이 튜토리얼에서는 Vertex AI에 Meta-Llama-3.1-8B 모델을 배포하는 방법을 안내합니다. 엔드포인트를 배포하고 특정 요구사항에 맞게 최적화하는 방법을 알아보게 될 것입니다. 내결함성 워크로드가 있는 경우 스팟 VM을 사용하여 비용을 최적화할 수 있습니다. 가용성을 보장하려면 Compute Engine 예약을 사용하세요. 다음을 활용하는 엔드포인트를 배포하는 방법을 알아봅니다.
- 스팟 VM: 스팟 프로비저닝 인스턴스를 사용하여 상당한 비용을 절감합니다.
- 예약: 특히 프로덕션 워크로드의 경우 예측 가능한 성능을 위해 리소스 가용성을 보장합니다. 이 튜토리얼에서는 자동(
ANY_RESERVATION) 및 특정(SPECIFIC_RESERVATION) 예약을 사용하는 방법을 보여줍니다.
자세한 내용은 Spot VM 또는 Compute Engine 리소스 예약을 참조하세요.
기본 요건
시작하기 전에 다음의 사건 요건을 완료하세요.
- 결제가 사용 설정된 Google Cloud 프로젝트가 있어야 합니다.
- Vertex AI 및 Compute Engine API가 사용 설정되어 있어야 합니다.
- 사용할 머신 유형 및 가속기(예: NVIDIA L4 GPU)에 할당량이 충분해야 합니다. 할당량을 확인하려면 Google Cloud 콘솔의 할당량 및 시스템 한도를 참조하세요.
- 읽기 권한이 있는 Hugging Face 계정 및 사용자 액세스 토큰이 준비되어 있어야 합니다.
- 공유 예약을 사용하는 경우 프로젝트 간에 IAM 권한을 부여해야 합니다. 이러한 권한은 모두 노트북에 설명되어 있습니다.
스팟 VM에 배포
다음 섹션에서는 Google Cloud 프로젝트를 설정하고, Hugging Face 인증을 구성하고, Spot VM 또는 예약을 사용하여 Llama-3.1 모델을 배포하고, 배포를 테스트하는 과정을 안내합니다.
1. Google Cloud 프로젝트 및 공유 예약 설정
Colab Enterprise 노트북을 엽니다.
첫 번째 섹션에서 Colab 노트북의 PROJECT_ID, SHARED_PROJECT_ID(해당하는 경우), BUCKET_URI, REGION 변수를 설정합니다.
노트북은 두 프로젝트의 서비스 계정에 compute.viewer 역할을 부여합니다.
동일한 조직 내의 다른 프로젝트에서 생성된 예약을 사용하려면 양쪽 프로젝트의 P4SA(주요 서비스 계정)에 compute.viewer 역할을 부여해야 합니다. 노트북 코드는 이를 자동화하지만 SHARED_PROJECT_ID가 올바르게 설정되어 있는지 확인하세요. 이 교차 프로젝트 권한을 사용하면 기본 프로젝트의 Vertex AI 엔드포인트가 공유 프로젝트의 예약 용량을 보고 사용할 수 있습니다.
2. Hugging Face 인증 설정
Llama-3.1 모델을 다운로드하려면 Colab 노트북 내 HF_TOKEN 변수에 Hugging Face 사용자 액세스 토큰을 제공해야 합니다. 제공하지 않으면 Cannot access gated repository for URL 오류가 발생합니다.
 그림 1: Hugging Face 액세스 토큰 설정
그림 1: Hugging Face 액세스 토큰 설정
3. Spot VM으로 배포
Llama 모델을 스팟 VM에 배포하려면 Colab 노트북의 '스팟 VM Vertex AI 엔드포인트 배포' 섹션으로 이동하여 is_spot=True를 설정합니다.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
공유 예약 인스턴스에 배포
다음 섹션에서는 공유 예약을 만들고, 예약 설정을 구성하고, ANY_RESERVATION 또는 SPECIFIC_RESERVATION을 사용하여 Llama-3.1 모델을 배포하고, 배포를 테스트하는 과정을 안내합니다.
