Esta página descreve como ver e interpretar os resultados da avaliação do modelo após executar a avaliação do modelo.
Veja os resultados da avaliação
Depois de definir a tarefa de avaliação, execute-a para obter os resultados da avaliação, da seguinte forma:
from vertexai.evaluation import EvalTask
eval_result = EvalTask(
dataset=DATASET,
metrics=[METRIC_1, METRIC_2, METRIC_3],
experiment=EXPERIMENT_NAME,
).evaluate(
model=MODEL,
experiment_run=EXPERIMENT_RUN_NAME,
)
A classe EvalResult representa o resultado de uma execução de avaliação com os seguintes atributos:
summary_metrics: um dicionário de métricas de avaliação agregadas para uma execução de avaliação.metrics_table: Uma tabelapandas.DataFrameque contém entradas do conjunto de dados de avaliação, respostas, explicações e resultados das métricas por linha.metadata: o nome da experiência e o nome da execução da experiência para a execução da avaliação.
A classe EvalResult é definida da seguinte forma:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: A dictionary of aggregated evaluation metrics for an evaluation run.
metrics_table: A pandas.DataFrame table containing evaluation dataset inputs,
responses, explanations, and metric results per row.
metadata: the experiment name and experiment run name for the evaluation run.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional["pd.DataFrame"] = None
metadata: Optional[Dict[str, str]] = None
Com a utilização de funções auxiliares, os resultados da avaliação podem ser apresentados no bloco de notas do Colab da seguinte forma:
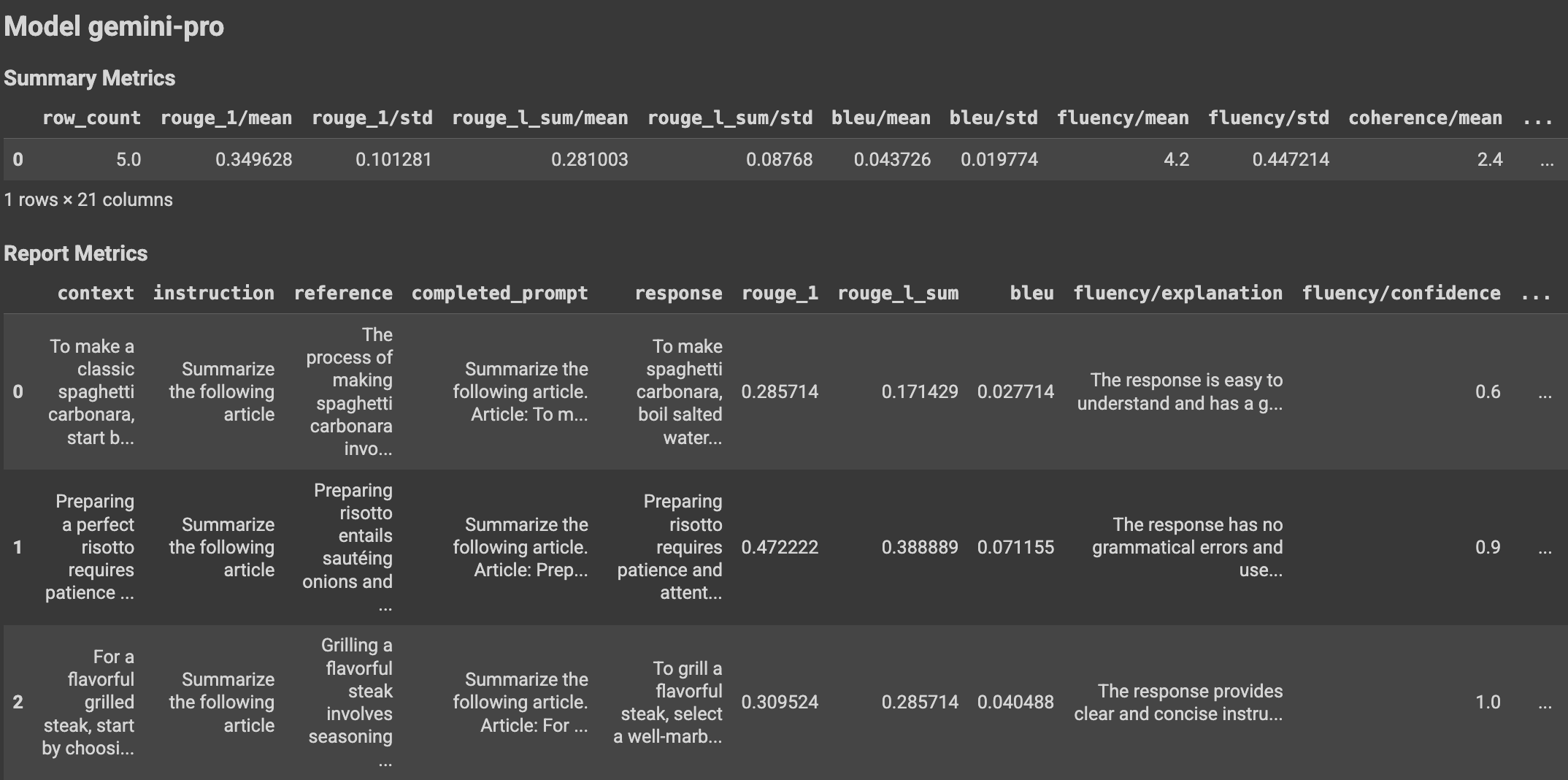
Visualize os resultados da avaliação
Pode traçar métricas de resumo num gráfico de radar ou de barras para visualização e comparação entre resultados de diferentes execuções de avaliação. Esta visualização pode ser útil para avaliar diferentes modelos e diferentes modelos de comandos.
No exemplo seguinte, visualizamos quatro métricas (coerência, fluidez, seguimento de instruções e qualidade geral do texto) para respostas geradas com quatro modelos de comandos diferentes. A partir do radar e do gráfico de barras, podemos inferir que o modelo de comando n.º 2 tem um desempenho consistentemente superior ao dos outros modelos nas quatro métricas. Isto é particularmente evidente nas suas classificações significativamente mais elevadas para o seguimento de instruções e a qualidade do texto. Com base nesta análise, o modelo de comando n.º 2 parece ser a escolha mais eficaz entre as quatro opções.
