Vertex AI 嵌入模型可為各種工作類型生成最佳化嵌入,例如文件檢索、問答和事實查證。工作類型是標籤,可根據預期用途,最佳化模型產生的嵌入內容。本文說明如何為嵌入選擇最佳工作類型。
支援的模型
下列模型支援工作類型:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
工作類型的優點
工作類型可提升嵌入模型生成的嵌入內容品質。

舉例來說,建構檢索增強生成 (RAG) 系統時,常見的設計是使用文字嵌入和 Vector Search 執行相似度搜尋。在某些情況下,這可能會導致搜尋品質下降,因為問題和答案在語意上並不相似。舉例來說,「為什麼天空是藍色的?」和「陽光散射造成藍色」這兩個陳述句的意義截然不同,因此 RAG 系統不會自動辨識兩者之間的關係,如圖 1 所示。如果沒有工作類型,RAG 開發人員就必須訓練模型,瞭解查詢和答案之間的關係,這需要進階的資料科學技能和經驗,或是使用 LLM 查詢擴展或 HyDE,但這可能會導致高延遲和高成本。
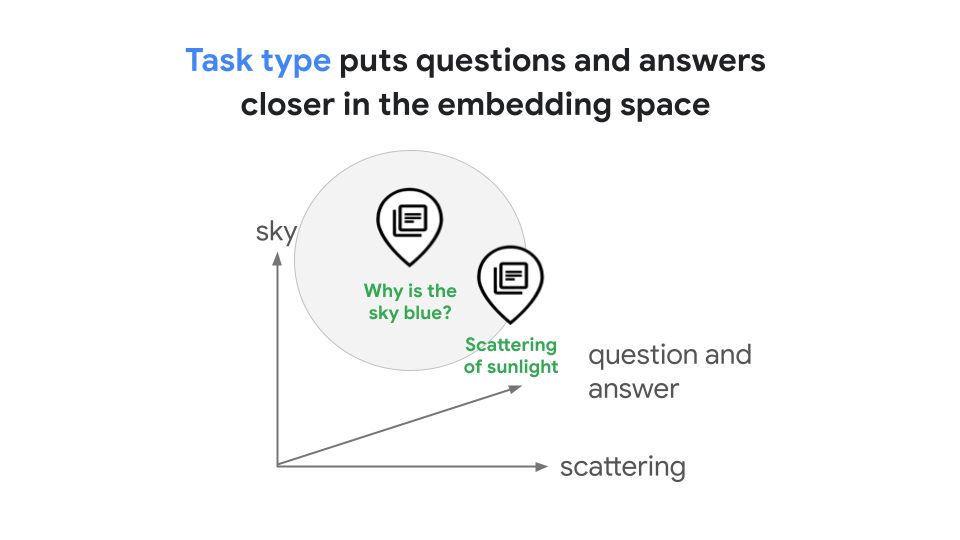
您可以使用工作類型,為特定工作產生最佳化嵌入,節省自行開發工作專屬嵌入的時間和費用。查詢「為什麼天空是藍的?」和答案「陽光散射造成藍色」產生的嵌入內容,會位於代表兩者關係的共用嵌入空間中,如圖 2 所示。在這個 RAG 範例中,經過最佳化的嵌入會提升相似度搜尋的準確度。
除了查詢和回答的使用案例,工作類型也提供最佳化的嵌入空間,適用於分類、叢集和事實查證等工作。
支援的工作類型
使用工作類型的嵌入模型支援下列工作類型:
| 工作類型 | 說明 |
|---|---|
CLASSIFICATION |
用於生成最佳化嵌入,根據預設標籤分類文字 |
CLUSTERING |
用於生成嵌入,並根據相似度將文字分組 |
RETRIEVAL_DOCUMENT、RETRIEVAL_QUERY、QUESTION_ANSWERING和 FACT_VERIFICATION |
用於生成最適合文件搜尋或資訊擷取的嵌入 |
CODE_RETRIEVAL_QUERY |
根據自然語言查詢擷取程式碼區塊,例如「排序陣列」或「反轉連結串列」。程式碼區塊的嵌入內容是使用 RETRIEVAL_DOCUMENT 計算而得。 |
SEMANTIC_SIMILARITY |
用於生成最佳化嵌入,以評估文字相似度。這項功能不適用於擷取用途。 |
最適合您嵌入作業的任務類型,取決於您嵌入的用途。選取工作類型前,請先判斷嵌入的用途。
判斷嵌入的用途
嵌入通常用於以下四種用途:評估文字相似度、分類文字、分群文字,或從文字中擷取資訊。如果您的用途不屬於上述任何類別,請預設使用 RETRIEVAL_QUERY 工作類型。
工作指令格式分為兩種:非對稱格式和對稱格式。請根據用途選用正確的參數。
| 擷取用途 (非對稱格式) |
查詢工作類型 | 文件工作類型 |
|---|---|---|
| 搜尋查詢 | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| 問題回答 | QUESTION_ANSWERING | |
| 事實查核 | FACT_VERIFICATION | |
| 擷取代碼 | CODE_RETRIEVAL_QUERY |
| 單一輸入內容的用途 (對稱格式) |
輸入工作類型 |
|---|---|
| 分類 | 分類 |
| 分群 | 分群 |
| 語意相似度 (請勿用於擷取用途; 適用於 STS) |
SEMANTIC_SIMILARITY |
分類文字
如要使用嵌入內容,根據預設標籤分類文字,請使用 CLASSIFICATION 工作類型。這類工作會在經過最佳化處理的嵌入空間中生成嵌入,以利分類。
舉例來說,假設您想為社群媒體貼文生成嵌入內容,然後用來將貼文的情緒分類為正面、負面或中立。如果社群媒體貼文的內嵌內容為「我不喜歡搭飛機旅行」,則情緒會分類為負面。
叢集文字
如要使用嵌入功能,根據文字相似度將文字分群,請使用 CLUSTERING 工作類型。這類工作會產生經過最佳化的嵌入,可根據相似度分組。
