En esta página se proporciona información que debes revisar antes de restablecer una instancia desde una copia de seguridad o realizar una recuperación de un momento determinado (PITR).
¿Qué sucede durante un restablecimiento?
Para la edición de Cloud SQL Enterprise y la de Cloud SQL Enterprise Plus, puedes restablecer una instancia desde una copia de seguridad. También puedes restablecer copias de seguridad en instancias de diferentes ediciones.
Cuando restableces una instancia, los siguientes datos de la instancia principal se restablecen en la nueva instancia:
- Bases de datos
- Usuarios
La operación de restablecimiento hace que la instancia se reinicie.
Recuperación de un momento determinado (PITR)
Con la recuperación de un momento determinado (PITR), puedes recuperar una instancia tal como se encontraba un punto específico en el tiempo. Por ejemplo, si un error provoca pérdida de datos, puedes recuperar el estado de una base de datos antes de que se produjera el error.
La PITR siempre crea una instancia nueva. no puedes realizar una PITR a una instancia existente. La instancia nueva heredará la configuración de la instancia de origen, de forma similar a la creación de clones.
Cuando creas una instancia de Cloud SQL en la Google Cloud consola, la PITR está habilitada de forma predeterminada.La PITR usa el archivo de almacenamiento de registros de escritura anticipada (WAL). De forma predeterminada, la PITR está habilitada para instancias de edición de Cloud SQL Enterprise Plus.
Cuando restableces una copia de seguridad en una instancia de Cloud SQL antes de habilitar la PITR, pierdes los registros archivados que te permiten usar la PITR. Si el tamaño de los registros de escritura anticipada en el disco causa problemas de rendimiento en la instancia, desactiva la PITR y vuelve a habilitarla. Esta acción garantiza que los registros nuevos se almacenen en Cloud Storage en lugar de en el disco.Si quieres obtener instrucciones paso a paso para realizar la PITR, consulta Usa la recuperación de un momento determinado (PITR).
Restablece una instancia no disponible
Puedes usar la PITR para restablecer una instancia de Cloud SQL que no esté disponible. Por lo general, la PITR ofrece un objetivo de punto de recuperación (RPO) de cinco minutos o menos.
Si la instancia no está disponible, puedes usar la API para obtener la hora de recuperación más reciente y más antigua a la que puedes restablecer la instancia y realizar la recuperación en ese momento. Si no se puede acceder a la zona en la que se configuró la instancia, puedes restablecer la instancia en una zona principal o secundaria diferente si proporcionas valores para las zonas preferidas.
Supongamos que una instancia de Cloud SQL deja de estar disponible a las 4 p.m. (hora del este). Si el tiempo de recuperación más reciente es a las 3:55 p.m. (hora del este), puedes recuperar la instancia hasta este momento.
Restablece una instancia borrada con la PITR
Puedes usar la PITR para restablecer una instancia de Cloud SQL después de que se borre. Para usar esta función, tu instancia debe tener habilitadas las funciones de PITR y copias de seguridad retenidas antes de que se borre la instancia. Cuando se habilita, los registros de la PITR se conservan después de que borras la instancia.
Después de que se borra una instancia, los registros de la PITR siguen los parámetros de configuración de retención definidos por la instancia cuando estaba activa. Los registros de PITR vencen según la configuración de retención de forma continua después de que se borra la instancia. El período continuo se define en función del período de retención de la PITR establecido en la instancia antes de la eliminación. Por ejemplo, si tu instancia de edición de Cloud SQL Enterprise Plus tiene la retención de PITR establecida en 14 días, el registro de PITR más reciente se borrará 14 días después de que se borre la instancia. Cuando vence un registro de PITR, no se puede recuperar.
Dado que los nombres de las instancias se pueden volver a usar después de que se borra una instancia en Cloud SQL, los registros de PITR conservados se pueden identificar en Google Cloud con los siguientes campos:
instance_deletion_timelog_retention_days
Estos campos te permiten identificar si un registro de PITR pertenece a una instancia borrada.
El período de recuperación de la PITR se define como los horarios de recuperación más antiguos y más recientes disponibles para restablecer tu instancia con la PITR. Para encontrar las horas de recuperación más temprana y más reciente de tu instancia borrada, consulta Cómo obtener la hora de recuperación más temprana y más reciente.
