Halaman ini memperkenalkan pemulihan dari bencana (disaster recovery) di Cloud SQL.
Ringkasan
Di Google Cloud, pemulihan dari bencana database (DR) berfokus pada penyediaan keberlangsungan pemrosesan, khususnya saat region gagal atau tidak tersedia. Cloud SQL adalah layanan regional (jika Cloud SQL dikonfigurasi untuk ketersediaan tinggi (HA)). Oleh karena itu, jika region Google Cloud yang menghosting database Cloud SQL menjadi tidak tersedia, database Cloud SQL juga tidak akan tersedia.
Untuk melanjutkan pemrosesan, Anda harus menyediakan database di region sekunder sesegera mungkin. Paket DR ini mengharuskan Anda mengonfigurasi replika baca lintas region di Cloud SQL. Failover berdasarkan ekspor/impor atau pencadangan/pemulihan juga dapat dilakukan, tetapi pendekatan tersebut memerlukan waktu yang lebih lama, terutama untuk database yang besar.
Skenario bisnis berikut adalah contoh yang menjamin konfigurasi failover lintas region:
- Perjanjian tingkat layanan aplikasi bisnis lebih besar daripada Cloud SQL Service Level Agreement (ketersediaan 99,99% bergantung pada edisi Cloud SQL Anda). Dengan melakukan failover ke region lain, Anda dapat memitigasi pemadaman layanan.
- Semua tingkat aplikasi bisnis sudah multi-regional dan dapat terus memproses saat terjadi pemadaman layanan region. Konfigurasi failover lintas region membantu mendukung ketersediaan database yang berkelanjutan.
- Batas waktu pemulihan (RTO) dan tujuan titik pemulihan (RPO) yang diperlukan adalah dalam menit, bukan dalam jam. Melakukan failover ke region lain lebih cepat daripada membuat ulang database.
Secara umum, ada dua varian untuk proses DR:
- Database gagal terhubung ke region sekunder. Setelah siap dan digunakan oleh aplikasi, database tersebut akan menjadi database utama baru dan tetap menjadi database utama.
- Database akan gagal terhubung ke region sekunder, tetapi kembali ke region utama setelah region utama pulih dari kegagalannya.
Ringkasan pemulihan dari bencana (disaster recovery) database SQL Google Cloud ini menjelaskan varian kedua, yaitu saat database yang gagal dipulihkan dan kembali ke region utama. Varian proses DR ini sangat relevan untuk database yang harus berjalan di region utama karena latensi jaringan, atau karena beberapa resource hanya tersedia di region utama. Dengan varian ini, database berjalan di region sekunder hanya selama pemadaman layanan di region utama.
Arsitektur pemulihan dari bencana (disaster recovery)
Diagram berikut menunjukkan arsitektur minimal yang mendukung DR database untuk instance Cloud SQL dengan ketersediaan tinggi (HA):
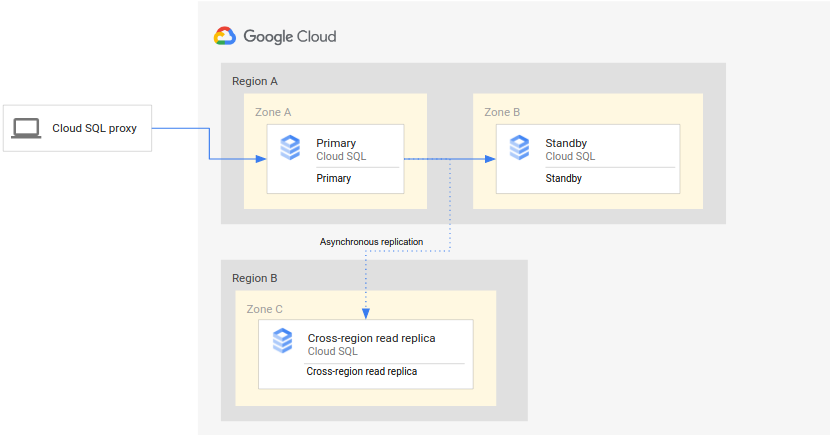
Arsitekturnya berfungsi sebagai berikut:
- Dua instance Cloud SQL (instance utama dan instance standby) terletak di dua zona terpisah dalam satu region (region utama). Instance disinkronkan menggunakan persistent disk regional.
