La replicación es la capacidad de crear copias de una instancia de Cloud SQL o de una base de datos local y de delegar trabajo en las copias.
Introducción
El motivo principal para usar la réplica es escalar el uso de los datos en una base de datos sin que el rendimiento se vea afectado.
Otros motivos:
- Migrar datos entre regiones
- Migrar datos entre plataformas
- Migrar datos de una base de datos local a Cloud SQL
Además, se puede promocionar una réplica si la instancia original se daña.
Cuando se hace referencia a una instancia de Cloud SQL, la instancia que se replica se denomina instancia principal y las copias se denominan réplicas de lectura. La instancia principal y las réplicas de lectura residen en Cloud SQL.
Cuando se hace referencia a una base de datos local, el escenario de replicación se denomina replicación desde un servidor externo. En este caso, la base de datos que se replica es el servidor de la base de datos de origen. Las copias que residen en Cloud SQL se denominan réplicas de Cloud SQL. También hay una instancia que representa el servidor de la base de datos de origen en Cloud SQL, denominada instancia de representación de origen.
En un escenario de recuperación tras desastres, puedes promocionar una réplica para convertirla en una instancia principal. De esta forma, puedes usarla en lugar de una instancia que se encuentre en una región que esté sufriendo una interrupción. También puedes promover una réplica para sustituir una instancia dañada.
Cloud SQL admite los siguientes tipos de réplicas:
Si usas la aplicación de conectores, puedes obligar a que solo se usen el proxy de autenticación de Cloud SQL o los conectores de lenguaje de Cloud SQL para conectarse a las instancias de Cloud SQL. Con la aplicación de conectores, Cloud SQL rechaza las conexiones directas a la base de datos. No puedes crear réplicas de lectura de una instancia que tenga habilitada la aplicación de conectores. Del mismo modo, si una instancia tiene réplicas de lectura, no puedes habilitar la aplicación de conectores en ella.
También puedes usar Database Migration Service para replicar continuamente datos de un servidor de base de datos de origen a Cloud SQL. Nota: Cloud SQL permite a los usuarios gestionar su propia replicación mediante las funciones de replicación lógica de PostgreSQL.Cloud SQL no admite la replicación entre dos servidores externos.
Réplicas de lectura
Usas una réplica de lectura para descargar el trabajo de una instancia de Cloud SQL. La réplica de lectura es una copia exacta de la instancia principal. Los datos y otros cambios de la instancia principal se actualizan casi en tiempo real en la réplica de lectura.
Las réplicas de lectura son de solo lectura, por lo que no puedes escribir en ellas. La réplica de lectura procesa las consultas, las solicitudes de lectura y el tráfico de analíticas, lo que reduce la carga de la instancia principal.
Puedes conectarte a una réplica directamente mediante su nombre de conexión y su dirección IP. Si te conectas a una réplica mediante una dirección IP privada, no es necesario que crees una conexión privada de VPC adicional para la réplica, ya que la conexión se hereda de la instancia principal.
Para obtener información sobre cómo crear una réplica de lectura, consulta el artículo Crear réplicas de lectura. Para obtener información sobre cómo gestionar una réplica de lectura, consulta el artículo Gestionar réplicas de lectura.
Como práctica recomendada, coloca las réplicas de lectura en una zona diferente a la de la instancia principal cuando uses la alta disponibilidad en la instancia principal. De esta forma, las réplicas de lectura siguen funcionando cuando la zona que contiene la instancia principal sufre una interrupción. Consulta la información general sobre la alta disponibilidad para obtener más información.
Seleccionar un tipo de máquina adecuado
Las réplicas de lectura pueden tener un número de vCPUs y una cantidad de memoria diferentes a los de la réplica principal. Debes monitorizar las métricas de tu instancia, como el uso de la CPU y la memoria, para asegurarte de que la instancia réplica tiene el tamaño adecuado para su carga de trabajo, sobre todo si es más pequeña que la instancia principal. Una instancia de réplica que sea demasiado pequeña es más propensa a tener un rendimiento deficiente, como eventos de falta de memoria (OOM) frecuentes.
Capacidad de almacenamiento en réplicas de lectura
Cuando se cambia el tamaño de una instancia principal, también se cambia el tamaño de todas sus réplicas de lectura, si es necesario, para que tengan al menos la misma capacidad de almacenamiento que la instancia principal actualizada.
