本頁面介紹 Cloud SQL 的災難復原功能。
總覽
在 Google Cloud中,資料庫災難復原 (DR) 是指提供持續處理作業,特別是當區域發生故障或無法使用時。Cloud SQL 是區域服務 (當 Cloud SQL 設定為高可用性 (HA) 時)。因此,如果託管 Cloud SQL 資料庫的 Google Cloud 區域無法使用,Cloud SQL 資料庫也會無法使用。
如要繼續處理,請盡快在次要區域提供資料庫。災難復原計畫需要您在 Cloud SQL 中設定跨區域唯讀副本。您也可以根據匯出/匯入或備份/還原作業進行容錯移轉,但這種做法耗時較長,尤其是大型資料庫。
以下商家情境範例需要跨區域容錯移轉設定:
- 商用應用程式的服務水準協議高於區域性 Cloud SQL 服務水準協議 (視 Cloud SQL 版本而定,可用性為 99.99%)。容錯移轉至其他區域,即可減輕中斷的影響。
- 業務應用程式的所有層級都已是多區域,因此區域發生中斷時,仍可繼續處理。跨區域容錯移轉設定有助於確保資料庫持續可用。
- 所需的復原時間目標 (RTO) 和復原點目標 (RPO) 是以分鐘為單位,而非小時。容錯移轉至其他區域的速度比重建資料庫更快。
一般來說,DR 程序有兩種變體:
- 資料庫容錯移轉至次要區域。資料庫準備就緒並供應用程式使用後,就會成為新的主要資料庫,且會維持主要資料庫的狀態。
- 資料庫容錯移轉至次要區域,但主要區域從故障中復原後,資料庫會回復至主要區域。
這份 Google Cloud SQL 資料庫災難復原總覽說明第二種情況,也就是復原失敗的資料庫,並還原至主要區域。如果資料庫必須在主要區域中執行 (因為網路延遲,或某些資源僅在主要區域中提供),這個 DR 程序變體就特別適用。使用這個變體時,資料庫只會在主要區域發生中斷期間,於次要區域中執行。
災難復原架構
下圖顯示支援高可用性 Cloud SQL 執行個體資料庫 DR 的最低架構:
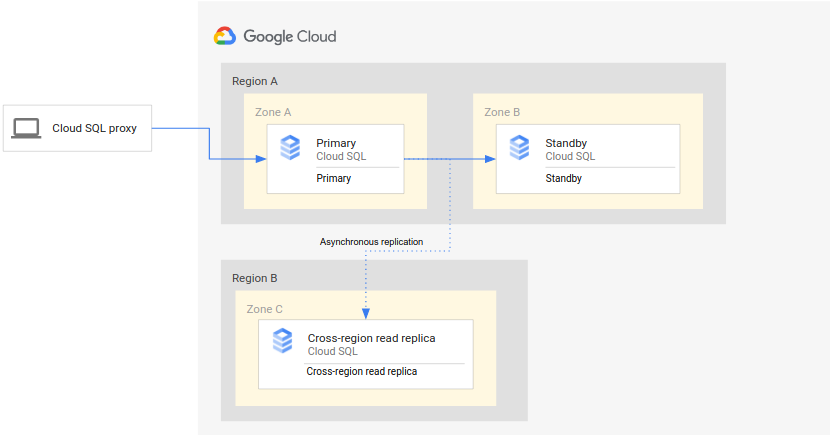
架構的運作方式如下:
- 兩個 Cloud SQL 執行個體 (主要執行個體和待命執行個體) 位於單一區域 (主要區域) 內的兩個不同可用區。執行個體會使用區域永久磁碟進行同步。
- 一個 Cloud SQL 執行個體 (跨區域唯讀備用資源) 位於第二個區域 (次要區域)。在 DR 方面,跨區域唯讀備用資源會設定為與主要執行個體同步 (使用非同步複製),方法是使用唯讀備用資源設定。
主要和待命執行個體共用同一個區域磁碟,因此兩者的狀態相同。
由於這項設定使用非同步複製,跨區域唯讀備用資源可能會落後於主要執行個體。因此,發生容錯移轉時,跨區域唯讀備用資源的 RPO 可能不為零。
災難復原 (DR) 程序
主要區域無法使用時,災難復原 (DR) 程序就會啟動。如要在次要區域繼續處理作業,請升級跨區域唯讀副本,觸發主要執行個體的容錯移轉。災難復原程序會規定必須執行的作業步驟 (手動或自動),以減輕區域故障的影響,並在次要區域建立執行中的主要執行個體。
