이 페이지에서는 Gen AI Evaluation Service를 사용하여 모델 평가를 실행한 후 모델 평가 결과를 보고 해석하는 방법을 설명합니다.
평가 결과 보기
Gen AI Evaluation Service를 사용하면 Colab 또는 Jupyter 노트북과 같은 개발 환경 내에서 평가 결과를 직접 시각화할 수 있습니다. EvaluationDataset 및 EvaluationResult 객체에서 사용할 수 있는 .show() 메서드는 분석을 위한 대화형 HTML 보고서를 렌더링합니다.
데이터 세트에서 생성된 기준표 시각화
client.evals.generate_rubrics()를 실행하면 결과 EvaluationDataset 객체에 rubric_groups 열이 포함됩니다. 평가를 실행하기 전에 이 데이터 세트를 시각화하여 각 프롬프트에 대해 생성된 기준표를 검사할 수 있습니다.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
각 프롬프트와 프롬프트에 대해 생성된 관련 기준표가 rubric_groups 열 내에 중첩되어 양방향 테이블에 표시됩니다.

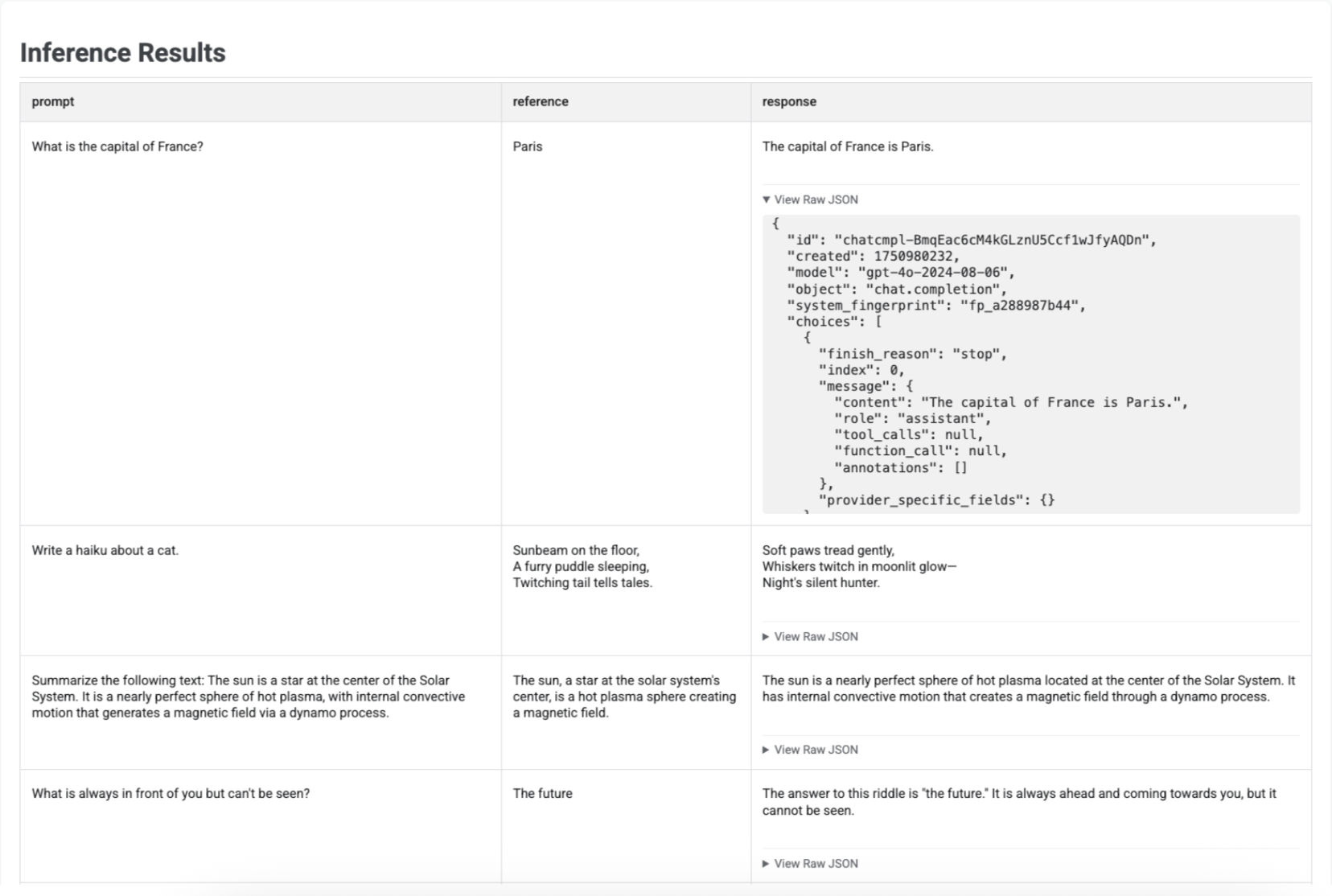
추론 결과 시각화
run_inference()로 응답을 생성한 후 결과 EvaluationDataset 객체에서 .show()를 호출하여 모델의 출력과 함께 원래 프롬프트 및 참조를 검사할 수 있습니다. 전체 평가를 실행하기 전에 빠른 품질 확인에 유용합니다.
