilita la facturación: Asegúrate de que la facturación esté habilitada para tu proyecto. Puedes consultar Habilita, inhabilita o cambia la facturación de un proyecto.
2. Disponibilidad y cuotas de GPU
- Para ejecutar predicciones con GPU de alto rendimiento (NVIDIA A100 de 80 GB o H100 de 80 GB), asegúrate de verificar las cuotas de estas GPU en la región seleccionada:
| Tipo de máquina | Tipo de acelerador | Regiones recomendadas |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Configura un Google Cloud proyecto
Ejecuta la siguiente muestra de código para asegurarte de que tu entorno de Google Cloud esté configurado correctamente. En este paso, se instalan las bibliotecas de Python necesarias y se configura el acceso a los recursos de Google Cloud . Se incluyen las siguientes acciones:
- Instalación: Actualiza la biblioteca
google-cloud-aiplatformy clona el repositorio que contiene las funciones de utilidad. - Configuración del entorno: Definición de variables para el ID del proyecto Google Cloud , la región y un bucket único de Cloud Storage para almacenar artefactos del modelo.
- Activación de la API: Habilita las APIs de Vertex AI y Compute Engine, que son esenciales para implementar y administrar modelos de IA.
- Configuración del bucket: Crea un bucket nuevo de Cloud Storage o verifica uno existente para asegurarte de que esté en la región correcta.
- Inicialización de Vertex AI: Inicializa la biblioteca cliente de Vertex AI con la configuración del proyecto, la ubicación y el bucket de etapa de pruebas.
- Configuración de la cuenta de servicio: Identifica la cuenta de servicio predeterminada para ejecutar trabajos de Vertex AI y otórgale los permisos necesarios.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Usa Hugging Face con Meta Llama 3.1, 3.2 y vLLM
Las colecciones Llama 3.1 y 3.2 de Meta proporcionan una variedad de modelos de lenguaje grandes (LLM) multilingües diseñados para la generación de texto de alta calidad en varios casos de uso. Estos modelos están previamente entrenados y ajustados para instrucciones, y se destacan en tareas como el diálogo multilingüe, el resumen y la recuperación de agentes. Antes de usar los modelos Llama 3.1 y 3.2, debes aceptar sus condiciones de uso, como se muestra en la captura de pantalla. La biblioteca de vLLM ofrece un entorno de entrega optimizado de código abierto con optimizaciones para la latencia, la eficiencia de la memoria y la escalabilidad.
 Figura 1: Contrato de licencia de la comunidad de Meta Llama 3
Figura 1: Contrato de licencia de la comunidad de Meta Llama 3
Descripción general de las colecciones de Llama 3.1 y 3.2 de Meta
Las colecciones de Llama 3.1 y 3.2 se adaptan a diferentes escalas de implementación y tamaños de modelos, lo que te brinda opciones flexibles para tareas de diálogo multilingüe y mucho más. Consulta la página de descripción general de Llama para obtener más información.
- Solo texto: La colección de modelos de lenguaje grandes (LLM) multilingües de Llama 3.2 es una colección de modelos generativos previamente entrenados y ajustados por instrucciones en tamaños de 1,000 y 3,000 millones (entrada de texto, salida de texto).
- Vision y Vision Instruct: La colección Llama 3.2-Vision de modelos de lenguaje grandes (LLMs) multimodales es una colección de modelos generativos de razonamiento de imágenes previamente entrenados y ajustados con instrucciones en tamaños de 11B y 90B (entrada de texto y de imágenes, salida de texto). Optimización: Al igual que Llama 3.1, los modelos 3.2 están diseñados para diálogos multilingües y tienen un buen rendimiento en tareas de recuperación y resumen, y logran los mejores resultados en comparativas estándar.
- Arquitectura del modelo: Llama 3.2 también incluye un framework de transformador de regresión automática, con SFT y RLHF aplicados para alinear los modelos en cuanto a utilidad y seguridad.
Tokens de acceso de usuario de Hugging Face
En este instructivo, se requiere un token de acceso de lectura del Hugging Face Hub para acceder a los recursos necesarios. Sigue estos pasos para configurar la autenticación:
 Figura 2: Configuración del token de acceso de Hugging Face
Figura 2: Configuración del token de acceso de Hugging Face
Genera un token de acceso de lectura:
- Navega a la configuración de tu cuenta de Hugging Face.
- Crea un token nuevo, asígnale el rol de lectura y guárdalo de forma segura.
Usa el token:
- Usa el token generado para autenticarte y acceder a los repositorios públicos o privados según sea necesario para el instructivo.
 Figura 3: Administra el token de acceso de Hugging Face
Figura 3: Administra el token de acceso de Hugging Face
Esta configuración garantiza que tengas el nivel de acceso adecuado sin permisos innecesarios. Estas prácticas mejoran la seguridad y evitan la exposición accidental de tokens. Para obtener más información sobre cómo configurar tokens de acceso, visita la página de tokens de acceso de Hugging Face.
