Cette page explique comment effectuer une évaluation par paire basée sur un modèle à l'aide d'AutoSxS, un outil qui s'exécute via le service de pipeline d'évaluation. Nous vous expliquons comment utiliser AutoSxS avec l'API Vertex AI, le SDK Vertex AI pour Python ou la console Google Cloud .
AutoSxS
AutoSxS (Automatic side-to-side) est un outil d'évaluation basé sur un modèle par paire qui s'exécute via le service de pipeline d'évaluation. AutoSxS peut être utilisé pour évaluer les performances des modèles d'IA générative dans Vertex AI Model Registry ou des prédictions prégénérées, ce qui lui permet d'accepter des modèles de fondation de Vertex AI, des modèles d'IA générative ajustés et des modèles de langage tiers. AutoSxS utilise un outil d'évaluation automatique pour choisir le modèle qui répond le mieux à une requête. Il est disponible à la demande et évalue les modèles de langage en offrant des performances comparables à celles des évaluateurs humains.
L'outil d'évaluation automatique
De manière générale, le schéma montre comment AutoSxS compare les prédictions des modèles A et B à celles d'un troisième modèle, l'outil d'évaluation automatique.
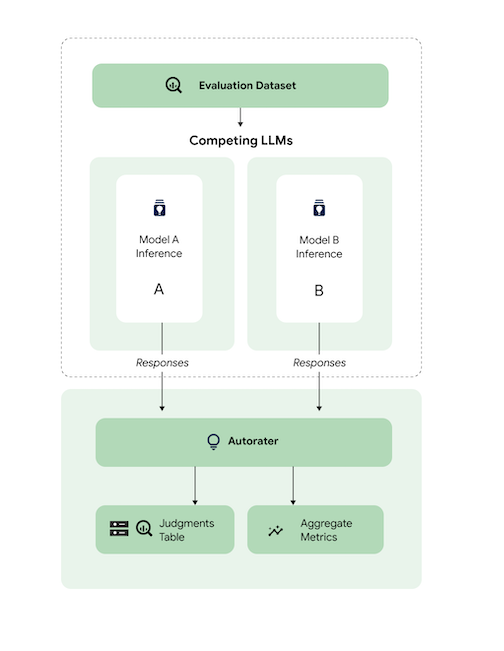
Les modèles A et B reçoivent des requêtes de commande d'entrée, et chaque modèle génère des réponses envoyées à l'évaluateur. Tout comme un évaluateur humain, un évaluateur est un modèle de langage qui évalue la qualité des réponses du modèle en fonction d'une requête d'inférence d'origine. Avec AutoSxS, l'outil d'évaluation automatique compare la qualité de deux réponses des modèles en fonction de leurs instructions d'inférence, à l'aide d'un ensemble de critères. Les critères permettent de déterminer quel modèle a enregistré les meilleures performances en comparant les résultats du modèle A à ceux du modèle B. L'outil d'évaluation automatique génère les préférences de réponse sous forme de métriques agrégées et génère des explications sur les préférences et des scores de confiance pour chaque exemple. Pour en savoir plus, consultez le tableau des jugements.
Modèles compatibles
AutoSxS est compatible avec l'évaluation de n'importe quel modèle lorsque des prédictions prégénérées sont fournies. AutoSxS permet également de générer automatiquement des réponses pour tout modèle du registre de modèles Vertex AI compatible avec la prédiction par lot sur Vertex AI.
Si votre modèle de texte n'est pas compatible avec le registre de modèles Vertex AI, AutoSxS accepte également les prédictions prégénérées stockées au format JSONL dans Cloud Storage ou une table BigQuery. Pour en savoir plus sur les tarifs, consultez la section Génération de texte.
Tâches et critères disponibles
AutoSxS est compatible avec l'évaluation des modèles pour les tâches de synthèse et de questions-réponses. Les critères d'évaluation sont prédéfinis pour chaque tâche, ce qui rend l'évaluation du langage plus objectif et améliore la qualité de la réponse.
Les critères sont listés par tâche.
