En esta página se describe cómo ver e interpretar los resultados de la evaluación de tu modelo después de ejecutarla.
Ver los resultados de la evaluación
Una vez que haya definido la tarea de evaluación, ejecútela para obtener los resultados de la evaluación, tal como se indica a continuación:
from vertexai.evaluation import EvalTask
eval_result = EvalTask(
dataset=DATASET,
metrics=[METRIC_1, METRIC_2, METRIC_3],
experiment=EXPERIMENT_NAME,
).evaluate(
model=MODEL,
experiment_run=EXPERIMENT_RUN_NAME,
)
La clase EvalResult representa el resultado de una ejecución de evaluación con los siguientes atributos:
summary_metrics: diccionario de métricas de evaluación agregadas de una ejecución de evaluación.metrics_table: una tablapandas.DataFrameque contiene las entradas del conjunto de datos de evaluación, las respuestas, las explicaciones y los resultados de las métricas por fila.metadata: el nombre del experimento y el nombre de la ejecución del experimento de la ejecución de la evaluación.
La clase EvalResult se define de la siguiente manera:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: A dictionary of aggregated evaluation metrics for an evaluation run.
metrics_table: A pandas.DataFrame table containing evaluation dataset inputs,
responses, explanations, and metric results per row.
metadata: the experiment name and experiment run name for the evaluation run.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional["pd.DataFrame"] = None
metadata: Optional[Dict[str, str]] = None
Con el uso de funciones auxiliares, los resultados de la evaluación se pueden mostrar en el cuaderno de Colab de la siguiente manera:
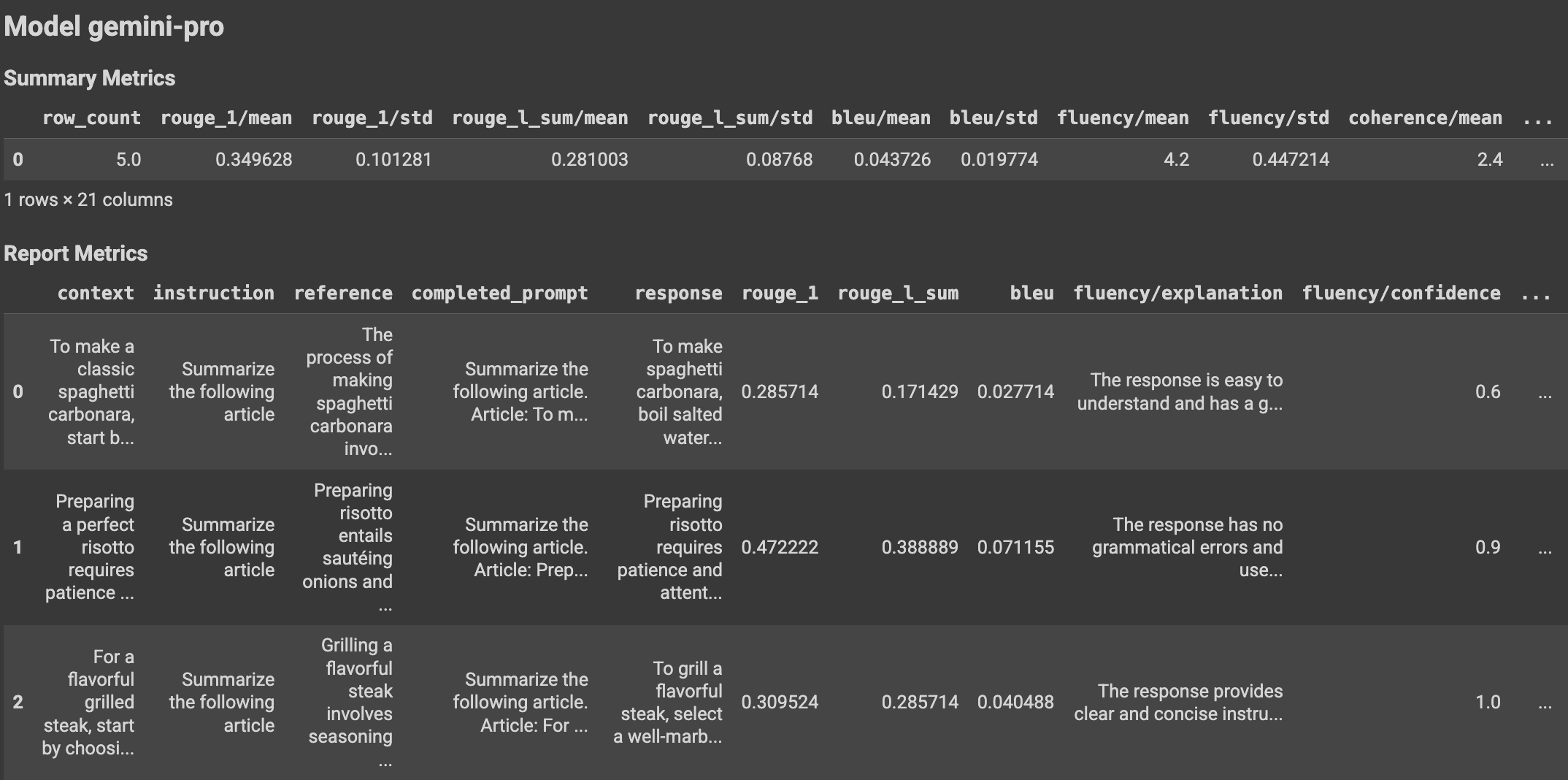
Visualizar los resultados de la evaluación
Puedes representar métricas de resumen en un gráfico de radar o de barras para visualizar y comparar los resultados de diferentes ejecuciones de evaluación. Esta visualización puede ser útil para evaluar diferentes modelos y plantillas de peticiones.
En el siguiente ejemplo, visualizamos cuatro métricas (coherencia, fluidez, cumplimiento de las instrucciones y calidad general del texto) de las respuestas generadas con cuatro plantillas de peticiones diferentes. A partir del gráfico de radar y del gráfico de barras, podemos deducir que la plantilla de petición n.º 2 supera sistemáticamente a las demás plantillas en las cuatro métricas. Esto se aprecia especialmente en sus puntuaciones significativamente más altas en cuanto a seguimiento de instrucciones y calidad del texto. Según este análisis, la plantilla de petición n.º 2 parece ser la opción más eficaz de las cuatro.
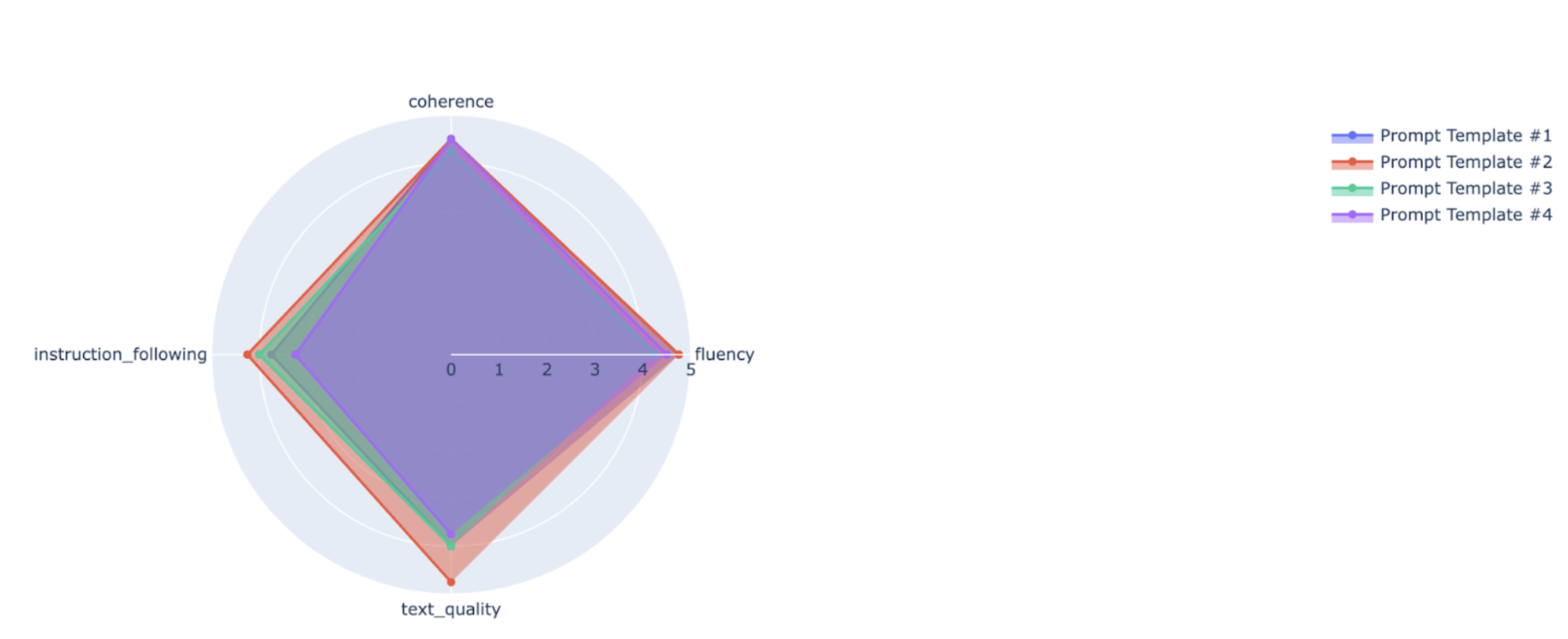