下圖顯示 DR 程序:
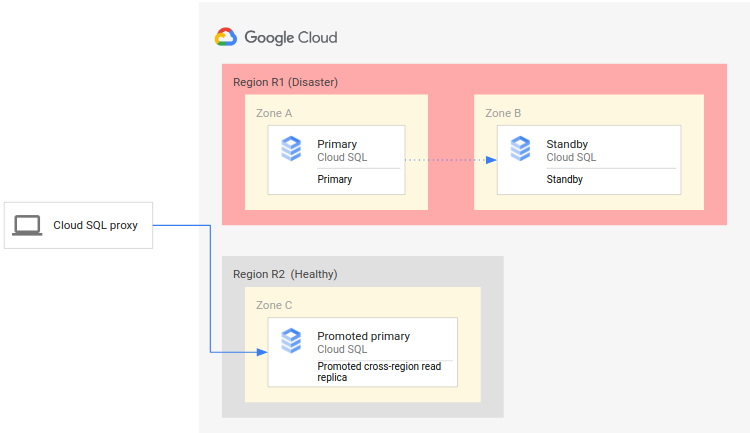
DR 程序包含下列步驟:
- 執行主要執行個體的主要區域 (R1) 無法使用。
- 營運團隊會確認並正式承認發生災害,並決定是否需要容錯移轉。
- 如果需要容錯移轉,您可以將次要區域 (R2) 中的跨區域唯讀備用資源升級為新的主要執行個體。
- 重新設定用戶端連線,以便在新主要執行個體上繼續處理作業,並存取 R2 中的主要執行個體。
這個初始程序會重新建立可運作的主要資料庫。不過,這不會建立完整的 DR 架構,因為新的主要執行個體本身具有待命執行個體和跨區域唯讀副本。
完整的 DR 程序可確保單一執行個體 (即新的主要執行個體) 啟用 HA,並具備跨區域唯讀備用資源。完整的 DR 程序也會提供備援機制,讓您在原始主要區域中還原為原始部署作業。
容錯移轉至次要區域
完整的 DR 程序會擴充基本 DR 程序,在容錯移轉後新增建立完整 DR 架構的步驟。下圖顯示容錯移轉後的完整資料庫 DR 架構:
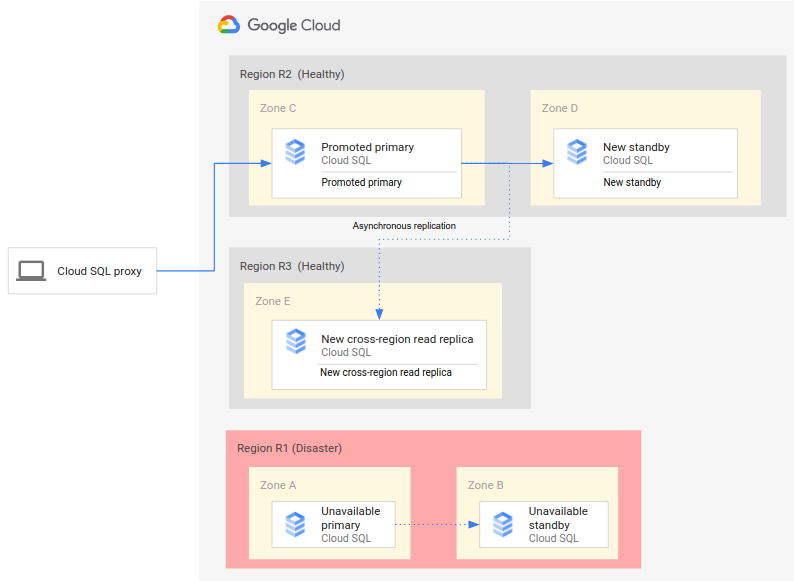
完整的資料庫 DR 程序包含下列步驟:
- 執行主要資料庫的主要區域 (R1) 無法使用。
- 營運團隊會確認並正式承認發生災害,並決定是否需要容錯移轉。
- 如果需要容錯移轉,您可以將次要區域 (R2) 中的跨區域唯讀備用資源升級為新的主要執行個體。
- 重新設定用戶端連線,以便存取及處理新的主要執行個體 (R2)。
- 系統會在 R2 中建立並啟動新的待命執行個體,並新增至主要執行個體。待命執行個體與主要執行個體位於不同區域。系統已為主要執行個體建立待命執行個體,因此主要執行個體現在具有高可用性。
- 在第三個區域 (R3) 中,系統會建立新的跨區域唯讀副本,並附加至主要執行個體。此時,完整的災難復原架構已重建並可運作。
如果在實作步驟 6 之前,原始主要區域 (R1) 恢復運作,跨區域唯讀副本可以立即放置在區域 R1,而不是區域 R3。在此情況下,回復至原始主要區域 (R1) 的複雜度較低,所需步驟也較少。
避免核心分裂狀態
主要區域 (R1) 發生故障時,原始主要執行個體及其待命執行個體不會自動關閉、移除或無法存取,R1 恢復運作時也是如此。如果 R1 可用,用戶端可能會在原始主要執行個體上讀取及寫入資料 (即使是意外)。在這種情況下,可能會發生核心分裂,也就是部分用戶端存取舊主要資料庫中的過時資料,其他用戶端則存取新主要資料庫中的最新資料,進而導致業務問題。
為避免核心分裂情況,您必須確保 R1 可用後,用戶端無法再存取原始主要執行個體。理想情況下,您應該在用戶端開始使用新的主要執行個體前,讓原始主要執行個體無法存取,然後在無法存取後立即刪除原始主要執行個體。
