Questo tutorial descrive la procedura per eseguire il deployment del modello Meta-Llama-3.1-8B su Vertex AI. Scoprirai come eseguire il deployment degli endpoint e ottimizzare in base alle tue esigenze specifiche. Se hai carichi di lavoro a tolleranza di errore, puoi ottimizzare i costi utilizzando le VM spot. Se vuoi assicurarti la disponibilità, utilizza le prenotazioni Compute Engine. Imparerai a eseguire il deployment di endpoint che utilizzano:
- VM spot:utilizza le istanze con provisioning spot per risparmiare in modo significativo sui costi.
- Prenotazioni:garantiscono la disponibilità delle risorse per prestazioni prevedibili, in particolare per i carichi di lavoro di produzione. Questo tutorial mostra come utilizzare prenotazioni automatiche (
ANY_RESERVATION) e specifiche (SPECIFIC_RESERVATION).
Per ulteriori informazioni, consulta VM spot o Prenotazioni di risorse Compute Engine.
Prerequisiti
Prima di iniziare, completa i seguenti prerequisiti:
- Un progetto Google Cloud con la fatturazione abilitata.
- Le API Vertex AI e Compute Engine abilitate.
- Una quota sufficiente per il tipo di macchina e l'acceleratore che intendi utilizzare, ad esempio le GPU NVIDIA L4. Per controllare le quote, consulta Quote e limiti di sistema nella Google Cloud console.
- Un account Hugging Face e un token di accesso utente con accesso in lettura.
- Se utilizzi prenotazioni condivise, concedi le autorizzazioni IAM tra i progetti. Queste autorizzazioni sono tutte trattate nel notebook.
Esegui il deployment su VM Spot
Le sezioni seguenti illustrano la procedura di configurazione del Google Cloud progetto, di configurazione dell'autenticazione di Hugging Face, di deployment del modello Llama-3.1 utilizzando le VM o le prenotazioni di Spot e di test del deployment.
1. Configura il Google Cloud progetto e la prenotazione condivisa
Apri il notebook di Colab Enterprise.
Nella prima sezione, imposta le variabili PROJECT_ID, SHARED_PROJECT_ID (se applicabile), BUCKET_URI e REGION nel notebook di Colab.
Il notebook concede il ruolo compute.viewer all'account di servizio di entrambi i progetti.
Se intendi utilizzare una prenotazione creata in un progetto diverso all'interno della stessa organizzazione, assicurati di concedere il ruolo compute.viewer all'account di servizio principale (P4SA) di entrambi i progetti. Il codice del notebook eseguirà l'automazione, ma assicurati che SHARED_PROJECT_ID sia impostato correttamente. Questa autorizzazione tra progetti consente all'endpoint Vertex AI nel progetto principale di visualizzare e utilizzare la capacità di prenotazione nel progetto condiviso.
2. Configurare l'autenticazione volti con abbraccio
Per scaricare il modello Llama-3.1, devi fornire il tuo token di accesso utente Hugging Face nella variabile HF_TOKEN all'interno del notebook di Colab. Se non ne fornisci uno, viene visualizzato il seguente errore: Cannot access gated repository for URL.
 Figura 1: impostazioni del token di accesso a Hugging Face
Figura 1: impostazioni del token di accesso a Hugging Face
3. Esegui il deployment con una VM Spot
Per eseguire il deployment del modello Llama in una VM Spot, vai alla sezione "Deployment dell'endpoint Vertex AI della VM Spot" nel notebook Colab e imposta is_spot=True.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
Esegui il deployment su istanze di prenotazione condivise
Le sezioni seguenti illustrano la procedura per creare una prenotazione condivisa, configurare le impostazioni di prenotazione, eseguire il deployment del modello Llama-3.1 utilizzando ANY_RESERVATION o SPECIFIC_RESERVATION e testare il deployment.
1. Creare una prenotazione condivisa
Per configurare le prenotazioni, vai alla sezione "Configura le prenotazioni per le previsioni di Vertex AI" del notebook. Imposta le variabili richieste per la prenotazione, ad esempio RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE e RES_ACCELERATOR_COUNT.
Devi impostare RES_ZONE su {REGION}-{availability_zone}
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. Condividere le prenotazioni
Esistono due tipi di prenotazioni: prenotazioni per un singolo progetto (predefinite) e prenotazioni condivise. Le prenotazioni per un singolo progetto possono essere utilizzate solo dalle VM all'interno dello stesso progetto della prenotazione stessa. Le prenotazioni condivise, invece, possono essere utilizzate dalle VM del progetto in cui si trova la prenotazione, nonché dalle VM di qualsiasi altro progetto con cui la prenotazione è stata condivisa. L'utilizzo delle prenotazioni condivise può migliorare l'utilizzo delle risorse prenotate e ridurre il numero complessivo di prenotazioni da creare e gestire. Questo tutorial è incentrato sulle prenotazioni condivise. Per saperne di più, vedi Come funzionano le prenotazioni condivise.
