このページでは、Cloud SQL での障害復旧について説明します。
概要
Google Cloudのデータベースの障害復旧(DR)は、特にリージョンで障害が発生した場合やリージョンが使用不可になった場合に、処理が継続されるようにすることを目的としています。Cloud SQL はリージョン サービスです(Cloud SQL が高可用性(HA)用に構成されている場合)。したがって、Cloud SQL データベースをホストする Google Cloud リージョンが使用不可になると、Cloud SQL データベースも使用できなくなります。
処理を続行するには、できるだけ早くセカンダリ リージョンでデータベースを利用できるようにする必要があります。このような DR 計画を実現するには、Cloud SQL の中でクロスリージョン リードレプリカを構成する必要があります。エクスポート / インポートまたはバックアップ / 復元によるフェイルオーバーも可能ですが、この方法では所要時間が長くなり、特に大規模なデータベースの場合は顕著です。
クロスリージョン フェイルオーバー構成を使用するのが適切であるビジネス シナリオの例を以下に示します。
- ビジネス アプリケーションのサービスレベル契約が、リージョンの Cloud SQL サービスレベル契約(Cloud SQL エディションに応じて 99.99% の可用性)を超えています。別のリージョンにフェイルオーバーすることで、サービスの停止を軽減できます。
- ビジネス アプリケーションのすべての階層はすでにマルチリージョンであり、リージョンが停止した場合も処理を続行できます。クロスリージョン フェイルオーバー構成は、データベースの継続的な可用性をサポートします。
- 要求される目標復旧時間(RTO)と目標復旧時点(RPO)は、時間単位ではなく分単位です。別のリージョンへのフェイルオーバーは、データベースの再作成よりも高速です。
通常、DR プロセスには 2 つのパターンがあります。
- データベースがセカンダリ リージョンにフェイルオーバーします。データベースの準備ができてアプリケーションで使用されると、そのデータベースが新たにプライマリ データベースになり、その後もプライマリ データベースを継続します。
- データベースがセカンダリ リージョンにフェイルオーバーしても、プライマリ リージョンが障害から回復すると、プライマリ リージョンにフォールバックします。
この Google Cloud SQL データベースの障害復旧の概要では、2 番目のバリアントについて説明します。これは、障害が発生したデータベースが回復し、プライマリ リージョンにフォールバックするケースです。この DR プロセスは、ネットワークのレイテンシや、プライマリ リージョンでのみ利用可能なリソースがあるため、プライマリ リージョンで実行する必要があるデータベースに特に適しています。このパターンを使用すると、データベースはプライマリ リージョンでサービスが停止している間のみ、セカンダリ リージョンで実行されます。
この DR ドキュメントに関連するチュートリアルは次のとおりです。- Cloud SQL for MySQL の障害復旧: 完全なフェイルオーバーとフォールバック プロセス
- Cloud SQL for PostgreSQL の障害復旧: 完全なフェイルオーバーとフォールバック プロセス
障害復旧アーキテクチャ
次の図は、HA Cloud SQL インスタンスのデータベース DR をサポートする最小限のアーキテクチャを示しています。
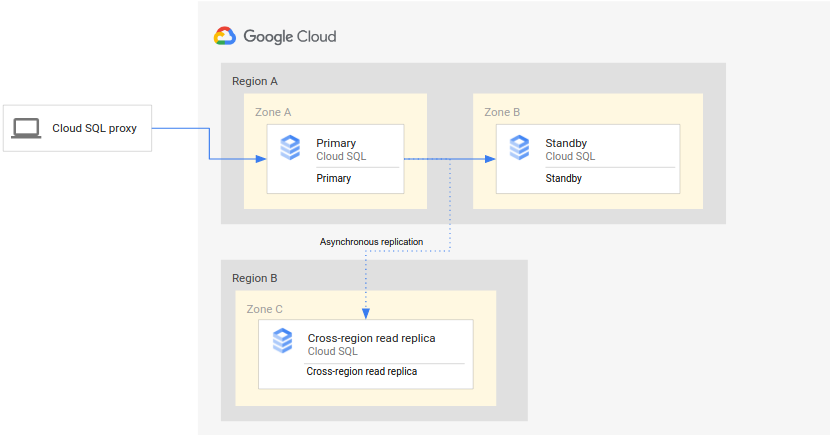
このアーキテクチャは次のように機能します。
- Cloud SQL の 2 つのインスタンス(プライマリ インスタンスとスタンバイ インスタンス)は、単一のリージョン(プライマリ リージョン)内の 2 つの別々のゾーンにあります。インスタンスは、リージョン永続ディスクを使用して同期されます。
- Cloud SQL(クロスリージョン リードレプリカ)の 1 つのインスタンスが 2 番目のリージョン(セカンダリ リージョン)にあります。DR の場合、クロスリージョン リードレプリカは、リードレプリカの設定を使用して(非同期レプリケーションを使用)プライマリ インスタンスとの同期をとるように設定されます。
プライマリ インスタンスとスタンバイ インスタンスは、同じリージョン ディスクを共有しているため、インスタンスの状態は同一です。
この設定では非同期レプリケーションを使用するため、クロスリージョン リードレプリカがプライマリ インスタンスの後で遅延する可能性があります。そのため、フェイルオーバーが発生した場合、クロスリージョン リードレプリカの RPO はゼロではない可能性があります。