- Satu instance Cloud SQL (replika baca lintas region) terletak di region kedua (region sekunder). Untuk DR, replika baca lintas region disiapkan untuk menyinkronkan (dengan menggunakan replikasi asinkron) dengan instance utama menggunakan penyiapan replika baca.
Instance utama dan standby menggunakan disk regional yang sama, sehingga statusnya identik.
Karena penyiapan ini menggunakan replikasi asinkron, ada kemungkinan replika baca lintas region tertinggal dari instance utama. Akibatnya, saat failover terjadi, RPO replika baca lintas region kemungkinan bukan nol.
Proses pemulihan dari bencana (DR)
Proses pemulihan dari bencana (DR) dimulai saat region utama menjadi tidak tersedia. Untuk melanjutkan pemrosesan di region sekunder, Anda memicu failover instance utama dengan mempromosikan replika baca lintas region. Proses DR menetapkan langkah-langkah operasional yang harus dilakukan, baik secara manual maupun otomatis, untuk mengurangi kegagalan region dan menetapkan instance utama yang berjalan di region sekunder.
Diagram berikut menunjukkan proses DR:
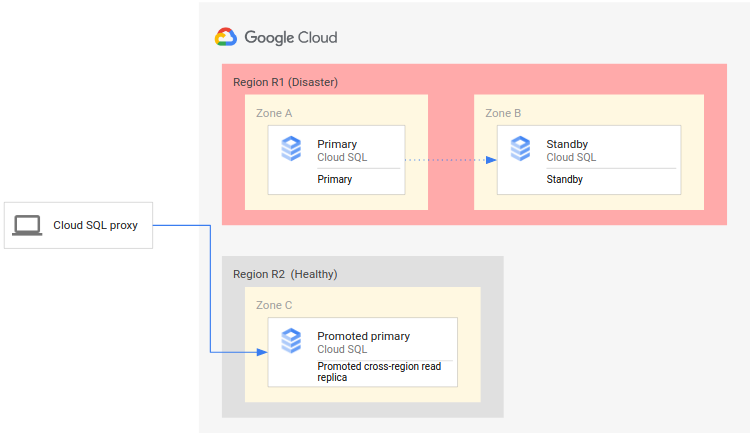
Proses DR terdiri dari langkah-langkah berikut:
- Region utama (R1), yang menjalankan instance utama, menjadi tidak tersedia.
- Tim operasi mengenali dan secara resmi mengonfirmasi bencana, dan memutuskan apakah failover diperlukan.
- Jika failover diperlukan, Anda dapat mempromosikan replika baca lintas region di region sekunder (R2) untuk menjadi instance utama baru.
- Koneksi klien dikonfigurasi ulang untuk melanjutkan pemrosesan pada instance utama yang baru dan mengakses instance utama di R2.
Proses awal ini menetapkan kembali database utama yang berfungsi. Namun, tindakan ini tidak membuat arsitektur DR yang lengkap, di mana instance utama yang baru itu sendiri memiliki instance standby dan replika baca lintas region.
Proses DR yang lengkap memastikan bahwa satu instance, yaitu instance utama yang baru, diaktifkan untuk HA dan memiliki replika baca lintas region. Proses DR yang lengkap juga memberikan penggantian ke deployment asli di region utama asli.
