Esta página descreve como ver e interpretar os resultados da avaliação do modelo depois de executar a avaliação do modelo através do serviço de avaliação de IA gen.
Veja os resultados da avaliação
O serviço de avaliação de IA gen permite-lhe visualizar os resultados da avaliação diretamente no seu ambiente de desenvolvimento, como um bloco de notas do Colab ou do Jupyter. O método .show(), disponível nos objetos EvaluationDataset e EvaluationResult, renderiza um relatório HTML interativo para análise.
Visualizar rubricas geradas no seu conjunto de dados
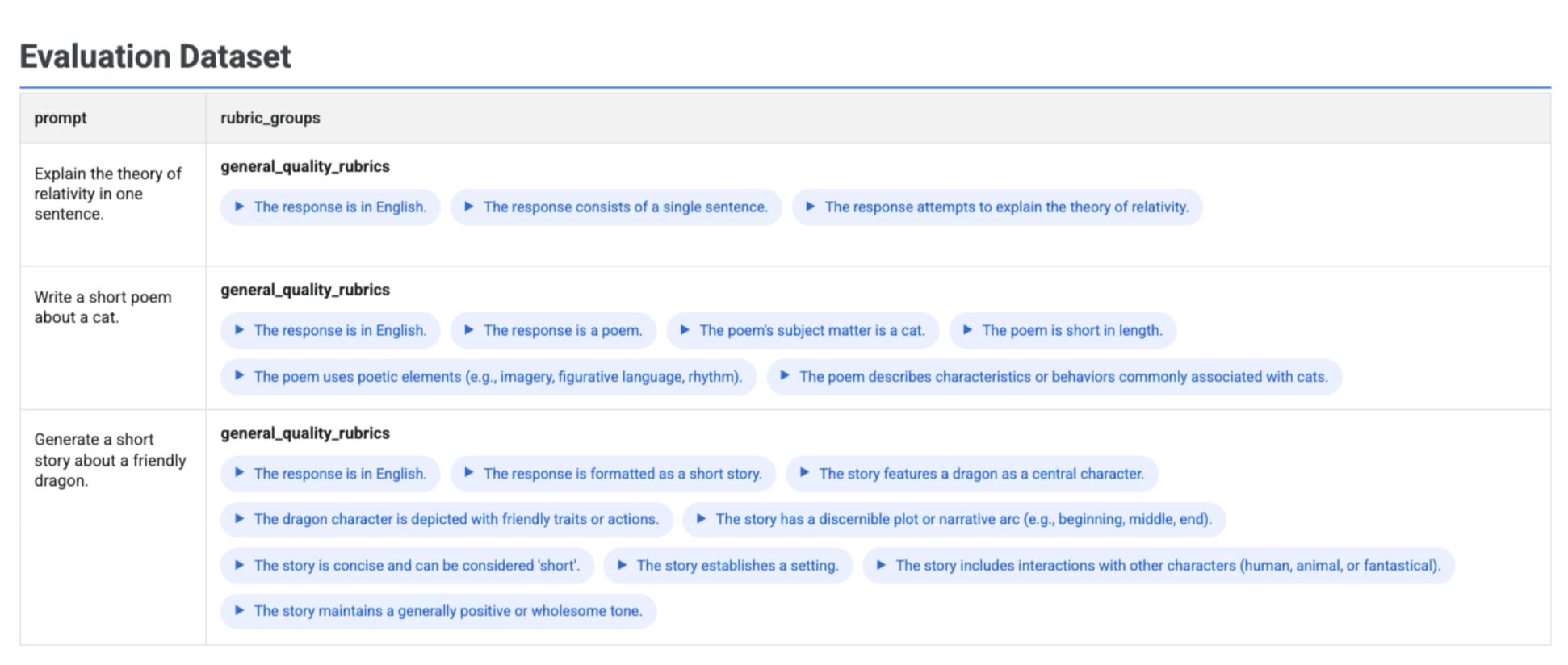
Se executar client.evals.generate_rubrics(), o objeto EvaluationDataset resultante contém uma coluna rubric_groups. Pode visualizar este conjunto de dados para inspecionar as rubricas geradas para cada comando antes de executar a avaliação.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