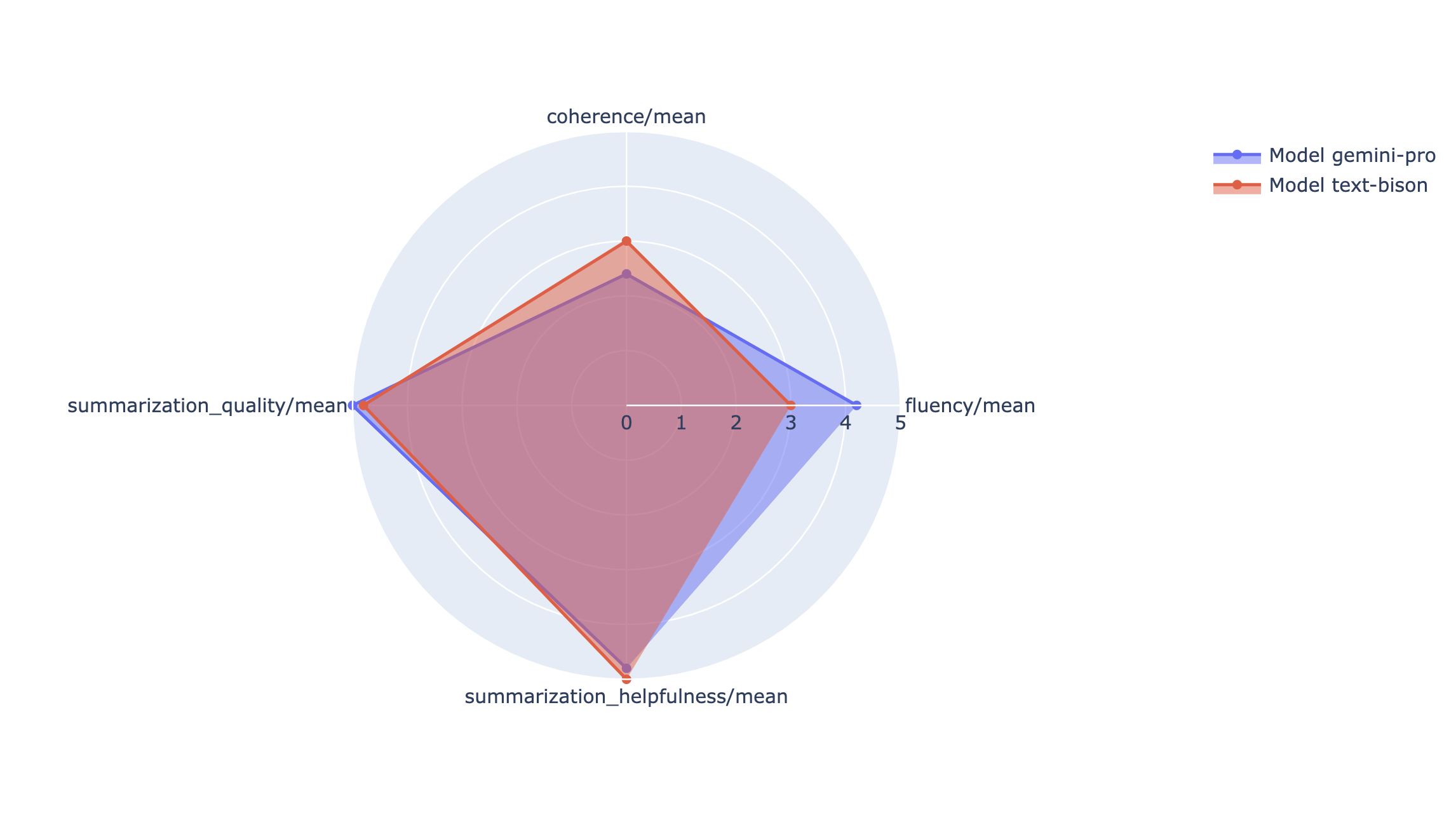
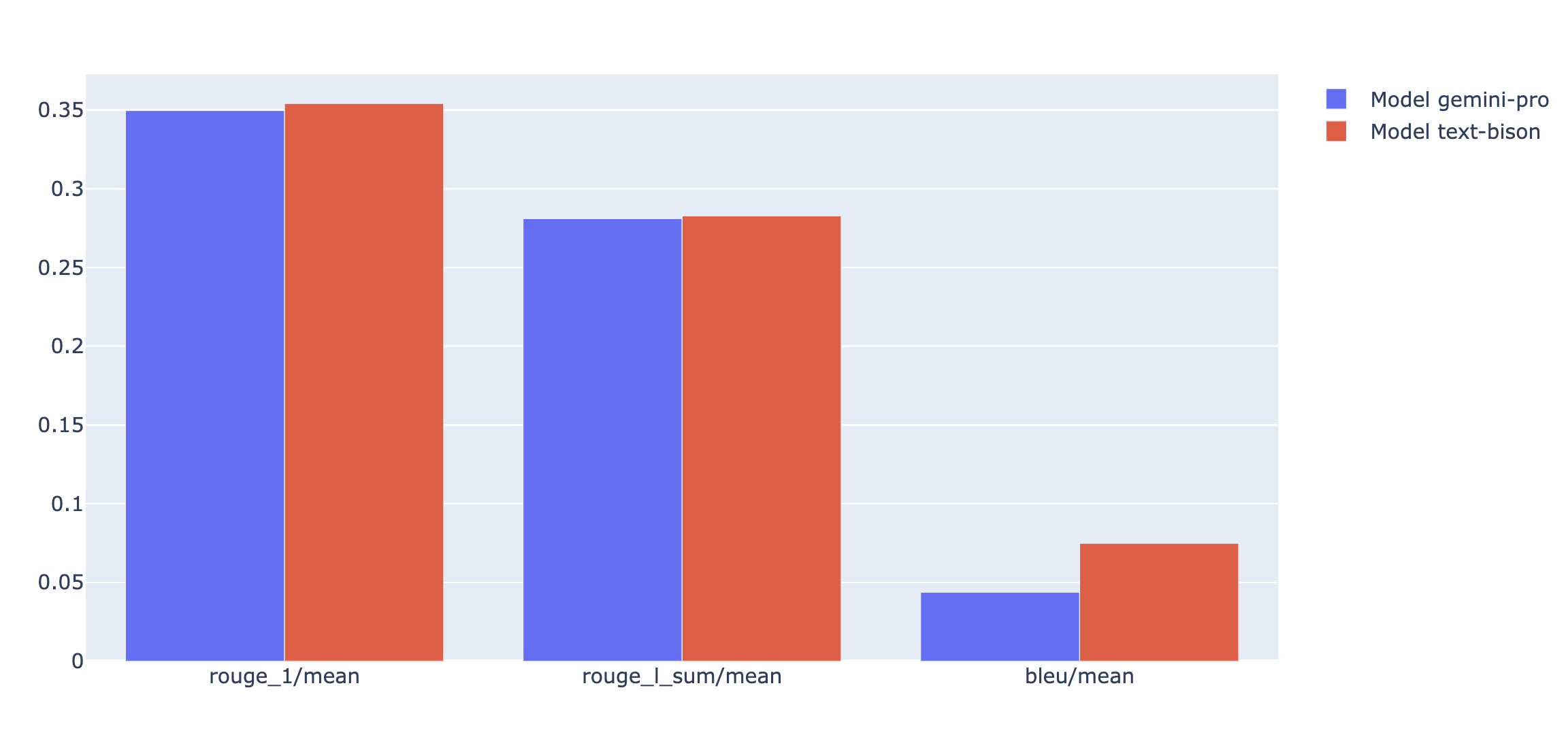
Compreenda os resultados das métricas
As tabelas seguintes apresentam vários componentes dos resultados ao nível da instância e agregados incluídos, respetivamente, em metrics_table e summary_metrics para PointwiseMetric, PairwiseMetric e métricas baseadas em cálculos:
PointwiseMetric
Resultados ao nível da instância
| Coluna | Descrição |
|---|---|
| resposta | A resposta gerada para o comando pelo modelo. |
| pontuação | A classificação atribuída à resposta de acordo com os critérios e a rubrica de classificação. A pontuação pode ser binária (0 e 1), numa escala de Likert (1 a 5 ou -2 a 2) ou flutuante (0, 0 a 1,0). |
| explicação | O motivo da pontuação do modelo de juiz. Usamos o raciocínio em cadeia de pensamento para orientar o modelo de juiz a explicar o seu raciocínio por detrás de cada veredito. Forçar o modelo de juiz a raciocinar melhora a precisão da avaliação. |
Agregue resultados
| Coluna | Descrição |
|---|---|
| pontuação média | Classificação média para todas as instâncias. |
| desvio padrão | Desvio padrão de todas as pontuações. |
PairwiseMetric
Resultados ao nível da instância
| Coluna | Descrição |
|---|---|