Kegagalan merujuk ke region sekunder
Proses DR yang lengkap memperluas proses DR dasar dengan menambahkan langkah-langkah untuk membuat arsitektur DR lengkap setelah failover. Diagram berikut menunjukkan arsitektur DR database yang lengkap setelah failover:
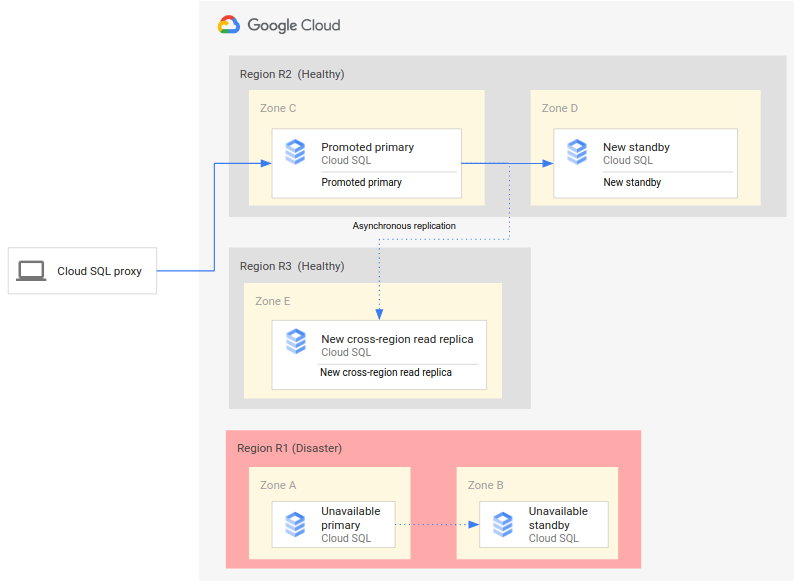
Proses DR database yang lengkap terdiri dari langkah-langkah berikut:
- Region utama (R1), yang menjalankan database utama, menjadi tidak tersedia.
- Tim operasi mengenali dan secara resmi mengonfirmasi bencana, dan memutuskan apakah failover diperlukan.
- Jika failover diperlukan, Anda kemudian dapat mempromosikan replika baca lintas region di region sekunder (R2) untuk menjadi instance utama baru.
- Koneksi klien dikonfigurasi ulang untuk mengakses dan memproses pada instance primer (R2) yang baru.
- Instance standby baru dibuat dan dimulai di R2 dan ditambahkan ke instance utama. Instance standby berada di zona yang berbeda dengan instance utama. Instance utama kini sangat tersedia karena instance standby telah dibuat untuknya.
- Di region ketiga (R3), replika baca lintas-region baru dibuat dan dilampirkan ke instance utama. Pada tahap ini, arsitektur pemulihan dari bencana yang lengkap dibuat ulang dan dapat dioperasikan.
Jika region utama asli (R1) tersedia sebelum langkah 6 diimplementasikan, replika baca lintas region dapat langsung ditempatkan di region R1, bukan region R3. Dalam hal ini, penggantian ke region utama asli (R1) tidak terlalu kompleks dan memerlukan lebih sedikit langkah.
Menghindari kondisi split-brain
Kegagalan region utama (R1) tidak berarti bahwa instance utama yang asli dan instance standby-nya otomatis dimatikan, dihapus, atau dibuat tidak dapat diakses saat R1 tersedia kembali. Jika R1 tersedia, klien dapat membaca dan menulis data (bahkan secara tidak sengaja) pada instance utama asli. Dalam hal ini, situasi split-brain apat berkembang, yaitu beberapa klien mengakses data lama di database utama yang lama, dan klien lainnya mengakses data baru di database utama yang baru, yang mengakibatkan masalah dalam bisnis Anda.
Untuk menghindari situasi split-brain, Anda harus memastikan bahwa klien tidak dapat lagi mengakses instance utama asli setelah R1 tersedia. Idealnya, Anda harus membuat instance utama yang asli tidak dapat diakses sebelum klien mulai menggunakan instance primer yang baru, lalu menghapus instance utama yang asli tepat setelah Anda membuatnya tidak dapat diakses.
