Replication is the ability to create copies of a Cloud SQL instance or an on-premises database, and offload work to the copies.
Introduction
The primary reason for using replication is to scale the use of data in a database without degrading performance.
Other reasons include:
- Migrating data between regions
- Migrating data between platforms
- Migrating data from an on-premises database to Cloud SQL
Additionally, a replica could be promoted if the original instance becomes corrupted.
When referring to a Cloud SQL instance, the instance that is replicated is called the primary instance and the copies are called read replicas. The primary instance and read replicas reside in Cloud SQL.
When referring to an on-premises database, the replication scenario is called replicating from an external server. In this scenario, the database that is replicated is the source database server. The copies that reside in Cloud SQL are called Cloud SQL replicas. There is also an instance that represents the source database server in Cloud SQL called the source representation instance.
In a disaster recovery scenario, you can promote a replica to convert it to a primary instance. This way, you can use it in place of an instance that's in a region that's having an outage. You can also promote a replica to replace an instance that's corrupted.
Cloud SQL supports the following types of replicas:
By using connector enforcement, you can enforce using only the Cloud SQL Auth Proxy or Cloud SQL Language Connectors to connect to Cloud SQL instances. With connector enforcement, Cloud SQL rejects direct connections to the database. You can't create read replicas for an instance that has connector enforcement enabled. Similarly, if an instance has read replicas, then you can't enable connector enforcement for the instance.
You can also use Database Migration Service for continuous replication from a source database server to Cloud SQL. Note: Cloud SQL allows users to manage their own replication using PostgreSQL's logical replication features.Cloud SQL doesn't support replication between two external servers.
Read replicas
You use a read replica to offload work from a Cloud SQL instance. The read replica is an exact copy of the primary instance. Data and other changes on the primary instance are updated in almost real time on the read replica.
Read replicas are read-only; you cannot write to them. The read replica processes queries, read requests, and analytics traffic, thus reducing the load on the primary instance.
You connect to a replica directly using its connection name and IP address. If you're connecting to a replica using a private IP address, you don't need to create an additional VPC private connection for the replica because the connection is inherited from the primary instance.
For information about how to create a read replica, see Creating read replicas. For information about managing a read replica, see Managing read replicas.
As a best practice, put read replicas in a different zone than the primary instance when you use HA on your primary instance. This practice ensures that read replicas continue to operate when the zone that contains the primary instance has an outage. See the Overview of high availability for more information.
Selecting an appropriate machine type
Read replicas can have a different number of vCPUs and memory from that of the primary. You should monitor metrics on your instance such as CPU and memory usage to ensure that the replica instance is sized correctly for its workload, especially if it is smaller than the primary instance. A replica instance that is undersized is more prone to poor performance, such as frequent out-of-memory (OOM) events.
Storage capacity on read replicas
When a primary instance is resized, all of its read replicas are resized, if needed, so that they have at least as much storage capacity as the updated primary instance.
Impact on the max_connections flag when the read replica has a machine type with less memory than the primary
On a PostgreSQL instance, if you don't set the max_connections flag
to a value of your choice, Cloud SQL automatically sets it based on the
amount of memory on the instance. For more information, see supported flags. PostgreSQL requires
that the
value of max_connections is always at least as large on a read
replica as it is on its primary. Therefore, if a read replica has less memory
than its primary, and you haven't set the max_connections flag, it
might inherit a larger value of max_connections based on the size
of the primary instance. In this situation, if you rely on the
max_connections setting to limit the number of connections to the
replica instance, it could become overloaded because the value is too high
relative to the machine type of the instance. To avoid this, you can do any of
the following:
- Resize the replica instance to a larger machine type.
- Configure your client application to limit it to some number of connections
that is less than the value of
max_connections. - Set the
max_connectionsflag on the primary and the replica to an appropriate value.
Hash index operations using read replicas
Hash index operations don't use write-ahead-logging for PostgreSQL 9.6. Cloud SQL has only one available version under PostgreSQL 10. This is documented in the yellow caution box on the PostgreSQL release page. This also applies to Cloud SQL read replicas.