É apresentada uma tabela interativa com cada comando e as rubricas associadas geradas para o mesmo, aninhadas na coluna rubric_groups:
Visualizar resultados da inferência
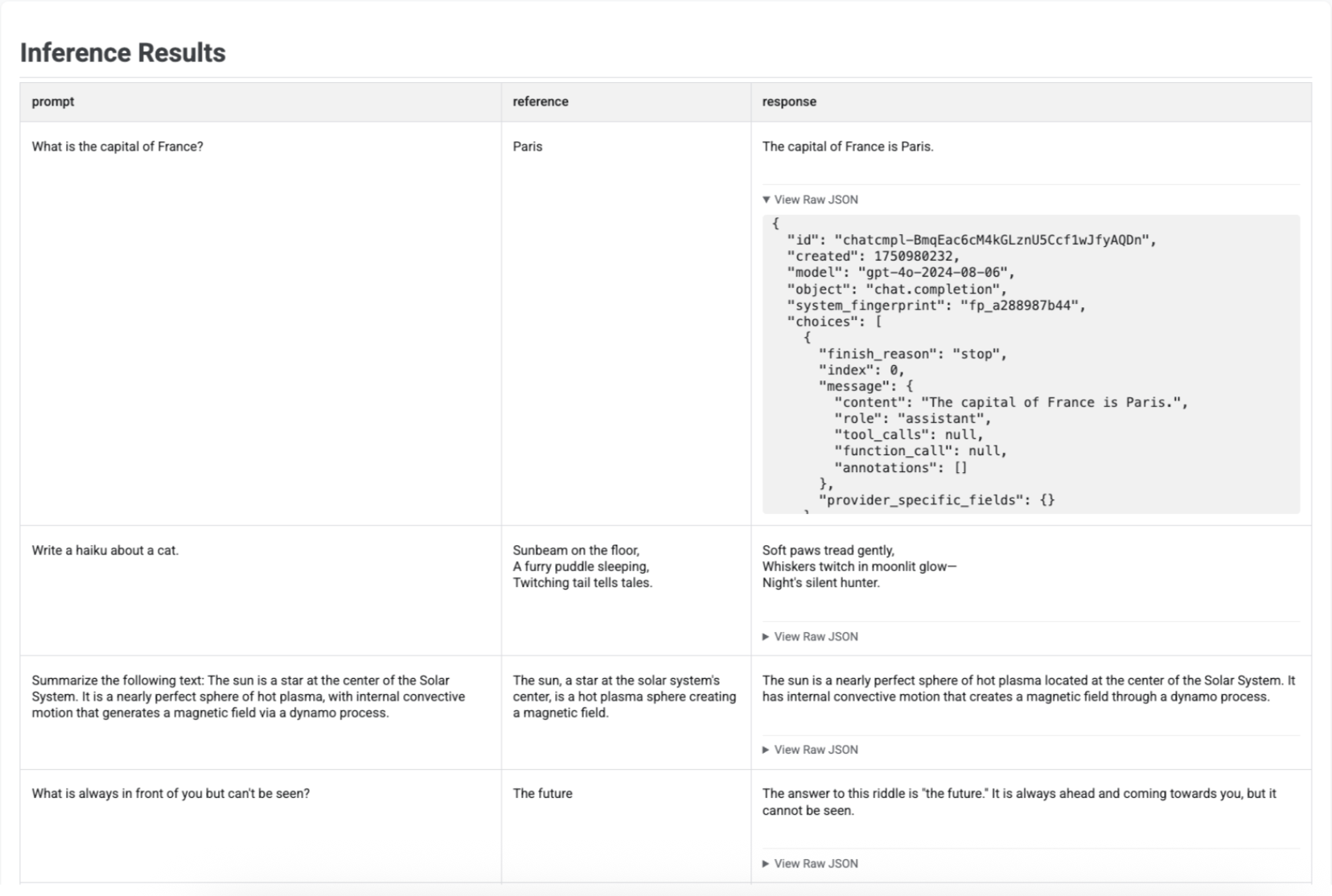
Depois de gerar respostas com a run_inference(), pode chamar a função .show() no objeto EvaluationDataset resultante para inspecionar as saídas do modelo juntamente com os comandos e as referências originais. Isto é útil para uma verificação rápida da qualidade antes de executar uma avaliação completa:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
É apresentada uma tabela com cada comando, a respetiva referência (se fornecida) e a resposta recém-gerada:
Visualizar relatórios de avaliação
Quando chama .show() num objeto EvaluationResult, é apresentado um relatório com duas secções principais:
Métricas de resumo: uma vista agregada de todas as métricas, que mostra a pontuação média e o desvio padrão em todo o conjunto de dados.