Membuat cadangan awal setelah failover
Saat Anda mempromosikan replika baca lintas region menjadi replika baca utama baru dalam failover, transaksi dalam replika baca utama yang baru mungkin tidak sepenuhnya disinkronkan dengan transaksi dari transaksi utama yang asli. Oleh karena itu, transaksi tersebut tidak tersedia di instance baru.
Sebagai praktik terbaik, sebaiknya segera cadangkan instance utama baru di awal failover dan sebelum klien mengakses database. Cadangan ini mewakili status yang konsisten dan diketahui pada titik failover. Cadangan tersebut dapat penting untuk tujuan peraturan atau untuk pemulihan ke status yang diketahui jika klien mengalami masalah saat mengakses status utama baru.
Melakukan penggantian ke region utama asli
Seperti yang diuraikan sebelumnya, dokumen ini menyediakan langkah-langkah untuk melakukan penggantian ke region asli (R1). Ada dua versi berbeda dari proses penggantian.
- Jika membuat replika baca lintas region baru di region tersier (R3), Anda harus membuat replika baca lintas region (kedua) lainnya di region utama (R1).
- Jika membuat replika baca lintas-region baru di region utama (R1), Anda tidak perlu membuat replika baca lintas-region tambahan lainnya di R1.
Setelah replika baca lintas region di R1 ada, instance Cloud SQL dapat dikembalikan ke R1. Karena penggantian ini dipicu secara manual dan tidak didasarkan pada pemadaman, Anda dapat memilih hari dan waktu yang sesuai untuk aktivitas pemeliharaan ini.
Dengan demikian, untuk mencapai DR lengkap yang memiliki replika baca utama, standby, dan lintas region, Anda memerlukan dua failover. Failover pertama dipicu oleh penghentian (failover yang sebenarnya), dan failover kedua menetapkan kembali deployment awal (penggantian).
Penggantian ke region utama asli (R1) terdiri dari langkah-langkah berikut:
- Promosikan replika lintas region yang baru dibuat di region utama asli (R1).
- Jika instance yang dipromosikan awalnya tidak dibuat sebagai replika HA, aktifkan HA di instance untuk perlindungan dari kegagalan zona.
- Konfigurasi ulang aplikasi Anda untuk terhubung ke instance utama yang baru.
- Buat replika lintas region untuk instance utama baru di region DR (R2).
- (Opsional) Untuk menghindari menjalankan beberapa instance utama independen, bersihkan instance utama di region DR (R2).
Pemulihan dari bencana (DR) lanjutan
Jika Anda menggunakan edisi Cloud SQL Enterprise Plus, Anda dapat memanfaatkan DR lanjutan. DR lanjutan menyederhanakan pemulihan dan penggantian setelah failover lintas region. Seperti yang dijelaskan dalam Proses pemulihan dari bencana, saat melakukan DR, Anda akan menghapus koneksi antara region yang gagal dari instance utama lama dan region operasional dari instance utama baru. Dengan DR, untuk memulihkan koneksi ke region deployment asli dan mendapatkan kembali instance utama lama, Anda harus melakukan serangkaian langkah penggantian manual.
Dengan DR lanjutan, saat terjadi kegagalan region, Anda dapat memanggil failover replika. Dengan failover replika, Anda mempromosikan replika baca lintas region yang serupa dengan melakukan DR reguler, kecuali Anda mempromosikan replika pemulihan dari bencana (DR) yang ditetapkan. Promosi replika DR dilakukan segera.
Daripada menghapus instance utama lama, instance tersebut tetap menjadi bagian dari topologi replikasi asinkron Cloud SQL. Instance utama lama (instance A) pada akhirnya menjadi replika dari replika DR-nya (instance B) setelah replika DR dipromosikan menjadi instance utama baru.