Impacto en la marca max_connections cuando la réplica de lectura tiene un tipo de máquina con menos memoria que la principal
En una instancia de PostgreSQL, si no asignas el valor que quieras a la marca max_connections, Cloud SQL la asignará automáticamente en función de la cantidad de memoria de la instancia. Para obtener más información, consulta las marcas admitidas. PostgreSQL requiere que el valor de max_connections sea siempre al menos tan grande en una réplica de lectura como en su principal. Por lo tanto, si una réplica de lectura tiene menos memoria que su réplica principal y no has definido la marca max_connections, puede heredar un valor mayor de max_connections en función del tamaño de la instancia principal. En esta situación, si utilizas el ajuste max_connections para limitar el número de conexiones a la instancia réplica, esta podría sobrecargarse porque el valor es demasiado alto en relación con el tipo de máquina de la instancia. Para evitarlo, puedes hacer lo siguiente:
- Cambia el tamaño de la instancia de réplica a un tipo de máquina más grande.
- Configura tu aplicación cliente para que se limite a un número de conexiones inferior al valor de
max_connections. - Asigna un valor adecuado a la marca
max_connectionsen la réplica y en el elemento principal.
Operaciones de índice de hash con réplicas de lectura
Las operaciones de índice hash no usan el registro anticipado de escritura en PostgreSQL 9.6. Cloud SQL solo tiene una versión disponible en PostgreSQL 10. Esto se explica en el cuadro de precaución amarillo de la página de lanzamiento de PostgreSQL. Esto también se aplica a las réplicas de lectura de Cloud SQL.
Como las actualizaciones de los índices hash no se propagan a la réplica de lectura en PostgreSQL 9.6, la réplica no puede usarlas. Como solución alternativa, puedes evitar tener réplicas de lectura o actualizar a una versión principal de PostgreSQL (10 o posterior).
Réplicas de lectura entre regiones
La replicación entre regiones te permite crear una réplica de lectura en una región diferente a la de la instancia principal. Las réplicas de lectura entre regiones se crean de la misma forma que las réplicas de la misma región.
Réplicas entre regiones:
- Mejora el rendimiento de lectura haciendo que las réplicas estén disponibles más cerca de la región de tu aplicación.
- Proporciona una función de recuperación tras desastres adicional para protegerte frente a un fallo regional.
- Te permite migrar datos de una región a otra.
Consulta Promocionar réplicas para la migración regional o la recuperación tras fallos para obtener más información sobre las réplicas entre regiones.
Réplicas de lectura en cascada
La replicación en cascada te permite crear una réplica de lectura en otra réplica de lectura de la misma región o de otra. Los siguientes casos prácticos muestran cómo usar réplicas en cascada:
- Recuperación tras fallos: puedes usar una jerarquía en cascada de réplicas de lectura para simular la topología de tu instancia principal y sus réplicas de lectura. Durante una interrupción, la réplica de lectura seleccionada se convierte en principal y las réplicas de lectura de la nueva principal siguen replicándose y están listas para usarse.
- Mejoras del rendimiento: reduce la carga de la instancia principal descargando el trabajo de replicación en varias réplicas de lectura.
- Escalar lecturas: puedes tener más réplicas para compartir la carga de lectura.
- Reducción de costes: puede reducir los costes de red usando una sola réplica en cascada con replicación entre regiones en otras regiones.
Terminología
- Réplica en cascada: réplica de lectura que puede tener su propia réplica.
- Niveles: puede crear niveles de réplicas en una jerarquía de réplicas en cascada. Por ejemplo, si añades cuatro réplicas a una instancia, esas cuatro réplicas estarán al mismo nivel.
- Instancias secundarias: varias réplicas que se replican desde la misma instancia principal. Los elementos del mismo nivel están en el mismo nivel de la jerarquía de réplicas. Una réplica puede tener oficialmente hasta ocho réplicas hermanas.
- Réplica hoja: réplica de lectura que no tiene ninguna réplica propia. En una jerarquía de replicación multinivel, la réplica de hoja es el último nivel.
- Promover: acción que convierte una réplica, en cualquier nivel de la jerarquía, en una instancia principal. Cuando se promueve, se conserva la jerarquía de réplicas en cascada de la réplica.