Evita compartir o exponer tu token públicamente o en línea. Cuando configuras tu token como una variable de entorno durante la implementación, permanece privado para tu proyecto. Vertex AI garantiza su seguridad impidiendo que otros usuarios accedan a tus modelos y extremos.
Para obtener más información sobre cómo proteger tu token de acceso, consulta las Prácticas recomendadas para los tokens de acceso de Hugging Face.
Implementa modelos Llama 3.1 de solo texto con vLLM
Para la implementación a nivel de producción de modelos de lenguaje grandes, vLLM proporciona una solución de entrega eficiente que optimiza el uso de la memoria, reduce la latencia y aumenta la capacidad de procesamiento. Esto lo hace especialmente adecuado para controlar los modelos Llama 3.1 más grandes, así como los modelos Llama 3.2 multimodales.
Paso 1: Elige un modelo para implementar
Elige la variante del modelo Llama 3.1 que deseas implementar. Las opciones disponibles incluyen varios tamaños y versiones ajustadas para instrucciones:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Paso 2: Verifica el hardware y la cuota de implementación
La función de implementación establece el tipo de GPU y de máquina adecuados según el tamaño del modelo y verifica la cuota en esa región para un proyecto en particular:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Verifica la disponibilidad de la cuota de GPU en la región especificada:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Paso 3: Inspecciona el modelo con vLLM
La siguiente función sube el modelo a Vertex AI, configura los parámetros de implementación y lo implementa en un extremo con vLLM.
- Imagen de Docker: La implementación usa una imagen de Docker de vLLM precompilada para la entrega eficiente.
- Configuración: Configura la utilización de la memoria, la longitud del modelo y otros parámetros de configuración de vLLM. Para obtener más información sobre los argumentos que admite el servidor, visita la página de documentación oficial de vLLM.
- Variables de entorno: Establece variables de entorno para la autenticación y la fuente de implementación.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Paso 4: Ejecuta la implementación
Ejecuta la función de implementación con el modelo y la configuración seleccionados. En este paso, se implementa el modelo y se devuelven las instancias del modelo y del extremo:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Después de ejecutar este muestra de código, tu modelo de Llama 3.1 se implementará en Vertex AI y se podrá acceder a él a través del extremo especificado. Puedes interactuar con él para realizar tareas de inferencia, como generación de texto, resumen y diálogo. Según el tamaño del modelo, la implementación del modelo nuevo puede tardar hasta una hora. Puedes verificar el progreso en la predicción en línea.
 Figura 4: Endpoints de implementación de Llama 3.1 en el panel de Vertex
Figura 4: Endpoints de implementación de Llama 3.1 en el panel de Vertex
Cómo realizar predicciones con Llama 3.1 en Vertex AI
Después de implementar correctamente el modelo de Llama 3.1 en Vertex AI, puedes comenzar a hacer predicciones enviando instrucciones de texto al extremo. En esta sección, se proporciona un ejemplo de cómo generar respuestas con varios parámetros personalizables para controlar el resultado.
Paso 1: Define tu instrucción y los parámetros
Comienza por configurar tu instrucción de texto y los parámetros de muestreo para guiar la respuesta del modelo. Estos son los parámetros clave:
prompt: Es el texto de entrada para el que deseas que el modelo genere una respuesta. Por ejemplo, prompt = "¿Qué es un automóvil?".max_tokens: Es la cantidad máxima de tokens en el resultado generado. Reducir este valor puede ayudar a evitar problemas de tiempo de espera.temperature: Controla la aleatorización de las predicciones. Los valores más altos (por ejemplo, 1.0) aumentan la diversidad, mientras que los valores más bajos (por ejemplo, 0.5) hacen que el resultado sea más enfocado.top_p: Limita el grupo de muestras a la probabilidad acumulada superior. Por ejemplo, si configuras top_p = 0.9, solo se considerarán los tokens dentro del 90% superior de la masa de probabilidad.top_k: Limita el muestreo a los k tokens más probables. Por ejemplo, si configuras top_k = 50, solo se realizará un muestreo de los 50 tokens principales.raw_response: Si es verdadero, devuelve el resultado sin procesar del modelo. Si es falso, aplica formato adicional con la estructura "Prompt:\n{prompt}\nOutput:\n{output}".lora_id(opcional): Es la ruta de acceso a los archivos de pesos de LoRA para aplicar pesos de adaptación de bajo rango (LoRA). Puede ser un bucket de Cloud Storage o una URL de repositorio de Hugging Face. Ten en cuenta que esto solo funciona si--enable-loraestá configurado en los argumentos de implementación. La función Dynamic LoRA no es compatible con los modelos multimodales.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Paso 2: Envía la solicitud de predicción
Ahora que la instancia está configurada, puedes enviar la solicitud de predicción al extremo de Vertex AI implementado. En este ejemplo, se muestra cómo hacer una predicción y, luego, imprimir el resultado:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Resultado de ejemplo
Este es un ejemplo de cómo podría responder el modelo a la instrucción "¿Qué es un automóvil?":
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Notas adicionales
- Moderación: Para garantizar la seguridad del contenido, puedes moderar el texto generado con las capacidades de moderación de texto de Vertex AI.
