Halaman ini memberikan informasi untuk ditinjau sebelum memulihkan instance dari cadangan atau melakukan pemulihan point-in-time (PITR).
Apa yang terjadi selama pemulihan?
Untuk edisi Cloud SQL Enterprise dan edisi Cloud SQL Enterprise Plus, Anda dapat memulihkan instance dari cadangan. Anda juga dapat memulihkan cadangan di berbagai edisi instance.
Saat Anda memulihkan instance, data berikut dari instance utama dipulihkan ke instance baru:
- Database
- Pengguna
Operasi pemulihan akan menyebabkan instance dimulai ulang.
Pemulihan point-in-time (PITR)
Pemulihan point-in-time (PITR) membantu Anda memulihkan instance ke titik waktu tertentu. Misalnya, jika error menyebabkan hilangnya data, Anda dapat memulihkan database ke statusnya sebelum error terjadi.
PITR selalu membuat instance baru; Anda tidak dapat melakukan PITR untuk instance yang ada. Instance baru mewarisi setelan instance sumber, mirip dengan cara kerja pembuatan clone.
Saat Anda membuat instance Cloud SQL di konsol Google Cloud , PITR diaktifkan secara default.PITR menggunakan pengarsipan write-ahead logging (WAL). Secara default, PITR diaktifkan untuk instance edisi Cloud SQL Enterprise Plus.
Saat Anda memulihkan cadangan pada instance Cloud SQL sebelum mengaktifkan PITR, Anda akan kehilangan log yang diarsipkan sehingga Anda dapat menggunakan PITR. Jika ukuran log write-ahead di disk menyebabkan masalah performa untuk instance Anda, nonaktifkan PITR dan aktifkan kembali. Tindakan ini memastikan bahwa log baru disimpan di Cloud Storage, bukan di disk.Untuk petunjuk langkah demi langkah dalam melakukan PITR, lihat Menggunakan pemulihan point-in-time (PITR).
Memulihkan instance yang tidak tersedia
Anda dapat menggunakan PITR untuk memulihkan instance Cloud SQL yang tidak tersedia. PITR biasanya menawarkan objektif titik pemulihan (RPO) maksimum lima menit atau kurang.
Jika instance tidak tersedia, Anda dapat menggunakan API untuk mendapatkan waktu pemulihan paling awal dan paling akhir kapan Anda dapat memulihkan instance dan melakukan pemulihan pada waktu tersebut. Jika zona tempat instance dikonfigurasi tidak dapat diakses, Anda dapat memulihkan instance ke zona primer atau sekunder yang berbeda dengan memberikan nilai untuk zona yang diinginkan.
Misalnya, instance Cloud SQL tidak tersedia pada pukul 16.00 EST. Jika waktu pemulihan terakhir adalah pada pukul 15.55 EST, maka Anda dapat memulihkan instance hingga waktu ini.
Memulihkan instance yang dihapus menggunakan PITR
Anda dapat menggunakan PITR untuk memulihkan instance Cloud SQL setelah dihapus. Untuk menggunakan fitur ini, instance Anda harus mengaktifkan PITR dan cadangan yang dipertahankan sebelum instance dihapus. Jika diaktifkan, log PITR akan dipertahankan setelah Anda menghapus instance.
Setelah instance dihapus, log PITR akan terus mengikuti setelan retensi yang ditentukan oleh instance saat instance tersebut aktif. Log PITR akan berakhir berdasarkan setelan retensi secara bergilir setelah instance dihapus. Periode bergulir ditentukan berdasarkan periode retensi PITR yang ditetapkan pada instance sebelum penghapusan. Misalnya, jika instance edisi Cloud SQL Enterprise Plus Anda memiliki retensi PITR yang ditetapkan ke 14 hari, maka log PITR terbaru akan dihapus 14 hari setelah penghapusan instance. Setelah masa berlaku log PITR berakhir, log tersebut tidak dapat dipulihkan.
Karena nama instance dapat digunakan kembali setelah instance dihapus di Cloud SQL, log PITR yang dipertahankan dapat diidentifikasi di Google Cloud dengan kolom berikut:
instance_deletion_timelog_retention_days
Kolom ini memungkinkan Anda mengidentifikasi apakah log PITR termasuk dalam instance yang dihapus.