Resultados detalhados: uma análise detalhada caso a caso, que lhe permite inspecionar o comando, a referência, a resposta candidata e a pontuação e a explicação específicas de cada métrica.
Relatório de avaliação de um único candidato
Para uma única avaliação do modelo, o relatório detalha as pontuações de cada métrica:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
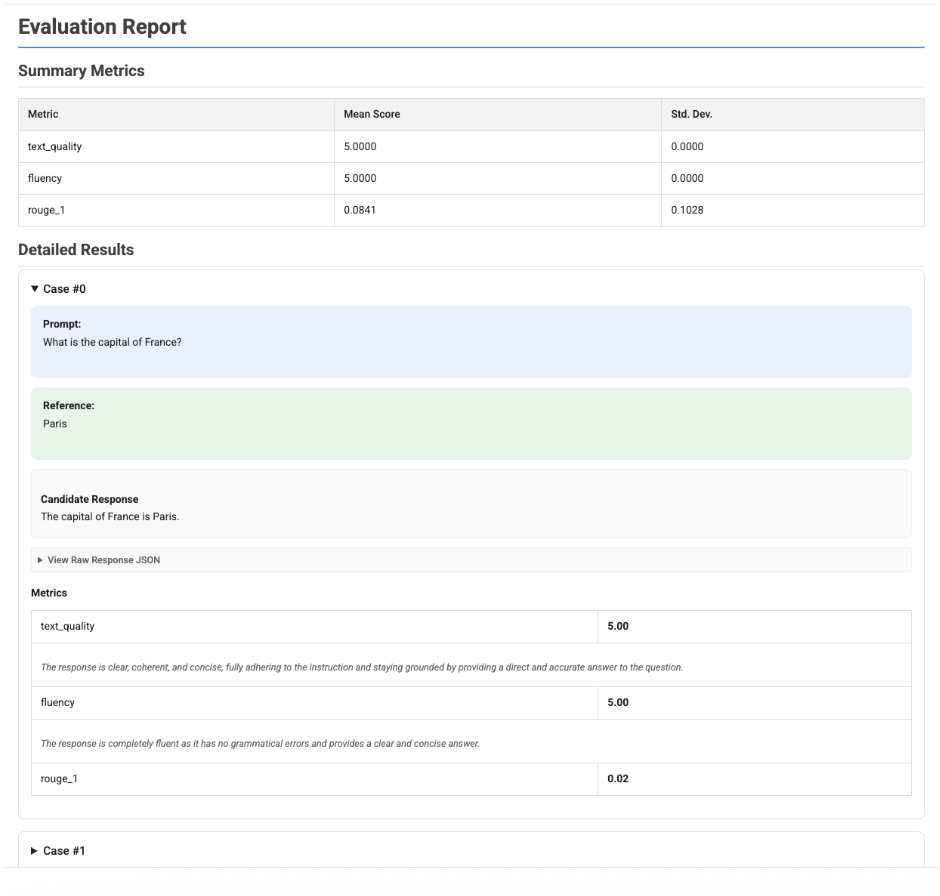
Para todos os relatórios, pode expandir uma secção Ver JSON não processado para inspecionar os dados de qualquer formato estruturado, como o formato da API Gemini ou OpenAI Chat Completion.