- Cómo controlar los tiempos de espera: Si tienes problemas como
ServiceUnavailable: 503, intenta reducir el parámetromax_tokens.
Este enfoque proporciona una forma flexible de interactuar con el modelo Llama 3.1 usando diferentes técnicas de muestreo y adaptadores de LoRA, lo que lo hace adecuado para una variedad de casos de uso, desde la generación de texto de uso general hasta respuestas específicas para tareas.
Implementa modelos multimodales de Llama 3.2 con vLLM
En esta sección, se explica el proceso para subir modelos Llama 3.2 prediseñados a Model Registry y, luego, implementarlos en un extremo de Vertex AI. El tiempo de implementación puede tardar hasta una hora, según el tamaño del modelo. Los modelos Llama 3.2 están disponibles en versiones multimodales que admiten entradas de texto y de imagen. vLLM admite lo siguiente:
- Formato de solo texto
- Formato de una sola imagen y texto
Estos formatos hacen que Llama 3.2 sea adecuado para aplicaciones que requieren procesamiento visual y de texto.
Paso 1: Elige un modelo para implementar
Especifica la variante del modelo Llama 3.2 que deseas implementar. En el siguiente ejemplo, se usa Llama-3.2-11B-Vision como el modelo seleccionado, pero puedes elegir entre otras opciones disponibles según tus requisitos.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Paso 2: Configura el hardware y los recursos
Selecciona el hardware adecuado para el tamaño del modelo. vLLM puede usar diferentes GPUs según las necesidades de procesamiento del modelo:
- Modelos de 1B y 3B: Usa GPU NVIDIA L4.
- Modelos de 11 B: Usa GPU NVIDIA A100.
- Modelos de 90B: Usa GPU NVIDIA H100.
En este ejemplo, se configura la implementación según la selección del modelo:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Asegúrate de tener la cuota de GPU necesaria:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Paso 3: Implementa el modelo con vLLM
La siguiente función controla la implementación del modelo Llama 3.2 en Vertex AI. Configura el entorno del modelo, la utilización de la memoria y la configuración de vLLM para una entrega eficiente.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Paso 4: Ejecuta la implementación
Ejecuta la función de implementación con el modelo y la configuración establecidos. La función devolverá tanto el modelo como las instancias del extremo, que puedes usar para la inferencia.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
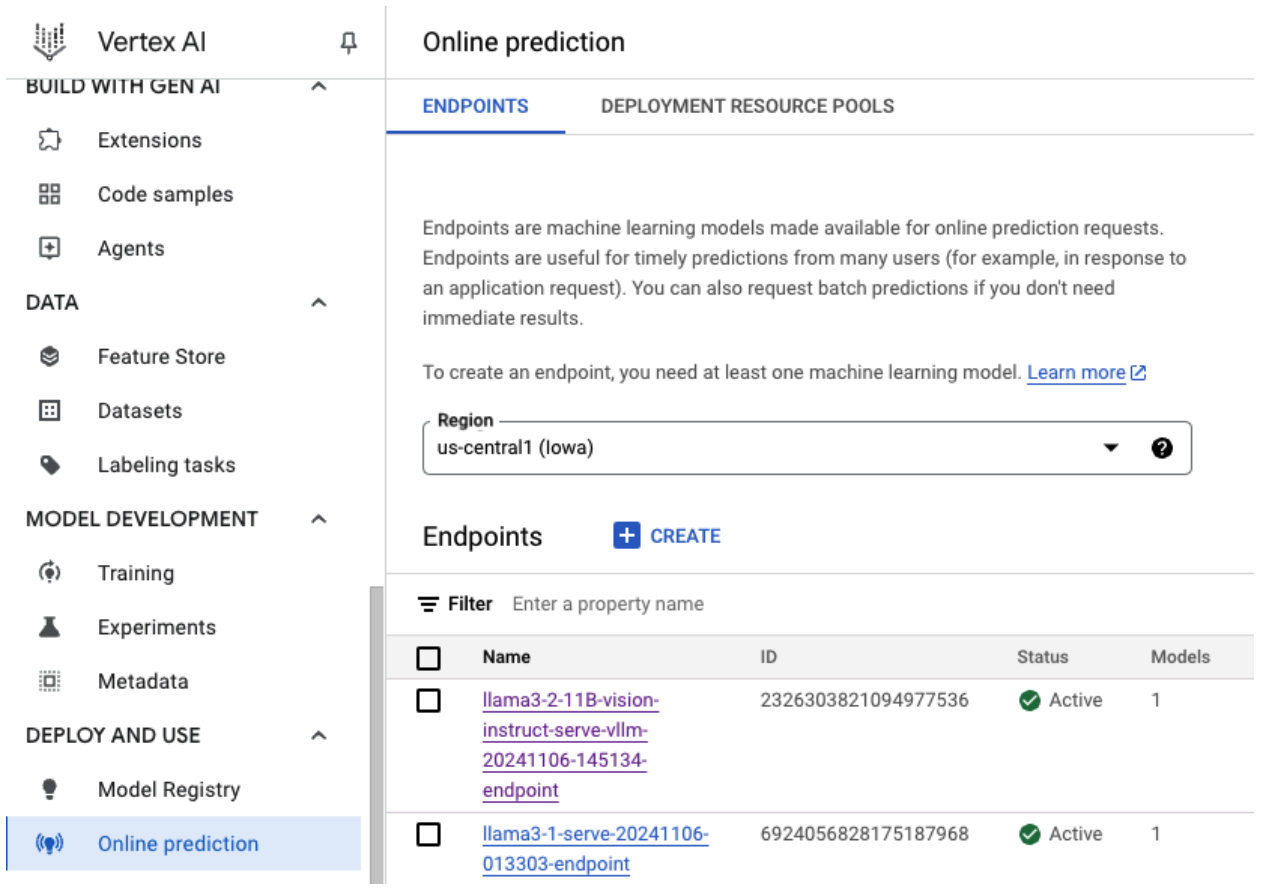 Figura 5: Extremo de implementación de Llama 3.2 en el panel de Vertex
Figura 5: Extremo de implementación de Llama 3.2 en el panel de Vertex
Según el tamaño del modelo, la implementación del modelo nuevo puede tardar hasta una hora en completarse. Puedes verificar su progreso en la predicción en línea.
