TPU v3
このドキュメントでは、Cloud TPU v3 のアーキテクチャとサポートされている構成について説明します。
システム アーキテクチャ
各 v3 TPU チップには、2 つの TensorCore が含まれています。各 TensorCore には、2 つのマトリックス乗算ユニット(MXU)、1 つのベクトル ユニット、1 つのスカラー ユニットがあります。次の表に、v3 TPU Pod の主な仕様と値を示します。
| 主な仕様 | v3 Pod の値 |
|---|---|
| チップあたりのピーク コンピューティング | 123 TFLOPS(bf16) |
| HBM2 の容量と帯域幅 | 32 GiB、900 GBps |
| 最小 / 平均 / 最大電力の測定値 | 123 / 220 / 262 W |
| TPU Pod のサイズ | 1,024 チップ |
| 相互接続トポロジ | 2D トーラス |
| Pod あたりのピーク コンピューティング | 126 PFLOPS(bf16) |
| Pod あたりの all-reduce 帯域幅 | 340 TB/秒 |
| Pod あたりの二分割帯域幅 | 6.4 TB/秒 |
次の図は、TPU v3 チップを示しています。
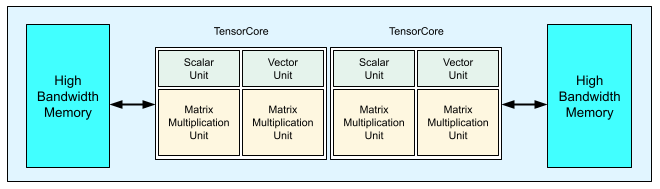
TPU v3 のアーキテクチャの詳細とパフォーマンス特性については、ディープ ニューラル ネットワークをトレーニングするための一領域に特化したスーパーコンピュータをご覧ください。
TPU v2 に対する TPU v3 のパフォーマンス上の利点
TPU v3 構成では、TensorCore あたりの FLOPS とメモリ容量が増えているため、以下の方法でモデルのパフォーマンスを改善できます。
計算依存型モデルの場合、TPU v3 構成を使用する TensorCore ごとのパフォーマンスが大幅に向上します。メモリ依存型モデルの場合、TPU v2 構成で TPU v3 構成と同等の改善を実現することはできません。
データが TPU v2 構成のメモリに収まらない場合、TPU v3 を使用することで、パフォーマンスが向上し、中間値の再計算(再実体化)も減少します。
TPU v3 構成では、TPU v2 構成に収まらないバッチサイズの新しいモデルを実行できます。たとえば、TPU v3 を使用すると、ResNet モデルでさらに詳しい処理を行い、RetinaNet でより大きなイメージを処理できます。
TPU v2 で入力依存型(インフィード)に近いモデルは、トレーニング ステップで入力を待機するため、Cloud TPU v3 でも入力依存型になる可能性があります。インフィードの問題を解決する方法については、パイプライン パフォーマンス ガイドをご覧ください。
構成
TPU v3 Pod は、高速リンクで相互接続された 1,024 個のチップで構成されます。TPU v3 デバイスまたはスライスを作成するには、TPU 作成コマンド(gcloud compute tpus tpu-vm)で --accelerator-type フラグを使用します。アクセラレータ タイプを指定するには、TPU のバージョンと TPU コアの数を指定します。たとえば、単一の v3 TPU の場合は、--accelerator-type=v3-8 を使用します。128 個の TensorCore を使用する v3 スライスの場合は、--accelerator-type=v3-128 を使用します。
次の表に、サポートされている v3 TPU タイプを示します。
| TPU バージョン | サポートの終了 |
|---|---|
| v3-8 | (終了日未定) |
| v3-32 | (終了日未定) |
| v3-128 | (終了日未定) |
| v3-256 | (終了日未定) |
| v3-512 | (終了日未定) |
| v3-1024 | (終了日未定) |
| v3-2048 | (終了日未定) |
次のコマンドは、128 個の TensorCore を使用して v3 TPU スライスを作成する方法を示しています。
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
TPU の管理の詳細については、TPU の管理をご覧ください。Cloud TPU のシステム アーキテクチャの詳細については、システム アーキテクチャをご覧ください。