この記事では、長期間の分析のために Cloud Monitoring の指標をエクスポートする方法について説明します。Cloud Monitoring には、Google Cloud と Amazon Web Services(AWS)を対象とするモニタリング ソリューションが用意されています。モニタリング指標には期限の制約があることが多く、Cloud Monitoring は指標を 6 週間保持します。そのため、指標は時間の経過とともに過去の値から削除されることになります。6 週間経過後の指標も分析対象に含めることで、短期間での分析では明らかにならない長期間での傾向を分析し、有意な結果を導き出せる可能性があります。
今回のソリューションでは、エクスポートの際の指標に関する詳細と、BigQuery へ指標をエクスポートする際のサーバーレスでのリファレンス実装について、詳細を説明します。
State of DevOps で、ソフトウェア デリバリーのパフォーマンスを向上させると認められた機能が報告されています。このシリーズでは、次の機能について説明します。
指標のエクスポートに関するユースケース
Cloud Monitoring は、 Google Cloud、AWS、アプリのインストルメンテーションから指標とメタデータを収集します。Monitoring の指標を使用することで、API、ダッシュボード、Metrics Explorer を通じて、クラウドアプリのパフォーマンス、稼働時間、全体の状態の詳細なオブザーバビリティを提供できます。これらのツールでは、過去 6 週間の分析用指標値を確認できますが、長期的な指標分析が必要な場合は、Cloud Monitoring API を使用して長期保存用の指標をエクスポートします。
Cloud Monitoring は、直近の 6 週間の指標を保持します。仮想マシンのインフラストラクチャ(CPU、メモリ、ネットワークの指標)およびアプリケーションのパフォーマンス指標(リクエストまたはレスポンスのレイテンシ)のモニタリングといった運用を目的として頻繁に使用されます。これらの指標が事前に定められたしきい値を超えると、警告が発せられることで、運用上のプロセスがトリガーされます。
取得された指標は、長期間での分析でも役立つ可能性があります。たとえば、サイバー マンデーなどのトラフィックの多いイベントがある場合に、アプリのパフォーマンス指標を前年の指標と比較して、次の同様のイベントに備えるケースがあります。また、 Google Cloud サービスの使用状況を四半期または年単位で確認し、コストをより正確に予測するような場合も考えられます。月単位、もしくは年単位でアプリのパフォーマンス指標を閲覧したいときもあるでしょう。
このように、長期間での分析を前提に、指標を保持しておく必要が生じる場合があります。そのようなときには、該当する指標を BigQuery にエクスポートすることで、同様のケースに対処するうえで必要な分析機能が提供されます。
要件
Monitoring の指標データに対して長期間の分析を行うには、主な要件として、次の 3 つが必要になります。
- Cloud Monitoring からのデータのエクスポート。Cloud Monitoring の指標データは、集計された指標値としてエクスポートする必要があります。未加工の
timeseriesデータポイントを格納することは技術的には実現可能ですが、値が追加されないため、指標の集計が必要です。長期分析は、長期間にわたって集計された状態で実施されることがほとんどです。どの程度の粒度で集計するかはユースケースごとに異なりますが、少なくとも 1 時間の範囲での集計が推奨されます。 - 分析用データの取り込み。分析用に、エクスポートした Cloud Monitoring 指標を分析エンジンにインポートする必要があります。
