Spanner 是由 Google 工程师开发的具备高度一致性的分布式可扩展数据库,用于支持一些 Google 最关键的应用。Spanner 采用数据库和分布式系统社区的核心理念,并以新的方式对其进行扩展。Spanner 将此内部 Spanner 服务放在 Google Cloud Platform 上供大众使用。
由于 Spanner 必须满足 Google 关键业务应用所需的较为严苛的正常运行时间要求和规模要求,因此我们自构建之初便开始将 Spanner 打造为一个广泛分布式数据库,可跨多台机器及多个数据中心和区域提供服务。我们利用这种分布特性来处理庞大的数据集和巨大的工作负载,同时仍然保持非常高的可用性。我们还力争使 Spanner 提供与其他企业级数据库同样严格的一致性保证,以期让开发者拥有绝佳的体验。与仅支持行级一致性、实体级一致性或根本没有一致性保证的数据库相比,为支持强一致性的数据库编写软件要容易得多,也更为合理。
在本文档中,我们详细描述了 Spanner 中的读写工作原理以及 Spanner 如何确保强一致性。
起点
有些数据集太大,无法存放在一台机器上。此外,即使数据集较小,工作负载也可能过重而无法在一台机器上处理。这意味着我们需要找到一种方法来将我们的数据拆分为多个单独的部分,以将其存储在多台机器上。我们采用的方法是将数据库表分为连续的键范围(称为“分片”(split))。一台机器可处理多个分片,并可提供快速查询服务,来判断处理给定键范围的机器。Spanner 用户可以看到数据的拆分方式及其所在机器的详细信息。因此,即使在工作负载很重、规模很大的情况下,我们的系统也能以较低的延迟处理读取和写入操作。
我们还希望确保在出现故障时,数据仍可访问。为实现这一目标,我们将每个分片复制到不同故障网域中的多台机器。 为了在不同的分片副本之间实现一致的复制,我们使用 Paxos 算法管理复制。 在 Paxos 算法中,如果分片的大多数投票副本均在正常运行,那么其中一个副本可以被选为主要副本来处理写入操作,并允许其他副本处理读取操作。
Spanner 提供只读事务和读写事务。前者是不会修改数据的操作(包括 SQL SELECT 语句)的首选事务类型。只读事务仍会提供强一致性,并且默认使用最新的数据副本。不过,它们能够在无需任何形式的内部锁定的情况下运行,这使得它们速度更快,也更具可扩展性。读写事务用于插入、更新或删除数据的事务;这包括执行读取但其后会紧跟写入操作的事务。它们仍然具有很高的可扩展性,但读写事务引入了锁定,并且必须由 Paxos 的主要副本进行编排。请注意,锁定对于 Spanner 客户端而言是透明的。
在此之前的许多分布式数据库系统选择了不提供高度一致性保证,因为那往往需要高成本的跨机器通信。Spanner 能够使用 Google 开发的 TrueTime 技术在整个数据库中提供高度一致的快照。就像 1985 年左右的时间机器中的通量电容器(使时间旅行成为可能)一样,TrueTime 使 Spanner 成为可能。TrueTime 是一种 API,它允许 Google 数据中心内的任何机器以高精度(误差在几毫秒内)获悉准确的全球时间。这使得各种 Spanner 机器能够推断事务操作的顺序(并且该顺序与客户端观察到的顺序相匹配),且通常无需任何通信。Google 不得不为其数据中心配备特殊硬件(原子钟!)以使 TrueTime 发挥作用。由此产生的时间精度和准确度远高于其他协议(如 NTP)所能达到的时间精度和准确度。具体来说,Spanner 会为所有读写操作分配一个时间戳。时间戳 T1 处的事务可确保反映在 T1 之前发生的所有写入的结果。如果一台机器想要满足 T2 处的读取请求,它必须确保其数据视图至少在 T2 处保持最新状态。得益于 TrueTime 技术,此判断通常成本不高。用于确保数据一致性的协议很复杂,但在原始的 Spanner 文档和本文档有关 Spanner 及一致性的部分中都有详细讨论。
实际示例
让我们通过几个实际的示例来看看它的运作方式:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
在这个示例中,我们有一个使用简单整数主键的表。
| 分块 | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
