La replica è la possibilità di creare copie di un'istanza Cloud SQL o di un database on-premise e di trasferire il lavoro alle copie.
Introduzione
Il motivo principale per utilizzare la replica è scalare l'utilizzo dei dati in un database senza peggiorare le prestazioni.
Altri motivi sono:
- Migrazione dei dati tra regioni
- Migrazione dei dati tra piattaforme
- Migrazione dei dati da un database on-premise a Cloud SQL
Inoltre, una replica potrebbe essere promossa se l'istanza originale viene danneggiata.
Quando si fa riferimento a un'istanza Cloud SQL, l'istanza replicata è chiamata istanza principale e le copie sono chiamate repliche di lettura. L'istanza principale e le repliche di lettura si trovano in Cloud SQL.
Quando si fa riferimento a un database on-premise, lo scenario di replica è chiamato replica da un server esterno. In questo scenario, il database replicato è il server di database di origine. Le copie che risiedono in Cloud SQL sono chiamate repliche Cloud SQL. Esiste anche un'istanza che rappresenta il server di database di origine in Cloud SQL chiamata istanza di rappresentazione dell'origine.
In uno scenario di ripristino di emergenza, puoi promuovere una replica per convertirla in un'istanza primaria. In questo modo, puoi utilizzarlo al posto di un'istanza che si trova in una regione in cui si è verificato un'interruzione. Puoi anche promuovere una replica per sostituire un'istanza danneggiata.
Cloud SQL supporta i seguenti tipi di repliche:
Utilizzando l'applicazione del connettore, puoi forzare l'utilizzo solo del proxy di autenticazione Cloud SQL o dei connettori dei linguaggi di Cloud SQL per connetterti alle istanze Cloud SQL. Con l'applicazione del connettore, Cloud SQL rifiuta le connessioni dirette al database. Non puoi creare repliche di lettura per un'istanza per cui è abilitata l'applicazione del connettore. Allo stesso modo, se un'istanza ha repliche di lettura, non puoi abilitare l'applicazione del connettore per l'istanza.
Puoi anche utilizzare Database Migration Service per la replica continua da un server di database di origine a Cloud SQL. Nota: Cloud SQL consente agli utenti di gestire la propria replica utilizzando le funzionalità di replica logica di PostgreSQL.Cloud SQL non supporta la replica tra due server esterni.
Repliche di lettura
Utilizzi una replica di lettura per trasferire il lavoro da un'istanza Cloud SQL. La replica di lettura è una copia esatta dell'istanza principale. I dati e le altre modifiche all'istanza primaria vengono aggiornati quasi in tempo reale sulla replica di lettura.
Le repliche di lettura sono di sola lettura, non puoi scriverci. La replica di lettura elabora query, richieste di lettura e traffico di analisi, riducendo così il carico sull'istanza primaria.
Ti connetti a una replica direttamente utilizzando il nome della connessione e l'indirizzo IP. Se ti connetti a una replica utilizzando un indirizzo IP privato, non devi creare una connessione privata VPC aggiuntiva per la replica perché la connessione viene ereditata dall'istanza primaria.
Per informazioni su come creare una replica di lettura, consulta Creazione di repliche di lettura. Per informazioni sulla gestione di una replica di lettura, vedi Gestione delle repliche di lettura.
Come best practice, inserisci le repliche di lettura in una zona diversa dall'istanza principale quando utilizzi l'alta disponibilità sull'istanza principale. Questa pratica garantisce che le repliche di lettura continuino a funzionare quando la zona che contiene l'istanza principale ha un'interruzione. Per ulteriori informazioni, consulta la panoramica dell'alta disponibilità.
Selezionare un tipo di macchina appropriato
Le repliche di lettura possono avere un numero diverso di vCPU e memoria rispetto a quelle del primario. Devi monitorare le metriche sulla tua istanza, come l'utilizzo di CPU e memoria, per assicurarti che l'istanza di replica sia dimensionata correttamente per il suo workload, soprattutto se è più piccola dell'istanza principale. Un'istanza di replica sottodimensionata è più soggetta a prestazioni scarse, ad esempio a frequenti eventi di esaurimento della memoria (OOM).
Capacità di archiviazione sulle repliche di lettura
Quando viene ridimensionata un'istanza primaria, vengono ridimensionate anche tutte le relative repliche di lettura, se necessario, in modo che abbiano almeno la stessa capacità di archiviazione dell'istanza primaria aggiornata.