障害復旧(DR)プロセス
障害復旧(DR)プロセスは、プライマリ リージョンが使用不可になったときに開始します。セカンダリ リージョンで処理を再開するには、クロスリージョン リードレプリカをプロモートすることによってプライマリ インスタンスのフェイルオーバーをトリガーします。DR プロセスでは、リージョン障害を軽減してセカンダリ リージョンでのプライマリ インスタンスの稼働を確立するために、手動または自動で実行する必要のある運用ステップが規定されます。
次の図は、DR プロセスを示しています。

この DR プロセスは以下の手順で構成されます。
- プライマリ インスタンスを実行しているプライマリ リージョン(R1)が使用不可になります。
- オペレーション チームがこの障害を認識して正式に認め、フェイルオーバーが必要かどうかを判断します。
- フェイルオーバーが必要な場合は、セカンダリ リージョン(R2)にあるクロスリージョン リードレプリカをプロモートして新しいプライマリ インスタンスにすることができます。
- クライアント接続が再構成されて新しいプライマリ インスタンスでの処理が再開し、R2 のプライマリ インスタンスにアクセスされるようになります。
この初期プロセスによって、プライマリ データベースが稼働する状態が再び確立します。ただし、完全な DR アーキテクチャ(新しいプライマリ インスタンス自体にスタンバイ インスタンスとクロスリージョン リードレプリカがある)は確立しません。
完全な DR プロセスによって、単一のインスタンス(新しいプライマリ)が HA に対して有効になり、クロスリージョン リードレプリカを持つ状態になります。また、完全な DR プロセスは、元のプライマリ リージョンでの元のデプロイへのフォールバックも実施します。
セカンダリ リージョンにフェイルオーバーする
完全な DR プロセスでは、フェイルオーバー後に完全な DR アーキテクチャを確立するためのステップを追加することで、基本的な DR プロセスを拡張します。次の図は、フェイルオーバー後の完全なデータベース DR アーキテクチャを示しています。

完全なデータベースの DR プロセスは、次の手順で構成されます。
- プライマリ データベースを実行しているプライマリ リージョン(R1)が使用できなくなります。
- オペレーション チームが障害を認識して正式に応答し、フェイルオーバーが必要かどうかを判断します。
- フェイルオーバーが必要な場合は、セカンダリ リージョン(R2)のクロスリージョン リードレプリカをプロモートして、新しいプライマリ インスタンスにできます。
- クライアント接続が、新しいプライマリ インスタンス(R2)にアクセスして処理するように再構成されます。
- R2 で新しいスタンバイ インスタンスが作成され、プライマリ インスタンスに追加されます。スタンバイ インスタンスは、プライマリ インスタンスとは異なるゾーンにあります。プライマリ インスタンスのスタンバイ インスタンスが作成されたため、プライマリ インスタンスの可用性が向上しました。
- 3 番目のリージョン(R3)では、新しいクロスリージョン リードレプリカが作成され、プライマリ インスタンスに接続されます。この時点で、完全な障害復旧アーキテクチャが再構築され、運用が可能になります。
ステップ 6 を実装する前に元のプライマリ リージョン(R1)が使用可能になると直ちに、クロスリージョン リードレプリカはリージョン R3 ではなくリージョン R1 に配置できるようになります。この場合は、元のプライマリ リージョン(R1)へのフォールバックの複雑性が低減し、必要とする手順が減少します。
スプリットブレイン状態を回避する
プライマリ リージョン(R1)の障害が発生しても、R1 が再び使用可能になったときに元のプライマリ インスタンスとスタンバイ インスタンスが、自動によるシャットダウンまたは削除が行われることなどにより、アクセス不可になることはありません。R1 が使用できるようになると、クライアントは(偶発的であっても)元のプライマリ インスタンスのデータの読み取りと書き込みを行うことができます。この場合、スプリットブレイン状態になる可能性があり、一部のクライアントが古いプライマリ データベースの古いデータにアクセスし、他のクライアントが新しいプライマリ データベースの最新データにアクセスして、ビジネス上の問題が起きる可能性があります
スプリットブレイン状態を回避するには、R1 が使用可能になった後でクライアントが元のプライマリ インスタンスにアクセスできないようにする必要があります。クライアントが新しいプライマリ インスタンスの使用を開始する前に、元のプライマリをアクセス不可にし、アクセス不可にした直後に元のプライマリを削除することをおすすめします。