- データに対するクエリおよびダッシュボードの作成。データのクエリ、分析、可視化を行うには、ダッシュボードと標準 SQL へのアクセスが必要です。
ステップごとの機能
- エクスポートの対象とする指標の一覧を作成します。
- Monitoring API から指標を読み取ります。
- Monitoring API からエクスポートされた JSON 出力の指標を、BigQuery テーブル形式にマッピングします。
- 指標を BigQuery に書き込みます。
- 指標をプログラムで定期的にエクスポートするスケジュールを作成します。
アーキテクチャ
アーキテクチャの設計では、マネージド サービスを活用し、運用と管理の負担軽減を図ります。また、コストを削減し、必要に応じてスケーリングできるようにします。
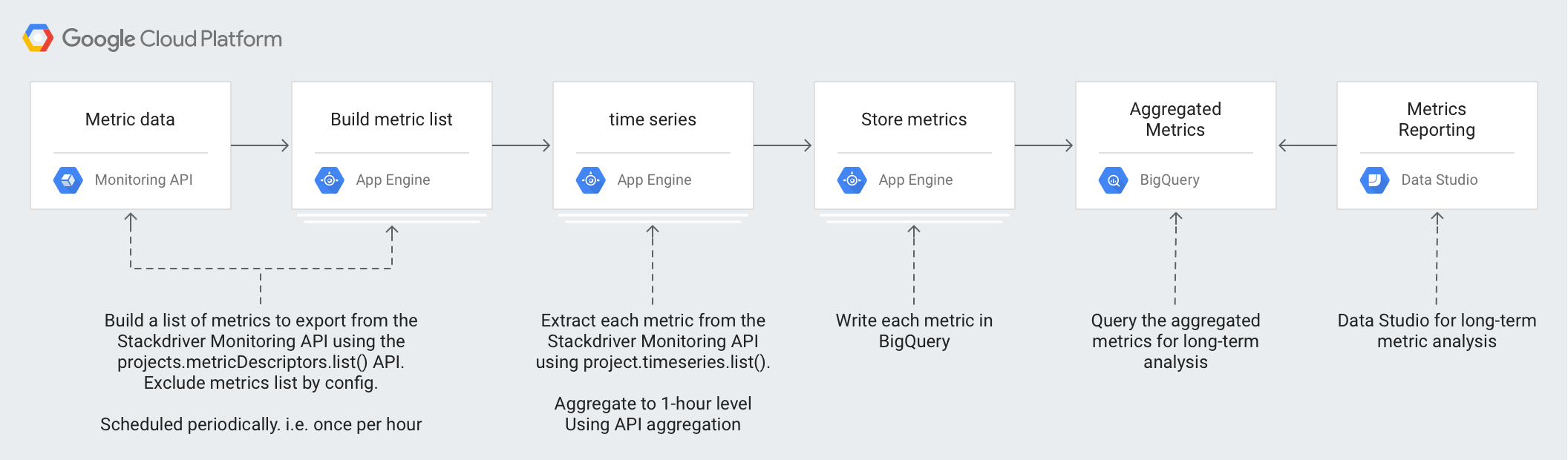
アーキテクチャでは、次の技術を使用します。
- App Engine - スケーラブルな Platform as a Service(PaaS)ソリューション。Monitoring API の呼び出しと BigQuery への書き込みに使用します。
- BigQuery - フルマネージド分析エンジン。
timeseriesデータの取り込みと分析に使用します。 - Pub/Sub - フルマネージドのリアルタイム メッセージング サービス。スケーラブルな非同期処理を行うために使用します。
- Cloud Storage - デベロッパーと企業を対象にした統合オブジェクト ストレージ。エクスポートの状態に関するメタデータの保存に使用します。
- Cloud Scheduler - cron 形式のスケジューラ。エクスポート プロセスを実行する際に使用します。
Cloud Monitoring 指標の詳細を理解する
Cloud Monitoring から指標をエクスポートする最適な方法を理解するには、指標の保存方法を理解することが重要です。
指標タイプ
エクスポートできる Cloud Monitoring の指標には、主に 4 つのタイプがあります。
- Google Cloud 指標リスト: Compute Engine や BigQuery などのサービスからの指標です。 Google Cloud
- エージェント指標リスト: Cloud Monitoring エージェントを実行している VM インスタンスの指標です。
- AWS 指標リスト: Amazon Redshift や Amazon CloudFront などの AWS サービスの指標です。
- 外部ソースの指標: サードパーティ アプリケーションの指標やユーザーの定義による指標です。カスタム指標も含まれます。
これらの各指標タイプには、指標タイプとその他の指標メタデータを含んだ指標記述子が定められています。次の指標は、Monitoring API の projects.metricDescriptors.list メソッドの指標記述子の一覧の例です。
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
指標記述子から把握できる重要な値は、type、valueType、metricKind の各フィールドです。これらのフィールドは、個々の指標の指定に使用できます。また、指標記述子で行える集計に関係します。
指標種別
各指標には、指標の種類と値タイプがあります。詳細については、値タイプと指標の種類をご覧ください。指標の種類と関連する値タイプは、その組み合わせにより指標の集計方法を左右するため、非常に重要です。
先に挙げた例では、指標タイプ pubsub.googleapis.com/subscription/push_request_count metric には、指標の種類 DELTA と値タイプ INT64 があります。

Cloud Monitoring では、指標の種類と値タイプは metricsDescriptors に保存され、Monitoring API で使用できます。