在上述 ExampleTable 的架构中,主键空间被分为多个分片。例如:如果 ExampleTable 中存在 Id 为 3700 的行,该行将位于分片 8 中。如上所述,分片 8 本身会被复制到多台机器上。
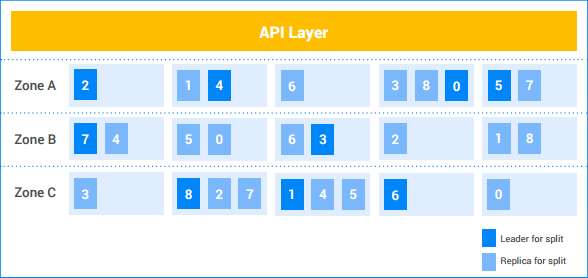
在这个示例的 Spanner 实例中,客户有五个节点,并且实例被复制到三个地区中。九个分片的编号为 0-8,每个分片的 Paxos 主要副本均用深色表示。此外,分片在每个地区中均有副本(浅色)。节点之间的分片分布可能因地区而异,而 Paxos 主要副本并不都在同一个地区中。这种灵活性有助于使 Spanner 对某些类型的负载配置文件和故障模式而言更加稳健。
单分块写入
假设客户端想要在 ExampleTable 中插入新行 (7, "Seven")。
- API 层查找拥有包含
7的键范围的分片。它位于分片 1。 - API 层向分片 1 的主要副本发送写入请求。
- 主要副本开始一个事务。
- 主要副本尝试获取行
Id=7的写锁。这是一个局部操作。如果有另一个并发读写事务当前正在读取此行,则后者就会有读锁,并且当前事务会被阻止直到其能够获取写锁。- 可能的情况是,事务 A 可能正在等待事务 B 持有的锁,与此同时,事务 B 也可能正在等待事务 A 持有的锁。由于这两个事务在获取所有锁之前都不会释放任何锁,因此可能会导致死锁。Spanner 使用标准的“受伤-等待”死锁预防算法来确保事务继续运行。具体来说,“较新”的事务会等待“较旧”的事务持有的锁,而“较旧”的事务会“伤害”(中止)持有该较旧事务所请求锁的较新事务。因此,锁等待者永远不会产生死锁循环。
- 获取锁后,主要副本就会基于 TrueTime 为事务分配一个时间戳。
- 该时间戳保证会晚于任何先前提交的触及数据的事务。这样可以确保事务顺序(客户端认为的顺序)与数据更改的顺序一致。
- 主要副本将事务及其时间戳告知分片 1 副本。 一旦这些副本中的大多数将事务变更存储在稳定存储空间(位于分布式文件系统)中,事务就会提交。 这样可以确保即使少数机器出现故障,事务也能够恢复。(副本尚未将变更应用于其数据副本。)
主要副本会等到能确定事务的时间戳已实时传递为止;这通常需要几毫秒,以避开 TrueTime 时间戳可能存在的不确定性。这样可以确保高度一致性:一旦客户端获知事务的结果,就可以保证所有其他读取者也能看到事务的效果。这个“提交等待”通常与上述步骤中的副本通信同时发生,因此它的实际延迟成本很低。如需了解详情,请参阅这篇文档。
主要副本响应客户端并告知其事务已提交,并选择性地报告事务的提交时间戳。
在响应客户端的同时,将事务变更应用于数据。
- 主要副本将变更应用于其数据副本,然后释放事务锁。
- 主要副本还通知其他分片 1 副本将变更应用于各自的数据副本。
- 任何应该看到变更效果的读写或只读事务都会等到变更被应用后再尝试读取数据。对于读写事务,这是强制执行的,因为此类事务必须具有读锁。对于只读事务,会将读取时间戳与最新应用的数据的时间戳进行比较以强制执行。
所有这些操作通常都在几毫秒内完成。这是由 Spanner 完成的写入中成本最低的一种,因为其中仅涉及单个分片。
多分片写入
如果涉及多个分片,则需要额外进行协调(使用标准的两段式提交算法)。
假设表包含四千行:
| 1 | "1" |
| 2 | "2" |
| … | … |
| 4000 | "4000" |
假设客户端希望通过一个事务读取行 1000 的值并为行 2000、3000 和 4000 写入值。该操作将在一个读写事务中执行,如下所示:
- 客户端开始一个读写事务 tt。
- 客户端向 API 层发出对行 1000 的读取请求并将其标记为 t 的t一部分。
- API 层查找拥有键
1000的分片。它位于分片 4。 API 层向分片 4 的主要副本发送读取请求并将其标记为 t 的t一部分。
分片 4 的主要副本尝试获取行
Id=1000的读锁。这是一个局部操作。如果有另一个并发事务持有该行的写锁,则当前事务会被阻止直到其能够获取读锁。不过,这个读锁不会阻止其他事务获取读锁。- 和单分块的情况一样,多分块写入也通过“受伤-等待”来避免死锁。
主要副本查找
Id1000的值 ("1000") 并将读取结果返回给客户端。
稍后...客户端为事务 t 发出提交请求。此提交请求包含 3 个变更:(
[2000, "Dos Mil"]、[3000, "Tres Mil"]和[4000, "Quatro Mil"])。- 事务中涉及的所有分片均成为该事务的参与者。在本例中,分片 4(执行键
