本頁為 Cloud SQL 執行個體的高可用性 (HA) 設定總覽。如要為 HA 設定新的執行個體,或在現有執行個體上啟用 HA,請參閱「在執行個體上啟用及停用高可用性」。
HA 設定總覽
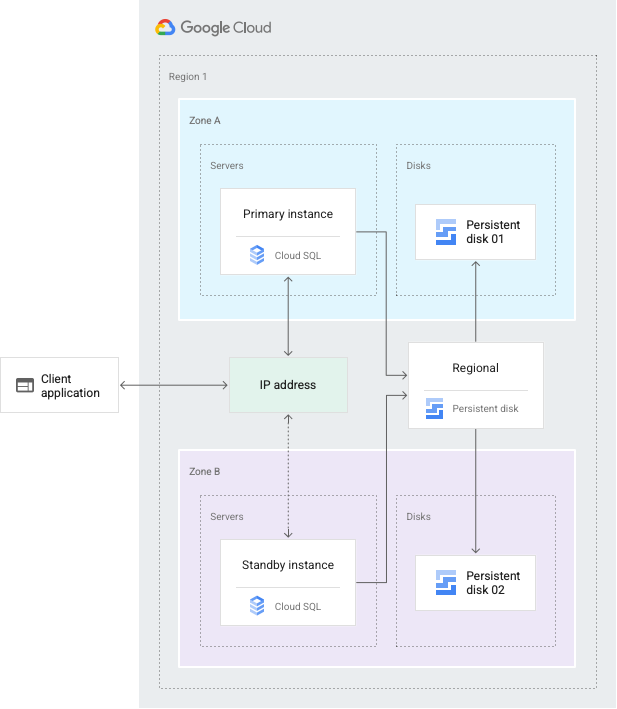
高可用性設定的目的是在可用區或執行個體無法使用時,縮短停機時間。這可能是區域性中斷或硬體問題所致。啟用高可用性後,用戶端應用程式仍可存取資料。
HA 設定可提供資料備援功能。設定為高可用性的 Cloud SQL 執行個體也稱為「區域執行個體」,且在設定的區域*內有主要和次要區域。在區域執行個體中,設定是由主要執行個體和待命執行個體組成。透過同步複製至各可用區的永久磁碟,對主要執行個體執行的所有寫入作業也會在回報交易已修訂前,複製至兩種可用區的磁碟。當執行個體或可用區發生故障時,待命執行個體會成為新的主要執行個體。然後將使用者重新導向至新的主要執行個體。這項程序稱為「容錯移轉」。
容錯移轉後,即使原始執行個體恢復連線,接收容錯移轉的執行個體仍會繼續擔任主要執行個體。在發生中斷的區域或執行個體恢復運作後,系統會刪除並重新建立原始主要執行個體。然後成為新的待命執行個體。如果日後發生容錯移轉,新的主要執行個體會容錯移轉至原始可用區中的原始執行個體。
如果需要將主要執行個體放在發生中斷的區域,可以執行「容錯回復」。回復程序會執行與容錯移轉相同的步驟,但方向相反,目的是將流量重新導回原始執行個體。如要執行容錯回復,請使用「啟動容錯移轉」一節中的程序。
Cloud SQL HA 設定 (至少有一個專屬 CPU) 的區域永久磁碟支援服務,完全適用服務水準協議 (SLA)。設定為高可用性的執行個體費用是獨立執行個體的兩倍。這個價格包含 CPU、RAM 和儲存空間。詳情請參閱定價頁面。
* 如要進一步瞭解特定地區的注意事項,請參閱「地理位置與區域」一文。
唯讀備用資源
如果唯讀備用資源的可用性是您考量的重點,可以在備用資源上啟用高可用性。將這類副本升級為主要執行個體時,系統會將其設定為高可用性執行個體。
可用區中斷期間,流量會停止流向該可用區的唯讀備用資源。區域恢復運作後,該區域中的所有唯讀備用資源都會從主要執行個體繼續複製資料。如果唯讀備用資源不在發生服務中斷的區域,當待命執行個體成為主要執行個體時,唯讀備用資源就會連線至該執行個體。
最佳做法是考慮將部分唯讀副本放在與主要和待命執行個體不同的區域。舉例來說,如果您在可用區 A 中有主要執行個體,在可用區 B 中有待命執行個體,請在可用區 C 中放置唯讀副本,以提高可靠性。這樣一來,即使主要執行個體所在的區域發生故障,唯讀備用資源仍可繼續運作。您也應在用戶端應用程式中新增商業邏輯,以便在唯讀備用資源無法使用時,將讀取作業傳送至主要執行個體。
容錯移轉總覽
如果完成 HA 設定的執行個體無法回應,Cloud SQL 會自動切換成從備援執行個體提供資料,如要確認容錯移轉是否生效,請查看作業記錄的容錯移轉記錄。
進一步瞭解如何在記錄檔探索工具中建構查詢。如要取得作業的詳細資訊 (例如執行作業的使用者),請 啟用稽核記錄。
點選各個分頁,即可查看容錯移轉對執行個體產生的影響。
一般