Para restablecer una instancia con la PITR después de que se borró, consulta Realiza la PITR en una instancia borrada.
Sugerencias generales para realizar restablecimientos
Cuando restableces una instancia desde una copia de seguridad, ya sea a la misma instancia o a una diferente, recuerda los siguientes elementos:
- La operación de restablecimiento reemplaza todos los datos en la instancia de destino.
- La instancia de destino no podrá establecer conexiones durante la operación de restablecimiento; se perderán las conexiones existentes.
- Si restableces a una instancia con réplicas de lectura, debes borrar todas las réplicas y crearlas de nuevo luego de que se complete la operación de restablecimiento.
- La operación de restablecimiento reinicia la instancia.
Para obtener instrucciones paso a paso sobre cómo realizar un restablecimiento, consulta:
Sugerencias y requisitos para restablecer a una instancia diferente
Cuando restablezcas una copia de seguridad a una instancia diferente, recuerda las siguientes restricciones y prácticas recomendadas:
La instancia de destino debe tener la misma versión y edición de base de datos que la instancia de la que se realizó la copia de seguridad.
Cloud SQL siempre establece la capacidad de almacenamiento de la instancia de destino en el valor máximo del tamaño del disco configurado y del disco de copia de seguridad. El disco de copia de seguridad es el tamaño del disco cuando se realiza la copia de seguridad.
La capacidad de almacenamiento de la instancia de destino debe ser al menos tan grande como la capacidad de la instancia de la que se realiza la copia de seguridad. No importa la cantidad de almacenamiento que se utiliza. Puedes ver la capacidad de almacenamiento de la instancia en la página de instancias de Cloud SQL en la consola.
La instancia de destino debe tener el estado
RUNNABLE.La instancia de destino puede tener una cantidad diferente de núcleos o de memoria que la instancia desde la que se toma la copia de seguridad.
La instancia de destino puede estar en una región diferente de la de origen.
Durante una interrupción, de todas maneras puedes recuperar una lista de copias de seguridad en un proyecto en particular. Consulta Visualiza las copias de seguridad durante una interrupción.
Límites de frecuencia para los restablecimientos
Puedes tener un máximo de tres operaciones de restablecimiento cada 30 minutos por instancia y por región por proyecto. Si una operación de restablecimiento falla, no se considera en esta cuota. Si alcanzas el límite, la operación falla con un mensaje de error que te indica cuándo puedes volver a ejecutar la operación.
Veamos cómo Cloud SQL aplica el límite de frecuencia para los restablecimientos.
Cloud SQL usa tokens de un bucket para determinar cuántas operaciones de restablecimiento están disponibles a la vez. Por cada copia de seguridad, hay un bucket para cada proyecto y región de destino. Las instancias de destino del mismo proyecto comparten un bucket si están en la misma región. Hay un máximo de tres tokens en cada bucket que puedes usar para operaciones de restablecimiento. Cada 10 minutos, se agrega un token nuevo al bucket. Si el bucket está lleno, el token se desborda.
Cada vez que emites una operación de restablecimiento, se otorga un token al bucket. Si la operación se realiza correctamente, el token se quita del bucket. Si falla, el token se muestra en el bucket. En el siguiente diagrama, se puede ver cómo funciona:

Por ejemplo, en la siguiente figura, Backup1, Backup2 y Backup3 son las copias de seguridad de la misma instancia de origen.