容錯移轉後建立初始備份
在容錯移轉中,當您將跨區域唯讀備用資源升級為新的主要資源時,新主要資源中的交易可能無法與原始主要資源中的交易完全同步。因此,新執行個體無法使用這些交易。
最佳做法是在容錯移轉開始時,以及用戶端存取資料庫之前,立即備份新的主要執行個體。這個備份作業代表容錯移轉時的一致已知狀態。這類備份對於法規遵循或在用戶存取新主伺服器時遇到問題時,還原至已知狀態來說非常重要。
還原為原始主要區域
如先前所述,本文將說明如何還原至原始區域 (R1)。備援程序有兩個不同版本。
- 如果您在第三個區域 (R3) 中建立了新的跨區域唯讀備用資源,則必須在主要區域 (R1) 中建立另一個 (第二個) 跨區域唯讀備用資源。
- 如果您在主要區域 (R1) 中建立了新的跨區域唯讀副本,則不需要在 R1 中建立其他跨區域唯讀副本。
R1 中有跨區域唯讀備用資源後,Cloud SQL 執行個體就能回復到 R1。由於這項備援作業是手動觸發,而非根據中斷情況,因此您可以選擇適合的日期和時間進行這項維護活動。
因此,如要完成 DR,並擁有主要、待命和跨區域的唯讀副本,您需要進行兩次容錯移轉。第一次容錯移轉是由中斷觸發 (真正的容錯移轉),第二次容錯移轉則會重新建立起始部署作業 (備用作業)。
還原至原始主要區域 (R1) 的步驟如下:
- 在原始主要區域 (R1) 中升級新建立的跨區域副本。
- 如果升級的執行個體原本不是高可用性副本,請在執行個體上啟用高可用性,以防範可用區故障。
- 重新設定應用程式,連線至新的主要執行個體。
- 在 DR 區域 (R2) 中,為新的主要執行個體建立跨區域副本。
- (選用) 為避免執行多個獨立的主要執行個體,請清除 DR 區域 (R2) 中的主要執行個體。
進階災難復原 (DR)
如果您使用 Cloud SQL Enterprise Plus 版本,就能運用進階 DR。進階 DR 可簡化跨區域容錯移轉後的復原和回復程序。如「災難復原程序」一文所述,執行災難復原時,您會移除舊主要執行個體故障區域與新主要執行個體運作區域之間的連線。使用 DR 時,如要還原與原始部署區域的連線,並重新取得舊的主要執行個體,您必須執行一連串的手動回復步驟。
使用進階 DR 時,如果發生區域故障,您可以叫用副本容錯移轉。透過備用資源容錯移轉,您可以升級跨區域唯讀備用資源,做法與執行一般災難復原作業類似,但升級的對象是指定的災難復原 (DR) 備用資源。系統會立即升級 DR 副本。
舊的主要執行個體不會遭到移除,而是會繼續做為 Cloud SQL 非同步複寫拓撲的一部分。容錯移轉備用資源 (執行個體 B) 升級為新的主要執行個體後,舊的主要執行個體 (執行個體 A) 最終會成為容錯移轉備用資源的副本。
