Esta página fornece informações para rever antes de restaurar uma instância a partir de uma cópia de segurança ou realizar uma recuperação num determinado momento (PITR).
O que acontece durante um restauro?
Para a edição Enterprise do Cloud SQL e a edição Enterprise Plus do Cloud SQL, pode restaurar uma instância a partir de uma cópia de segurança. Também pode restaurar cópias de segurança em instâncias de edições diferentes.
Quando restaura uma instância, os seguintes dados da instância principal são restaurados para a nova instância:
- Bases de dados
- Utilizadores
A operação de restauro faz com que a instância seja reiniciada.
Recuperação pontual (PITR)
A recuperação pontual (PITR) ajuda a recuperar uma instância para um ponto específico no tempo. Por exemplo, se um erro causar uma perda de dados, pode recuperar uma base de dados para o estado em que se encontrava antes de o erro ocorrer.
A PITR cria sempre uma nova instância. Não pode executar uma PITR numa instância existente. A nova instância herda as definições da instância de origem, de forma semelhante ao funcionamento da criação de clones.
Quando cria uma instância do Cloud SQL na Google Cloud consola, a PITR é ativada por predefinição.O PITR usa o arquivo de registo antecipado (WAL). Por predefinição, a PITR está ativada para instâncias da edição Cloud SQL Enterprise Plus.
Quando restaura uma cópia de segurança numa instância do Cloud SQL antes de ativar a PITR, perde os registos arquivados que lhe permitem usar a PITR. Se o tamanho dos registos de gravação antecipada no disco estiver a causar problemas de desempenho na sua instância, desative a PITR e volte a ativá-la. Esta ação garante que os novos registos são armazenados no Cloud Storage em vez de no disco.Para receber instruções passo a passo sobre como realizar a PITR, consulte o artigo Use a recuperação num ponto específico no tempo (PITR).
Restaure uma instância indisponível
Pode usar a PITR para restaurar uma instância do Cloud SQL que não esteja disponível. Normalmente, a PITR oferece um objetivo de ponto de recuperação (RPO) de cinco minutos ou menos.
Se a instância estiver indisponível, pode usar a API para obter a hora de recuperação mais antiga e mais recente para a qual pode restaurar a instância e executar a recuperação até essa hora. Se a zona na qual a instância está configurada não estiver acessível, pode restaurar a instância para uma zona principal ou secundária diferente fornecendo valores para as zonas preferenciais.
Suponhamos que uma instância do Cloud SQL fica indisponível às 16:00 (EST). Se a hora de recuperação mais recente for às 15:55 (EST), pode recuperar a instância até esta hora.
Restaure uma instância eliminada através da PITR
Pode usar a PITR para restaurar uma instância do Cloud SQL após a eliminação. Para usar esta funcionalidade, a sua instância tem de ter o PITR e as cópias de segurança retidas ativados antes de a instância ser eliminada. Quando ativado, os registos de PITR são retidos após a eliminação da instância.
Após a eliminação de uma instância, os registos de PITR continuam a seguir as definições de retenção definidas pela instância quando estava ativa. Os registos PITR expiram com base nas definições de retenção de forma contínua após a eliminação da instância. O período contínuo é definido com base no período de retenção da PITR definido na instância antes da eliminação. Por exemplo, se a sua instância da edição Cloud SQL Enterprise Plus tiver a retenção de PITR definida para 14 dias, o registo de PITR mais recente é eliminado 14 dias após a eliminação da instância. Quando um registo PITR expira, não é possível recuperá-lo.
Uma vez que os nomes das instâncias podem ser reutilizados depois de uma instância ser eliminada no Cloud SQL, os registos de PITR retidos podem ser identificados em Google Cloud com os seguintes campos:
instance_deletion_timelog_retention_days
Estes campos permitem-lhe identificar se um registo PITR pertence a uma instância eliminada.
O período de recuperação PITR é definido como os horários de recuperação mais antigos e mais recentes disponíveis para restaurar a sua instância através da PITR. Para encontrar as horas de recuperação mais antigas e mais recentes da instância eliminada, consulte o artigo Obtenha a hora de recuperação mais antiga e mais recente.