時系列
timeseries は、指標タイプ、メタデータ、ラベル、個々の測定データポイントを含む、時間経過とともに保存された各指標タイプの定期的な測定値です。Google Cloud や AWS の指標など、Monitoring によって自動的に収集される指標は、定期的に収集されます。たとえば、appengine.googleapis.com/http/server/response_latencies 指標は 60 秒ごとに収集されます。
特定の timeseries について収集された一連のポイントは、レポートされたデータの頻度と指標タイプに関連付けられたラベルに基づいて、時間経過とともに増加する可能性があります。未加工の timeseries データポイントをエクスポートすると、結果として大量のエクスポートになる可能性があります。返される timeseries データポイントの数を減らすには、一定の期間を範囲として指標を集計します。たとえば、1 分あたり 1 データポイントだった任意の指標 timeseries に対して、集計を行うことで、1 時間あたり 1 データポイントを返すようにできます。こうすることで、エクスポートされるデータポイントの数を減らし、分析エンジンで必要となる分析処理を軽減できます。この記事では、選択した指標タイプごとに timeseries が返されます。
指標の集計
集計を使用して、複数の timeseries を単一の timeseries にデータを結合できます。Monitoring API には強力な配置機能と集計機能があり、集計を自身で行う必要はありません。配置と集計に関するパラメータを API 呼び出しに渡すだけで処理が行えます。Monitoring API における集計の仕組みの詳細については、フィルタリングと集計およびブログ投稿をご覧ください。
metric type を aggregation type にマッピングすることで、分析ニーズに合わせて指標の配置と、timeseries の削減を適切に行うことができます。timeseries を集計するのに使用できる配置指定子と削減指定子のリストがあります。配置指定子と削減指定子は、指標の種類と値タイプによって、配置または削減できる指標の組み合わせが決められています。たとえば、1 時間を超える期間に対して集計を行うと、timeseries の集計結果として 1 時間あたり 1 ポイントが返されます。
集計を微調整するもう 1 つの方法は、集計値を集計された timeseries のリストにグループ化できる Group By 関数を使用することです。たとえば、App Engine のモジュールを選択して、そのモジュールに関して App Engine の指標をグループ化できます。配置指定子や削減指定子を 1 時間の期間で集計するように指定し、App Engine モジュールと組み合わせてグループ化することで、App Engine モジュール 1 つあたりで、1 時間に 1 データポイントが生成されるようになります。
指標の集計を行うことで、個々のデータポイントの記録によるコストの増加とのバランスを取りながら、長期間の詳細な分析を行ううえで十分なデータを保持できます。
リファレンス実装の詳細
リファレンス実装には、アーキテクチャ設計の図で示したものと同じコンポーネントが備えられています。各ステップでの機能面での実装、および関連する実装については、以下をご覧ください。
指標の一覧の作成
Cloud Monitoring には、 Google Cloud、AWS、サードパーティ ソフトウェアのモニタリングに活用できる 1,000 を超える指標タイプが定義されています。Monitoring API には、projects.metricDescriptors.list メソッドが用意されており、 Google Cloudプロジェクトで使用できる指標のリストが返されます。Monitoring API にはフィルタリングの仕組みもあり、長期間でのデータ保存と分析用にエクスポートする指標の一覧にフィルタをかけることもできます。