Impatto sul flag max_connections quando la replica di lettura ha un tipo di macchina con meno memoria rispetto al database primario
In un'istanza PostgreSQL, se non imposti il flag max_connections
su un valore a tua scelta, Cloud SQL lo imposta automaticamente in base alla
quantità di memoria dell'istanza. Per ulteriori informazioni, vedi flag supportati. PostgreSQL richiede
che il
valore di max_connections sia sempre almeno pari a quello della replica di lettura. Pertanto, se una replica di lettura ha meno memoria
rispetto alla relativa istanza principale e non hai impostato il flag max_connections, potrebbe
ereditare un valore maggiore di max_connections in base alle dimensioni
dell'istanza principale. In questa situazione, se ti affidi all'impostazione
max_connections per limitare il numero di connessioni all'istanza
replica, questa potrebbe sovraccaricarsi perché il valore è troppo alto
rispetto al tipo di macchina dell'istanza. Per evitare questo problema, puoi procedere in uno dei seguenti modi:
- Ridimensiona l'istanza di replica a un tipo di macchina più grande.
- Configura l'applicazione client in modo da limitarla a un numero di connessioni
inferiore al valore di
max_connections. - Imposta il flag
max_connectionssul database primario e sulla replica su un valore appropriato.
Operazioni di indice hash utilizzando le repliche di lettura
Le operazioni di indice hash non utilizzano la registrazione anticipata per PostgreSQL 9.6. Cloud SQL ha una sola versione disponibile in PostgreSQL 10. Questo è documentato nella casella di avviso gialla nella pagina di rilascio di PostgreSQL. Questo vale anche per le repliche di lettura Cloud SQL.
Poiché gli aggiornamenti dell'indice hash non vengono propagati alla replica di lettura in PostgreSQL 9.6, non possono essere utilizzati dalla replica. Come soluzione alternativa, puoi evitare di avere repliche di lettura o eseguire l'upgrade a una versione principale di PostgreSQL (10 o successive).
Repliche di lettura tra regioni
La replica tra regioni consente di creare una replica di lettura in una regione diversa dall'istanza principale. Crea una replica di lettura tra regioni nello stesso modo in cui crei una replica nella regione.
Repliche tra regioni:
- Migliora le prestazioni di lettura rendendo disponibili le repliche più vicine alla regione della tua applicazione.
- Fornire una funzionalità di ripristino di emergenza aggiuntiva per proteggersi da un errore a livello regionale.
- Consente di eseguire la migrazione dei dati da una regione all'altra.
Per saperne di più sulle repliche tra regioni, consulta la sezione Promozione di repliche per la migrazione a livello di area geografica o il ripristino di emergenza.
Repliche di lettura a cascata
La replica a cascata consente di creare una replica di lettura sotto un'altra replica di lettura nella stessa regione o in una regione diversa. I seguenti scenari sono casi d'uso per l'utilizzo di repliche in cascata:
- Disaster recovery: puoi utilizzare una gerarchia a cascata di repliche di lettura per simulare la topologia dell'istanza principale e delle relative repliche di lettura. Durante un'interruzione, la replica di lettura selezionata viene promossa a principale e le repliche di lettura sotto la nuova istanza principale continuano a replicarsi e sono pronte per l'uso.
- Miglioramenti delle prestazioni: riduci il carico sull'istanza principale trasferendo il lavoro di replica a più repliche di lettura.
- Scalare le letture: puoi avere più repliche per condividere il carico di lettura.
- Riduzione dei costi: puoi ridurre i costi di networking utilizzando una singola replica in cascata con la replica tra regioni in altre regioni.
Terminologia
- Replica a cascata: una replica di lettura che può avere la propria replica.
- Livelli: puoi creare livelli di repliche in una gerarchia di repliche a cascata. Ad esempio, se aggiungi quattro repliche a un'istanza, queste quattro repliche si trovano allo stesso livello.
- Istanze secondarie: più repliche che vengono replicate dalla stessa istanza principale. I peer si trovano allo stesso livello nella gerarchia di replica. Una replica può avere ufficialmente fino a otto fratelli.
- Replica foglia: una replica di lettura che non ha repliche proprie. In una gerarchia di replica multilivello, la replica foglia è l'ultimo livello.