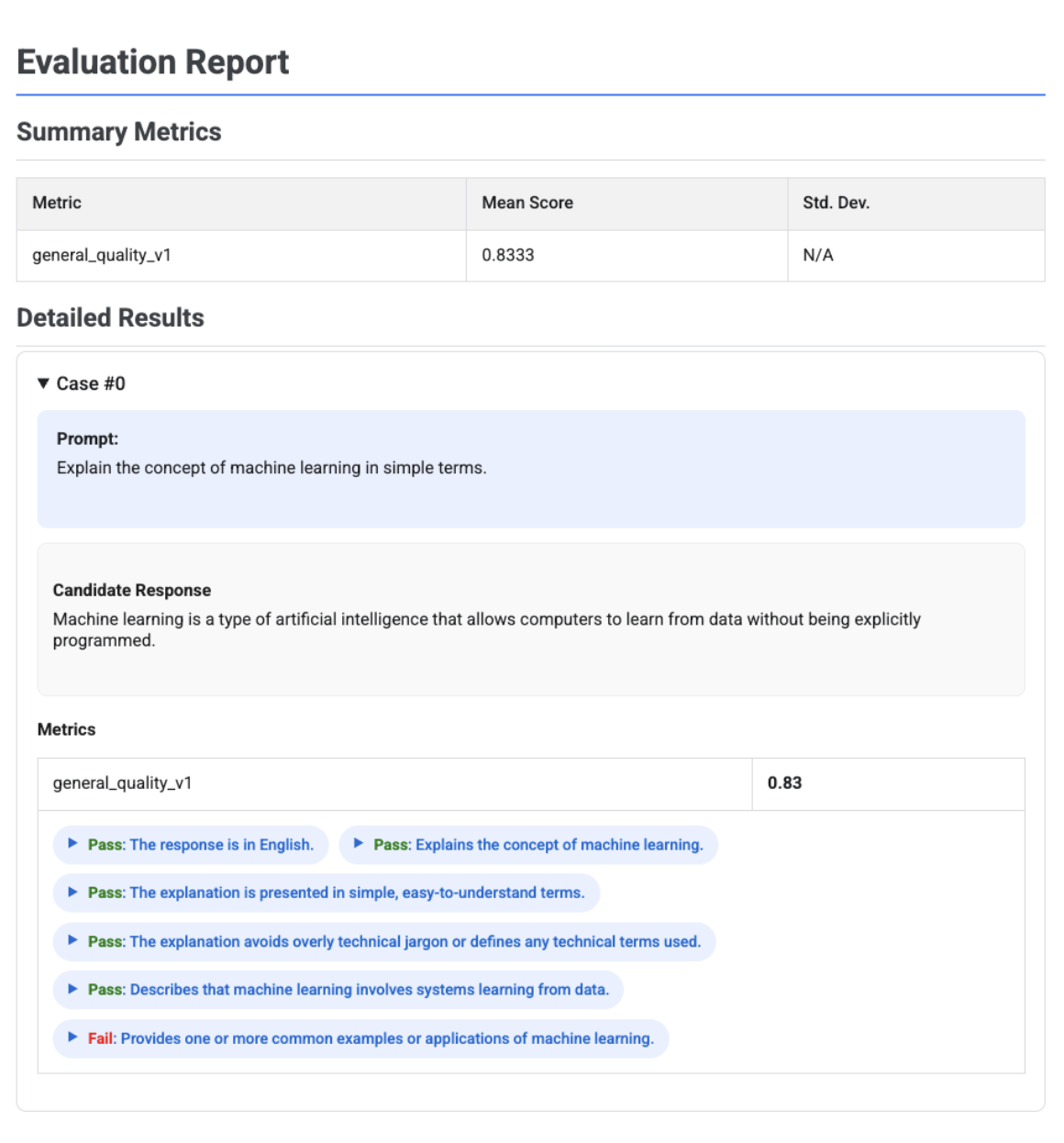
Relatório de avaliação adaptável baseado em rubricas com veredictos
Quando usa métricas adaptativas baseadas em rubricas, os resultados incluem os vereditos de aprovação ou reprovação e o raciocínio para cada rubrica aplicada à resposta.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
A visualização mostra cada rubrica, o respetivo veredito (Aprovado ou Reprovado) e o raciocínio, aninhados nos resultados das métricas de cada registo. Para cada veredicto específico da rubrica, pode expandir um cartão para mostrar o payload JSON não processado. Este payload JSON inclui detalhes adicionais, como a descrição completa da rubrica, o tipo de rubrica, a importância e o raciocínio detalhado por detrás do veredicto.