1000的读取)、分片 7(处理键2000的变更)和分片 8(处理键3000和键4000的变更)是参与者。
- 事务中涉及的所有分片均成为该事务的参与者。在本例中,分片 4(执行键
一个参与者成为协调者。在本例中,分片 7 的主要副本可能会成为协调者。协调者的工作是确保事务在所有参与者之间以原子方式提交或中止。也就是说,在一个参与者处提交的同时无法在另一个参与者处中止。
- 参与者和协调者完成的工作实际上是由这些分片的主要机器完成的。
参与者获取锁。(这是两段式提交的第一阶段。)
- 分片 7 获取键
2000上的写锁。 - 分片 8 获取键
3000和键4000上的写锁。 - 分片 4 验证其仍然持有键
1000上的读锁(换句话说,锁没有因为机器崩溃或“受伤-等待”算法而丢失)。 - 每个参与者分片通过将其一组锁复制到(至少)大部分分片副本来记录这些锁。这样可以确保即使服务器出现故障,锁也能够保持被持有状态。
- 如果所有参与者成功地通知协调者锁已持有,那么整个事务就可以提交了。这确保了事务所需的所有锁在某一个时间点都处于被持有状态,且这个时间点会成为该事务的提交时间点,进而确保我们能正确地将此事务的效果与在其之前或之后的其他事务的效果进行排序。
- 锁可能无法被获取(例如,如果我们通过“受伤-等待”算法了解到可能会出现死锁)。如果有任意参与者表示无法提交事务,则整个事务会中止。
- 分片 7 获取键
如果所有参与者和协调者成功获取锁,协调者(分片 7)会决定提交事务。它将基于 TrueTime 为事务分配时间戳。
- 这个提交决定以及键
2000的变更会被复制到分片 7 的成员。当分片 7 的大多数副本将提交决定记录到稳定存储空间时,事务就会被提交。
- 这个提交决定以及键
协调者将事务结果传达给所有参与者。(这是两段式提交的第二阶段。)
- 每个参与者主要副本会将提交决定复制到参与者分片的副本。
事务被提交后,协调者和所有参与者会将变更应用于数据。
- 和单分块的情况一样,协调者或参与者中后续的数据读取者必须等到数据应用完毕。
协调者主要副本响应客户端并告知其事务已提交,并选择性地返回事务的提交时间戳。
- 和单分块的情况一样,在提交等待后,结果会被传递给客户端,以确保强一致性。
所有这些操作通常都在几毫秒内完成,但由于存在额外的跨分块协调,因此时间通常比单分块情况略长一些。
强读取(多分块)
假设客户端要读取 Id >= 0 和 Id < 700 作为只读事务一部分的所有行。
- API 层查找拥有处于范围
[0, 700)的任意键的分片。这些行由分片 0、分片 1 和分片 2 所有。 - 由于这是跨多台机器的强读取,API 层会使用当前 TrueTime 来选择读取时间戳。这样可以确保两次读取从数据库的同一快照返回数据。
- 其他类型的读取(如过时读取)也会选择一个时间戳来进行读取(但时间戳可能位于过去)。
- API 层将读取请求发送到分片 0、分片 1 和分片 2 的一些副本。还会加入上一步中选择的读取时间戳。
对于强读取,服务副本通常会向主要副本发出 RPC,要求提供其需要应用的最后一个事务的时间戳,并且在应用该事务后可以继续读取。如果副本是主要副本,或者它根据其内部状态和 TrueTime 确定自己的同步程度足以满足处理请求的条件,则会直接处理读取。
来自各个副本的结果会被合并并返回给客户端(通过 API 层)。
请注意,读取不会在只读事务中获取任何锁。此外,由于读取操作可能会由给定分片的任意最新副本执行,因此系统的读取吞吐量可能非常高。如果客户端能够容忍至少过时 10 秒的读取,则读取吞吐量可能会更高。由于主要副本通常每隔十秒便会用最新的安全时间戳更新一次副本,因此在过时时间戳处执行的读取可以避免向主要副本发送额外的 RPC。
总结
就传统的分布式数据库系统而言,提供强有力的事务性保证成本高昂,因为需要进行各种跨机器通信。对于 Spanner,我们专注于降低事务成本,以便在规模较大和采用分布式结构的情况下事务依然可行。实现这一点的一个关键因素是 TrueTime,它减少了许多类型的协调所需的跨机器通信。除此之外,通过细致的工程设计和性能调整,系统能够在提供强有力保证的同时维持高性能。在 Google 内部,我们发现,与使用较弱保证的其他数据库系统相比,在 Spanner 上开发应用要简单得多。当应用开发者不必担心数据竞争条件或数据不一致时,便可以专注于自己真正关心的事情:构建和发布一个出色的应用。