Ce document explique comment surveiller le comportement, l'état et les performances de vos modèles entièrement gérés dans Vertex AI. Il explique comment utiliser le tableau de bord d'observabilité des modèles prédéfinis pour obtenir des insights sur l'utilisation des modèles, identifier les problèmes de latence et résoudre les erreurs.
Vous allez apprendre à :
- Accédez au tableau de bord d'observabilité des modèles et interprétez-le.
- Affichez les métriques de surveillance disponibles.
- Surveillez le trafic des points de terminaison du modèle à l'aide de l'explorateur de métriques.
Accéder au tableau de bord d'observabilité des modèles et l'interpréter
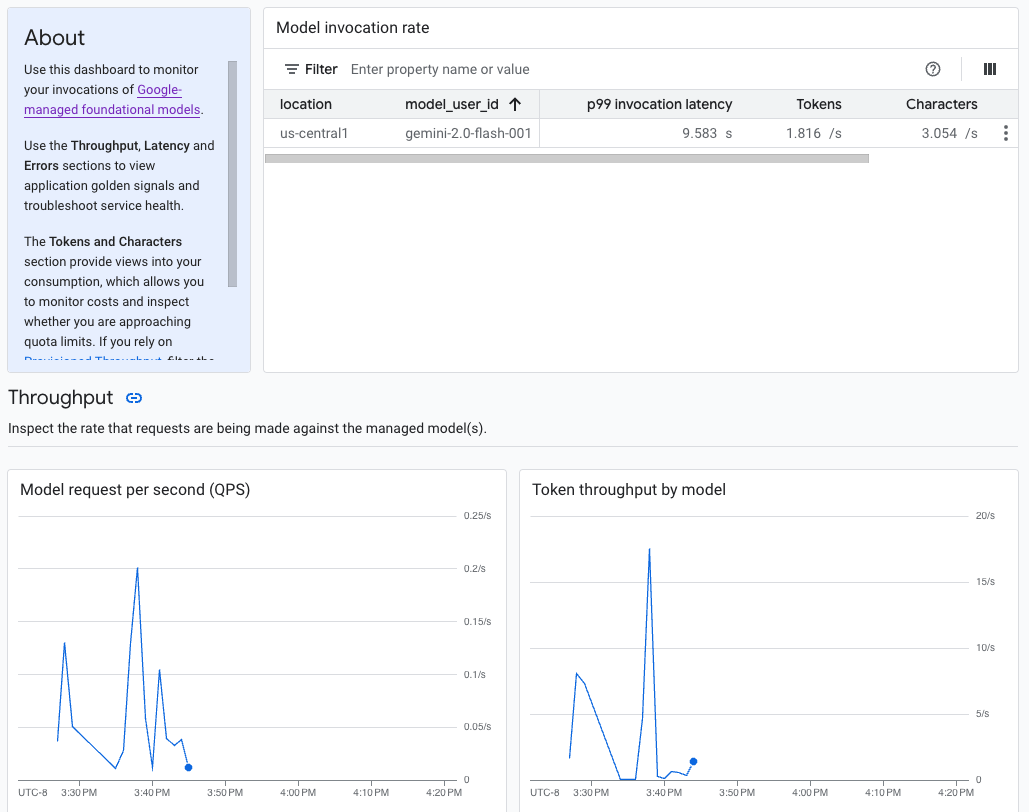
L'IA générative sur Vertex AI fournit un tableau de bord d'observabilité de modèle prédéfini pour afficher le comportement, l'état et les performances des modèles entièrement gérés. Les modèles entièrement gérés, également appelés "modèle en tant que service" (MaaS, Model as a Service), sont fournis par Google. Ils incluent les modèles Gemini de Google et les modèles partenaires avec des points de terminaison gérés. Les métriques des modèles auto-hébergés ne sont pas incluses dans le tableau de bord.
L'IA générative sur Vertex AI collecte et signale automatiquement l'activité des modèles MaaS pour vous aider à résoudre rapidement les problèmes de latence et à surveiller la capacité.