| resposta | A resposta gerada para o comando pelo modelo candidato. |
| baseline_model_response | A resposta gerada para o comando pelo modelo de base. |
| pairwise_choice | O modelo com a melhor resposta. Os valores possíveis são CANDIDATE, BASELINE ou TIE. |
| explicação | O motivo da escolha do modelo de juiz. |
Agregue resultados
| Coluna | Descrição |
|---|---|
| candidate_model_win_rate | Rácio do tempo em que o modelo de juiz decidiu que o modelo candidato tinha a melhor resposta em relação ao total de respostas. Varia entre 0 e 1. |
| baseline_model_win_rate | Rácio do tempo em que o modelo de avaliação decidiu que o modelo de base tinha a melhor resposta em relação ao total de respostas. Varia entre 0 e 1. |
Métricas baseadas em cálculos
Resultados ao nível da instância
| Coluna | Descrição |
|---|---|
| resposta | A resposta do modelo está a ser avaliada. |
| referência | A resposta de referência. |
| pontuação | A pontuação é calculada para cada par de respostas e referências. |
Agregue resultados
| Coluna | Descrição |
|---|---|
| pontuação média | Classificação média para todas as instâncias. |
| desvio padrão | Desvio padrão de todas as pontuações. |
Exemplos
Os exemplos nesta secção demonstram como ler e compreender os resultados da avaliação.
