Esta página é uma vista geral da configuração de alta disponibilidade (HA) para instâncias do Cloud SQL. Para configurar uma nova instância para HA ou ativar a HA numa instância existente, consulte o artigo Ativar e desativar a alta disponibilidade numa instância.
Vista geral da configuração de HA
O objetivo de uma configuração de HA é reduzir o tempo de inatividade quando uma zona ou uma instância fica indisponível. Isto pode acontecer durante uma indisponibilidade zonal ou quando existe um problema de hardware. Com a HA, os seus dados continuam a estar disponíveis para as aplicações cliente.
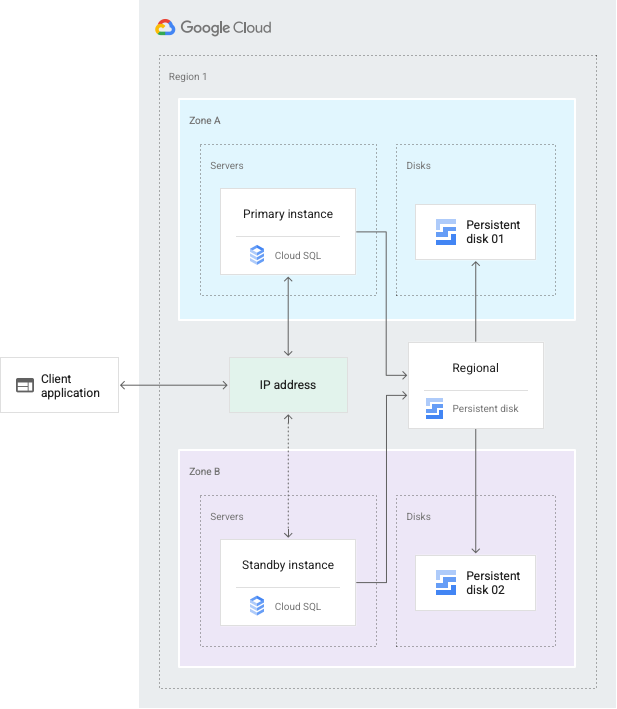
A configuração de HA oferece redundância de dados. Uma instância do Cloud SQL configurada para HA também é denominada instância regional e tem uma zona principal e secundária na região configurada*. Numa instância regional, a configuração é composta por uma instância principal e uma instância em espera. Através da replicação síncrona para o disco persistente de cada zona, todas as escritas feitas na instância principal são replicadas para os discos em ambas as zonas antes de uma transação ser comunicada como confirmada. Em caso de falha de uma instância ou de uma zona, a instância em espera torna-se a nova instância principal. Em seguida, os utilizadores são reencaminhados para a nova instância principal. Este processo é denominado failover.
Após uma ativação pós-falha, a instância que recebeu a ativação pós-falha continua a ser a instância principal, mesmo depois de a instância original voltar a ficar online. Depois de a zona ou a instância que sofreu uma indisponibilidade ficar novamente disponível, a instância principal original é destruída e recriada. Em seguida, torna-se a nova instância de reserva. Se ocorrer uma comutação por falha no futuro, o novo servidor principal vai comutar por falha para a instância original na zona original.
Se precisar de ter a instância principal na zona que teve a indisponibilidade, pode fazer um failback. Uma reversão executa os mesmos passos que a comutação por falha, mas na direção oposta, para reencaminhar o tráfego de volta para a instância original. Para fazer um failback, use o procedimento em Iniciar failover.
O apoio técnico de discos persistentes regionais para a configuração de HA do Cloud SQL que tenha, pelo menos, uma CPU dedicada tem cobertura total do Contrato de Nível de Serviço (SLA). Uma instância configurada com HA custa o dobro de uma instância autónoma. Este preço inclui a CPU, a RAM e o armazenamento. Para mais informações, consulte a página de preços.
* Para mais informações sobre considerações específicas da região, consulte Geografia e regiões.
Réplicas de leitura
Se a disponibilidade for uma consideração para as suas réplicas de leitura, pode ativar a HA nas réplicas. Quando promove uma réplica deste tipo para se tornar uma instância principal, esta já está configurada como uma instância de elevada disponibilidade.
Durante uma indisponibilidade zonal, o tráfego para de ler réplicas nessa zona. Depois de a zona voltar a ficar disponível, todas as réplicas de leitura na zona retomam a replicação a partir da instância principal. Se as réplicas de leitura não estiverem localizadas numa zona que esteja a sofrer uma indisponibilidade, estabelecem ligação à instância de espera quando esta se torna a instância principal.
Como prática recomendada, considere colocar algumas das suas réplicas de leitura numa zona diferente das instâncias primárias e de reserva. Por exemplo, se tiver uma instância principal na zona A e uma instância de espera na zona B, coloque uma réplica de leitura na zona C para melhorar a fiabilidade. Esta prática garante que as réplicas de leitura continuam a funcionar mesmo que a zona da instância principal fique inativa. Também deve adicionar lógica de negócio na aplicação cliente para enviar leituras para a instância principal quando as réplicas de leitura não estiverem disponíveis.
Vista geral da comutação por falha
Se uma instância configurada com HA deixar de responder, o Cloud SQL muda automaticamente para o serviço de dados da instância em espera. Para ver se ocorreu uma comutação por falha, verifique o registo de operações histórico de comutações por falha.
Saiba como criar consultas no Explorador de registos. Se precisar de informações mais detalhadas sobre uma operação, como o utilizador que a realizou, tem de ativar o registo de auditoria.
Clique nos separadores para ver como a comutação por falha afeta a sua instância.
Normal