GitHub のリファレンス実装では、Python App Engine アプリを使用して指標のリストを取得し、Pub/Sub トピックに各メッセージを個別に書き込みます。エクスポートは、アプリを実行するための Pub/Sub 通知を生成する Cloud Scheduler によって開始されます。
Monitoring API を呼び出すにはさまざまな方法があります。今回は、Google API に柔軟にアクセスできるため、Python 用 Google API クライアント ライブラリを使用して Cloud Monitoring と Pub/Sub API を呼び出します。
timeseries を取得する
指標の timeseries を抽出して、それぞれの timeseries を Pub/Sub に書き込みます。Monitoring API では、project.timeseries.list メソッドを使用して、特定のアライメント期間の指標値を集計できます。データを集計することで、処理時の負荷、ストレージの要件、クエリ時間、分析コストを削減できます。長期間での指標分析を効率的に実施するには、データの集計を行うことをおすすめします。
GitHub のリファレンス実装では、トピックの登録に Python で記述された App Engine アプリが使用されており、エクスポートの際の各指標が個別のメッセージとして送信されます。受信したメッセージごとに、Pub/Sub はメッセージを App Engine アプリに push します。アプリは、入力構成に基づいて集計された特定の指標の timeseries を取得します。この場合、Cloud Monitoring API と Pub/Sub API は、Google API クライアント ライブラリを使用して呼び出されます。
各指標は timeseries. を 1 つ以上返すことができます。各指標は、BigQuery に挿入する個別の Pub/Sub メッセージによって送信されます。指標 type-to-aligner と指標 type-to-reducer のマッピングは、リファレンス実装に組み込まれています。次の表に、リファレンス実装で使用されているマッピングについて示します。配置指定子と削減指定子のそれぞれがサポートする指標の種類と値タイプについて分類しています。
| 値タイプ | GAUGE |
配置指定子 | 削減指定子 | DELTA |
配置指定子 | 削減指定子 | CUMULATIVE2 |
配置指定子 | 削減指定子 |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
○ |
ALIGN_FRACTION_TRUE
|
なし | × | N/A | N/A | × | N/A | N/A |
INT64 |
○ |
ALIGN_SUM
|
なし | ○ |
ALIGN_SUM
|
なし | ○ | なし | なし |
DOUBLE |
○ |
ALIGN_SUM
|
なし | ○ |
ALIGN_SUM
|
なし | ○ | なし | なし |
STRING |
○ | 除外 | 除外 | × | N/A | N/A | × | N/A | N/A |
DISTRIBUTION |
○ |
ALIGN_SUM
|
なし | ○ |
ALIGN_SUM
|
なし | ○ | なし | なし |
MONEY |
× | N/A | N/A | × | N/A | N/A | × | N/A | N/A |