1. 공유 예약 만들기
예약을 구성하려면 노트북의 'Vertex AI 예측 예약 설정' 섹션으로 이동합니다. RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE, RES_ACCELERATOR_COUNT 등 예약에 필요한 변수를 설정합니다.
RES_ZONE을 {REGION}-{availability_zone}으로 설정해야 합니다.
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. 예약 공유
예약에는 단일 프로젝트 예약(기본값)과 공유 예약이라는 두 가지 유형이 있습니다. 단일 프로젝트 예약은 예약 자체와 동일한 프로젝트 내의 VM에서만 사용할 수 있습니다. 반면 공유 예약은 예약이 있는 프로젝트의 VM과 예약이 공유된 다른 프로젝트의 VM에서 사용할 수 있습니다. 공유 예약을 활용하면 예약된 리소스의 사용률을 개선하고 만들고 관리해야 하는 전체 예약 수를 줄일 수 있습니다. 이 튜토리얼에서는 공유 예약을 중점적으로 다룹니다. 자세한 내용은 공유 예약 작동 방법을 참조하세요.
계속하기 전에 그림과 같이 Google Cloud 콘솔에서 '다른 Google 서비스와 공유'를 선택해야 합니다.
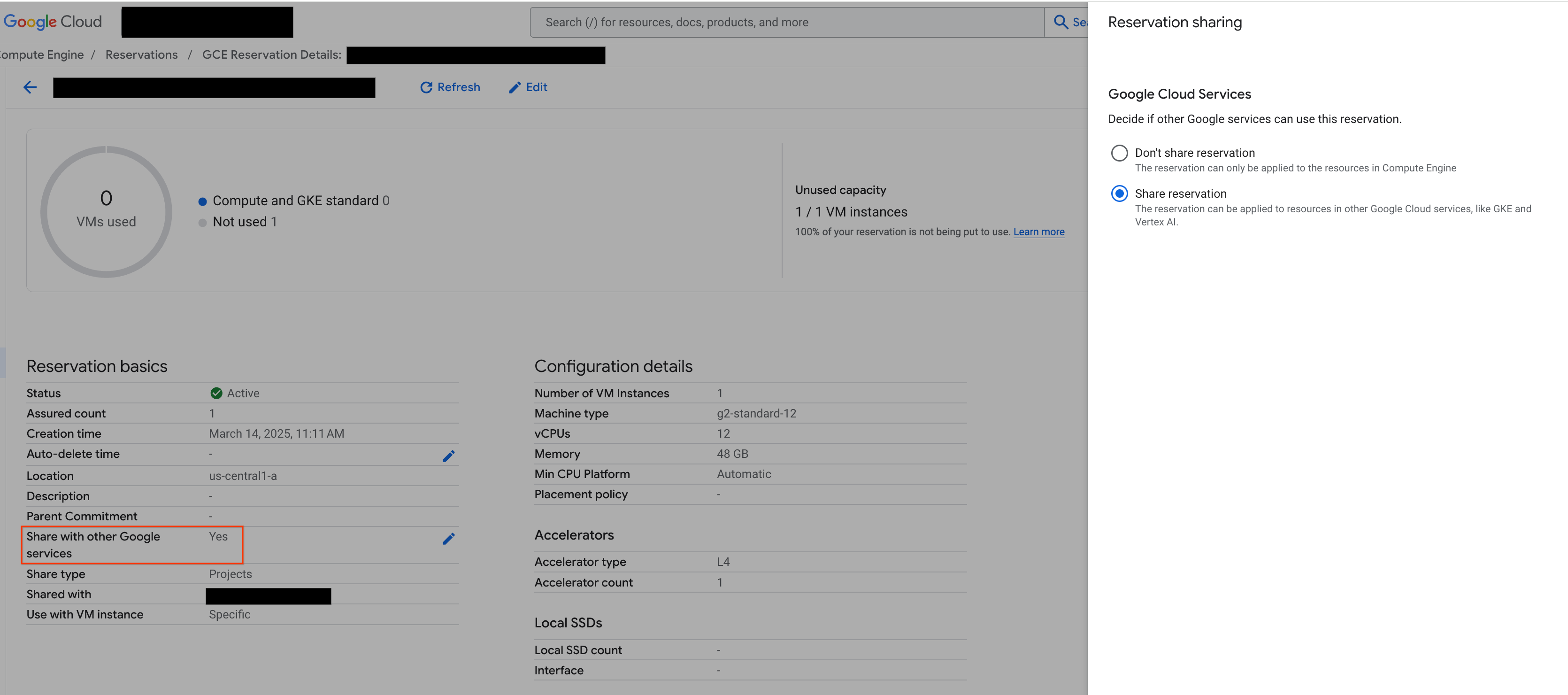 그림 2: 다른 Google 서비스와 예약 공유