フェイルオーバー後の初期バックアップの確立
クロスリージョン リードレプリカをフェイルオーバーの新しいプライマリに昇格させると、新しいプライマリ内のトランザクションと元のプライマリのトランザクションが完全には同期されないことがあります。したがって、こうしたトランザクションは新しいインスタンスでは使用できません。
ベスト プラクティスとして、フェイルオーバーの開始時とクライアントがデータベースにアクセスする前に、新しいプライマリ インスタンスを直ちにバックアップすることをおすすめします。このバックアップは、フェイルオーバー発生時点の整合性がとれた既知の状態を表しています。このようなバックアップは、規制目的で、またはクライアントが新しいプライマリにアクセスするときに問題が発生した場合に既知の状態に戻すという目的で重要になる可能性があります。
元のプライマリ リージョンにフォールバックする
前述したように、このドキュメントでは元のリージョン(R1)にフォールバックする手順を説明します。フォールバック プロセスには 2 つのバージョンがあります。
- 第 3 リージョン(R3)で新しいクロスリージョン リードレプリカを作成した場合は、プライマリ リージョン(R1)に別の(2 番目の)クロスリージョン リードレプリカを作成する必要があります。
- プライマリ リージョン(R1)で新しいクロスリージョン リードレプリカを作成した場合、R1 で別のクロスリージョン リードレプリカを新たに作成する必要はありません。
R1 のクロスリージョン リードレプリカが存在する場合、Cloud SQL インスタンスは R1 にフォールバックできます。このフォールバックはサービスの停止によってではなく、手動でトリガーされるため、このメンテナンス作業に適した日時を選択できます。
したがって、プライマリ、スタンバイ、クロスリージョン リードレプリカを備えた完全な DR を実現するには、2 回のフェイルオーバーが必要になります。1 回目のフェイルオーバーは、サービスの停止によってトリガーされます(真のフェイルオーバー)。2 回目のフェイルオーバーによって、出発点となるデプロイが再確立されます(フォールバック)。
元のプライマリ リージョン(R1)へのフォールバックは、次のステップで構成されます。
- 元のプライマリ リージョン(R1)で、新しく作成されたクロスリージョン レプリカをプロモートします。
- プロモートしたインスタンスが HA レプリカとして作成されたものではない場合は、ゾーン障害から保護するためにそのインスタンス上で HA を有効にします。
- 新しいプライマリ インスタンスに接続するようにアプリケーションを再構成します。
- DR リージョン(R2)に新しいプライマリ インスタンスのクロスリージョン レプリカを作成します。
- (省略可)複数の独立したプライマリ インスタンスが実行される状態を回避するために、DR リージョン(R2)のプライマリ インスタンスをクリーンアップします。
高度な障害復旧(DR)
Cloud SQL Enterprise Plus エディションを使用している場合は、高度な DR を利用できます。高度な DR によって、クロスリージョン フェイルオーバー後の復旧とフォールバックが単純になります。障害復旧プロセスで説明しているように、DR を行うときに、古いプライマリ インスタンスの、障害が発生したリージョンと、新しいプライマリ インスタンスの稼働中リージョンとの接続が解除されます。DR のときに、元のデプロイ リージョンへの接続を復元して古いプライマリ インスタンスを再び稼働させるには、一連の手動フォールバック手順を実施する必要があります。
高度な DR では、リージョン障害が発生したときにレプリカ フェイルオーバーを起動できます。レプリカ フェイルオーバーでは、通常の DR を行うときと同様にクロスリージョン リードレプリカをプロモートしますが、指定障害復旧(DR)レプリカをプロモートする点が異なります。DR レプリカのプロモートは即時に行われます。
古いプライマリ インスタンスは削除されるのではなく、Cloud SQL の非同期レプリケーション トポロジの一部として残ります。古いプライマリ インスタンス(インスタンス A)は最終的に、自身の DR レプリカ(インスタンス B)が新しいプライマリ インスタンスにプロモートされた後に、その DR レプリカのレプリカとなります。