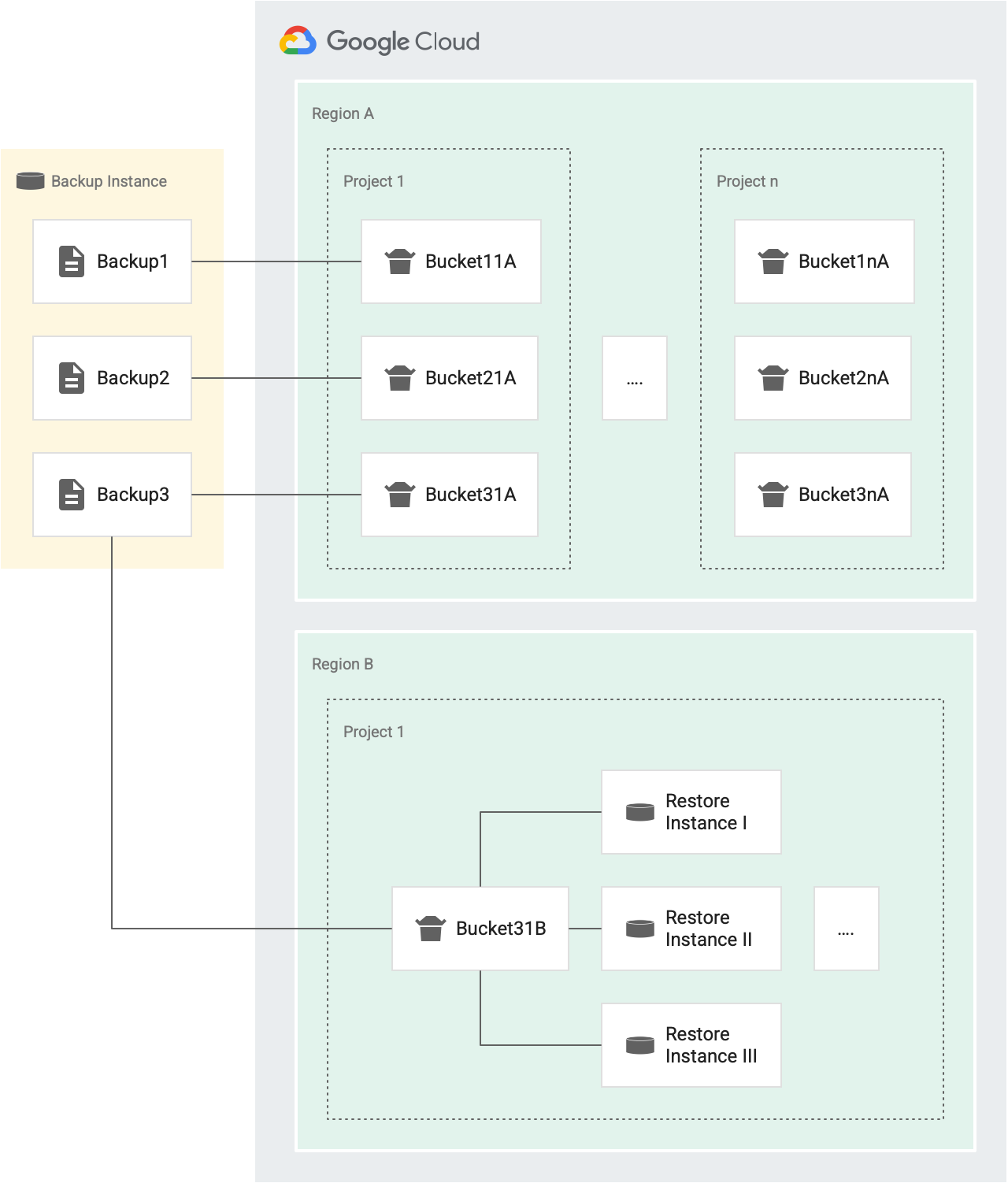
- Cada copia de seguridad (Backup1, Backup2 y Backup3) tienen su propio bucket de tokens para operaciones de restablecimiento que se orientan a diferentes instancias en el Proyecto 1 de la Región A (Bucket11A, Bucket21A y Bucket31A). Debido a que cada copia de seguridad tiene su propio bucket, puedes restablecer cada copia de seguridad en la misma instancia tres veces cada treinta minutos.
- Cada copia de seguridad tiene un bucket para un proyecto y una región diferentes.
Por ejemplo, si hay cinco proyectos en una región, hay cinco buckets para esa copia de seguridad en esa región, uno en cada proyecto. En la figura anterior, tenemos dos proyectos en la región A: Proyecto 1 y Proyecto n.
- Backup1 tiene dos buckets de tokens para las operaciones de restablecimiento en la región A. Un bucket para el Proyecto 1 (Bucket11A) y otro para el Proyecto n (Bucket1nA).
- Del mismo modo, Backup3 tiene dos buckets para las operaciones de restablecimiento en la región A. Uno para el Proyecto 1 (Bucket31A) y otro para el Proyecto n (Bucket3nA).
- Backup3 tiene un bucket en la región B, para el proyecto 1, porque todas las instancias en el mismo proyecto de destino y la misma región de destino comparten un bucket.