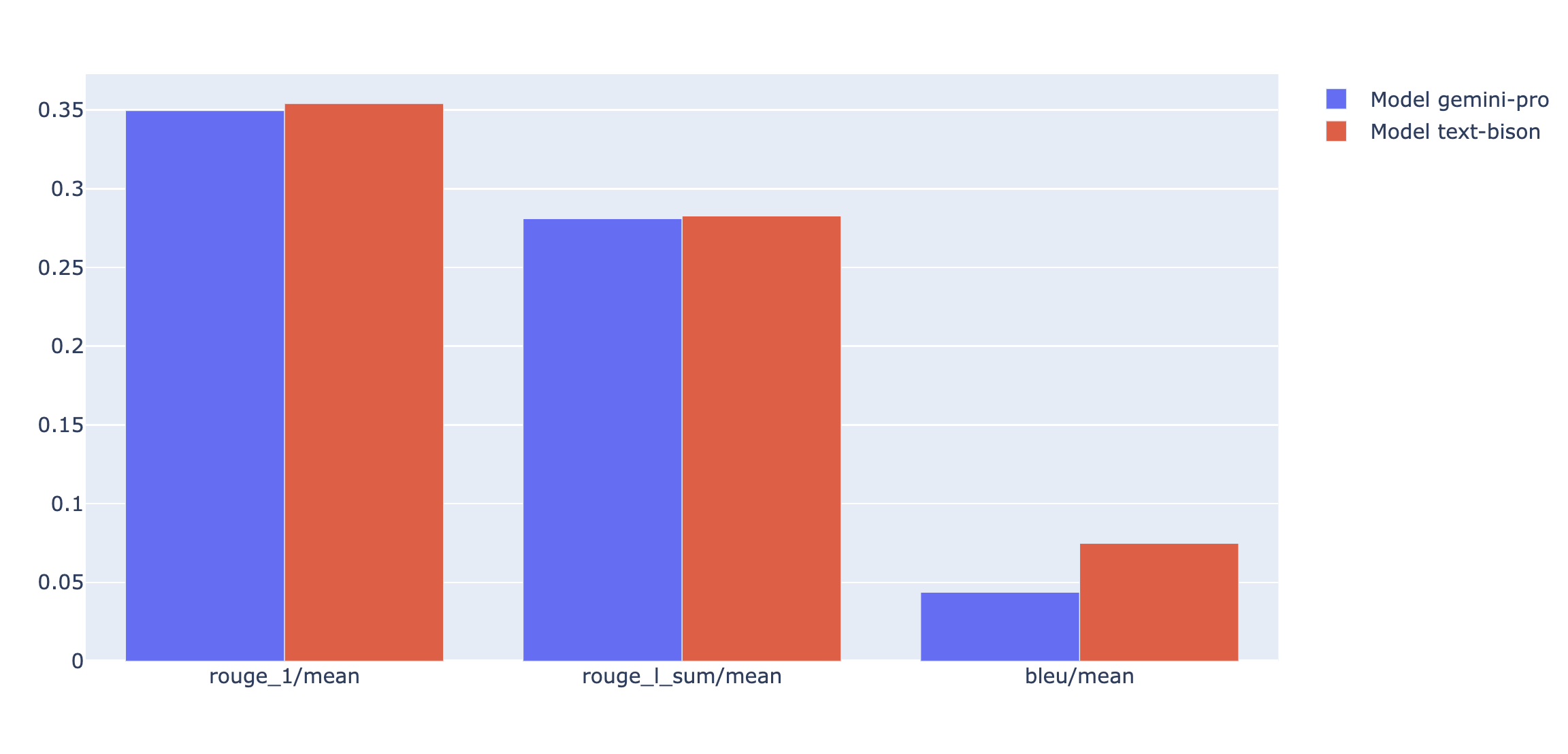
Interpretar los resultados de las métricas
En las siguientes tablas se enumeran varios componentes de los resultados a nivel de instancia y agregados incluidos en metrics_table y summary_metrics, respectivamente, para PointwiseMetric, PairwiseMetric y las métricas basadas en cálculos:
PointwiseMetric
Resultados a nivel de instancia
| Columna | Descripción |
|---|---|
| response | Respuesta generada por el modelo a la petición. |
| puntuación | La calificación que se ha dado a la respuesta según los criterios y la rúbrica de calificación. La puntuación puede ser binaria (0 y 1), de escala Likert (de 1 a 5 o de -2 a 2) o flotante (de 0, 0 a 1,0). |
| explicación | El motivo de la puntuación del modelo de juez. Usamos el razonamiento en cadena de pensamiento para guiar al modelo juez y que explique el motivo de cada veredicto. Se ha demostrado que obligar al modelo juez a razonar mejora la precisión de la evaluación. |
Resultados agregados
| Columna | Descripción |
|---|---|
| puntuación media | Puntuación media de todas las instancias. |
| desviación estándar | Desviación estándar de todas las puntuaciones. |
PairwiseMetric
Resultados a nivel de instancia
| Columna | Descripción |
|---|---|
| response | La respuesta generada por el modelo candidato a la petición. |