集計は、配置指定子と削減指定子ごとに特定の valueTypes と metricKinds に対してのみ可能であるため、valueType の配置指定子と削減指定子へのマッピングを考慮することが重要です。
たとえば、pubsub.googleapis.com/subscription/push_request_count metric タイプについて考えてみましょう。指標の種類が DELTA で、値タイプが INT64 であれば、指標を集計する方法の 1 つとして、次のような方法があります。
- 集計対象期間 - 3600 秒(1 時間)
Aligner = ALIGN_SUM- 集計期間内の結果のデータポイントは、集計期間内のすべてのデータポイントの合計です。Reducer = REDUCE_SUM- 各集計期間のtimeseriesの合計を計算することで、データポイントを減らします。
project.timeseries.list メソッドには、集計対象期間、配置指定子、削減指定子の値に加えて、他にもいくつかの入力が必要です。
filter- 返す指標を選択します。startTime-timeseriesを返す際の開始時間を選択します。endTime-timeseriesを返す際の最終時間を選択します。groupBy-timeseriesのレスポンスをグループ化するフィールドを入力します。alignmentPeriod- 指標の集計範囲とする時間間隔を入力します。perSeriesAligner-alignmentPeriodで定義された時間で等間隔にポイントを調整します。crossSeriesReducer- 異なるラベル値を持つ複数のポイントを、時間間隔ごとに 1 つのポイントにまとめます。
API に対する GET リクエストには、前述のすべてのパラメータが含まれています。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
次の HTTP GET は、入力パラメータを使用した projects.timeseries.list API メソッドの呼び出し例を示しています。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
前述の Monitoring API 呼び出しには crossSeriesReducer=REDUCE_SUM が含まれています。これは、次の例のように、指標がまとめられて単一の合計に削減されています。
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
このレベルの集計では、プロジェクト全体の理想的な指標となる 1 つのデータポイントにデータが集約されます。 Google Cloud ただし、どのリソースが指標に影響しているのか詳しく確認することはできません。先に挙げた例では、リクエスト数に最も影響をもたらした Pub/Sub サブスクリプションがどれなのかはわかりません。
timeseries を生成する個々のコンポーネントの詳細を確認するには、crossSeriesReducer パラメータを削除します。crossSeriesReducer がない場合、Monitoring API は単一の値を作成するために、さまざまな timeseries を結合しません。
次の HTTP GET は、入力パラメータを使用した projects.timeseries.list API メソッドの呼び出し例を示しています。crossSeriesReducer は含まれていません。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
次の JSON レスポンスでは、timeseries がグループ化されているため、両方の結果で metric.labels.keys が同じになります。resource.labels.subscription_ids 値ごとに個別のポイントが返されます。次の JSON の metric_export_init_pub と metrics_list の値を確認します。BigQuery クエリでリソースラベルとして含まれているGoogle Cloud プロダクトを使用できるため、このレベルの集計をおすすめします。