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
각 프롬프트, 해당 참조(제공된 경우), 새로 생성된 대답이 표에 표시됩니다.
평가 보고서 시각화
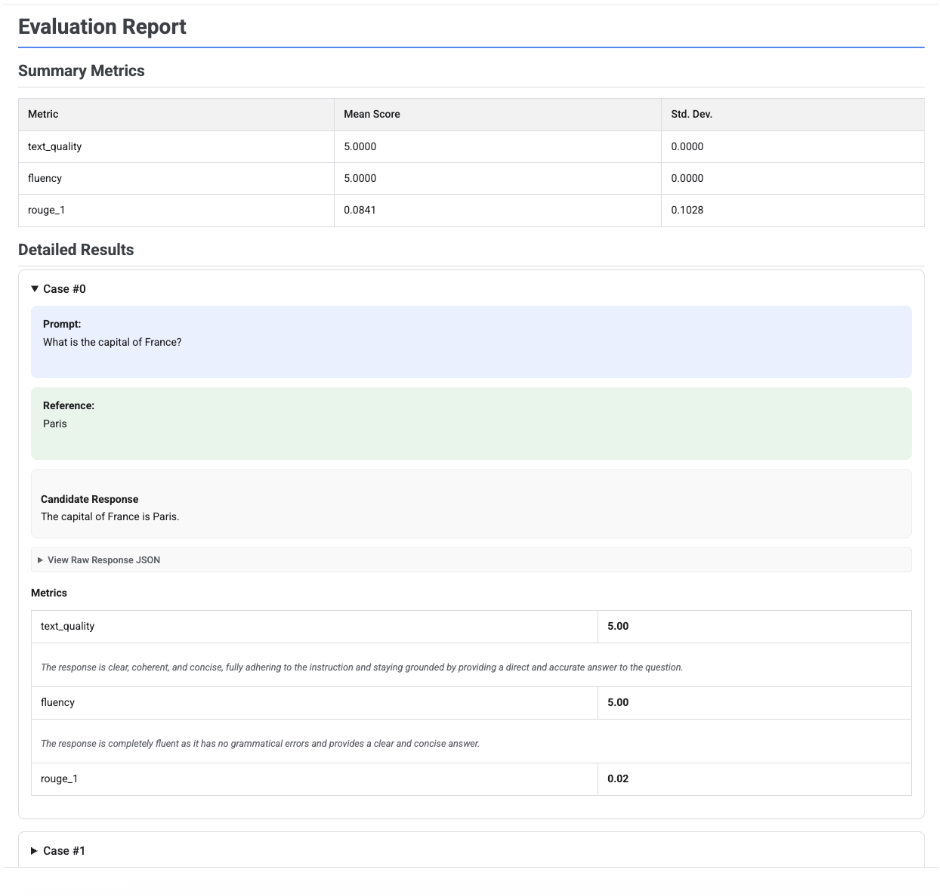
EvaluationResult 객체에서 .show()를 호출하면 다음과 같은 두 가지 주요 섹션이 포함된 보고서가 표시됩니다.
요약 측정항목: 모든 측정항목의 집계된 뷰로, 전체 데이터 세트의 평균 점수와 표준 편차를 보여줍니다.
세부 결과: 케이스별 분석을 통해 프롬프트, 참조, 후보 응답, 각 측정항목의 구체적인 점수와 설명을 검사할 수 있습니다.
단일 후보 평가 보고서
단일 모델 평가의 경우 보고서에 각 측정항목의 점수가 자세히 나와 있습니다.
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
모든 보고서에서 원시 JSON 보기 섹션을 펼쳐 Gemini 또는 OpenAI Chat Completion API 형식과 같은 구조화된 형식의 데이터를 검사할 수 있습니다.
확인 결과가 포함된 적응형 기준표 기반 평가 보고서
적응형 기준표 기반 측정항목을 사용하면 응답에 적용된 각 기준표의 통과 또는 실패 확인 결과와 이유가 결과에 포함됩니다.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
시각화에는 각 케이스의 측정항목 결과 내에 중첩된 각 기준표, 확인 결과(통과 또는 실패), 이유가 표시됩니다. 특정 기준표 확인 결과마다 카드를 펼쳐 원시 JSON 페이로드를 표시할 수 있습니다. 이 JSON 페이로드에는 전체 기준표 설명, 기준표 유형, 중요도, 확인 결과에 관한 자세한 이유와 같은 추가 세부정보가 포함됩니다.

다중 후보 비교 보고서
단일 후보를 평가하는지 아니면 여러 후보를 비교하는지에 따라 보고서 형식이 달라집니다. 후보가 여러 개인 평가의 경우 보고서에 나란히 보기 기능이 제공되며 요약 표에 승률/무승부율 계산이 포함됩니다.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()