Exemplo 1: avaliação ponto a ponto
No primeiro exemplo, considere avaliar uma instância de avaliação pontual para TEXT_QUALITY. A pontuação da avaliação pontual da métrica TEXT_QUALITY é 4 (numa escala de 1 a 5), o que significa que a resposta é boa. Além disso, a explicação no resultado da avaliação mostra por que motivo o modelo de juiz considera que a previsão merece a classificação 4 e não uma classificação superior ou inferior.
Conjunto de dados
prompt: "Resume o seguinte texto de forma que uma criança de cinco anos possa compreender: Plataforma de redes sociais enfrenta críticas devido às políticas de moderação de conteúdo\nUma plataforma de redes sociais proeminente encontra-se envolvida em controvérsia, uma vez que os utilizadores e os criadores de conteúdo expressam descontentamento relativamente às respetivas políticas de moderação de conteúdo. As alegações de censura parcial, aplicação inconsistente e supressão de determinados pontos de vista geraram indignação entre os utilizadores que afirmam que a plataforma está a sufocar a liberdade de expressão. Por outro lado, a plataforma afirma que as suas políticas foram concebidas para manter um ambiente online seguro e inclusivo. Esta controvérsia levanta questões mais amplas sobre o papel das redes sociais na formação do discurso público e as responsabilidades das plataformas na curadoria de conteúdo online."response: "As pessoas estão descontentes com um Website porque consideram que não está a ser justo com o que as pessoas podem publicar. Algumas pessoas afirmam que o Website as impede de dizer o que querem. No entanto, o Website afirma que está a tentar manter a segurança de todos. Isto faz com que as pessoas se perguntem se os Websites devem controlar o que as pessoas podem dizer online."
Resultado
score: 4,explanation: o resumo na resposta segue a instrução para resumir o contexto de uma forma que uma criança de cinco anos possa compreender. Baseia-se no contexto e fornece detalhes importantes no resumo. No entanto, a linguagem usada na resposta é um pouco prolixa.
Exemplo 2: avaliação aos pares
O segundo exemplo é uma avaliação de comparação aos pares em PAIRWISE_QUESTION_ANSWERING_QUALITY. O resultado pairwise_choice mostra que a resposta candidata "França é um país localizado na Europa Ocidental" é preferida pelo modelo de juiz em comparação com a resposta de base "França é um país" para responder à pergunta na instrução. Tal como nos resultados por pontos, também é fornecida uma explicação para explicar por que motivo a resposta do candidato é melhor do que a resposta de referência (a resposta do candidato é mais útil neste caso).
Conjunto de dados
prompt: "Podes responder onde se situa França com base no seguinte parágrafo? França é um país localizado na Europa Ocidental. Faz fronteira com a Alemanha, Andorra, Bélgica, Espanha, Itália, Luxemburgo, Mónaco e Suíça. A costa de França estende-se ao longo do Canal da Mancha, do Mar do Norte, do Oceano Atlântico e do Mar Mediterrâneo. Conhecida pela sua história rica, monumentos icónicos como a Torre Eiffel e gastronomia deliciosa, a França é uma grande potência cultural e económica na Europa e em todo o mundo."response: "França é um país localizado na Europa Ocidental.",baseline_model_response: "França é um país.",
Resultado
pairwise_choice: CANDIDATE,explanation: A resposta BASELINE é fundamentada, mas não responde totalmente à pergunta. No entanto, a resposta CANDIDATE está correta e fornece detalhes úteis sobre a localização de França.
O que se segue?
Experimente um bloco de notas de exemplo de avaliação.
Saiba mais sobre a avaliação da IA generativa.