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
projects.timeseries.list API 呼び出しの JSON 出力の各指標は、個別のメッセージとして Pub/Sub に直接書き込まれます。1 つの入力指標が 1 つ以上の timeseries を生成するファンアウトが起こる可能性があります。Pub/Sub には、タイムアウトを超えずに大規模なファンアウトを吸収する機能が用意されています。
集計対象の期間は入力として指定されますが、指定された時間枠を超える値については、前述のレスポンス例にもあるように、単一の値にまとめて集計されます。また、集計対象期間により、エクスポートの実施頻度も定められます。たとえば、集計対象期間が 3,600 秒(1 時間)の場合、エクスポートは 1 時間ごとに実行され、timeseries が定期的にエクスポートされます。
指標の保存
GitHub のリファレンス実装では、Python App Engine アプリを使用して各 timeseries を読み込み、レコードを BigQuery テーブルに挿入します。受信したメッセージごとに、Pub/Sub はメッセージを App Engine アプリに push します。Pub/Sub メッセージには、Monitoring API から JSON 形式でエクスポートされた指標データが含まれており、BigQuery のテーブル構造にマッピングする必要があります。この際、BigQuery API の呼び出しには Google API Client Library が使用されます。
BigQuery のスキーマは、Monitoring API からエクスポートされた JSON に近い形式でマッピングできるように設計されています。ただ、データサイズの規模が時間の経過とともに拡大していくため、BigQuery テーブルのスキーマを構築する際には、その点を考慮しておく必要があります。
BigQuery では、日付フィールドでテーブルを分割することをおすすめします。日付で範囲を指定することで、すべてのテーブルをスキャンすることなく、より効率的にクエリを実行できます。定期的にエクスポートを実施する場合は、取り込み日を基準にデフォルトのパーティションを使用すると安全です。
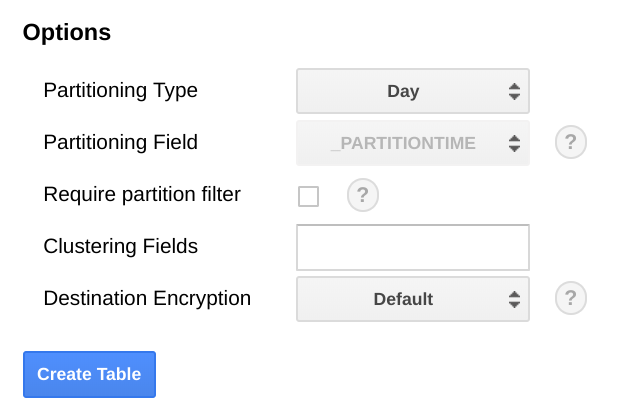
指標を一括アップロードする場合や、エクスポートを定期的に実行しない場合は、end_time, で分割します。その際、BigQuery スキーマの変更が必要です。end_time をスキーマ内の最上位フィールドに移動して、そこでパーティショニングに使用するか、スキーマに新しいフィールドを追加できます。end_time フィールドは BigQuery レコードに含まれており、パーティショニングは最上位フィールドで行われる必要があるため、このフィールドの移動は必須です。詳細については、BigQuery でのパーティショニングに関するドキュメントをご覧ください。
また、BigQuery には、一定の期間が経過した場合に、データセット、テーブル、テーブル分割を期限切れとする機能もあります。
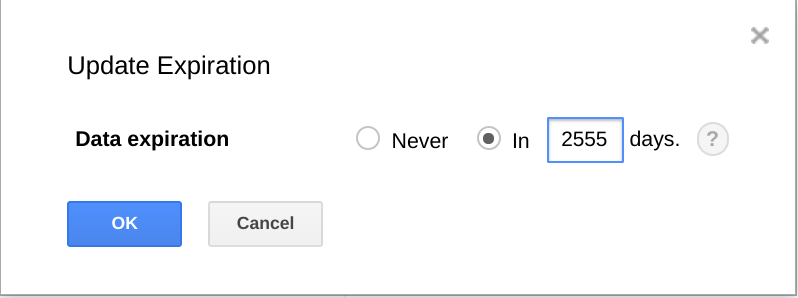
この機能を使用すると、データが不要になった際に、古いデータを削除できます。たとえば、分析の対象期間が 3 年であれば、3 年以上前のデータを削除するポリシーを追加できます。
エクスポートのスケジュールを設定する