舉例來說,假設您想為新聞文章產生嵌入內容,以便向使用者顯示與他們先前閱讀文章主題相關的內容。產生並叢集嵌入內容後,您可以向大量閱讀運動文章的使用者推薦其他運動相關的文章。
分群的其他用途包括:
- 顧客區隔:根據顧客的個人資料或活動產生的類似嵌入,將顧客分組,以便進行目標行銷和提供個人化體驗。
- 產品區隔:根據產品名稱和說明、產品圖片或消費者評論,將產品嵌入內容分群,有助於商家對產品進行區隔分析。
- 市場研究:將消費者問卷調查回覆或社群媒體資料分群,可揭露消費者意見、偏好和行為的隱藏模式和趨勢,有助於市場研究工作,並為產品開發策略提供資訊。
- 醫療照護:從醫療資料衍生出的病患嵌入內容進行分群,有助於找出具有類似病況或治療反應的群組,進而制定更個人化的醫療照護計畫和目標治療。
- 顧客意見回饋趨勢:將各種管道 (問卷調查、社群媒體、支援單) 的顧客意見回饋歸類成群組,有助於找出常見痛點、功能要求和產品改善領域。
從訊息中擷取資訊
建構搜尋或擷取系統時,您會使用兩種文字:
- 語料庫:要搜尋的文件集合。
- 查詢:使用者提供的文字,用於在語料庫中搜尋資訊。
如要獲得最佳成效,您必須使用不同的工作類型,為語料庫和查詢產生嵌入。
首先,為整份文件集合生成嵌入。這是使用者查詢時會擷取的內容。嵌入這些文件時,請使用 RETRIEVAL_DOCUMENT 工作類型。您通常會執行這個步驟一次,為整個語料庫建立索引,然後將產生的嵌入項目儲存在向量資料庫中。
接著,當使用者提交搜尋查詢時,您會即時產生查詢文字的嵌入。為此,您應使用符合使用者意圖的工作類型。系統接著會使用這個查詢嵌入,在向量資料庫中找出最相似的文件嵌入。
查詢會使用下列工作類型:
RETRIEVAL_QUERY:用於標準搜尋查詢,可找出相關文件。模型會尋找與查詢嵌入在語意上相近的文件嵌入。QUESTION_ANSWERING:如果所有查詢都應為適當的問題,例如「為什麼天空是藍的?」或「如何綁鞋帶?」,請使用這個模式。FACT_VERIFICATION:如要從語料庫中擷取文件,證明或反駁某項陳述,請使用這項功能。舉例來說,查詢「蘋果生長在地下」可能會擷取有關蘋果的文章,但最終會證明這項陳述不實。
請參考下列實際情境,瞭解擷取查詢的用途:
- 以電子商務平台為例,您可以使用嵌入功能,讓使用者透過文字查詢和圖片搜尋產品,提供更直覺且引人入勝的購物體驗。
- 您想為教育平台建構問答系統,根據教科書內容或教育資源回答學生的問題,提供個人化學習體驗,協助學生瞭解複雜的概念。
擷取代碼
text-embedding-005 支援新的工作類型 CODE_RETRIEVAL_QUERY,可用於透過純文字查詢擷取相關程式碼區塊。如要使用這項功能,程式碼區塊應使用 RETRIEVAL_DOCUMENT 工作類型內嵌,而文字查詢則應使用 CODE_RETRIEVAL_QUERY 內嵌。
如要瞭解所有工作類型,請參閱模型參考資料。
範例如下:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
如要瞭解如何安裝或更新 Python 適用的 Vertex AI SDK,請參閱「安裝 Python 適用的 Vertex AI SDK」。 詳情請參閱 Python API 參考說明文件。
評估文字相似度
如要使用嵌入評估文字相似度,請使用 SEMANTIC_SIMILARITY 工作類型。這類工作會產生經過最佳化的嵌入,可產生相似度分數。
舉例來說,假設您想生成嵌入項目,用來比較下列文字的相似度:
- 貓咪正在睡覺
- 貓咪正在小睡
使用嵌入內容建立相似度分數時,由於兩段文字的意義幾乎相同,因此相似度分數會很高。
請參考下列實際情境,瞭解評估輸入內容相似度有何用處:
- 對於推薦系統,您想找出與使用者偏好項目語意相似的項目 (例如產品、文章、電影),提供個人化推薦內容並提升使用者滿意度。
使用這些模型時,請注意下列限制:
- 請勿在任務關鍵或生產系統中使用這些預覽模型。
- 這些型號僅在
us-central1販售。 - 不支援批次預測。
- 不支援自訂。
後續步驟
- 瞭解如何取得文字嵌入。