- Promuovi Un'azione che converte una replica, a qualsiasi livello della gerarchia, in un'istanza principale. Una volta promossa, la gerarchia delle repliche a cascata della replica viene mantenuta.
Configurare le repliche a cascata
Le repliche a cascata ti consentono di aggiungere repliche di lettura a qualsiasi replica esistente. Puoi aggiungere fino a quattro livelli di repliche, inclusa l'istanza primaria. Quando promuovi la replica nella parte superiore di una gerarchia di repliche a cascata, questa diventa un'istanza principale e le relative repliche a cascata continuano a essere replicate.
Per pianificare la configurazione, devi avere un obiettivo per le repliche di lettura. Le due sezioni successive descrivono le configurazioni per il ripristino di emergenza e la replica multiregionale.
Disaster recovery
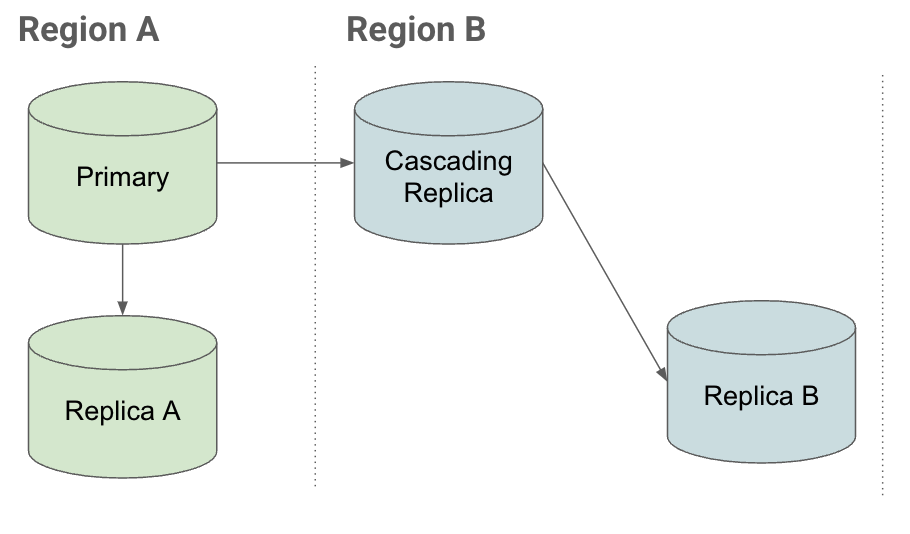
Per capire in che modo le repliche a cascata ti aiutano a eseguire il ripristino rapidamente durante un'interruzione, considera lo scenario di replica seguente:
Configurazione
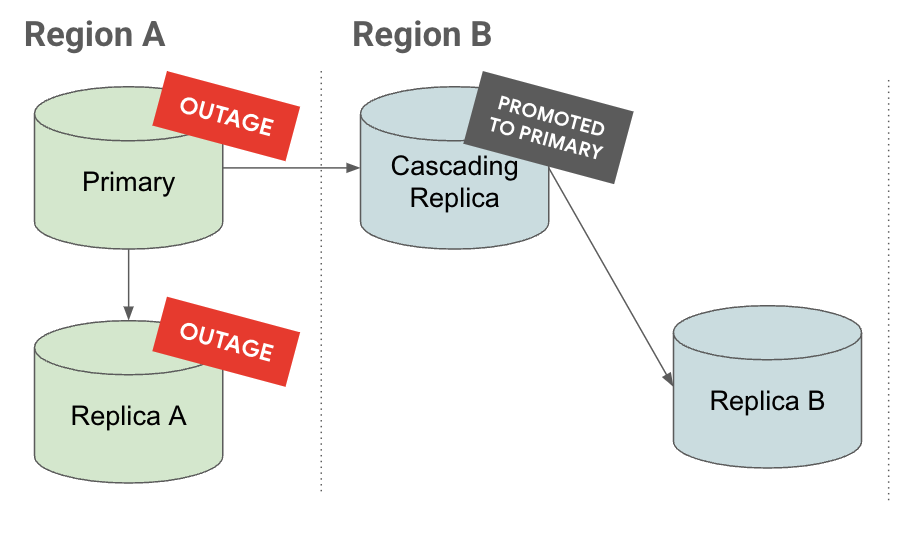
Interruzione
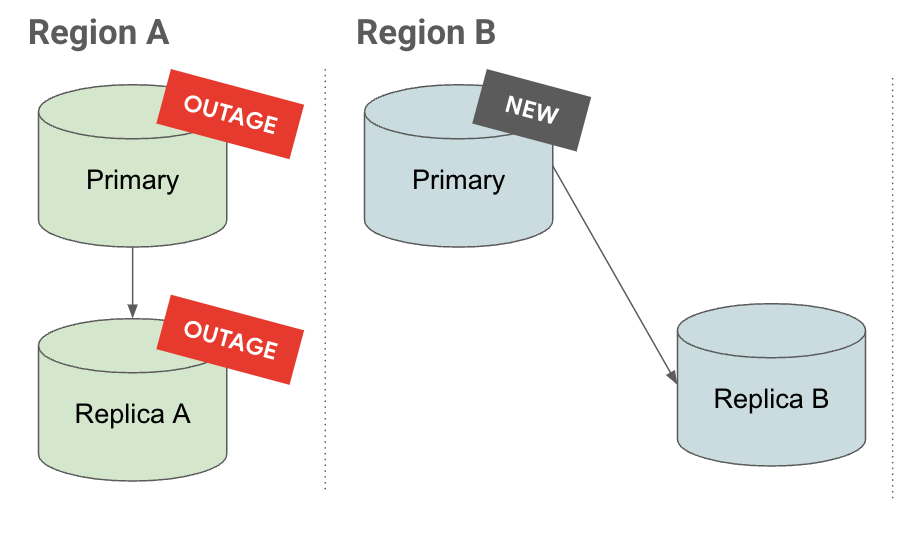
Promozione
Se vuoi utilizzare un'istanza nella regione B in una configurazione di ripristino di emergenza e hai:
- Repliche nella stessa regione collegate all'istanza principale (replica A)
- Replica in altre regioni (replica a cascata) collegata alla replica primaria.
Puoi creare repliche di lettura nella replica a cascata nella regione B.
Nella scheda Interruzione, se si verifica un'interruzione nella regione A, la replica in cascata viene promossa a istanza principale. Ha già repliche di lettura sottostanti, riducendo il Recovery Time Objective (RTO).
Nella scheda Promuovi, puoi notare che quando viene promossa una replica a cascata, anche le relative repliche vengono promosse e continuano a essere replicate.
Replica su più regioni
