En este documento, se explica cómo supervisar el comportamiento, el estado y el rendimiento de tus modelos completamente administrados en Vertex AI. En él, se describe cómo usar el panel de observabilidad del modelo prediseñado para obtener estadísticas sobre el uso del modelo, identificar problemas de latencia y solucionar errores.
Aprenderás a hacer lo siguiente:
- Acceder al panel de observabilidad del modelo e interpretarlo
- Consulta las métricas de supervisión disponibles.
- Supervisa el tráfico del extremo del modelo con el Explorador de métricas.
Cómo acceder al panel de observabilidad del modelo y cómo interpretarlo
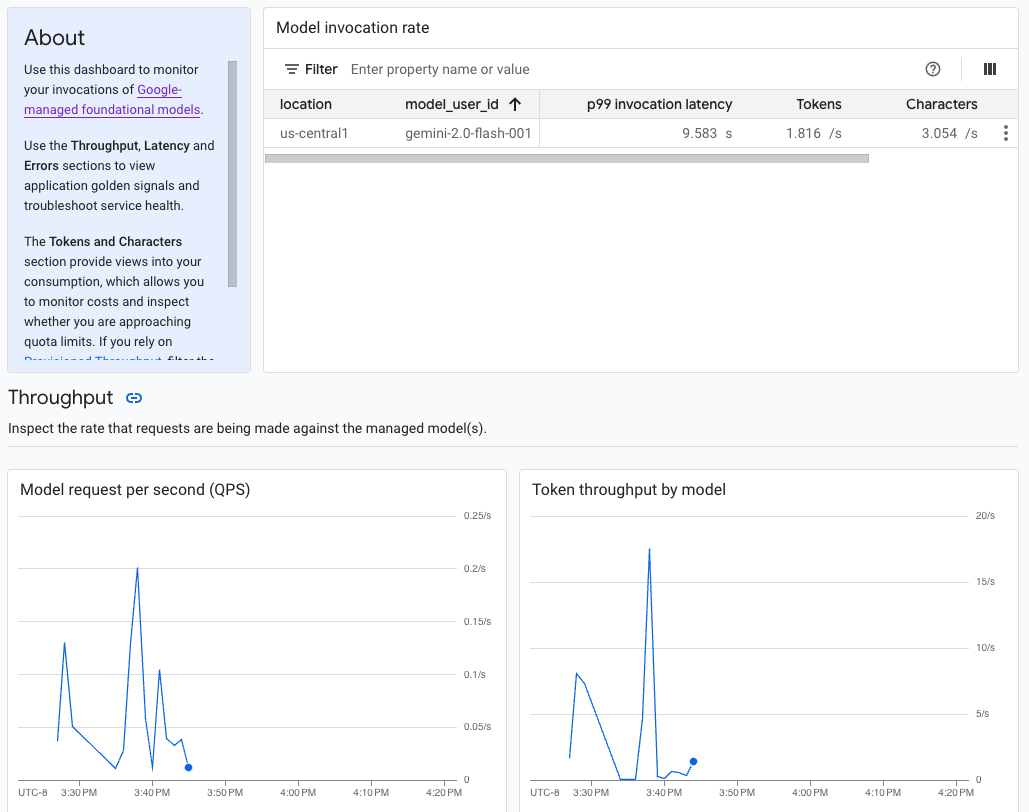
La IA generativa en Vertex AI proporciona un panel de observabilidad de modelos prediseñado para ver el comportamiento, el estado y el rendimiento de los modelos completamente administrados. Google proporciona los modelos completamente administrados, también conocidos como Modelos como servicio (MaaS), que incluyen los modelos Gemini de Google y los modelos de socios con extremos administrados. Las métricas de los modelos alojados por el usuario no se incluyen en el panel.
La IA generativa en Vertex AI recopila y registra automáticamente la actividad de los modelos de MaaS para ayudarte a solucionar rápidamente los problemas de latencia y supervisar la capacidad.
