En este tutorial se explica cómo desplegar el modelo Meta-Llama-3.1-8B en Vertex AI. Aprenderás a implementar endpoints y a optimizarlos para tus necesidades específicas. Si tienes cargas de trabajo tolerantes a fallos, puedes optimizar los costes usando máquinas virtuales de Spot. Si quieres asegurarte de que los recursos estén disponibles, usa las reservas de Compute Engine. Aprenderás a desplegar endpoints que utilicen lo siguiente:
- Máquinas virtuales de Spot: usa instancias aprovisionadas de acceso puntual para ahorrar costes de forma significativa.
- Reservas: garantiza la disponibilidad de recursos para ofrecer un rendimiento predecible, sobre todo en el caso de las cargas de trabajo de producción. En este tutorial se muestra cómo usar reservas automáticas (
ANY_RESERVATION) y específicas (SPECIFIC_RESERVATION).
Para obtener más información, consulta VMs de acceso puntual o Reservas de recursos de Compute Engine.
Requisitos previos
Antes de empezar, completa los siguientes requisitos previos:
- Un Google Cloud proyecto con la facturación habilitada.
- Las APIs de Vertex AI y Compute Engine están habilitadas.
- Cuota suficiente para el tipo de máquina y el acelerador que quieras usar, como las GPUs NVIDIA L4. Para consultar tus cuotas, consulta Cuotas y límites del sistema en la consola Google Cloud .
- Una cuenta de Hugging Face y un token de acceso de usuario con acceso de lectura.
- Si usas reservas compartidas, concede permisos de gestión de identidades y accesos entre proyectos. Todos esos permisos se explican en el cuaderno.
Despliega en máquinas virtuales de acceso puntual
En las siguientes secciones se explica cómo configurar tu Google Cloud proyecto, configurar la autenticación de Hugging Face, desplegar el modelo Llama 3.1 con VMs de Spot o reservas, y probar el despliegue.
1. Configurar tu Google Cloud proyecto y reserva compartida
Abre el cuaderno de Colab Enterprise.
En la primera sección, define las variables PROJECT_ID, SHARED_PROJECT_ID (si procede), BUCKET_URI y REGION en el cuaderno de Colab.
El cuaderno concede el rol compute.viewer a la cuenta de servicio de ambos proyectos.
Si tienes intención de usar una reserva que se haya creado en un proyecto diferente de la misma organización, asegúrate de asignar el rol compute.viewer a la cuenta de servicio principal (P4SA) de ambos proyectos. El código del cuaderno automatizará este proceso, pero asegúrate de que SHARED_PROJECT_ID esté configurado correctamente. Este permiso entre proyectos permite que el endpoint de Vertex AI de tu proyecto principal vea y use la capacidad de reserva del proyecto compartido.
2. Configurar la autenticación de Hugging Face
Para descargar el modelo Llama 3.1, debes proporcionar tu token de acceso de usuario de Hugging Face en la variable HF_TOKEN del cuaderno de Colab. Si no lo proporciona, recibirá el siguiente error: Cannot access gated repository for URL.
 Imagen 1: Configuración del token de acceso de Hugging Face
Imagen 1: Configuración del token de acceso de Hugging Face
3. Desplegar con una máquina virtual de acceso puntual
Para desplegar el modelo Llama en una VM de acceso puntual, ve a la sección "Spot VM Vertex AI Endpoint Deployment" (Despliegue de endpoint de Vertex AI de VM de acceso puntual) del cuaderno de Colab y define is_spot=True.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
Implementar en instancias de reserva compartidas
En las siguientes secciones se explica cómo crear una reserva compartida, configurar los ajustes de la reserva, desplegar el modelo Llama-3.1 con ANY_RESERVATION o SPECIFIC_RESERVATION y probar el despliegue.
1. Crear una reserva compartida
Para configurar las reservas, ve a la sección "Set Up Reservations for Vertex AI Predictions" (Configurar reservas para predicciones de Vertex AI) del cuaderno. Define las variables necesarias para la reserva, como RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE y RES_ACCELERATOR_COUNT.
Debes definir RES_ZONE como {REGION}-{availability_zone}
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. Compartir tus reservas
Hay dos tipos de reservas: las de un solo proyecto (el valor predeterminado) y las compartidas. Las reservas de un solo proyecto solo pueden usarse en VMs del mismo proyecto que la reserva. Por otro lado, las reservas compartidas pueden usarse en las VMs del proyecto en el que se encuentran, así como en las VMs de cualquier otro proyecto con el que se haya compartido la reserva. Si utilizas reservas compartidas, puedes mejorar el uso de los recursos reservados y reducir el número total de reservas que tienes que crear y gestionar. Este tutorial se centra en las reservas compartidas. Para obtener más información, consulta Cómo funcionan las reservas compartidas.