Un altro caso d'uso per le repliche a cascata è la distribuzione della capacità di lettura a una seconda regione in modo conveniente. È possibile creare le repliche a cascata C e D che vengono replicate dalla replica B. I client possono distribuire le query di lettura tra le repliche B, C e D per ridurre il carico su ciascuna replica. Il costo del traffico di rete tra regioni viene addebitato una sola volta, dall'istanza primaria alla replica B. La replica da B a C e D utilizza il trasferimento di rete nella regione, che è gratuito.
Puoi creare una gerarchia di massimo quattro istanze utilizzando repliche a cascata per la replica multiregionale:
Primario A → Replica B → Replica C e Replica D
Limitazioni
- Non puoi eliminare una replica che contiene altre repliche. Per eliminare la replica, devi iniziare dalle repliche foglia e procedere verso l'alto nella gerarchia.
- La dipendenza circolare della regione non è supportata. Per avere la replica di una replica a cascata nella stessa regione dell'istanza primaria, anche la replica a cascata deve trovarsi nella stessa regione.
Replica logica
Cloud SQL ti consente di configurare le tue soluzioni di replica utilizzando le funzionalità di replica logica di PostgreSQL. La replica logica è una soluzione flessibile che consente di:
- Replica standard da un'istanza principale a una replica
- Replica selettiva solo di determinate tabelle o righe
- Replica tra le versioni principali di PostgreSQL
- Replica su database non PostgreSQL
- Flussi di lavoro Change Data Capture (CDC) in cui tutte le modifiche al database vengono trasmesse in streaming a un consumer
Per maggiori informazioni, vedi Configurazione della replica logica. Questa pagina include informazioni su:
- Replica logica integrata
- L'estensione pglogical
Casi d'uso della replica
I seguenti casi d'uso si applicano a ogni tipo di replica.
| Nome | Principale | Replica | Vantaggi e casi d'uso | Ulteriori informazioni |
|---|---|---|---|---|
| Replica in lettura | Istanza Cloud SQL | Istanza Cloud SQL |
|
|
| Replica di lettura tra regioni | Istanza Cloud SQL | Istanza Cloud SQL |
|
|
| Replica logica | Qualsiasi istanza PostgreSQL standalone o primaria | Qualsiasi istanza PostgreSQL o un consumer esterno |
|
Fatturazione
- Una replica di lettura viene addebitata alla stessa tariffa di un'istanza Cloud SQL standard. Non è previsto alcun costo per la replica dei dati.