Synthèse
La tâche summarization a une limite de jetons de 4 096 entrées.
La liste des critères d'évaluation pour summarization est la suivante :
| Critères | |
|---|---|
| 1. Suit les instructions | Dans quelle mesure la réponse du modèle démontre-elle la compréhension de l'instruction de la requête ? |
| 2. Grounded | La réponse n'inclut-elle que les informations du contexte d'inférence et les instructions d'inférence ? |
| 3. Complet | Dans quelle mesure le modèle capture-t-il les détails clés ? |
| 4. Aperçu | Le résumé est-il détaillé ? Inclut-il un langage recherché ? Est-il trop long ? |
Question réponse
La tâche question_answering a une limite de jetons de 4 096 entrées.
La liste des critères d'évaluation pour question_answering est la suivante :
| Critères | |
|---|---|
| 1. Répond entièrement à la question | La réponse répond entièrement à la question. |
| 2. Grounded | La réponse n'inclut-elle que les informations du contexte de l'instruction et les instructions d'inférence ? |
| 3. Pertinence | Le contenu de la réponse est-il lié à la question ? |
| 4. Complet | Dans quelle mesure le modèle capture-t-il les détails clés de la question ? |
Préparer l'ensemble de données d'évaluation pour AutoSxS
Cette section détaille les données que vous devez fournir dans votre ensemble de données d'évaluation AutoSxS et les bonnes pratiques pour la création de l'ensemble de données. Les exemples doivent refléter les entrées réelles que vos modèles peuvent rencontrer en production et mieux différencier le comportement de vos modèles opérationnels.
Format de l'ensemble de données
AutoSxS accepte un seul ensemble de données d'évaluation avec un schéma flexible. L'ensemble de données peut être une table BigQuery ou stocké en tant que JSON Lines dans Cloud Storage.
Chaque ligne de l'ensemble de données d'évaluation représente un seul exemple, et les colonnes sont l'un des éléments suivants :
- Colonnes d'identifiants : permettent d'identifier chaque exemple unique.
- Colonnes de données : permettent de remplir des modèles de requête. Consultez la section Paramètres de requête.
- Prédictions prégénérées : prédictions effectuées par le même modèle à l'aide de la même requête. L'utilisation de prédictions prégénérées permet d'économiser du temps et des ressources.
- Préférences humaines de vérité terrain : permet de comparer AutoSxS avec vos données de vérité terrain de préférence lorsque les prédictions pré-générées sont fournies pour les deux modèles.
Voici un exemple d'ensemble de données d'évaluation dans lequel context et question sont des colonnes de données, et où model_b_response contient des prédictions prégénérées.
context |
question |
model_b_response |
|---|---|---|
| Certains peuvent penser que l'acier est le matériau le plus dur, ou le titane, mais le diamant est en fait le matériau le plus dur. | Quel est le matériau le plus dur ? | Le diamant est le matériau le plus dur. Il est plus dur que l'acier ou le titane. |
Pour en savoir plus sur l'appel d'AutoSxS, consultez la page Évaluer le modèle. Pour en savoir plus sur la longueur des jetons, consultez la section Tâches et critères compatibles. Pour importer vos données dans Cloud Storage, consultez la page Importer un ensemble de données d'évaluation dans Cloud Storage.
Paramètres de requête
De nombreux modèles de langage utilisent des paramètres de requête comme entrées au lieu d'une seule chaîne de requête. Par exemple, chat-bison prend plusieurs paramètres de requête (messages, exemples, contexte) qui constituent des parties de la requête. Cependant, text-bison ne dispose que d'un seul paramètre de requête, appelé requête, qui contient la requête complète.
Nous décrivons comment spécifier de manière flexible les paramètres de requête de modèle au moment de l'inférence et de l'évaluation. AutoSxS vous permet d'appeler des modèles de langage avec différentes entrées attendues à l'aide de paramètres de requête modélisés.
Inférence
Si l'un des modèles ne dispose pas de prédictions prégénérées, AutoSxS utilise la prédiction par lot Vertex AI pour générer des réponses. Les paramètres de requête de chaque modèle doivent être spécifiés.