Para restaurar uma instância através da PITR após a eliminação da instância, consulte o artigo Realize a PITR numa instância eliminada.
Sugestões gerais sobre como fazer um restauro
Quando restaura uma instância a partir de uma cópia de segurança, quer seja para a mesma instância ou para uma instância diferente, tenha em atenção os seguintes itens:
- A operação de restauro substitui todos os dados na instância de destino.
- A instância de destino não está disponível para associações durante a operação de restauro. As associações existentes são perdidas.
- Se estiver a restaurar para uma instância com réplicas de leitura, tem de eliminar todas as réplicas e recriá-las após a conclusão da operação de restauro.
- A operação de restauro reinicia a instância.
Para ver instruções passo a passo sobre como fazer um restauro, consulte:
Sugestões e requisitos para a restauração para uma instância diferente
Quando restaura uma cópia de segurança para uma instância diferente, tenha em atenção as seguintes restrições e práticas recomendadas:
A instância de destino tem de ter a mesma versão da base de dados que a instância a partir da qual foi feita a cópia de segurança.
O Cloud SQL define sempre a capacidade de armazenamento da instância de destino para o valor máximo do tamanho do disco configurado e do disco de cópia de segurança. O disco de cópia de segurança tem o tamanho do disco quando a cópia de segurança é feita.
A capacidade de armazenamento da instância de destino tem de ser, pelo menos, tão grande quanto a capacidade da instância da qual está a ser feito uma cópia de segurança. A quantidade de armazenamento usado não é importante. Pode ver a capacidade de armazenamento da instância na página Instâncias do Cloud SQL da consola.
A instância de destino tem de estar no estado
RUNNABLE.A instância de destino pode ter um número diferente de núcleos ou uma quantidade de memória diferente da instância a partir da qual foi feita a cópia de segurança.
A instância de destino pode estar numa região diferente da instância de origem.
Durante uma indisponibilidade, pode continuar a aceder a uma lista de cópias de segurança num projeto específico. Consulte o artigo Ver cópias de segurança durante uma indisponibilidade.
Restaurar limitações de taxa
São permitidas, no máximo, três operações de restauro a cada 30 minutos por instância, por região e por projeto. Se uma operação de restauro falhar, não é contabilizada para esta quota. Se atingir o limite, a operação falha e é apresentada uma mensagem de erro a indicar quando pode executar novamente a operação.
Vejamos como o Cloud SQL aplica limites de taxa para restauros.
O Cloud SQL usa tokens de um contentor para determinar quantas operações de restauro estão disponíveis em qualquer altura. Para cada cópia de segurança, existe um contentor para cada projeto de destino e região de destino. As instâncias de destino do mesmo projeto partilham um contentor se estiverem na mesma região. Existe um máximo de três tokens em cada contentor que pode usar para operações de restauro. A cada 10 minutos, é adicionado um novo token ao depósito. Se o limite for atingido, o token excede o limite.
Sempre que emite uma operação de restauro, é concedido um token do contentor. Se a operação for bem-sucedida, o token é removido do contentor. Se falhar, o token é devolvido ao depósito. O diagrama seguinte mostra como funciona:

Por exemplo, na figura seguinte, Backup1, Backup2 e Backup3 são as cópias de segurança da mesma instância de origem.