- Il prezzo di una replica di lettura tra regioni è lo stesso della creazione di una nuova istanza Cloud SQL nella regione. Consulta i prezzi delle istanze Cloud SQL e seleziona la regione appropriata. Oltre al costo normale associato all'istanza, una replica tra regioni comporta costi di trasferimento di dati tra regioni per i log di replica inviati dall'istanza principale all'istanza di replica, come descritto in Prezzi del traffico di rete in uscita.
Guida di riferimento rapida per le repliche di lettura Cloud SQL
| Argomento | Discussione |
|---|---|
| Backup | Non puoi configurare i backup sulla replica. |
| Core e memoria | Le repliche di lettura possono utilizzare un numero diverso di core e una quantità di memoria rispetto a quelli dell'istanza principale. |
| Eliminazione dell'istanza primaria | Prima di poter eliminare un'istanza primaria, devi promuovere tutte le relative repliche di lettura a istanze autonome o eliminare le repliche di lettura. |
| Eliminazione della replica | Quando elimini una replica, lo stato dell'istanza principale non viene modificato. |
| Disattivare il logging write-ahead | Prima di poter disabilitare i log write-ahead su un'istanza principale, devi promuovere o eliminare tutte le relative repliche di lettura. |
| Failover | Un'istanza principale può eseguire il failover su una replica solo se la replica è una replica di RE. Le repliche di lettura non sono in grado di eseguire il failover in alcun modo durante un'interruzione. |
| Alta disponibilità | Le repliche di lettura ti consentono di abilitare l'alta disponibilità sulle repliche. |
| Bilanciamento del carico | Cloud SQL non fornisce il bilanciamento del carico tra le repliche. Puoi scegliere di implementare il bilanciamento del carico per l'istanza Cloud SQL. Puoi anche utilizzare il pooling delle connessioni per distribuire le query tra le repliche con la configurazione del bilanciamento del carico per ottenere prestazioni migliori. |
| Periodi di manutenzione | Le repliche di lettura condividono i periodi di manutenzione con l'istanza principale. Le repliche seguono le impostazioni di manutenzione per l'istanza principale, inclusi il periodo di manutenzione, la riprogrammazione e il periodo di manutenzione negata. Durante la manutenzione, Cloud SQL aggiorna prima tutte le repliche di lettura e poi l'istanza principale. |
| Più repliche di lettura | Cloud SQL supporta le repliche a cascata. Di conseguenza, puoi creare fino a 10 repliche per una singola istanza principale e creare repliche di queste repliche, fino a quattro livelli inclusa l'istanza principale. |
| IP privato | Se ti connetti a una replica utilizzando un indirizzo IP privato, non devi creare una connessione privata VPC aggiuntiva per la replica, in quanto viene ereditata dall'istanza principale. |
| Ripristino dell'istanza principale | Non puoi ripristinare l'istanza principale di una replica mentre la replica esiste. Prima di ripristinare un'istanza da un backup o di eseguire un recupero point-in-time, devi promuovere o eliminare tutte le relative repliche. |
| Impostazioni | Le impostazioni dell'istanza principale vengono propagate alla replica, inclusa la password per l'utente postgres e le modifiche alla tabella utenti. |
| Arresto di una replica | Non puoi stop una replica. Puoi restart,
delete o disable replication, ma non puoi
interromperla come un'istanza principale. |
| Eseguire l'upgrade di una replica | Le repliche di lettura possono subire un upgrade distruttivo in qualsiasi momento. |
| Tabelle degli utenti | Non puoi apportare modifiche alla replica. Tutte le modifiche all'utente devono essere apportate all'istanza principale. |
Passaggi successivi
- Scopri come creare una replica di lettura.
- Scopri come configurare un'istanza per l'alta disponibilità.
- Scopri di più sul disaster ripristino di emergenza (RE) avanzato