Periode pemulihan PITR ditentukan sebagai waktu pemulihan paling awal dan paling akhir yang tersedia untuk memulihkan instance Anda menggunakan PITR. Untuk menemukan waktu pemulihan paling awal dan terbaru instance yang dihapus, lihat Mendapatkan waktu pemulihan paling awal dan terbaru.
Untuk memulihkan instance menggunakan PITR setelah penghapusan instance, lihat Melakukan PITR pada instance yang dihapus.
Tips umum tentang cara melakukan pemulihan
Saat Anda memulihkan instance dari cadangan, baik ke instance yang sama atau ke instance yang berbeda, perhatikan item berikut:
- Operasi pemulihan akan menimpa semua data pada instance target.
- Instance target tidak tersedia untuk koneksi selama operasi pemulihan; koneksi yang ada akan terputus.
- Jika memulihkan ke instance dengan replika baca, Anda harus menghapus semua replika dan membuatnya kembali setelah operasi pemulihan selesai.
- Operasi pemulihan akan memulai ulang instance.
Untuk petunjuk langkah demi langkah dalam melakukan pemulihan, lihat:
Tips dan persyaratan untuk memulihkan ke instance lain
Saat Anda memulihkan cadangan ke instance yang berbeda, perhatikan pembatasan dan praktik terbaik berikut:
Instance target harus memiliki versi database yang sama dengan instance yang berasal dari tempat cadangan diambil.
Cloud SQL selalu menetapkan kapasitas penyimpanan instance target ke nilai maksimum ukuran disk baik disk yang dikonfigurasi dan disk cadangan. Disk cadangan merupakan ukuran disk saat cadangan diambil.
Kapasitas penyimpanan instance target setidaknya harus sebesar kapasitas instance yang dicadangkan. Jumlah penyimpanan yang digunakan tidak menjadi masalah. Anda dapat melihat kapasitas penyimpanan instance di konsol halaman instance Cloud SQL.
Instance target harus dalam status
RUNNABLE.Instance target dapat memiliki jumlah core atau jumlah memori yang berbeda dari instance tempat cadangan diambil.
Instance target dapat berada di region yang berbeda dengan instance sumber.
Selama layanan berhenti, Anda masih dapat mengambil daftar cadangan dalam project tertentu. Lihat Melihat cadangan selama pemadaman layanan.
Memulihkan batasan kapasitas
Anda dapat melakukan maksimum tiga operasi pemulihan setiap 30 menit per instance per region per project. Jika operasi pemulihan gagal, operasi tersebut tidak masuk hitungan dalam kuota ini. Jika sudah mencapai batas, operasi akan gagal dengan pesan error yang memberi tahu Anda kapan operasi dapat dijalankan kembali.
Mari kita lihat cara Cloud SQL melakukan pembatasan kapasitas untuk pemulihan.
Cloud SQL menggunakan token dari bucket untuk menentukan jumlah operasi pemulihan yang tersedia pada satu waktu. Untuk setiap cadangan, ada bucket untuk setiap project target dan region target. Instance target dari project yang sama menggunakan satu bucket jika berada di region yang sama. Ada maksimum tiga token di setiap bucket yang dapat Anda gunakan untuk operasi pemulihan. Setiap 10 menit, token baru ditambahkan ke bucket. Jika bucket penuh, token akan meluap.
Setiap kali Anda melakukan operasi pemulihan, token diberikan dari bucket. Jika operasi berhasil, token akan dihapus dari bucket. Jika gagal, token akan dikembalikan ke bucket. Diagram berikut menunjukkan cara kerjanya:

Misalnya, dalam gambar berikut, Cadangan1, Cadangan2, dan Cadangan3 adalah cadangan dari instance sumber yang sama.