Cloud Scheduler は、フルマネージドの cron ジョブ スケジューラです。Cloud Scheduler では、標準の cron スケジュール形式を使用して、App Engine アプリの起動、Pub/Sub を使用したメッセージの送信、任意の HTTP エンドポイントに対するメッセージ送信を行えます。
GitHub のリファレンス実装では、Cloud Scheduler は、App Engine の構成と一致するトークンを含む Pub/Sub メッセージを送信して、list-metrics App Engine アプリを 1 時間ごとに起動します。アプリにデフォルトで構成されている集計期間は 3600 秒か 1 時間で、アプリの起動される頻度にも関係します。集計期間は、データ量の削減とデータ精度の維持とのバランスを考え、最低でも 1 時間以上にすることをおすすめします。集計対象期間を別の値に設定する場合は、エクスポートの頻度も集計対期間に合わせて変更してください。リファレンス実装では、最後の end_time 値が Cloud Storage に保存され、start_time がパラメータとして渡されない限り、その値が後続の start_time として使用されます。
次の Cloud Scheduler のスクリーンショットは、 Google Cloud コンソールを使用して list-metrics App Engine アプリを 1 時間ごとに起動するように Cloud Scheduler を構成する方法を示しています。
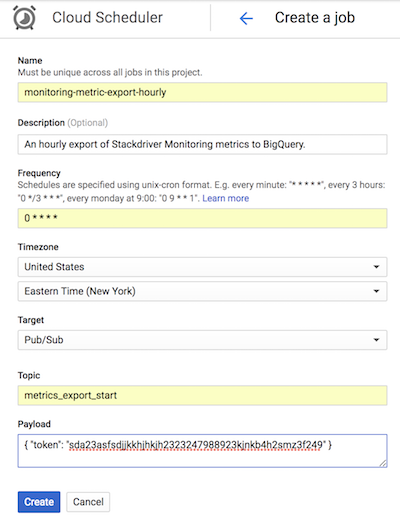
[Frequency] フィールドでは、cron 形式の構文を使用して Cloud Scheduler にアプリの実行頻度を指示します。[Target] には、生成される Pub/Sub メッセージを指定し、[Payload] フィールドには Pub/Sub メッセージに含まれるデータを格納します。
エクスポートされた指標の使用
エクスポートされたデータを BigQuery で使用して、データに対して標準 SQL クエリを実行したり、ダッシュボードを作成して指標の時系列での傾向を可視化したりできます。
サンプルクエリ: App Engine のレイテンシ
次のクエリでは、App Engine アプリの平均レイテンシ指標値の最小値、最大値、平均値を検索します。metric.type は App Engine 指標を指定し、ラベルは project_id ラベル値に基づいて App Engine アプリを指定します。point.value.distribution_value.mean が使用されるのは、この指標は Monitoring API の DISTRIBUTION 値であるためです。この値は BigQuery の distribution_value フィールド オブジェクトにマッピングされています。end_time フィールドでは、過去 30 日間の値が検索されます。
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
サンプルクエリ: BigQuery のクエリ数
次のクエリでは、プロジェクト内の 1 日あたりの BigQuery に対するクエリ数が返されます。int64_value フィールドが使用されるのは、この指標が Monitoring API の INT64 値であるためです。この値は、BigQuery の int64_value フィールドにマッピングされています。metric.type は BigQuery 指標を指定し、ラベルは project_id ラベル値に基づいてプロジェクトを指定します。end_time フィールドでは、過去 30 日間の値が検索されます。
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
サンプルクエリ: Compute Engine インスタンス