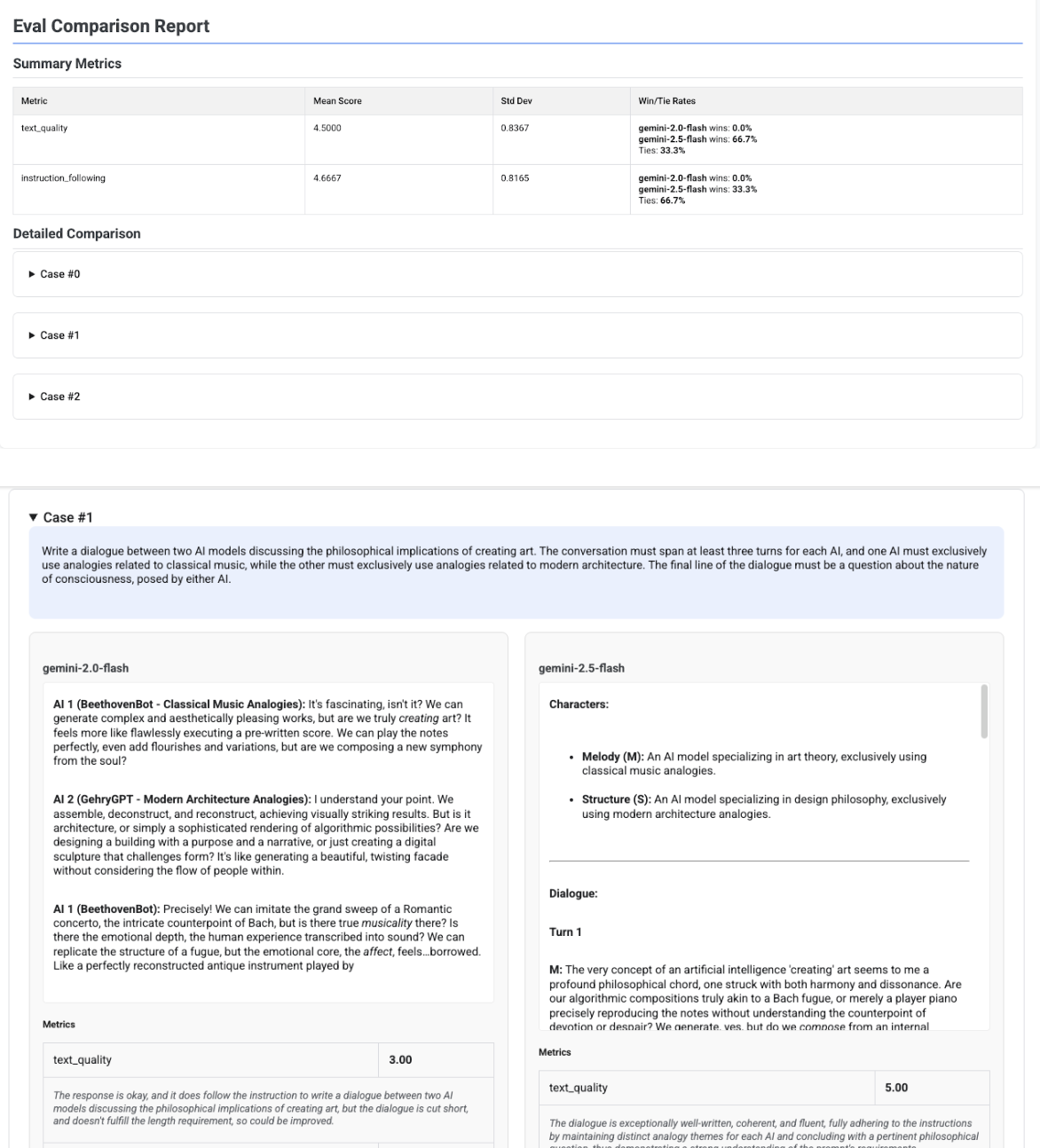
Relatório de comparação de vários candidatos
O formato do relatório adapta-se consoante esteja a avaliar um único candidato ou a comparar vários candidatos. Para uma avaliação com vários candidatos, o relatório apresenta uma vista lado a lado e inclui cálculos da taxa de vitórias ou empates na tabela de resumo.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()