| baseline_model_response | La respuesta generada por el modelo de referencia a la petición. |
| pairwise_choice | El modelo con la mejor respuesta. Los valores posibles son CANDIDATE, BASELINE o TIE. |
| explicación | El motivo por el que el modelo de juez ha tomado esa decisión. |
Resultados agregados
| Columna | Descripción |
|---|---|
| candidate_model_win_rate | Relación entre el tiempo que el modelo de juez ha decidido que el modelo candidato tenía la mejor respuesta y el total de respuestas. El valor está comprendido entre 0 y 1. |
| baseline_model_win_rate | Ratio del tiempo en el que el modelo de juez ha decidido que el modelo de referencia tenía la mejor respuesta en comparación con el total de respuestas. El valor está comprendido entre 0 y 1. |
Métricas basadas en cálculos
Resultados a nivel de instancia
| Columna | Descripción |
|---|---|
| response | Se está evaluando la respuesta del modelo. |
| referencia | La respuesta de referencia. |
| puntuación | La puntuación se calcula para cada par de respuestas y referencias. |
Resultados agregados
| Columna | Descripción |
|---|---|
| puntuación media | Puntuación media de todas las instancias. |
| desviación estándar | Desviación estándar de todas las puntuaciones. |
Ejemplos
En los ejemplos de esta sección se muestra cómo leer e interpretar los resultados de la evaluación.