Inferencia con vLLM en Vertex AI usando la ruta de predicción predeterminada
En esta sección, se explica cómo configurar la inferencia para el modelo Llama 3.2 Vision en Vertex AI con la ruta de predicción predeterminada. Usarás la biblioteca vLLM para una entrega eficiente y, luego, interactuarás con el modelo enviando una instrucción visual en combinación con texto.
Para comenzar, asegúrate de que el extremo del modelo esté implementado y listo para generar predicciones.
Paso 1: Define tu instrucción y los parámetros
En este ejemplo, se proporciona una URL de imagen y una instrucción de texto, que el modelo procesará para generar una respuesta.
 Figura 6: Imagen de entrada de muestra para solicitarle a Llama 3.2
Figura 6: Imagen de entrada de muestra para solicitarle a Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Paso 2: Configura los parámetros de predicción
Ajusta los siguientes parámetros para controlar la respuesta del modelo:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Paso 3: Prepara la solicitud de predicción
Configura la solicitud de predicción con la URL de la imagen, la instrucción y otros parámetros.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Paso 4: Realiza la predicción
Envía la solicitud a tu extremo de Vertex AI y procesa la respuesta:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Si tienes un problema de tiempo de espera (por ejemplo, ServiceUnavailable: 503 Took too
long to respond when processing), intenta reducir el valor de max_tokens a un número más bajo, como 20, para mitigar el tiempo de respuesta.
Inferencia con vLLM en Vertex AI con la finalización de chat de OpenAI
En esta sección, se explica cómo realizar inferencias en los modelos de Llama 3.2 Vision con la API de Chat Completions de OpenAI en Vertex AI. Este enfoque te permite usar capacidades multimodales enviando instrucciones de imágenes y texto al modelo para obtener respuestas más interactivas.
Paso 1: Ejecuta la implementación del modelo Llama 3.2 Vision Instruct
Ejecuta la función de implementación con el modelo y la configuración establecidos. La función devolverá tanto el modelo como las instancias del extremo, que puedes usar para la inferencia.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Paso 2: Configura el recurso del extremo
Comienza por configurar el nombre del recurso del extremo para tu implementación de Vertex AI.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Paso 3: Instala el SDK de OpenAI y las bibliotecas de autenticación
Para enviar solicitudes con el SDK de OpenAI, asegúrate de que estén instaladas las bibliotecas necesarias:
!pip install -qU openai google-auth requests
Paso 4: Define los parámetros de entrada para la finalización del chat
Configura la URL de la imagen y la instrucción de texto que se enviarán al modelo. Ajusta max_tokens y temperature para controlar la longitud y la aleatoriedad de la respuesta, respectivamente.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Paso 5: Configura la autenticación y la URL base
Recupera tus credenciales y establece la URL base para las solicitudes a la API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Paso 6: Envía una solicitud de Chat Completion
Con la API de Chat Completions de OpenAI, envía la imagen y la instrucción de texto a tu extremo de Vertex AI:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
Paso 7 (opcional): Vuelve a conectarte a un extremo existente
Para volver a conectarte a un extremo creado anteriormente, usa el ID del extremo. Este paso es útil si deseas reutilizar un extremo en lugar de crear uno nuevo.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Esta configuración proporciona flexibilidad para cambiar entre los extremos existentes y los recién creados según sea necesario, lo que permite realizar pruebas y la implementación de forma optimizada.
Limpieza
Para evitar cargos continuos y liberar recursos, asegúrate de borrar los modelos y los extremos implementados, y, de manera opcional, el bucket de almacenamiento que se usó para este experimento.