Dans AutoSxS, vous pouvez fournir une seule colonne de l'ensemble de données d'évaluation en tant que paramètre de requête.
{'some_parameter': {'column': 'my_column'}}
Vous pouvez également définir des modèles en utilisant les colonnes de l'ensemble de données d'évaluation sous forme de variables pour spécifier les paramètres de requête :
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Lorsqu'ils fournissent des paramètres de requête de modèle pour l'inférence, les utilisateurs peuvent utiliser le mot clé default_instruction protégé en tant qu'argument de modèle, qui est remplacé par l'instruction d'inférence par défaut pour la tâche donnée :
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Si vous générez des prédictions, indiquez les paramètres de requête du modèle et une colonne de sortie. Consultez les exemples suivants :
Gemini
Pour les modèles Gemini, les clés des paramètres d'invite du modèle sont contents (obligatoire) et system_instruction (facultatif), qui s'alignent sur le schéma du corps de la requête Gemini.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Par exemple, text-bison utilise "invite de commande" pour l'entrée et "contenu" pour la sortie. Procédez comme suit :
- Identifier les entrées et les sorties requises par les modèles évalués.
- Définissez les entrées en tant que paramètres de requête de modèle.
- Transmettez le résultat à la colonne de réponse.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Évaluation
De la même façon que vous devez fournir des paramètres de requête pour l'inférence, vous devez également fournir des paramètres de requête pour l'évaluation. L'outil d'évaluation automatique nécessite les paramètres de requête suivants :
| Paramètre de requête de l'outil d'évaluation automatique | Configurable par l'utilisateur ? | Description | Exemple |
|---|---|---|---|
| Instructions pour l'outil d'évaluation automatique | Non | Instructions calibrées décrivant les critères que l'outil d'évaluation automatique doit utiliser pour évaluer les réponses données. | Choisissez la réponse qui répond à la question et suivez au mieux les instructions. |
| Instruction d'inférence | Oui | Description de la tâche que chaque modèle candidat doit effectuer. | Répondez avec précision à la question suivante : quel est le matériau le plus dur ? |
| Contexte d'inférence | Oui | Contexte supplémentaire pour la tâche en cours d'exécution. | Alors que le titane et le diamant sont tous deux plus durs que le cuivre, le diamond a une note de dureté de 98, tandis que celle du titane est de 36. Une note élevée signifie une dureté plus élevée. |
| Réponses | No1 | Paire de réponses à évaluer, une pour chaque modèle candidat. | Diamant |
1 Vous ne pouvez configurer le paramètre de requête que via des réponses prégénérées.
Exemple de code utilisant les paramètres :
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Les modèles A et B peuvent comporter des instructions d'inférence et un contexte différents, que les mêmes informations soient fournies ou non. Cela signifie que l'outil d'évaluation automatique utilise une instruction d'inférence distincte, mais une seule instruction contextuelle.
Exemple d'ensemble de données d'évaluation
Cette section fournit un exemple d'ensemble de données d'évaluation de tâches de questions-réponses, y compris des prédictions prégénérées pour le modèle B. Dans cet exemple, AutoSxS n'effectue l'inférence que pour le modèle A. Nous fournissons une colonne id pour différencier les exemples associés à la même question et au même contexte.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Bonnes pratiques
Suivez ces bonnes pratiques lorsque vous définissez votre ensemble de données d'évaluation :
- Fournissez des exemples représentant les types d'entrées que vos modèles traitent en production.
- Votre ensemble de données doit inclure au moins un exemple d'évaluation. Nous vous recommandons d'utiliser environ 100 exemples pour garantir des métriques agrégées de haute qualité. Le taux d'amélioration de la qualité agrégée tend à diminuer lorsque plus de 400 exemples sont fournis.
- Pour obtenir des instructions sur l'écriture de requêtes de commande, consultez la page Concevoir des requêtes de commande de texte.