舊的主要執行個體 (A) 變成備用資源後,您就可以執行進階 DR 的最後一個步驟。您可以將 Cloud SQL 部署作業還原至原始狀態,並將舊的主要執行個體 (A) 還原為主要執行個體,且不會遺失任何資料。如要對舊的主要執行個體 (A) 執行這項零資料遺失還原作業,可以使用「切換」作業。執行切換作業時,主要執行個體 (B) 會維持唯讀模式,直到指定的 DR 備用資源 (A) 趕上主要執行個體 (B) 為止,因此不會遺失任何資料。災難復原副本 (A) 收到所有複製更新後,就會擔任主要執行個體,而先前的主要執行個體 (B) 會自動重新設定為目前主要執行個體 (A) 的災難復原副本。執行個體會恢復原本的角色,因此拓撲會回到災難復原和副本容錯移轉前的原始狀態。
在進階 DR 期間,參與副本容錯移轉和切換作業的所有執行個體都會保留 IP 位址。
您也可以使用進階 DR 的切換作業執行例行 DR 演練,在發生災害前測試及準備 Cloud SQL 拓撲,以進行跨區域容錯移轉。如果真的發生災難,您可以執行已測試過的跨區域副本容錯移轉。
災難復原 (DR) 副本
做為進階 DR 的必要元件,DR 副本具有下列特徵:
- DR 備用資源是直接連線的跨區域唯讀備用資源。
- 您可以多次變更 DR 副本的指定項目。
- 您隨時可以變更 DR 副本指定項目,但切換或副本容錯移轉作業期間除外。
此外,為減少使用進階 DR 後的 RTO,建議您採取下列做法:
- 設定與主要執行個體大小相同的 DR 副本。
- 如果主要執行個體已啟用高可用性,建議您也為 DR 副本啟用高可用性。如要這麼做,請先確認主要伺服器已啟用 HA。接著,請切換至 DR 副本。切換作業完成後,請在新主要執行個體上啟用高可用性。然後切換回舊版主要執行個體。即使 DR 副本再次成為副本,仍會保留高可用性設定。
備用資源容錯移轉
總而言之,副本容錯移轉包含下列事件:
- 建立及指派 DR 副本。
- 主要區域無法使用。
- 對 DR 備用資源執行備用資源容錯移轉。
- 寫入端點會更新,並開始指向新的主要執行個體。
- 原先的主要執行個體恢復連線後,會成為新主要執行個體的唯讀備用資源。
- 您可以使用切換作業,將部署作業還原至原始拓撲。
如要查看副本容錯移轉作業的詳細資料和圖表,請按一下下列分頁標籤。
指派 DR 備用資源
執行備用資源容錯移轉前,您已將 DR 備用資源指派給主要執行個體,並可能已執行切換來測試程序。

發生服務中斷
執行主要資料庫的主要區域無法使用。

備用資源容錯移轉
確認需要災難復原後,請對跨區域指定的 DR 備用資源執行備用資源容錯移轉。
跨區域指定 DR 備用資源會立即成為主要執行個體,並開始接受傳入的讀取和寫入作業。寫入端點會更新,並開始指向新的主要執行個體。

原始主要執行個體會變成備用執行個體
備用資源升級後,Cloud SQL 會定期檢查原始主要執行個體是否恢復連線。如果原始主要執行個體處於上線狀態,Cloud SQL 會將舊的主要執行個體重新建立為已升級執行個體的備用資源。舊的主要執行個體會保留 IP 位址。

還原為原始設定