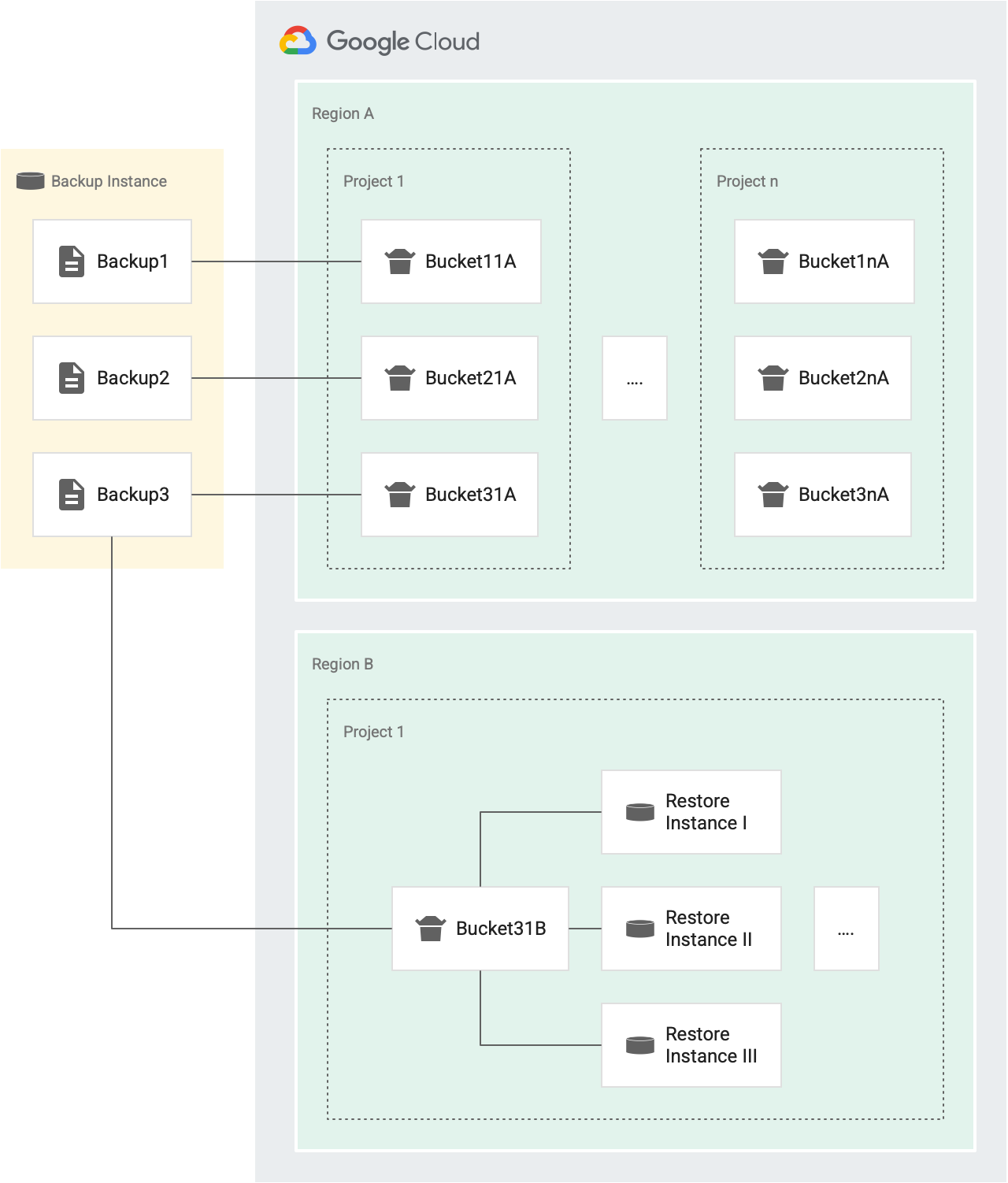
- Setiap cadangan (Cadangan1, Cadangan2, dan Cadangan3) memiliki bucket token sendiri untuk operasi pemulihan yang menargetkan berbagai instance dalam Project 1 di Region A (Cadangan11A, Cadangan21A, dan Cadangan31A). Karena setiap cadangan memiliki bucket sendiri, Anda dapat memulihkan setiap cadangan ke instance yang sama tiga kali setiap tiga puluh menit.
- Setiap cadangan memiliki bucket untuk project terpisah dan untuk region terpisah.
Misalnya, jika ada lima project di satu region, ada lima
bucket untuk cadangan itu di region tersebut, satu di setiap project. Pada gambar
sebelumnya, kita memiliki dua project di region A: Project 1 dan Project n.
- Cadangan1 memiliki dua bucket token untuk operasi pemulihan di Region A. Satu bucket untuk Project 1 (Bucket11A), dan satu bucket untuk Project n (Bucket1nA).
- Demikian pula, Cadangan3 memiliki dua bucket untuk operasi pemulihan di Region A. Satu untuk project 1 (Bucket31A) dan satu untuk project n (Bucket3nA).
- Cadangan3 memiliki satu bucket di Region B, untuk Project1, karena semua instance dalam project target yang sama dan region target yang sama menggunakan satu bucket.