Paso 1: Borra los extremos y los modelos
El siguiente código anulará la implementación de cada modelo y borrará los extremos asociados:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Paso 2: (Opcional) Borra el bucket de Cloud Storage
Si creaste un bucket de Cloud Storage específicamente para este experimento, puedes borrarlo configurando delete_bucket como True. Este paso es opcional, pero se recomienda si ya no necesitas el bucket.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Si sigues estos pasos, te asegurarás de que se limpien todos los recursos que se usaron en este instructivo, lo que reducirá los costos innecesarios asociados con el experimento.
Cómo depurar problemas comunes
En esta sección, se proporciona orientación para identificar y resolver problemas comunes que se producen durante la implementación y la inferencia de modelos de vLLM en Vertex AI.
Verifica los registros
Revisa los registros para identificar la causa raíz de las fallas en la implementación o el comportamiento inesperado:
- Navega a la consola de Vertex AI Prediction: Ve a la consola de Vertex AI Prediction en la Google Cloud consola.
- Selecciona el extremo: Haz clic en el extremo que tiene problemas. El estado debe indicar si falló la implementación.
- Ver registros: Haz clic en el extremo y, luego, navega a la pestaña Registros o haz clic en Ver registros. Esto te dirige a Cloud Logging, filtrado para mostrar los registros específicos de ese extremo y la implementación del modelo. También puedes acceder a los registros directamente a través del servicio de Cloud Logging.
- Analiza los registros: Revisa las entradas de registro para ver mensajes de error, advertencias y otra información relevante. Consulta las marcas de tiempo para correlacionar las entradas de registro con acciones específicas. Busca problemas relacionados con las restricciones de recursos (memoria y CPU), problemas de autenticación o errores de configuración.
Problema común 1: Error de CUDA por falta de memoria (OOM) durante la implementación
Los errores de memoria insuficiente (OOM) de CUDA ocurren cuando el uso de memoria del modelo supera la capacidad de GPU disponible.
En el caso del modelo solo de texto, usamos los siguientes argumentos del motor:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
En el caso del modelo multimodal, usamos los siguientes argumentos del motor:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
Implementar el modelo multimodal con max_num_seqs = 256, como hicimos en el caso del modelo solo de texto, podría causar el siguiente error:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
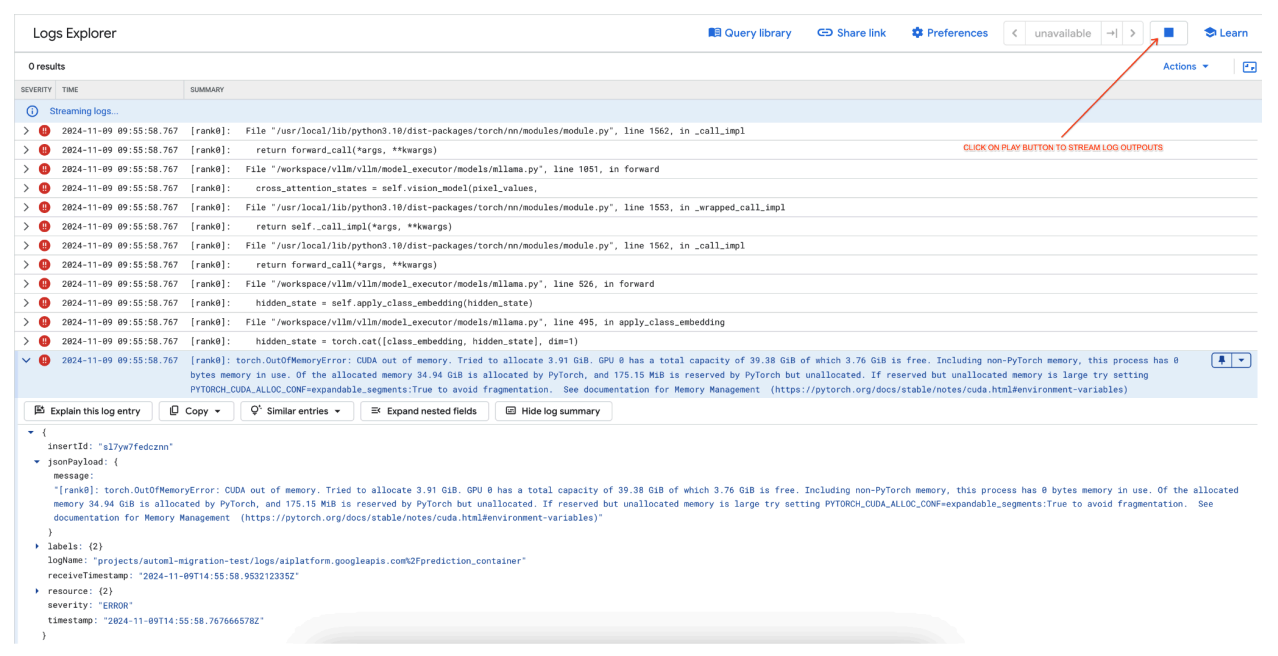 Figura 7: Registro de errores de GPU por falta de memoria (OOM)
Figura 7: Registro de errores de GPU por falta de memoria (OOM)
Comprende max_num_seqs y la memoria de la GPU:
- El parámetro
max_num_seqsdefine la cantidad máxima de solicitudes simultáneas que el modelo puede controlar. - Cada secuencia que procesa el modelo consume memoria de GPU. El uso total de memoria es proporcional a
max_num_seqsmultiplicado por la memoria por secuencia. - Los modelos de solo texto (como Meta-Llama-3.1-8B) suelen consumir menos memoria por secuencia que los modelos multimodales (como Llama-3.2-11B-Vision-Instruct), que procesan texto e imágenes.