- Si vous utilisez des prédictions prégénérées pour l'un des modèles, incluez les prédictions prégénérées dans une colonne de votre ensemble de données d'évaluation. Les prédictions prégénérées sont utiles, car elles vous permettent de comparer les résultats de modèles qui ne se trouvent pas dans Vertex Model Registry et de réutiliser les réponses.
Évaluer des modèles
Vous pouvez évaluer des modèles à l'aide de l'API REST, du SDK Vertex AI pour Python ou de la consoleGoogle Cloud .
Utilisez cette syntaxe pour spécifier le chemin d'accès à votre modèle :
- Modèle éditeur :
publishers/PUBLISHER/models/MODELExemple :publishers/google/models/text-bison Modèle ajusté :
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONExemple :projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Pour créer un job d'évaluation de modèle, envoyez une requête POST avec la méthode pipelineJobs.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PIPELINEJOB_DISPLAYNAME : nom à afficher pour
pipelineJob. - PROJECT_ID : projet Google Cloud qui exécute les composants du pipeline.
- LOCATION : région d'exécution des composants de pipeline.
us-central1est accepté. - OUTPUT_DIR : URI Cloud Storage où stocker le résultat de l'évaluation.
- EVALUATION_DATASET : table BigQuery ou liste d'éléments séparés par une virgule des chemins d'accès Cloud Storage vers un ensemble de données JSONL contenant des exemples d'évaluation.
- TASK : tâche d'évaluation, qui peut être
[summarization, question_answering]. - ID_COLUMNS : colonnes qui distinguent des exemples d'évaluation uniques.
- AUTORATER_PROMPT_PARAMETERS : paramètres de requête de l'outil d'évaluation automatique mappés à des colonnes ou à des modèles. Les paramètres attendus sont les suivants :
inference_instruction(détails sur l'exécution d'une tâche) etinference_context(contenu à référencer pour effectuer la tâche). Par exemple,{'inference_context': {'column': 'my_prompt'}}utilise la colonne "my_prompt" de l'ensemble de données d'évaluation pour le contexte de l'outil d'évaluation automatique. - RESPONSE_COLUMN_A : nom de la colonne dans l'ensemble de données d'évaluation contenant des prédictions prédéfinies, ou nom de la colonne dans le résultat du modèle A contenant les prédictions. Si aucune valeur n'est fournie, le nom de la colonne de sortie du modèle correct sera tenté d'être inféré.
- RESPONSE_COLUMN_B : nom de la colonne dans l'ensemble de données d'évaluation contenant des prédictions prédéfinies ou nom de la colonne dans le résultat du modèle B contenant les prédictions. Si aucune valeur n'est fournie, le nom de la colonne de sortie du modèle correct sera tenté d'être inféré.
- MODEL_A (facultatif) : nom complet de la ressource de modèle (
projects/{project}/locations/{location}/models/{model}@{version}) ou nom de ressource du modèle éditeur (publishers/{publisher}/models/{model}). Si des réponses du modèle A sont spécifiées, ce paramètre ne doit pas être fourni. - MODEL_B (facultatif) : nom complet de la ressource de modèle (
projects/{project}/locations/{location}/models/{model}@{version}) ou nom de ressource du modèle éditeur (publishers/{publisher}/models/{model}). Si des réponses du modèle B sont spécifiées, ce paramètre ne doit pas être fourni. - MODEL_A_PROMPT_PARAMETERS (facultatif) : paramètres de modèle de requête du modèle A mappés à des colonnes ou à des modèles. Si des réponses du modèle A sont prédéfinies, ce paramètre ne doit pas être fourni. Exemple :
{'prompt': {'column': 'my_prompt'}}utilise la colonnemy_promptde l'ensemble de données d'évaluation pour le paramètre de requête nomméprompt. - MODEL_B_PROMPT_PARAMETERS (facultatif) : paramètres de modèle de requête de commande du modèle B mappés à des colonnes ou à des modèles. Si des réponses du modèle B sont prédéfinies, ce paramètre ne doit pas être fourni. Exemple :
{'prompt': {'column': 'my_prompt'}}utilise la colonnemy_promptde l'ensemble de données d'évaluation pour le paramètre de requête nomméprompt. - JUDGMENTS_FORMAT
(facultatif) : format dans lequel écrire les jugements. Peut être
jsonl(par défaut),jsonoubigquery. - BIGQUERY_DESTINATION_PREFIX : table BigQuery dans laquelle écrire les jugements si le format spécifié est
bigquery.