Configurar réplicas en cascada
Las réplicas en cascada te permiten añadir réplicas de lectura a cualquier réplica que ya tengas. Puedes añadir hasta cuatro niveles de réplicas, incluida la instancia principal. Cuando asciendes la réplica de la parte superior de una jerarquía de réplicas en cascada, se convierte en una instancia principal y sus réplicas en cascada siguen replicándose.
Para planificar tu configuración, debes tener un objetivo para lo que van a hacer las réplicas de lectura. En las dos secciones siguientes se describen las configuraciones para la recuperación ante desastres y la replicación multirregional.
Recuperación tras fallos
Para entender cómo te ayudan las réplicas en cascada a recuperarte rápidamente durante una interrupción, considera el siguiente escenario de replicación:
Configuración
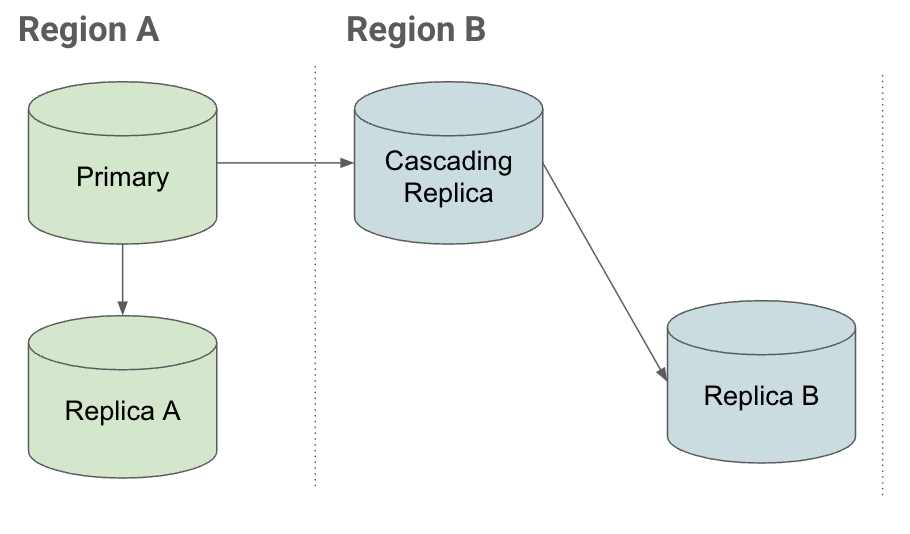
interrupción | interrupción del servicio (depending on context)
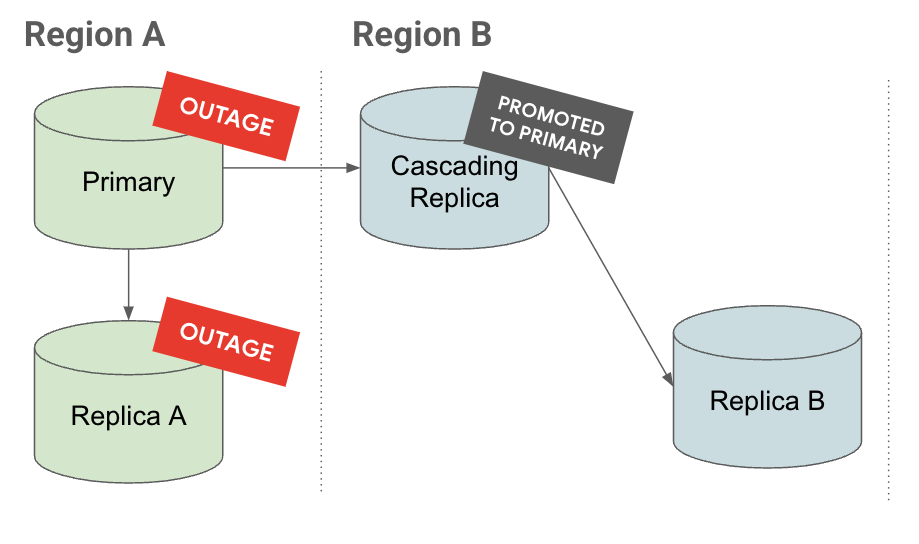
Promoción
Si quieres usar una instancia de la región B en una configuración de recuperación tras fallos y tienes lo siguiente:
- Réplicas de la misma región conectadas a la instancia principal (réplica A)
- Réplicas de otras regiones (réplica en cascada) conectadas a la principal.