Antes de continuar, asegúrate de compartir con otros servicios de Google desde la Google Cloud consola, como se muestra en la figura:
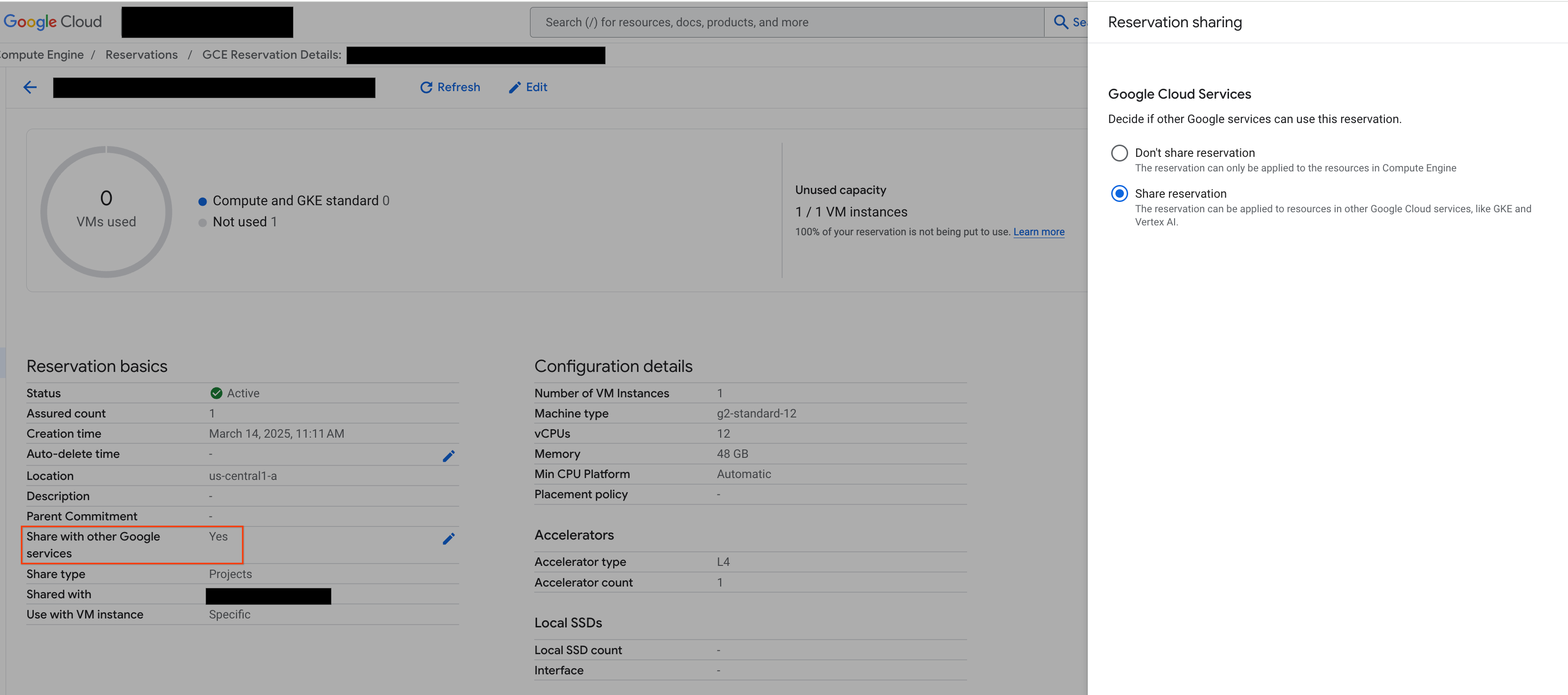 Imagen 2: Compartir una reserva con otros servicios de Google
Imagen 2: Compartir una reserva con otros servicios de Google
3. Desplegar con ANY_RESERVATION
Para desplegar el endpoint con ANY_RESERVATION, ve a la sección "Deploy Llama-3.1 Endpoint with ANY_RESERVATION" (Desplegar el endpoint de Llama-3.1 con ANY_RESERVATION) del cuaderno. Especifica los ajustes de implementación y, a continuación, define reservation_affinity_type="ANY_RESERVATION". A continuación, ejecuta la celda para implementar el endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. Probar el endpoint ANY_RESERVATION
Una vez que hayas implementado tu endpoint, prueba algunas peticiones para asegurarte de que se ha implementado correctamente.
5. Desplegar con SPECIFIC_RESERVATION
Para desplegar el endpoint con SPECIFIC_RESERVATION, ve a la sección "Deploy Llama-3.1 Endpoint with SPECIFIC_RESERVATION" (Desplegar el endpoint de Llama-3.1 con SPECIFIC_RESERVATION) del cuaderno. Especifique los siguientes parámetros: reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project y reservation_zone. A continuación, ejecuta la celda para implementar el endpoint.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. Prueba el endpoint SPECIFIC_RESERVATION
Una vez que hayas desplegado el endpoint, verifica que Vertex AI online prediction usa la reserva y prueba algunas peticiones para asegurarte de que se ha desplegado correctamente.