Corps JSON de la requête
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Utilisez curl pour envoyer votre requête.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Réponse
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
SDK Vertex AI pour Python
Pour savoir comment installer ou mettre à jour le SDK Vertex AI pour Python, consultez la section Installer le SDK Vertex AI pour Python. Pour plus d'informations sur l'API Python, consultez la page SDK Vertex AI pour l'API Python.
Pour plus d'informations sur les paramètres du pipeline, consultez la documentation de référence sur les composants du pipeline Google Cloud.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PIPELINEJOB_DISPLAYNAME : nom à afficher pour
pipelineJob. - PROJECT_ID : projet Google Cloud qui exécute les composants du pipeline.
- LOCATION : région d'exécution des composants de pipeline.
us-central1est accepté. - OUTPUT_DIR : URI Cloud Storage où stocker le résultat de l'évaluation.
- EVALUATION_DATASET : table BigQuery ou liste d'éléments séparés par une virgule des chemins d'accès Cloud Storage vers un ensemble de données JSONL contenant des exemples d'évaluation.
- TASK : tâche d'évaluation, qui peut être
[summarization, question_answering]. - ID_COLUMNS : colonnes qui distinguent des exemples d'évaluation uniques.
- AUTORATER_PROMPT_PARAMETERS : paramètres de requête de l'outil d'évaluation automatique mappés à des colonnes ou à des modèles. Les paramètres attendus sont les suivants :
inference_instruction(détails sur l'exécution d'une tâche) etinference_context(contenu à référencer pour effectuer la tâche). Par exemple,{'inference_context': {'column': 'my_prompt'}}utilise la colonne "my_prompt" de l'ensemble de données d'évaluation pour le contexte de l'outil d'évaluation automatique. - RESPONSE_COLUMN_A : nom de la colonne dans l'ensemble de données d'évaluation contenant des prédictions prédéfinies, ou nom de la colonne dans le résultat du modèle A contenant les prédictions. Si aucune valeur n'est fournie, le nom de la colonne de sortie du modèle correct sera tenté d'être inféré.
- RESPONSE_COLUMN_B : nom de la colonne dans l'ensemble de données d'évaluation contenant des prédictions prédéfinies ou nom de la colonne dans le résultat du modèle B contenant les prédictions. Si aucune valeur n'est fournie, le nom de la colonne de sortie du modèle correct sera tenté d'être inféré.
- MODEL_A (facultatif) : nom complet de la ressource de modèle (
projects/{project}/locations/{location}/models/{model}@{version}) ou nom de ressource du modèle éditeur (publishers/{publisher}/models/{model}). Si des réponses du modèle A sont spécifiées, ce paramètre ne doit pas être fourni. - MODEL_B (facultatif) : nom complet de la ressource de modèle (
projects/{project}/locations/{location}/models/{model}@{version}) ou nom de ressource du modèle éditeur (publishers/{publisher}/models/{model}). Si des réponses du modèle B sont spécifiées, ce paramètre ne doit pas être fourni. - MODEL_A_PROMPT_PARAMETERS (facultatif) : paramètres de modèle de requête du modèle A mappés à des colonnes ou à des modèles. Si des réponses du modèle A sont prédéfinies, ce paramètre ne doit pas être fourni. Exemple :
{'prompt': {'column': 'my_prompt'}}utilise la colonnemy_promptde l'ensemble de données d'évaluation pour le paramètre de requête nomméprompt. - MODEL_B_PROMPT_PARAMETERS (facultatif) : paramètres de modèle de requête de commande du modèle B mappés à des colonnes ou à des modèles. Si des réponses du modèle B sont prédéfinies, ce paramètre ne doit pas être fourni. Exemple :
{'prompt': {'column': 'my_prompt'}}utilise la colonnemy_promptde l'ensemble de données d'évaluation pour le paramètre de requête nomméprompt. - JUDGMENTS_FORMAT
(facultatif) : format dans lequel écrire les jugements. Peut être
jsonl(par défaut),jsonoubigquery. - BIGQUERY_DESTINATION_PREFIX : table BigQuery dans laquelle écrire les jugements si le format spécifié est
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Console
Pour créer un job d'évaluation de modèle par paire à l'aide de la console Google Cloud , procédez comme suit :
Commencez avec un modèle de fondation Google ou utilisez un modèle qui existe déjà dans votre registre de modèles Vertex AI:
Pour évaluer un modèle de fondation Google, procédez comme suit:
Accédez à Vertex AI Model Garden et sélectionnez un modèle compatible avec l'évaluation par paires, tel que
text-bison.Cliquez sur Évaluer.