容錯移轉

容錯移轉後

容錯回復
程序
發生的流程如下:
主要執行個體或區域故障。
活動訊號系統每秒都會偵測主要執行個體是否正常運作。如未偵測到多個活動訊號,便會啟動容錯移轉。
備援執行個體在重新連線時開始提供資料。
透過與主要執行個體共用靜態 IP 位址,備援執行個體現在開始從次要區域提供資料。
需求條件
為了讓 Cloud SQL 允許容錯移轉,設定必須符合以下條件要求:
- 主要執行個體必須處於正常作業狀態 (非停止、非維護中或非執行長時間 Cloud SQL 執行個體作業,例如備份作業)。
- 次要區域和待命執行個體都必須處於運作良好的狀態。 如果待命執行個體沒有回應,系統會封鎖容錯移轉作業。Cloud SQL 修復待命執行個體並恢復次要可用區後,即可進行容錯移轉。
備份與還原
強烈建議啟用自動備份功能,以確保高可用性。
獨立執行個體的復原選項
Cloud SQL 不會自動從區域性中斷還原獨立執行個體。如要將未設為高可用性的執行個體重新建立到正常區域,您必須手動還原任何區域執行個體。您可以手動從區域性中斷中復原獨立執行個體,方法如下:
對執行個體執行時間點復原,並將資料復原至您建立的新執行個體。如要使用這個選項,您必須先在區域執行個體上啟用 PITR,才能在區域中斷前使用。執行個體的交易記錄必須儲存在 Cloud Storage 中。如果交易記錄儲存在磁碟上,您可以將其切換至 Cloud Storage。如要使用這個選項,請按照「對無法使用的例項執行 PITR」一文中的步驟操作。
如果執行個體在不同區域有唯讀備用資源,您可以升級該唯讀備用資源,取代發生區域性服務中斷的獨立執行個體。如要使用這個選項,請按照「升級副本」一文中的步驟操作。
無論選擇哪種做法,都適用下列注意事項:
在主要執行個體上最近提交的部分交易,可能不會顯示在剛復原的執行個體上。交易可能遺失的時間間隔就是復原點目標 (RPO)。
- 對於 PITR 復原,RPO 通常為五分鐘或更短。
- 唯讀備用資源升級的 RPO 會因資料庫工作負載而異。 如要進一步瞭解如何監控及減少複製延遲,請參閱「複製延遲」。
執行任一還原選項後,您必須重新設定發生區域性中斷的執行個體的所有用戶端,因為還原的執行個體會有不同的 IP 位址和連線名稱。
應用程式與執行個體
使用非 HA 與 HA 執行個體的方法沒有差別,因此無需對應用程式進行任何特殊設定。容錯移轉發生時,所有連至主要執行個體和讀取副本的現有連線均會關閉,且重新建立連至主要執行個體的連線約需 60 秒。您的應用程式會使用同樣的連線字串或 IP 位址來重新連線,因此您不需要在容錯移轉後更新應用程式。
如要瞭解容錯移轉會對應用程式造成什麼確切影響,請手動啟動容錯移轉。
維護作業停機時間
維護事件對設定高可用性的主要執行個體,影響方式與其他執行個體相同。主要執行個體預計會短暫停機。如要進一步瞭解維護作業對高可用性執行個體的影響,請參閱「維護作業的運作方式」。如要盡量減少對服務的影響,請變更維護設定,控管停機時間。
後續步驟
- 啟用及停用執行個體的高可用性設定。
- 啟動容錯移轉。
- 進一步瞭解如何管理資料庫連線。
- 進一步瞭解 Cloud SQL 中的地區與區域。