클라이언트
Spanner는 SQL 쿼리를 지원합니다. 다음은 샘플 쿼리입니다.
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
구조 @firstName은 쿼리 매개변수에 대한 참조입니다. 리터럴 값을 사용할 수 있는 곳은 어디든지 쿼리 매개변수를 사용할 수 있습니다. 프로그래매틱 API에서는 매개변수를 사용하는 것이 좋습니다. 쿼리 매개변수를 사용하면 SQL 주입 공격을 피할 수 있으며 결과 쿼리가 다양한 서버 측 캐시의 이점을 더욱 누릴 수 있습니다. 아래의 캐싱을 참조하세요.
쿼리 실행 시 쿼리 매개변수가 값에 바인딩되어야 합니다. 예를 들면 다음과 같습니다.
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Spanner에서 API 호출을 받으면 쿼리와 바인딩된 매개변수를 분석하여 쿼리를 처리할 Spanner 서버 노드를 결정합니다. 서버는 ResultSet.next() 호출을 통해 소비되는 결과 행의 스트림을 되돌려 보냅니다.
쿼리 실행
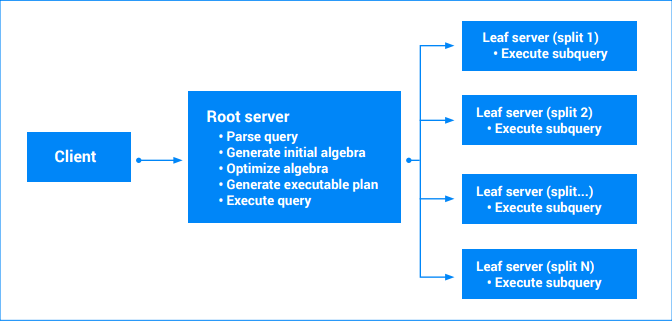
일부 Spanner 서버에 '쿼리 실행' 요청이 도착하면 쿼리가 실행됩니다. 서버는 다음 단계를 수행합니다.
- 요청 유효성 확인
- 쿼리 텍스트 파싱
- 초기 쿼리 대수 생성
- 최적화된 쿼리 대수 생성
- 실행 가능한 쿼리 계획 생성
- 계획 실행(권한 확인, 데이터 읽기, 결과 인코딩 등)
파싱
SQL 파서는 쿼리 텍스트를 분석하여 이를 추상 구문 트리로 변환합니다. 기본 쿼리 구조 (SELECT …
FROM … WHERE …)를 추출하고 구문 검사를 수행합니다.
대수
Spanner의 유형 시스템은 스칼라, 배열, 구조체 등을 나타낼 수 있습니다. 쿼리 대수는 테이블 스캔, 필터링, 정렬/그룹화, 모든 종류의 조인, 집계 등에 대한 연산자를 정의합니다. 초기 쿼리 대수는 파서의 출력에서 만들어집니다. 파싱 트리의 필드 이름 참조는 데이터베이스 스키마를 사용하여 확인됩니다. 또한 이 코드는 의미 오류(예: 잘못된 매개변수 수, 유형 불일치 등) 여부를 확인합니다.
다음 단계('쿼리 최적화')에서는 초기 대수를 가져와 보다 최적 상태의 대수를 생성합니다. 이 대수는 더 간단하거나 더 효율적이거나 실행 엔진의 기능에 더욱 적합할 수 있습니다. 예를 들어, 초기 대수는 '조인'만 지정하지만 최적화된 대수는 '해시 조인'을 지정할 수 있습니다.
실행
최종 실행 가능 쿼리 계획은 다시 작성된 대수에서 만들어집니다. 기본적으로 실행 가능 계획은 '반복자'의 방향성 비순환 그래프(DAG)입니다. 각 반복자는 일련의 값을 노출합니다. 반복자는 출력을 생성하기 위해 입력을 소비할 수 있습니다(예: 정렬 반복자). 단일 분할을 포함하는 쿼리는 단일 서버(데이터를 보유한 서버)에서 실행될 수 있습니다. 서버는 다양한 테이블에서 범위를 스캔하고, 조인을 실행하며, 집계를 수행하고, 쿼리 대수에 의해 정의된 다른 모든 연산을 수행합니다.
다중 분할을 포함하는 쿼리는 여러 부분으로 분해됩니다. 쿼리의 일부는 기본(루트) 서버에서 계속 실행됩니다. 다른 부분 하위 쿼리는 리프 노드(읽을 분할을 소유한 노드)로 전달됩니다. 복합 쿼리에서는 이러한 전달이 재귀적으로 적용되어 서버 실행 트리가 될 수 있습니다. 모든 서버가 타임스탬프에 동의하므로 쿼리 결과는 데이터의 일관된 스냅샷이 됩니다. 각 리프 서버가 부분 결과 스트림을 되돌려 보냅니다. 집계를 포함하는 쿼리의 경우, 이는 부분 집계된 결과일 수 있습니다. 쿼리 루트 서버가 리프 서버의 결과를 처리하고 나머지 쿼리 계획을 실행합니다. 자세한 내용은 쿼리 실행 계획을 참조하세요.
쿼리에 여러 분할이 포함된 경우 Spanner는 분할 전체에서 쿼리를 동시에 실행할 수 있습니다. 동시 로드 정도는 쿼리가 스캔하는 데이터 범위, 쿼리 실행 계획, 분할에 걸쳐 데이터가 배포되는 방식에 따라 다릅니다. Spanner는 최적의 쿼리 성능을 얻고 CPU 과부하를 방지하기 위해 인스턴스 크기와 인스턴스 구성(리전 또는 멀티 리전)을 기준으로 쿼리의 최대 수준의 동시 로드를 자동으로 설정합니다.
캐싱
쿼리 처리의 아티팩트 중 대부분은 자동으로 캐시되어 후속 쿼리에 다시 사용됩니다. 여기에는 쿼리 대수, 실행 가능 쿼리 계획 등이 포함됩니다. 캐싱은 바인딩된 매개변수의 유형, 이름, 쿼리 텍스트 등을 기반으로 합니다. 따라서 바인딩된 매개변수(위 예시에서의 @firstName)를 사용하는 것이 쿼리 텍스트에서 리터럴 값을 사용하는 것보다 좋습니다. 전자는 한 번 캐시되어 실제 바인딩된 값과 관계없이 다시 사용될 수 있습니다. 자세한 내용은 Spanner 쿼리 성능 최적화를 참조하세요.
오류 처리
executeQuery 메서드의 결과 행 스트림은 일시적인 네트워크 오류, 한 서버에서 다른 서버로 분할 전달(예: 부하 분산), 서버 다시 시작(예: 새 버전으로 업그레이드) 등을 포함한 다양한 이유로 인해 중단될 수 있습니다. 이러한 오류가 복구되도록 Spanner는 부분 결과 데이터의 배치와 함께 불투명한 '재개 토큰'을 보냅니다. 쿼리가 중단된 곳에서 쿼리를 재시도할 때 이러한 재개 토큰을 사용할 수 있습니다. Spanner 클라이언트 라이브러리를 사용하면 이 작업은 자동으로 수행됩니다. 따라서 클라이언트 라이브러리 사용자는 이러한 유형의 일시적인 오류에 대해 걱정할 필요가 없습니다.