Dans le menu qui s'affiche, cliquez sur Sélectionner pour sélectionner une version du modèle.
Un volet Enregistrer le modèle peut vous demander d'enregistrer une copie du modèle dans Vertex AI Model Registry si vous n'en avez pas déjà une. Saisissez un nom de modèle, puis cliquez sur Continuer.
La page Créer une évaluation s'affiche. Pour l'étape Méthode d'évaluation, sélectionnez Comparer ce modèle à un autre modèle.
Cliquez sur Continuer.
Pour évaluer un modèle existant dans Vertex AI Model Registry :
Accédez à la page Vertex AI Model Registry.
Cliquez sur le nom du modèle que vous souhaitez évaluer. Assurez-vous que le type de modèle est compatible avec l'évaluation par paires. Par exemple,
text-bison.Dans l'onglet Évaluer, cliquez sur SxS.
Cliquez sur Créer une évaluation côte à côte.
Pour chaque étape de la page de création de l'évaluation, saisissez les informations requises et cliquez sur Continuer :
Pour l'étape Ensemble de données d'évaluation, sélectionnez un objectif d'évaluation et un modèle à comparer à celui que vous avez choisi. Sélectionnez un ensemble de données d'évaluation et saisissez les colonnes d'ID (colonnes de réponse).
Pour l'étape Paramètres du modèle, indiquez si vous souhaitez utiliser les réponses du modèle déjà présentes dans votre ensemble de données ou si vous souhaitez utiliser Vertex AI Batch Prediction pour générer les réponses. Spécifiez les colonnes de réponse pour les deux modèles. Pour l'option de prédiction par lot Vertex AI, vous pouvez spécifier les paramètres d'invite de votre modèle d'inférence.
À l'étape Paramètres de l'évaluateur automatique, saisissez les paramètres de l'invite de l'évaluateur automatique et un emplacement de sortie pour les évaluations.
Cliquez sur Démarrer l'évaluation.
Afficher les résultats de l'évaluation
Vous pouvez trouver les résultats de l'évaluation dans Vertex AI Pipelines en inspectant les artefacts suivants générés par le pipeline AutoSxS :
- La table Jugements est produite par l'arbitre AutoSxS.
- Les métriques agrégées sont générées par le composant de métriques AutoSxS.
- Les métriques d'alignement des préférences humaines sont générées par le composant de métriques AutoSxS.