Failover

Após a comutação por falha

Failback
Processo
Ocorre o seguinte processo:
A instância ou a zona principal falha.
A cada segundo, o sistema de batimentos cardíacos deteta se a instância principal está em bom estado. Se não forem detetadas várias pulsações, é iniciada a comutação por falha.
A instância de espera agora disponibiliza dados após a nova ligação.
Através de um endereço IP estático partilhado com a instância principal, a instância de reserva publica agora dados da zona secundária.
Requisitos
Para que o Cloud SQL permita uma comutação por falha, a configuração tem de cumprir os seguintes requisitos:
- A instância principal tem de estar num estado de funcionamento normal (não parada, em manutenção ou a executar uma operação de instância do Cloud SQL de longa duração, como uma operação de cópia de segurança).
- A zona secundária e a instância de espera têm de estar ambas em bom estado. Quando a instância de espera não responde, as operações de comutação por falha são bloqueadas. Depois de o Cloud SQL reparar a instância de reserva e a zona secundária ficar disponível, o Cloud SQL permite a comutação por falha.
Cópia de segurança e restauro
As cópias de segurança automáticas são altamente recomendadas para uma elevada disponibilidade.
Opções de recuperação para instâncias autónomas
O Cloud SQL não recupera automaticamente instâncias autónomas de uma indisponibilidade zonal. Para restabelecer uma instância que não esteja configurada para alta disponibilidade numa zona em bom estado, tem de restaurar manualmente todas as instâncias zonais. Pode recuperar manualmente uma instância autónoma de uma indisponibilidade zonal através de uma das seguintes opções:
Realize a recuperação num ponto específico no tempo na instância para uma nova instância que criar. Para usar esta opção, tem de ter ativado a PITR na instância zonal antes da interrupção zonal. Os registos de transações da instância têm de ser armazenados no Cloud Storage. Se os registos de transações estiverem armazenados no disco, pode transferi-los para o Cloud Storage. Para usar esta opção, siga os passos em Realize a PITR numa instância indisponível.
Se a instância tiver uma réplica de leitura numa zona diferente, pode promover essa réplica de leitura para substituir a instância autónoma que está a sofrer a indisponibilidade zonal. Para usar esta opção, siga os passos em Promova uma réplica
Para ambas as opções, aplicam-se as seguintes considerações:
Algumas transações recentes realizadas na instância principal podem não aparecer na instância recuperada recentemente. O intervalo de tempo em que as transações podem ter sido perdidas é o objetivo de ponto de recuperação (OPR).
- Para a recuperação PITR, o RPO é normalmente de cinco minutos ou menos.
- Para a promoção de réplicas de leitura, o RPO varia consoante a carga de trabalho da base de dados. Para mais informações sobre como monitorizar e reduzir o intervalo de tempo da replicação, consulte o artigo Intervalo de tempo da replicação.
Depois de executar qualquer uma das opções de restauro, tem de reconfigurar todos os clientes das instâncias que sofreram a indisponibilidade zonal, porque as instâncias recuperadas vão ter endereços IP e nomes de ligação diferentes.
Aplicações e instâncias
Não existe qualquer diferença no trabalho com instâncias não de HA e de HA, pelo que a sua aplicação não tem de ser configurada de nenhuma forma específica. Quando ocorre a comutação por falha, todas as ligações existentes à instância principal e às réplicas de leitura são fechadas, e as ligações à instância principal demoram aproximadamente 60 segundos a serem restabelecidas. A sua aplicação volta a estabelecer ligação através da mesma string de ligação ou endereço IP, pelo que não tem de atualizar a aplicação após a comutação por falha.
Para ver exatamente como as suas aplicações são afetadas pela comutação por falha, inicie manualmente a comutação por falha.
Tempo de inatividade para manutenção
Os eventos de manutenção afetam as instâncias principais configuradas com HA da mesma forma que outras instâncias. Pode esperar que as instâncias principais fiquem indisponíveis durante um breve período. Para mais informações sobre como a manutenção afeta as instâncias de HA, consulte o artigo Como funciona a manutenção. Para minimizar o impacto no seu serviço, altere as definições de manutenção para controlar quando ocorrem as indisponibilidades.
O que se segue?
- Ative e desative a alta disponibilidade numa instância.
- Inicie a comutação por falha.
- Saiba mais sobre como gerir as ligações à base de dados.
- Saiba mais sobre as regiões e as zonas no Cloud SQL.