Revisa el registro de errores (figura 8):
- El registro muestra un
torch.OutOfMemoryErrorcuando se intenta asignar memoria en la GPU. - El error se produce porque el uso de memoria del modelo supera la capacidad de GPU disponible. La GPU NVIDIA L4 tiene 24 GB, y establecer el parámetro
max_num_seqsdemasiado alto para el modelo multimodal provoca un desbordamiento. - El registro sugiere establecer
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truepara mejorar la administración de la memoria, aunque el problema principal aquí es el alto uso de memoria.
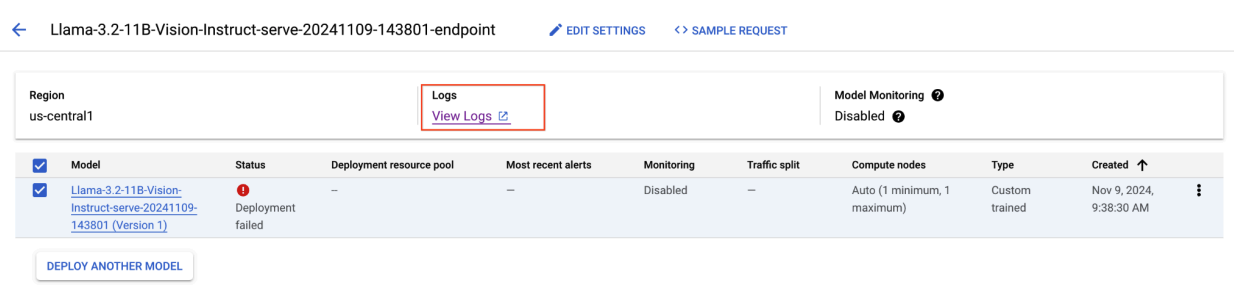 Figura 8: Error en la implementación de Llama 3.2
Figura 8: Error en la implementación de Llama 3.2
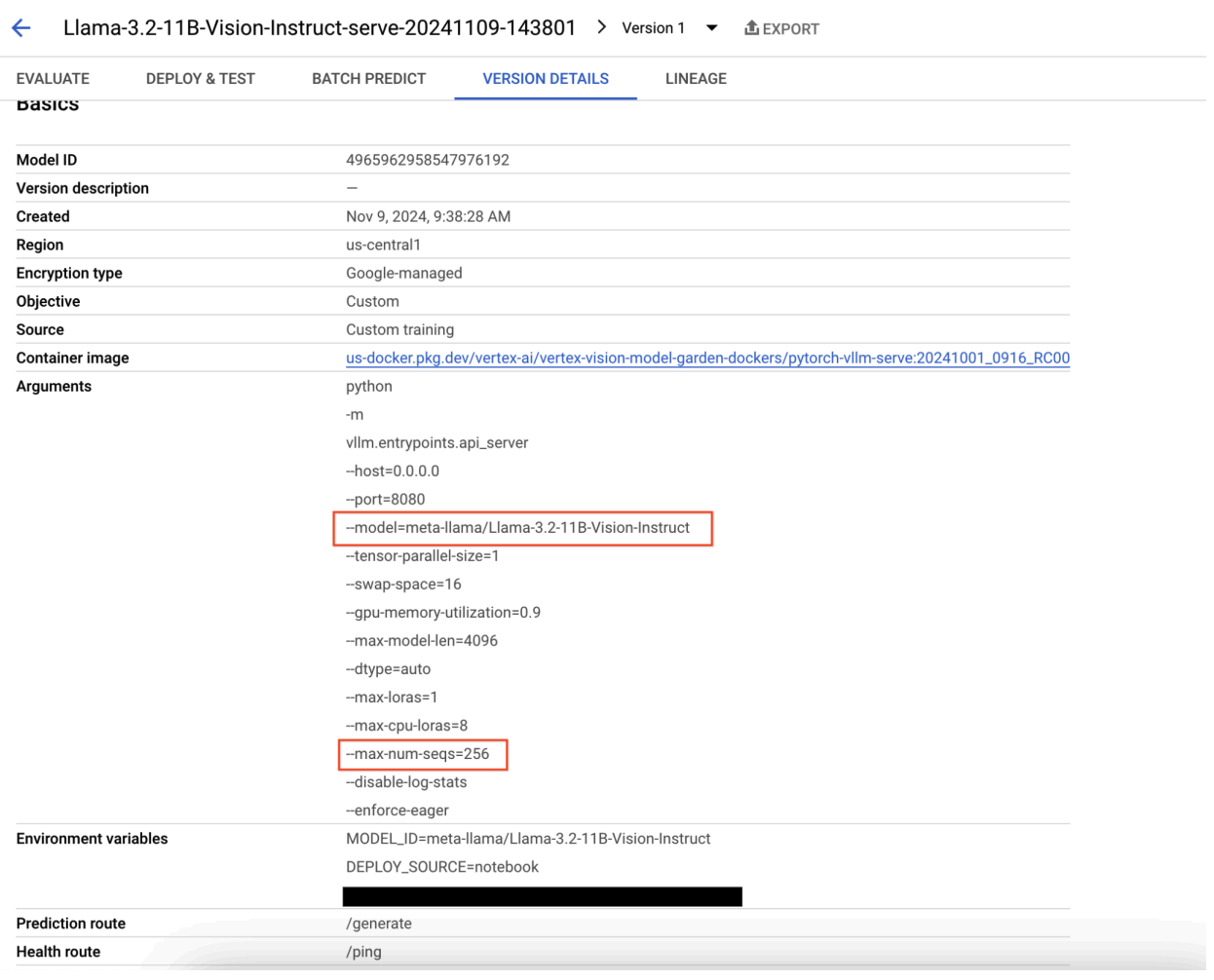 Figura 9: Panel de detalles de la versión del modelo
Figura 9: Panel de detalles de la versión del modelo
Para resolver este problema, navega a la consola de Vertex AI Prediction y haz clic en el extremo. El estado debe indicar que la implementación falló. Haz clic para ver los registros. Verifica que max-num-seqs = 256. Este valor es demasiado alto para Llama-3.2-11B-Vision-Instruct. Un valor más adecuado sería 12.