Prima di procedere, assicurati di selezionare "Condividi con altri servizi Google" dalla Google Cloud console, come mostrato nella figura:
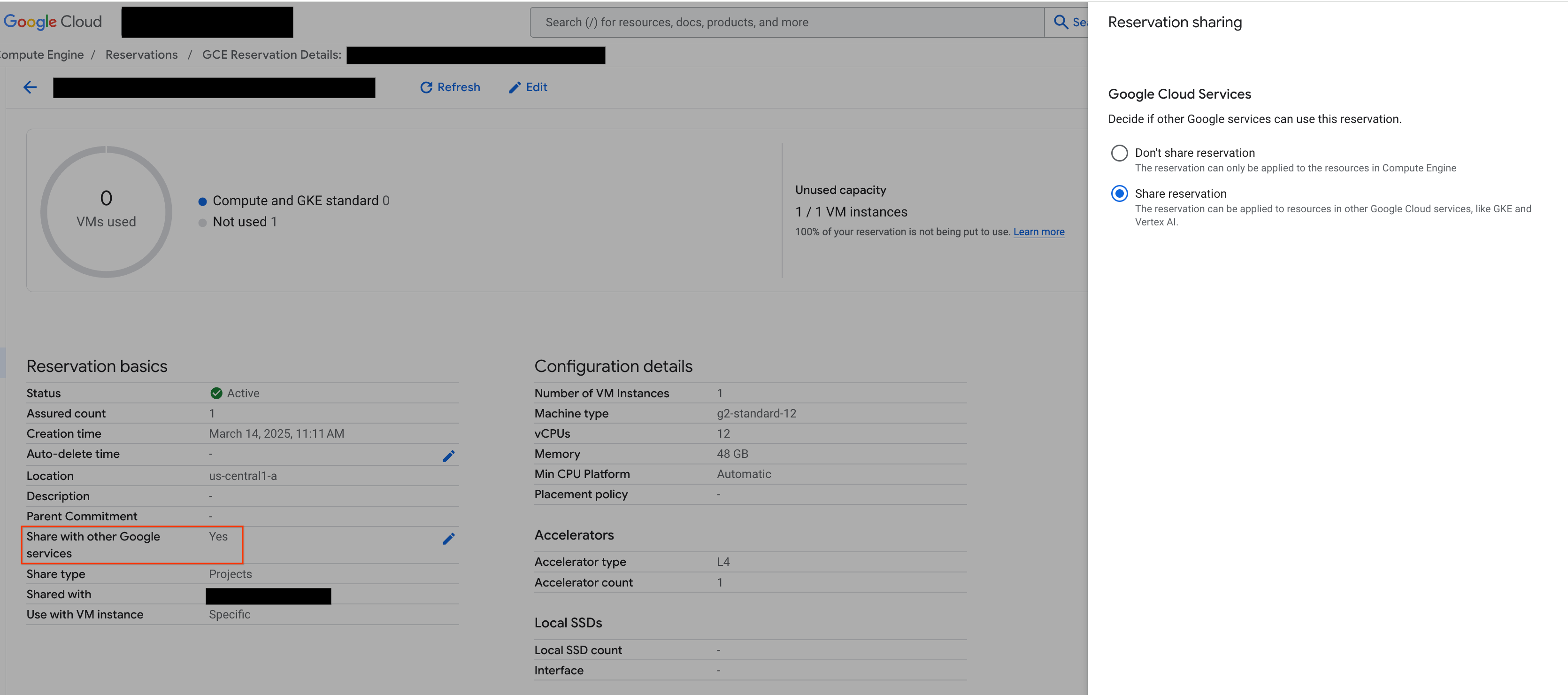 Figura 2: Condividere la prenotazione con altri servizi Google
Figura 2: Condividere la prenotazione con altri servizi Google
3. Esegui il deployment con ANY_RESERVATION
Per eseguire il deployment dell'endpoint utilizzando ANY_RESERVATION, vai alla sezione "Esegui il deployment dell'endpoint Llama-3.1 con ANY_RESERVATION" del notebook. Specifica le impostazioni di deployment e imposta reservation_affinity_type="ANY_RESERVATION". Quindi, esegui la cella per eseguire il deployment dell'endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. Testa l'endpoint ANY_RESERVATION
Dopo aver eseguito il deployment dell'endpoint, assicurati di testare alcuni prompt per verificare che sia stato eseguito correttamente.
5. Esegui il deployment con SPECIFIC_RESERVATION
Per eseguire il deployment dell'endpoint utilizzando SPECIFIC_RESERVATION, vai alla sezione "Esegui il deployment dell'endpoint Llama-3.1 con SPECIFIC_RESERVATION" del notebook. Specifica i seguenti parametri: reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project e reservation_zone. Quindi, esegui la cella per eseguire il deployment dell'endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. Testa l'endpoint SPECIFIC_RESERVATION
Dopo aver eseguito il deployment dell'endpoint, verifica che la prenotazione venga utilizzata dalla previsione online di Vertex AI e assicurati di testare alcuni prompt per verificare che il deployment sia stato eseguito correttamente.