Cas d'utilisation
En tant que développeur d'applications, vous pouvez voir comment vos utilisateurs interagissent avec les modèles que vous avez exposés. Par exemple, vous pouvez voir comment l'utilisation du modèle (requêtes de modèle par seconde) et l'intensité de calcul des requêtes utilisateur (latences d'invocation du modèle) évoluent au fil du temps. Par conséquent, comme ces métriques sont liées à l'utilisation des modèles, vous pouvez également estimer les coûts d'exécution de chaque modèle.
En cas de problème, vous pouvez le résoudre rapidement depuis le tableau de bord. Vous pouvez vérifier si les modèles répondent de manière fiable et rapide en consultant les taux d'erreur de l'API, les latences du premier jeton et le débit de jetons.
Métriques de surveillance disponibles
Le tableau de bord d'observabilité des modèles affiche un sous-ensemble de métriques collectées par Cloud Monitoring, telles que les requêtes par seconde (RPS) du modèle, le débit de jetons et les latences du premier jeton. Affichez le tableau de bord pour voir toutes les métriques disponibles.
Limites
Vertex AI ne capture les métriques du tableau de bord que pour les appels d'API à un point de terminaison de modèle.L'utilisation de la console Google Cloud , comme les métriques de Vertex AI Studio, n'est pas ajoutée au tableau de bord.
Consulter le tableau de bord
- Dans la section Vertex AI de la console Google Cloud , accédez à la page Tableau de bord.
Accéder à Vertex AI 1. Dans le tableau de bord, sous "Observabilité du modèle", cliquez sur Afficher toutes les métriques pour afficher le tableau de bord d'observabilité du modèle dans la console Google Cloud Observability.
Pour afficher les métriques d'un modèle spécifique ou dans un lieu particulier, définissez un ou plusieurs filtres en haut de la page du tableau de bord.
Pour obtenir une description de chaque métrique, consultez la section "
aiplatform" sur la page Google Cloud métriques.
Surveiller le trafic des points de terminaison du modèle
Suivez les instructions ci-dessous pour surveiller le trafic vers votre point de terminaison dans l'explorateur de métriques.
Dans la console Google Cloud , accédez à la page Explorateur de métriques.
Sélectionnez le projet pour lequel vous souhaitez afficher les métriques.
Dans le menu déroulant Métrique, cliquez sur Sélectionner une métrique.
Dans la barre de recherche Filtrer par nom de ressource ou de métrique, saisissez
Vertex AI Endpoint.Sélectionnez la catégorie de métrique Point de terminaison Vertex AI > Prédiction. Sous Métriques actives, sélectionnez l'une des métriques suivantes :
prediction/online/error_countprediction/online/prediction_countprediction/online/prediction_latenciesprediction/online/response_count
Cliquez sur Appliquer. Pour ajouter plusieurs métriques, cliquez sur Ajouter une requête.
Vous pouvez filtrer ou agréger vos métriques à l'aide des menus déroulants suivants :
Pour sélectionner et afficher un sous-ensemble de vos données en fonction de critères spécifiés, utilisez le menu déroulant Filtre. Par exemple, pour filtrer le modèle
gemini-2.0-flash-001, utilisezendpoint_id = gemini-2p0-flash-001(notez que le.dans la version du modèle est remplacé par unp).Pour combiner plusieurs points de données en une seule valeur et afficher un récapitulatif de vos métriques, utilisez le menu déroulant Agrégation. Par exemple, vous pouvez agréger la somme de
response_code.
Vous pouvez éventuellement configurer des alertes pour votre point de terminaison. Pour en savoir plus, consultez Gérer les règles d'alerte.
Pour afficher les métriques que vous ajoutez à votre projet à l'aide d'un tableau de bord, consultez Présentation des tableaux de bord.
Étapes suivantes
- Pour savoir comment créer des alertes pour votre tableau de bord, consultez la présentation des alertes.
- Pour en savoir plus sur la conservation des données métriques, consultez la page Quotas et limites de Monitoring.
- Pour en savoir plus sur les données au repos, consultez Protéger les données au repos.
- Pour afficher la liste de toutes les métriques collectées par Cloud Monitoring, consultez la section "
aiplatform" de la page Google Cloud métriques.