Problema habitual 2: Se necesita un token de Hugging Face
Los errores de tokens de Hugging Face ocurren cuando el modelo está restringido y requiere credenciales de autenticación adecuadas para acceder a él.
En la siguiente captura de pantalla, se muestra una entrada de registro en el Explorador de registros de Google Cloud que muestra un mensaje de error relacionado con el acceso al modelo Meta LLaMA-3.2-11B-Vision alojado en Hugging Face. El error indica que el acceso al modelo está restringido y que se requiere autenticación para continuar. El mensaje indica específicamente que "No se puede acceder al repositorio restringido para la URL", lo que destaca que el modelo está restringido y requiere credenciales de autenticación adecuadas para acceder a él. Esta entrada de registro puede ayudar a solucionar problemas de autenticación cuando se trabaja con recursos restringidos en repositorios externos.
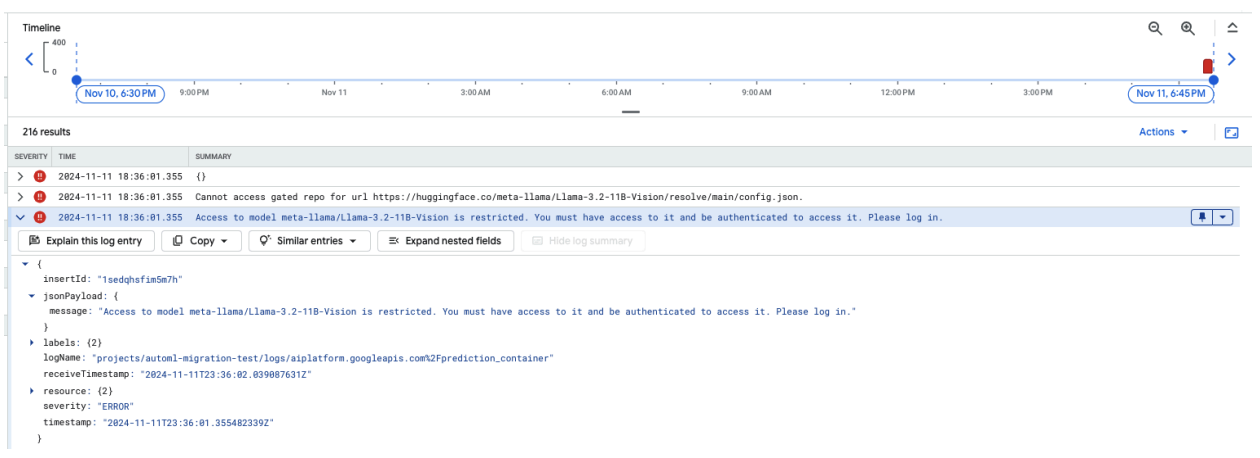 Figura 10: Error de token de Hugging Face
Figura 10: Error de token de Hugging Face
Para resolver este problema, verifica los permisos de tu token de acceso de Hugging Face. Copia el token más reciente y, luego, implementa un extremo nuevo.