Setelah instance utama lama (A) diubah menjadi replika, Anda dapat melakukan langkah terakhir DR lanjutan. Anda dapat mengembalikan deployment Cloud SQL ke status aslinya dan memulihkan instance utama lama (A) ke peran sebelumnya sebagai instance utama tanpa kehilangan data. Untuk melakukan pemulihan tanpa kehilangan data ini pada instance utama lama (A), Anda dapat menggunakan operasi pengalihan. Saat Anda melakukan pengalihan, tidak ada kehilangan data karena instance utama (B) tetap dalam mode hanya baca hingga replika DR yang ditetapkan (A) menyamai instance utama (B). Setelah replika DR (A) menerima semua update replikasinya, replika DR (A) akan mengambil peran instance utama, sedangkan instance utama sebelumnya (B) akan otomatis dikonfigurasi ulang sebagai replika DR dari instance utama saat ini (A). Instance dikembalikan ke peran aslinya, sehingga mengembalikan topologi ke keadaan aslinya sebelum DR dan failover replika.
Selama DR lanjutan, semua instance yang terlibat dalam operasi failover dan pengalihan replika mempertahankan alamat IP-nya.
Anda juga dapat menggunakan operasi pengalihan DR tingkat lanjut untuk melakukan latihan DR rutin guna menguji dan menyiapkan topologi Cloud SQL untuk failover lintas region sebelum terjadi bencana. Jika terjadi bencana yang sebenarnya, Anda dapat melakukan failover replika lintas region yang telah Anda uji.
Replika pemulihan dari bencana (DR)
Sebagai komponen wajib DR lanjutan, replika DR memiliki karakteristik berikut:
- Replika DR adalah replika baca lintas region yang terhubung langsung.
- Anda dapat mengubah penetapan replika DR beberapa kali.
- Anda dapat mengubah penetapan replika DR kapan saja, kecuali selama operasi pengalihan atau failover replika.
Selain itu, untuk mengurangi RTO setelah menggunakan DR lanjutan, sebaiknya lakukan hal berikut:
- Konfigurasi replika DR dengan ukuran yang sama dengan instance utama.
- Jika instance utama mengaktifkan HA, sebaiknya Anda mengaktifkan HA di replika DR juga. Untuk melakukannya, verifikasi terlebih dahulu bahwa primer telah mengaktifkan HA. Kemudian, lakukan pengalihan ke replika DR. Setelah operasi pengalihan selesai, aktifkan HA di instance utama baru. Kemudian, Anda dapat beralih kembali ke instance utama lama. Replika DR mempertahankan konfigurasi HA-nya bahkan setelah menjadi replika lagi.
Failover replika
Singkatnya, failover replika terdiri dari peristiwa berikut:
- Anda membuat dan menetapkan replika DR.
- Region utama menjadi tidak tersedia.
- Anda melakukan failover replika ke replika DR.
- Endpoint tulis diperbarui dan mulai mengarah ke instance utama yang baru.
- Saat instance utama asli kembali online, instance tersebut akan menjadi replika baca dari instance utama baru.
- Anda dapat menggunakan operasi pengalihan untuk memulihkan deployment ke topologi aslinya.
Untuk melihat detail dan diagram operasi failover replika, klik tab berikut.
Menetapkan replika DR
Sebelum melakukan failover replika, Anda telah menetapkan replika DR ke instance utama dan mungkin telah menguji prosesnya dengan melakukan pengalihan.

Terjadi gangguan
Region utama, yang menjalankan database utama, menjadi tidak tersedia.

Failover replika
Setelah menentukan bahwa pemulihan dari bencana diperlukan, Anda melakukan failover replika ke replika DR yang ditetapkan lintas region.
Replika DR yang ditetapkan lintas region menjadi instance utama secara langsung dan mulai menerima bacaan dan penulisan masuk. Endpoint tulis diperbarui dan mulai mengarah ke instance primer baru.

Primary asli menjadi replika
Setelah replika dipromosikan, Cloud SQL akan memeriksa secara berkala apakah instance utama asli sudah kembali online. Jika instance utama asli online, Cloud SQL akan membuat ulang instance utama lama sebagai replika dari instance yang dipromosikan. Instance utama lama mempertahankan alamat IP-nya.