古いプライマリ インスタンス(A)がレプリカになった後に、高度な DR の最後のステップを実行できます。Cloud SQL のデプロイを元の状態に戻して、データの損失を発生させることなく古いプライマリ インスタンス(A)を元の役割つまりプライマリ インスタンスに戻すことができます。このような、古いプライマリ インスタンス(A)のゼロデータ損失復元を実行するには、スイッチオーバー オペレーションを使用できます。スイッチオーバーを実行するときに、データが失われることはありません。プライマリ インスタンス(B)は、その指定 DR レプリカ(A)がプライマリ インスタンス(B)と等しい状態になるまでの間、読み取り専用モードで残っているからです。DR レプリカ(A)がレプリケーションの更新をすべて受信すると、DR レプリカ(A)がプライマリ インスタンスの役割を引き継ぎ、それまでのプライマリ インスタンス(B)は自動的に、現在のプライマリ インスタンス(A)の DR レプリカとして再構成されます。インスタンスはそれぞれの元の役割に戻り、その結果としてトポロジは DR とレプリカ フェイルオーバーの前の、元の状態に戻ります。
高度な DR では、レプリカ フェイルオーバーとスイッチオーバーの両方のオペレーションに関与するすべてのインスタンスがそれぞれの IP アドレスを保持します。
高度な DR のスイッチオーバー オペレーションは定期的な DR 訓練の実施にも使用できるので、Cloud SQL トポロジがクロスリージョン フェイルオーバーに対応できるかどうかのテストと準備を、実際の障害発生前に行うことができます。実際の障害が発生した場合は、テスト済みのクロスリージョン レプリカ フェイルオーバーを実行できます。
障害復旧(DR)レプリカ
高度な DR の必須コンポーネントの一つである DR レプリカには、次の特性があります。
- DR レプリカは、直接接続されたクロスリージョン リードレプリカです。
- DR レプリカの指定は何回でも変更できます。
- DR レプリカの指定は、スイッチオーバーまたはレプリカ フェイルオーバーのオペレーション中を除き、いつでも変更できます。
また、高度な DR を使用した後の RTO を短縮するために、次のことをおすすめします。
- DR レプリカをプライマリ インスタンスと同じサイズで構成します。
- プライマリ インスタンスで HA が有効になっている場合は、DR レプリカでも HA を有効にすることをおすすめします。そうするには、まず、プライマリで HA が有効になっていることを確認します。次に、DR レプリカへの切り替えを行います。切り替えオペレーションが完了したら、新しいプライマリ インスタンスで HA を有効にします。その後、古いプライマリ インスタンスに戻すことができます。DR レプリカは、レプリカに戻った後も HA 構成を保持します。
レプリカ フェイルオーバー
要約すると、レプリカ フェイルオーバーは次のイベントで構成されます。
- DR レプリカを作成して割り当てます。
- プライマリ リージョンが使用できなくなります。
- DR レプリカへのレプリカ フェイルオーバーを実行します。
- 書き込みエンドポイントが更新され、新しいプライマリ インスタンスを指すようになります。
- 元のプライマリ インスタンスがオンラインに戻ると、新しいプライマリ インスタンスのリードレプリカになります。
- スイッチオーバー オペレーションを使用して、デプロイを元のトポロジに復元できます。
レプリカのフェイルオーバー オペレーションの詳細と図を表示するには、次のタブをクリックします。
DR レプリカを割り当てる
レプリカ フェイルオーバーの実行前に、DR レプリカがプライマリ インスタンスに割り当て済みであり、可能であればスイッチオーバーを実行することによってプロセスがテスト済みです。

サービス停止が発生する
プライマリ リージョン(ここでプライマリ データベースが実行されています)が使用不可になります。

レプリカ フェイルオーバー
障害復旧が必要と判断したら、クロスリージョン指定 DR レプリカへのレプリカ フェイルオーバーを実行します。
クロスリージョン指定 DR レプリカが即座にプライマリ インスタンスになり、読み取りと書き込みの受け入れを開始します。書き込みエンドポイントが更新され、新しいプライマリ インスタンスを指すようになります。

元のプライマリがレプリカになる
レプリカが昇格された後、Cloud SQL は元のプライマリ インスタンスがオンラインに戻ったかどうかを定期的に確認します。元のプライマリ インスタンスがオンラインの場合、Cloud SQL は古いプライマリを昇格されたインスタンスのレプリカとして再作成します。古いプライマリ インスタンスの IP アドレスはそのまま保持されます。

元のプライマリにフェイルバックする