Because hash index updates don't propagate to the read replica under PostgreSQL 9.6, they can't be used by the replica. As a workaround, you can either refrain from having read replicas or upgrade to a major PostgreSQL version (10 or above).
Cross-region read replicas
Cross-region replication lets you create a read replica in a different region from the primary instance. You create a cross-region read replica the same way as you create an in-region replica.
Cross-region replicas:
- Improve read performance by making replicas available closer to your application's region.
- Provide additional disaster recovery capability to guard against a regional failure.
- Let you migrate data from one region to another.
See Promoting replicas for regional migration or disaster recovery for more information about cross-region replicas.
Cascading read replicas
Cascading replication lets you create a read replica under another read replica in the same or a different region. The following scenarios are use cases for using cascading replicas:
- Disaster recovery: You can use a cascading hierarchy of read replicas to simulate the topology of your primary instance and its read replicas. During an outage, your selected read replica is promoted to primary and the read replicas under the new primary continue to replicate and are ready for use.
- Performance improvements: Reduce the burden on the primary instance by offloading replication work to multiple read replicas.
- Scale Reads: You can have more replicas to share the read load.
- Cost reduction: You can reduce networking costs by using a single cascading replica with cross-region replication in other regions.
Terminology
- Cascading replica: A read replica that can have its own replica.
- Levels: You can create levels of replicas in a cascading replica hierarchy. For example, if you add four replicas to an instance, those four replicas are at the same level.
- Sibling instances: Multiple replicas that replicate from the same primary instance. Siblings are at the same level in the replica hierarchy. A replica can officially have up to eight siblings.
- Leaf replica: A read replica that does not have any replicas of its own. In a multi-level replication hierarchy, the leaf replica is the last level.