그림 2: 다른 Google 서비스와 예약 공유
3. ANY_RESERVATION으로 배포
ANY_RESERVATION을 사용하여 엔드포인트를 배포하려면 노트북의 'ANY_RESERVATION을 사용하여 Llama-3.1 엔드포인트 배포' 섹션으로 이동합니다. 배포 설정을 지정한 다음 reservation_affinity_type="ANY_RESERVATION"을 설정합니다. 그런 다음 셀을 실행하여 엔드포인트를 배포하세요.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. ANY_RESERVATION 엔드포인트 테스트
엔드포인트가 배포되면 몇 가지 프롬프트를 테스트하여 엔드포인트가 올바르게 배포되었는지 확인합니다.
5. SPECIFIC_RESERVATION으로 배포
SPECIFIC_RESERVATION을 사용하여 엔드포인트를 배포하려면 노트북의 'SPECIFIC_RESERVATION을 사용하여 Llama-3.1 엔드포인트 배포' 섹션으로 이동합니다. 파라미터 reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project, reservation_zone을 지정합니다. 그런 다음 셀을 실행하여 엔드포인트를 배포하세요.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. SPECIFIC_RESERVATION 엔드포인트 테스트
엔드포인트가 배포되면 Vertex AI 온라인 예측에서 예약을 사용하는지 확인하고 프롬프트를 몇 개 테스트하여 올바르게 배포되었는지 확인합니다.
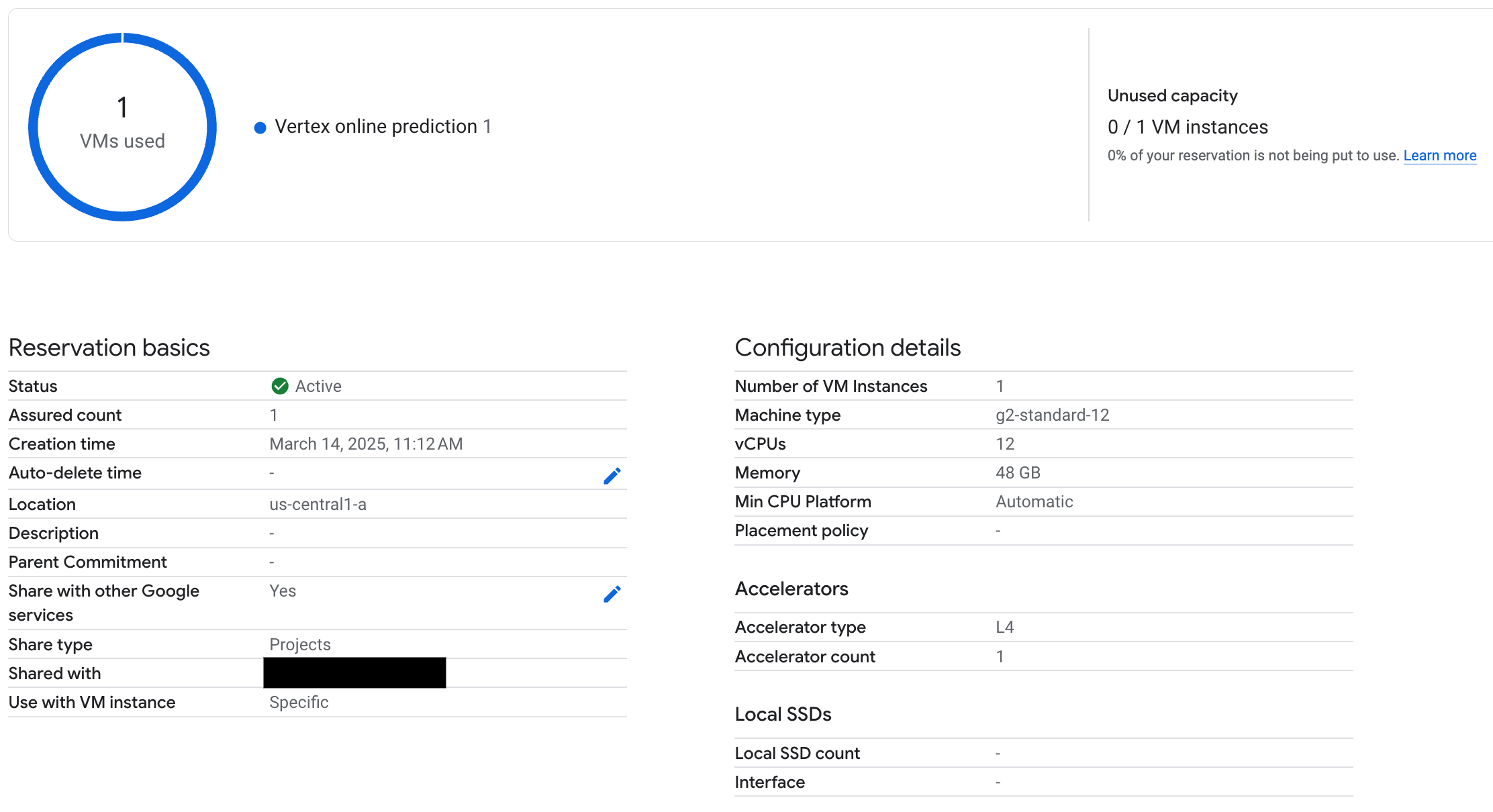 그림 3: Vertex 온라인 예측에서 예약이 사용되는지 확인
그림 3: Vertex 온라인 예측에서 예약이 사용되는지 확인
7. 삭제
요금이 계속 청구되지 않도록 하려면 이 튜토리얼에서 만든 모델, 엔드포인트, 예약을 삭제합니다. Colab 노트북의 '정리' 섹션에는 이 정리 프로세스를 자동화하는 코드가 제공됩니다.
문제 해결
- Hugging Face 토큰 오류: Hugging Face 토큰에
read권한이 있고 노트북에 올바르게 설정되어 있는지 다시 한번 확인합니다. - 할당량 오류: 배포하려는 리전에 GPU 할당량이 충분한지 확인합니다. 필요한 경우 할당량 상향 조정을 요청합니다.
- 예약 충돌: 엔드포인트 배포의 머신 유형 및 가속기 구성이 예약 설정과 일치하는지 확인합니다. 예약을 Google 서비스와 공유하도록 사용 설정했는지 확인하세요.
다음 단계
- 다양한 Llama 3 모델 변형 살펴보기
- Compute Engine 예약 개요에서 예약에 대해 자세히 알아보기
- 스팟 VM 개요에서 스팟 VM에 대해 자세히 알아보기