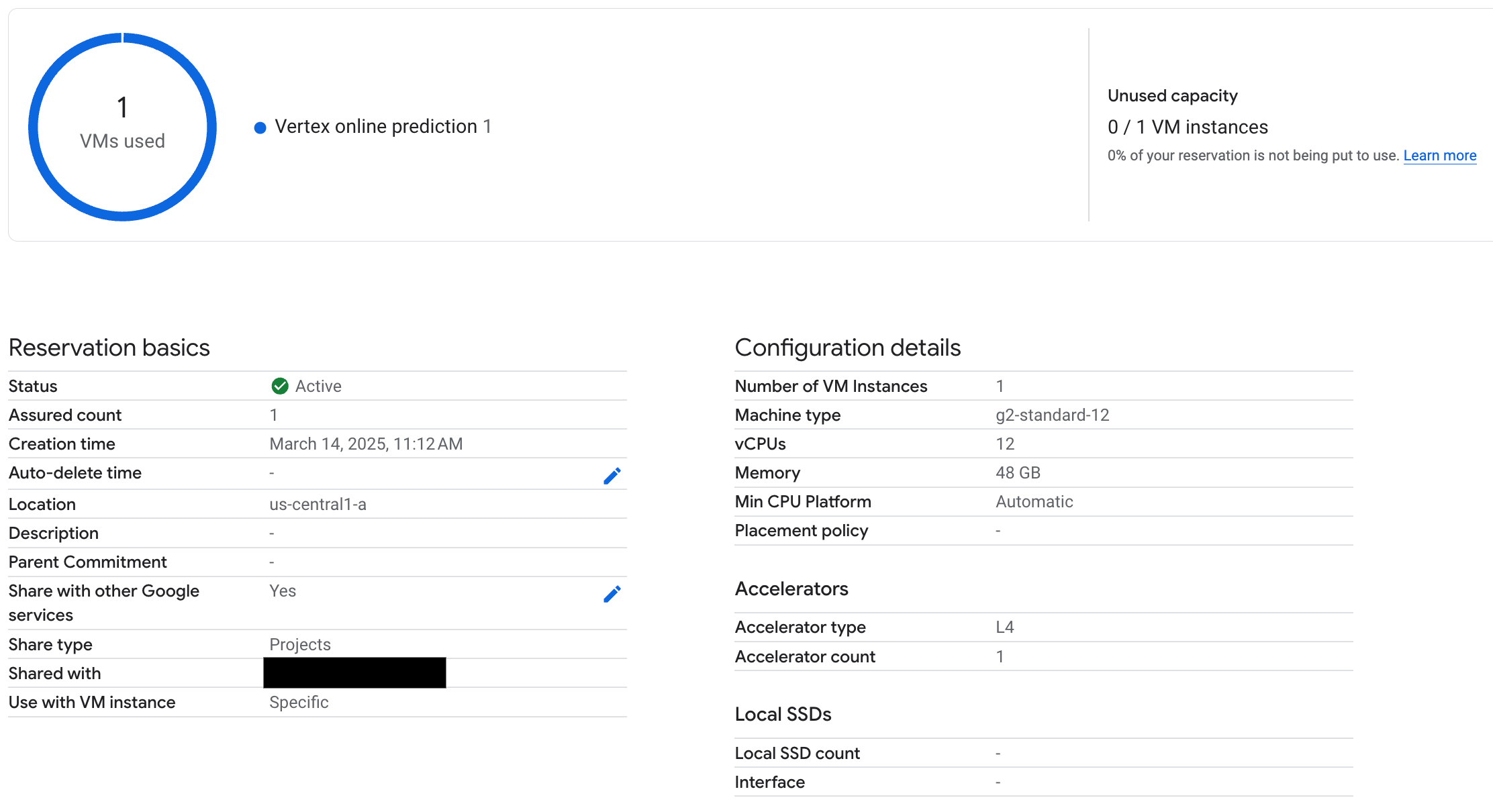 Figura 3: La comprobación de reservas se usa en la predicción online de Vertex
Figura 3: La comprobación de reservas se usa en la predicción online de Vertex
7. Limpieza
Para evitar que se te cobre, elimina los modelos, los endpoints y las reservas que hayas creado durante este tutorial. El cuaderno de Colab proporciona código en la sección "Clean Up" (Limpieza) para automatizar este proceso.
Solución de problemas
- Errores de token de Hugging Face: comprueba que tu token de Hugging Face tenga permisos
ready esté configurado correctamente en el cuaderno. - Errores de cuota: comprueba que tengas suficiente cuota de GPU en la región en la que vas a implementar. Solicita un aumento de la cuota si es necesario.
- Conflictos de reserva: asegúrate de que el tipo de máquina y la configuración del acelerador de tu implementación de endpoint coincidan con los ajustes de tu reserva. Asegúrate de que las reservas se puedan compartir con los servicios de Google
Pasos siguientes
- Consulta las diferentes variantes del modelo Llama 3.
- Consulta más información sobre las reservas en esta descripción general de las reservas de Compute Engine.
- Consulta más información sobre las máquinas virtuales de acceso puntual en este resumen.