- Promote An action that converts a replica, at any level in the hierarchy, into a primary instance. When promoted, the replica's cascading replica hierarchy is retained.
Configure cascading replicas
Cascading replicas let you add read replicas to any existing replicas. You can add up to four levels of replicas, including the primary instance. When you promote the replica at the top of a cascading replica hierarchy, it becomes a primary instance and its cascading replicas continue to replicate.
To plan your configuration, you need to have a goal for what the read replicas intend to do. The next two sections describe the configurations for disaster recovery and multi-region replication.
Disaster recovery
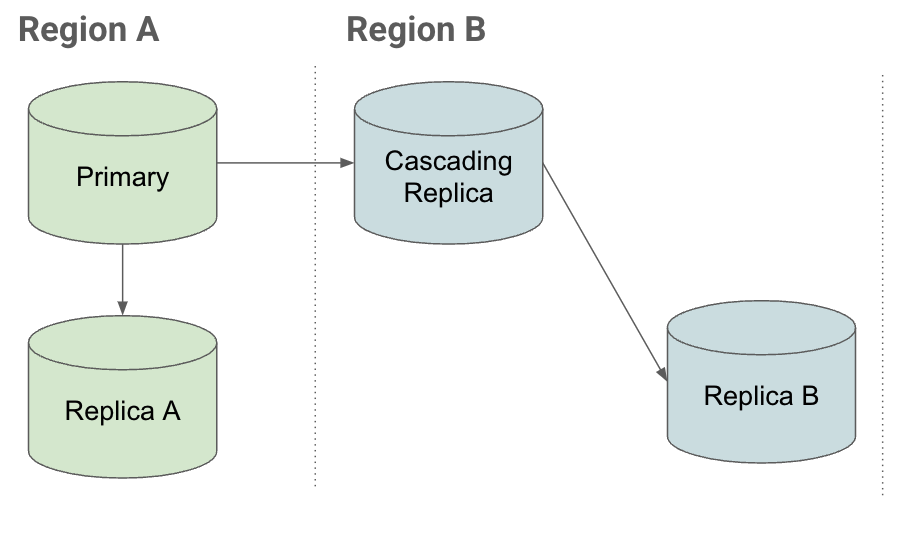
To understand how cascading replicas help you recover quickly during an outage, consider the following replication scenario:
Configuration
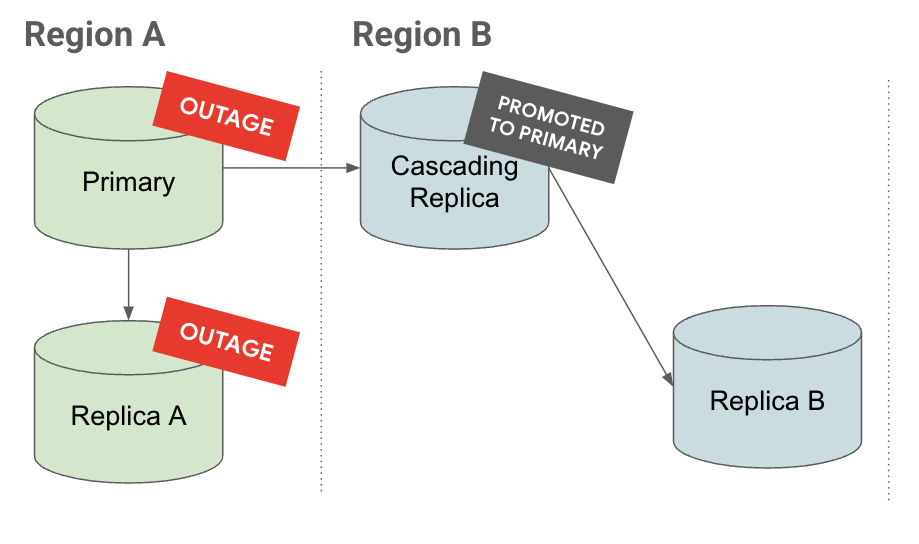
Outage
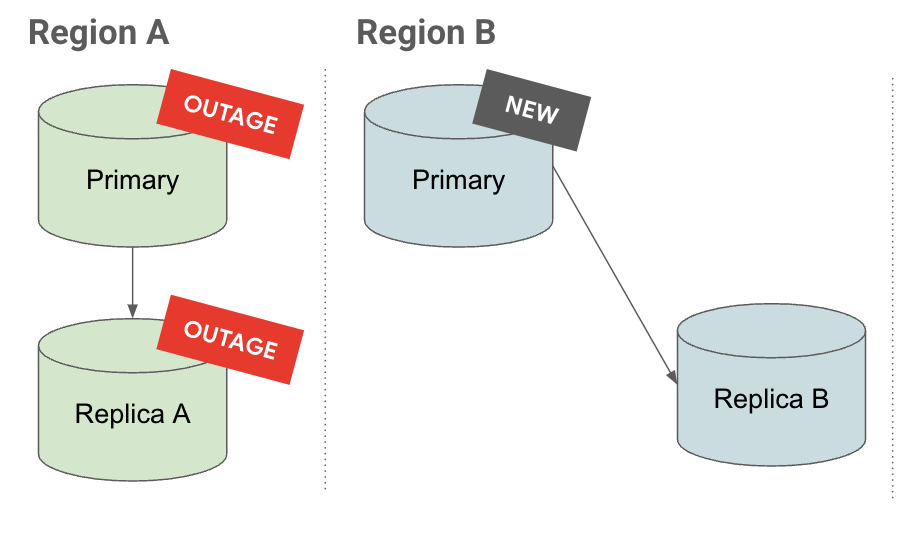
Promotion
If you want to use an instance in Region B in a disaster recovery configuration and have:
- Replicas in the same region attached to the primary instance (Replica A)
- Replicas in other regions (Cascading Replica) attached to the primary.
You can create read replicas under the cascading replica in Region B.
On the Outage tab, if there's an outage in Region A, the cascading replica is promoted to a primary instance. It already has read replicas underneath it, reducing the recovery time objective (RTO).
On the Promote tab, you see that when a cascading replica is promoted, its replicas are also promoted and continue to replicate under it.
Multi-region replication
Another use case for cascading replicas is to distribute read capacity to a second region in a cost-efficient manner. Cascading replicas C and D can be created that replicate from Replica B. Clients can distribute read queries across replicas B, C, and D to reduce the load on each replica. The cost of cross-region network traffic is incurred only once, from the primary instance to Replica B. Replication from B to C and D uses in-region network transfer, which is free.