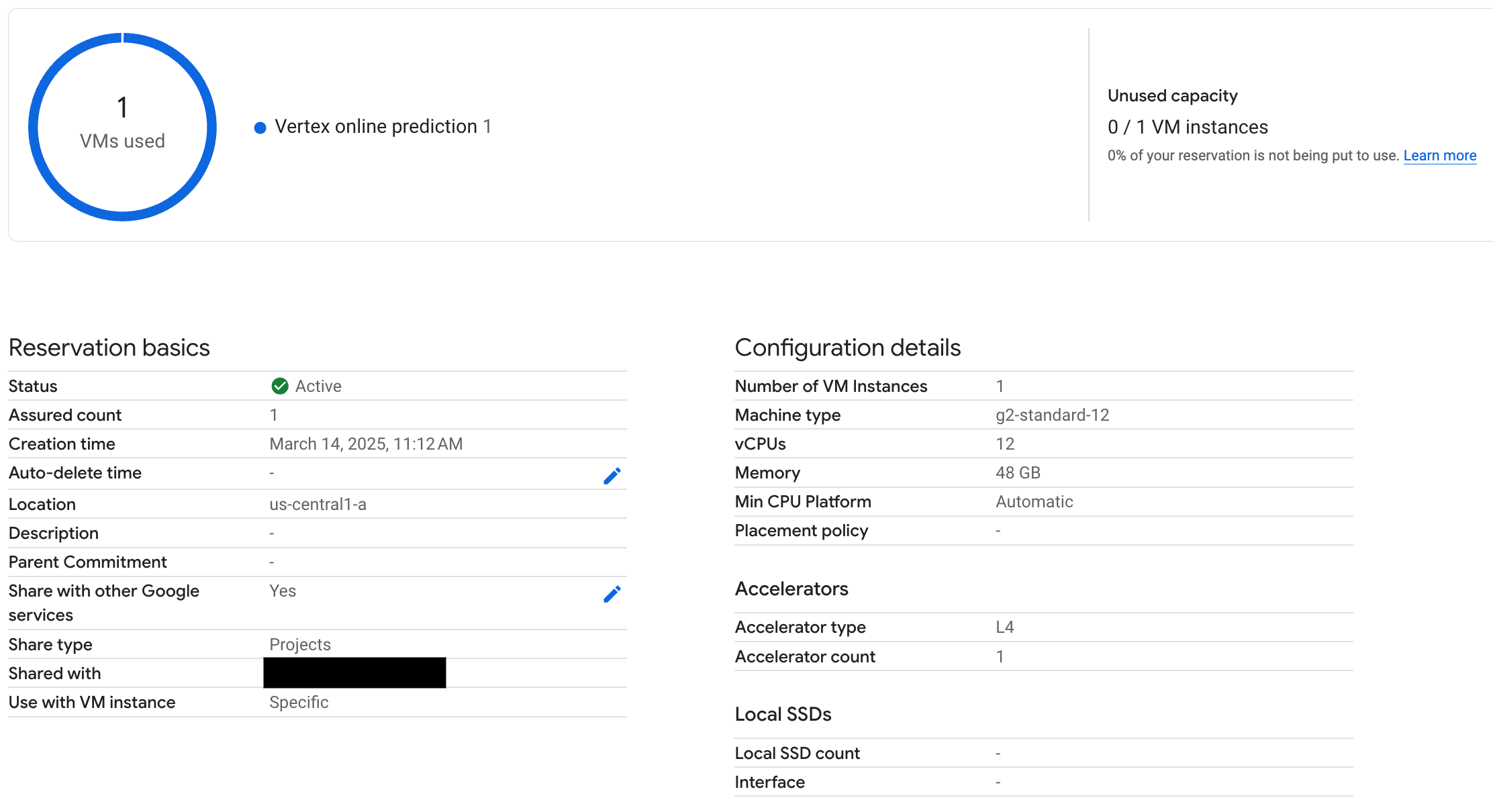 Figura 3: la prenotazione viene controllata dalla previsione online di Vertex
Figura 3: la prenotazione viene controllata dalla previsione online di Vertex
7. Esegui la pulizia
Per evitare addebiti continui, elimina i modelli, gli endpoint e le prenotazioni creati durante questo tutorial. Il notebook di Colab fornisce il codice nella sezione "Pulizia" per automatizzare questa procedura.
Risoluzione dei problemi
- Errori relativi al token Hugging Face: verifica che il token Hugging Face disponga delle autorizzazioni
reade che sia impostato correttamente nel notebook. - Errori di quota: verifica di disporre di una quota GPU sufficiente nella regione in cui esegui il deployment. Se necessario, richiedi un aumento della quota.
- Conflitti di prenotazione: assicurati che il tipo di macchina e la configurazione dell'acceleratore del deployment dell'endpoint corrispondano alle impostazioni della prenotazione. Assicurati che le prenotazioni siano abilitate per la condivisione con i servizi Google
Passaggi successivi
- Esplora le diverse varianti del modello Llama 3.
- Scopri di più sulle prenotazioni con questa panoramica delle prenotazioni di Compute Engine.
- Scopri di più sulle VM spot con questa panoramica delle VM spot.