レプリカ フェイルオーバーを行った後に、プライマリ インスタンスを元のリージョンで復元するには、スイッチオーバー オペレーションを実行します。これで、同じ DR レプリカとプライマリ インスタンスのペアが逆転します。

切り替え
スイッチオーバー オペレーションは、次のイベントで構成されます。
- DR レプリカを作成して割り当てます。
- スイッチオーバーを開始します。
- レプリケーション ラグがゼロになると、新しいプライマリ インスタンスが受信接続の受け入れを開始します。
- 古いプライマリ インスタンスはリードレプリカになります。
- DNS 書き込みエンドポイントが使用されている場合、新しいプライマリ インスタンスを指すように DNS 書き込みエンドポイントが更新されます。
スイッチオーバー オペレーションの詳細と図を表示するには、次のタブをクリックします。
DR レプリカを割り当てる
「スイッチオーバー」オペレーションを開始する前に、DR レプリカをプライマリ インスタンスに割り当てる必要があります。
プライマリ インスタンスが正常に稼働していることを確認します。スイッチオーバーを実行できるのは、プライマリ インスタンスと DR レプリカの両方がオンラインの場合のみです。
スイッチオーバーを開始する
スイッチオーバーを開始します。スイッチオーバーを開始すると、プライマリ インスタンスは書き込みの受け入れを停止して読み取り専用になります。Cloud SQL は、トランザクション ログが Cloud Storage にコピーされるまで待ちます。指定 DR レプリカがプライマリ インスタンスと同じ状態になります。
レプリケーション ラグがゼロになると、DR レプリカが新しいプライマリ インスタンスとして昇格されます。新しいプライマリ インスタンスが接続の受け入れを開始します。これにはアプリケーションの読み取りと書き込みも含まれます。
エンドポイントの更新
DR レプリカが新しいプライマリ インスタンスに昇格すると、DNS 書き込みエンドポイントが更新され、新しいプライマリ インスタンスを指すようになります。DNS 書き込みエンドポイントを使用していない場合は、新しいプライマリ インスタンスの IP アドレスを指すようにアプリケーションを構成する必要があります。
古いプライマリ インスタンスがリードレプリカとして再構成されます。
PITR が新しいプライマリ インスタンスに対して自動的に有効になります。PITR は、最初の自動バックアップ後にのみ可能です。
書き込みエンドポイント
書き込みエンドポイントは、現在のプライマリ インスタンスの IP アドレスに自動的に解決されるグローバル ドメイン名サービス(DNS)名です。このエンドポイントは、レプリカのフェイルオーバーまたはスイッチオーバー オペレーションが発生した場合に、受信接続を新しいプライマリ インスタンスに自動的にリダイレクトします。IP アドレスの代わりに、SQL 接続文字列で書き込みエンドポイントを使用できます。書き込みエンドポイントを使用すると、リージョンが停止した場合にアプリケーション接続を変更する必要がなくなります。
書き込みエンドポイントを使用するには、Cloud SQL Enterprise Plus エディションのプライマリ インスタンスを作成するプロジェクトまたは既存のプロジェクトで Cloud DNS API が有効になっている必要があります。プライベート IP アドレスと承認済みネットワークを使用して Cloud SQL Enterprise Plus エディション インスタンスを作成すると、Cloud SQL はインスタンスの書き込みエンドポイントを自動的に生成します。Cloud SQL Enterprise Plus エディションのプライマリ インスタンスがすでにある場合は、DR レプリカ(プライマリ インスタンスに指定するクロスリージョン レプリカ)を作成するときに、Cloud SQL によって書き込みエンドポイントが生成されます。切り替えまたはレプリカ フェイルオーバー オペレーションによりプライマリ インスタンスが変更された場合、DR レプリカが新しいプライマリ インスタンスになると、Cloud SQL は書き込みエンドポイントを DR レプリカに割り当てます。
書き込みエンドポイントを使用してインスタンスに接続する方法の詳細については、書き込みエンドポイントを使用してインスタンスに接続するをご覧ください。
次のステップ
- 高度な障害復旧(DR)を使用する。
- Cloud SQL for MySQL の障害復旧のチュートリアルを試す。
- Google Cloudに関するリファレンス アーキテクチャ、図、チュートリアル、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。