You can create a hierarchy of up to four instances using cascading replicas for multi-region replication:
Primary A → Replica B → Replica C and Replica D
Restrictions
- You can't delete a replica that has replicas under it. To delete the replica, you must start with the leaf replicas and work your way upward through the hierarchy.
- Circular region dependency isn't supported. To have the replica of a cascading replica in the same region as the primary instance, the cascading replica must also be in the same region.
Logical replication
Cloud SQL lets you configure your own replication solutions by using PostgreSQL's logical replication features. Logical replication is a flexible solution allowing:
- Standard replication from a primary instance to a replica
- Selective replication of only certain tables or rows
- Replication across PostgreSQL major versions
- Replication to non-PostgreSQL databases
- Change data capture (CDC) workflows where all database changes are streamed to a consumer
For more information, see Setting up logical replication. That page includes information about:
- Built-in logical replication
- The pglogical extension
Replication use cases
The following use cases apply for each type of replication.
| Name | Primary | Replica | Benefits and use cases | More information |
|---|---|---|---|---|
| Read replica | Cloud SQL instance | Cloud SQL instance |
|
|
| Cross-region read replica | Cloud SQL instance | Cloud SQL instance |
|
|
| Logical replication | Any PostgreSQL standalone or primary instance | Any PostgreSQL instance, or an external consumer |
|
Billing
- A read replica is charged at the same rate as a standard Cloud SQL instance. There is no charge for the data replication.
- Pricing for a cross-region read replica is the same as for creating a new Cloud SQL instance in the region. Refer to Cloud SQL instance pricing and select the appropriate region. In addition to the regular cost associated with the instance, a cross-region replica incurs cross-region data transfer charges for replication logs sent from the primary instance to the replica instance, as described in Network Egress Pricing.
Quick reference for Cloud SQL read replicas
| Topic | Discussion |
|---|---|
| Backups | You cannot configure backups on the replica. |
| Cores and memory | Read replicas can use a different number of cores and amount of memory from those of the primary instance. |
| Deleting the primary instance | Before you can delete a primary instance, you must promote all of its read replicas to standalone instances or delete the read replicas. |
| Deleting the replica | When you delete a replica, there is no impact on the status of the primary instance. |
| Disabling write-ahead logging | Before you can disable write-ahead logs on a primary instance, you must promote or delete all of its read replicas. |
| Failover | A primary instance can failover to a replica only if the replica is a DR replica. Read replicas are unable to failover in any way during an outage. |
| High availability | Read replicas allow you to enable high availability on the replicas. |
| Load balancing | Cloud SQL doesn't provide load balancing between replicas. You can choose to implement load balancing for your Cloud SQL instance. You can also use connection pooling to distribute queries across replicas with your load balancing setup for better performance. |
| Maintenance windows | Read replicas share maintenance windows with the primary instance. The replicas follow the maintenance settings for the primary instance, including the maintenance window, rescheduling, and the deny maintenance period. During maintenance, Cloud SQL updates all read replicas first before updating the primary instance. |
| Multiple read replicas | Cloud SQL supports cascading replicas. As a result, you can create up to 10 replicas for a single primary instance and create replicas of those replicas, up to four levels including the primary instance. |
| Private IP | If you're connecting to a replica using a private IP address, you don't need to create an additional VPC private connection for the replica, as it is inherited from the primary instance. |
| Restoring the primary instance | You cannot restore the primary instance of a replica while the replica exists. Before restoring an instance from a backup, or performing a point-in-time recovery on it, you must promote or delete all of its replicas. |
| Settings | The settings of the primary instance are propagated to the replica, including the password for the postgres user and changes to the user table. |
| Stopping a replica | You cannot stop a replica. You can restart,
delete, or disable replication on it, but you
cannot stop it as you can a primary instance. |
| Upgrading a replica | Read replicas can experience a disruptive upgrade at any time. |
| User tables | You cannot make changes on the replica. All user changes must be done on the primary instance. |
What's next
- Learn how to create a read replica.
- Learn how to configure an instance for high availability.
- Learn about Advanced disaster recovery (DR)