Problema habitual 3: Se necesita una plantilla de chat
Los errores de plantilla de chat se producen cuando ya no se permite la plantilla de chat predeterminada y se debe proporcionar una plantilla de chat personalizada si el tokenizador no define una.
En esta captura de pantalla, se muestra una entrada de registro en el Explorador de registros de Google Cloud, en la que se produce un ValueError debido a la falta de una plantilla de chat en la versión 4.44 de la biblioteca de Transformers. El mensaje de error indica que la plantilla de chat predeterminada ya no está permitida y que se debe proporcionar una plantilla de chat personalizada si el tokenizador no define una. Este error destaca un cambio reciente en la biblioteca que requiere la definición explícita de una plantilla de chat, lo que resulta útil para depurar problemas cuando se implementan aplicaciones basadas en chat.
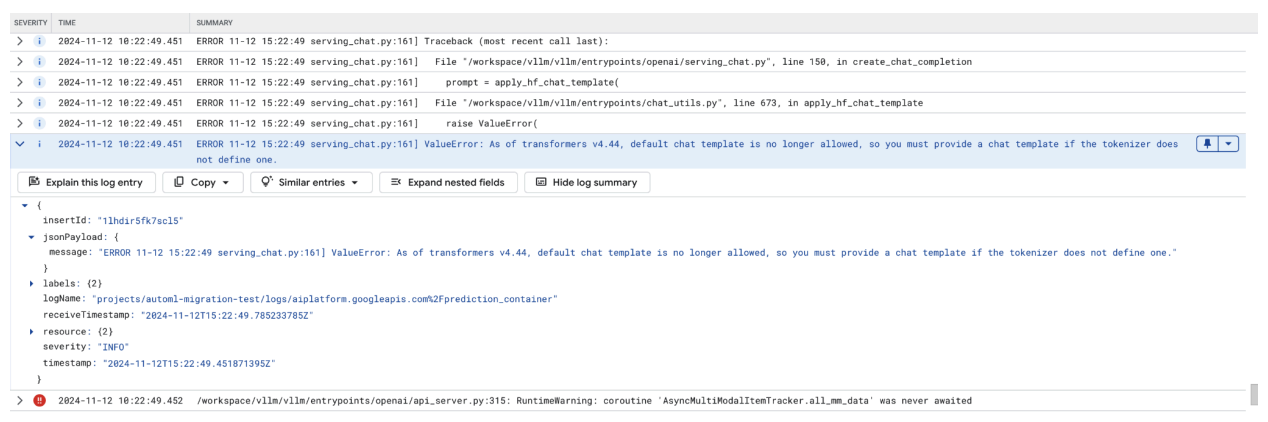 Figura 11: Se necesita una plantilla de chat
Figura 11: Se necesita una plantilla de chat
Para evitar esto, asegúrate de proporcionar una plantilla de chat durante la implementación con el argumento de entrada --chat-template. Puedes encontrar plantillas de ejemplo en el repositorio de ejemplos de vLLM.
Problema habitual 4: Longitud máxima de secuencia del modelo
Los errores de longitud máxima de secuencia del modelo se producen cuando la longitud máxima de secuencia del modelo (4096) es mayor que la cantidad máxima de tokens que se pueden almacenar en la caché de KV (2256).
 Figura 12: Max Seq Length too Large
Figura 12: Max Seq Length too Large
ValueError: La longitud máxima de secuencia del modelo (4096) es mayor que la cantidad máxima de tokens que se pueden almacenar en la caché de KV (2256). Intenta aumentar gpu_memory_utilization o disminuir max_model_len cuando inicialices el motor.
Para resolver este problema, establece max_model_len en 2048, que es inferior a 2256. Otra solución para este problema es usar más GPUs o GPUs más grandes. Si optas por usar más GPUs, deberás configurar tensor-parallel-size de forma adecuada.
Notas de la versión del contenedor de vLLM de Model Garden
Versiones principales
vLLM estándar
Fecha de lanzamiento |
Arquitectura |
Versión de vLLM |
URI del contenedor |
|---|---|---|---|
| 17 de julio de 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 de julio de 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 de junio de 2025 | x86 |
Después de la versión 0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 de junio de 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 de junio de 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 de mayo de 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 29 de abril de 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17 de abril de 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 10 de abril de 2025 | x86 |
Después de la versión 0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| Apr 7, 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| Apr 7, 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5 de abril de 2025 | x86 |
Después de la versión 0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 de marzo de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 de marzo de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23 de marzo de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 de marzo de 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11 de marzo de 2025 | x86 |
Después de la versión 0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3 de marzo de 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 de enero de 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 de diciembre de 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 de noviembre de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 de octubre de 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM optimizado
Fecha de lanzamiento |
Arquitectura |
URI del contenedor |
|---|---|---|
| Jan 21, 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 de octubre de 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Lanzamientos adicionales
La lista completa de versiones de contenedores estándar de vLLM de VMG se encuentra en la página de Artifact Registry.
Las versiones de vLLM-TPU en estado experimental se etiquetan con <yyyymmdd_hhmm_tpu_experimental_RC00>.