Ejemplo 1: Evaluación punto a punto
En el primer ejemplo, vamos a evaluar una instancia de evaluación puntual para TEXT_QUALITY. La puntuación de la evaluación puntual de la métrica TEXT_QUALITY es 4 (en una escala del 1 al 5), lo que significa que la respuesta es buena. Además, la explicación del resultado de la evaluación muestra por qué el modelo de juez cree que la predicción merece una puntuación de 4 y no una puntuación superior o inferior.
Conjunto de datos
prompt: "Resume el siguiente texto de forma que lo entienda un niño de cinco años: Social Media Platform Faces Backlash Over Content Moderation Policies\nA prominent social media platform finds itself embroiled in controversy as users and content creators express discontent over its content moderation policies. Las acusaciones de censura sesgada, de aplicación incoherente y de supresión de determinados puntos de vista han provocado indignación entre los usuarios que afirman que la plataforma está sofocando la libertad de expresión. Por otro lado, la plataforma afirma que sus políticas se han diseñado para mantener un entorno online seguro e inclusivo. Esta polémica plantea cuestiones más amplias sobre el papel de las redes sociales a la hora de dar forma al discurso público y sobre las responsabilidades de las plataformas a la hora de seleccionar el contenido online".response: "La gente está descontenta con un sitio web porque cree que no está siendo justo con lo que se puede publicar. Algunos usuarios dicen que el sitio web les impide decir lo que quieren. Pero el sitio web dice que está intentando proteger a todos los usuarios. Esto hace que los usuarios se pregunten si los sitios web deberían controlar lo que pueden decir online".
Resultado
score: 4,explanation: El resumen de la respuesta sigue la instrucción de resumir el contexto de forma que lo pueda entender un niño de cinco años. Se basa en el contexto y proporciona detalles importantes en su resumen. Sin embargo, el lenguaje utilizado en la respuesta es un poco extenso.
Ejemplo 2: Evaluación por pares
El segundo ejemplo es una evaluación de comparación por pares en PAIRWISE_QUESTION_ANSWERING_QUALITY. El resultado pairwise_choice muestra que el modelo juez prefiere la respuesta candidata "Francia es un país situado en Europa Occidental" a la respuesta de referencia "Francia es un país" para responder a la pregunta de la petición. Al igual que en los resultados de puntos, también se proporciona una explicación para indicar por qué la respuesta candidata es mejor que la respuesta de referencia (en este caso, la respuesta candidata es más útil).
Conjunto de datos
prompt: "¿Puedes decirme dónde está Francia basándote en el siguiente párrafo? Francia es un país situado en Europa Occidental. Limita con Bélgica, Luxemburgo, Alemania, Suiza, Italia, Mónaco, España y Andorra. La costa de Francia se extiende a lo largo del canal de la Mancha, el mar del Norte, el océano Atlántico y el mar Mediterráneo. Francia, conocida por su rica historia, sus monumentos emblemáticos, como la Torre Eiffel, y su deliciosa gastronomía, es una potencia cultural y económica de primer orden en Europa y en todo el mundo".response: "Francia es un país situado en Europa Occidental",baseline_model_response: "Francia es un país",
Resultado
pairwise_choice: CANDIDATE,explanation: la respuesta BASELINE se basa en la información proporcionada, pero no responde completamente a la pregunta. Sin embargo, la respuesta del CANDIDATO es correcta y proporciona detalles útiles sobre la ubicación de Francia.
Siguientes pasos
Prueba un cuaderno de ejemplo de evaluación.
Consulta información sobre la evaluación de la IA generativa.