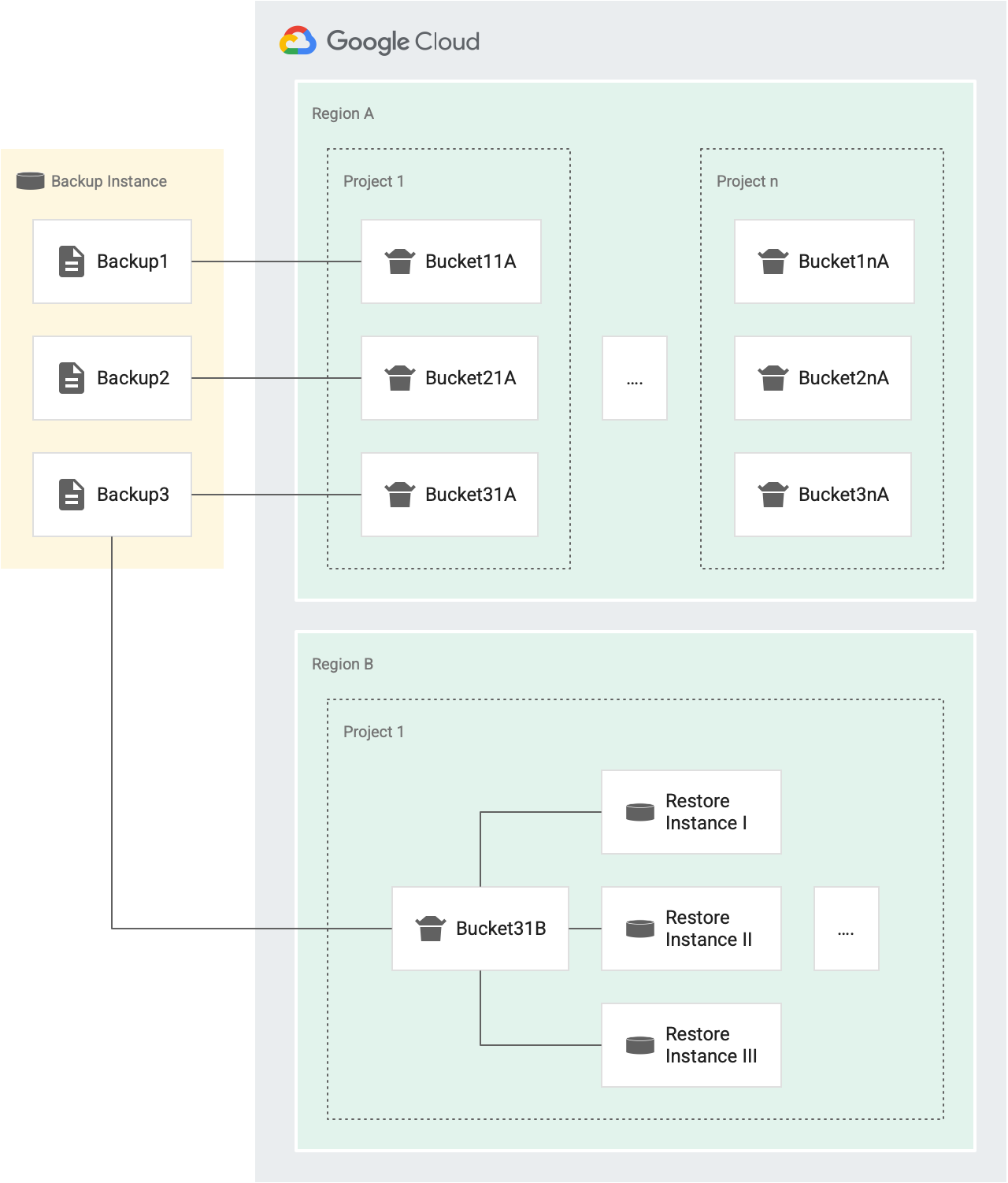
- Cada cópia de segurança (Backup1, Backup2 e Backup3) tem o seu próprio conjunto de tokens para operações de restauro que segmentam instâncias diferentes no projeto 1 na região A (Bucket11A, Bucket21A e Bucket31A). Uma vez que cada cópia de segurança tem o seu próprio contentor, pode restaurar cada cópia de segurança para a mesma instância três vezes a cada trinta minutos.
- Cada cópia de segurança tem um contentor para um projeto separado e para uma região separada.
Por exemplo, se existirem cinco projetos numa região, existem cinco contentores para essa cópia de segurança nessa região, um em cada projeto. Na figura anterior, temos dois projetos na região A: o projeto 1 e o projeto n.
- Backup1 tem dois contentores de tokens para operações de restauro na região A. Um contentor para o projeto 1 (Bucket11A) e um contentor para o projeto n (Bucket1nA).
- Da mesma forma, o Backup3 tem dois contentores para operações de restauro na região A. Um para o projeto 1 (Bucket31A) e um para o projeto n (Bucket3nA).
- Backup3 tem um contentor na região B, para o Project1, porque todas as instâncias no mesmo projeto de destino e na mesma região de destino partilham um contentor.