Jugements
AutoSxS génère des jugements (métriques au niveau de l'exemple) qui aident les utilisateurs à comprendre les performances du modèle au niveau de l'exemple. Les jugements comprennent les informations suivantes :
- Requêtes de commande d'inférence
- Réponses du modèle
- Décisions de l'outil d'évaluation automatique
- Explication des évaluations
- Scores de confiance
Les décisions peuvent être écrites dans Cloud Storage au format JSONL ou dans une table BigQuery à l'aide des colonnes suivantes :
| Colonne | Description |
|---|---|
| Colonnes des identifiants | Colonnes qui distinguent des exemples d'évaluation uniques. |
inference_instruction |
Instruction utilisée pour générer les réponses du modèle. |
inference_context |
Contexte utilisé pour générer des réponses du modèle. |
response_a |
Réponse du modèle A, selon les instructions d'inférence et le contexte. |
response_b |
Réponse du modèle B, selon les instructions d'inférence et le contexte. |
choice |
Modèle avec la meilleure réponse. Les valeurs possibles sont Model A, Model B ou Error. Error signifie qu'une erreur a empêché l'outil d'évaluation automatique de déterminer si la réponse du modèle A ou celle du modèle B était la meilleure. |
confidence |
Un score compris entre 0 et 1, qui indique le degré de confiance de l'outil d'évaluation automatique quant à son choix. |
explanation |
Raison du choix de l'outil d'évaluation automatique. |
Métriques agrégées
AutoSxS calcule les métriques agrégées (taux de réussite) à l'aide de la table des jugements. Si aucune donnée de préférence humaine n'est fournie, les métriques agrégées suivantes sont générées :
| Métrique | Description |
|---|---|
| Taux de réussite du modèle A de l'outil d'évaluation automatique | Pourcentage de fois où l'outil d'évaluation automatique a décidé que le modèle A avait la meilleure réponse. |
| Taux de réussite du modèle B de l'outil d'évaluation automatique | Pourcentage de fois où l'outil d'évaluation automatique a décidé que le modèle B avait la meilleure réponse. |
Pour mieux comprendre le taux de réussite, examinez les résultats basés sur les lignes et les explications de l'outil d'évaluation automatique pour déterminer si les résultats et les explications correspondent à vos attentes.
Métriques d'alignement de préférences humaines
Si des données de préférence humaines sont fournies, AutoSxS génère les métriques suivantes :
| Métrique | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Taux de réussite du modèle A de l'outil d'évaluation automatique | Pourcentage de fois où l'outil d'évaluation automatique a décidé que le modèle A avait la meilleure réponse. | ||||||||||||||
| Taux de réussite du modèle B de l'outil d'évaluation automatique | Pourcentage de fois où l'outil d'évaluation automatique a décidé que le modèle B avait la meilleure réponse. | ||||||||||||||
| Taux de réussite du modèle A de préférence humaine | Pourcentage de temps où des humains ont décidé que le modèle A avait la meilleure réponse. | ||||||||||||||
| Taux de réussite du modèle B de préférence humaine | Pourcentage de temps où des humains ont décidé que le modèle B avait la meilleure réponse. | ||||||||||||||
| VP | Nombre d'exemples où l'outil d'évaluation automatique et les préférences humaines ont considéré que le modèle A avait la meilleure réponse. | ||||||||||||||
| FP | Nombre d'exemples où l'outil d'évaluation automatique a choisi le modèle A comme ayant la meilleure réponse, mais la préférence humaine a considéré que le modèle B avait la meilleure réponse. | ||||||||||||||
| VN | Nombre d'exemples où l'outil d'évaluation automatique et les préférences humaines ont considéré que le modèle B avait la meilleure réponse.. | ||||||||||||||
| FN | Nombre d'exemples où l'outil d'évaluation automatique a choisi le modèle B comme ayant la meilleure réponse, mais la préférence humaine a considéré que le modèle A avait la meilleure réponse. | ||||||||||||||
| Précision | Pourcentage de temps où l'outil d'évaluation automatique a été d'accord avec les évaluateurs humains. | ||||||||||||||
| Précision | Pourcentage de temps où l'outil d'évaluation automatique et les évaluateurs humains ont considéré que le modèle A avait une meilleure réponse, parmi tous les cas où l'outil d'évaluation automatique a considéré que le modèle A avait une meilleure réponse. | ||||||||||||||
| Rappel | Pourcentage de temps où l'outil d'évaluation automatique et les évaluateurs humains ont considéré que le modèle A avait une meilleure réponse, parmi tous les cas où les évaluateurs humains ont considéré que le modèle A avait une meilleure réponse. | ||||||||||||||
| F1 | Moyenne harmonique de la précision et du rappel. | ||||||||||||||
| Kappa de Cohen | Mesure de l'accord entre l'outil d'évaluation automatique et les évaluateurs humains, qui prend en compte la probabilité d'acceptation aléatoire. Cohen suggère l'interprétation suivante :
|
Cas d'utilisation d'AutoSxS
Vous pouvez découvrir comment utiliser AutoSxS à l'aide de trois scénarios d'utilisation.