Puedes crear réplicas de lectura en la réplica en cascada de la región B.
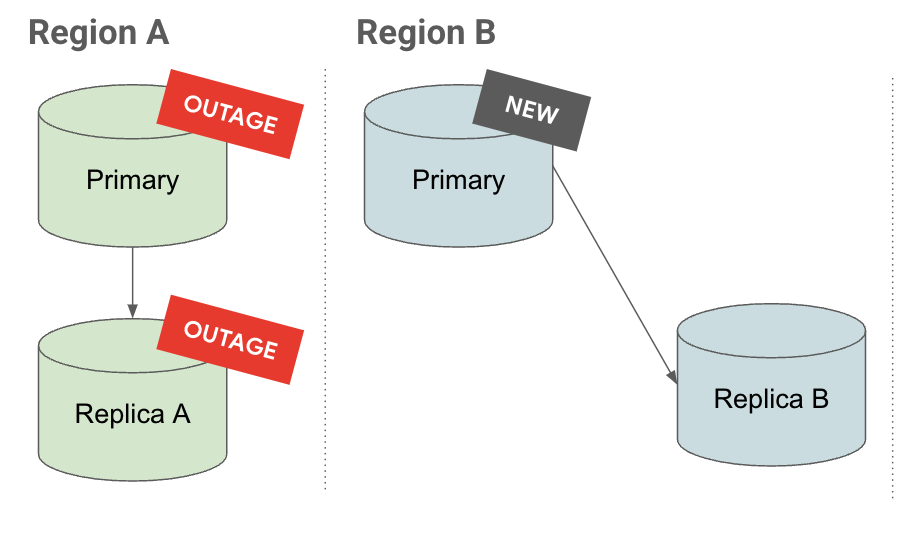
En la pestaña Interrupción del servicio, si hay una interrupción en la región A, la réplica en cascada se convierte en una instancia principal. Ya tiene réplicas de lectura, lo que reduce el objetivo de tiempo de recuperación (RTO).
En la pestaña Promocionar, verás que, cuando se promociona una réplica en cascada, sus réplicas también se promocionan y siguen replicándose en ella.
Replicación multirregional
Otro caso práctico de las réplicas en cascada es distribuir la capacidad de lectura a una segunda región de forma rentable. Se pueden crear réplicas en cascada C y D que se repliquen desde la réplica B. Los clientes pueden distribuir las consultas de lectura entre las réplicas B, C y D para reducir la carga de cada réplica. El coste del tráfico de red entre regiones solo se incurre una vez, desde la instancia principal hasta la réplica B. La replicación de B a C y D usa la transferencia de red en la región, que es gratuita.
Puedes crear una jerarquía de hasta cuatro instancias mediante réplicas en cascada para la replicación multirregión:
Principal A → Réplica B → Réplica C y Réplica D
Restricciones
- No puedes eliminar una réplica que tenga réplicas. Para eliminar la réplica, debes empezar por las réplicas de hoja y avanzar hacia arriba en la jerarquía.
- No se admite la dependencia de regiones circulares. Para que la réplica de una réplica en cascada esté en la misma región que la instancia principal, la réplica en cascada también debe estar en la misma región.
Replicación lógica
Cloud SQL te permite configurar tus propias soluciones de replicación mediante las funciones de replicación lógica de PostgreSQL. La réplica lógica es una solución flexible que permite lo siguiente:
- Replicación estándar de una instancia principal a una réplica
- Replicación selectiva de solo determinadas tablas o filas
- Replicación entre versiones principales de PostgreSQL
- Replicación en bases de datos que no son de PostgreSQL
- Flujos de trabajo de captura de datos de cambios (CDC) en los que todos los cambios de la base de datos se transmiten a un consumidor
Para obtener más información, consulta Configurar la replicación lógica. En esa página se incluye información sobre lo siguiente:
- Replicación lógica integrada
- La extensión pglogical
Casos prácticos de replicación
Los siguientes casos prácticos se aplican a cada tipo de replicación.
| Nombre | Principal | Réplica | Beneficios y casos prácticos | Más información |
|---|---|---|---|---|
| Réplica de lectura | Instancia de Cloud SQL | Instancia de Cloud SQL |
|
|
| Réplica de lectura entre regiones | Instancia de Cloud SQL | Instancia de Cloud SQL |
|
|
| Replicación lógica | Cualquier instancia de PostgreSQL independiente o principal | Cualquier instancia de PostgreSQL o un consumidor externo |
|
Facturación
- Una réplica de lectura se cobra a la misma tarifa que una instancia estándar de Cloud SQL. No se cobra nada por la replicación de datos.