執行備用資源容錯移轉後,您可以執行切換作業,反向操作相同的災難復原備用資源和主要執行個體配對,在原始區域還原主要執行個體。

切換
總而言之,切換作業包含下列事件:
- 建立及指派 DR 副本。
- 您啟動切換作業。
- 當複寫延遲降至零時,新的主要執行個體就會開始接受連入連線。
- 舊的主要執行個體會變成唯讀備用資源。
- 如果使用 DNS 寫入端點,系統會更新 DNS 寫入端點,指向新的主要執行個體。
如要查看切換作業的詳細資料和圖表,請按一下下列分頁標籤。
指派 DR 備用資源
開始「切換」作業前,您必須將 DR 副本指派給主要執行個體。
確認主要執行個體健康狀態良好。只有在主要執行個體和 DR 備用資源都處於連線狀態時,才能執行切換作業。
啟動切換程序
您啟動切換作業。啟動切換作業後,主要執行個體會停止接受寫入作業,並變成唯讀狀態。Cloud SQL 會等待交易記錄複製到 Cloud Storage。指定的 DR 備用資源會趕上主要執行個體。
當複製延遲降至零時,系統會將 DR 備用資源升級為新的主要執行個體。新的主要執行個體開始接受連入連線,包括應用程式讀取和寫入作業。
已更新端點
將 DR 副本升級為新的主要執行個體後,DNS 寫入端點會更新,並開始指向新的主要執行個體。 如果您未使用 DNS 寫入端點,則必須將應用程式設定為指向新主要執行個體的 IP 位址。
舊的主要執行個體會重新設定為唯讀備用資源。
系統會自動為新的主要執行個體啟用 PITR。只有在首次自動備份後,才能執行 PITR。
寫入端點
寫入端點是全域網域名稱服務 (DNS) 名稱,會自動解析為目前主要執行個體的 IP 位址。如果發生備用資源容錯移轉或切換作業,這個端點會自動將連入連線重新導向至新的主要執行個體。您可以在 SQL 連線字串中使用寫入端點,取代 IP 位址。使用寫入端點後,發生區域中斷時,您就不必變更應用程式連線。
如要使用寫入端點,您必須在建立或擁有現有 Cloud SQL Enterprise Plus 版本主要執行個體的專案中,啟用 Cloud DNS API。建立採用私人 IP 位址和授權網路的 Cloud SQL Enterprise Plus 版執行個體時,Cloud SQL 會自動為該執行個體產生寫入端點。如果您已有 Cloud SQL Enterprise Plus 版本的主要執行個體,當您建立 DR 備用資源 (您為主要執行個體指定的跨區域備用資源) 時,Cloud SQL 會產生寫入端點。如果主要執行個體因切換或備用資源容錯移轉作業而變更,當 DR 備用資源成為新的主要執行個體時,Cloud SQL 會將寫入端點指派給 DR 備用資源。
如要進一步瞭解如何使用寫入端點連線至執行個體,請參閱使用寫入端點連線至執行個體。
後續步驟
- 使用進階災難復原 (DR) 功能。
- 探索 Google Cloud的參考架構、圖表、教學課程和最佳做法。歡迎瀏覽我們的雲端架構中心。