Comparer des modèles
Évaluez un modèle propriétaire réglé (1p) par rapport à un modèle propriétaire de référence.
Vous pouvez spécifier que l'inférence s'exécute simultanément sur les deux modèles.
Cet exemple de code évalue un modèle ajusté à partir de Vertex Model Registry par rapport à un modèle de référence du même registre.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Comparer les prédictions
Évaluez un modèle tiers réglé (3p) par rapport à un modèle tiers de référence 3p.
Vous pouvez ignorer l'inférence en fournissant directement des réponses du modèle.
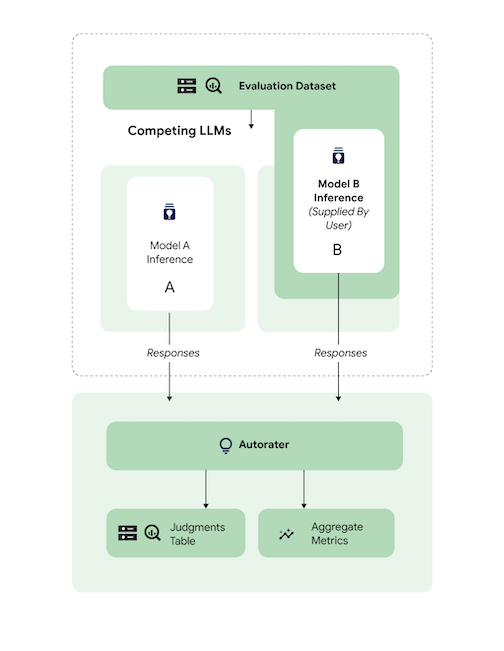
Cet exemple de code évalue un modèle 3p réglé par rapport à un modèle de référence 3p.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Vérifier l'alignement
Toutes les tâches compatibles ont été comparées à l'aide de données d'un évaluateur humain afin de garantir que les réponses de l'outil d'évaluation automatique sont alignées sur les préférences humaines. Si vous souhaitez effectuer une analyse comparative d'AutoSxS pour vos cas d'utilisation, fournissez des données de préférences humaines directement à AutoSxS, qui génère des statistiques agrégées d'alignement.
Pour vérifier l'alignement par rapport à un ensemble de données de préférence humaine, vous pouvez spécifier les deux sorties (résultats de prédiction) à l'outil d'évaluation automatique. Vous pouvez également fournir vos résultats d'inférence.
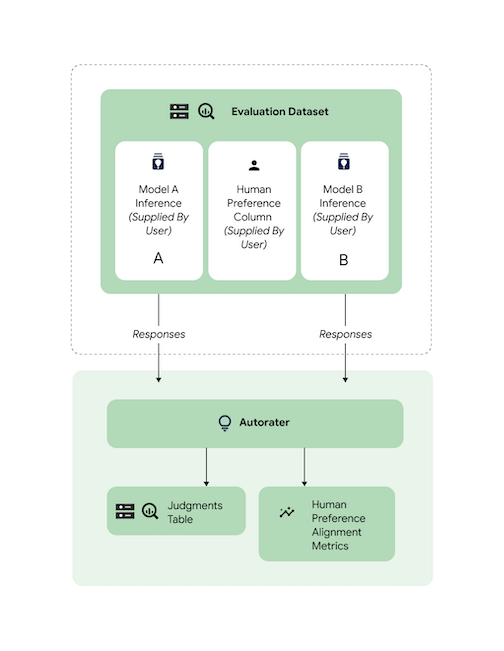
Cet exemple de code vérifie que les résultats et les explications de l'outil d'évaluation automatique sont conformes à vos attentes.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
Étape suivante
- Apprenez-en plus sur l'évaluation de l'IA générative.
- Découvrez l'évaluation en ligne avec le Gen AI Evaluation Service.
- Découvrez comment régler les modèles de fondation de langage.