- El precio de una réplica de lectura interregional es el mismo que el de crear una instancia de Cloud SQL en la región. Consulta los precios de las instancias de Cloud SQL y selecciona la región adecuada. Además del coste habitual asociado a la instancia, una réplica entre regiones incurre en cargos por transferencia de datos entre regiones por los registros de replicación enviados desde la instancia principal a la réplica, tal como se describe en la sección Precios del tráfico de salida de red.
Referencia rápida de las réplicas de lectura de Cloud SQL
| Tema | Debate |
|---|---|
| Copias de seguridad | No puedes configurar copias de seguridad en la réplica. |
| Núcleos y memoria | Las réplicas de lectura pueden usar un número de núcleos y una cantidad de memoria diferentes a los de la instancia principal. |
| Eliminar la instancia principal | Para poder eliminar una instancia principal, debes convertir todas sus réplicas de lectura en instancias independientes o eliminarlas. |
| Eliminar la réplica | Cuando eliminas una réplica, no afecta al estado de la instancia principal. |
| Inhabilitar el almacenamiento de registros de escritura previa | Para inhabilitar los registros write-ahead en una instancia principal, debes promover o eliminar todas sus réplicas de lectura. |
| Conmutación por error | Una instancia principal solo puede conmutar por error a una réplica si esta es una réplica de recuperación ante desastres. Las réplicas de lectura no pueden conmutar por error de ninguna forma durante una interrupción. |
| Alta disponibilidad | Las réplicas de lectura te permiten habilitar la alta disponibilidad en las réplicas. |
| Balanceo de carga | Cloud SQL no ofrece equilibrio de carga entre réplicas. Puedes implementar el balanceo de carga en tu instancia de Cloud SQL. También puedes usar el agrupamiento de conexiones para distribuir las consultas entre las réplicas con tu configuración de equilibrio de carga y mejorar el rendimiento. |
| Ventanas de mantenimiento | Las réplicas de lectura comparten ventanas de mantenimiento con la instancia principal. Las réplicas siguen la configuración de mantenimiento de la instancia principal, incluida la ventana de mantenimiento, la reprogramación y el periodo de denegación del mantenimiento. Durante el mantenimiento, Cloud SQL actualiza primero todas las réplicas de lectura y, después, la instancia principal. |
| Varias réplicas de lectura | Cloud SQL admite replicaciones en cascada. Por lo tanto, puedes crear hasta 10 réplicas de una sola instancia principal y crear réplicas de esas réplicas, hasta cuatro niveles, incluida la instancia principal. |
| IP privada | Si te conectas a una réplica mediante una dirección IP privada, no es necesario que crees una conexión privada de VPC adicional para la réplica, ya que se hereda de la instancia principal. |
| Restaurar la instancia principal | No puedes restaurar la instancia principal de una réplica mientras la réplica exista. Antes de restaurar una instancia a partir de una copia de seguridad o de realizar una recuperación a un momento dado en ella, debes promocionar o eliminar todas sus réplicas. |
| Ajustes | Los ajustes de la instancia principal se propagan a la réplica, incluido el password del usuario postgres y los cambios en la tabla de usuarios. |
| Detener una réplica | No puedes stop una réplica. Puedes restart, delete o disable replication en ella, pero no puedes detenerla como harías con una instancia principal. |
| Actualizar una réplica | Las réplicas de lectura pueden experimentar una actualización disruptiva en cualquier momento. |
| Tablas de usuarios | No puedes hacer cambios en la réplica. Todos los cambios de usuario deben realizarse en la instancia principal. |
Siguientes pasos
- Aprende a crear una réplica de lectura.
- Consulta cómo configurar una instancia para alta disponibilidad.
- Información sobre la recuperación tras fallos avanzada