Failback ke versi asli
Setelah melakukan failover replika, Anda dapat memulihkan instance utama di region asli dengan melakukan operasi pengalihan, membalikkan pasangan replika DR dan instance utama yang sama.

Pengalihan
Singkatnya, operasi pengalihan terdiri dari peristiwa berikut:
- Anda membuat dan menetapkan replika DR.
- Anda memulai pengalihan.
- Saat jeda replikasi turun menjadi nol, instance utama baru mulai menerima koneksi masuk.
- Instance utama lama menjadi replika baca.
- Jika endpoint penulisan DNS sedang digunakan, endpoint penulisan DNS akan diperbarui untuk mengarah ke instance utama yang baru.
Untuk melihat detail dan diagram operasi pengalihan, klik tab berikut.
Menetapkan replika DR
Sebelum memulai operasi *pengalihan*, Anda harus menetapkan replika DR ke instance utama.
Pastikan instance utama responsif. Anda hanya dapat melakukan pengalihan jika instance utama dan replika DR online.
Memulai pengalihan
Anda memulai pengalihan. Saat Anda memulai pengalihan, instance utama berhenti menerima penulisan dan menjadi hanya baca. Cloud SQL menunggu log transaksi disalin ke Cloud Storage. Replika DR yang ditetapkan akan mengejar ketertinggalan dari instance utama.
Saat jeda replikasi turun menjadi nol, replika DR akan dipromosikan sebagai instance utama baru. Instance utama baru mulai menerima koneksi masuk, termasuk baca dan tulis aplikasi.
Endpoint diperbarui
Setelah replika DR dipromosikan ke instance utama baru, endpoint penulisan DNS diperbarui dan mulai mengarah ke instance utama baru. Jika Anda tidak menggunakan endpoint penulisan DNS, Anda harus mengonfigurasi aplikasi untuk mengarah ke alamat IP instance utama yang baru.
Instance utama lama dikonfigurasi ulang sebagai replika baca.
PITR diaktifkan secara otomatis untuk instance utama baru. PITR hanya dapat dilakukan setelah pencadangan otomatis pertama.
Menulis endpoint
Endpoint tulis adalah nama layanan nama domain (DNS) global yang otomatis di-resolve ke alamat IP instance utama saat ini. Endpoint ini mengalihkan koneksi masuk ke instance utama baru secara otomatis jika terjadi operasi failover atau pengalihan replika. Anda dapat menggunakan endpoint tulis dalam string koneksi SQL, bukan alamat IP. Dengan menggunakan endpoint tulis, Anda dapat menghindari perubahan koneksi aplikasi saat terjadi gangguan di suatu region.
Endpoint tulis mengharuskan Cloud DNS API diaktifkan di project tempat Anda membuat atau memiliki instance utama edisi Cloud SQL Enterprise Plus yang ada. Saat Anda membuat instance edisi Cloud SQL Enterprise Plus dengan alamat IP pribadi dan jaringan yang diizinkan, Cloud SQL akan membuat endpoint tulis untuk instance tersebut secara otomatis. Jika Anda sudah memiliki instance utama edisi Cloud SQL Enterprise Plus, Cloud SQL akan membuat endpoint tulis saat Anda membuat replika DR (replika lintas region yang Anda tetapkan untuk instance utama). Jika instance utama berubah karena operasi pengalihan atau failover replika, Cloud SQL akan menetapkan endpoint tulis ke replika DR saat replika DR menjadi instance utama yang baru.
Untuk mengetahui informasi selengkapnya tentang cara menggunakan endpoint tulis untuk terhubung ke instance, lihat Menghubungkan ke instance menggunakan endpoint tulis.
Langkah berikutnya
- Menggunakan pemulihan dari bencana (DR) lanjutan.
- Pelajari arsitektur referensi, diagram, tutorial, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.