Caso de uso
Como desarrollador de aplicaciones, puedes ver cómo interactúan los usuarios con los modelos que expusiste. Por ejemplo, puedes ver cómo evoluciona el uso del modelo (solicitudes del modelo por segundo) y la intensidad de procesamiento de las instrucciones del usuario (latencias de invocación del modelo) con el tiempo. Por lo tanto, como estas métricas se relacionan con el uso del modelo, también puedes estimar los costos de ejecución de cada modelo.
Cuando surge un problema, puedes solucionarlo rápidamente desde el panel. Puedes verificar si los modelos responden de manera confiable y oportuna consultando las tasas de error de la API, las latencias del primer token y la capacidad de procesamiento de tokens.
Métricas de supervisión disponibles
En el panel de observabilidad del modelo, se muestra un subconjunto de las métricas que recopila Cloud Monitoring, como las solicitudes del modelo por segundo (QPS), el rendimiento de los tokens y las latencias del primer token. Consulta el panel para ver todas las métricas disponibles.
Limitaciones
Vertex AI captura las métricas del panel solo para las llamadas a la API al extremo de un modelo. Google Cloud El uso de la consola, como las métricas de Vertex AI Studio, no se agrega al panel.
Visualiza el panel
- En la sección Vertex AI de la Google Cloud consola, ve a la página Panel.
Ir a Vertex AI 1. En el panel, en Observabilidad del modelo, haz clic en Mostrar todas las métricas para ver el panel de observabilidad del modelo en la consola de Google Cloud Observability.
Para ver las métricas de un modelo específico o en una ubicación en particular, configura uno o más filtros en la parte superior de la página del panel.
Para ver descripciones de cada métrica, consulta la sección "
aiplatform" en la página Google Cloud métricas.
Supervisa el tráfico del extremo del modelo
Sigue las instrucciones que se indican a continuación para supervisar el tráfico hacia tu extremo en el Explorador de métricas.
En la consola de Google Cloud , ve a la página Explorador de métricas.
Selecciona el proyecto cuyas métricas deseas ver.
En el menú desplegable Métrica, haz clic en Seleccionar una métrica.
En la barra de búsqueda Filtrar por nombre de recurso o métrica, ingresa
Vertex AI Endpoint.Selecciona la categoría de métrica Vertex AI Endpoint > Prediction. En Métricas activas, selecciona cualquiera de las siguientes métricas:
prediction/online/error_countprediction/online/prediction_countprediction/online/prediction_latenciesprediction/online/response_count
Haz clic en Aplicar. Para agregar más de una métrica, haz clic en Agregar consulta.
Puedes filtrar o agregar tus métricas con los siguientes menús desplegables:
Para seleccionar y ver un subconjunto de tus datos según criterios específicos, usa el menú desplegable Filtro. Por ejemplo, para filtrar el modelo
gemini-2.0-flash-001, usaendpoint_id = gemini-2p0-flash-001(ten en cuenta que el.en la versión del modelo se reemplaza por unp).Para combinar varios puntos de datos en un solo valor y ver un resumen de tus métricas, usa el menú desplegable Agregación. Por ejemplo, puedes agregar la suma de
response_code.
De forma opcional, puedes configurar alertas para tu extremo. Para obtener más información, consulta Administra políticas de alertas.
Para ver las métricas que agregas a tu proyecto con un panel, consulta Descripción general de los paneles.
¿Qué sigue?
- Para obtener información sobre cómo crear alertas para tu panel, consulta Descripción general de alertas.
- Para obtener información sobre la retención de datos de métricas, consulta Cuotas y límites de Monitoring.
- Para obtener más información sobre los datos en reposo, consulta Protección de datos en reposo.
- Para ver una lista de todas las métricas que recopila Cloud Monitoring, consulta la sección "
aiplatform" en la página Google Cloud Métricas.