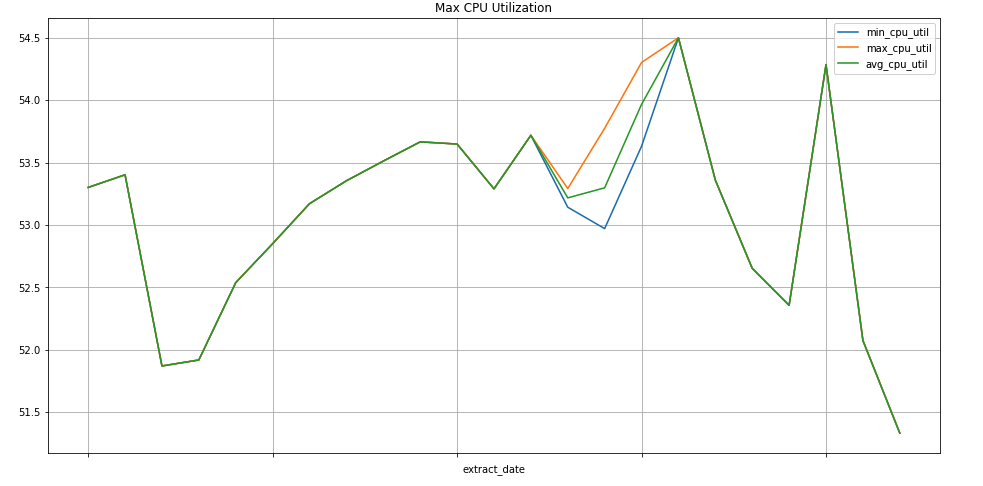
次のクエリでは、プロジェクトの Compute Engine インスタンスの CPU 使用率指標に関する週の最小値、最大値、平均値を検索します。metric.type は Compute Engine 指標を指定し、ラベルは project_id ラベル値に基づいてインスタンスを指定します。end_time フィールドでは、過去 30 日間の値が検索されます。
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
データの可視化
BigQuery には、データの可視化に使用できるさまざまなツールが統合されています。
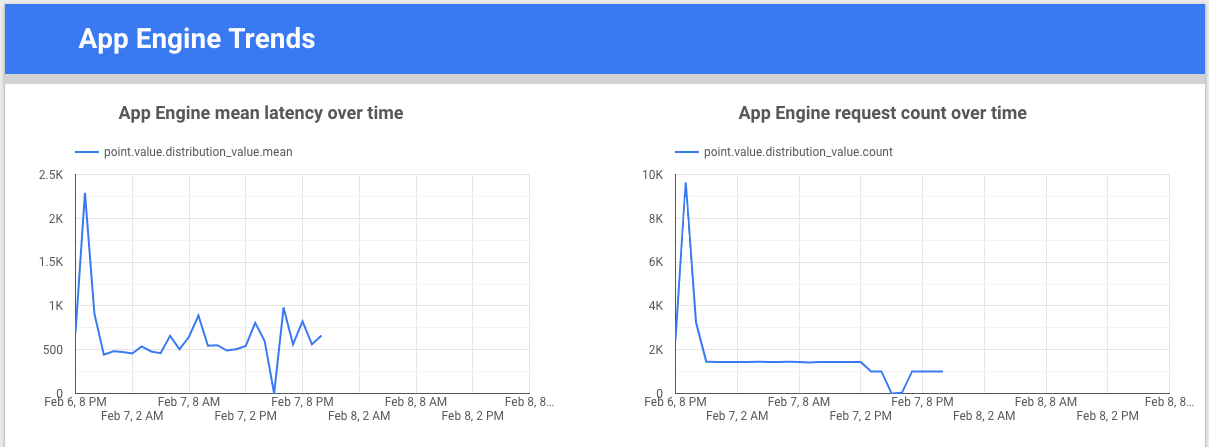
Looker Studio は Google が開発した無料のツールで、データのグラフやダッシュボードを作成して指標データを可視化し、チームと共有できます。次の例は、appengine.googleapis.com/http/server/response_latencies 指標のレイテンシとカウントを時間経過とともに示したトレンドラインのグラフです。
Colaboratory は、ML に関する教育と研究を目的としたリサーチツールです。ホスト型の Jupyter ノートブック環境で、セットアップの必要がなく、BigQuery のデータにアクセスして使用できます。Colab ノートブック、Python コマンド、SQL クエリを使用して、詳細な分析と可視化が行えます。
エクスポートのモニタリングに関するリファレンス実装
エクスポートの実行中には、エクスポートをモニタリングする必要があります。モニタリング対象の指標の決定に際しては、サービスレベル目標(SLO)を設定するという方法があります。SLO では、指標によって測定されるサービスレベルのターゲットとなる値や、値の範囲を定めます。サイト信頼性エンジニアリングの解説書には、SLO に関する 4 つの主要分野として、可用性、スループット、エラー率、レイテンシについて説明があります。データのエクスポートに関しては、スループットとエラー率が考慮すべき項目になり、次の指標を通じてモニタリングできます。
- スループット -
appengine.googleapis.com/http/server/response_count - エラー率 -
logging.googleapis.com/log_entry_count
たとえば、log_entry_count 指標を使用してエラー率をモニタリングし、App Engine アプリ(list-metrics、get-timeseries、write-metrics)を ERROR の重大度でフィルタリングできます。その後、Cloud Monitoring のアラート ポリシーを使用して、エクスポート アプリで発生したエラーをアラートできます。
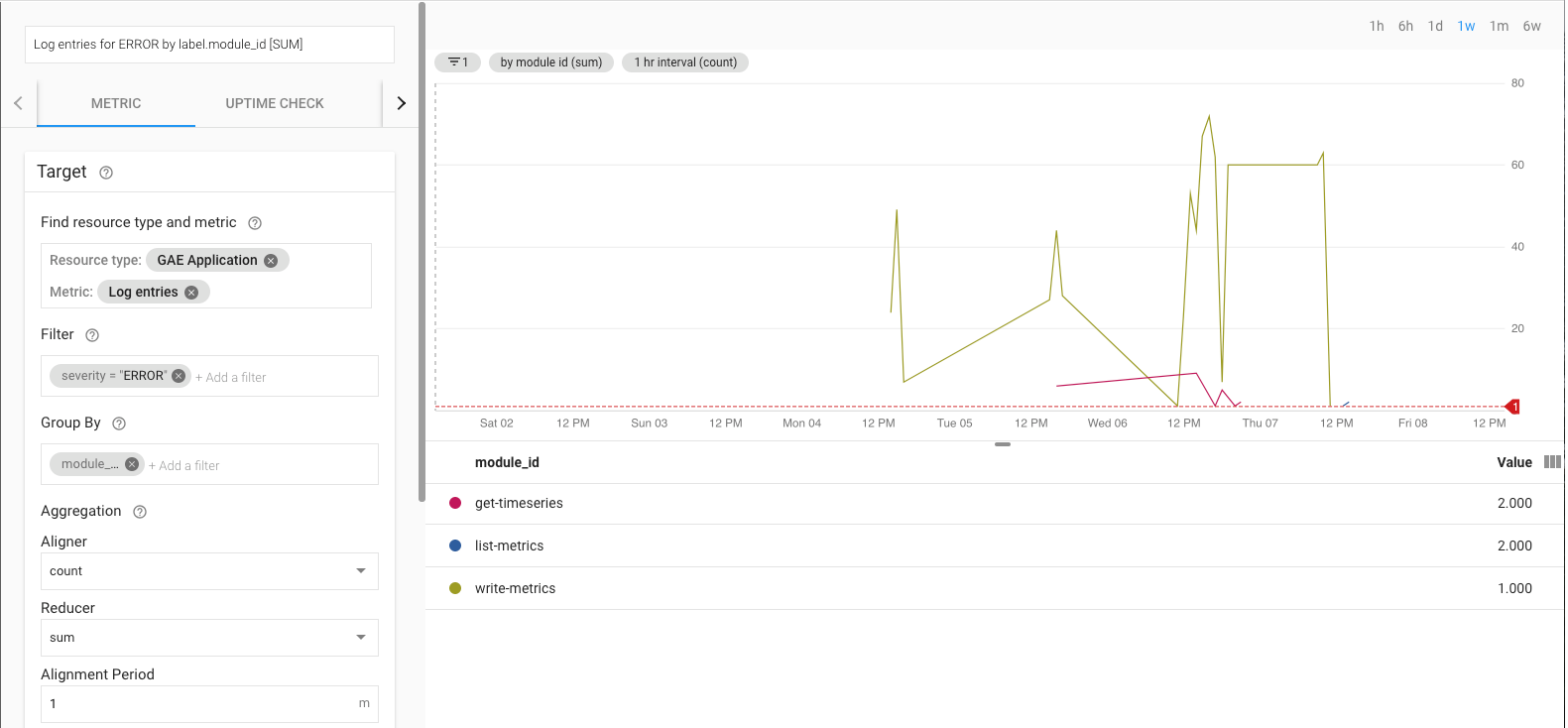
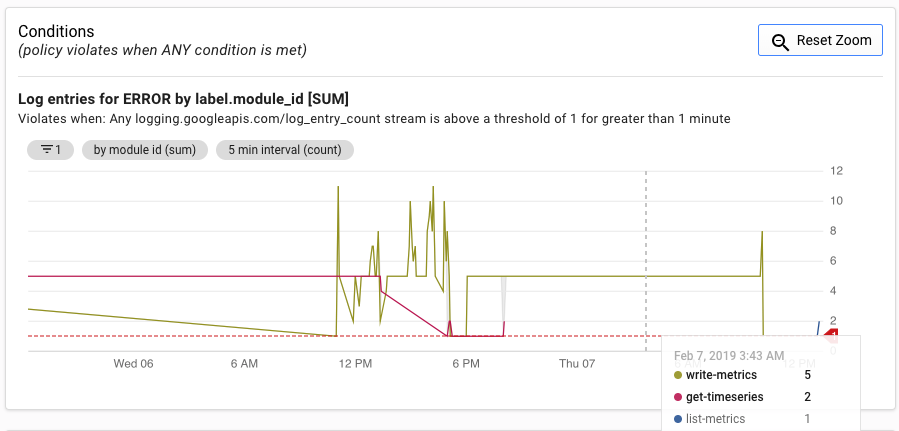
アラート UI には、アラートの生成のしきい値と比較した log_entry_count 指標のグラフが表示されます。
次のステップ
- GitHub のリファレンス実装を確認する。
- Cloud Monitoring のドキュメントを確認する。
- Cloud Monitoring v3 API のドキュメントを確認する。
- リファレンス アーキテクチャ、図、ベスト プラクティスについては、Cloud アーキテクチャ センターをご確認ください。
- DevOps に関するリソースを読む。
このソリューションに関連する DevOps 機能の詳細について確認する。
DevOps のクイック チェックで、業界における立ち位置を把握する。